项目背景
当前创蓝云智信息科技有限公司作为短信服务商在日常的提供客户短信服务同时,积累了一些用户数据,大数据部门通过对这一些数据进行分析挖掘,通过用户的行为信息,统计信息给用户打上相应的标签,为了减少标签抽样和建模重复步骤,节约时间成本,将一些重叠步骤进行规划整合,标准化相关流程,遂开启用户标签画像自动化建模项目。
项目总体框架
项目代码目录结构
Sms_Auto_ml├── code_tmp # 存储每次训练生成的抽样正负样本和样本拼接维度的hql文件│ ├── 202103.hql # 某月份维度特征与正负样本表格join的hql│ ├── 20220217142011.hql # 抽样抽取正负样本的hql├── config_data # 存放模型训练需要的相关文件│ ├── sampling2.hql # 维度特征与正负样本表格join的hql文件│ ├── sampling.hql # 抽取正负样本的hql│ ├── sign_06_6367_2400.npy # 签名用户-关键词6月份的svd降维矩阵数据│ ├── sign_07_6367_2400.npy # 签名用户-关键词7月份的svd降维矩阵数据│ ├── sign_08_6367_2400.npy # 签名用户-关键词8月份的svd降维矩阵数据│ ├── sign_word.json # 签名关键词的json文件│ ├── sms_06_3418_2900.npy # 短信用户-关键词6月份的svd降维矩阵数据│ ├── sms_07_3418_2900.npy # 短信用户-关键词7月份的svd降维矩阵数据│ ├── sms_08_3418_2900.npy # 短信用户-关键词8月份的svd降维矩阵数据│ └── sms_word.json # 短信关键词的json文件├── data_source # 存储标签模型训练文件│ ├── ACGER # “动漫爱好者”标签文件│ │ └── 20220322173607.csv # 动漫爱好者模型训练样本csv文件│ ├── babymom # “母婴用户”标签文件│ ├── driver # “司机”标签文件│ ├── examinee # “考试者(追梦少年)”标签文件│ ├── Part-time_Workers # ”兼职倾向者“标签文件│ ├── pet # ”宠物爱好者“标签文件│ ├── serpico_test_20220302 # ”短链点击倾向“标签文件│ ├── short_term_insurance # ”短险点击“标签文件│ └── working_people # ”职场人“标签文件├── GetModelCoef.py # 获取模型系数,并将模型系数上传到hdfs的py文件├── main.py # 主函数py文件├── ModelLearingCurve.py # 获取学习率曲线的py文件├── MoldelValidationCurve.py # 获取验证曲线的py文件├── project # 用于存储不同标签相关结果文件│ ├── ACGER # 存储”漫画爱好者“模型相关文件│ │ ├── data_model3_x.txt # 模型训练的X的txt文件│ │ ├── data_model3_y.txt # 模型训练的y的txt文件│ │ ├── image # 存储模型结果的相关图片│ │ │ ├── ks_all.jpg # 整体模型ks图片│ │ │ ├── ks_sign.jpg # 签名模型的ks图片│ │ │ ├── ks_sms.jpg # 短信模型训练的ks图片│ │ │ ├── roc_all.jpg # 整体模型ROC曲线的图片│ │ │ ├── roc_sign.jpg # 签名模型的ROC曲线的图片│ │ │ └── roc_sms.jpg # 短信模型的ROC曲线的图片│ │ ├── metric_all.txt # 整体模型的模型效果报告.txt文件│ │ ├── metric_sign.txt # 签名模型的模型效果报告.txt文件│ │ ├── metric_sms.txt # 短信模型的模型效果报告.txt文件│ │ ├── model_all.pkl # 整体模型的模型pkl文件│ │ ├── model_sign.pkl # 签名数据模型的pkl文件│ │ ├── model_sms.pkl # 短信数据模型的pkl文件│ │ ├── ss_mean.txt # 训练集特征均值txt文件│ │ └── ss_std.txt # 训练集特征方差txt文件│ ├── babymom # 存储”母婴用品者“模型结果的相关文件│ ├── driver # 存储”司机“模型结果的相关文件│ ├── examinee # 存储”考试者/追梦青年“模型结果的相关文件│ ├── Part-time_Workers # 存储”倾向于兼职者“模型结果的相关文件│ ├── pet # 存储”宠物爱好者“模型结果的相关文件│ ├── serpico_test_20220302 # 存储”短链点击者“模型结果的相关文件│ ├── short_term_insurance # 存储”短险点击者“模型结果的相关文件├── __pycache__ # 存储系统配置相关文件│ ├── main.cpython-38.pyc│ ├── main.cpython-39.pyc│ ├── sampling1.cpython-38.pyc│ ├── sampling1.cpython-39.pyc│ ├── sampling.cpython-39.pyc│ ├── train_mode.cpython-38.pyc│ ├── train_mode.cpython-39.pyc│ ├── utils.cpython-38.pyc│ └── utils.cpython-39.pyc├── result # 存储最终模型数据系数输出结果相关文件│ ├── test01 # 存储标签为”test01“的相关模型系数的文件│ │ |── mean_std.txt # 存储均值-方差整合的模型系数文件│ │ ├── model_all_coef.txt # 存储整体模型的系数文件│ │ ├── model_sign_coef.txt # 存储签名模型的系数文件│ │ └── model_sms_coef.txt # 存储短信签名的系数文件├── sampling1.py # 获取模型训练样本的py文件├── train_mode.py # 模型训练的py文件└── utils.py # 一些公共通用函数的py文件
主要模块

主函数
自动化建模的主体部分,输入本次需要建模的标签列表,就能实现对该列表中的标签进行自动化的抽样和建模。
调用方式:
先进入bigdata-automl的训练服务器,进入已经配置好训练环境的conda环境下
(base) [user@bigdata-automl ~]$ conda activate lr
(lr) [user@bigdata-automl Sms_Auto_ml]$python main.py babymom pet driver examinee
主函数主要进行两部分工作
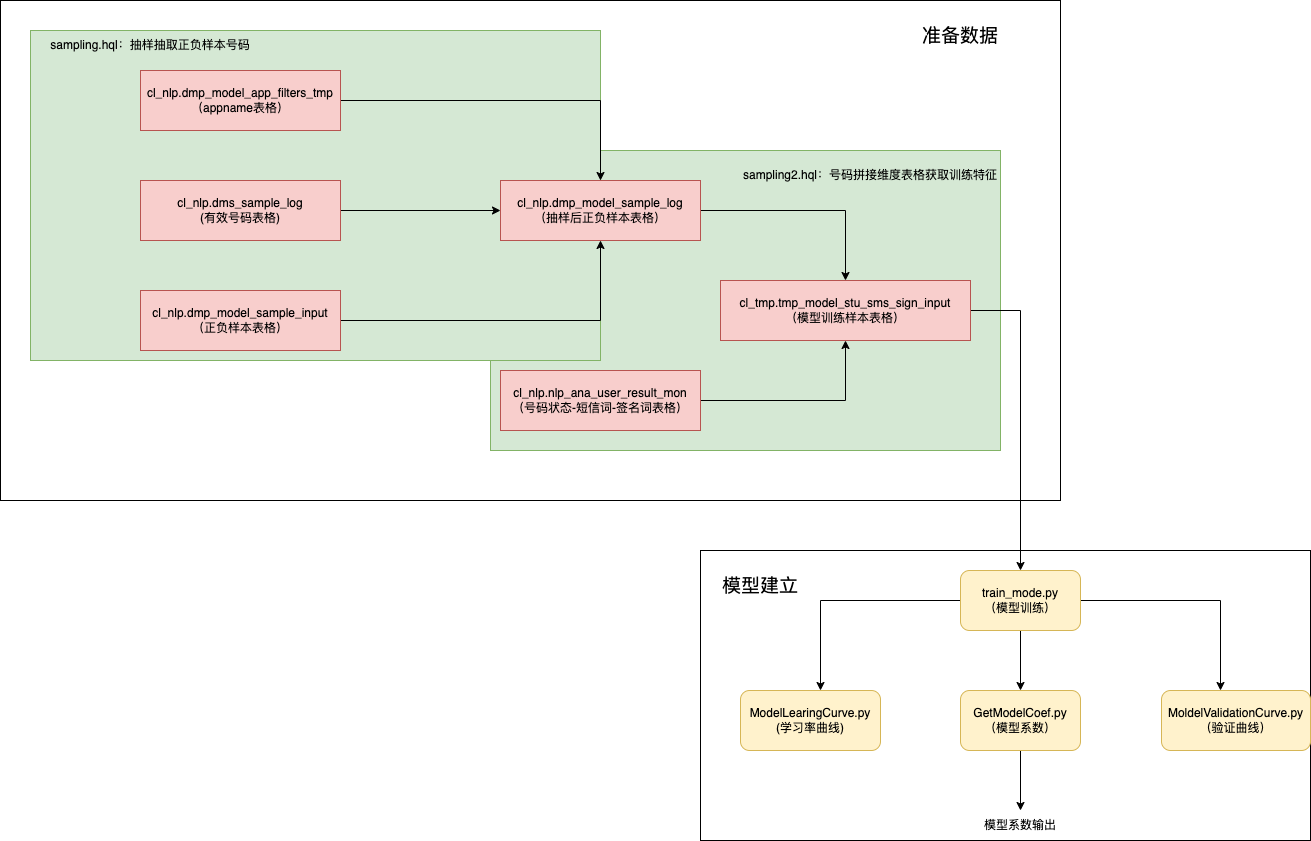
(1)一个是抽取样本,获取模型训练的样本集,python连接集群上的hive数据库,先抽样获取标签正负样本的号码用户,再获取这些用户的维度特征信息,拼接成建模宽表,结果存储与Sms_Auto_ml/data_source/{app_name}/ {文件日期.csv} ,不同的标签会生成不同的文件夹,不同标签的训练样本的保存其自身对应的相应的文件夹下,以其生成的日期作为文件名进行保存,如:Sms_Auto_ml/data_source/babymom/20220322173607.csv
(2)对得到模型训练样本,进行数据预处理,将数据模型处理成模型接受的格式,进行三次建模,分别是(1)短信:用户-关键词空间向量建模,获取模型结果(不进行sigmod)(2)签名:用户-关键词空间向量,获取模型结果(不进行sigmod)(3)综合模型,以号码的状态特征,并结合短信建模结果,签名建模结果作为特征,进行模型的建立。相关结果存储在Sms_Auto_ml/project/{app_name}下
project│ ├── ACGER # 存储”漫画爱好者“模型相关文件│ │ ├── data_model3_x.txt # 模型训练的X的txt文件│ │ ├── data_model3_y.txt # 模型训练的y的txt文件│ │ ├── image # 存储模型结果的相关图片│ │ │ ├── ks_all.jpg # 整体模型ks图片│ │ │ ├── ks_sign.jpg # 签名模型的ks图片│ │ │ ├── ks_sms.jpg # 短信模型训练的ks图片│ │ │ ├── roc_all.jpg # 整体模型ROC曲线的图片│ │ │ ├── roc_sign.jpg # 签名模型的ROC曲线的图片│ │ │ └── roc_sms.jpg # 短信模型的ROC曲线的图片│ │ ├── metric_all.txt # 整体模型的模型效果报告.txt文件│ │ ├── metric_sign.txt # 签名模型的模型效果报告.txt文件│ │ ├── metric_sms.txt # 短信模型的模型效果报告.txt文件│ │ ├── model_all.pkl # 整体模型的模型pkl文件│ │ ├── model_sign.pkl # 签名数据模型的pkl文件│ │ ├── model_sms.pkl # 短信数据模型的pkl文件│ │ ├── ss_mean.txt # 训练集特征均值txt文件│ │ └── ss_std.txt # 训练集特征方差txt文件
其中以metric_开头的文件记录着关于模型效果评估的相关指标,如模型的roc值,ks的值,模型的混淆矩阵,模型的分类报告等,如下所示:
roc_auc:0.7497902664117639ks_value:0.37136664754002224confusion_matrix:[[13727 762][ 5345 3894]]classification_report: precision recall f1-score support0 0.72 0.95 0.82 144891 0.84 0.42 0.56 9239accuracy 0.74 23728macro avg 0.78 0.68 0.69 23728weighted avg 0.77 0.74 0.72 23728
以.pkl文件结尾都是存储的模型文件,image文件夹下存储评价模型效果的ROC,KS曲线图片。
由于main.py主函数,集成了抽样和建模的两个过程。由于抽样的过程花费较长的时间,如果样本已经训练样本已经抽取完成,只想对单个标签模型进行调参建模,查看不同参数下的模型结果,可以只调用train_mode.py文件,先对utils.py文件中函数params里面的内容进行修改,传入想传入的模型参数:
def get_model(X_train, y_train, model=LogisticRegression,params={'C':[100,500,800],'max_iter':[500]}):'''模型训练,通过网格搜索获取最优模型参数@df_Y:模型训练集特征X@df_Y:模型训练集label@model:要使用的分类模型@params:网格搜索使用的参数字典'''print("------------------------------------开始模型训练-------------------------------------------------")print(model,id(model))ml = model()# print(ml,id(model))# 利用网格搜索进行模型调参clf = GridSearchCV(ml, param_grid=params)clf.fit(X_train, y_train)print(type(clf))# 根据以上绘图结果选择一个合理参数值classifier = model(**clf.best_params_)# 训练模型classifier.fit(X_train, y_train)print("--------------------------------------模型训练完成-----------------------------------------------")return classifier
修改代码里面下面示例部分内容,此时是对”pet”的标签进行建模,改成其他的标签名,则对其他的标签进行建模:
if __name__ == '__main__':from main import ready_configconfig_data = ready_config()p_status = ml_main("pet",*config_data)print(p_status)
调用方式:
(lr) [user@bigdata-automl Sms_Auto_ml]$python train_mode.py
结果输出
该部分的功能主要是与王兵那边同步生产环境获取标签评分所需要的模型系数格式,并将相应模型系数上传到指定的hdfs的路径上,以供王兵那边调用。该过程是手动一个标签一个标签执行的,需要修改GetModelCoef.py下面部分代码的标签的名称,该示例中,标签名称为:”test_p1”
if __name__ == "__main__":result_01 = get_model_coef("test_p1")print(result_01)if result_01 == 1:print("开始连接hdfs!")result_02 = file_upload("test_p1")print(result_01)
调用方式:
(lr) [user@bigdata-automl Sms_Auto_ml]$python GetModelCoef.py
此部分的生成的模型系数会存储于两个部分:(1)hdfs路径:hdfs_path = ‘/user/cltianman/model2/{app_name}/‘ (2) 本地路径:Sms_Auto_ml/result/{app_name}/ 下
辅助查看效果
该部分功能主要辅助查看,模型的主要参数对模型效果的效果的影响,以及样本量大小对模型效果的影响,作为模型效果的辅助查看。主要有两个部分分别是学习率曲线:ModelLearingCurve.py,验证曲线:MoldelValidationCurve.py
(1)ModelLearingCurve.py,修改下面部分传入的参数信息,标签名、estimator:所用模型,cv:交叉验证系数,train_sizes:训练样本站总体样本比例,获得不同训练样本下的学习率曲线。
if __name__ == "__main__":p_status = lc_main("test01",estimator=LogisticRegression,cv=5,train_sizes=np.linspace(0.1, 1.0, 5))
调用方式:
(lr) [user@bigdata-automl Sms_Auto_ml]$python ModelLearingCurve.py
(2)MoldelValidationCurve.py ,标签名,“C”:验证参数,[100,500]:验证参数的取值范围,estimator:所用模型,cv:交叉验证的折数,scoring:结果计算方式,获得验证参数在不同取值下模型效果的验证曲线。
if __name__ == "__main__":p_status = vc_main("test01","C", [100,500],estimator=LogisticRegression, cv=5, scoring="accuracy")
调用方式:
(lr) [user@bigdata-automl Sms_Auto_ml]$python MoldelValidationCurve.py .py

若有收获,就点个赞吧
0 人点赞
