环境安装
- $GOROOT 是 go 的安装路径
- $GOPATH 是自己使用 go 进行开发的工作路径
- $GOPATH/bin 是存放 go install 下载的依赖包
Mac
注意,brew 工具依赖于 ruby,所以要提前安装好 ruby 环境再进行 brew 工具的安装。 使用 brew 或者 wget 工具安装 Go,。安装完之后解压到一个自己喜欢的目录(该目录之后就是GOROOT), vi ~/.zshrc 更改环境变量,添加export GOROOT=go安装路径export GOPATH=自己定一个GOPATHexport PATH=$PATH:$GOROOT/bin:$GOPATH/bin
Linux
使用 brew 或者 wget 命令下载好 go 之后,解压到一个自己喜欢的目录(该目录之后就作为 GOROOT了)。接着设置环境变量,vi $HOME/.profile,添加export GOROOT=go安装路径export GOPATH=自己定一个GOAPTHepoxrt PATH=$PATH:$GOROOT/bin:$GOPATH/bin
module 相关
全局开启 module 的时候,创建项目无需受 $GOPATH/src 格式的约束,参数如下go env -w GO111MODULE=on # 全局启用 module,无需 $GOPATH/src 格式的束缚# auto 默认值,在 $GOPATH/src 中不开启 module# off 关闭 module 模式
变量导出
方法名开头大写,则方法为导出方法;否则方法为包内私有
module 依赖
不同模块的依赖:
- 本地未发布模块```go module hello
go 1.14
// 使用关键字 replace, go build 之后,会使用本地路径来引用模块 replace example.com/greetings => ../greetings
- 已发布的包```gorequire example.com/greetings v1.1.0
执行
func init() {...}
go 会在全局变量初始化完后,执行 init() 函数
Basic
变量声明
方法内部,可以使用 := 的简版声明变量方式,可以由编译器自动推断类型;在方法外,每一个声明都必须使用关键字(var func),不能使用简版声明方式
数据类型
基本类型
boolstringint int8 int16 int32 int64uint uint8 uint16 uint32 uint64 uintptrbyte // alias for uint8rune // alias for int32// represents a Unicode code pointfloat32 float64complex64 complex128
零值
0,数值类型false,布尔类型"",string类型nil,指针类型
对于 struct 结构体而言,其默认零值就是一个可访问的结构体,其所有字段都其默认零值。
类型转换
- 显式类型转换,
T(x)
常量
使用 const 关键字声明,不能够使用 := 的方式创建
指针
基本同 C 语言,但是 Go 没有指针运算,即指针仅用于索引内存的值
func main() {arr := [...]int{1,2,3,4}p := &arr// fmt.Println(*p) // [1 2 3 4]fmt.Println(*(p + 1)) // 报错!}
结构体 struct
和 C 语言基本一致,区别在于结构体指针 p 仍然可以使用 p.X 的方式访问字段,这是 Go 对语法的简化。
Array Slice
数组定长,切片是数组的一个窗口引用,描述的了底层数组的一个片段,切片的所有操作本质上改变的是底层的数组。所以多个切片引用一个数组的时候,改动相互之间可见。
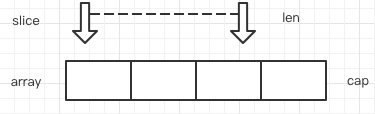
names := [...]int{1, 2, 3, 4, 5, 6, 7}a := names[0: 4]b := names[2: 4] // 两者引用自同一个数组,只是引用片段有区别
[3]bool{true, true, false} // 创建一个数组[]bool{true, true, false} // 创建一个数组,再创建切片指向数组
slice 有两个长度属性,len就是当前引用窗口的大小,cap就是底层数组的大小(从切片下界开始计算)。
func main() {arr := []int{1,2,3,4,5,6,7}s := arr[:4]fmt.Println(len(s)) // 4fmt.Println(cap(s)) // 7}
注意点
与面向对象的 Java 不同,Golang 中的 array 在函数传参的时候穿的是值。slice 在函数传参的时候也是传值,由于 slice 本身就是引用,所以操作会影响底层的数组。
创建切片
- 从数组创建切片
- 使用
make([]Type, len, cap)
切片操作
末尾添加
go func append(s []T, vs ...T) []T // 返回新的切片引用range 关键字可以作用于数组、切片,返回
idx, val或者只需获取`val`go for i, val := range s { // ... } for val := range s { // ... }
Map
存储 K-V 键值对。
map 操作
创建map
go m := make(map[string]int)修改值
go m[key] = val删除key
go delete(m, key)获取值,key不存在的时候,获取的 val 是该类型的默认零值
go val = m[key] val, ok := m[key] // 若key不存在,则ok=false, val为零值
控制流程
循环 For
和其他语言的类似,但是 Go 中没有 while 关键字,一切循环都使用 for 关键字
for sum < 1000 {sum += sum}for { // 不停循环,和 while(true) 一样}
range
range 关键字返回可迭代类型的 KV 键值对。可迭代类型包括 map、array、string、slice,其中 array、string、slice 返回的 K 键值对的 K 就是从0开始的下标值。
在使用 range 遍历 string 的时候,被切分出来的是 rune 类型的一个符文。rune 是什么意思呢?在 Golang 中,string 底层是使用 byte 数组实现的。对于非英文而言就会有些问题,例如中文在 unicode 下是2个字节,而在 utf-8 中是3个字节(Golang 的默认编码是 utf-8)。那么想知道一个字符串中有多少个字面可见的字符就不能够使用 len(s) 来做到,因为这个计算的是字节数。
- byte 等同于 uint8,用于处理 ascii 字符
- rune 等同与 int32,用于处理 unicode 或者 utf-8 字符
看一个例子来具体区分 rune 和 char
s := "hi 哈哈"fmt.Println(len(s)) // 输出9,统计的是字符串的总 字节fmt.Println(utf8.RuneCountInString(s)) // 输出5,统计的是字符串的总 字符元素
条件判断 if,switch
if 和 switch 都可以使用一个简短声明来创建一个变量,且 switch 的 break 可忽略不写。
func pow(x, n, lim float64) {if v := math.Pow(x, n); v < lim {return v}return lim}func main() {switch os := runtime.GOOS; os {case "darwin":fmt.Println("OS X.")case "linux":fmt.Println("Linux.")default:fmt.Printf("%s.\n", os)}}
switch 还可以不写判断的变量,直接变成了 if-else 的相同作用
func main() {t := time.Now()switch {case t.Hour() < 12:fmt.Println("Morning")case t.Hour() < 17:fmt.Println("Afternoon")default:fmt.Println("Evening")}}
Defer
总而言之就是在当前函数完全退出之前必然执行 defer 之后的语句。但是这要保证 defer 语句本身被执行,所以 defer 的放置位置很重要,尽量避免相隔多行之后进行处理,保证 defer 之后的语句入栈(LIFO 式调用执行)。
Defer 中涉及返回值的细节
在有返回值的函数中,使用 defer 后的函数完成顺序如下:
- 确定返回的值
- 执行 defer 后的语句
- 执行 return 退出函数
有名返回值情况
func testDefer() (res int) {i := 1defer func() {res++}()return i}
对于这个例子:
- 首先进入到函数中后,res 被赋上默认值 0
- 执行到 defer 则先将之后的 func 注册到栈中
- 接着执行到 return 时,先确定返回值,即 res=i,res 此时的值变成了 1
- 执行 defer 后的语句,res++,res 值变成 2
- 执行 return 退出函数,所以最终的返回值是 2
无名返回值的情况可以看作是,系统自己创建了一个返回值的名字
func testDefer() int {i := 1defer func() {i++}()return i}// 等价于func testDefer() int {i := 1defer func() {i++}()res := ireturn res}
函数
闭包
函数方面和 JS 很类似,可以传递回调函数,所以在 Go 中也有闭包的概念。闭包就是子函数引用的父函数变量集合,然后使用者使用这个子函数控制其引用的父函数变量。
类型赋予方法
Go 语言中没有类,但是可以给所有类型附加方法。
type MyType struct {X, Y int}func (v MyType) Add() int { // 将 Add 方法附加给 MyType 类型return v.X + v.Y}
上述方法获取的是方法接收者的值拷贝进行操作,若要改变原本的接收者值,接收者需要使用指针类型。
type MyString stringfunc (v *MyString) Smile() { // 将 Add 方法,附加给 *MyString 类型*v += " smile:)"}
接口
接口就是方法声明的集合。在类型实现接口的时候,无需指明接口名,只需将接口的所有方法实现并赋值给实现类型。普通接收者实现,则该类型实现了接口;指针接收者实现,则该类型指针实现了接口。
type ITest interface {SayHello() string}type HerString stringfunc (s *HerString) SayHello() string { // *HerString 实现接口return "Hello yeah"}func main() {hs := HerString("")// var t ITest = hs 报错var t ITest = &hsfmt.Println(t.SayHello())}
type ITest interface {SayHello() string}type MyString stringfunc (s MyString) SayHello() string { // MyString 实现接口return "Hello"}func main() {ms := MyString("")var t ITest = msfmt.Println(t.SayHello())}
接口原理
接口值可以看作是一个值、具体类型 (value, concreteType) 形式的元组,调用一个接口的方法调用的就是其具体类型的方法,这种多态的思想和 C++/Java 是一致的。
package maintype I interface {M()}type T struct {S string}func (t *T) M() {// ...}func main() {var i Ii = &T{"Hello"}fmt.Printf("%v, %T", i, i) // &{Hello}, *main.T}
nil 值接口
在 Go 中空指针也可以调用接口的方法,因为接口的变量一旦声明,其本身就可以看作是一个非空元组(<nil>, <nil>),只不过值为 nil,具体实现类型为 nil。
一旦指定了实现类型,(<nil>, concreteType) 就算值为 nil 仍然可以进行接口方法调用。
没有指定实现类型,调用方法报错!
type I interface {M()}type T struct {S string}func (t *T) M() {if t == nil {fmt.Println("<nil>")return}fmt.Println(t.S)}func main() {var i I// i.M() // 报错var t *T // t == <nil>i = ti.M() // "<nil>"}
空接口
空接口 interface{} 可以拥有任何类型的值,即任何类型都实现了空接口。
package mainimport "fmt"func main() {var i interface{}describe(i) // (<nil>,<nil>)i = 42describe(i) // (42, int)}func describe(i interface{}) {fmt.Printf("(%v, %T)\n", i, i)}
类型断言
通过类型断言,可以在获取接口值的时候检查其具体类型,即获取到元组 (val, type) 中的 type。
// i 的具体类型不是T时 panict := i.(T)// i 的具体类型不是T时,ok=false,t为T类型零值// 和 map 类似t, ok := i.(T)
var i interface{} = "Hello"s, ok := i.(string)fmt.Println(s, ok) // Hello, true
Type switch
使用关键字 type 可以结合 switch 进行类型分支判断
switch v := i.(type) {case T:// v has type Tcase S:// v has type Sdefault:// no match}
常用接口
Stringer
打印某个类型的时候 fmt 通过 String() 方法获取值,类似 Java 中的 toString。
type Stringer interface {String() string}
Error
错误类型,打印错误的时候 fmt 包通过 Error 接口获取值。
type error interface {Error() string}
注意:在实现 Error 方法时,若要在其中打印值本身,要将该值转换成非error类型,否则会导致无限循环。
Reader
io.Reader 接口声明用于读取字节流的方法,标准库中有许多对这个接口的实现。其工作流程如下:
- 将字节流读入字节切片 p
- 返回读取到的字节数 n
- 当流结束时,返回
io.EOF
type Reader interface {Read(p []byte) (n int, err error)}
例子:strings.Reader 读取 string
func main() {r := strings.NewReader("Hello Reader!")b := make([]byte, 8) // 每次最多读入8bytefor {n, err := r.Read(b)fmt.Printf("b[:n] = %q\n", b[:n])if err == io.EOF {break}}}
Image
图片接口描述的实际是有限的颜色方形颜色块
type Image interface {ColorModel() color.Model // 默认为 color.RGBAModelBounds() RectangleAt(x, y int) color.Color // 默认为 color.RGBA}
并发
协程
更加轻量级的线程,多个协程执行在同一个地址空间。也可以看作是每一个线程执行的任务,线程可以主动切换任务执行,减少了上下文切换、cache 同步的开销。
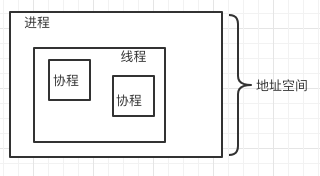
具体看看进程、线程、协程的比较
| 进程 | 线程 | 协程 | |
|---|---|---|---|
| CPU | - | 线程是 CPU 调度的基本单位,OS 负责分配线程到 CPU 上进行执行 | 运行在线程上 |
| 内存 | 进程是资源分配的基本单位,进程拥有自己独立的内存空间 | 多个线程共享使用进程的内存空间 | 同样是使用进程的空间 |
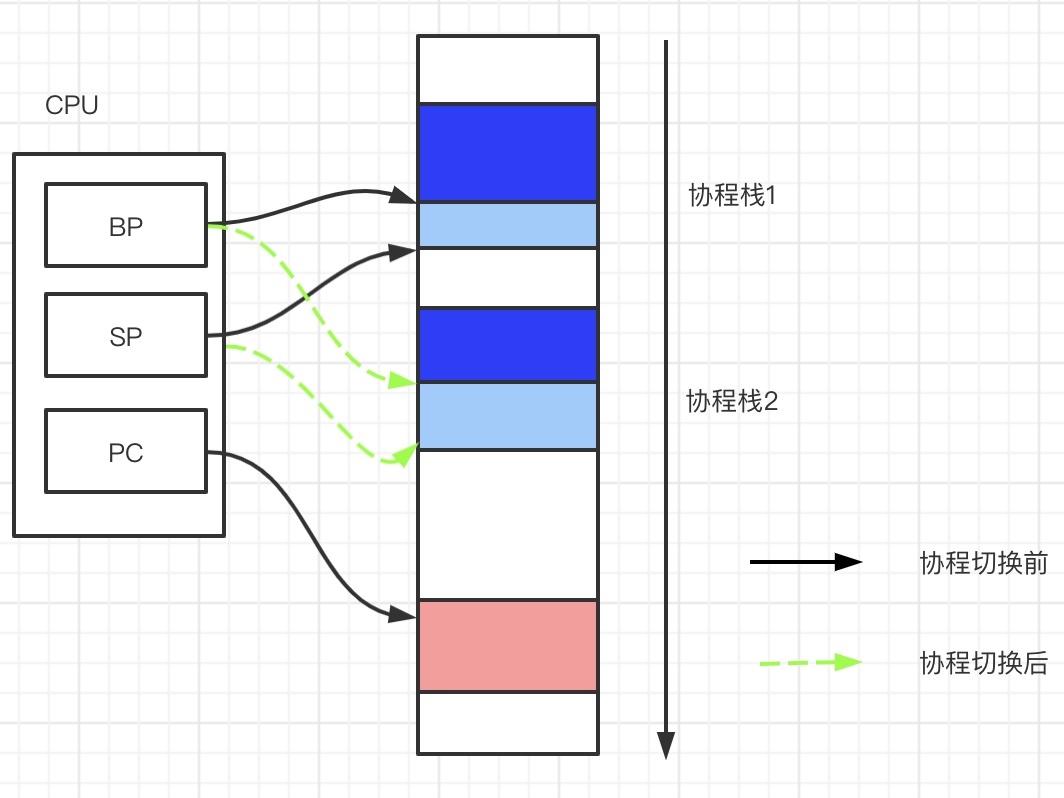
| 栈 | - | 一个运行时的方法产生一个栈帧,OS 分配的调用栈大小默认为 8MB | 用户程序在堆上保存每一个协程栈的信息,切换的时候修改相关寄存器的指针(SP栈顶,BP栈底,PC) |
| 切换方式 | - | 触发中断,内核负责切换线程 | 主动 yield 切换,让出 CPU,在用户态完成 |
| 切换内容 | 通用寄存器 PC 寄存器 内核栈 CPU 缓存信息 页表寄存器 TLB 缓存 |
通用寄存器 PC 寄存器 内核栈 CPU 缓存信息 |
通用寄存器 PC 寄存器 |
所以协程的切换其实就类似当前线程在执行代码的时候,突然跳到另一个部分的代码进行执行,主要需要修改栈帧寄存器 BP 和 SP 的还有 PC 寄存器的指向即可。
Goroutine
goroutine 是由 Go runtime 管理的轻量级线程(本质为协程),所以不同多个 goroutines 运行在相同的地址空间中,对于共享内容需要进行同步互斥。
在方法前使用关键字 go,则该方法在一个新的 goroutine 中执行,当前 goroutine 继续执行当前方法内容。
func say(s string) {fmt.Println(s)}func main() {go say("hahaha")say("wowow")}
Channel
一种传输特定类型的半双工管道,默认情况下,管道缓冲区只能存放一个元素,其半双工性质有利于用于在多协程环境下协程之间的同步通信。注意,在使用的时候 channel 缓冲为空会阻塞读,channel 缓冲满会阻塞写。
使用关键字 chan
ch <- v // 将 v 的值送入管道v := <- ch // 将管道的内容输出到 vch := make(chan int) // 创建一个传输 int 类型的管道
func sum(s []int, c chan int) {sum := 0for _, v := range s {sum += v}c <- sum // send sum to c}func main() {s := []int{7, 2, 8, -9, 4, 0}c := make(chan int)go sum(s[: len(s) / 2], c)go sum(s[len(s) / 2:], c)x, y := <-c, <-c // 从左到右执行赋值fmt.Println(x, y, x+y) // -5, 17, 12}
Buffered Channel
默认情况下channel只能存储一个元素,可以在创建 channel 时显式指定缓冲区存储元素的个数,这样在缓冲区满的时候就会阻塞写。
// 创建一个 channel,其缓冲区能够存储 100 个 intch := make(chan int, 100)
Range and Close
channel 可以被 for 循环遍历,由于 channel 是动态地获取数据的,所以要关闭 channel 才能够在遍历的时候正确停止,否则一直阻塞等待导致死锁。
一般情况下很少会关闭 channel。
func fibonacci(n int, c chan int) {x, y := 0, 1for i := 0; i < n; i++ {c <- xx, y = y, x+y}close(c) // 关闭管道}func main() {c := make(chan int, 100)go fibonacci(10, c)for i := range c { // 打印前 10 个数fmt.Println(i)}}
Select
select 表达式配合管道使用,让当前 goroutine 阻塞等待分支语句,直到其中的一个语句分支能够执行。
func fibonacci(c, quit chan int) {x, y := 0, 1for {select {case c <- x: // 往管道中输入数据x, y = y, x+ycase <-quit: // quit 中没有数据的时候阻塞fmt.Println("quit")return// default: 也可以使用一个 default 情况,使得循环不阻塞}}}func main() {c := make(chan int)quit := make(chan int)go func() {for i := 0; i < 10; i++ {fmt.Println(<-c) // c 中没有数据时,读阻塞}quit <- 0}()fibonacci(c, quit)}
sync.Mutex
互斥锁,用于框定互斥操作,包含两个方法。其中解锁方法可以使用 defer 关键字标识,保证其成功执行。
LockUnlock
type SafeCounter struct {m sync.Mutextv map[string]int}func (c *SafeCounter) Incr(key string) {c.m.Lock()c.v[key]++ // 临界区,单线程访问defer c.m.Unlock()}func (c *SafeCounter) Value(key string) {c.m.Lock()defer c.m.Unlock()return c.v[key]}func main() {c := SafeCounter{v: make(map[string]int)}for i := 0; i < 1000; i++ {go c.Incr("a key")}time.Sleep(time.Second)fmt.Println(c.Value("a key"))}

若有收获,就点个赞吧
0 人点赞
