您应该让容器在本地计算机上运行,以便您可以在以下练习中使用它,在这些练习中,您将检查容器如何在不使用虚拟机的情况下实现进程隔离。 Linux 内核的几个特性使这成为可能,现在是了解它们的时候了。
使用命名空间自定义进程环境
第一个称为 Linux 命名空间的特性确保每个进程都有自己的系统视图。这意味着在容器中运行的进程将只能看到系统上的一些文件、进程和网络接口,以及不同的系统主机名,就像它在单独的虚拟机中运行一样。
最初,Linux 操作系统中可用的所有系统资源,例如文件系统、进程 ID、用户 ID、网络接口等,都位于所有进程都可以看到和使用的同一个存储桶中。但是内核允许您创建称为命名空间的额外存储桶并将资源移动到其中,以便将它们组织成更小的集合。这允许您使每个集合仅对一个进程或一组进程可见。当你创建一个新进程时,你可以指定它应该使用哪个命名空间。该进程只看到此命名空间中的资源,而在其他命名空间中看不到任何资源。
介绍可用的命名空间类型
更具体地说,不只是单一类型的命名空间。实际上有几种类型——每种类型都有自己的命名空间。因此,一个进程不仅使用一个命名空间,而且为每种类型使用一个命名空间。
存在以下类型的命名空间:
- Mount 命名空间 (mnt) 隔离挂载点(文件系统)。
- 进程 ID 命名空间 (pid) 隔离进程 ID。
- 网络命名空间(net)隔离网络设备、堆栈、端口等。
- 进程间通信命名空间 (ipc) 隔离进程之间的通信(这包括隔离消息队列、共享内存等)。
- UNIX 分时系统 (UTS) 命名空间隔离系统主机名和网络信息服务 (NIS) 域名。
- 用户 ID 命名空间(用户)隔离用户和组 ID。
- Cgroup 命名空间隔离了控制组根目录。你将在本章后面学习 cgroups。
使用网络命名空间为进程提供一组专用的网络接口
进程运行所在的网络命名空间决定了该进程可以看到哪些网络接口。每个网络接口都属于一个命名空间,但可以从一个命名空间移动到另一个命名空间。如果每个容器都使用自己的网络命名空间,那么每个容器都会看到自己的一组网络接口。
下图所示,以更好地了解如何使用网络命名空间来创建容器。想象一下,您想运行一个容器化进程,并为其提供一组专用的网络接口,只有该进程才能使用。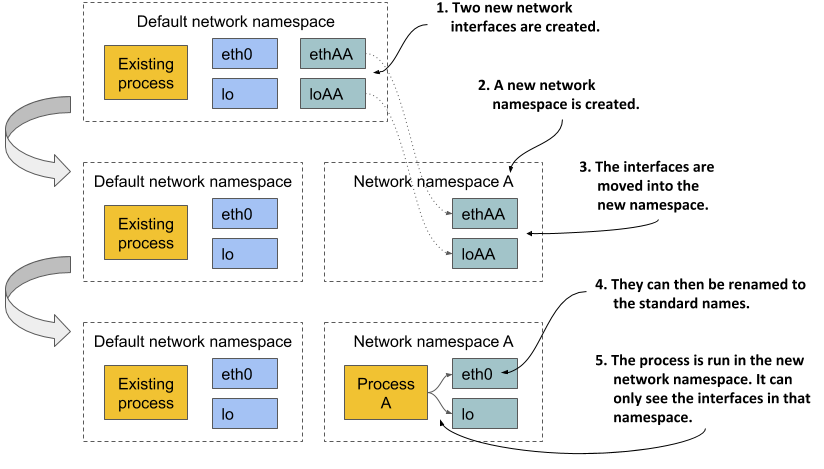
最初,仅存在默认的网络命名空间。然后为容器创建两个新的网络接口和一个新的网络命名空间。然后可以将接口从默认命名空间移动到新命名空间。在那里,它们可以被重命名,因为名称只能在每个命名空间中是唯一的。最后,该进程可以在这个网络命名空间中启动,这使得它只能看到为其创建的两个接口。
通过仅查看可用的网络接口,该进程无法判断它是在容器中还是在虚拟机中,或者是直接在裸机上运行的操作系统中。
使用 UTS 命名空间为进程提供专用主机名
另一个如何使进程看起来像在自己的主机上运行的示例是使用 UTS 命名空间。它确定在此命名空间内运行的进程所看到的主机名和域名。通过将两个不同的 UTS 命名空间分配给两个不同的进程,您可以让它们看到不同的系统主机名。对于这两个进程来说,它们看起来好像在两台不同的计算机上运行。
了解命名空间如何将进程彼此隔离
通过为所有可用的命名空间类型创建一个专用的命名空间实例并将其分配给一个进程,您可以使该进程相信它在自己的操作系统中运行。主要原因是每个进程都有自己的环境。一个进程只能看到和使用它自己的命名空间中的资源。它不能在其他命名空间中使用任何东西。同样,其他进程也不能使用它的资源。这就是容器如何隔离在其中运行的进程的环境。
在多个进程之间共享命名空间
在下一章中,您将了解到您并不总是希望将容器彼此完全隔离。相关容器可能想要共享某些资源。下图显示了两个进程的示例,它们共享相同的网络接口以及系统的主机和域名,但不共享文件系统。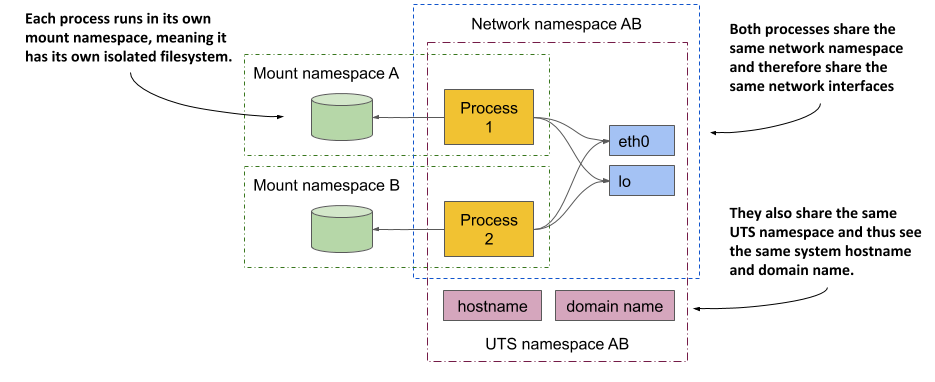
首先专注于共享网络设备。这两个进程看到并使用相同的两个设备(eth0 和 lo),因为它们使用相同的网络命名空间。这允许它们绑定到相同的 IP 地址并通过环回设备进行通信,就像它们在不使用容器的机器上运行一样。这两个进程也使用相同的 UTS 命名空间,因此看到相同的系统主机名。相反,它们各自使用自己的挂载命名空间,这意味着它们具有独立的文件系统。
总之,进程可能希望共享一些资源而不共享其他资源。这是可能的,因为存在单独的命名空间类型。进程对每种类型都有一个关联的命名空间。
鉴于这一切,有人可能会问,容器到底是什么? “在容器中”运行的进程不会在类似于虚拟机之类的真实机箱中运行。这只是一个分配了七个命名空间(每种类型一个)的进程。一些与其他进程共享,而另一些则不共享。这意味着进程之间的边界并不都落在同一条线上。
在后面的章节中,您将学习如何通过直接在主机操作系统上运行新进程来调试容器,但使用现有容器的网络命名空间,同时使用主机的默认命名空间进行其他所有操作。这将允许您使用主机上可用的工具来调试容器的网络系统,这些工具在容器中可能不可用。
探索运行容器的环境
如果你想看看容器内的环境是什么样的呢?系统主机名是什么,本地 IP 地址是什么,文件系统上有哪些二进制文件和库,等等?
要在 VM 的情况下探索这些功能,您通常通过 ssh 远程连接到它并使用 shell 执行命令。这个过程与容器非常相似。您在容器内运行一个 shell。
shell 的可执行文件必须在容器的文件系统中可用。在生产环境中运行的容器并非总是如此。
在现有容器中运行 shell
您的镜像所基于的 Node.js 镜像提供了 bash shell,这意味着您可以使用以下命令在容器中运行它:
$ docker exec -it kubia-container bashroot@44d76963e8e1:/#
此命令将 bash 作为现有 kubia-container 容器中的附加进程运行。该进程与主容器进程(正在运行的 Node.js 服务器)具有相同的 Linux 命名空间。通过这种方式,您可以从内部探索容器,并查看 Node.js 和您的应用程序在容器中运行时如何看待系统。 -it 选项是两个选项的简写:
- -i 告诉 Docker 以交互模式运行命令。
- -t 告诉它分配一个伪终端 (TTY),以便您可以正确使用 shell。
如果您想以习惯的方式使用 shell,则两者都需要。如果省略第一个,则无法执行任何命令,如果省略第二个,则不会出现命令提示符,并且某些命令可能会抱怨未设置 TERM 变量。
列出容器中正在运行的进程
让我们通过在容器中运行的 shell 中执行 ps aux 命令来列出容器中运行的进程。以下清单显示了命令的输出。
root@44d76963e8e1:/# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.1 676380 16504 ? Sl 12:31 0:00 node app.jsroot 10 0.0 0.0 20216 1924 ? Ss 12:31 0:00 bashroot 19 0.0 0.0 17492 1136 ? R+ 12:38 0:00 ps aux
该列表仅显示三个进程。这些是唯一在容器中运行的。您看不到在主机操作系统或其他容器中运行的其他进程,因为容器在其自己的进程 ID 命名空间中运行。
在主机的进程列表中查看容器进程
如果您现在打开另一个终端并列出主机操作系统本身的进程,您还将看到容器中运行的进程。这证实了容器中的进程实际上是在主机操作系统中运行的常规进程,如下面的清单所示。
$ ps aux | grep app.jsUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 382 0.0 0.1 676380 16504 ? Sl 12:31 0:00 node app.js
如果您使用 macOS 或 Windows,则必须列出托管 Docker 守护程序的 VM 中的进程,因为这是您的容器运行的地方。在 Docker Desktop 中,您可以使用以下命令进入 VM: docker run —net=host —ipc=host —uts=host —pid=host -it —security-opt=seccomp=unconfined —privileged —rm -v /:/host alpine chroot /host
如果您有敏锐的眼光,您可能会注意到容器中的进程 ID 与主机上的进程 ID 不同。因为容器使用自己的进程 ID 命名空间,所以它有自己的进程树和自己的 ID 编号序列。如下图所示,树是主机全进程树的子树。因此,每个进程都有两个 ID。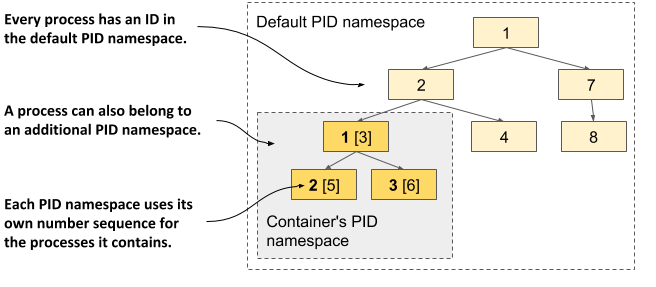
容器的文件系统与主机和其他容器隔离
与隔离的进程树一样,每个容器也有一个隔离的文件系统。如果列出容器根目录的内容,则只显示容器中的文件。这包括来自容器镜像的文件和在容器操作期间创建的文件,例如日志文件。下一个清单显示了您的 kubia 容器中的文件。
root@44d76963e8e1:/# ls /app.js boot etc lib media opt root sbin sys usrbin dev home lib64 mnt proc run srv tmp var
它包含 app.js 文件和属于 node:12 基本映像的其他系统目录。欢迎您浏览容器的文件系统。您会发现无法从主机的文件系统中查看文件。这很棒,因为它可以防止潜在的攻击者通过 Node.js 服务器中的漏洞访问它们。
要离开容器,通过运行 exit 命令或按 Control-D 离开 shell,您将返回到主机(类似于从 ssh 会话中注销)。
在调试容器中运行的应用程序时,像这样进入运行中的容器很有用。当出现问题时,您首先要调查的是您的应用程序看到的系统的实际状态。
使用 Linux 控制组限制进程的资源使用
Linux 命名空间使进程可以仅访问主机的部分资源,但它们不限制每个进程可以消耗多少资源。例如,您可以使用命名空间来允许进程仅访问特定的网络接口,但不能限制进程消耗的网络带宽。同样,您不能使用命名空间来限制进程可用的 CPU 时间或内存。您可能希望这样做以防止一个进程消耗所有 CPU 时间并防止关键系统进程正常运行。为此,我们需要 Linux 内核的另一个特性。
介绍 cgroups
使容器成为可能的第二个 Linux 内核特性称为 Linux 控制组 (cgroups)。它限制、考虑和隔离系统资源,例如 CPU、内存和磁盘或网络带宽。例如,使用 cgroups 时,一个进程或一组进程只能使用分配的 CPU 时间、内存和网络带宽。这样,进程就不能占用为其他进程保留的资源。
在这一点上,你不需要知道控制组是如何做这一切的,但你可以看看如何让 Docker 限制容器可以使用的 CPU 和内存量。
限制容器对 CPU 的使用
如果您不对容器对 CPU 的使用施加任何限制,则它可以不受限制地访问主机上的所有 CPU 内核。您可以使用 Docker 的 —cpuset-cpus 选项明确指定容器可以使用哪些内核。例如,要允许容器仅使用核心一和二,您可以使用以下选项运行容器:
$ docker run --cpuset-cpus="1,2" ...
您还可以使用选项—cpus、—cpu-period、—cpu-quota 和—cpu-shares 限制可用的CPU 时间。例如,要让容器只使用一半的 CPU 内核,请按如下方式运行容器:
$ docker run --cpus="0.5" ...
限制容器的内存使用
与 CPU 一样,容器可以使用所有可用的系统内存,就像任何常规 OS 进程一样,但您可能希望限制这一点。 Docker 提供了以下选项来限制容器内存和交换使用:—memory、—memory-reservation、—kernel-memory、—memory-swap 和—memory-swappiness。
例如,要将容器中可用的最大内存大小设置为 100MB,请按如下方式运行容器(m 代表兆字节):
$ docker run --memory="100m" ...
在幕后,所有这些 Docker 选项只是配置进程的 cgroups。内核负责限制进程可用的资源。有关其他内存和 CPU 限制选项的更多信息,请参阅 Docker 文档。
加强容器之间的隔离
Linux 命名空间和 Cgroup 将容器的环境分开,并防止一个容器耗尽其他容器的计算资源。但是这些容器中的进程使用相同的系统内核,所以我们不能说它们是真正隔离的。流氓容器可能会进行会影响其邻居的恶意系统调用。
想象一个运行多个容器的 Kubernetes 节点。每个都有自己的网络设备和文件,只能消耗有限数量的 CPU 和内存。乍一看,其中一个容器中的恶意程序不会对其他容器造成损坏。但是如果流氓程序修改了所有容器共享的系统时钟呢?
根据应用程序的不同,更改时间可能不是什么大问题,但是允许程序对内核进行任何系统调用可以让它们几乎可以做任何事情。系统调用允许他们修改内核内存,添加或删除内核模块,以及许多其他常规容器不应该做的事情。
这将我们带到了使容器成为可能的第三组技术。全面解释它们超出了本书的范围,因此请参阅专门关注容器或用于保护它们的技术的其他资源。本节简要介绍这些技术。
授予容器对系统的完全权限
操作系统内核提供了一组系统调用,程序使用系统调用与操作系统和底层硬件进行交互。其中包括创建进程、操作文件和设备、建立应用程序之间的通信通道等的调用。
其中一些系统调用相当安全,可用于任何进程,但其他系统调用仅保留给具有提升权限的进程。如果您查看前面提供的示例,在 Kubernetes 节点上运行的应用程序应该可以打开其本地文件,但不能更改系统时钟或以破坏其他容器的方式修改内核。
大多数容器应该在没有提升权限的情况下运行。只有那些您信任且实际需要额外权限的程序才能在特权容器中运行。
使用 Docker,您可以使用 —privileged 标志创建一个特权容器。
使用 Capabilities 赋予容器所有特权的子集
如果应用程序只需要调用一些需要提升权限的系统调用,那么创建具有完全权限的容器并不理想。幸运的是,Linux 内核还将权限划分为称为 capabilities的单元。能力的例子是:
- CAP_NET_ADMIN 允许进程执行网络相关的操作,
- CAP_NET_BIND_SERVICE 允许它绑定到小于 1024 的端口号,
- CAP_SYS_TIME 允许它修改系统时钟,等等。
创建容器时,可以从容器中添加或删除 capabilities。每个 capability代表一组可用于容器中的进程的权限。 Docker 和 Kubernetes 删除了除典型应用程序所需的功能之外的所有功能,但如果获得授权,用户可以添加或删除其他功能。
运行容器时始终遵循最小权限原则。不要给他们任何他们不需要的能力。这可以防止攻击者使用它们来访问您的操作系统。
使用 seccomp 配置文件过滤单个系统调用
如果您需要更好地控制程序可以进行的系统调用,您可以使用 seccomp(安全计算模式)。您可以通过创建一个 JSON 文件来创建自定义 seccomp 配置文件,该文件列出允许使用该配置文件的容器进行的系统调用。然后在创建容器时将文件提供给 Docker。
使用 AppArmor 和 SELinux 强化容器
似乎到目前为止讨论的技术还不够,容器还可以通过两种额外的强制访问控制 (MAC) 机制来保护:SELinux(安全增强型 Linux)和 AppArmor(应用程序装甲)。
使用 SELinux,您可以将标签附加到文件和系统资源,以及用户和进程。如果涉及的所有主体和对象的标签都与一组策略匹配,则用户或进程只能访问文件或资源。 AppArmor 类似,但使用文件路径而不是标签,并专注于进程而不是用户。
SELinux 和 AppArmor 都大大提高了操作系统的安全性,但如果您被所有这些与安全相关的机制所淹没,请不要担心。本节的目的是阐明正确隔离容器所涉及的所有内容,但目前对命名空间的基本了解应该绰绰有余。

若有收获,就点个赞吧
0 人点赞
