3. Flink高级API
3.1 Flink四大基石
Flink流行的原因主要在于其四大基石:Checkpoint、State、Time和Window
image-20220425144508408
- Checkpoint(最重要特性):Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义;
- State:提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能够自动享受到这种一致性的语义;
- Time:Flink实现了Watermark的机制(这个概念在SparkStreaming中有提到过),能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据;
- Window:另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
3.2 窗口(Window)
3.2.1 窗口的作用
在流处理应用中,数据是连续不断的,有时我们需要做一些聚合类的处理,例如在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,必须定义一个窗口(window),用来收集最近1分钟内的数据,并对这个窗口内的数据进行计算。
3.2.2 窗口的分类
- 按照Time和Count分类:
- 时间窗口(Time-Window):根据时间划分窗口,如每XX分钟统计最近XX分钟的数据;
- 数量窗口(Count-Window):根据数量划分窗口,如每XX个数据统计最近XX个数据;

- 按照Slide和Size分类。窗口有两个重要的属性——窗口大小(size)和时间间隔(slide),根据它们的大小关系可以划分为如下几种窗口:
- 滚动窗口(Tumbling-Window):size = slide,比如每隔10秒统计近10秒的数据
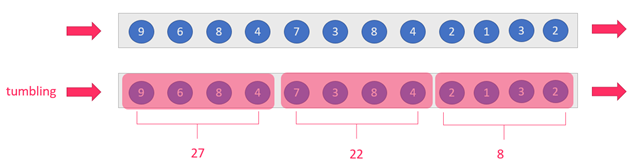
- image-20220428095946475
- 滑动窗口(Sliding-Window):size > slide,比如每隔5秒统计近10秒的数据
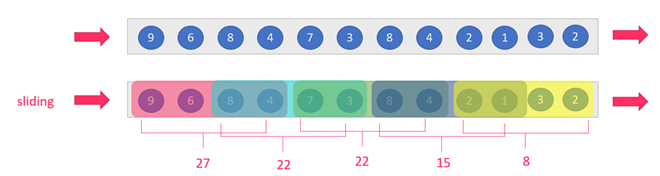
- image-20220428095956939
根据上面的分类方式,还可以组合出以下的窗口:
- 基于时间的滚动窗口(tumbling-time-window)—— 用的较多
- 基于时间的滑动窗口(sliding-time-window)—— 用的较多
- 基于数量的滚动窗口(tumbling-count-window)—— 用的较少
- 基于数量的滑动窗口(sliding-count-window)—— 用的较少
【注意】:Flink不支持会话窗口(Session-Window),会话窗口需要设置一个会话超时时间,如30s,则表示30s内没有数据到来,则触发上个窗口的计算。
3.2.3 窗口的API
3.2.3.1 简介
窗口的API主要有window和windowAll,如下图所示:
其中,
- window或windowAll 方法接收的输入是一个 WindowAssigner, WindowAssigner 负责将每条输入的数据分发到正确的 window 中,Flink种有很多种WindowAssigner:
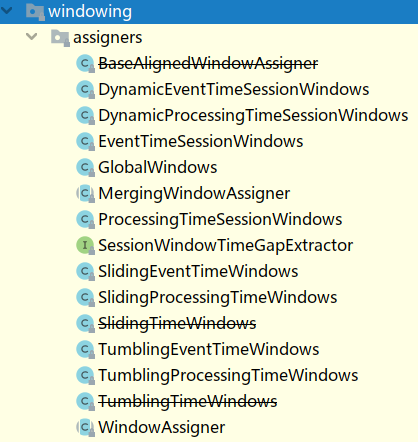
- image-20220428142137725
- evictor主要用于做一些数据的自定义操作,可以在执行用户代码之前,也可以在执行用户代码之后,Flink中有如下三种常用的evictor方法:
- CountEvictor:保留指定数量的元素;
- TimeEvictor:设定一个阈值 interval,删除所有不再 max_ts - interval 范围内的元素,其中 max_ts 是窗口内时间戳的最大值;
- DeltaEvictor:通过执行用户给定的 DeltaFunction 以及预设的 theshold,判断是否删除一个元素。
- trigger 用来判断一个窗口是否需要被触发,每个 WindowAssigner 都自带一个默认的trigger,如果默认的 trigger 不能满足你的需求,则可以自定义一个类,继承自Trigger 即可。Triger有以下几种常用的接口:
- onElement():每次往 window 增加一个元素的时候都会触发;
- onEventTime():当 event-time timer 被触发的时候会调用;
- onProcessingTime() :当 processing-time timer 被触发的时候会调用;
- onMerge(): 对两个 Trigger 的 state 进行 merge 操作;
- clear():window 销毁的时候被调用。
- 上面的接口中前三个会返回一个 TriggerResult, TriggerResult 有如下几种可能的选
- 择:
- CONTINUE —— 不做任何事情;
- FIRE —— 触发window;
- PURGE —— 清空整个 window 的元素并销毁窗口;
- FIRE_AND_PURGE —— 触发窗口,然后销毁窗口。
【注意】:
- 使用keyBy的流应该使用window方法;
- 未使用keyBy的流应该调用windowAll方法。
3.2.3.2 基于时间的滚动和滑动窗口
有以下数据,表示信号灯编号和通过信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
5,4
需求1:每5秒钟统计一次,最近5秒钟内,各个路口通过红绿灯汽车的数量 —— 基于时间的滚动窗口
需求2:每5秒钟统计一次,最近10秒钟内,各个路口通过红绿灯汽车的数量 —— 基于时间的滑动窗口
package org.example.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class TimeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<String> lines = env.socketTextStream("node01", 9999);SingleOutputStreamOperator<CarInfo> carDS = lines.map(<br /> new MapFunction<String, CarInfo>() {<br /> @Override<br /> public CarInfo map(String value) throws Exception {<br /> String[] arr = value.split(",");<br /> // 注意count要转成int类型<br /> return new CarInfo(arr[0], Integer.parseInt(arr[1]));<br /> }<br /> });// 由于要求的是每个红绿灯的结果,所以要先分组<br /> KeyedStream<CarInfo, String> keysDS = carDS.keyBy(CarInfo::getSensorId);// 实现需求1<br /> SingleOutputStreamOperator<CarInfo> result1 = keysDS.window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum("count");// 实现需求2<br /> SingleOutputStreamOperator<CarInfo> result2 = keysDS.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).sum("count");// result1.print();<br /> result2.print();env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class CarInfo {<br /> private String sensorId; // 信号灯的id<br /> private Integer count; // 通过信号灯的车的数量<br /> }<br />}<br />
3.2.3.3 基于数量的滚动和滑动窗口
同样是这些数据,表示信号灯编号和通过信号灯的车的数量
9,3
9,2
9,7
4,9
2,6
5,4
需求1:统计最近5次消息中,各个路口通过红绿灯汽车的数量,相同的key每出现5次进行统计 —— 基于数量的滚动窗口
需求2:统计最近5次消息中,各个路口通过红绿灯汽车的数量,相同的key每出现3次进行统计 —— 基于数量的滑动窗口
package org.example.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class CountWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<String> lines = env.socketTextStream("node01", 9999);SingleOutputStreamOperator<CarInfo> carDS = lines.map(<br /> new MapFunction<String, CarInfo>() {<br /> @Override<br /> public CarInfo map(String value) throws Exception {<br /> String[] arr = value.split(",");<br /> // 注意count要转成int类型<br /> return new CarInfo(arr[0], Integer.parseInt(arr[1]));<br /> }<br /> });// 由于要求的是每个红绿灯的结果,所以要先分组<br /> KeyedStream<CarInfo, String> keysDS = carDS.keyBy(CarInfo::getSensorId);// 实现需求1<br /> SingleOutputStreamOperator<CarInfo> result1 = keysDS.countWindow(5).sum("count");<br /> // 实现需求2<br /> SingleOutputStreamOperator<CarInfo> result2 = keysDS.countWindow(5, 3).sum("count");// result1.print();<br /> result2.print();env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class CarInfo {<br /> private String sensorId; // 信号灯的id<br /> private Integer count; // 通过信号灯的车的数量<br /> }<br />}<br />
3.2.3.4 会话窗口
需求:基于上面的例子,设定会话超时时间为10秒,10秒内数据没有来,则触发上一个窗口的计算
package org.example.window;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class SessionWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<String> lines = env.socketTextStream("node01", 9999);SingleOutputStreamOperator<CarInfo> carDS = lines.map(<br /> new MapFunction<String, CarInfo>() {<br /> @Override<br /> public CarInfo map(String value) throws Exception {<br /> String[] arr = value.split(",");<br /> // 注意count要转成int类型<br /> return new CarInfo(arr[0], Integer.parseInt(arr[1]));<br /> }<br /> });// 由于要求的是每个红绿灯的结果,所以要先分组<br /> KeyedStream<CarInfo, String> keysDS = carDS.keyBy(CarInfo::getSensorId);// 设置会话超时时间为10s,10s内没有数据到来,则触发上个窗口的计算(上个窗口有数据)<br /> SingleOutputStreamOperator<CarInfo> result = keysDS.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))).sum("count");result.print();env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class CarInfo {<br /> private String sensorId; // 信号灯的id<br /> private Integer count; // 通过信号灯的车的数量<br /> }<br />}<br />
3.3 Flink-Time和Watermarker
3.3.1 时间分类
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示: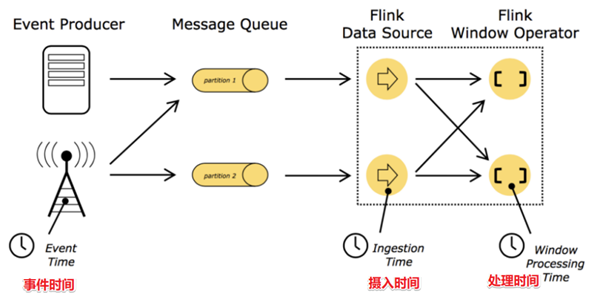
image-20220428145954585
- 事件时间(EventTime): 事件真真正正发生产生的时间;
- 摄入时间(IngestionTime): 事件到达Flink(计算框架)的时间;
- 处理时间(ProcessingTime):事件真正被处理/计算的时间。
这三种时间里我们更关注事件时间,因为它反应了事件的本质,事件时间一旦产生就不会变化。
3.3.2 EventTime的重要性
正如上一节所说的,我们希望基于时间窗口实际开发中我们希望基于事件时间来处理数据,但因为数据可能因为网络延迟等原因,出现了乱序或延迟到达,那么可能处理的结果不是我们想要的甚至出现数据丢失的情况,所以需要一种机制来解决一定程度上的数据乱序或延迟到底的问题。也就是接下来要学习的水位线机制(Watermarker)。
3.3.3 Watermarker基本概念和计算方式
- 定义:水位线是给数据再额外加的一个时间,本质是一个时间戳;
- 计算公式(两种,基于单一数据的和基于窗口的):
- 第二种方式可以保证水位线是是一直上升的,不会下降
- 作用:
- 之前的窗口都是依靠系统时间来触发计算,这种方式可能会丢失延迟到达的数据;
- 而当有了Watermarker后,就可以基于Watermarker来触发计算;
- 所以Watermarker就是用于触发窗口计算的。
- Watermarker就是用于触发窗口计算的方式,窗口计算的触发主要由以下两个条件:
- 窗口中有数据;
- Watermaker >= 窗口的结束时间 -> 当前窗口的最大的事件时间 >= 窗口的结束时间 + 最大允许的延迟时间或者乱序时间(这个公式也需要反复理解)。
3.3.4 Watermarker案例(难点,反复理解)
有一些订单数据,格式为(订单ID,用户ID,时间戳,订单金额)
需求:每隔5秒计算5秒内每个用户的订单总金额,并通过增加Watemarker来解决一定程度上的数据延迟问题。
package org.example.watermarker;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
public class Watermarker {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 这里的数据是通过自定义Source随机产生的<br /> DataStreamSource<Order> orderDS = env.addSource(<br /> new SourceFunction<Order>() {<br /> private Boolean flag = true;@Override<br /> public void run(SourceContext<Order> ctx) throws Exception {<br /> Random random = new Random();while (flag) {<br /> String orderId = UUID.randomUUID().toString();<br /> int userId = random.nextInt(2);<br /> int money = random.nextInt(101);<br /> // 模拟数据到达延迟<br /> long eventTime = System.currentTimeMillis() - random.nextInt(5) * 1000;<br /> ctx.collect(new Order(orderId, userId, money, eventTime));<br /> Thread.sleep(1000);<br /> }<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> });SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(<br /> // 指定maxOutOfOrderness 即最大无序度/最大允许的延迟时间/乱序时间<br /> WatermarkStrategy<br /> .<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))<br /> .withTimestampAssigner(<br /> // 指定事件的时间列<br /> (order, timestamp) -> order.getEventTime()<br /> )<br /> );SingleOutputStreamOperator<Order> result = orderDSWithWatermark.keyBy(Order::getUserId)<br /> .window(TumblingEventTimeWindows.of(Time.seconds(5)))<br /> .sum("money");result.print();env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class Order {<br /> private String orderId;<br /> private Integer userId;<br /> private Integer money;<br /> private Long eventTime;<br /> }<br />}<br />学习中可以使用如下代码来进行验证我们的流程:<br />package org.example.watermarker;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.time.FastDateFormat;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.text.DateFormat;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Random;
import java.util.UUID;
public class WatermarkerCheck {
public static void main(String[] args) throws Exception {
// 自定义的时间显示模板
FastDateFormat df = FastDateFormat.getInstance(“HH:mm:ss”);
// env<br /> StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();<br /> env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 这里的数据是通过自定义Source随机模拟产生的<br /> DataStreamSource<Order> orderDS = env.addSource(<br /> new SourceFunction<Order>() {<br /> private Boolean flag = true;@Override<br /> public void run(SourceContext<Order> ctx) throws Exception {<br /> Random random = new Random();while (flag) {<br /> String orderId = UUID.randomUUID().toString();<br /> int userId = random.nextInt(2);<br /> int money = random.nextInt(101);<br /> // 模拟数据到达延迟<br /> long eventTime = System.currentTimeMillis() - random.nextInt(5) * 1000;<br /> ctx.collect(new Order(orderId, userId, money, eventTime));<br /> Thread.sleep(1000);<br /> }<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> });<br /> /*<br /> SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(<br /> // 指定maxOutOfOrderness 即最大无序度/最大允许的延迟时间/乱序时间<br /> WatermarkStrategy<br /> 。<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))<br /> .withTimestampAssigner(<br /> // 指定事件的时间列<br /> (order, timestamp) -> order.getEventTime()<br /> )<br /> );<br /> */// 自己实现上述的过程进行验证<br /> SingleOutputStreamOperator<Order> watermarkerDS = orderDS.assignTimestampsAndWatermarks(<br /> new WatermarkStrategy<Order>() {<br /> @Override<br /> public WatermarkGenerator<Order> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {<br /> return new WatermarkGenerator<Order>() {<br /> private int userId = 0;<br /> private long eventTime = 0L;<br /> private final long outOfOrdernessMillis = 3000;<br /> private long maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1;@Override<br /> public void onEvent(Order event, long eventTimestamp, WatermarkOutput output) {<br /> userId = event.userId;<br /> eventTime = event.eventTime;<br /> maxTimestamp = Math.max(maxTimestamp, eventTimestamp);<br /> }@Override<br /> public void onPeriodicEmit(WatermarkOutput output) {<br /> Watermark watermark = new Watermark(maxTimestamp - outOfOrdernessMillis - 1);<br /> System.out.println("key:" + userId + ",系统时间:" +<br /> df.format(System.currentTimeMillis()) + ",事件时间:" +<br /> df.format(eventTime) + ",水位线时间:" +<br /> df.format(watermark.getTimestamp()));<br /> output.emitWatermark(watermark);<br /> }<br /> };<br /> }<br /> }.withTimestampAssigner((order, timestamp) -> order.getEventTime())<br /> );/*<br /> SingleOutputStreamOperator<Order> result = orderDSWithWatermark.keyBy(Order::getUserId)<br /> .window(TumblingEventTimeWindows.of(Time.seconds(5)))<br /> .sum("money");<br /> */// 同样也是自己实现上述的过程进行验证<br /> SingleOutputStreamOperator<String> result = watermarkerDS.keyBy(Order::getUserId)<br /> .window(TumblingEventTimeWindows.of(Time.seconds(5)))<br /> .apply(<br /> new WindowFunction<Order, String, Integer, TimeWindow>() {@Override<br /> public void apply(Integer key, TimeWindow window, Iterable<Order> orders, Collector<String> out) throws Exception {<br /> // 用来存放当前窗口的数据的格式化后的事件时间<br /> ArrayList<Object> list = new ArrayList<>();<br /> for (Order order : orders) {<br /> Long eventTime = order.eventTime;<br /> String formatEventTime = df.format(eventTime);<br /> list.add(formatEventTime);<br /> }<br /> String start = df.format(window.getStart());<br /> String end = df.format(window.getEnd());<br /> // 现在就已经获取到了当前窗口的开始和结束时间,以及属于该窗口的所有数据的事件时间,把这些拼接并返回<br /> String outStr = String.format("key:%s,窗口开始结束:[%s~%s),属于该窗口的事件时间:%s", key.toString(), start, end, list.toString());<br /> out.collect(outStr);}<br /> });result.print();env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class Order {<br /> private String orderId;<br /> private Integer userId;<br /> private Integer money;<br /> private Long eventTime;<br /> }<br />}<br />
3.3.5 Allowed Lateness(难点)
Allowed Lateness主要用于解决之前窗口已经关闭的延迟严重的数据的处理问题,可以用一个OutputTag将这类数据全部收集起来,具体的使用方式如下图所示: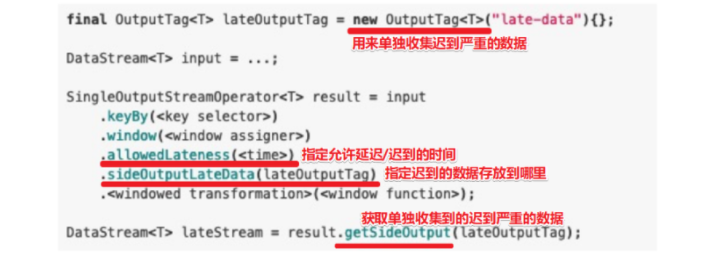
image-20220428164607412
下面来看一个案例:
需求:在上一节案例的基础上,使用 OutputTag + allowedLateness 解决延迟数据丢失问题
package org.example.watermarker;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
import java.util.Random;
import java.util.UUID;
public class AllowedLateness {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 这里的数据是通过自定义Source随机产生的<br /> DataStreamSource<Order> orderDS = env.addSource(<br /> new SourceFunction<Order>() {<br /> private Boolean flag = true;@Override<br /> public void run(SourceContext<Order> ctx) throws Exception {<br /> Random random = new Random();while (flag) {<br /> String orderId = UUID.randomUUID().toString();<br /> int userId = random.nextInt(2);<br /> int money = random.nextInt(101);<br /> // 模拟数据到达延迟,可能会出现严重延迟<br /> long eventTime = System.currentTimeMillis() - random.nextInt(20) * 1000;<br /> ctx.collect(new Order(orderId, userId, money, eventTime));<br /> Thread.sleep(1000);<br /> }<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> });SingleOutputStreamOperator<Order> orderDSWithWatermark = orderDS.assignTimestampsAndWatermarks(WatermarkStrategy<br /> // 指定maxOutOfOrderness 即最大无序度/最大允许的延迟时间/乱序时间<br /> .<Order>forBoundedOutOfOrderness(Duration.ofSeconds(3))<br /> .withTimestampAssigner(<br /> // 指定事件的时间列<br /> (order, timestamp) -> order.getEventTime()<br /> )<br /> );// 准备一个 OutputTag 来存放到达延迟的数据<br /> OutputTag<Order> seriousLateOutputTag = new OutputTag<>("seriousLate", TypeInformation.of(Order.class));SingleOutputStreamOperator<Order> result1 = orderDSWithWatermark<br /> .keyBy(Order::getUserId)<br /> .window(TumblingEventTimeWindows.of(Time.seconds(5)))<br /> .allowedLateness(Time.seconds(3))<br /> .sideOutputLateData(seriousLateOutputTag)<br /> .sum("money");DataStream<Order> result2 = result1.getSideOutput(seriousLateOutputTag);result1.print("正常的或迟到不严重的数据");<br /> result2.print("迟到严重的数据并丢弃后单独收集的数据");env.execute();<br /> }@Data<br /> @AllArgsConstructor<br /> @NoArgsConstructor<br /> public static class Order {<br /> private String orderId;<br /> private Integer userId;<br /> private Integer money;<br /> private Long eventTime;<br /> }<br />}<br />
3.4 状态管理
3.4.1 无状态计算和有状态计算
- 无状态计算
- 不需要考虑历史数据;
- 相同的输入得到相同的输出,比如map/flatMap/filter
- 例子——消费延迟计算
- 消息队列:一个生产者持续写入,多个消费者组分别读取;
- 如何实现统计每个消费者落后消费了多少条数据,输入输出如下:

- image-20220429085839987
- 实现过程:使用map把消息读取进来,然后分别相减,即可知道每个 consumer 分别落后了几条。map一直往下发,则会得出最终结果
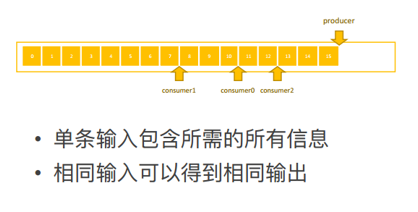
- image-20220429085813033
- 有状态计算
- 需要考虑历史数据
- 相同的输入不一定得到相同的输出,如sum/reduce
- 例子——访问量统计:这里需要结合用户的历史访问,所以是有状态计算
- 使用场景:

- image-20220429085623200
3.4.2 Flink中的有状态计算
前面写的Flink代码中其实已经做好了状态自动管理,如:
- 发送hello,得到(hello,1);
- 再发送hello,得到(hello,2)
说明Flink已经自动的将当前数据和历史状态/历史结果进行了聚合,做到了状态的自动管理。在实际开发中绝大多数情况下,我们直接使用自动管理即可,一些特殊情况才会使用手动的状态管理。
3.4.3 状态的分类
- ManagerState —— 开发中推荐使用,Fink自动管理/优化,支持多种数据结构
- KeyState —— 只能在keyedStream上使用,支持多种数据结构
- OperatorState —— 一般用在Source上,支持ListState
- RawState —— 完全由用户自己管理,只支持byte[],只能在自定义Operator上使用
- OperatorState

- OperatorState

- image-20220429090647190
下面来分别看一下KeyedState和OperatorState的代码演示:
- KeyedState
- 需求:使用KeyState中的ValueState获取数据中的最大值(实际中直接使用maxBy即可)
- package org.example.state;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KeyedStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
DataStreamSource<Tuple2<String, Long>> tupleDS = env.fromElements(<br /> Tuple2.of("北京", 1L),<br /> Tuple2.of("上海", 2L),<br /> Tuple2.of("北京", 6L),<br /> Tuple2.of("上海", 8L),<br /> Tuple2.of("北京", 3L),<br /> Tuple2.of("上海", 4L)<br /> );// 求各个城市的value的最大值<br /> SingleOutputStreamOperator<Tuple2<String, Long>> result1 = tupleDS.keyBy(t -> t.f0).maxBy(1);// 使用KeyState中的ValueState来实现maxBy的底层<br /> SingleOutputStreamOperator<Tuple3<String, Long, Long>> result2 = tupleDS.keyBy(t -> t.f0).map(<br /> new RichMapFunction<Tuple2<String, Long>, Tuple3<String, Long, Long>>() {<br /> // 定义一个涨停存放最大值<br /> private ValueState<Long> maxValueState;// 状态初始化<br /> @Override<br /> public void open(Configuration conf) {<br /> // 创建状态描述器<br /> ValueStateDescriptor stateDescriptor = new ValueStateDescriptor("maxValueState", Long.class);<br /> // 根据状态描述器取出或者初始化状态<br /> maxValueState = getRuntimeContext().getState(stateDescriptor);<br /> }// 使用状态<br /> @Override<br /> public Tuple3<String, Long, Long> map(Tuple2<String, Long> value) throws Exception {<br /> Long currentValue = value.f1;<br /> Long historyValue = maxValueState.value();<br /> // 判断状态<br /> if (historyValue == null || currentValue > historyValue) {<br /> historyValue = currentValue;<br /> // 更新状态<br /> maxValueState.update(historyValue);<br /> return Tuple3.of(value.f0, currentValue, historyValue);<br /> } else {<br /> return Tuple3.of(value.f0, currentValue, historyValue);<br /> }<br /> }<br /> });// result.print()<br /> result2.print();env.execute();<br /> }<br />}
- OperatorState
- 需求:使用OperatorState中的ListState模拟KafkaSource进行offset维护
- 编码步骤:
- 声明一个 OperatorState 来记录 offset
- 创建状态描述器
- 根据状态描述器获取State
- 获取State中的值
- 保存State到Checkpoint中
- 将offset存入State中
- package org.example.state;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.util.Iterator;
public class OpreatorStateDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 设定并行度为1,方便观察
env.setParallelism(1);
// 每隔1秒执行一次checkpoint
env.enableCheckpointing(1000);
env.setStateBackend(new FsStateBackend(“file:///D:/Flink Code/FlinkCore/ckp”));
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 设置固定延迟重启策略:程序出现异常的时候,重启2次,每次延迟3秒钟重启,超过2次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(2, 3000));
DataStreamSource<String> kafkaDS = env.addSource(new MyKafkaSource()).setParallelism(1);kafkaDS.print();env.execute();<br /> }// 使用OperatorState中的ListState模拟KafkaSource进行offset维护<br /> public static class MyKafkaSource extends RichParallelSourceFunction<String> implements CheckpointedFunction {<br /> private boolean flag = true;<br /> // 声明ListState<br /> private ListState<Long> offsetState = null; //用 来存放offset<br /> private Long offset = 0L; // 用来存放offset的值// 初始化ListState<br /> @Override<br /> public void initializeState(FunctionInitializationContext context) throws Exception {<br /> ListStateDescriptor<Long> stateDescriptor = new ListStateDescriptor<>("offsetState", Long.class);<br /> offsetState = context.getOperatorStateStore().getListState(stateDescriptor);<br /> }// 使用State<br /> @Override<br /> public void run(SourceContext<String> ctx) throws Exception {<br /> while(flag) {<br /> Iterator<Long> iterator = offsetState.get().iterator();<br /> if(iterator.hasNext()) {<br /> offset = iterator.next();<br /> }<br /> offset += 1;<br /> int subTaskId = getRuntimeContext().getIndexOfThisSubtask();<br /> ctx.collect("subTaskId:"+ subTaskId + ",当前的offset值为:" + offset);<br /> Thread.sleep(1000);// 模拟异常<br /> if(offset % 5 == 0) {<br /> System.out.println("ERROR");<br /> throw new Exception("ERROR");<br /> }<br /> }<br /> }// 持久化State<br /> // 该方法会定时执行将state状态从内存存入Checkpoint磁盘目录中<br /> @Override<br /> public void snapshotState(FunctionSnapshotContext context) throws Exception {<br /> offsetState.clear();<br /> offsetState.add(offset);<br /> }@Override<br /> public void cancel() {<br /> flag = false;<br /> }<br /> }<br />}
3.5 容错机制
3.5.1 Checkpoint
3.5.1.1 Checkpoint和State
- State:
- 存储或维护某一个算子(Operator)的运行的状态或历史值,注意维护在内存中;
- 一般指某个具体的Operator的状态(operator的状态表示一些算子在运行的过程中会产生的一些历史结果,如前面的maxBy的底层会维护当前的最大值,也就是会维护一个keyedOperator,这个State里面存放就是maxBy这个Operator中的最大值);
- State数据默认保存在Java的堆内存中或TaskManage节点的内存中;
- State可以被记录,在失败的情况下数据还可以恢复。
- Checkpoint:
- 某一时刻,Flink中所有的Operator的当前State的全局快照,一般存在磁盘上;
- 表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有Operator的状态;
- 可以理解为Checkpoint是把State数据定时持久化存储了;
- 比如KafkaConsumer算子中维护的Offset状态,当任务重新恢复的时候可以从Checkpoint中获取。
- 【注意】:
- Flink中的Checkpoint底层使用了Chandy-Lamport algorithm分布式快照算法可以保证数据的在分布式环境下的一致性;
3.5.1.2 Checkpoint执行流程
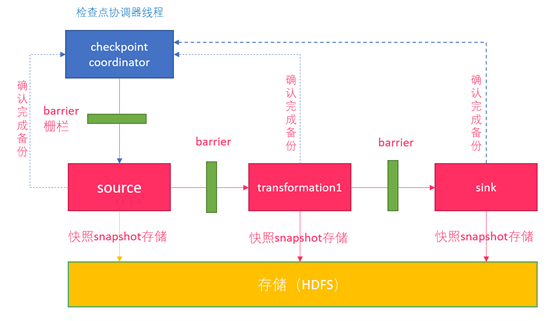
image-20220429165152193
- Flink的JobManager创建CheckpointCoordinator;
- Coordinator向所有的SourceOperator发送Barrier栅栏(理解为执行Checkpoint的信号);
- SourceOperator接收到Barrier之后,暂停当前的操作(暂停的时间很短,因为后续的写快照是异步的),并制作State快照,然后将自己的快照保存到指定的介质中(如HDFS),一切 ok 之后向Coordinator汇报并将Barrier发送给下游的其他Operator;
- 其他的如TransformationOperator接收到Barrier,重复第3步,最后将Barrier发送给Sink;
- Sink接收到Barrier之后重复第3步;
- Coordinator接收到所有的Operator的执行ok的汇报结果,认为本次快照执行成功。
【注意】:
- 为了提高效率,往HDFS中写入快照数据的时候是异步的。
3.5.1.3 状态后端或存储介质
前面学习了Checkpoint其实就是Flink中某一时刻所有的Operator的全局快照,那么快照应该要有一个地方进行存储,这个存储的地方叫做状态后端。Flink中的State状态后端有很多种:
- MemStateBackend —— 内存存储:
- 构造方法:MemoryStateBackend(int maxStateSize, boolean asynchronousSnapshots)
- 存储方式:
- State:TaskManager 内存
- Checkpoint:JobManager 内存
- 容量限制:
- 单个 State 的 maxStateSize 默认 5M;
- maxStateSize <= akka.framesize 默认 10M;
- Checkpoint 存储在 JobManager 内存中,因此总大小不超过 JobManager 的内存。
- 推荐使用的场景:
- 练习使用,不建议用于生产场景
- FsStateBackend —— 在文件系统上:
- 构造方法:FsStateBackend(URI checkpointDataUri, boolean asynchronousSnapshots)
- 存储方式:
- State:TaskManager 内存
- Checkpoint:外部文件系统(本地或者HDFS)
- 容量限制:
- 单 TaskManager 上的 State 总量不超过它的内存;
- 总大小不超过配置的文件系统容量;
- 推荐场景:
- 常规使用状态的作业
- 可用于生产环境
- RocksDBStateBackend—— key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中:
- 构造方法:RocksDBStateBackend(URI checkpointDataUri, boolean enablelncrementalCheckpoint)
- 存储方式:
- State:TaskManager 上的KV数据库(实际使用内存+磁盘)
- Checkpoint:外部文件系统(本地或者HDFS)
- 容量限制:
- 单 TaskManager 上的 State 总量不超过它的内存 + 磁盘;
- 单 Key 最大 2G;
- 总大小不超过配置的文件系统容量;
- 推荐场景:
- 超大状态的作业
- 可用于生产环境
3.5.1.4 配置方式
- 全局配置:在flink-conf.yaml中加入如下内容:
jobmanager(即MemoryStateBackend),
# filesystem(即FsStateBackend),
# rocksdb(即RocksDBStateBackend)
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:8020/flink/checkpoints- 代码中配置(这部分重点理解下各种配置参数的含义):
- package org.example.checkpoint;
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class CheckpointDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// checkpoint设置<br /> // 1.必要参数<br /> // 设置Checkpoint的时间间隔为1000ms做一次Checkpoint,其实就是每隔1000ms发一次Barrier<br /> env.enableCheckpointing(1000);// 设置State状态存储介质/状态后端<br /> // Memory: State存内存, Checkpoint存内存 -- 开发不用<br /> // Fs: State存内存,Checkpoint存FS(本地/HDFS) -- 一般情况下使用<br /> // RocksDB: State存RocksDB(内存+磁盘),Checkpoint存FS(本地/HDFS) -- 超大状态使用,但是对于状态的读写效率要低一点<br /> if (SystemUtils.IS_OS_WINDOWS) {<br /> env.setStateBackend(new FsStateBackend("file:///D:/ckp"));<br /> } else {<br /> env.setStateBackend(new FsStateBackend("hdfs://node01:8020/flink-checkpoint/checkpoint"));<br /> }// 2.建议设置的参数<br /> // 设置两个Checkpoint之间最少等待时间,如设置Checkpoint之间最少是要等500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)<br /> env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);<br /> // 默认值为0,表示不容忍任何检查点失败<br /> env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);<br /> // 设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除<br /> // ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)<br /> // ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint<br /> env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 3.直接使用默认的参数<br /> // 设置checkpoint的执行模式为EXACTLY_ONCE<br /> env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);<br /> // 设置checkpoint的超时时间,如果 Checkpoint 在60s内尚未完成说明该次Checkpoint失败,则丢弃<br /> env.getCheckpointConfig().setCheckpointTimeout(60000);<br /> // 设置同一时间有多少个checkpoint可以同时执行<br /> env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);DataStreamSource<String> socketDS = env.socketTextStream("node01", 9999);SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = socketDS.flatMap(<br /> new FlatMapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public void flatMap(String value, Collector<Tuple2<String, Integer>> output) throws Exception {<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> output.collect(Tuple2.of(word, 1));<br /> }<br /> }<br /> });SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(t -> t.f0).sum(1);<br /> <br /> res.print();<br /> <br /> env.execute();<br /> }<br />}
- 【注意】:
- RocksDBStateBackend还需要引入依赖
org.apache.flink
flink-statebackend-rocksdb_2.11
1.7.2
3.5.2 状态恢复和重启策略
3.5.2.1 自动重启策略和恢复
- 配置方式:
- 配置文件中配置
- 在flink-conf.yml中加入以下内容:
- restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10s - 代码中配置
- package org.example.checkpoint;
import org.apache.commons.lang3.SystemUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.util.Collector;
import java.util.concurrent.TimeUnit;
import static org.apache.flink.api.common.time.Time.*;
public class RestartDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// checkpoint设置<br /> // 1.必要参数<br /> // 设置Checkpoint的时间间隔为1000ms做一次Checkpoint,其实就是每隔1000ms发一次Barrier<br /> env.enableCheckpointing(1000);// 设置State状态存储介质/状态后端<br /> // Memory: State存内存, Checkpoint存内存 -- 开发不用<br /> // Fs: State存内存,Checkpoint存FS(本地/HDFS) -- 一般情况下使用<br /> // RocksDB: State存RocksDB(内存+磁盘),Checkpoint存FS(本地/HDFS) -- 超大状态使用,但是对于状态的读写效率要低一点<br /> if (SystemUtils.IS_OS_WINDOWS) {<br /> env.setStateBackend(new FsStateBackend("file:///D:/ckp"));<br /> } else {<br /> env.setStateBackend(new FsStateBackend("hdfs://node01:8020/flink-checkpoint/checkpoint"));<br /> }// 2.建议设置的参数<br /> // 设置两个Checkpoint之间最少等待时间,如设置Checkpoint之间最少是要等500ms(为了避免每隔1000ms做一次Checkpoint的时候,前一次太慢和后一次重叠到一起去了)<br /> env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);<br /> // 默认值为0,表示不容忍任何检查点失败<br /> env.getCheckpointConfig().setTolerableCheckpointFailureNumber(10);<br /> // 设置是否清理检查点,表示 Cancel 时是否需要保留当前的 Checkpoint,默认 Checkpoint会在作业被Cancel时被删除<br /> // ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:true,当作业被取消时,删除外部的checkpoint(默认值)<br /> // ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:false,当作业被取消时,保留外部的checkpoint<br /> env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 3.直接使用默认的参数<br /> // 设置checkpoint的执行模式为EXACTLY_ONCE<br /> env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);<br /> // 设置checkpoint的超时时间,如果 Checkpoint 在60s内尚未完成说明该次Checkpoint失败,则丢弃<br /> env.getCheckpointConfig().setCheckpointTimeout(60000);<br /> // 设置同一时间有多少个checkpoint可以同时执行<br /> env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 配置重启策略<br /> // 固定延迟重启<br /> // 下面的设置表示: 如果job失败,重启3次,每次间隔5s<br /> env.setRestartStrategy(RestartStrategies.fixedDelayRestart(<br /> 3,<br /> Time.of(5, TimeUnit.SECONDS)<br /> ));DataStreamSource<String> socketDS = env.socketTextStream("node01", 9999);SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = socketDS.flatMap(<br /> new FlatMapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public void flatMap(String value, Collector<Tuple2<String, Integer>> output) throws Exception {<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> if(word.equals("bug")) {<br /> System.out.println("bug");<br /> throw new Exception("bug");<br /> }<br /> output.collect(Tuple2.of(word, 1));<br /> }<br /> }<br /> });SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(t -> t.f0).sum(1);res.print();env.execute();<br /> }<br />}
- 重启策略分类
- 默认重启策略:如果配置了Checkpoint,而没有配置重启策略,那么代码中出现了非致命错误时,程序会无限重启;
- 无重启策略:Job执行失败,不会尝试重启
- 固定延迟策略 —— 开发中常用:采用固定策略的方式进行重启,可以在配置文件中设置也可以在代码中设置
- 失败重启策略 —— 开发中偶尔使用,设置方式如下:
- // 该设置表示如果5分钟内job失败不超过三次,自动重启,每次间隔10s (如果5分钟内程序失败超过3次,则程序退出)
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), // 失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启的时间间隔
))
3.5.2.2 手动重启
- 把程序打包;
- 启动Flink集群(本地单机版,集群版都可以);
- 访问webUI;
- 使用FlinkWebUI提交;
- 取消任务;
- 重新启动任务并指定从哪(指检查点的保存路径)恢复;
- 关闭/取消任务;
- 关闭集群;
3.5.2.3 Savepoint
Savepoint类似于游戏中的存档点。在实际开发中,可能会遇到这样的情况:如要对集群进行停机维护/扩容,那么这时候需要执行一次Savepoint(也就是执行一次手动的Checkpoint或手动的发一个barrier栅栏),此时程序的所有状态都会被执行快照并保存。当维护/扩容完毕之后,可以从上一次Savepoint的目录中进行恢复。
Savepoint和Checkpoint主要有如下区别:
| Checkpoint | Savepoint | |
|---|---|---|
| 触发管理方式 | Flink自动触发 | 用户手动触发 |
| 用途 | 在Task出现异常时进行恢复 | 有计划的进行备份,使作业停止后可以恢复 |
| 特点 | 轻量,自动从故障中恢复,作业停止后会自动消除 | 持久,以标准格式存储,允许代码或者配置发生变化,手动触发恢复 |
| 目标 | 任务失败恢复或者故障转移机制 | 手动备份任务 |
| 实现 | 轻量快速 | 注重可移植性,成本较高 |
| 生命周期 | Flink自身控制 | 用户手动控制 |

若有收获,就点个赞吧
0 人点赞
