从零揣摩是采用将自己想象成设计者的角度,以作者的视角去揣摩代码的设计,并不是对着代码逐段逐段去解释,因为这样太枯燥了,缺乏代入感,而是从最原始的代码一步步优化至作者的代码,达到知其然知其所以然的目的。
由于本人水平有限,只能尽量去揣摩代码的设计思路,并不代表原作者本人的意愿。
前言
缓存是提升性能的利器,redis、memcache 等作为缓存服务被大量应用在实际业务中。但如果让我们自己开发一个分布式缓存,我们应该如何设计呢?本文将参照 groupcache(Go语言实现) 的源码一步步实现一个分布式缓存,首先从设计目标来看,主要需实现两部分功能:缓存功能设计和分布式功能设计。
缓存功能设计
针对缓存部分的功能,因为缓存一般都是kv的键值对,所以第一反应就是使用字典类型。在 Go 语言中就是 Map 数据结构,那如果直接使用 Map 作为缓存的底层结构可以么?答案是不行的,直接使用将面临以下几个问题:
- 作为缓存,需要应对大量的并发读写操作。在 Go 语言中就是
Map是不支持并发写操作的。不过这个问题好解决,加个互斥锁就可以了。 - 内存不是无限大的,也就是说必定需要淘汰一些不经常被访问的数据。并且
Map删除数据使用的delete操作并不是真正删除数据,而是标记删除,这些数据是不会释放内存的。(参考:https://github.com/golang/go/issues/20135)。
基于以上情况,我们首先要考虑一种缓存替换策略,目前经常被使用的就是 LRU 算法(最近最少使用算法)),基本原理如下图所示: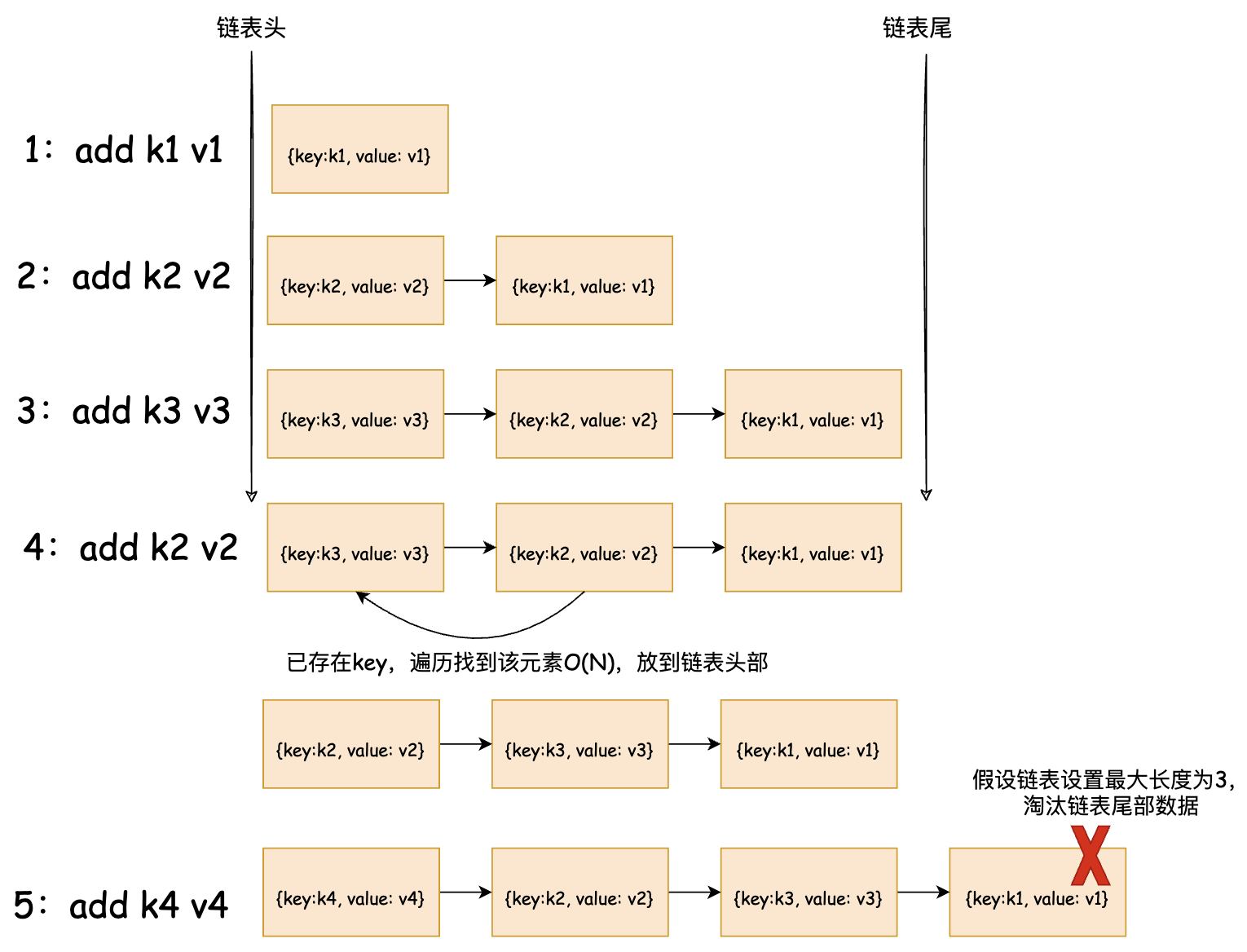
根据上图可知,以链表作为缓存的底层结构,那么写入新的key时,只需要将元素插入链表头,时间复杂度 O(1)。当淘汰元素的时候,也是删除链表尾的元素,时间复杂度 O(1)。但是在查找元素的时候,需要遍历整个链表,时间复杂度为 O(N)。因此可以增加一个 Map 存储指向链表中元素的指针,通过查询的key获得指向元素的指针,然后直接获得元素,时间复杂度 O(1),存储结构如下图所示: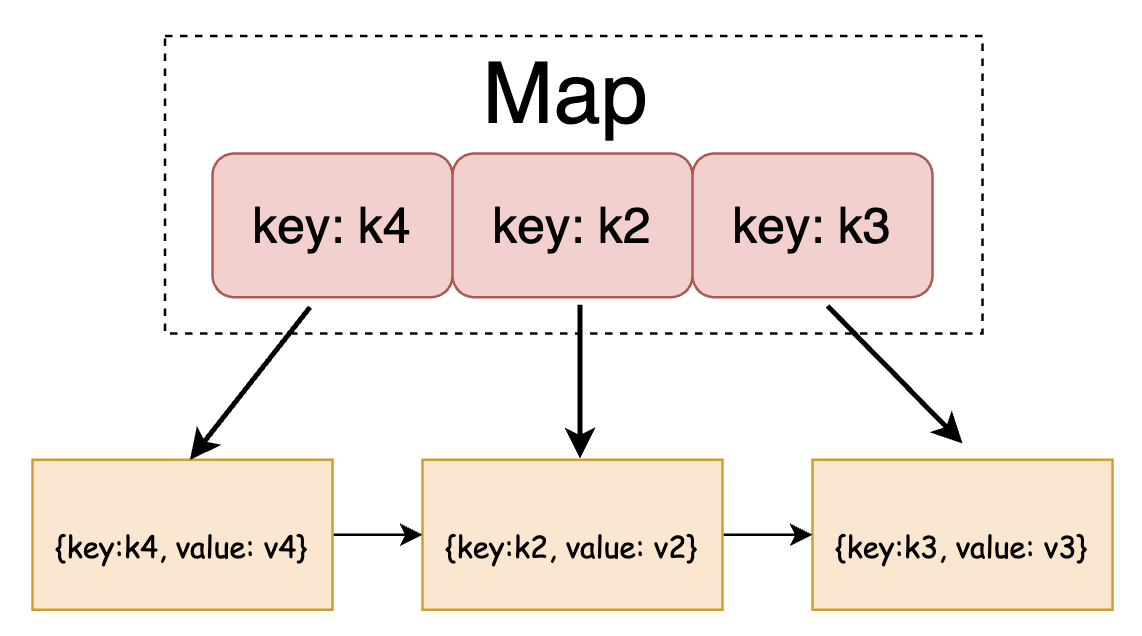
LRU代码实现
如果对源码分析不感兴趣,可以跳过本节,不影响内容阅读。
// Key 需要是可以比较的类型,参考 https://go.dev/ref/spec#Comparison_operatorstype Key interface{}// entry 结构体就是链表中存储的元素type entry struct {key Keyvalue interface{}}// LRU 缓存结构type Cache struct {// 实际存储数据的链表,使用标准库 container/listll *list.List// map 结构,辅助元素的查询cache map[interface{}]*list.Element// 执行删除元素时的回调函数OnEvicted func(key Key, value interface{})}
接下来就是缓存需要支持的写入和读取操作,分别对应 Add 和 Get 方法:
func (c *Cache) Add(key Key, value interface{}) {// 查询 key 是否已经存在,则将元素放到链表头部,并更新 value 的内容if ee, ok := c.cache[key]; ok {c.ll.MoveToFront(ee)ee.Value.(*entry).value = valuereturn}// 如果 key 不存在,则将元素直接放到链表头部,并更新辅助 map 的内容ele := c.ll.PushFront(&entry{key, value})c.cache[key] = el}
func (c *Cache) Get(key Key) (value interface{}, ok bool) {if c.cache == nil {return}// 查询辅助 map,如果 key 存在,则将元素放到链表头部if ele, hit := c.cache[key]; hit {c.ll.MoveToFront(ele)return ele.Value.(*entry).value, true}return}
当链表的长度超过最大数量限制时,需要淘汰链表尾部的元素,代码如下:
// 淘汰链表尾部元素的代码func (c *Cache) RemoveOldest() {if c.cache == nil {return}// 获取链表尾部元素,然后删除ele := c.ll.Back()if ele != nil {c.removeElement(ele)}}// 实际删除操作func (c *Cache) removeElement(e *list.Element) {c.ll.Remove(e)kv := e.Value.(*entry)delete(c.cache, kv.key)// 执行回调函数if c.OnEvicted != nil {c.OnEvicted(kv.key, kv.value)}}
以上代码实现了一个LRU的存储结构,但是作为缓存功能来说,还需要满足以下几点:
- 针对高并发读写,需要增加读写锁保证数据一致性
entry结构中的value字段是interface{}类型,需要一个确定的结构来统一操作。- 需要保存缓存当前使用的内存大小,当超过预设的最大上限,则开始淘汰尾部元素
基于以上需要,可以利用LRU缓存封装一层核心的 cache 功能。
type cache struct {mu sync.RWMutex // 读写锁,对应第1点nbytes int64 // 记录缓存当前使用的内存大小,以字节为单位,对应第3点lru *lru.Cache // LRU缓存结构}
针对第2点,groupcache 中定义了统一的结构体 ByteView ,具体结构如下:
type ByteView struct {// If b is non-nil, b is used, else s is used.b []bytes string}
这是因为缓存的内容一般为 byte[] 或 string ,而定义一个统一的 ByteView,可以避免 byte[] 转换为 string(或 string 转换为 byte[]) ,转换操作都会带来额外的内存分配,降低整体性能。接下来,继续看下封装之后的 cache 的读写方法的代码实现:
func (c *cache) add(key string, value ByteView) {c.mu.Lock()defer c.mu.Unlock()// 延迟初始化,在使用时在初始化,避免浪费资源,很常用的手段if c.lru == nil {c.lru = &lru.Cache{// 在淘汰元素的时候,减去该元素 key 和 value 所占的大小OnEvicted: func(key lru.Key, value interface{}) {val := value.(ByteView)c.nbytes -= int64(len(key.(string))) + int64(val.Len())c.nevict++},}}// 调用底层的 lru.Add 方法c.lru.Add(key, value)// 增加当前加入的 key 和 value 的大小c.nbytes += int64(len(key)) + int64(value.Len())}
func (c *cache) get(key string) (value ByteView, ok bool) {c.mu.Lock()defer c.mu.Unlock()if c.lru == nil {return}// 调用底层 lru.Get 方法vi, ok := c.lru.Get(key)if !ok {return}return vi.(ByteView), true}
func (c *cache) removeOldest() {c.mu.Lock()defer c.mu.Unlock()if c.lru != nil {// 调用底层的 lru.RemoveOldest() 方法c.lru.RemoveOldest()}}
从以上代码可以看出,核心 cache 结构就是对底层的 LRU 结构的增加了一层封装。目前这个核心的 cache 结构能直接用于实际业务中了么?其实还是不行,因为我们搭建了一个缓存的服务,是希望不仅仅是只为一个业务服务的,所以需要有一个命名空间的概念,类似kafka的topic。同时,如果缓存没有命中,是需要从另外一个数据源(数据库、文件等)中加载命中数据到缓存中,因此需要提供一个方式给用户编写自定义的加载逻辑,需求总结如下:
- 需要提供命名空间功能
- 需要提供一个方式给用户编写自定义的加载逻辑
因此我们在核心的 cache 结构上再封装一层 group 结构满足以上两个需求,结构定义如下:
type Group struct {name string // 命名空间,对应第1点getter Getter // Getter接口,应对第2点cacheBytes int64 // 缓存服务内存最大限制,限制缓存占用的最大内存mainCache cache // 核心 cache 结构}
应对第2点,定义了一个 Getter 接口,用户只要实现了这个接口,就能完成缓存数据的加载。代码如下:
type Getter interface {Get(key string) (ByteView, error)}type GetterFunc func(key string) (ByteView, error)func (f GetterFunc) Get(key string) (ByteView, error) {return f(key)}
同时,定义了一个 GetterFunc 的函数实现了 Getter 接口的 Get(key string) (ByteView, error) 方法,这种叫做接口型函数,方便使用者在调用时既能够传入函数作为参数,也能够传入实现了该接口的结构体作为参数。
接口型函数在 http 标准库 Handler 和 HandlerFunc 大量使用。
整体流程
根据以上分析,目前的缓存加载流程如下: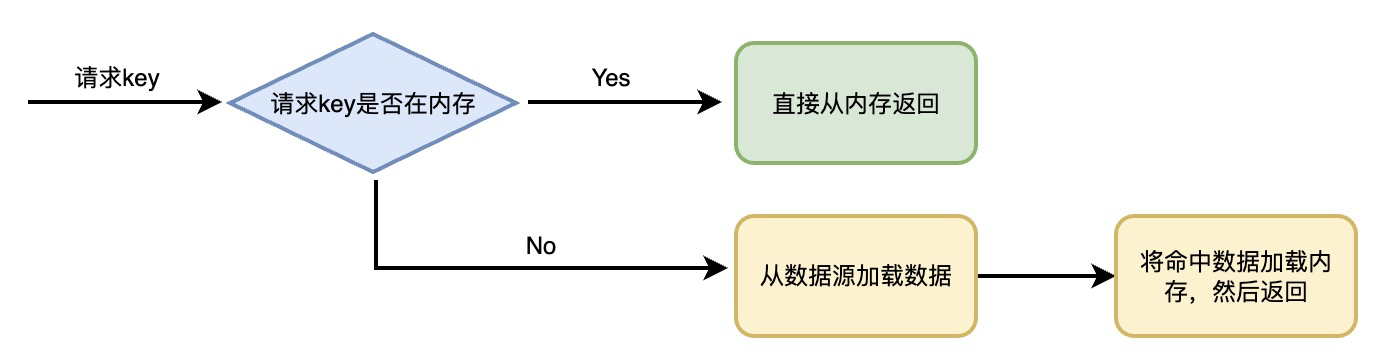
- 初始化全局
groups,用于区分命名空间,同时添加读写锁控制并发操作。 ```go var ( mu sync.RWMutex // 全局 groups,区分命名空间 groups = make(map[string]*Group) )
// 初始化 group,特别注意 getter 是用于当缓存没有命中时,从其他数据源加载数据的方式 func NewGroup(name string, cacheBytes int64, getter Getter) *Group { if getter == nil { panic(“nil Getter”) } mu.Lock() defer mu.Unlock() if _, dup := groups[name]; dup { panic(“duplicate registration of group “ + name) } g := &Group{ name: name, getter: getter, cacheBytes: cacheBytes, } groups[name] = g return g }
// 根据命名空间,获取对应 group func GetGroup(name string) *Group { mu.RLock() g := groups[name] mu.RUnlock() return g }
2. 定义从读取缓存的 `Get` 方法,代码如下:```gofunc (g *Group) Get(ctx context.Context, key string) (value ByteView, err error) {// 从缓存中获取数据value, cacheHit := g.lookupCache(key)if cacheHit {return}// 从数据源加载数据value, err := g.load(key)if err != nil {return}return}
func (g *Group) lookupCache(key string) (value ByteView, ok bool) {if g.cacheBytes <= 0 {return}// 从底层核心 cache 获取数据value, ok = g.mainCache.get(key)return}
func (g *Group) load(key string) (value ByteView, err error) {// 从本地加载数据value, err = g.getLocally(key)return}
func (g *Group) getLocally(key string) (value ByteView, err error) {// 从自定义的数据源加载数据value, err = g.getter.Get(key)if err != nil {return}g.populateCache(key, value, &g.mainCache)return}
将数据源获取的数据加载到缓存中,超过最大限制需要淘汰尾部元素 ```go func (g Group) populateCache(key string, value ByteView, cache cache) { if g.cacheBytes <= 0 {
return
} cache.add(key, value)
for {
mainBytes := g.mainCache.bytes()if mainBytes <= g.cacheBytes {return}g.mainCache.removeOldest()
}
总结
本篇是 groupcache 从零揣摩的第一篇重点在缓存设计,在下一篇中将基于目前的缓存设计的基础上增加分布式的功能,最终完成分布式缓存的设计。本篇涉及以下几个重点内容:
LRU算法由于链表的关系,再查询时时间复杂度时O(N),因此可以辅助一个字典Map,提升效率。- 在设计代码时,可以先从基础功能出发,然后在基础功能上进行一层封装,一步步得到最终结果,代码的可读性也更好。
- 接口型函数在
Go语言中被大量的使用,它可以使得我们在完成接口实现时,不需要定义一个结构体,然后去New结构体再调用,简化使用方式(当然在复杂的场景下还是需要定义结构体的,接口型函数主要是在简单的场景下使用)。

若有收获,就点个赞吧
0 人点赞
