1、了解spark的概念
1、什么是spark
- 基于内存的计算引擎,他的计算速度非常的快,但是仅仅只涉及到数据的计算,并没有涉及到数据的存储
- 只负责算,不负责存
- spark在离线计算上功能上类似于mapreduce的作用
2、为什么要学习spark
MapReduce框架局限性(的缺点)
- 1、Map结果写磁盘,Reduce写HDFS,多个MR之间之间通过HDFS交换数据
- 2、任务调度和启动开销大
- 无法充分利用内存
- 不适合迭代计算(如机器学习,图计算等等),交互式处理(数据挖掘)
- 不适合流式处理(点击日志分析)
- MapReduce编程不够灵活,仅支持Map和Reduce两种操作
- 1、运行速度慢(没有充分利用内存)2、接口比较简单,仅支持Map Reduce 3、功能比较单一只能做离线计算
Hadoop生态圈
- 批处理:MapReduce、Hive、Pig
- 流式计算:Storm
- 交互式计算:lmpala、presto
需要一种灵活的框架可以同时进行批处理,流式计算,交互式计算
2、知道spark的特点(与Hadoop对比)
- 运行速度快(比mapreduce在内存中快100倍,在磁盘中快10倍)
- spark中的job中间结果可以不落地,可以存放在内存中
- mapreduce中的map和reduce任务都是可以进程的方式运行着,而spark中的job是以线程方式在进行中
- 易用性(可以通过java/scala/python/R开发spark应用程序)使用各种语言进行编程操作
- 通用性(可以使用spark sql/spark streaming/milb/Graphx)
- 兼容性(spark程序可以运行在standalone/yarn/mesos)
- 自身生态比较完整
- api比较丰富
3、独立实现spark local模式的启动
spark-core概述
1、知道RDD的概念
2、独立实现RDD的创建
什么是RDD
- 弹性的分布式数据集
- spark当中对数据的抽象
- 所有的spark中对数据的操作最终都会转换成RDD的操作
- spark sql
- spark streaming
- spark ml,spark mllib
- RDD分布式的可容错可以进行并行计算
RDD(Resilient Distrbuted Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可并行计算的集合。
概念:
rdd的存储可以对比HDFS
- hdfs数据拆分成多个block rdd拆分成多个partition
- 读取的时候spark加载hdfs数据1个block 对应spark rdd的一个partition
- 写数据的时候spark的1个partition可能对应多个block
- RDD是不可变的(容错角度考虑)
- 父RDD生成一个子RDD,父RDD的状态不会发生变化
- 从容错的角度去做这样的一个设计
第一步 创建sparkContext
- SparkContext,spark程序的入口,SparkContext代表了和spark集群的连接,在spark集群中通过SparkContext来创建RDD。
SparkConf 创建SparkContext的时候需要一个SparkConf,用来传递Saprk的基本信息。
conf = SparkConf().setAppName(appName).setMaster(master)sc = SparkContext(conf=conf)
Parallelized Collections方式创建RDD
调用SparkContext的parallelize方法并且传入已有的可迭代对象或者集合
data = [1,2,3,4,5]disData = sc.parallelize(data)
Spark将为集群的每一个分区(partition)运行一个任务(task),通常,可以根据CPU核心的数量指定分区的数量(每个CPU有2-4个分区)如果未指定分区数量,Spark会自动的设置分区数。
通过外部的数据创建RDD(hadoop支持什么就支持读取什么样的文件)
- PySpark可以从Hadoop支持任何的存储源建设RDD,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3等
- 支持整个目录,文件,通配符
- 支持压缩文件
小结:rdd1 = sc.textFile('file://home/hadoop/tmp/word.txt')rdd1.collect()
创建RDD之前要有spark context
- 通过内存中的数据创建RDD
- 创建RDD的时候可以指定partition的数量(RDD会分成几份)
一个 partition会对应一个task(会对应一个线程),根据CPU的内核数据来指定partition(1核对应2到4个partition)
从文件创建RDD可以是 HDFS支持的任何一种存储介质
- 可以从hdfs数据库(mysql)本地文件系统hbase这些地方加载数据创建rdd
- rdd = sc.textFile(‘file:///root/tmp/text.txt’)
RDD常用操作
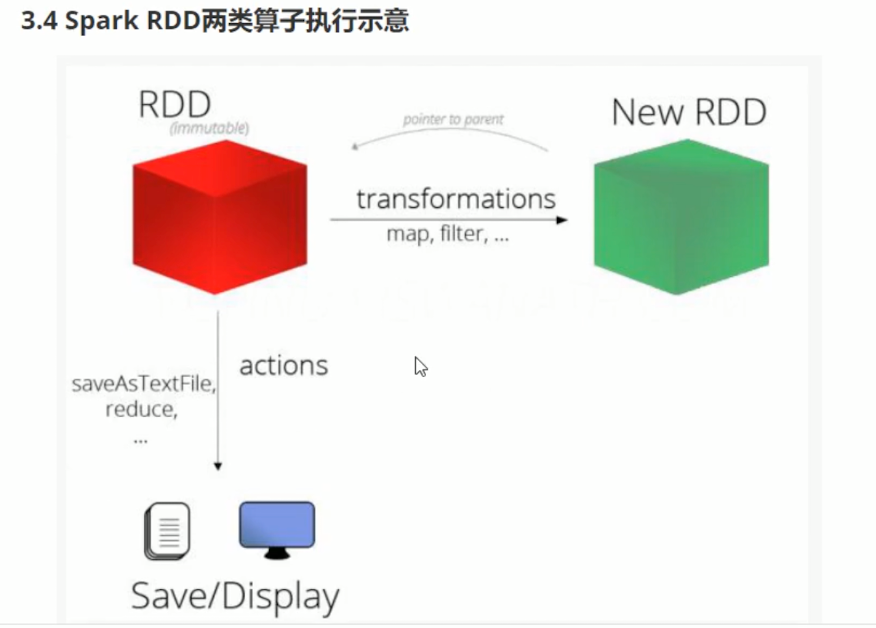
RDD支持两种类型的操作
- 从一个已经存在的数据集中创建一个新的数据集
- rdd—->transfromation—->rdd b
- 比如,map就是一个transformation操作,把数据集中的每一个元素给一个函数并返回一个新的RDD,代表transformation操作的结果
- action
- 获取对数据进行运算操作后的结果
- 比如,reduce就是一个action操作,使用某一个函数聚合RDD所有元素的的操作,并返回最终的计算结果。
- 从一个已经存在的数据集中创建一个新的数据集
- 所有的transformation操作都是懒惰的(lazy)
- 不会立即计算结果
- 只记下应用于数据集的tansformation
- 这种设计使spark的效率更高
- 例如map,reduce操作,map创建的数据集将用于reduce,map阶段的结果不会返回,仅会返回reduce的结果。
- persist操作
- persist操作用于将数据缓存在内存中也可以缓存到磁盘上,也可以复制到磁盘的其他节点上。
小结:
- transformation
- 所有的transformation都是延迟执行的,只要不调用action不会执行,只是记录过程
- transformation这一类算子返回值还是rdd
- rdd.transformation还会得到新的rdd
- action
- 回之前的rdd的transformation
- 获取最终的结果
- persist
- 数据存储,可以存到内存,可以是磁盘
RDD的算子练习-transformation算子
map:map(func)
将func函数作用到数据集的每一个元素上,生成一个新的RDD返回
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)rdd2 = rdd1.map(lambda x:x+1)rdd2.collect()
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)def add(x)return x+1rdd2 = rdd1(add)rdd2.collect()
filter
filter(func)选出所有func返回值为true的元素,生成一个新的rdd返回
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)rdd2 = rdd1.map(lambda x:x*2)rdd3 = rdd2.filter(lambda x:x>4)rdd3.collect()
flatmap(扁平化操作)
flatmap会先将对象执行一个map的操作,再将所有的对象合并成一个对象
rdd1 = sc.parallelize(["a,b,c","d,e,f","h,i,j"])rdd2 = rdd1.flat.flatMap(lambda x:x.split(", "))rdd2.collect()
union
对两个RDD求并集
rdd1 = sc.parallelize([("a",1),("b",2)])rdd2 = sc.parallelize([("c",1),("b",3)])rdd3 = rdd1.union(rdd2)rdd3.collect()[('a',1),('b',2),('c',1),('d',2)]
intersection
对两个RDD求交集
rdd1 = sc.parallelize([("a",1),("b",2)])rdd2 = sc.parallelize([("c",1),("d",3)])rdd3 = rdd1.union(rdd2)rdd4 = rdd3.intersection(rdd2)rdd4.collect()[('c',1),('b',3)]
groupByKey
以元祖中的第0个元素作为key,返回一个新的RDD
rdd1 = sc.parallelize([("a",1),("b",2)])rdd2 = sc.parallelize([("c",1),("b",3)])rdd3 = rdd1.union(rdd2)rdd4 = rdd3.groupByKey()rdd4.collect()
groupByKey之后的结果中value是一个iterable
result[2]result[2][1]list(result[2][1])
reduceByKey
将key相同的键值对,按照Function进行计算
rdd = sc.parallelize([("a",1),("b",1),("a",1)])rdd.reduceByKey(lambda x,y:x+y).collect()[('b',1),('a',2)]
sortByKey
按照key进行排序(按照key的ascll码进行排序)
sortByKey(ascending=True,numPartitions,keyfunc=<funcationRDD.<lambda>>)
tmp = [('a',1),('b',2),('1',3),('d',4),('2',5)]sc.parallelize(tmp).sortByKey().first()sc.parallelize(tmp).sortByKey(True,1).collect()tmp2 = [('Marry',1),('had',2),('little',4),('lamb',5)]tmp2.extend([('whose',6),('fleece',7),('white',9)])sc.parallelize(tmp2).sortByKey(True,3,keyfunc=lambda k:k.lower()).collect()
RDD Action算子
collect
- 返回一个list,list中包含RDD中的所有的元素
- 只有当数据量较小的时候使用collect 因为所有的结果全都会加载到内存中
reduce
- reduce将RDD中的元素两两传递给一个函数,同事产生一个新值,新产生的值与RDD中下一个元素再被传递输入到函数直到最后一个值为止。
rdd1 = sc.parallelize([1,2,3,4,5])rdd1.reduce(lambda x,y:x+y)
- reduce将RDD中的元素两两传递给一个函数,同事产生一个新值,新产生的值与RDD中下一个元素再被传递输入到函数直到最后一个值为止。
first
- 返回RDD的第一个元素
sc.parallelize([2,3,4]).first()
- 返回RDD的第一个元素
take
- 返回RDD的前N个元素
- take(num)
sc.parallelize([2,3,4,5,6]).take(2)sc.parallelize([2,3,4,5,6]).take(10)sc.parallelize(range(100),100).filter(lamnda x:x>90).take(3 )
count
- 返回当前RDD的元素的个数
sc.parallelize([2,3,4]).count()3
注:写的再多,不调action是不会计算的。所以有的代码会在transformations后面加collect()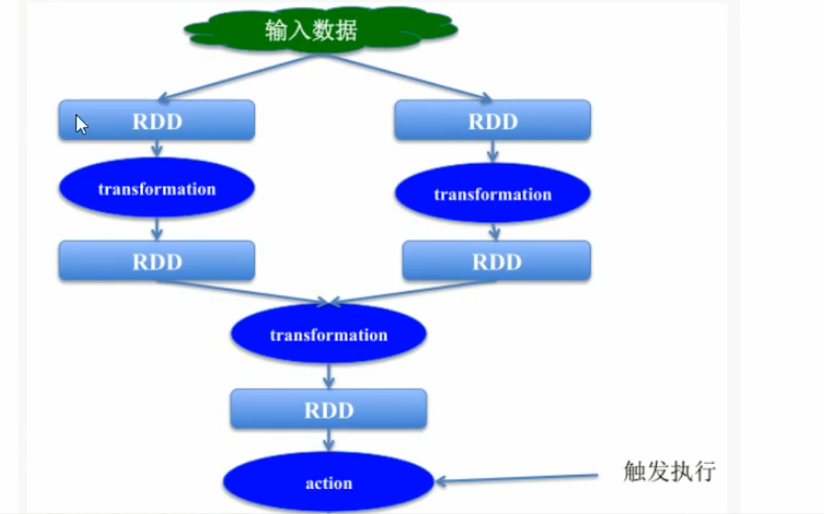
spark比mapreduce的一些常用的操作封装的更好一些。
注:pycharm连接centos远程提交代码
- 返回当前RDD的元素的个数
ip地址统计案例
广播变量
- 多个task会用到同一份的数据,默认每一个task都会复制一份
- 用到的数据如果知识查询可以通过广播变量保存,避免数据的反复的复制
- SparkContext可以创建广播变量
广播变量 = sc.broadcast(值)广播变量.value
mapPartitions
- 是一个transformation操作
- 类似于map,map一条做一个函数(一条一条的传入函数),mapPartitions是一个分区的数据做一个函数(一部分一部分传入函数)
- 应用场景 数据 处理的时候需要连接其他的资源,如果一条一条的处理,会处理一条连接一次,一份一份的处理可以很多条数据连接一次其他的资源,可以用来提高效率。
- 二分法查找
- ip_transform把223.243.0.0转化成10进制的数字 ```python from pyspark import SparkContext
def ip_transfrom(ip): ips = ip.split(“.”) #[223,243,0,0] ip_num = 0 for i in ips: ip_num = int(i)|ip_num <<8 return ip_num
二分法查找
def binary_search(ip_num,broadcast_value): start = 0 end = len(broacast_value)-1 while(start<=end): mid = int((start+end)/2) if ip_num >= int(broadcast_value[mid][0] and ip_num<=int(broacast_value[mid][1])): return mid if ip_num < int(broacast_value[mid][1]): end = mid if ip_num < int(broacast_value[mid][1]): start = mid
if name==’main‘:
# 创建spark contextsc = SparkContext('local[2]','iptopN')city_id_rdd = sc.textFile("file:///root/tmp/ip.txt")\.map(lambda x:x.split('|')).map(lambda x:(x[2],x[3],x[13],x[14]))temp = city_id_rdd.collect()#创建广播变量city_broadcast = sc.broadcast(temp)dest_data = sc.textFile('file:///root/tmp/20090121000132.394251.http.format')\.map(lambda x:x.split('|')[1])def get_pos(x):# 从广播变量中获取ip地址cbv = city_broadcast.valuedef get_result(ip):ip_num = ip_transfrom(ip)index = binary_search(ip_num,cbv)return ((cbv[index][2],cbv[index][3]),1)result = map(tuple,[get_result(ip) for ip in x])return resultdest_rdd = dest_data.mapPartitions(lambda x:get_pos(x))#((经度,维度),1)result_rdd = dest_rdd.reduceByKey(lambda a,b:a+b).sortBy(lambda x:x[1],ascending=False)print(result_rdd.collect())
启动Saprk集群- 进入到$SPARK_HOME/sbin目录- 启动Master```powershell./start-master.sh -h 192.168.199.188
启动Slave
./start-slave.sh spark://192.168.199.188:7077
jps查看进程
27073 Master27151 Worker
关闭防火墙
systemctl stop firewalld
spark集群相关概念(spark自己搞了一个集群)
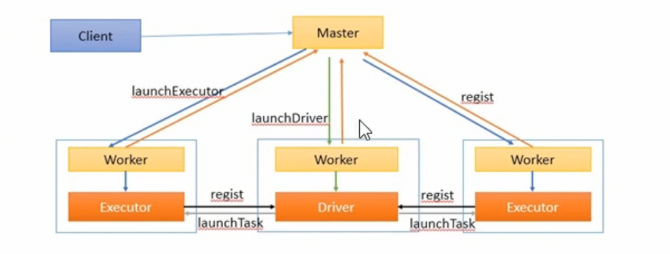

DAGScheduler负责将作业分成多少个阶段,每一个阶段负责多少个task,TaskScheduler负责将作业分发到不同的Executor上。
spark作业的相关的概念
- Stage:一个Saprk作业一般包含一到多个Stage
- Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能
- DAGScheduler:实现将Saprk作业分解成一个到多个Stage,每一个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中
- TaskScheuler:实现Task分配到Executor上执行。
总结:
Spark standalone的模式
- Master
- 主节点
- 负责Worker状态管理
- 响应client提交来的Application
- Worker
- 管理自身资源
- 运行Application对应的task
- 启动图driver执行application
- Executor
- task最终执行的容器
- Application
- spark作业
Driver
- 作业提交给spark的时候先由Worker启动一个Driver来分析Application
- DAGScheduler
- task的划分交个TaskScheduler
- 作业可以划分为多个stage
- 每一个stage根据partition的数量决定由多少个task
- TaskScheduler
- 将task调度到对应Executor执行
- client
spark core总结
spark core是spark生态中最核心的部分
- spark生态
- spark core (mapreduce)
- spark sql (类似于hive,hive将sql翻译成MapReduce,park sql 将sql翻译成RDD)
- spark streaming (对应strom与flink)
- spark ML 基于dataframe sparkmlib rdd
spark生态回避hadoop更加丰富一些,这些最终都会转成rdd来做
- spark
- 基于内存的分布式计算框架
- MapReduce和spark优劣
- spark基于内存算的更快
- spark api更加的丰富比mapreduce代码少
- spark生态完整
- 离线计算
- 实时计算/流式计算 spark streaming 准实时
- 交互式计算,pandas处理DataFrame
- 机器学习spark ML
- RDD
- 弹性分布式数据集
- 不可变 rdd->rdd2 rdd和rdd2的状态会分别保存
- 弹性 存储弹性,分布式弹性,容错可以分多个partition存,每个partition有多个副本
- 分布式
- 并行计算(一个partition和多个partition的计算结果可能是不相同的)
- RDD创建
- spark context
- 在内存中list iterable
- 从文件中加载
- 在创建rdd的时候可以指定partition的数量,一个partition对应一个task,task是一起跑的
- spark context
- 三类算子
- tansformation
- 返回rdd
- 延迟执行 只要没调用action类算子,就不会执行,只是记下了执行的计划
- action
- 获取结果
- tansformation
- spark local模式standalone
- 广播变量

若有收获,就点个赞吧
0 人点赞
