Spark Sql的概念
- spark中用于处理结构化数据的一个模块
- 它是spark中用于处理结构化数据的一个模块(功能和hive类似,最早是shark,为了解决hive速度慢的问题 )
- Spark SQL和Spark Core的关系(RDD)和hive和Mapreduce关心类似
- Spark SQL历史
- Hive是目前大数据领域,事实上的数据仓库标准
- shark:shark底层使用spark的基于内存的计算模型,从而让性能比Hive提升了数倍到上百倍。
- 底层很多东西还是依赖于Hive,修改了内存管理,物理计划,执行三个模块
- 2014年6月的时候,Spark宣布不在开发Shark,全面转向Spark SQL的开发
Spark SQL优势
- write less code
RDD
SC.textFile('路径').flatMap(lambda x:x.split("")).map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b).collect()
Spark SQL
SSC.sql('select word,count(1) as cnt from a group by word')df.groupBy('word').count().show()
- spark SQL操作数的两种方式
- 通过sql语句
- 自带的DataFrame的API
- 速度快(对比直接写RDD代码)
- SparkSQL API转换成RDD的时候会执行优化
- 优化引擎转化的RDD代码比自己写的效率更高
- performance

python操作RDD,转换为可以执行代码,运行在java虚拟机上,涉及两个不同语言引擎之间的切换,进程之间通信很耗费性能。
DataFrame
- 是RDD为基础的分布式数据集,类似于传统的关系型数据库中的二维表,dataframe记录对应的列的名称和类型
dataframe引入schema和off-heap(使用操作系统层面的内存)
- 1、解决RDD的特点(优点)
- 序列化和反序列化的开销大
- 频繁的创建和销毁对象造成大量的GC
- 2、丢失了RDD的特点(缺点)
- RDD编译时进行类型的检查
- RDD具有面向对象编程的特性
用scala编写的RDD比Spark SQL编写的转换RDD慢,涉及到执行计划
- CatalyOptimizer:Catalyst优化器
- ProjectTungsten:钨丝计划,为了提高RDD的效率而制定的计划
- Code gen:代码生成器
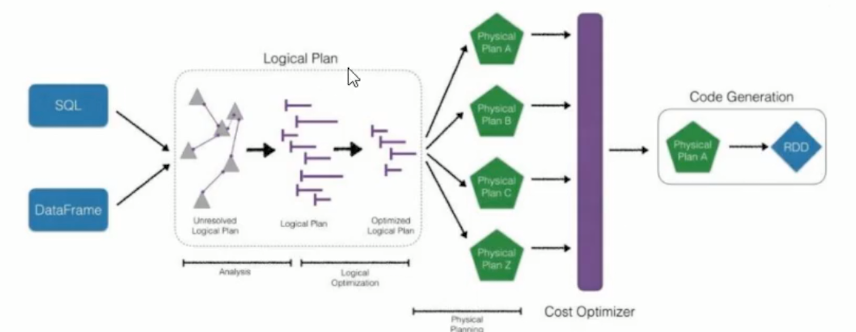
直接编写RDD也可以自实现代码优化,但是远不及SparkSQL前面的优化操作后转化的RDD的效率高,快1倍左右
首先执行逻辑执行计划,然后转化为物理执行计划(选择成本最小的),通过Code Generation最终生成为RDD
- Language-independent API
- 用任何语言编写生成的RDD都是一样的,而使用spark-core编写的RDD,不同语言生成不同的RDD
- Schema
- 结构化数据,可以直接看出数据的详情
- 在RDD中无法看出,解释性不强,无法告诉引擎信息,没有详细优化
为什么要学习sparksql
- 代码少
- 速度快
- 可以之间连接数据库(提供了标准的数据库连接jdbc/odbc)
- 兼容hive
DataFrame
在Spark语义中,DataFrame是一个分布式的行集合,可以想像为一个关系型数据库的表,或者一个带有列名的Excel表格,它和RDD一样,有这样的一些特点:
- immuatable:一旦RDD,DataFrame被创建,就不能更改,只能通过transformation生成新的RDD,DataFrame(不可变)
- Lazy Evaluations:只有action才会触发Transformation的执行(延迟执行)
- Distributed:DataFrame和RDD一样都是分布式的
- dataframe和dataset统一,dataframe只是dataset[ROW]的类型别名,由于python是弱类型语言,只能使用DataFrame
DataFrame vs RDD
- RDD:分布式的对象的集合,Spark并不知道对象的详细模式信息
- DataFrame:分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某一些形式的执行优化
DataFrame和普通的RDD的逻辑框架区别如下所示:
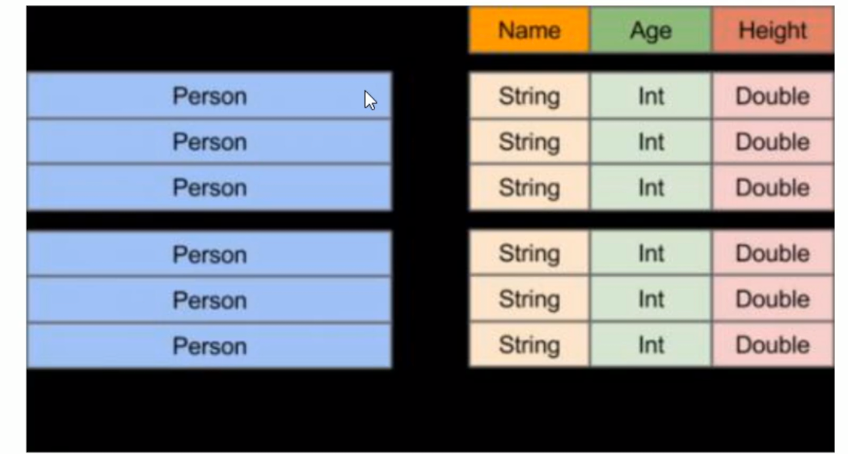
左侧的RDD Spark框架本身下不了解Rerson类的内部结构
- 右侧的DataFrame提供了详细的结构信息(schema—每列的名称,类型)
- DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id,name from xx_table where …)
- DataFrame还引入了off-head,这意味着JVM堆以外的内存,这些内存直接受操作系统的管理(而不是jvm)
- RDD是分布式的java对象的集合,DataFrame是分布式的Row对象的集合,DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升了执行效率,减少数据 读取以及执行计划的优化
- DataFrame的抽象后,我们的处理数据更加简单了,甚至可以用SQL来处理数据了
- 通过DataFrame API或SQL处理数据,会自动经历Spark优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快
- DataFrame相当于是一个带着schema的RDD
Pandas DataFrame vs Spark DataFrame
- Cluster Parallel:集群并行执行
- Lazy Evaluations:只有action才会触发Transfromation的执行
- lmmutable:不可更改
- Pandas rich API:比spark SQL api丰富
2.2 创建DataFrame
1、创建dataFrame的步骤
调用方法例如:spark.read.xxx方法
2、其他方式创建dataframe
- createDataFrame:pandas dataframe,list,RDD
- 数据源:RDD,csv,json,parquet,orc,jdbc
基于RDD创建
- 创建DataFrame先需要一个spark session

从RDD创建DataFrame
dataframe_people = spark.createDataFrame(Row对象的RDD)
从csv文件中读取数据
# 加载csv类型的数据并转换为DataFramedf = spark.read.format("csv").option("header","true").load("iris.csv")# 显示数据结构df.printSchema()# 显示前10条数据df.show(10)# 统计总量df.count()# 列名df.columns
增加一列
提取部分列
df.select('SepalLength','SepalWidth').show()
基本统计功能
df.select('cls').distinct().count()
分组统计
# 分组统计 groupby(colname).agg({'col':'fun','col2':'fun2'})df.groupby('cls').agg({'SepalWidth':'mean','SepalLength':'max'}).show()# avg(),count(),countDistinct(),first(),kurtosis(),max(),mean(),min(),skewness(),stddev(),stddev_pop()# stddev_samp(),sum(),sumDistint(),var_pop(),var_samp(),variance()
自定义的汇总的方法
# 自定义的汇总方法import pyspark.sql.functions as fn# 调用函数并起一个别名df.agg(fn.count('setosa').alias("yuanweihua"),fn.countDistinct('versicolor').alias('distinct_v')).show()
拆分数据集
# 设置数据比例将数据拆分成为两个部分trainDF,testDF = df.randomSplit([0.6,0.4])
采样数据
# withReplacement:是否有放回的采样# fraction :采样比例# seed:随机种子sdf = df.sample(False,0.2,100)
查看两个数据集在类别上的差异
创建交叉表
# 查看数据的分布情况df.crosstab('cls','SepalLength').show()

若有收获,就点个赞吧
0 人点赞
