参考文章:
我的知识管理标签系统 | 原创干货分享 (简书的文章) 手把手教你打造一套最牛的知识笔记管理系统!(知乎)
1.为什么需要索引体系统?
任何一件事物都可以有很多个维度。
如果你把某事物按照一个维度归类,你就相当于把它给定死了,同理我们的知识依旧如此。
很多人的笔记之所以没有效率,用的时候找不到,很大的原因就是你把知识给限定死了。
那么如何解决这个问题呢?
打标签就是为解决这个问题设置的,你可以给一个知识点打上无数个标签,当你搜索任何一个标签维度的时候都能够索引到这个知识点。
如此,我们就不用纠结于某个知识点具体该归入『储存体』的那个文件夹中,无论是你放到那,只要标签打上了,就不用担心索引问题。
当你部署了一系列标签的时候,你的知识就活了。
2.索引体系统是什么?
笔记量和标签一多,标签本身也就乱了,都不知道标签那个是哪个了,那如何解决这一系列问题呢?
就需要建立一套索引相关的系统,管理整个索引体系,这就是索引体系统。
3.索引体系统如何建立?
不同的人都有合适自己的索引体系统,因人而异。
我参考了他人的索引系统,建立了这样一套索引系统。
① 底层系统搭建
储存体有GTD作为底层操作系统,那么索引体同样也应该有操作系统作为分类。
我的索引体的分类规则就是学科分类、方法论、体裁三个分类,因为你笔记上所有的东西都逃不过这三点,它是符合MECE的。
② 一个维度分类所有知识标签
体系的构成一定有底层分类作为支撑的,所以想要把零散的标签,编织成系统就需要对他们进行分类,那么从作用的维度,你会把 “所有的知识” 标签分成哪几类?
可能每个人都有自己的标准~
我本人按照和参考了 “儒家的最高理想” 把一个人的一生所有的知识分成了四类:
为了让两者更有辨识度,文件夹系统作为储存体识别符号『C』,标签系统作为索引体,识别符『S』。
此索引系统分为3个维度:
- 学科门类-杜威十进制分类法
- 方法论
- 体裁
1.学科门类
“学科门类”是该系统的根本大类,其分类原则基于笔记的内容,是最主要和最关键的分类结构。
我采用杜威十进制分类法对各级学科门类进行编号,并按实际需要增加细目。目前来说,编到二级分类基本够用。
学科分类可根据个人习惯和实际用途自行设计,更多关于杜威分类法的内容可登录相关网站查阅资料。目前DDC已更新到23版:杜威十进制分类法 - The Dewey Decimal Classification (DDC) Summaries
一级分类:
- 000 知识和系统(原本为“总类”,我按需求替换)
- 100 哲学类
- 200 宗教类
- 300 社会科学类
- 400 语言文字类
- 500 自然科学类
- 600 技术类
- 700 艺术类
- 800 文学类
- 900 历史地理类
二级分类:
这也是参考 杜威分类法 ,进行了适当的修改而成的。
一般而言,一级分类就够了,如果自己对于某个分类的研究特别深入,则可以进行二级分类。
若是研究超级深入,则可以进行3级分类。这里就不展开赘述了,具体可参考上文中的 杜威十进制分类法 。
| 0 | 知识和系统 | 100 | 哲学 | 200 | 宗教 | 300 | 社会科学、社会学和人类学 | 400 | 语 |
|---|---|---|---|---|---|---|---|---|---|
| 10 | 参考书目 | 110 | 形而上学 | 210 | 宗教哲学与理论 | 310 | 统计数据 | 410 | 语言学 |
| 20 | 图书馆与信息科学 | 120 | 认识论 | 220 | 圣经 | 320 | 政治学 | 420 | 中文和古中文 |
| 30 | 百科全书和事实书籍 | 130 | 超心理学和神秘学 | 230 | 基督教 | 330 | 经济学 | 430 | 英语和古英语 |
| 40 | 小说 | 140 | 哲学思想流派 | 240 | 基督徒的实践与遵守 | 340 | 法律 | 440 | 德语及相关语言 |
| 50 | 杂志、期刊和连续出版物 | 150 | 心理学 | 250 | 基督教牧灵实践和宗教秩序 | 350 | 公共管理与军事科学 | 450 | 法语及相关语言 |
| 60 | 协会、组织和博物馆 | 160 | 哲学逻辑 | 260 | 基督教组织、社会工作和敬拜 | 360 | 社会问题和社会服务 | 460 | 意大利语、罗马尼亚语及相关语言 |
| 70 | 新闻媒体、新闻与出版 | 170 | 伦理 | 270 | 基督教史 | 370 | 教育 | 470 | 西班牙语、葡萄牙语、加利西亚语 |
| 80 | 博客 | 180 | 古代、中世纪和东方哲学 | 280 | 基督教教派 | 380 | 商业、通讯和运输 | 480 | 拉丁语和斜体语言 |
| 90 | 手稿和珍本 | 190 | 现代西方哲学 | 290 | 其他宗教 | 390 | 风俗、礼仪和民俗 | 490 | 其他语言 |
| 500 | 科学(基础科学) | 600 | 技术 | 700 | 艺术 | 800 | 文学、修辞与批评 | 900 | 历史与地理 |
| 510 | 数学 | 610 | 医药与健康 | 710 | 区域规划和景观建筑 | 810 | 中文文学和古中文文学 | 910 | 地理与旅行 |
| 520 | 天文学 | 620 | 工程 | 720 | 建筑学 | 820 | 美国英语文学 | 920 | 传记和家谱 |
| 530 | 物理 | 630 | 农业 | 730 | 雕塑、陶瓷和金属制品 | 830 | 英语和古英语文学 | 930 | 古代世界史(至约 499 年) |
| 540 | 化学 | 640 | 计算机 | 740 | 平面艺术和装饰艺术 | 840 | 德语及相关文献 | 940 | 欧洲史 |
| 550 | 地球科学与地质学 | 650 | 管理与公共关系 | 750 | 绘画 | 850 | 法语及相关文献 | 950 | 亚洲史 |
| 560 | 化石和史前生命 | 660 | 化学工程 | 760 | 版画和版画 | 860 | 意大利语、罗马尼亚语及相关文献 | 960 | 非洲史 |
| 570 | 生物学 | 670 | 制造业 | 770 | 摄影、电脑艺术、电影、录像 | 870 | 西班牙语、葡萄牙语、加利西亚文学 | 970 | 北美历史 |
| 580 | 植物(植物学) | 680 | 为特定用途制造 | 780 | 音乐 | 880 | 拉丁文和斜体文学 | 980 | 南美洲历史 |
| 590 | 动物(动物学) | 690 | 建筑物的建造 | 790 | 运动、游戏和娱乐 | 890 | 其他文献 | 990 | 其他地区的历史 |
2.方法论
整理好的知识只有转化为用途才能体现价值,我为知识的价值流向单独设计了一套标签,命名为“方法论”,它为知识的用途分类,为解决某个知识“可以用来做什么”提供索引。例如:
- S2-1-提升效率
- S2-2-学习技能
- S2-3-精神升华
- S2-4-方法经验
- S2-5-风险预警
- S2-6-写作素材
- S2-7-习惯培养
上述方法论标签可以进一步细分,最终目的是为笔记的价值输出提供分类引导,便于在写作时为论点找寻素材,或是为精进学习指明方向。
3.体裁
顾名思义,就是笔记的体裁类型。笔记有摘抄的也有自己编写的,我利用体裁标签区分不同的创作文体,例如:
- S3-1-计划方案
- S3-2-方法总结
- S3-3-指南手册
- S3-4-宣传文案
- S3-5-合同协议
- S3-6-读书笔记
- S3-7-杂记随笔
- S3-8-故事轶闻
- S3-9-技术文档
该标签组可在多数工作场景中快速检索出相关体裁用做模版。对于原创笔记,可通过对创作文体分类,分析出适合自己的写作风格,非常适合新媒体写作。
4.检索逻辑
介绍完存储系统和标签系统,下面说说使用逻辑。
语雀的搜索功能非常强大,支持复杂的语法检索。这里我简要介绍基于标签系统的检索逻辑,其他涉及检索的代码语法可参考产品手册。
上文说的存储系统加上标签系统的三大类别,我们一共得到4个检索维度,简单回顾一下:
- 存储系统(笔记库):知识的来源或归属
- 学科门类:知识内容的学科分类
- 方法论:知识所能提供的用途或帮助
- 体裁:知识的格式体裁或表现形式
举个例子,我在Kindle上阅读了一本关于欧洲历史文化的书,并从中导出一篇关于十字军东征与拜占庭历史的读书笔记,将其存入笔记,放在“知识库”笔记本组下的“Kindle”笔记本中,同时打上“历史地理类”、“写作素材”、“读书笔记”的标签,与其他数百篇笔记安置在一起。
某天我要写一篇“拜占庭帝国如何影响文艺复兴”的文章时,我会同时检索满足条件的标签,它一定遵循这样的逻辑:
我需要检索出能够当作写作素材(方法论)的历史地理类(学科门类)的读书笔记(体裁),它可能存放在Kinlde(知识来源)笔记本中。
当我完成检索时,所有满足该条件的笔记会迅速罗列在待选清单中,里面不仅有那篇拜占庭历史的笔记,还顺便带出了曾经记录过的“东西罗马帝国的分裂”和“阿拉伯帝国翻译运动”等笔记,这些“意外之喜”都给文章的写作带来莫大的帮助,“知识管理”也在这时最大程度发挥了其价值。
结语
这篇文章的内容仍处在探索阶段,我自己的笔记系统也还在完善中,我将在使用过程中不断迭代本文,所有对标签系统的意见和建议都可以在评论中留言,我们一同探讨改进。
① 底层系统搭建
储存体有GTD作为底层操作系统,那么索引体同样也应该有操作系统作为分类。索引体的分类规则就是我们前文说的『学习』、『工作』、『生活』三个分类,因为你笔记上所有的东西都逃不过这三点,它是符合MECE的。
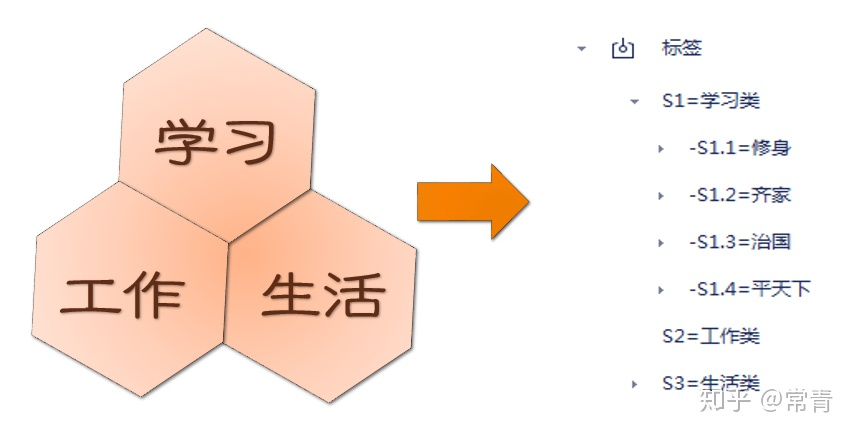
工作和生活的分类我这里不多介绍,因为这个体系不体系无所谓,大家按照自己的喜好打标签即可。这里主要介绍的是『学习』,因为这才是承载我们知识标签的大本营,我们所有的知识标签都以这个分类为底。
那么在『学习』这个分类底下,应该怎么去构建知识架构呢?
② 一个维度分类所有知识标签
体系的构成一定有底层分类作为支撑的,所以想要把零散的标签,编织成系统就需要对他们进行分类,那么从作用的维度,你会把 “所有的知识” 标签分成哪几类?
可能每个人都有自己的标准~
我本人按照和参考了 “儒家的最高理想” 把一个人的一生所有的知识分成了四类:
③ 区别符号
你可能看到索引体中每个对象的前面都有个符号,有的符号是『 # 』有的符号是『 - 』,这是什么意思呢?
这两个符号是区别符号,前面有『 # 』的,说明它是标签。
而前面有『 - 』的说明它不是标签,这些东西的存在仅仅是为了连接标签,把标签串联成系统的连接符号,帮助我们看的更清晰,更有结构和层次感,它们是不参与索引的,当然『 - 』符号你可加可不加,但是『 # 』这个符号,我建议一定要加上,原因会在下面说。
④ 通过『索引体』快速提取内容
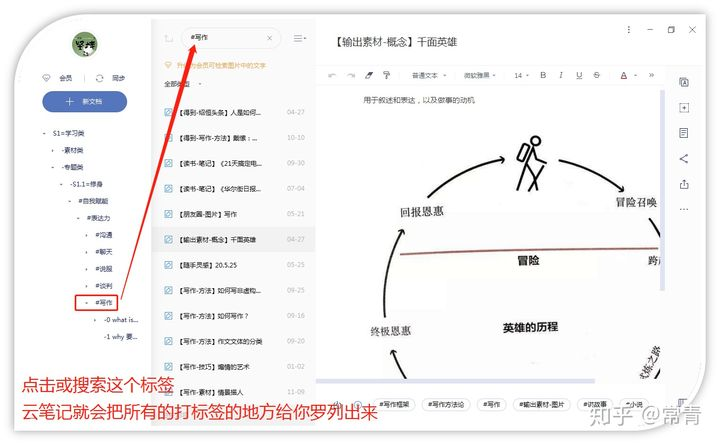
当一切都搭建完毕以后,剩下的就是我们提取东西的时候了,你可以通过单击标签提取,但是我最常用的就是搜索提取,想要啥,直接搜索,如探囊取物一样酸爽。
比如:在我笔记中,我搜索『写作』这个标签,你看~,云笔记会把我打这个标签的所有内容都给我找了出来。
无论是我个人的随手感想、我读书的笔记,或者我收集到的任何东西,只要它是在这个标签之下,瞬间提取~~
⑤ 如何让提取效率更高?
我们在实际的提取笔记的场景中,经常会遇到一个问题~
比如一本书的读书笔记,就在这一篇笔记中,它就可能涵盖无数个知识点,即使我用标签定位到了这篇笔记,想要找到笔记中的我想要的东西,也要翻看好久,那么有没有瞬间就能找到我想要的信息的方法呢?
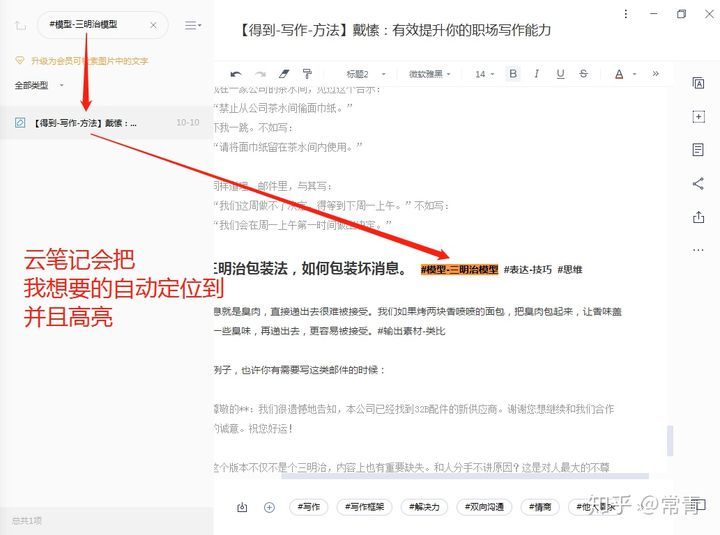
有的,解决方案就是在笔记文件内处处打标签,如此可以瞬间找到我们想要的内容。
比如下图,我就在这个笔记的某一处的知识点,打上了三个标签,当我需要找这三个标签任意一个的时候,云笔记会迅速帮我找到它所在的位置,并且打上高亮,这样整篇文章都变成了我标签系统中的一个个知识点,它不再属于原作者,而是属于我体系中的一部分。
这就回答了上面所说的为什么要在标签上加一个#,原因就在这,如果你不加这个识别符号,搜索到的东西就会乱七八糟,异常痛苦啊,这是坑,我已经替你们踩过了~
好了,到了这里,整篇文章也到了结尾了,这个剩下的你只需要在不断的学习过程中去完善和填充这个骨架,最终它就会形成一张庞大的知识结构网,到时候你就神功大成,就可以任意纵横了。

若有收获,就点个赞吧
0 人点赞
