在面对流量激增,上游服务质量下降时,容错可以保护服务,避免产生级联错误,导致服务雪崩。容错包含两方面工作,第一是产生错误事件,比如限流(限制速率、限制并发)、熔断,第二是处理错误事件,比如降级、重试。
目前业界的容错库实现有 Hystirx,Sentinel 以及 OPPO 自研的 ESA ServiceKeeper。本文以 ServiceKeeper 为例,阐述单机场景下的容错。至于分布式场景容错,可以参考原理使用 Redis 实现。
@RateLimit 限制速率
有两类算法,窗口算法(固定、滑动),桶算法(桶、令牌桶)。
窗口算法实现简单,逻辑清晰,可以很直观的得到当前的 QPS 情况,但是会有时间窗口的临界突变问题。
桶算法实现复杂,解决了窗口临界突变问题,但各自存在一些问题。
固定窗口
ServiceKeeper 的方案,用一个原子计数器就能实现,代码参考文献2。有时间窗口临界问题,比如将 QPS 设置为 2,有可能出现 QPS 为 4 的情况。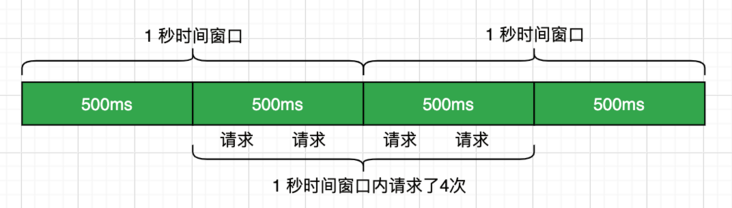
滑动窗口
只能缓解固定窗口的临界问题,比如:每 500ms 滑动一次窗口,可以发现窗口滑动的间隔越短,时间窗口的临界突变问题发生的概率也就越小,不过只要有时间窗口的存在,还是有存在时间窗口临界问题。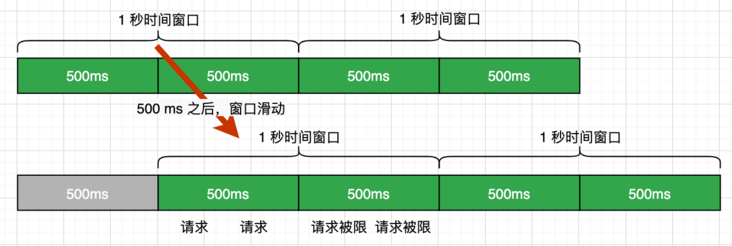
漏桶模式
消费速率恒定,可以很好的保护自身系统,可以对流量进行整形,但是面对突发流量不能快速响应。
令牌桶模式
Guava RateLimiter 的方案,能应对突发流量,但是有慢启动的过程,不过 Guava 已经对此做了优化。
@ConcurrentLimit 限制并发
@CircuitBreaker 熔断
有限状态机 OPEN CLOSED HALF_OPEN + FORCE_CLOSE + FORCE_OPEN
基于计数的滑动窗口
基于计数的滑动窗口是用一个 N 个测量值的圆形数组来实现的。
如果 count 窗口大小为 10,则循环数组总是有 10 个度量值。
滑动窗口增量更新总的统计值,随着新的调用结果被记录在环形数组中,总的统计值也随之进行更新。当环形数组满了,时间最久的元素将被驱逐,将从总的统计值中减去该元素的统计值,并该元素所在的桶进行重置。
检索快照(总的统计值)的时间复杂度为O(1),因为快照已经预先统计好了,并且和滑动窗口大小无关。
关于此方法实现的空间需求(内存消耗)为O(n)。
基于时间的滑动窗口
基于时间的滑动窗口是通过有 N 个桶的环形数组实现。
如果滑动窗口的大小为10秒,这个环形数组总是有10个桶,每个桶统计了在这一秒发生的所有调用的结果(部分统计结果),数组中的第一个桶存储了当前这一秒内的所有调用的结果,其他的桶存储了之前每秒调用的结果。
滑动窗口不会单独存储所有的调用结果,而是对每个桶内的统计结果和总的统计值进行增量的更新,当新的调用结果被记录时,总的统计值会进行增量更新。
检索快照(总的统计值)的时间复杂度为 O(1),因为快照已经预先统计好了,并且和滑动窗口大小无关。
关于此方法实现的空间需求(内存消耗)约等于O(n)。由于每次调用结果(元组)不会被单独存储,只是对N个桶进行单独统计和一次总分的统计。
每个桶在进行部分统计时存在三个整型,为了计算,失败调用数,慢调用数,总调用数。还有一个long类型变量,存储所有调用的响应时间。
@Fallback 降级
@Retryable 重试
参考文献

若有收获,就点个赞吧
0 人点赞
