基本数据类型
| 包装 | 注意事项 | |
|---|---|---|
| int | Integer | 一个整数 默认 就是 int 类型 |
| short | Short | |
| long | Long | 整数加上L/l可以表示 long 类型 |
| byte | Byte | java中没有 bit 这种类型,所以byte 是最小的单位 |
| char | Character | Java 中的 char 采用 unicode,所以长度为2个字节 |
| double | Double | java中的浮点数 默认就是double类型 ,仍可以选择加上后缀D/d |
| float | Float | 在小数后加上后缀F/f即可表示 float 类型 |
| boolean | Boolean | 最小的数据类型,长度为1位 |
OOP三大特性
1. 封装
利用抽象数据类型,将数据和基于数据的操作封装成一个不可分割的实体。数据尽可能的保留在抽象数据类型的内部,只对外边暴露接口。内部的逻辑细节对用户不可见,用户所见只有接口。
高内聚,低耦合:
- 容易维护,拓展。
- 可重用性高。
- 降低构建大型系统的风险。因为即使系统出问题,各个模块还能够工作。
2. 继承
继承实现了 IS-A 关系。
Java 只支持单继承,因为多继承时若不同父类有相同签名的方法会造成混乱;但是 Java 可以实现多个接口,因为接口本身是抽象没有具体内容的,所以多个接口的签名相同没关系。(Java 8 中接口支持实现 default 的方法,暂时不考虑)
3. 多态
多态是对同一个规范采用不同的实现方式,多态分为两种:
- 编译时多态:方法重载,同一个类中多个同名不同内容的方法
- 运行时多态:程序中定义的对象的引用所指向的具体类型在运行期间才确定。
编译时多态
方法重载只是改写方法参数类型、个数,修改 Access Level、返回值是非法的重载。
运行时多态
- 继承
- 重写:子类覆盖父类的同名方法
- 向上转型
动态绑定
运行时多态的主要体现,意思是方法的使用者类型在运行时才确定。注意只有普通方法有动态绑定,静态和final方法、字段没有动态绑定,字段是在编译期间就已经确定。
public class Test {public static void main(String[] args) throws IOException {Test testSub = new TestSub();System.out.println(testSub.f1); // 3 字段没有动态绑定,在编译期间确定,即由左侧修饰类型决定testSub.hello(); // TestSub 普通方法,运行时动态绑定}int f1 = 3;void hello() {System.out.println("Test");}}class TestSub extends Test {int f1 = 2;@Overridevoid hello() {System.out.println("TestSub");}}
向上转型
父类引用指向子类对象,子类对象以父类身份出现。调用普通方法动态绑定成子类的重写方法,访问字段访问父类身份的成员字段,调用 final 方法调用父类的 final 方法,调用 private 方法调用父类的 private 方法(private方法就是final类型的)。
向上转型是安全的,自动转型。因为父亲有的,儿子肯定有。
Father ref = new Son();
向下转型
子类引用指向父类对象,父类对象以子类身份出现,由于是非安全的,所以会在编译时就报错。但可以使用强制类型转换来强行引用,若没有完全确认安全不推荐这么做。
向下转型是不安全的,需强制转型。因为儿子有的,父亲不一定有,继承的目的就是为了在原有的模板上拓展。
总结
个人理解,多态就是一个规范存在多种具体的实现,使用者通过高层的这个规范动态地使用某一个具体实现。最终实例化是什么具体类,调用的就是什么具体类的方法。
由于多态是一种调用方法的概念,所以与字段无关,即直接访问对象字段的时候不存在多态的概念。
- 成员字段:编译时看左边(Father),运行时看左边(Father)。
- 成员普通方法:编译时看左边(Father),运行时看右边(Son)。
- final、静态方法:编译时看左边(Father),运行时看左边(Father)。
- 静态的方法和类相关,故不存在所谓的多态和动态绑定。
- 动态绑定(方法),就看当前的实现对象。
- 非动态绑定,就看当前出现的身份(定义的类)。
- 方法有多态,字段没多态。
字段关键字
Access Levels
| Modifier | class | Package | Subclass | World |
|---|---|---|---|---|
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| no modifier | Y | Y | N | N |
| private | Y | N | N | N |
static关键字
static标识的字段是属于类对象的,即是类的资源。一个类对象只在运行时按需由类加载器加载到JVM的方法区一次仅且一次,之后该类的所有实例对象都是以这个类对象为模板刻画出来。
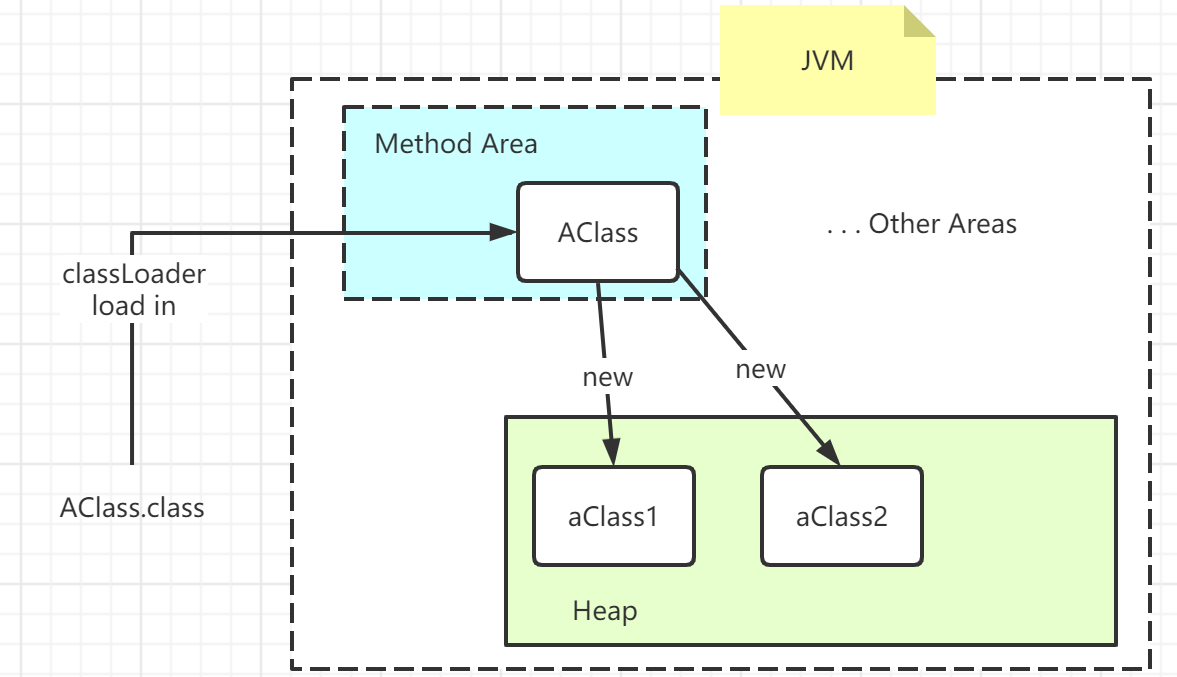
所以类的资源是该类所有实例共享的。下边这个简单的测试代码就可以印证:
public class TestStatic {public static int a = 0;public static void main(String[] args) {TestStatic test1 = new TestStatic();TestStatic test2 = new TestStatic();test1.a++;test2.a++;System.out.println(test1.a); // "2"}}
final关键字
本质
final关键字的本质是:修饰的变量的内存值不改变,所以对于普通数据类型值是不能改变的;而对于对象类型,由于变量存储的是引用,所以只要引用不变,对象本身的数据是可以改变的。
常量池对象复用
- final 是用于定义常量的, 定义常量的好处是: 不需要重复地创建相同的变量。 而常量池是Java的一项重要技术, 由final修饰的变量会在编译阶段放入到调用类的常量池中(方法区)。
final、static final
前边提到过final定义的常量会存储在方法区中的常量池,给对象复用;static变量本质上也是给多个类的实例复用。这两者的主要区别就是:
- static final定义的值从常量池复用,但可以直接通过类名访问,常用于工具类。
- final定义的值也是从常量池复用,但是只能通过实例对象访问。
内部类
字面意思,内部类就是定义在一个类内部的类。每一个技术的存在都会解决一部分问题产生一定的便利:
- 内部类可以实现对同一个包中的其他类的隐藏。
- 内部类可以补充Java单继承的缺陷。
- 内部类简化接口的实现。
内部类与外部类的交互
内部类对象可以访问其外部类对象的所有成员,因为一个内部类对象的创建必然是建立在一个外部类对象已经创建的基础上。当一个内部类对象被创建时就会隐式地捕获一个外部类对象的引用,之后在访问外部类对象成员的时候,实际上是自动隐式地通过该引用来访问。
- 内部类对象访问外部类对象:
外部类.this - 外部类对象创建内部类对象:
外部类对象.new 内部类()
public class Outer {class Inner {public Outer getOuter() { return Outer.this; } // 内部类获取外部类}public static void main(String[] args) {Outer outer = new Outer();// 那么 outer == outer.new Innter().getOuter()// 两者指向的对象完全一致}}
匿名类
很常见的一种内部类的使用方式就是new一个接口的对象 MyInterface inter = new MyInterface() { … }
匿名内部类是对在类中实现接口和实现继承的进一步简化的写法。正是因为内部类可以实现继承其他类,所以可以弥补Java的单继承限制。
- 内部类可以和接口配合使用,内部类实现接口,通过外部类提供外界访问的入口。
interface Contents {private int i = 0;public int value();}public class Parcel {public Contents getContents() { // 获取接口的一个实现实例return new Contents() { // 匿名内部类实现了一个接口int i = 11;@Overridepublic int value() { return i; }}}public static void main(String[] args) {Contents contents = new Parcel().getContents();}}
- 内部类继承某一个类,不需要再声明一个类名
extends,直接匿名构造
class Wrapping {private int i;public Wrapping(int i) { this.i = i; }public int value() { return this.i; }}public class Parcel {// 这里实际上实现了一个类继承Wrapping类// 使用的是父类的有参构造函数,// 接着通过父类的value()方法获取父类的私有字段重写方法。public Wrapping getWrapping(int x) {return new Wrapping(x) { // 一个继承了Wrapping 的内部类@Overridepublic int value() { return super.value() * 10; }}}// 以上写法等价于这样// 可以发现,其实这个类的名字根本没有必要出现!public Wrapping getWrapping(int x) {class In extends Wrapping {public In(int x) { super(x); }public int value() { return super.value() * 10; }}return new In(x);}public static void main(String[] args) {new Parcel().getWrap(47).value(); // 47 * 10 = 470}}
嵌套类/静态内部类
嵌套类就是 static 静态的内部类,属于类,不属于对象。可以用作编写内部的测试类,实现测试代码生成的类和本类分离,这样在之后项目整合的时候就可以直接将测试类生成的class文件抽离。
interface Contents { ... }class Wrapping { ... }public class Parcel {void f() { ... }public class Inner { ... }public Contents getContent() { return new Contents() { ... }; }public Wrapping getWrap(int x) { return new Wrapping(x) { ... }; }public static class Test {public static void main(String[] args) { ...Test }}}

内部类的内存泄漏风险
由于内部类始终持有其外部类的引用,所以如果当内部类一直被使用的时候,即使外部类没有被其他引用,外部类对象也不会被回收。
解决方法
若内部类不需要使用外部类的成员信息,则将内部类声明为静态内部类。
IO
三大模型

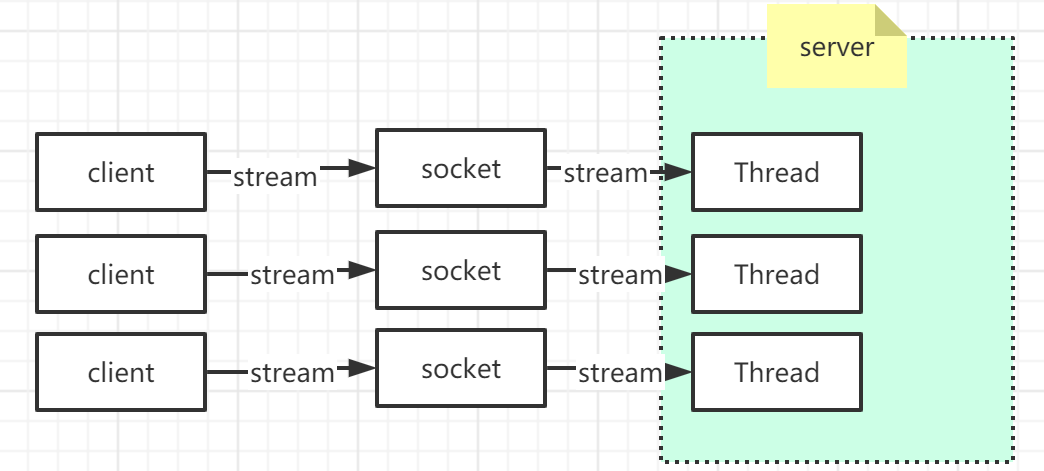
BIO
传统的同步阻塞式IO,面向字节流传输数据。这种情况下阻塞等待一个连接,连接成功则启动一个线程来处理连接。
比较明显的好处就是
- 实现简单;
- 以流的方式连续地传输数据,不会出现只收到部分数据的情况;
这种方式会有比较大的问题:
- 一个连接一个线程,在客户端很多的情况下,会导致线程的数量过多。
- 客户连接之后不一定有活动,就导致了许多不活跃的连接没有任何活动却占用着一个线程资源,资源的浪费严重。
// 创建线程池管理线程ExecutorService threadPool = new ThreadPoolExecutor(...);// 创建服务端套接字ServerSocket server = new ServerSocket(...);while (true) {Socket client = server.accept(); // accept() 方法一直阻塞直到有连接threadPool.execute(() -> { // 分配线程来服务连接handleConnection(client);})}
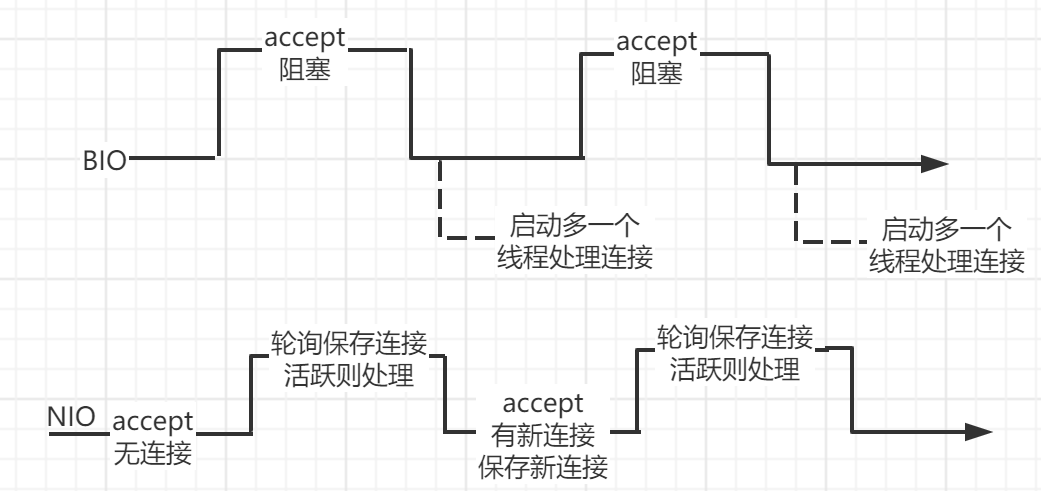
NIO
同步非阻塞式IO,面向数据块传输数据。在尝试连接的时候不再阻塞,没有连接则不管,进行下一次尝试;有连接,则将连接先保存起来。接着通过一个选择器,轮询保存的连接,选出有活动的连接,为这些连接提供服务。基本的过程如下:
- 创建服务端通道,创建活跃连接的选择器;
- 判断是否有新连接,连接成功,保存连接;
- 选择器轮询已经保存的所有连接,判断是否活跃,活跃则提供服务;这里将连接保存起来,反复访问就是IO多路复用。
三大重要组成模块
- Buffer
在非阻塞IO中的数据读写单位是数据数据块,数据块临时存储的位置就是Buffer。
- Channel
输入输出的通道,所有读写数据块的操作都要通过其来完成。
- Selector
IO事件的选择器。Selector通过注册IO通道来对IO通道上的事件进行监控,对活跃的IO事件做出反应。
代码实现
模拟版本:
try {ServerSocketChannel serverSocket = ServerSocketChannel.open(); // 创建通道serverSocket.bind(new InetSocketAddress(...));serverSocket.configureBlocking(false); // 设置非阻塞List<SocketChannel> socketChannelList = new LinkedList<>(); // 用于保存连接ByteBuffer buffer = ByteBuffer.allocate(1024); // 使用数据块进行传输数据int read;while (true) {SocketChannel socketChannel = serverSocket.accept(); // 非阻塞连接if (socketChannel != null) { // 成功连接,则保存连接socketChannel.configureBlocking(false);socketChannelList.add(socketChannel);}for (SocketChannel s : socketChannelList) { // 轮询所有保存的连接if ((read = s.read(buffer)) > 0) // 有读事件则进行处理,否则不管(也可以增加判断其他事件)readMesFrom(buffer);}}} catch (IOException e) {...}
使用API版本:
try (Selector selector = Selector.open();ServerSocketChannel serverChannel = ServerSocketChannel.open()) {serverChannel.bind(new InetSocketAddress(...));serverChannel.configureBlocking(false); // 设置管道非阻塞// 将server通道注册到选择器,server通道监听的的是 SelectionKey.OP_ACCEPT 事件// 当有事件发生,即有连接活跃的时候,selector.select()才会返回,否则轮询连接(阻塞)serverChannel.register(selector, SelectionKey.OP_ACCEPT);while (true) {selector.select(); // 轮询连接,选择有事件发生的连接Iterator<SelectionKey> iter = selector.selectedKeys().iterator();while (iter.hasNext()) {SelectionKey key = iter.next();iter.remove(); // 连接处理完后销毁,防止重复处理if (key.isAcceptable()) { // 服务端发生了连接事件SocketChannel clientChannel = serverChannel.accept();clientChannel.configureBlocking(false); // 设置管道非阻塞clientChannel.register(selector, SelectionKey.OP_READ); // 注册到选择器,监听读事件} else if (key.isReadable()) { // 来自客户端的连接发生消息输入事件doSomething(key);}}}} catch (IOException e) {...}
NIO2
异步IO就是指读写操作由操作系统来完成,程序只需要提供相应的参数和回调函数,操作系统处理完成后通知应用程序。这和JavaScript的执行思想非常类似,JavaScript经常通过通过提供回调函数来完成异步操作,进而实现复杂的任务处理功能。
基础IO操作
1、磁盘操作 File
File类可以用于表示文件和目录的信息,但是不能表示文件的内容。
// 递归地列出一个目录下的所有文件public void ListAllFiles(File dir) {if (dir == null || !dir.exists()) {return;}if (dir.isFile()) {System.out.println(dir.getName());return;}for (File f : dir.listFiles()) {listAllFiles(f);}}
2、字节操作 Stream
文件的复制demo
| function | explain |
|---|---|
| read(b, off, m) | b:存储读取内容的字节 buffer off:从b的哪一个偏移位置开始存储 m:最大的读取长度 |
| write(b, off, l) | b:存储内容的字节buffer off:从b的哪一个偏移位置开始读取 l:要读取的长度。 |
public static void copyFile(String s, String d) throws IOException {try (FileInputStream in = new FileInputStream(s);FileOutputStream out = new FileOutputStream(d)) {byte[] buffer = new byte[20 * 1024];int cnt;// read() 返回的是读取到的实际byte个数// 可以通过哦第三个参数来限制单次读取的最多字节数// 返回-1表示读取到EOFwhile ((cnt = in.read(buffer, 0, buffer.length)) != -1) {out.write(buffer, 0, cnt);}}}
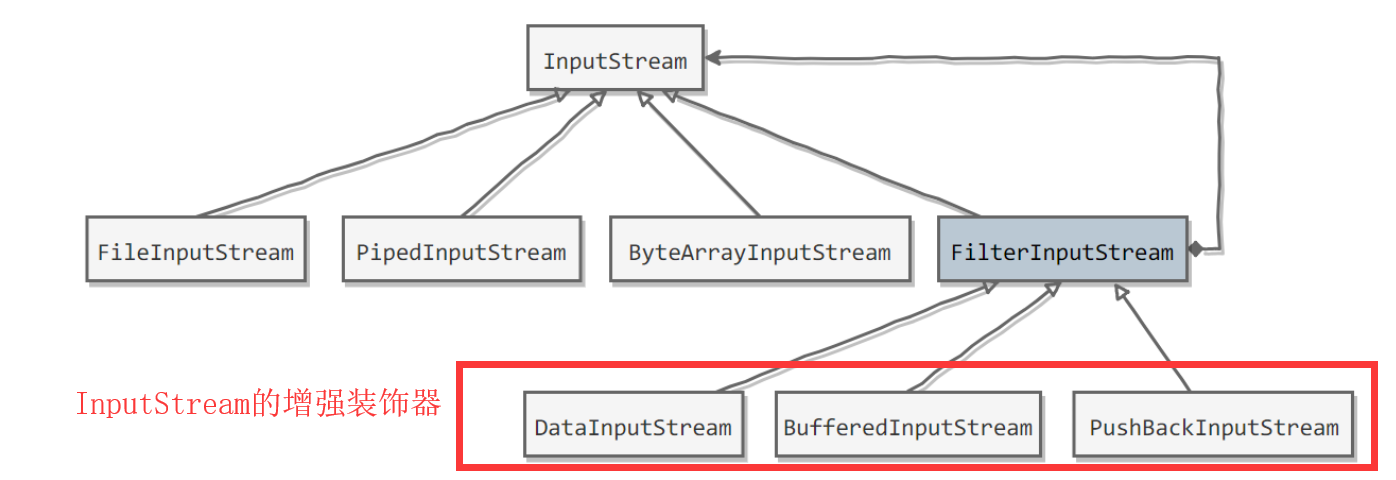
装饰器模式
Java I/O使用了装饰器模式来实现,装饰器模式本质就是使用聚合的方式来逐渐拓充被装饰者的功能。
public class FilterInputStream extends InputStream {/*** The input stream to be filtered.*/protected volatile InputStream in;}
3、字符操作
编码与解码
编码就是把字符转换为字节,而解码就是把字节重新组合成字符。
编码和解码时使用不同的规则,就会出现所谓的乱码现象。常见的编码规则如下:
- GBK,中文2byte,英文1byte;
- UTF-8,中文3byte,英文1byte;
- UTF-16be,中文英文都是2byte。
UTF-16be的be指的时Big Endian,就是大端法;相应的UTF-16le就是Little Endian的意思。
对比上边各种编码可以发现,使用UTF-16对于中文和英文是最统一的,所以 Java 的内存编码使用双字节编码UTF-16be。
String编码方式
String s = "我是Beney";byte[] bytes = s.getBytes(StandardCharsets.UTF_8); // 编码 字符 -> 字节String s2 = new String(bytes, StandardCharsets.UTF_8) // 解码 字节 -> 字符.intern(); // 复用常量池的String对象System.out.println(s2);
在调用无参getBytes()的时候,默认编码不是UTF-16be,而是使用当前平台的默认编码。因为双字节编码的好处是统一用一个char来存储中文和英文,而程序运行过程中String与byte[]的转换不需要这种好处。
Reader 与 Writer 操作字符
无论是磁盘还是网络哦,最小的存储传输单元都是字节,而不是字符。但是在程序的操作中,往往需要使用字符这种人可阅读的方式来进行。因此JDK提供了对字符进行操作的途径。
- InputStreamReader:实现字节流解码成字符流;
- OutputStreamWriter:实现字符流编码成字节流。
- BufferedReader/BufferWriter:原理同上,但是使用了Buffer后的主要不同是数据会先缓存到Buffer中,只有Buffer塞满或者是主动调用flush方法才会将数据从Buffer中输出!
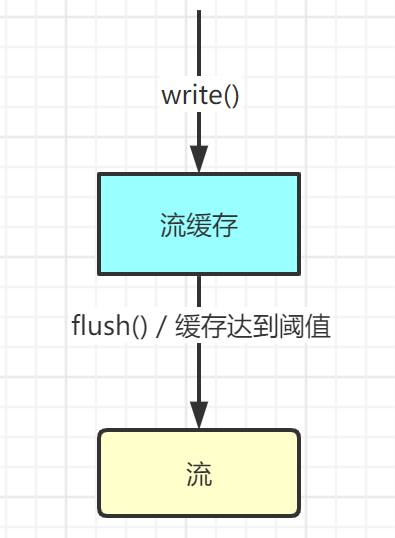
public static void readFileContent(String filePath) throws IOException {try (FileReader fileReader = new FileReader(filePath);BufferedReader br = new BufferedReader(fileReader)) { // 使用缓冲提高效率String line; // reader 是字符操作,使用 string 来存储while ((line = br.readLine()) != null) {System.out.println(line);}}}
4、对象IO
序列化
序列化就是将对象转换成字节序列,用于存储传输。
- 序列化:ObjectOutputStream.writeObject(),对象->字节;
- 反序列化:ObjectInputStream.readObject(),字节->对象。
Serializable 接口
实现了Serializable的类对象才能够进行序列化,否则会报异常。
public class TestSerialize implements Serializable {private int x;private String y;public TestSerialize(int x, String y) {this.x = x;this.y = y;}@Overridepublic String toString() {return "x = " + x + ", y = " + y;}}public class TestMain {public static void main(String[] args) throws IOException, ClassNotFoundException {TestSerialize obj = new TestSerialize(10, "Beney");String fp = "src/main/java/storage";try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(fp))) {oos.writeObject(obj);}try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(fp))) {TestSerialize o = (TestSerialize) ois.readObject();System.out.println(o);}}}
transient
使用transient关键字标记的属性值在序列化的时候不会保留,只保留其默认零值。
ArrayList中的elementData就用了transient标记,因为elementData是变长的,所以在序列化的时候会有冗余的空间,故ArrayList重写了writeObject方法来输出只存储了内容的空间。
transient Object[] elementData;private void writeObject(java.io.ObjectOutputStream s)throws java.io.IOException{...// Write out size as capacity for behavioural compatibility with clone()s.writeInt(size);// Write out all elements in the proper order.for (int i=0; i<size; i++) {s.writeObject(elementData[i]);}...}
5、网络IO
Java网络中的重要元素:
- InetAddress:用于标识网络硬件资源,即IP地址;
- URL:统一资源定位符;
- Socket:TCP通信数据传输的出入口;
- Datagram:UDP通信的数据包。
InetAddress
只能通过静态方法来构建
InetAddress.getByAddress(String host, byte[] addr);InetAddress.getByAddress(byte[] addr);InetAddress.getByName(String host);InetAddress addr = InetAddress.getByAddress("localhost", new byte[] { 127, 0, 0, 1 });
URL
直接从URL中读取字节内容。
public static void main(String[] args) throws IOException {URL url = new URL("https://www.baidu.com");InputStream is = url.openStream();InputStreamReader isr = new InputStreamReader(is, StandardCharsets.UTF_8);BufferedReader br = new BufferedReader(sr);String line;while ((line = br.readLine()) != null) {System.out.println(line);}br.close(); // 装饰器模式,调用最外层,内层会依次调用}
Socket
- ServerSocket:服务器端
- Socket:客户端
- 在BIO模式下,服务器和客户通过InputStream和OutputStream进行读入输出。
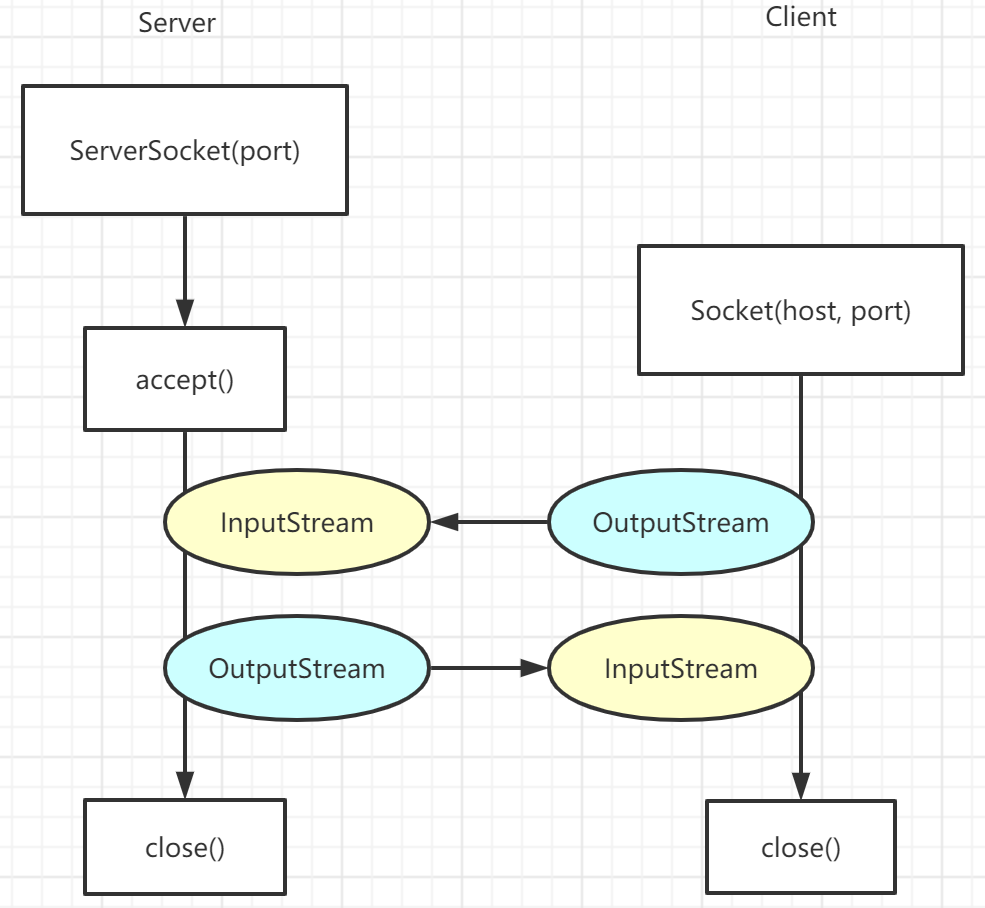
Socket 编程的基本思路:
- Server
- 创建 server socket
- socket 绑定端口,开始监听
- 接收到连接,则进行 read -> 业务处理 -> write
- Client
- 创建 socket
- socket 连接到 (ip, port)
- 成功连接后,进行 write -> read
Datagram
用于 UDP 通信编程。UDP 和 TCP 编程类似,都是在 receive() 方法的时候会出现阻塞
- DatagramSocket:通信出入口
- DatagramPacket:数据包
反射
反射用一句话来解释就是,通过实例对象反向得到其元信息,例如类型、方法、字段等。
工作原理
在运行时,通过解析class文件加载类对象,进而获得类的所有信息(包括方法,字段,注解,泛型……)。 一句话:正向是类创建实例,反射就是通过实例获取类的信息
解决的问题:在运行期,对某个实例一无所知的情况下调用其方法。
每一个类都有一个Class对象,包含了类的模板数据,当我们new了一个对象后,对象的数据信息主要存储在Java堆,而其行为方法则由方法区中的Class对象管理。
在new一个对象的时候,JVM会先检查这个类对应的Class对象,有这个Class对象则对应创建我们的对象;若没有Class对象则会到外存查找.class文件,通过类加载器加载进入元空间创建Class对象。即某个类的Class对象只会在整个运行期间加载一次。
由于Java有多态性,即其运行时的类型有时不能够通过编译期确定,反射机制可以实现对象的运行时检查,并且可以通过反射调用任意对象的任意方法。一般是通过Class类中的方法和java.lang.reflect类库中的类型进行实现。
java.lang.reflect类库中主要包含以下三类:
- Field:字段相关,可以通过
get(),set()方法修改Field对象相关的字段。 - Method: 方法相关,可以通过
invoke(绑定某个对象)方法调用。 - Constructor: 可以使用Constructor关联到的对象构造方法创建对象。
优缺点总结
优点:
- 灵活。能够动态地创建类对象。
缺点:
- 性能开销大。反射涉及到了动态类型的检查,所以JVM很难对这些代码进行优化。因此反射操作效率会比普通的操作效率低。所以要避免在经常被执行的代码或者对性能要求很高的程序中使用反射。
- 安全问题。反射允许代码执行一些正常情况下不允许的操作,例如访问私有属性和方法,所以使用反射可能会导致意料之外的副作用。
应用
IOC
Inversion Of Control,控制反转的意思是:将创建对象的控制权由用户转移到别处,使得用户不直接通过new关键字来创建对象,降低耦合度。这种思想的常见实现有三种:
- setter DI,通过setter依赖注入,获得对象。
- constructor DI,通过构造器传参注入,获得对象。
反射。相当于把对象的创建控制权交给JVM,JVM在运行时通过解析class文件加载相应的类,然后创建一个对象返回给用户。
/*** 工厂模式创建实例*/public class VehicleFactory {public static IVehicle createIVehicle(String name) {try {return (IVehicle) Class.forName(name).getConstructor().newInstance();} catch (Exception e) {e.printStackTrace();}return null;}}
动态代理
proxy无需实现interface,目标对象聚合到proxy后,proxy使用反射来动态调用其方法。
注解
基本概念
- Annotation对程序做出解释,可以被编译器读取。
- 出现形式:
@注解名,@注解名(参数)。
内置注解
@Override:表明重写方法。@Deprecated:表明当前的元素不推荐使用,可以有更好的替代。SuppressWarnings(参数):抑制警告信息。
元注解
用于注解注解的注解。
@Target:用于描述注解的使用范围。@Retention:表示要在什么级别保存该注释信息,注解的生命周期。(RUNTIME > CLASS > SOURCE)- runtime:注解从源码到运行时一直存在。
- class:注解只保留到class文件为止,运行时被遗弃(默认生命周期)。
- source:注解只在源码保留,编译成class文件后就被遗弃。
@Documented:包含在文档中。@Inherited:子类能够继承父类的注解。
// Target 注解的作用目标// Retention 有效的时期,一般都是运行期有效// Documented 表示是否生成在文档doc中// Inherited 注解可继承,即子类继承父类的时候,注解也被传递下去// 当只有一个参数,推荐命名为value,这样就可以省略 value=@Target(value = {ElementType.METHOD, ElementType.TYPE})@Retention(value = RetentionPolicy.RUNTIME)@Inheritedpublic @interface MyAnnotation {// 注解的参数!并不是方法,可以有默认值// 参数类型 参数名()String value() default "";}
异常
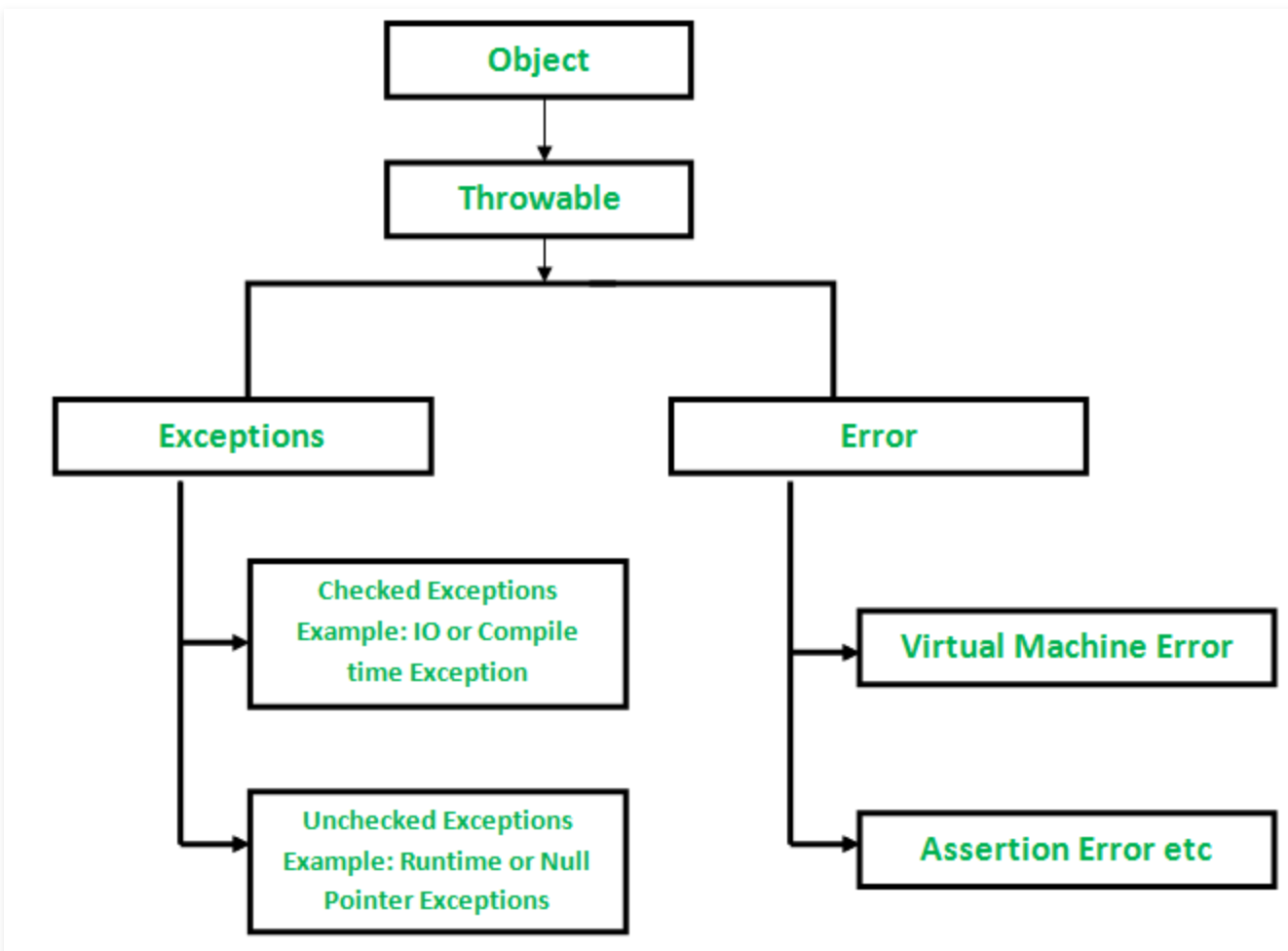
错误和异常的异同
两者都是Throwable的子类,是其两大分支。
- 错误:错误是指程序在运行期间出现的严重问题,不建议进行捕获处理,而是直接终止程序。
错误一般由JVM来抛出,一般是跟JRE相关的错误,例如OOM,所以。可以说设计者一般抛出的是异常而JVM抛出的一般是错误。 - 异常:异常也是程序出现的问题,但是推荐处理的。
两大类异常
- 受检异常。在编译阶段就能够检测出的异常,编译器会要求强制进行捕获或者抛出处理。通常由编程者根据逻辑判断主动抛出。
- 非受检异常。在运行期间出现的异常,这种异常的出现往往就是程序设计的错误。
异常处理
原理
异常的默认处理机制就是根据调用栈一级级往上抛,直到匹配到对应类型的处理代码。
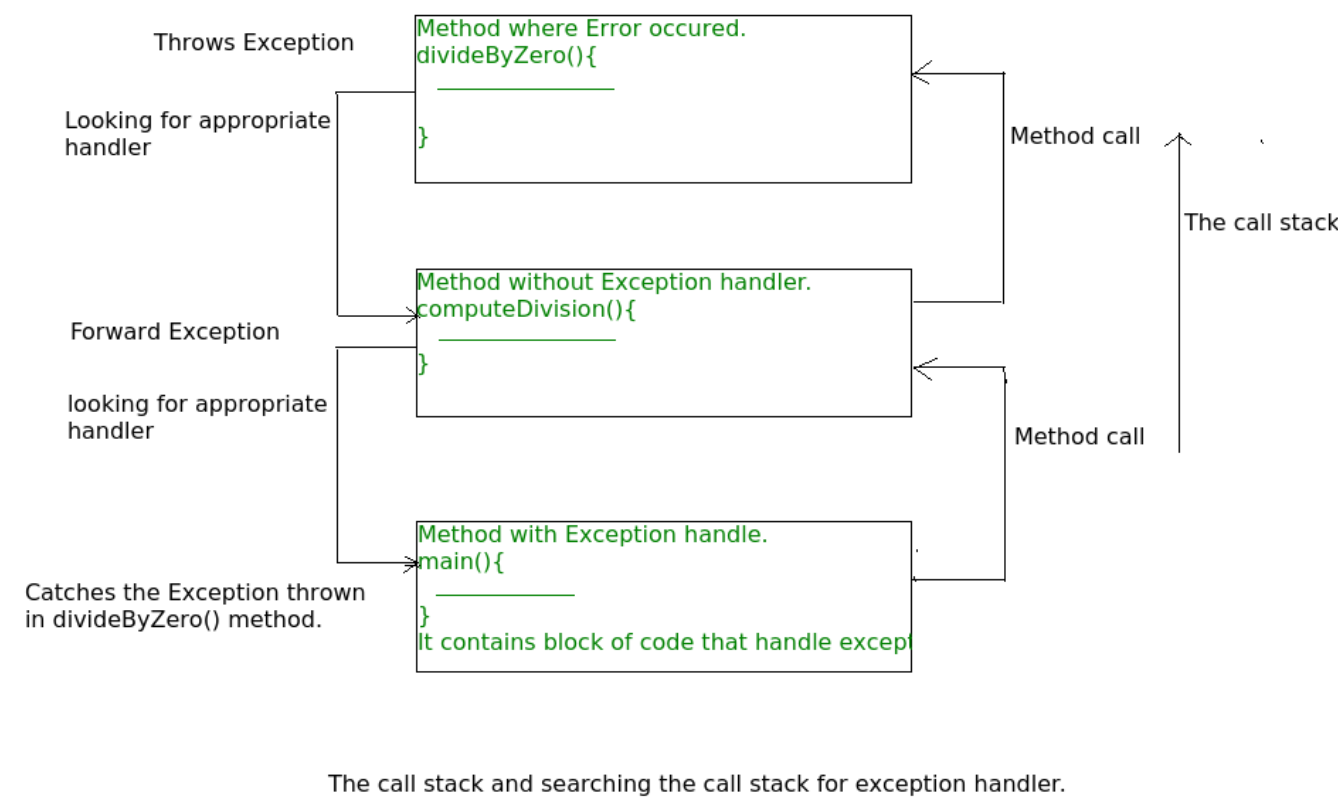
方法
- 方法名中
throws抛出异常的类型给调用者处理。 - 方法内利用
throw抛出异常的对象给调用者处理。 - 方法内
try-catch-finally内部进行异常的处理。其中finally是可选字段,因为当异常发生后,所在代码之后的语句就不会在执行了,但是有一些重要的操作往往不能够忽略,例如空间的释放等。所以这类重要的收尾操作就可以放到fianlly语句块中,这样无论异常与否都会执行。 try-with-resouce可以方便地使用需要用完则关闭的资源,其可以保证资源在代码块执行完成后被关闭,无需再编写finally代码块。Any object that implements
java.lang.AutoCloseable, which includes all objects which implementjava.io.Closeable, can be used as a resource.
try (Scanner sc = new Scanner(System.in)) {while (sc.hasNext()) {freq[sc.nextByte()] += 1;}}
泛型
将类型参数化。
why-好处
泛型的出现就是为了适应面向对象的多态特性,以往没有出现泛型的时候是使用Object来达到运运行时的类型的泛化,但是我们知道向下转型是不安全的,而且Object定义的容器无法在编译期检查容器存储的元素类型是否符合预期。为此,出现了泛型,在实例化时指定类型,使得编译时能过够检查类型是否符合预期。
稍加注意:由于具体的类型在实例化才能够确定,非泛型的static方法是不能够访问泛型的参数的。
泛型原理
在泛型代码的内部,我们实际上是无法获取任何有关类型的信息。而当泛型的类型实例化的时候,编译器在编译时使用一种类型擦除的技术,将泛化的类型统一替换成:
- Object,若泛型没有设定界限
- 或者是泛型的设定的上限
public class Node<T> {private T data;...}// 类型擦除后public class Node {private Object data;}
public class Node<T extends Comparable<T>> {private T data;}// 类型擦除后public class Node {private Comparable data;}
故有如下的等式:
new ArrayList<String>().getClass()== new ArrayList<Integer>().getClass()== ArrayList.class// 类对象整个运行期间只会加载一次,所以必然是相同的。
泛型方法
泛型为参数的方法是不存在重载的,因为泛型方法的参数本身的类型在擦除后就统一了。
泛型的使用
边界
在泛型技术中,可以使用通配符 ? 来表示一种未知类型,也可以使用英文字母表示类型。
| <?> | 无界通配符,表示从 Object 开始往下的所有类型都可以指定 |
|---|---|
| <? extends X & IA & IB> | 指定上界为实现了 IA、IB 接口的 X 类 |
| <? super X> | 指定了下界为 X 类 |
约定
E元素,K键、N数字、T类型、V值、R返回值。
对象初始化
当我门创建某个对象 new ClassName(), 或者是访问某个类的静态方法 ClassName.staticFields 的时候就需要初始化一个类。 先字段,后方法
首先要初始对象必然是要程序先运行起来,所以从main()所在的类开始进行初始化。所以一开始是先去寻找main函数所在类。
Step1 寻找类对象
先去方法区寻找是否有对应的Class对象,有则根据Class对象跳到step2加载类资源;否则,Java 解释器去寻找类的路径,从外存找到编译好的 .class 文件,通过类加载器加载到JVM方法区创建一次仅且一次Class对象。若有父类则先定位父类的 .class 文件。
Step2 加载类资源
这里的类资源就是指类中的静态方法、静态变量,这些种资源属于类不属于特定的实例对象,只在类首次加载的时候初始一次,存放在 JVM 的方法区(静态区)。
Step3 实例化对象
- 先来到构造函数,分配堆空间,属性/方法设置默认值。
- 检查是否有父类,有父类就先运行父类的构造函数。
- 初始化实例的字段。
- 执行构造函数内部的操作。
有父类的情况再强调
在找出子类的class文件后通过extends关键字发现,它有父类,那么就先加载父类的静态资源,接在结束之后再加载子类的静态资源。
加载子类的资源时实际上就进入了main函数了,遇到new Son()的语句时,找到构造函数先为Son分配相应的存储空间、创建字段赋默认值,接着先执行隐含的super(),即前往父类的构造函数,完成父类的字段/方法构造后,再开始的子类的字段/方法初始,最后执行构造函数中的语句。
简而言之:父类加载资源
子类加载资源
对象实例化(父类成员(字段、方法) > 父类构造器 > 子类成员 > 子类构造器) 加载父类 加载子类 实例父类对象 实例子类对象
class Shape {/*** 8. 初始创建好的字段方法*/private int field = printInit("@Father Field");private void method() {}/*** 7. 构造对象(实例化) 创建字段、方法* 完成后发现自己已经是祖宗了(其实往上还有 Object,但这里忽略)*/Shape() {/** 9. 执行构造函数中的语句 */System.out.println("@Father Constructor: i = " + i + ", j = " + j);j = 5;}/*** 2. 顺序加载父类的资源 注意由于赋值是右边赋值给左边,所以实际上是 printInit 先加载完毕*/private static int i;protected static int j = 10;private static int x1 =printInit("@Father Static Source: private Shape.x1 initialized Static Source");static int printInit(String s) {System.out.println(s);return ++i;}}public class Circle extends Shape {/** 10. 初始化字段和方法 */int k = printInit("@Son Field: Circle.k initialized");/*** 6. 进入构造函数,开始创建对象(实例化)* 分配存储空间 -> 创建字段和方法(还没有赋值,但已经存在) 先执行 super() 父类的构造*/public Circle() {/** 11. 执行构造函数中的语句 */System.out.println("@Son Constructor: k = " + k);System.out.println("j = " + j);System.out.println("x2 = " + x2);}/*** 3. 父类的资源加载完后,子类加载资源* 类的资源就是静态资源,对象的资源就是普通字段/方法 main 函数也是静态资源!*/public static int x2 = printInit("@Son Static Source: public Circle.x2 initialized Static Sourcce");/*** 1. 要加载 main 函数(子类的static资源)就要先加载 Circle.class* 发现有父类 Shape,所以先加载 Shape.class*/public static void main(String[] args) {/** 4. 执行 main 函数 */System.out.println("@Son Static Source: main method");/** 5. 遇到 new Circle() 要调用构造函数 */Circle b = new Circle();/** 12. b 对象构造完成继续下一条语句 */System.out.println("@Keep Going in main: b.k=" + b.k);}}/*@Father Static Source: private Shape.x1 initialized Static Source@Son Static Source: public Circle.x2 initialized Static Sourcce@Son Static Source: main method@Father Field@Father Constructor: i = 3, j = 10@Son Field: Circle.k initialized@Son Constructor: k = 4j = 5x2 = 2@Keep Going in main: b.k=4*/
抽象类、接口
接口
接口是对行为的抽象,往往是抽象方法的集合,达到定义规范和实现细节的分离。
注意点:
- 接口不能实例化,除非实现了所有方法;
- 接口中的字段必须且默认是
public、static、final; - 方法默认都是
**public**的; static方法、default方法、private方法需要实现,**public**方法只能定义;
抽象类
抽象类同样是不能实例化的类,其构造器只能在子类的构造器中以super的形式调用,通常是抽取多个相关联的类中共用的方法实现,或是共同成员变量,主要目的是代码的复用。
注意点:
- 可以没有抽象方法;
- 抽象方法的类型不能是private
- 继承其的非抽象类,必须实现所有的抽象方法;
- 其余和普通类一样,可以有各种类型的字段、方法;
异同对比
同:
- 抽象类和方法都是一种规范,不能够直接实例化。
不同:
- 抽象类更接近普通类,可以有各种类型的字段方法,实现各个有一定关联类共性的抽取;接口则更偏向于一种更加广泛的行为的定义。
- 抽象类由于可以实现多种的方法、字段,且通过继承来进行复用,所以类之间的耦合度更高;
接口则更加灵活,通过implements实现其定义的行为,类的耦合度较小。
枚举 enum
枚举类型常用于定义一组有限个且确定的对象常量,其值在编译期就确定,之后固定不变。
重要注意点
- 枚举类型本质使用类实现的,继承自java.lang.Enum。
- 其中的
toString()方法已经由Enum类重写,为对象的名字。 - 每一个枚举对象,实际上是
public static final的,故在类加载的时候就完成初始化,即在枚举类加载的时候,其中的枚举对象就调用构造函数完成初始化。 - 所以枚举对象的实例化是线程安全的。故当枚举类中只有一个对象的时候,可以用作线程安全的单例模式。
// 1.5 之后使用关键字enum(推荐使用)// 字段默认就是 public static final,无需要显示写出enum Season2 {// 提供当前枚举类的对象// 多个对象之间逗号隔开,末尾;结束SPRING("春天", "春暖花开"),SUMMER("夏天", "夏日炎炎");// 每一个对象中的属性private final String seasonName;private final String seasonDesc;// 构造器私有化private Season2(String seasonName, String seasonDesc) {this.seasonName = seasonName;this.seasonDesc = seasonDesc;}public String getSeasonName() {return seasonName;}public String getSeasonDesc() {return seasonDesc;}}
enum关键字的本质(也是1.5之前的写法)
class Season {// 1. 声明Season对象属性 private finalprivate final String seasonName; // 确定的!使用finalprivate final String seasonDesc;// 2. 私有化构造器private Season(String seasonName, String seasonDesc) {this.seasonName = seasonName;this.seasonDesc = seasonDesc;}// 3. 提供当前枚举类的多个对象public static final Season SPRING = new Season("春天", "春暖花开");public static final Season SUMMER = new Season("夏天", "夏日炎炎");// 4. 其他诉求:获取枚举类对象的属性public String getSeasonName() {return seasonName;}public String getSeasonDesc() {return seasonDesc;}@Overridepublic String toString() {return "Season{" +"seasonName='" + seasonName + '\'' +", seasonDesc='" + seasonDesc + '\'' +'}';}}
进阶操作
枚举类和其他普通类一样可以实现接口,特别之处在于其中的每一个枚举对象可以单独实现自己的接口
interface Info {void show();}enum School implements Info {MIT {@Overridepublic void show() {System.out.println("**** MIT ****");}},CMU {@Overridepublic void show() {System.out.println("---- CMU ----");}}}
Enum的重要方法
| 方法 | 作用 |
|---|---|
| values() | 获取枚举类中的所有对象,数组形式 |
| valueOf(String name) | 通过变量名索引枚举类中的一个 对象 。失败则抛出异常。 |
| toString() | 默认输出枚举 对象名字 |
String家族
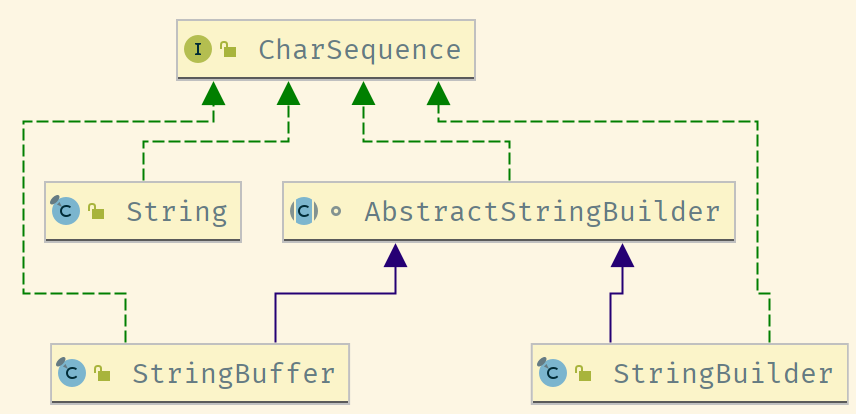
String概览
String被声明成final class,所以String是一种不可变类,不可被继承。大部分的属性也都是final的。
所以对于字符串的拼接、裁剪等操作都会产生一个新的String对象。
Java8中,String 内部使用char数组存储数据。
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {private final char value[];}
Java 9之后,String改用byte数组存储字符串,同时使用coder来标识使用了哪一种编码。
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {@Stableprivate final byte[] value;private final byte coder;
String不可变的好处
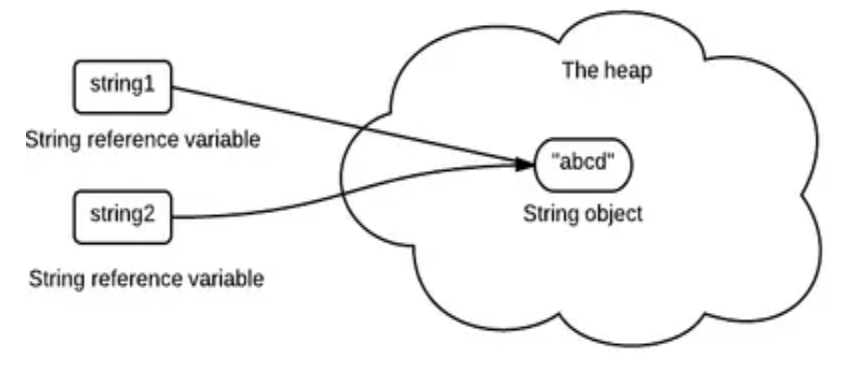
1、String池需要
String intern Pool 是方法区常量池中的一个存储区域,用于复用内容相一致的 String 对象。为了保证常量池中的String 对象内容不被其中一个引用修改而影响其他的引用,String 需要不可变。
String a = "abcd";String b = "abcd";
2、缓存hash值
String 的 hash 值常常被使用,例如 HashMap、HashSet 中常使用 String 作为 Key。那么 String 不可变就使得 hash 值能够被缓存复用,无需要在每一次使用的时候重新计算,提高了效率。
所以在 String 类中,还定义了一个字段 hash 用来存储 hash 值。
/** Cache the hash code for the string */private int hash; // Default to 0
3、安全性
String常常用作其他操作的参数,例如网络连接、文件路径、反射等。那么String的不可变性就可以保证这些操作的安全。
4、线程安全
线程间可以共享,减少了同步操作。
“” 和使用构造器的区别
- 使用 “” 进行创建则可以复用 String 常量池的对象。
- 使用构造器有两个步骤
- 创建一个新的 String 对象
- 将其字面量存入String Pool 中。
就如下例,传入的参数 “abc” 实际上就是一个字符串字面量,所以存入 String Pool 中;而 new 则会在堆上创建一个新的对象。通过 javap -verbose 可以看到常量池中的信息。
String s = new String("abc");
Constant pool:...#22 = NameAndType #7:#8 // "<init>":()V#23 = Utf8 java/lang/String#24 = Utf8 abc // abc存到了常量池中...
String Pool
字符串常量池保存着所有字符串的字面量(literal strings),所以只要两个 String 的字面量相同,就算是同一个对象,其 intern 方法获得到的 String 也是同一个对象。
intern 方法作用就是显式从字符串常量池中获取字面量一样的 String 对象(没有则创建后存储到 String Pool 然后返回)。
String s = new String("1"); // new 先在堆上创建一个新的对象,再将字面量存储到常量池中String s1 = s.intern(); // 从常量池中获取对象,没有则在常量池创建对象String s2 = "1"; // 取来Pool中的stringSystem.out.println(s == s2); // falseSystem.out.println(s1 == s2); // trueString s3 = new String("a") + new String("a"); // 常量池中存有了 "a" 但是并没有 "aa"// 因为并没有 "aa" 这个字面量s3.intern(); // 尝试从常量池中获取 s3 的字面量,没有则创建String s4 = "aa"; // 优先从String Pool中获取System.out.println(s3 == s4); // true
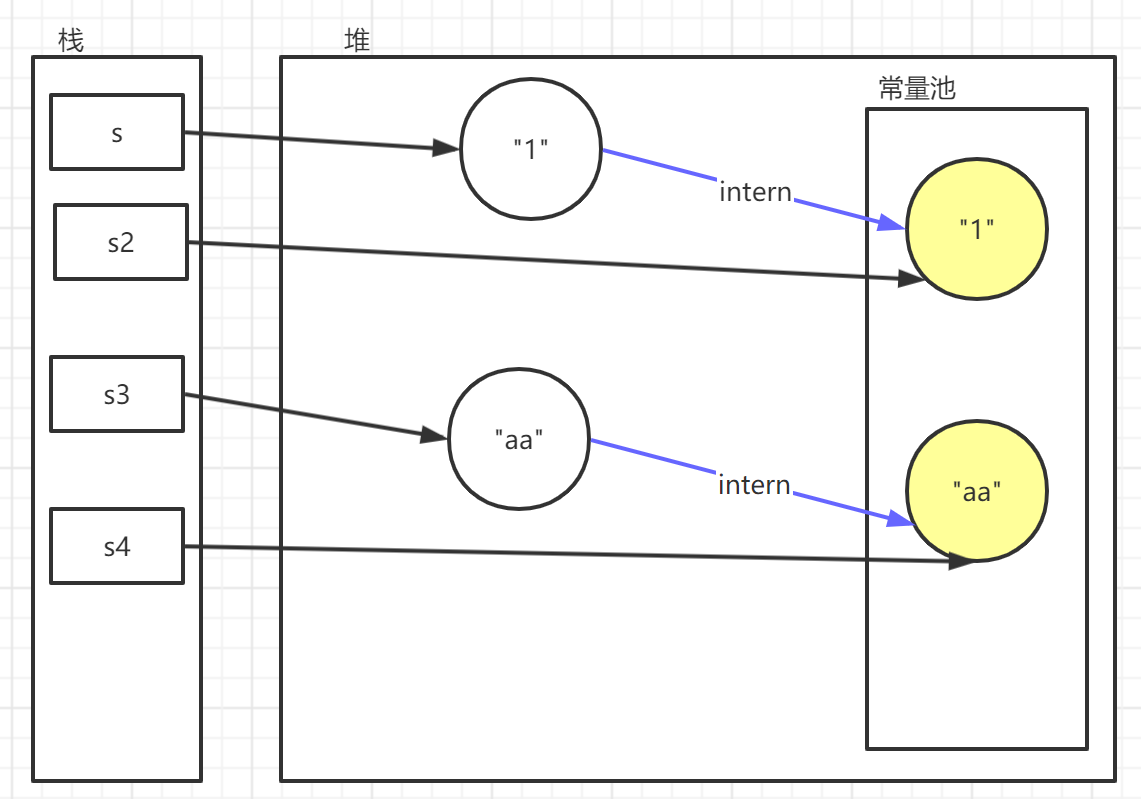
String s = new String("1") + new String("1"); // string pool 中只有 "1", 还未出现 "11" 字面量String s1 = "11"; // stirng pool 中新增了 "11"System.out.println(s == s1); // false
可变Builder、Buffer
String是不可变的,所以一旦涉及到字符串的操作就要想到使用StringBuilder,多线程环境下使用StringBuffer。
StringBuffer就是为了解决操作String的时候产生过多的拼接对象而产生的类,是线程安全的,因为其对外的操作方法都加synchronized关键字,但也正因如此带来了同步互斥操作的开销。
public synchronized StringBuffer append(StringBuffer sb) {toStringCache = null;super.append(sb);return this;}
StringBuilder是Java1.5中新增的,操作上和StringBuffer没有太大区别,只是去掉了线程安全的部分,减小了同步互斥的开销。大部分情况下使用StringBuilder是比较高效的。
@Override@HotSpotIntrinsicCandidatepublic StringBuilder append(char c) {super.append(c);return this;}
Builder的基本操作
增
append(字面量):末尾添加元素,字面量可以是int、float等类型。
sb.append(23.4); // "23.4"
insert(offset, 字面量):插入元素;
删
- deleteCharAt(index):删除元素;
- delete(st, en):范围删除;
改
- reverse():原builder上进行反转。
- replace(st, en, string):范围替换。
- setCharAt(index, char):更改某个字符。
查
- indexOf(string)/lastIndexOf(string):查找字符串。
- charAt(index):查找index处的字符
- substring(st, en):获取子串。
正则表达式
import java.util.regex.Pattern 正则表达式的规则
Java 中使用标准的字符串构造正则表达式,使用 Pattern.compile(String s) 将字符串编译成一个匹配器,之后就可以使用匹配器来正则检验字符串。
String s = "^[0-9]{1,4}$"; // ^ $ 分别匹配字符串的开始、结束Pattern p = Pattern.compile(s);String e = "123"; // 要检验的字符串if (p.matcher(e).matches()) {// match} else {// unmatch}
在其他语言中,\ 表示:我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给它任何特殊的意义。
在 Java 中,\ 表示:我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如 Perl),一个反斜杠 \ 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 \ 代表其他语言中的一个 \,这也就是为什么表示一位数字的正则表达式是 \d,而表示一个普通的反斜杠是 \。
常用 API
| 方法 | 参数/返回值说明 |
|---|---|
| String[] split(String regex, int limit) | - limit 默认值为0,表明忽略长度为0的段; - limit=-1 则不会忽略长度为0的段 |
| toUpperCase(), toLowerCase() | 返回新的大小写字符串 |
| toCharArray() | |
| indexOf(xxx) | 返回第一次出现字面量的位置,-1说明没有查找到 |
| contains(“xxx”) | 是否包含某个字符串 |
| replace(target, replacement) | 批量替换字符串中的某些字串,返回新的字符串 |
| substring(begin, end?) |
Object
一切对象的父类。
equals & hashCode
public boolean equals(Object obj) {return (this == obj);}public native int hashCode();
为什么将这两个放在一起说呢?因为这两个方法常常需要同时重写,为了使得当前类能够正确作为 HashMap 的 Key 值。
从源码可以知道,equals 默认就是比较两个对象的引用是否一致;hashCode 是本地方法根据对象的地址转换得到。在 HashMap 比较 Key 的时候就同时使用了这两个方法,所以为了保证两个值相同的不同对象能够正确被看作是相同的 Key,需要同时重写这两个方法。
if (e.hash == hash && // 比较 hash 值((k = e.key) == key || (key != null && key.equals(k)))) // 比较 keybreak;

若有收获,就点个赞吧
0 人点赞
