2. Flink API
2.1 流处理的概念
2.2.1 流数据和批数据
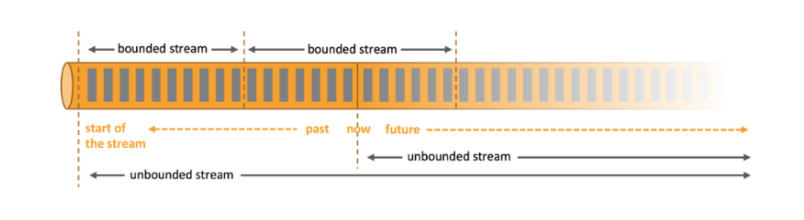
- 流数据:有边界的流(bounded stream);
- 批数据:无边界的流(unbounded stream)。
2.2.2 流计算和批计算的不同点
- 批计算:统一收集数据 -> 存储到DB -> 对数据进行批量处理,就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表;
- 流计算:对数据流进行处理,如使用流式分析引擎如 Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
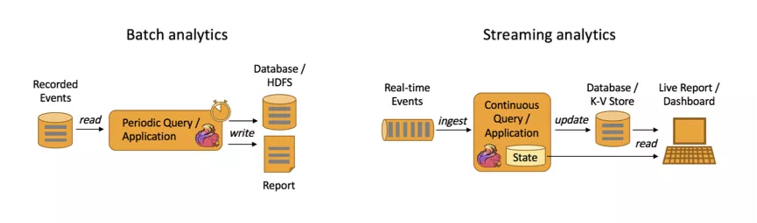
image-20220427093933647
它们之间主要有以下四点不同:
- 数据时效性不同:流式计算实时、低延迟,而批计算非实时,高延迟;
- 数据特征不同:流式计算的数据一般是动态的、没有边界的,而批处理的数据一般是静态数据;
- 应用场景不同:流式计算主要应用于实时场景,即时效性要求较高的场景,而批处理主要用于实时性不高的离线计算场景;
- 运行方式不同:流式计算的任务是持续进行的,而批计算的任务则是一次性完成的。
2.2.3 Flink的流批一体API
Flink 1.12之后取消了DataSet API,使用 DataStream API进行流批一体处理。Flink提供了多个层次的API供开发者使用,越往上抽象程度越高,使用起来越方便;越往下越底层,使用起来难度越大: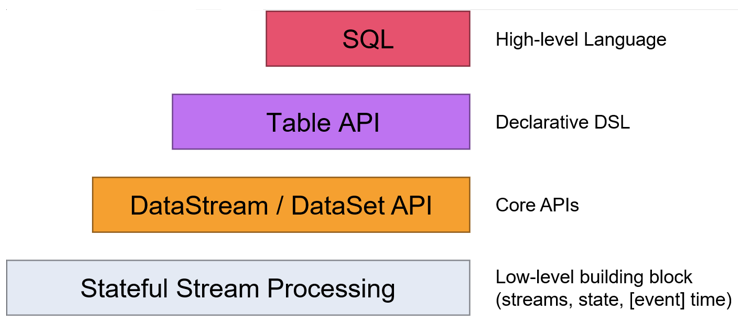
image-20220427094536734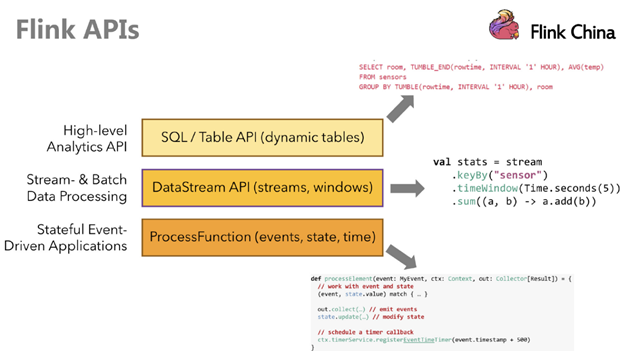
image-20220427094554437
2.2 Source
2.2.1 基于集合的Source
- env.fromElements(可变参数);
- env.fromCollections(各种集合);
- env.generateSequence(start, end);
- env.fromSequence(start, end);
package org.example.source;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class CollectionSource {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<String> lines = env.fromElements("hadoop, flink, spark", "hbase, hive", "zookeeper");<br /> DataStreamSource<String> collections = env.fromCollection(Arrays.asList("hadoop spark flink", "java scala"));<br /> DataStreamSource<Long> geneseq = env.generateSequence(1, 100);<br /> DataStreamSource<Long> seq = env.fromSequence(1, 100);// Transformation// Sink<br /> lines.print();<br /> collections.print();<br /> geneseq.print();<br /> seq.print();// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />
2.2.2 基于文件的Source
- env.readTextFile(本地/HDFS文件夹/文件夹/压缩文件)
package org.example.source;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class FileSource {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<String> text = env.readTextFile("data/input/words.txt");<br /> DataStreamSource<String> dir = env.readTextFile("data/input/words_dir");;<br /> // 这里没有测试压缩文件// Transformation// Sink<br /> text.print();<br /> dir.print();// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />
2.2.3 基于Socket的Source
- env.socketTextStream(host, port)
案例:实时单词统计
- 需求:在node01上使用nc -lk 9999命令向指定的端口发送数据,然后用Flink编写流处理应用实时统计单词的数量
package org.example.source;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class SocketSource {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<String> lines = env.socketTextStream("node01", 9999);// Transformation<br /> SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(<br /> new FlatMapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> out.collect(Tuple2.of(word, 1));<br /> }<br /> }<br /> });SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(t -> t.f0).sum(1);// Sink<br /> res.print();// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />
2.2.4 自定义Source
Flink提供了数据源接口,只要我们实现这个接口就可以自定义数据源,不同的接口的功能不同,分类如下:
- SourceFunction:非并行数据源,并行度只能为1;
- RichSourceFunction:多功能非并行数据源,并行度同样只能为1;
- ParallelSourceFunction:并行数据源
- RichParallelSourceFunction:多功能并行数据源,后续Kafka数据源就是用的这个接口。
2.2.4.1 随机生成数据
随机生成数据一般通过模拟一些实时数据用于测试和学习,下面来看一个案例:
需求:每一秒中生成一个订单信息(订单ID, 用户ID, 订单金额, 时间戳),其中前三个元素是随机的,时间戳为系统当前的时间戳。
package org.example.source;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import scala.reflect.api.FlagSets;
import java.util.Random;
import java.util.UUID;
public class CustomerSource {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<Order> orderDS = env.addSource(new MyOrderSource()).setParallelism(2);// Transformation// Sink<br /> orderDS.print();// 执行并等待结束<br /> env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class Order{<br /> private String id;<br /> private Integer userId;<br /> private Integer money;<br /> private Long createTime;<br /> }public static class MyOrderSource extends RichParallelSourceFunction<Order> {private Boolean flag = true;// 执行并生成数据<br /> @Override<br /> public void run(SourceContext<Order> ctx) throws Exception {<br /> Random random = new Random();<br /> while (flag) {<br /> String oid = UUID.randomUUID().toString();<br /> int userId = random.nextInt(3);<br /> int money = random.nextInt(101);<br /> long createTime = System.currentTimeMillis();<br /> ctx.collect(new Order(oid, userId, money, createTime));<br /> Thread.sleep(1000);<br /> }<br /> }// 执行cancel命令时使用<br /> @Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> }<br />}<br />【补充】:<br />@Data、@AllArgsConstructor和@NoArgsConstructor这三个注解的作用:
- @Data:生成get和set方法;
- @AllArgsConstructor:生成全参构造函数;
- @NoArgsConstructor:生成无参构造函数。
2.2.4.2 MySQL
在实际开发中,经常需要实时接收一些数据,要和MySQL中存储的一些规则进行匹配,这时候就可以使用Flink自定义数据源从MySQL中读取数据,下面来看一个案例:
需求:从MySQL中实时加载数据,要求MySQL中的数据有变化,也能被实时加载出来
首先需要连接本机的MySQL:
mysql -u<用户,如root> -p<密码>
然后创建flinktest数据库:
create database if not exists flinktest;
再然后使用该数据库,并创建t_student表
CREATE TABLE t_student (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(255) DEFAULT NULL,
age int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
插入一些数据,这里先插入前三条,后三条等程序启动起来再插入,看看程序是否可以捕捉变化
INSERT INTO t_student VALUES (‘1’, ‘jack’, ‘18’);
INSERT INTO t_student VALUES (‘2’, ‘tom’, ‘19’);
INSERT INTO t_student VALUES (‘3’, ‘rose’, ‘20’);
INSERT INTO t_student VALUES (‘4’, ‘tom’, ‘19’);
INSERT INTO t_student VALUES (‘5’, ‘jack’, ‘18’);
INSERT INTO t_student VALUES (‘6’, ‘rose’, ‘20’);
然后进行代码实现:
package org.example.source;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import java.sql.*;
public class MySQLSource {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<Student> studentDS = env.addSource(new SQLSource()).setParallelism(1);// Transformation// Sink<br /> studentDS.print();// Execute<br /> env.execute();<br /> }@Data<br /> @NoArgsConstructor<br /> @AllArgsConstructor<br /> public static class Student{<br /> private Integer id;<br /> private String name;<br /> private Integer age;<br /> }public static class SQLSource extends RichParallelSourceFunction<Student> {<br /> private boolean flag = true;<br /> private Connection conn = null;<br /> private PreparedStatement ps = null;<br /> private ResultSet rs = null;// open只执行一次,用于开启资源<br /> @Override<br /> public void open(Configuration conf) throws SQLException {<br /> conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/flinktest?serverTimezone=GMT&characterEncoding=UTF-8", "root", "2020212295");<br /> String sql = "select id, name, age from t_student";<br /> ps = conn.prepareStatement(sql);<br /> }@Override<br /> public void run(SourceContext<Student> ctx) throws Exception {<br /> while (flag) {<br /> rs = ps.executeQuery();<br /> while (rs.next()) {<br /> int id = rs.getInt("id");<br /> String name = rs.getString("name");<br /> int age = rs.getInt("age");<br /> ctx.collect(new Student(id, name, age));<br /> }<br /> Thread.sleep(5000);<br /> }<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }// close() 中关闭资源<br /> @Override<br /> public void close() throws Exception {<br /> if(conn != null) conn.close();<br /> if(ps != null) ps.close();<br /> if(rs != null) rs.close();<br /> }<br /> }<br />}<br />【注意】:<br />由于我的电脑中的MySQL为8.0.22的,所以对应的依赖版本需要匹配,需要在pom.xml中修改如下内容:<br /><dependency><br /> <groupId>mysql</groupId><br /> <artifactId>mysql-connector-java</artifactId><br /> <version>8.0.22</version><br /> <!--<version>8.0.20</version>--><br /> </dependency><br />
2.3 TransFormation
2.3.1 基本操作
基本操作和Spark的那些操作差不多,就是map、flatMap、filter、keyBy、sum、reduce等等,具体的转换关系如下图所示: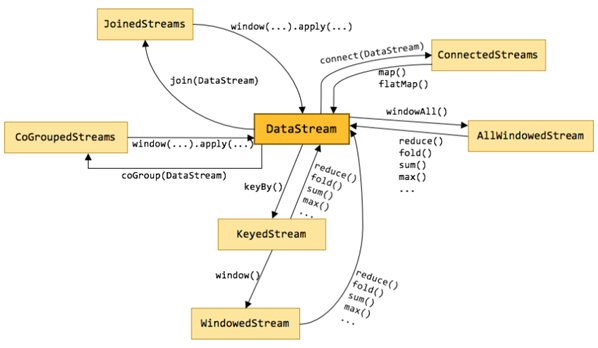
image-20220427094854286
操作概览如下: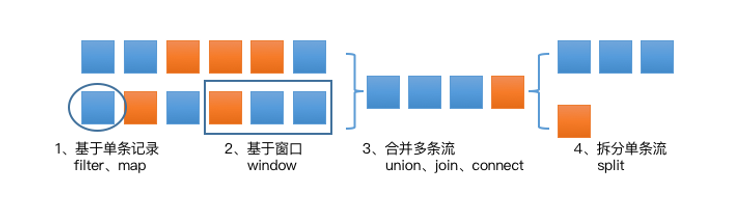
image-20220427094918277
可以看出,流式处理的操作整体可以分为四类:
- 操作单条记录:
- map:对每一个记录做一个转换
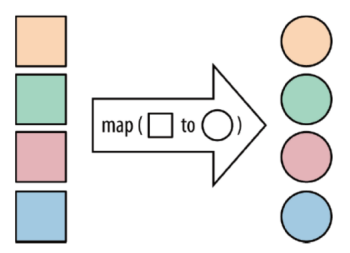
- image-20220427130107386
- flatMap:将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果
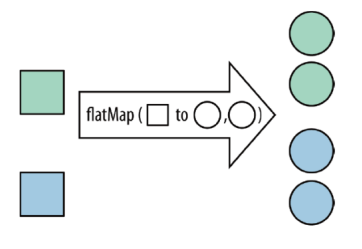
- image-20220427145933849
- fliter:过滤不符合要求的记录
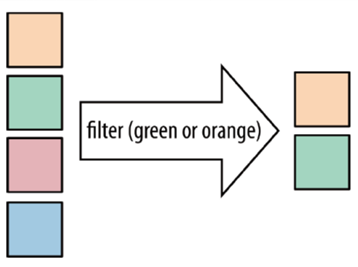
- image-20220427145948376
- 处理多条记录:
- keyBy:按照指定的key对流中的数据进行分组,注意流处理没有groupBy只有keyBy
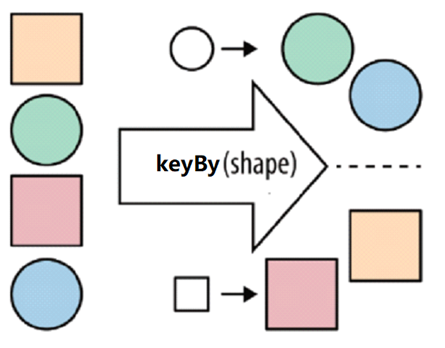
- image-20220427150538527
- reduce:对集合中的元素进行聚合
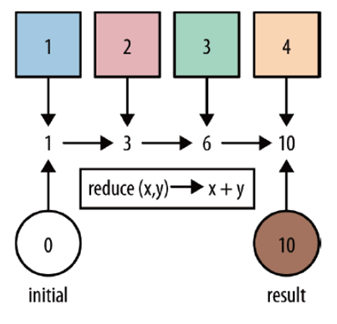
- image-20220427150715347
- 处理多个流并和转换为单个流,比如多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作;
- 合并对称的拆分操作,即将一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理。
下面来看一个案例:
需求:对流数据中的单词进行统计,并排除敏感词python
public static void main(String[] args) throws Exception {
//TODO 0.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//TODO 1.source<br /> DataStream<String> lines = env.socketTextStream("node01", 9999);//TODO 2.transformation<br /> DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {<br /> @Override<br /> public void flatMap(String value, Collector<String> out) throws Exception {<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> out.collect(word);<br /> }<br /> }<br /> });DataStream<String> filted = words.filter(new FilterFunction<String>() {<br /> @Override<br /> public boolean filter(String value) throws Exception {<br /> return !value.equals("python"); // 如果是python则返回false表示过滤掉<br /> }<br /> });SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = filted.map(new MapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public Tuple2<String, Integer> map(String value) throws Exception {<br /> return Tuple2.of(value, 1);<br /> }<br /> });KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);//SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.reduce(new ReduceFunction<Tuple2<String, Integer>>() {<br /> @Override<br /> public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {<br /> //Tuple2<String, Integer> value1 :进来的(单词,历史值)<br /> //Tuple2<String, Integer> value2 :进来的(单词,1)<br /> //需要返回(单词,数量)<br /> return Tuple2.of(value1.f0, value1.f1 + value2.f1); //_+_<br /> }<br /> });//TODO 3.sink<br /> result.print();//TODO 4.execute<br /> env.execute();<br />
2.3.2 合并、拆分和选择操作(重点)
2.3.2.1 union 和 connect 操作(注意区别)
- union:可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重;
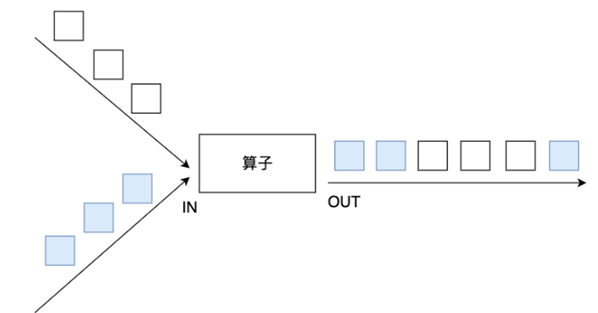
- image-20220427152840837
- connect:只能合并两个流,并且合并的流的数据类型可以不一致,两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态;
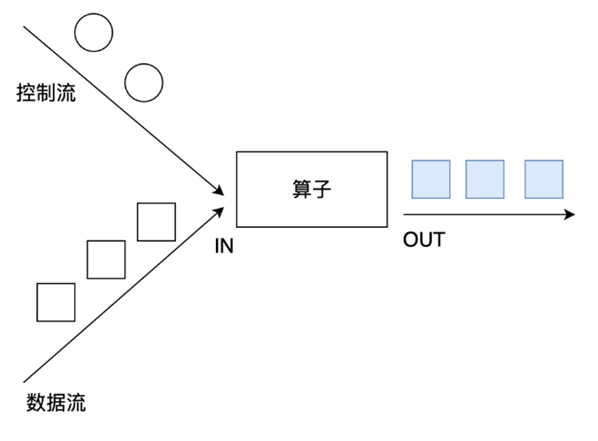
下面来看一个案例:
需求:将两个String类型的流进行Union,并将一个String类型的流和一个Long类型的流进行Connect
package org.example.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
public class UnionAndConnect {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source<br /> DataStreamSource<String> stringDS1 = env.fromElements("hadoop", "spark", "flink");<br /> DataStreamSource<String> stringDS2 = env.fromElements("hadoop", "spark", "flink");<br /> DataStreamSource<Long> longDS = env.fromElements(1L, 2L, 3L);// transformation<br /> // union可以合并同类型的流,并生成同类型的流<br /> DataStream<String> unionRes = stringDS1.union(stringDS2);<br /> // connect可以合并两个不同类型的流,但是需要后续的处理才可以输出<br /> ConnectedStreams<String, Long> connectRes = stringDS1.connect(longDS);<br /> SingleOutputStreamOperator<String> res = connectRes.map(<br /> new CoMapFunction<String, Long, String>() {<br /> @Override<br /> public String map1(String value) throws Exception {<br /> return "String: " + value;<br /> }@Override<br /> public String map2(Long value) throws Exception {<br /> return "Long: " + value;<br /> }<br /> });// sink<br /> res.print();<br /> unionRes.print();// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />
2.3.2.2 split、select和Side Outputs
- Split:用于将一个流分为多个流(目前split函数已过期并移除,使用outPutTag和process来替代)
- Select:获取分流后的数据
- Side Outputs:可以使用process方法对流中的数据进行处理,并针对不同的处理结果将数据收集到不同的OutputTag中(侧输出流,数仓重点知识)
下面来看一个案例:
需求:对流中的数据按照奇数和偶数分类
package org.example.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class SelectAndSideOutputs {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// source<br /> DataStreamSource<Integer> ds = env.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// transformation<br /> // 定义两个 outputTag 用于分流<br /> OutputTag<Integer> oddTag = new OutputTag<>("奇数", TypeInformation.of(Integer.class));<br /> OutputTag<Integer> evenTag = new OutputTag<>("偶数", TypeInformation.of(Integer.class));SingleOutputStreamOperator<Integer> res = ds.process(<br /> new ProcessFunction<Integer, Integer>() {<br /> @Override<br /> public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception {<br /> // out收集完是放在一起的,ctx可以将数据放到不同的OutputTag<br /> if (value % 2 == 0) {<br /> ctx.output(evenTag, value);<br /> } else {<br /> ctx.output(oddTag, value);<br /> }<br /> }<br /> });DataStream<Integer> oddRes = res.getSideOutput(oddTag);<br /> DataStream<Integer> evenRes = res.getSideOutput(evenTag);// sink<br /> System.out.println(oddTag);<br /> System.out.println(evenTag);<br /> oddRes.print("奇数");<br /> evenRes.print("偶数");// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />
2.3.3 分区
2.3.3.1 重平衡分区(rebalance)
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如下图所示的状况,出现了数据倾斜,其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成。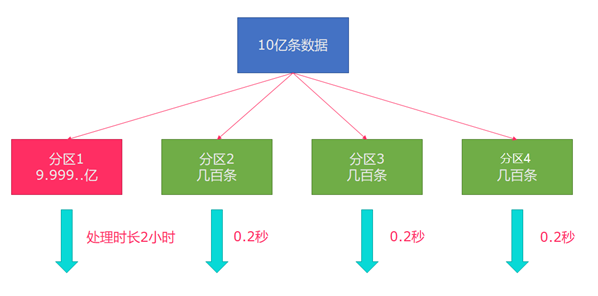
image-20220427163505833
所以在实际中遇到这种情况最好是使用重平衡分区(内部使用round robin方式将数据打散),结果如下图所示: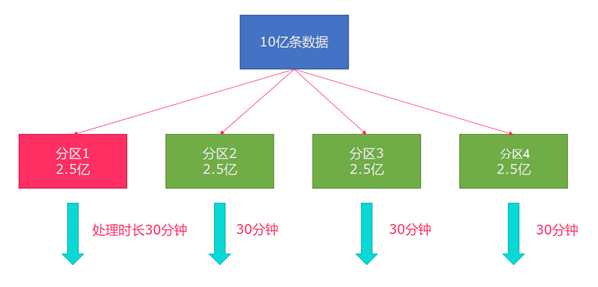
image-20220427163632557
下面来通过一个案例来理解重平衡分区:
package org.example.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Rebalance {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<Long> longDS = env.fromSequence(0, 100);<br /> // 将数据随机分配,可能会导致数据倾斜<br /> SingleOutputStreamOperator<Long> filted = longDS.filter(<br /> new FilterFunction<Long>() {<br /> @Override<br /> public boolean filter(Long num) throws Exception {<br /> return num > 10;<br /> }<br /> });// Transformation<br /> // 没有经过重平衡可能会导致数据倾斜<br /> SingleOutputStreamOperator<Tuple2<Integer, Integer>> result = filted.map(<br /> new RichMapFunction<Long, Tuple2<Integer, Integer>>() {<br /> @Override<br /> public Tuple2<Integer, Integer> map(Long aLong) throws Exception {<br /> // 获取子任务ID或者是分区编号<br /> int subTaskId = getRuntimeContext().getIndexOfThisSubtask();<br /> return Tuple2.of(subTaskId, 1);<br /> }<br /> // 按照子任务id或分区编号分组,并统计每个分区中的元素<br /> }).keyBy(t -> t.f0).sum(1);// 经过重平衡的不会出现数据倾斜<br /> SingleOutputStreamOperator<Tuple2<Integer, Integer>> rbResult = filted.rebalance().map(<br /> new RichMapFunction<Long, Tuple2<Integer, Integer>>() {<br /> @Override<br /> public Tuple2<Integer, Integer> map(Long aLong) throws Exception {<br /> // 获取子任务ID或者是分区编号<br /> int subTaskId = getRuntimeContext().getIndexOfThisSubtask();<br /> return Tuple2.of(subTaskId, 1);<br /> }<br /> // 按照子任务id或分区编号分组,并统计每个分区中的元素<br /> }).keyBy(t -> t.f0).sum(1);// Sink<br /> result.print();<br /> rbResult.print();// 启动并等待结束<br /> env.execute();<br /> }<br />}<br />
2.3.3.2 其他分区
除了重平衡分区外,还有许多其他分区的API,具体如下表所示: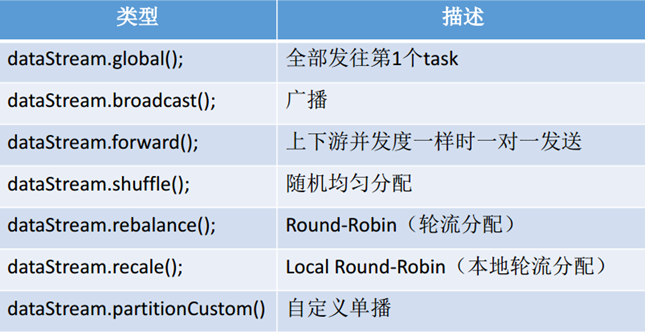
image-20220427163718814
下面来看一个例子:
package org.example.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Partition {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<String> lines = env.readTextFile("data/input/words.txt");// TransformationSingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = lines.flatMap(<br /> new FlatMapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {<br /> String[] words = value.split(" ");<br /> for (String word : words) {<br /> out.collect(Tuple2.of(word, 1));<br /> }<br /> }<br /> });// 演示各种分区方式<br /> DataStream<Tuple2<String, Integer>> result1 = tupleDS.global();<br /> DataStream<Tuple2<String, Integer>> result2 = tupleDS.broadcast();<br /> DataStream<Tuple2<String, Integer>> result3 = tupleDS.forward();<br /> DataStream<Tuple2<String, Integer>> result4 = tupleDS.shuffle();<br /> DataStream<Tuple2<String, Integer>> result5 = tupleDS.rebalance();<br /> DataStream<Tuple2<String, Integer>> result6 = tupleDS.rescale();<br /> DataStream<Tuple2<String, Integer>> result7 = tupleDS.partitionCustom(new MyPartitioner(), t -> t.f0);// Sink<br /> result1.print();<br /> result2.print();<br /> result3.print();<br /> result4.print();<br /> result5.print();<br /> result6.print();<br /> result7.print();// 启动并等待结束<br /> env.execute();<br /> }// 自定义分区方式<br /> public static class MyPartitioner implements Partitioner<String> {<br /> @Override<br /> public int partition(String s, int i) {<br /> // 这部分写自己的分区逻辑<br /> return 0;<br /> }<br /> }<br />}<br />
2.4 Sink
2.4.1 基于控制台和文件的Sink
- ds.print():直接输出至控制台
- ds.printToErr():直接输出至控制台,显示为红色
- ds.writeAsText(“本地/HDFS的路径”, WriteMode.OVERWRITE).setParallelism(1)
- 在输出到Path时,可以设置并行度,其中:
- 并行度大于1,则path为目录
- 并行度等于0,则path为文件名
- 在输出到Path时,可以设置并行度,其中:
下面来看一个例子:
package org.example.sink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Sink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<String> ds = env.readTextFile("data/input/words.txt");// Sink<br /> ds.print();<br /> ds.print("输出标识");<br /> ds.printToErr();<br /> ds.printToErr("输出标识");<br /> ds.writeAsText("data/output/result").setParallelism(2);env.execute();<br /> }<br />}<br />
2.4.2 自定义Sink
2.4.2.1 MySQL Sink
需求:将Flink集合中的数据通过自定义Sink的方式保存到MySQL中
package org.example.sink;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class MySQLSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> DataStreamSource<Student> studentDS = env.fromElements(new Student(20, "tony", 18));// Transformation// Sink<br /> studentDS.addSink(new SQLSink());env.execute();<br /> }@Data<br /> @NoArgsConstructor<br /> @AllArgsConstructor<br /> public static class Student {<br /> private Integer id;<br /> private String name;<br /> private Integer age;<br /> }public static class SQLSink extends RichSinkFunction<Student> {<br /> private Connection conn = null;<br /> private PreparedStatement ps = null;@Override<br /> public void open(Configuration conf) throws Exception {<br /> conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/flinktest?serverTimezone=GMT&characterEncoding=UTF-8", "root", "2020212295");<br /> String sql = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (?, ?, ?);";<br /> ps = conn.prepareStatement(sql);<br /> }@Override<br /> public void invoke(Student student, Context context) throws SQLException {<br /> // 设置?占位符的参数值<br /> ps.setInt(1, student.getId());<br /> ps.setString(2, student.getName());<br /> ps.setInt(3, student.getAge());// 执行SQL<br /> ps.execute();<br /> }@Override<br /> public void close() throws Exception {<br /> if (conn != null) conn.close();<br /> if(ps != null) ps.close();<br /> }<br /> }<br />}<br />
2.5 Connector
2.5.1 JDBC
需求:通过JDBC的方式将数据保存到MySQL中
package org.example.connector;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class JDBC {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<Student> studentDS = env.fromElements(new Student(21, "Tom", 15));// 使用JDBC的方式将数据送入MySQL<br /> studentDS.addSink(<br /> JdbcSink.sink(<br /> "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (?, ?, ?)",<br /> (ps, value) -> {<br /> ps.setInt(1, value.getId());<br /> ps.setString(2, value.getName());<br /> ps.setInt(3, value.getAge());<br /> }, new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()<br /> .withUrl("jdbc:mysql://localhost:3306/flinktest?serverTimezone=GMT&characterEncoding=UTF-8")<br /> .withUsername("root")<br /> .withPassword("2020212295")<br /> .withDriverName("com.mysql.jdbc.Driver")<br /> .build()));env.execute();<br /> }@Data<br /> @NoArgsConstructor<br /> @AllArgsConstructor<br /> public static class Student {<br /> private Integer id;<br /> private String name;<br /> private Integer age;<br /> }<br />}<br />【注意】:
- 由于我的MySQL版本为8.0.2,因此JDBC的连接url和5.x版本的有所不同
- jdbc:mysql://localhost:3306/flinktest?serverTimezone=GMT&characterEncoding=UTF-8
- 对部分字段的解释如下:
- serverTimezone=GMT:用于匹配时区
- characterEncoding=UTF-8:数据库的字符集设置的编码为UTF-8
2.5.2 Kafka
2.5.2.1 pom依赖
【注意】:Flink 里已经提供了一些绑定的 Connector,例如 kafka source 和 sink,Es sink 等,虽然该部分是 Flink 项目源代码里的一部分,但是真正意义上不算作 Flink 引擎相关逻辑,并且该部分没有打包在二进制的发布包里面。所以在提交 Job 时候需要注意, job 代码 jar 包中一定要将相应的 connetor 相关类打包进去,否则在提交作业时就会失败,提示找不到相应的类,或初始化某些类异常。
2.5.2.2 参数设置与说明
以下参数都必须/建议设置:
- 订阅的主题;
- 反序列化规则
- 将Kafka中的二进制数据转换为具体的scala、java对象;
- 常用方法SimpleStringSchema —— 按字符串进行序列化和返序列化;
- 消费者属性——集群地址
- 消费者属性——消费者组id(如果不设置,会有默认的,但是默认的不方便管理)
- 消费者属性——offset重置规则,如earliest/latest…
- 动态分区检测(当kafka的分区数变化/增加时,Flink能够检测到!)
- 如果没有设置Checkpoint,那么可以设置自动提交offset,后续学习了Checkpoint会把offset随着做Checkpoint的时候提交到Checkpoint和默认主题中
2.5.2.3 kafka命令回顾
- 查看当前服务器中的所有topic
- /export/servers/kafka-2.11/bin/kafka-topics.sh —list —zookeeper node01:2181
- 创建topic
- /export/servers/kafka-2.11/bin/kafka-topics.sh —create —zookeeper node01:2181 —replication-factor 2 —partitions 3 —topic flink_kafka
- 查看某个topic的详情
- /export/servers/kafka-2.11/bin/kafka-topics.sh —topic flink_kafka —describe —zookeeper node01:2181
- 删除topic
- /export/servers/kafka-2.11/bin/kafka-topics.sh —delete —zookeeper node01:2181 —topic flink_kafka
- 通过shell命令发送消息
- /export/servers/kafka-2.11/bin/kafka-console-producer.sh —broker-list node01:9092 —topic flink_kafka
- 通过shell命令消费消息
- /export/servers/kafka-2.11/bin/kafka-console-consumer.sh —bootstrap-server node01:9092 —topic flink_kafka —from-beginning
- 修改分区
- /export/servers/kafka-2.11/bin/kafka-topics.sh —alter —partitions 4 —topic flink_kafka —zookeeper node01:2181
2.5.2.1 Kafka Consumer/Source
需求:使用flink-connector-kafka_2.11中的FlinkKafkaConsumer消费Kafka中的数据做WordCount
package org.example.connector;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class KafkaConsumer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// Source<br /> // 准备Kafka的连接参数<br /> Properties props = new Properties();<br /> props.setProperty("bootstrap.servers", "node01:9092"); // 集群地址<br /> props.setProperty("group.id", "flink"); // 消费者组id<br /> props.setProperty("auto.offset.reset", "latest"); // 从最后的记录开始消费<br /> props.setProperty("flink.partition-discovery.interval-millis", "5000"); // 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测<br /> props.setProperty("enable.auto.commit", "true"); // 自动提交<br /> props.setProperty("auto.commit.interval.ms", "2000"); // 自动提交时间间隔// 使用连接参数创建kafkaConsumer<br /> FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("flink_kafka", new SimpleStringSchema(), props);<br /> // 使用KafkaSource<br /> DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);// Transformation<br /> SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = kafkaDS.flatMap(<br /> new FlatMapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public void flatMap(String value, Collector<Tuple2<String, Integer>> output) throws Exception {<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> output.collect(Tuple2.of(word, 1));<br /> }<br /> }<br /> });<br /> SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(t -> t.f0).sum(1);// Sink<br /> res.print();// 启动并等待结束<br /> env.execute();<br /> }<br />}
- 创建主题
- /export/servers/kafka-2.11/bin/kafka-topics.sh —create —zookeeper node01:2181 —replication-factor 2 —partitions 3 —topic flink_kafka
- 启动生产者并发送数据
- /export/servers/kafka-2.11/bin/kafka-console-producer.sh —broker-list node01:9092 —topic flink_kafka
- 启动程序,并等待控制台输出结果。
2.5.2.2 Kafka Producer/Sink
需求:将Flink集合中的数据通过自定义Sink保存到Kafka,具体的流程为:控制台生产者 -> flink_kafka主题 -> Flink -> etl -> flink_kafka2主题 -> 控制台消费者
package org.example.connector;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
public class KafkaProducer {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 准备Kafka连接参数<br /> Properties props = new Properties();<br /> props.setProperty("bootstrap.servers", "node01:9092"); // 集群地址<br /> props.setProperty("group.id", "flink"); // 消费者组id<br /> props.setProperty("auto.offset.reset", "latest"); // 从最后的记录开始消费<br /> props.setProperty("flink.partition-discovery.interval-millis", "5000"); // 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测<br /> props.setProperty("enable.auto.commit", "true"); // 自动提交<br /> props.setProperty("auto.commit.interval.ms", "2000"); // 自动提交时间间隔// 使用连接参数创建kafkaConsumer<br /> FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>("flink_kafka", new SimpleStringSchema(), props);<br /> // 使用KafkaSource<br /> DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);// Transformation<br /> SingleOutputStreamOperator<String> etlDS = kafkaDS.filter(<br /> new FilterFunction<String>() {<br /> @Override<br /> public boolean filter(String s) throws Exception {<br /> return s.contains("success");<br /> }<br /> });// Sink<br /> etlDS.print();Properties prop2 = new Properties();<br /> prop2.setProperty("bootstrap.servers", "node01:9092");<br /> FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("flink_kafka2", new SimpleStringSchema(), prop2);<br /> etlDS.addSink(kafkaSink);env.execute();<br /> }<br />}
- 准备第二个主题
- /export/servers/kafka-2.11/bin/kafka-topics.sh —create —zookeeper node01:2181 —replication-factor 2 —partitions 3 —topic flink_kafka2
- 启动控制台向生产者发送如下数据:
- /export/servers/kafka-2.11/bin/kafka-console-producer.sh —broker-list node01:9092 —topic flink_kafka
- log:2020-10-10 success xxx
log:2020-10-11 success xxx
log:2020-10-12 success xxx
log:2020-10-13 fail xxx - 启动控制台消费者消费数据
- /export/servers/kafka-2.11/bin/kafka-console-consumer.sh —bootstrap-server node01:9092 —topic flink_kafka2 —from-beginning
2.5.3 Redis
2.5.3.1 API
flink 操作 redis 其实可以通过传统的 redis 连接池 Jpools 进行 redis 的相关操作,但是 flink 提供了专门操作 redis 的 RedisSink,使用起来更方便。RedisSink 核心类是 RedisMapper 接口,使用时我们要编写自己的 redis 操作类实现这个接口中的三个方法,如下所示:
- getCommandDescription() : 设置使用的redis 数据结构类型,和key 的名称,通过RedisCommand 设置数据结构类型;
- String getKeyFromData(T data):设置value 中的键值对key的值;
- String getValueFromData(T data):设置value 中的键值对value的值。
使用RedisCommand设置数据结构类型时和redis结构对应关系如下表所示:
| Data Type | Redis Command [Sink] |
|---|---|
| HASH | HSET |
| LIST | RPUSH, LPUSH |
| SET | SADD |
| PUBSUB | PUBLISH |
| STRING | SET |
| HYPER_LOG_LOG | PFADD |
| SORTED_SET | ZADD |
| SORTED_SET | ZREM |
2.5.3.2 案例
需求:从Socket接收实时流数据做WordCount,并将结果写入到Redis
数据结构使用:
- 单词:数量 (key-String, value-String)
- wcresult: 单词:数量 (key-String, value-Hash)
【注意】:Redis的Key始终是String, value可以是:String/Hash/List/Set/有序Set
package org.example.connector;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import org.apache.flink.util.Collector;
public class RedisDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<String> lines = env.socketTextStream("node01", 9999);SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(<br /> new FlatMapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {<br /> String[] arr = s.split(" ");<br /> for (String word : arr) {<br /> collector.collect(Tuple2.of(word, 1));<br /> }<br /> }<br /> });SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(t -> t.f0).sum(1);res.print();// 保存到Redis中<br /> FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();<br /> RedisSink<Tuple2<String, Integer>> redisSink = new RedisSink<>(conf, new MyRedisMapper());env.execute();<br /> }public static class MyRedisMapper implements RedisMapper<Tuple2<String, Integer>> {@Override<br /> public RedisCommandDescription getCommandDescription() {<br /> // 我们选择的数据结构对应的是 key:String("wcresult"), value:Hash(单词,数量), 命令为HSET<br /> return new RedisCommandDescription(RedisCommand.HSET, "wcresult");<br /> }@Override<br /> public String getKeyFromData(Tuple2<String, Integer> t) {<br /> return t.f0;<br /> }@Override<br /> public String getValueFromData(Tuple2<String, Integer> t) {<br /> return t.f1.toString();<br /> }<br /> }<br />}

若有收获,就点个赞吧
0 人点赞
