jdk8/11
概览
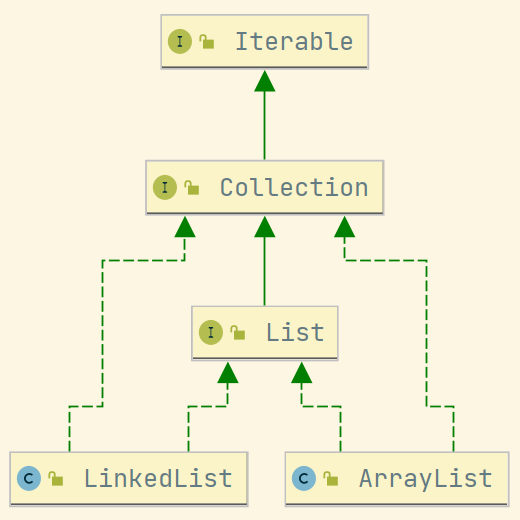
集合总体可以分为两大类:Collection和Map,Collection是存储对象的集合,Map是存储键值对的映射表。
1、Collection
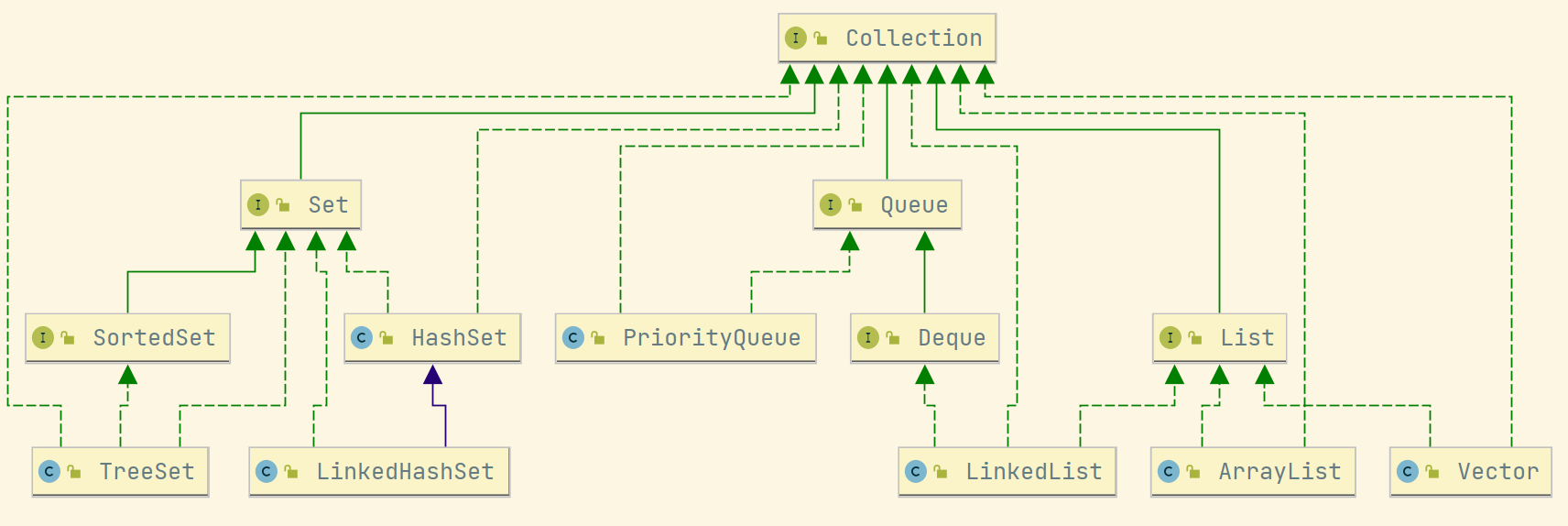
- Set:唯一对象的集合
- TreeSet:基于红黑树实现,支持有序操作,例如范围查找。由于是基于树结构的查找,所以查找效率最优为
#card=math&code=O%28logN%29&id=ovOxy),效率不及HashSet。
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作,并且失去了插入顺序的概念,即使用Iterator遍历HashSet得到的结果是不确定的。
- LinkedHashSet:具有HashSet的查找效率,内部使用双向链表维护元素的插入删除,所以与HashSet不同,LinkedHashSet的Iterator遍历结果是确定的。
- TreeSet:基于红黑树实现,支持有序操作,例如范围查找。由于是基于树结构的查找,所以查找效率最优为
- List:线性存储结构
- ArrayList:基于动态数组实现,空间连续,所以随机访问效率高。
- Vector:加了重锁的ArrayList(几乎所有操作的方法都使用了synchronized关键字),可以看成是线程安全的ArrayList。
- LinkedList:基于双向链表实现,空间不连续,插入删除元素比较高效。可以用作栈、队列、双向队列。
- 用作栈的时候,栈顶在第一个元素;
- 用作队列的时候,队头为第一个元素,队尾为最后一个元素;
- 用作双向队列的时候,同上。
- Queue:一种先进先出的结构。
- LinkedList实现;
- PriorityQueue:基于堆结构实现的优先队列。
2、Map
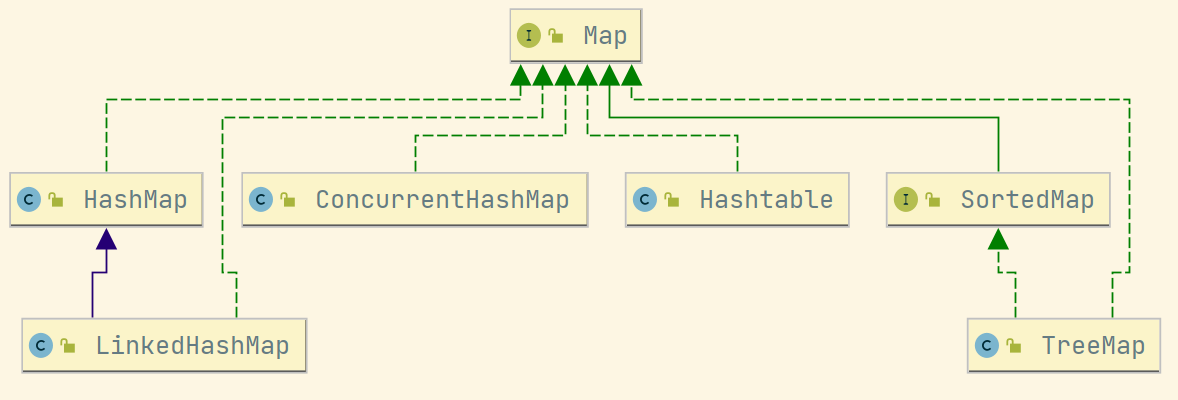
- TreeMap:基于红黑树实现,可以实现有序遍历
- HashMap:基于哈希、链表、b红黑树实现,遍历时无序
- HashTable:线程安全的HashMap,已经不推荐使用。
- LinkedHashMap:使用双向链表来维护数据的顺序,典型的LRU逻辑,最近使用的元素在链表头。
设计模式
迭代器模式
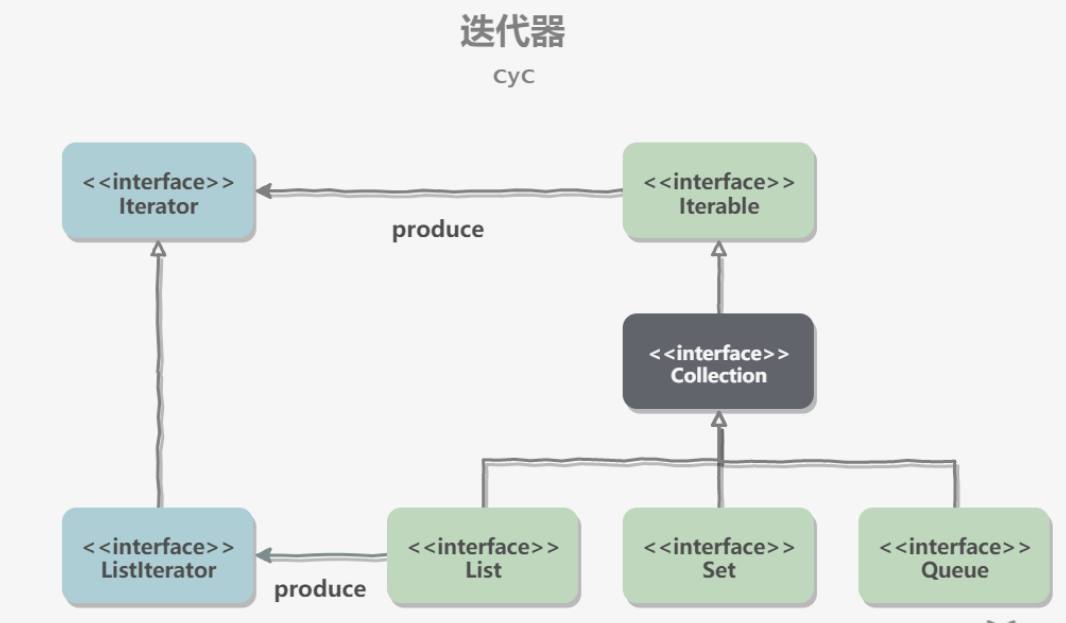
Collection 继承了Iterable接口,其中的iterator()方法能够产生一个Iterator对象,接着就可以通过这个迭代器对象遍历Collection中的元素。注意,JDK5之后可以直接使用foreach的语法来更加便捷地实现遍历。
适配器模式
Arrays工具类提供asList(T…a)方法将数组类型转换为List类型。
public static <T> List<T> asList(T... a) {return new ArrayList<>(a);}
Map
HashMap
关键点
1. 底层数据结构
底层的数据结构主要是Node类型的数组table、链表和红黑树。其中Node类型实现的是Map.Entry接口,其定义结构如下:
static class Node<K,V> implements Map.Entry<K,V> {final int hash; // 对应key的hash值,为了方便之后的比较final K key; // HashMap中的key值必须是唯一的V value;Node<K,V> next; // 使用拉链法来解决冲突,链表的关系指针// methods ...}
2. 初始化,懒加载
初始化HashMap的时候,主要是初始了负载因子(默认情况下为0.75)。而底层的存储结构数组在初始化的时候仍然是空的,只有在第一次put的时候,才会通过resize()方法建立初始长度为 16 的table。(懒加载)
3. 哈希桶的长度
table的长度cap必然是 2 的幂次,这跟存储元素的下标计算有关,所以无论用户在构造函数指定的大小为多少,最终都会通过tableSizeFor方法将大小转为大于且最近的2的幂次。
static final int tableSizeFor(int cap) {// 获取cap的前导零个数,然后用-1逻辑右移,接着+1构造盘子(数组的上边界)// 最终获取的值就是比cap大的最近的2的幂次int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1);return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
4. 元素定位
元素在数组中的下标=哈希值和哈希表容量-1相与hash & (cap - 1)。由于cap的大小必然是2的幂次,所以cap-1就是一连串的1,与hash值一与恰好就和求余等价,限制了下标在0~cap-1之间。
5. hash值计算
hash(k)方法。在获取了**key**对象的hashCode之后与这个hashCode的高16位相与的结果作为key的hash值。因为一般情况下哈希表不会太大,所以给元素分配位置的时候往往只使用了低16位,这样子相当于高16位就浪费了。故这么做是为了让高位也参与影响最终数组下标,增加散列性。
static final int hash(Object key) {int h;// key为空的情况下,hash为0// 否则利用Object的hashCode再进行处理// 不处理的话:// 那么之后每一次访问元素,只利用了hash值的低lgn位,高位没有利用到// 使得冲突的概率较大,导致hashmap的效率变低// 所以希望高位也被利用:// 将高位逻辑右移一段长度与低位进行异或// 使得高位也能够影响之后计算数组下标的结果// 减少冲突,增加散列性return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
6. 红黑树优化
红黑树优化。jdk8之后使用的红黑树,原因可以这样理解:之前的版本中使用链表来解决哈希冲突,会出现链表过长的情况,导致元素的访问效率下降。如果不在某个阶段改变这个数据结构,这个问题就一直存在。
链表插入非常高效,但访问慢;红黑树呢,插入删除都非常可以,put/get都能够比较均衡。
7. 树化标准
为了转换为红黑树,有两个标准要同时满足:
- 达到树化阈值=8,但并不是一旦到达8就进行树化,从源码可以看出当整个数组的长度<64的时候仍然是使用拓容来解决,因为拓容往往能够缩小一定的链表长度。
- 故第二个标准就是,数组长度>=64.
还有一个反向的阈值=6,变回链表。之所以两个阈值不同,是为了防止频繁的在临界插入删除导致转化频繁。
并发问题
在并发情况下,链表转换成红黑树可能会出现死循环。测试方法,用多线程来操作 hashmap,出现了程序不退出的情况:
- 查看 CPU 的使用率,使用率很高说明大概率出现了死循环
- jps 和 jstack 命令,查看 JVM 进程的执行状态,定位出错的位置
- 发现是在 TreeNode 的 treeify 函数位置出现的死循环
关键源码
大佬写的代码都是能简则简,看起来还是有那么些吃力⊙﹏⊙∥
put
put方法。若key值之前存储过,则put会返回上一次的oldValue;否则返回null。
大体分为四种情况:
- 定位的槽没有元素,直接将key和value包装成一个新的Node节点存在该槽即可。
- 出现了key值是完全相同的,则用新value覆盖旧的,保证key值的唯一性。
- 若树化了就在红黑树上进行遍历比较key
- 没有树化,就从头遍历链表匹配key。匹配到key值则覆盖旧的value;若最终都没有匹配到key,就在链表的尾部添加一个新的节点,后检查是否达到树化条件。(尾插法)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0) // 第一次初始n = (tab = resize()).length; // 拓容和初始化统一为 resize()if ((p = tab[i = (n - 1) & hash]) == null) // p对应着要访问的节点(链表头)// n为当前table大小,tab指向table// 根据key的hash值取余之后得到在table中的下标// 若没有元素,则是第一次新添加,创建一个新节点tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) // key值完全相同e = p;else if (p instanceof TreeNode) // 树化,遍历红黑树e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {// 遍历链表,检查是否有完全匹配的key// 无完全匹配的key,则把新节点插入链表的最后// 否则覆盖原有的节点,保证hashmap中key的唯一性for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash); // 大于等于阈值,链表转红黑树break;}// hash值不相等则key必然不相等,逻辑&&能够减少一定后边的计算// equals方法的效率会稍微比较低if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) // key值完全匹配break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold) // 若添加元素后大小超过了阈值,进行拓容resize();afterNodeInsertion(evict);return null;}
get
final Node<K,V> getNode(int hash, Object key) {// 找到对应的槽,遍历链表查找元素Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {if (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do { // 遍历链表查找if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
resize
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold; // 阈值int newCap, newThr = 0;if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // double threshold}else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;else { // zero initial threshold signifies using defaults// 创建了HashMap之后,初始时Node数组=null// 第一次put的时候,才给数组创建长度=16newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab; // 将原本的table指向新的newTabif (oldTab != null) {// 数组转移,元素的位置再根据数组的长度重新计算// 因为下标值 index = hash & (len - 1)for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null; // 将原本的对象引用去掉,使变成垃圾对象if (e.next == null) // 链表长度为 1,直接移动表头即可newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode) // 对于已经红黑树化的 hashmap,调用 split 方法((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else { // preserve order// 拓容之后,链表上的某些节点对应的槽可能会有所改变// 所以需要遍历链表一个个判断Node<K,V> loHead = null, loTail = null; // 下标值不改变的链表Node<K,V> hiHead = null, hiTail = null; // 下标值改变的链表// 因为拓容就是原本的1左移一位,如果原本oldCap 1的位置// hash是有值的,那么现在其下标值就会发生改变;// 否则不会改变。一共就只有两种情况,所以原本的一个链表最多拆成两个链表Node<K,V> next;do {next = e.next;// e.hash & oldCap 的作用实际上就是检查// 拓容后是否会改变原本的下标值if ((e.hash & oldCap) == 0) {// == 0 不会改变下标值// 尾插法连接链表if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else {// 拓容后下标值会变化,仍然是尾插法// 为了避免遍历链表,使用了一个链表尾指针if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) { // 下标值未改变的链表放入槽loTail.next = null;newTab[j] = loHead;}if (hiTail != null) { // 下标值更新的链表放入槽hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;}
remove
final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;if ((tab = table) != null && (n = tab.length) > 0 && // 存储数组不为空(p = tab[index = (n - 1) & hash]) != null) { // 能够查找到该元素Node<K,V> node = null, e; K k; V v;if (p.hash == hash && // 优先比较hash值,相同则不需要额外比较key了((k = p.key) == key || (key != null && key.equals(k))))node = p;else if ((e = p.next) != null) {if (p instanceof TreeNode) // 树化则调用树的方法 getTreeNodenode = ((TreeNode<K,V>)p).getTreeNode(hash, key);else {do { // 遍历链表查找key值匹配的元素if (e.hash == hash && // hash值不同,key必然不同;key相同,hash值必然相同((k = e.key) == key || // key可能为null(key != null && key.equals(k)))) {node = e;break;}p = e; // p最初为链表头节点,在遍历链表的过程中维护为e的上一个节点} while ((e = e.next) != null);}}// 获得的匹配key的节点由node引用// 从链表中删去节点并返回被删除的节点if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);else if (node == p)tab[index] = node.next;elsep.next = node.next;++modCount;--size;afterNodeRemoval(node);return node;}}return null;}
treeifyBin
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// table的大小在一定范围内时,仍然使用拓容来解决链表过长的问题。默认64if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do { // 遍历链表,转化为树节点TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab);}}
ConcurrentHashMap
主要使用了 Unsafe 类中的 CAS 操作还有 volatile 操作来进行支持并发操作,当然还使用 synchronized 锁代码块。来看看一些主要的操作。
Unsafe 类操作
@SuppressWarnings("unchecked")static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {// 使用 volatile 来读取内存中的最新值return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);}static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,Node<K,V> c, Node<K,V> v) {// 使用 cas 来更新某个哈希桶的值return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);}static final <K, V> void setTabAt(Node<K, V>[] tab, int i, Node<K, V> v) {// 用 volatile 的方法来设置节点值,保证可见性U.putObjectVolatile(tab, ((long) i << ASHIFT) + ABASE, v);}
putVal
可以发现在添加元素的时候,是以定位到的哈希槽的链表头作为锁,所以锁的粒度是一个哈希槽,粒度较小,能够减少发生竞争的概率,更好地支持高并发。
// 整体的逻辑基本和 HashMap 的一致,增加了线程安全的操作final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))// 在空 bin 添加元素的时候使用 cas,不用加锁// 加不加锁的主要区别在于是否要切换到内核态,由操作系统管理break;}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;// 查找并且添加元素到链表,使用 synchronized 进行线程安全保护// synchronized 底层有 JVM 的优化,// 偏向锁(仅仅标识对象头) -> 轻量级锁(cas) -> 重量级锁(切换到内核态)// 以当前的哈希槽 f 作为锁synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
TreeMap
HashMap 是一种空间换时间的映射表,其实现原理决定了内部的 Key 是无序的。那么在希望有序遍历 map 的场景下,jdk 还提供链了一种 SorrtedMap,其实现就是 TreeMap。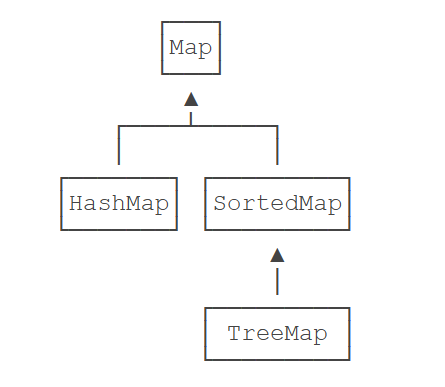
和其他有序集合的实现一样,默认情况下 TreeMap 是升序组织,若要降序需要实现一个 Comparator 接口。
SortedMap<Integer, String> ascMap = new TreeMap<>();SortedMap<Integer, String> descMap = new TreeMap<>((k1, k2) -> k2 - k1);
List
ArrayList
ArrayList底层是Object数组,默认初始为一个空的数组。只有在第一次添加元素之后,才会进行拓容到默认容量10。ArrayList的拓容,除了第一次初始化的时候拓容为默认大小 10,之后的拓容都是拓容到原本的倍1.5。拓容调用的是Arrays.copyOf(更往下调用的是本地方法System.arrayCopy)方法,重新获得一个新的拓容后的数组对象。- 由于数组是空间连续的结构,所以支持快速地随机访问元素。但是添加、删除元素的效率比较低。
关键源码分析
基本属性
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable{private static final int DEFAULT_CAPACITY = 10; // 默认第一次大小为 10private static final Object[] EMPTY_ELEMENTDATA = {};private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};transient Object[] elementData; // non-private to simplify nested class accessprivate int size;}
constructor
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {// 按照用户的参数初始化数组的大小,用户指定多大就是多大// 这里要区别HashMap,HashMap中为了方便计算哈希值,限定了容量必须为2的幂次this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}public ArrayList() { // 默认情况下,为长度=0的空数组this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
grow拓容
private Object[] grow(int minCapacity) { // 拓容调用Arrays.copyOf方法return elementData = Arrays.copyOf(elementData,newCapacity(minCapacity));}private Object[] grow() {return grow(size + 1);}private int newCapacity(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1); // 新容量 = 旧容量 * 1.5if (newCapacity - minCapacity <= 0) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) // 初始为空数组return Math.max(DEFAULT_CAPACITY, minCapacity);if (minCapacity < 0) // 数值过大导致整数溢出throw new OutOfMemoryError();return minCapacity;}return (newCapacity - MAX_ARRAY_SIZE <= 0)? newCapacity: hugeCapacity(minCapacity);}
add末尾添加元素
// 末尾添加元素public boolean add(E e) {modCount++;add(e, elementData, size);return true;}private void add(E e, Object[] elementData, int s) {if (s == elementData.length) // 当前数组已满,就先拓容再添加元素elementData = grow();elementData[s] = e;size = s + 1;}
// 特定位置添加元素public void add(int index, E element) {rangeCheckForAdd(index); // 检查是否越界modCount++;final int s;Object[] elementData; // 用于获取当前的数组if ((s = size) == (elementData = this.elementData).length) // 数组已满先拓容elementData = grow();System.arraycopy(elementData, index, // 将index之后的元素通过拷贝全部后移一位elementData, index + 1,s - index);elementData[index] = element; // 后移完成后,填入新元素size = s + 1;}
remove删除元素
public E remove(int index) {Objects.checkIndex(index, size);final Object[] es = elementData;@SuppressWarnings("unchecked") E oldValue = (E) es[index];fastRemove(es, index);return oldValue;}private void fastRemove(Object[] es, int i) {modCount++;final int newSize;if ((newSize = size - 1) > i)// 若删除的元素不是最后一个元素,通过逐个向前拷贝将其覆盖// 仍然是调用本地方法arraycopySystem.arraycopy(es, i + 1, es, i, newSize - i);es[size = newSize] = null;}
LinkedList
- 内部结构是双向链表。添加、删除元素效率比较高,但是不支持随机访问某个元素。
- 默认的添加删除行为的特性和队列一样,即先进先出。
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}
关键源码分析
基本属性
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, java.io.Serializable{transient int size = 0;transient Node<E> first; // 指向第一个元素transient Node<E> last; // 指向最后一个元素}
add尾部添加元素
public boolean add(E e) {linkLast(e);return true;}// 链表末尾添加新链接void linkLast(E e) {final Node<E> l = last; // 临时保存最后一个元素final Node<E> newNode = new Node<>(l, e, null); // 添加新节点last = newNode; // 尾结点更新为新添加的结点if (l == null) // 若原本链表就是空的,则更新头节点为新添加的结点first = newNode;elsel.next = newNode; // 否则将新的末尾结点链接上来size++; // 增加链表长度记录值modCount++;}
addFirst首部添加元素
private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f); // 创建新的结点,向后指向firstfirst = newNode;if (f == null) // 若这是第一次添加元素,则last指向也更新last = newNode;elsef.prev = newNode; // 否则链接上当前的头节点size++;modCount++;}
remove删除首元素
public E remove() {return removeFirst();}public E removeFirst() {final Node<E> f = first;if (f == null)throw new NoSuchElementException();return unlinkFirst(f);}private E unlinkFirst(Node<E> f) {// assert f == first && f != null;final E element = f.item;final Node<E> next = f.next;f.item = null;f.next = null; // help GCfirst = next; // 将首元素指针指向下一个元素if (next == null) // 若下一个元素为空,则说明当前链表没有元素,更新lastlast = null;elsenext.prev = null; // 否则,当前的首元素向前的链接去掉size--;modCount++;return element;}
removeLast删除末尾元素
public E removeLast() {final Node<E> l = last;if (l == null)throw new NoSuchElementException();return unlinkLast(l);}private E unlinkLast(Node<E> l) {// assert l == last && l != null;final E element = l.item;final Node<E> prev = l.prev; // 获取到最后一个元素的前驱l.item = null;l.prev = null; // help GClast = prev; // last指向向前移if (prev == null) // 若当前链表已经没有元素了,更新firstfirst = null;elseprev.next = null; // 否则,当前末尾的元素的向后链接去掉size--;modCount++;return element;}
CopyOnWriteArrayList
读写分离
写操作在一个复制的数组上进行,读操作在原始的数组中进行。
写操作需要加锁保证数据的同步,写完后将原始数组指向新的数组。
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;return true;} finally {lock.unlock();}}final void setArray(Object[] a) {array = a;}
@SupperessWarnings("unchecked")private E get(Object[] a, int index) {return (E) a[index];}
优缺分析
非常适合读多写少的场景,但是缺陷也很明显:
- 内存占用:在写操作是需要复制一个新的数组。
- 数据不一致:读操作可能获取到的数据不是最新的。
所以不适合内存敏感以及对实时性要求很高的场景。
Set
TreeSet
结构分析
底层使用 NavigableMap 来实现(大部分情况下就是 TreeMap),所以基础结构是红黑树。所以根据红黑树的性质,其元素是有序的,插入和删除的复杂度都是 O(logN),查询的复杂度也是 O(logN)。
public class TreeSet<E> extends AbstractSet<E>implements NavigableSet<E>, Cloneable, java.io.Serializable{// backing map 用于存储元素private transient NavigableMap<E,Object> m;TreeSet(NavigableMap<E, Object> m) { this.m = m; }public TreeSet() {// 使用TreeMap进行初始化this(new TreeMap<>());}public TreeSet(Comparator<? super E> comparator) {this(new TreeMap<>(comparator));}}
集合使用
Set
| 作用 | 返回值 | |
|---|---|---|
| boolean add(E e) | 添加元素 | - true,set 没有包含元素 e - false,set 中已经包含元素 e |
| boolean remove(Object o) | 删除元素 | - true,set 中包含 o - false,set 中不包含 o |
| boolean contains(Object o) | 判断是否包含元素 o | |
| boolean isEmpty() | ||
| int size() |
TreeSet
可以当作 Java 内置的平衡二叉树使用(虽然红黑树不是严格的平衡二叉树)
| 方法 | 介绍 |
|---|---|
| public E first() | 返回最小的元素 |
| public E last() | 返回最大的元素 |
| public E lower(E e) | 返回 < e 的最大元素 |
| public E higher(E e) | 返回 > e 的最小元素 |
| public E floor(E e) | 返回 <= e 的最大元素 |
| public E ceiling(E e) | 返回 >= e 的最小元素 |
| public E pollFirst() | 弹出最小元素 |
| public E pollLast() | 弹出最大元素 |
List
- add(E e) add(int index, E e)
- remove(E e) remove(int index)
- indexOf(Object o) lastIndexOf(Object o)
- contains(Object o)
Deque
单线程环境下用于用于替代 Stack,同时也可以作为 Queue 使用,非常灵活。
- void push(E e), E pop() 栈顶在第一个元素的栈操作
- offer(E e), E poll() 队首在第一个元素,队尾在最后一个元素
- addFirst(E e) addLast(E e)
- offerFirst(E e), offerLast(E e) 压入元素,返回成功与否的 boolean
- pollLast() pollFirst() 弹出元素,失败返回 null
- peekLast() peekFirst() 读取元素,失败返回 null
Queue
- boolean offer(E e),E poll() 队列的操作,尾部添加、头部删除
PriorityQueue
默认为小根堆,可以在构造的时候指定 Comparator
// 构造一个降序排序PriorityQueue<Integer> q = new PriorityQueue<>((i1, i2) -> {return -i1.compareTo(i2)});q.offer(e);e = q.poll();
Map
- isEmpty() size()
- containsKey(Object key)
- V get(Object key) V put(K key, V value) 返回 key 之前对应的值或 null
- V remove(Object key)
遍历
for (K key: map.KeySet()) {}for (Map.Entry<K, V> e: map.entrySet()) {}map.forEach((k, v) -> {});
常用技巧
基本类型的数组,转换成为 List
int[] arr = { 4, 3, 2, 5, 12, 2, 22, 13, 34, 50, 9 };List<Integer> list = Arrays.stream(arr).boxed().collect(Collectors.toList());
List 转换成基本类型数组
List<Integer> list;int[] arr = list.stream().mapToInt(Integer::intValue).toArray();
List 普通转换成数组
List<String> list;String[] arr = list.toArray(new String[list.size()]);
数字与 String 的转换
// 不同数字的包装类含有对应的 toString 方法,例如 IntegerString s = Integer.toString(12);// 数字的包装类同样有 parse 方法,例如 Integerint v = Integer.parseInt("123");

若有收获,就点个赞吧
0 人点赞
