消息队列具有低耦合、可靠投递、广播、流量控制、最终一致性等功能,是异步RPC的主要实现。
Kafka 是一个分布式、高效能消息队列。官方基准测试 10ms,10万 QPS。
RocketMQ 实现类似 Kafka,但适用于业务,所以放在一起记录。
1 使用场景
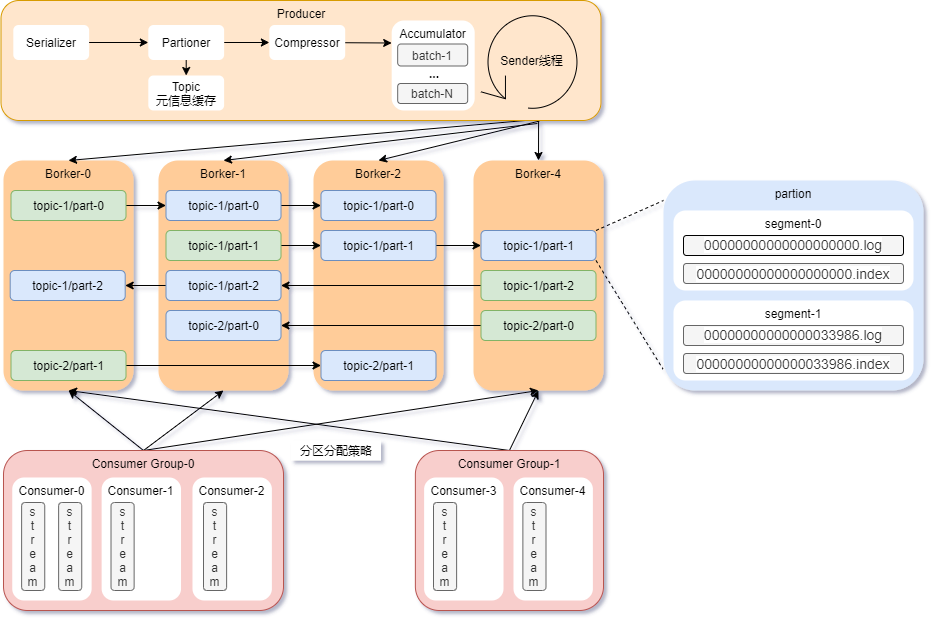
producer 一个进程,负责序列化、计算分区、压缩、收集、发送消息consumer 一个进程,负责拉取消息,线程 stream 可以做更细力度的拉取borker 一个进程,一台机器可以有多个 borker 进程,相当于一台机器可以有多个 Kafka 节点topic 逻辑概念,Kafka 希望用户只关心 topic,屏蔽底层细节partition 一个目录,存储了部分 topic 的数据,提高吞吐量replica 多副本机制将 partition 区分为 leader replica、follower replicasegment 一组文件,包含 log文件(存储数据)、index文件(稀疏索引),文件名是 offset(偏移量)consumer group 一组消费者,同一组的 consumer 不能消费同一个 partition。group 是 Kafka集群全局的,而非某个Topic的,若 consumer 不指定则属于默认的 group。
3 如何实现高可用
可用性,服务在一段时间内,正常运行的时间占比,所谓三个九就是 99.9%。
为了实现高可用,Kafka 分片了数据,并且对数据做冗余。
3.1 分区机制
数据堆积,是 MQ 实现流量控制的方式,这就要求 MQ 对数据持久化。持久化会遇到2个瓶颈:硬盘读写速度慢、硬盘容量有限。
Kafka 在创建 topic 的时候,将 topic 分片为多个 partion,分别存储在不同的机器,从而分散读写压力,方便横向扩展。图2.1的 topic-1 被切分为3个partion:topic-1/part0、topic-1/part1、topic-1/part2。
producer 发送消息时,使用 Partioner 计算分区:
- 指定了 partition,则直接写入
- 未指定 partition,但设置了 key,则根据 key 哈希出一个 partition
未指定 partition,又未设置 key,则轮询出一个 partition
3.2 多副本机制
Kafka 对 partition 做备份,避免 borker 宕机导致数据丢失。
leader replica 是主分区,负责处理 partition 所有读写请求。
follower replica 是备份分区,负责定期复制 leader 上的数据。
图2.1 的 topic-1 拥有3个 replica,绿色是 leader,蓝色是 follower。
注意事项:leader、follower 分散在不同的机器,否则容灾失效
-
3.3 主从同步
ISRIn-Sync Replicas,记录 partion 当前活跃副本。LEOLog End Offset,日志末端位移,记录 replica 下一条消息的位移值。如果 LEO=10,表示该副本保存了10条消息,offset 范围是[0, 9]。HWHigh Watermark,高水位线,表示消息被 ISR 确认 commit,并且写入log文件,所以在 HW 以下的消息都可以被消费。 维护在 ZooKeeper,/brokers/topics/[topic]/partitions/[partition]/state
- 如果 follower 落后太多,或超时未发起数据复制请求,则 leader 将其移出 ISR
- 如果 leader 宕机,使用 ZooKeeper 选出新 leader
4 如何实现高性能
Kafka 使用了一系列技术实现高性能:批量发送、压缩、顺序写、零拷贝、批量拉取。
producer 在发送消息前,会在主线程收集消息,压缩成一个 batch 后,等待 send线程发送。
这可以降低网络IO的次数、负载,同时使得 borker 可以顺序写,不用每次消息来了就寻道。4.1 顺序写
即便 topic 分片为 partition,数据依然很大,Kafka 进一步将 partition 分为 segment,可以发现 partition 目录下包含多个 segment。
borker 收到消息,直接把数据追加到 log文件,这里只需一次 lseek() 寻址,找到文件的末尾,接下来全都是 write() 写入操作。
然后维护稀疏索引,把 offset、物理偏移量追加到 index文件,同样是顺序写操作。4.2 零拷贝
borker 收到 producer 的消息,使用 FileChannel.write 写入硬盘,底层的系统调用 pwrite() 把数据写入 Page Cache 后直接返回,等待 OS 异步刷盘。
borker 收到 consumer 的拉取,使用 FileChannel.transferTo 读取硬盘,底层的系统调用 sendfile() 把数据从 Page Cache 拷贝到 socket buffer。
如果消息刚到 borker,那么它大概率还在 Page Cache,这时候零拷贝生效,消息经过 borker 全程在内存中完成,速度很快。
4.3 批量拉取
consumer 实现了 pull模式 ,有以下特性:
- consumer 可以根据自身负载,批量拉取并消费,提高吞吐量
- consumer 无法感知新消息到达 borker,实时性差
- 没有背压机制通知 producer 调整发送速率
针对 pull 模式的缺点,有以下解决方案:
- 动态等待时间。如果 1ms 没有消息来,则 2ms 后轮询,以此类推。直到有消息来,重新从 5ms 开始等待
长轮询。consumer 拉取失败后不回收连接,而是让 borker 使用该连接 push 新消息
5 如何保证可靠性
可靠性,指服务连续运行的时间,但这个定义很少用,所以可靠性常被用来描述别的指标,比如 MQ 的 QoS 分为:at-most-once、at-least-once、exactly-once。
5.1 at-most-once
消息可能丢失,但不会重复投递。这是 Kafka 的默认可靠性。
producer 默认 ack=1,leader 写入log文件,返回成功,在准备同步到 follower 时宕机,消息丢失。
consumer 默认 auto commit offset,如果消费过程中宕机,消息丢失。5.2 at-least-once
消息不会丢失,但可能会重复投递。
producer 配置 ack=-1,要求 ISR 全部确认 commit。
consumer 关闭 auto commit,如果消费成功,但 commit 失败,那么消息会被其它 consumer 重复消费。
在 at-least-once 级别下,要实现幂等消费,重复执行同一个请求,其产生的结果不会改变:版本号控制,update 前对比消息中的 version 和数据库中的 version
- 唯一键约束,例如 insert into update on duplicate key
- 全局唯一ID,消费前先根据这个ID 判断是否之前消费过(布隆过滤器)
5.3 exactly-once
消息不丢失、不重复,只会被分发一次。
需要先实现 at-least-once,落地成本太高,一般不予考虑。参考文献

若有收获,就点个赞吧
0 人点赞
