客户端说明及作用
客户端说明
客户端节点是不需要安装datanode等组件的,只作为一个Gateway用于hdfs数据查询和任务提交等工作
单独部署的原因
对于一个较大的集群来说,数据安全性是比较重要的,可能不允许开发或测试人员直接登录数据节点,避免误操作删除数据,那么只能部署客户端提供给开发人员或者测试人员来使用
还有就是如果客户端和数据节点部署在一起,根据HDFS数据副本机制,第一个副本会存放在本地机器,所以可能会造成数据不均衡
添加客户端
同步hosts文件
随便登录一台集群中的主机,然后将hosts文件同步至Gateway节点
scp /etc/hosts root@Gateway节点:/etc/
安装krb5客户端
如果集群开启kerberos需要安装客户端,如果没有开启可以忽略这一步
安装kerber客户端
yum install -y krb5-workstation
随便登录集群中的主机,将krb5.conf配置文件拷贝到客户端节点
scp /etc/krb5.conf root@Gateway节点:/etc/
验证是否可以认证成功 ```shell kinit xxx
klist
<a name="4CNm4"></a>### 安装JDK1. 卸载客户端现有的OpenJDK```shellrpm -qa|grep openjdk |xargs -I {} rpm -e --nodeps {}
- 安装和集群一致的JDK
rpm -ivh jdk-8u181-linux-x64.rpm

拷贝Parcel包
登录到集群中的任意一台节点,压缩parcel包
cd /opt/cloudera/parcels/ tar -zcvf cdh_parcel.tar.gz CDH-6.2.0-1.cdh6.2.0.p0.967373/ CDH/ scp /opt/cloudera/parcels/cdh_parcel.tar.gz root@Gateway节点:/opt在Gateway节点中创建文件夹,并解压parcels包
mkdir -p /opt/cloudera/parcels/ tar -zxvf /opt/cdh_parcel.tar.gz -C /opt/cloudera/parcels/检查是否解压成功
ll /opt/cloudera/parcels/拷贝配置文件
在客户端节点创建配置文件目录
mkdir -p /etc/spark/conf mkdir -p /etc/hadoop/conf mkdir -p /etc/hbase/conf mkdir -p /etc/hive/conf
拷贝配置文件,进入集群中的spark、hadoop、hbase、hive等Gateway节点上将/etc/*/conf目录下的配置文件拷贝至客户端节点的相应目录下
scp -r /etc/hadoop/conf/* 客户端节点:/etc/hadoop/conf scp -r /etc/spark/conf/* 客户端节点:/etc/spark/conf scp -r /etc/hbase/conf/* 客户端节点:/etc/hbase/conf scp -r /etc/hive/conf/* 客户端节点:/etc/hive/conf将各组件的配置文件解压到对应的/etc/组件/目录下




- 添加环境变量,修改/etc/profile配置文件,在文件的末尾增加如下配置 ```shell vim /etc/profile
export CDH_HOME=/opt/cloudera/parcels/CDH export PATH=$CDH_HOME/bin:$PATH

5. 使环境变量生效
```shell
source /etc/profile
需要注意的是,如果要配置多版本集群的客户端,可以将环境变量调整如下,可以将不同版本的Parcels解压然后在指定,如果集群版本只有一个 这个可以忽略
export PATH=$PATH:/opt/cloudera/parcels/CDH/bin export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop export HADOOP_CONF_DIR=/etc/hive/conf export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive export CDH_MR2_HOME=/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark测试
HDFS测试
上传文件 ```shell
先认证Kerberos用户
kinit hdfs_admin_131
创建测试文件,并上传HDFS
echo “tb hdfs test” >> text.txt hdfs dfs -put text.txt /tmp
查看是否上传成功
hdfs dfs -ls /tmp
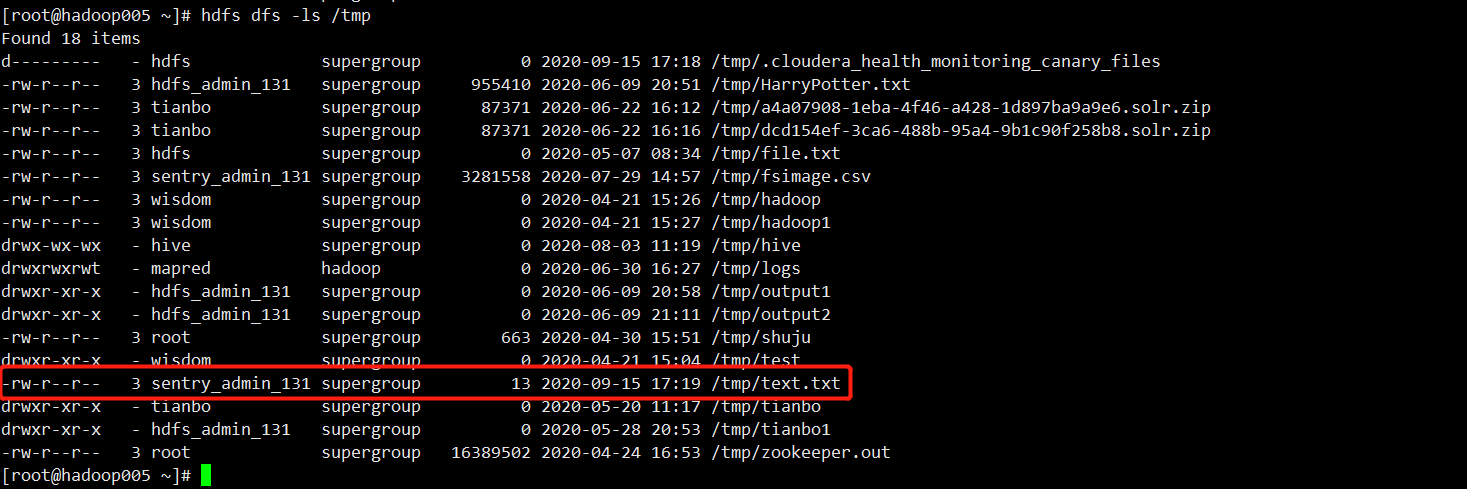
2. 删除文件
```shell
hdfs dfs -rm /tmp/text.txt
Yarn测试
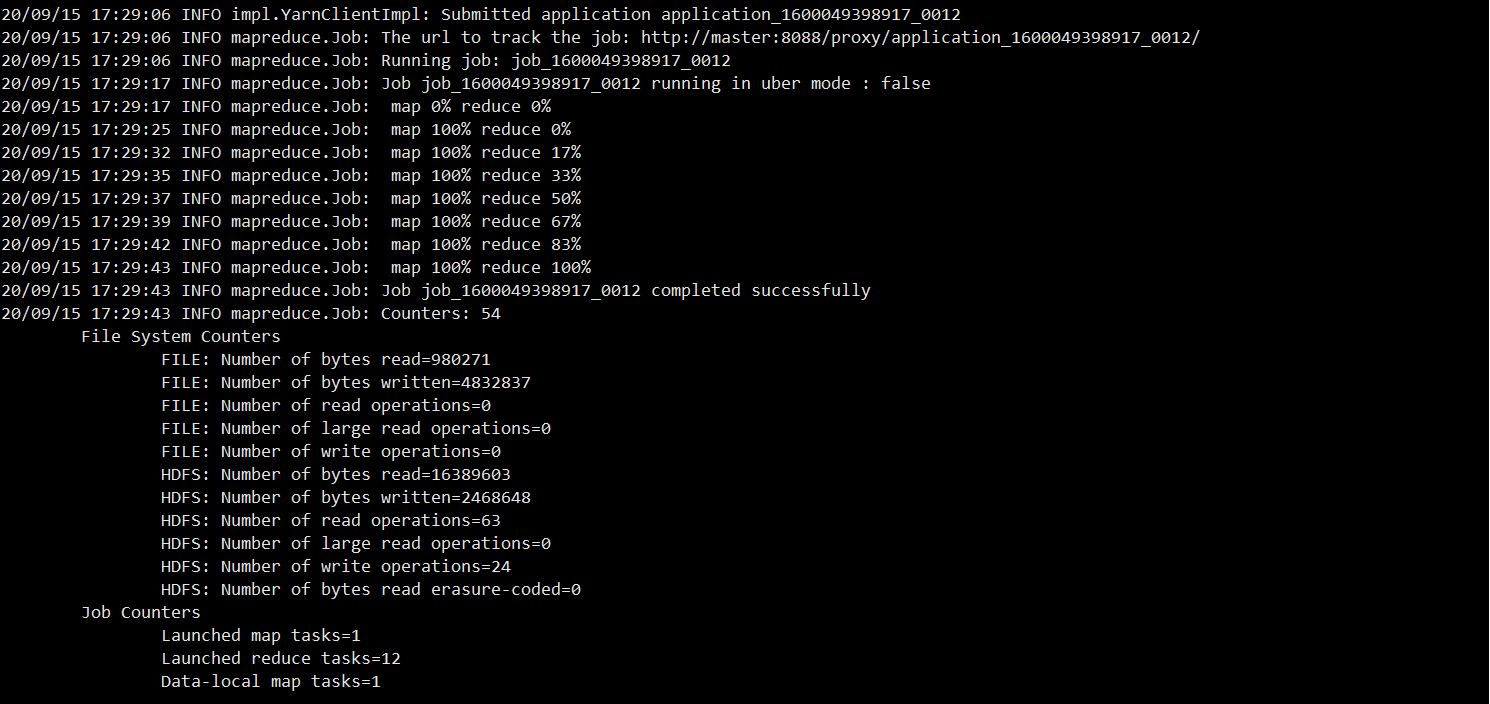
提交WC任务
hadoop jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/hadoop-mapreduce-examples-3.0.0-cdh6.2.0.jar wordcount /tmp/zookeeper.out /tmp/output1Hive测试
建库建表测试 ```shell
认证用户
kinit sentry_admin_131
使用beeline连接Hive
beeline -u “jdbc:hive2://load:10001/;principal=hive/load@FAYSON.COM”
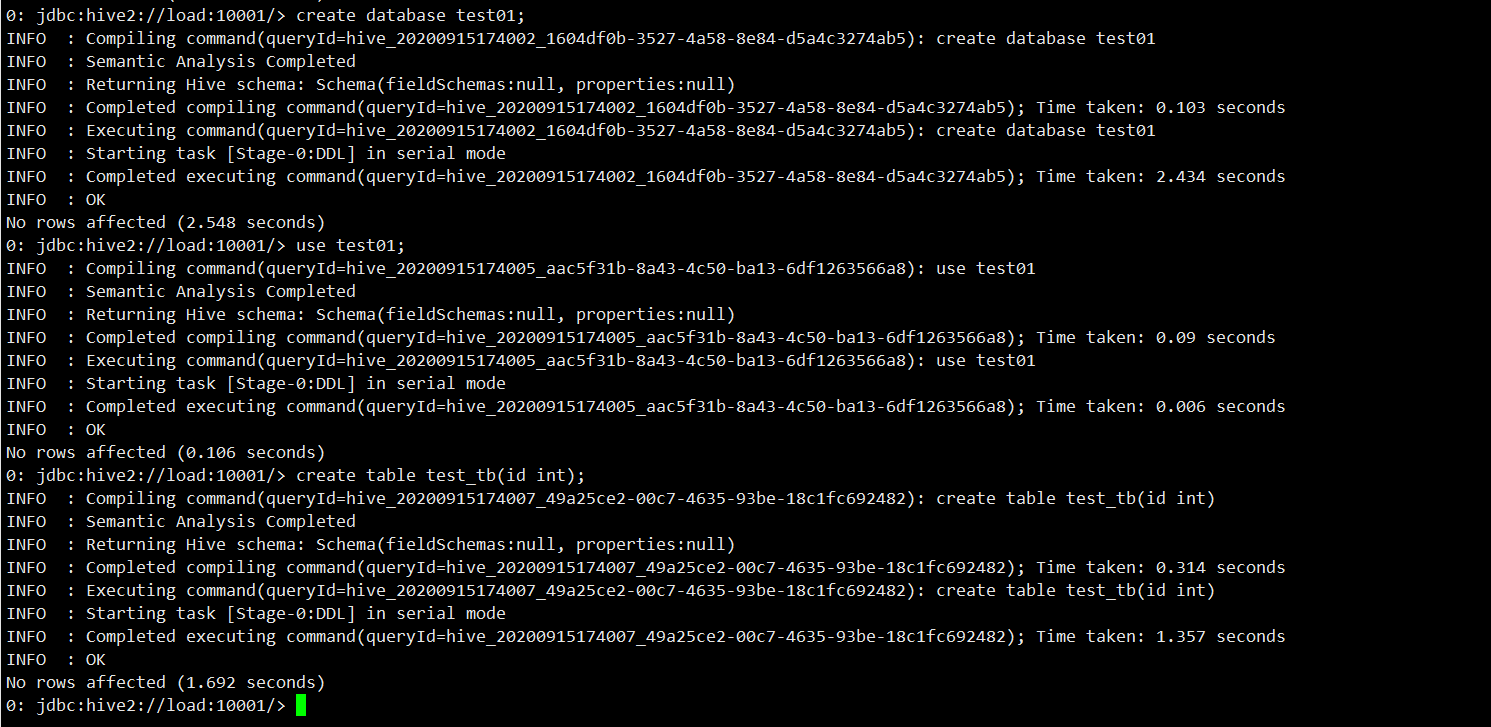
建库建表
create database test01;
use test01;
create table test_tb(id int);
```

若有收获,就点个赞吧
0 人点赞
