1.1 简介

1.1.1 组件栈
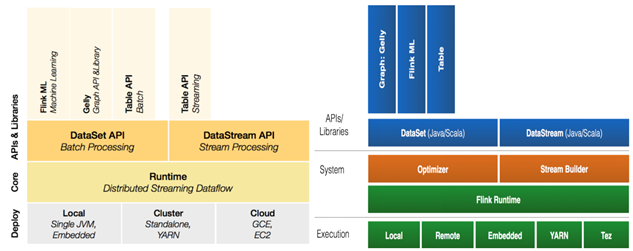
- 物理部署层:支持本地部署、独立集群部署、部署在Yarn管理的集群上或云服务器上;
- Runtime核心层:主要提供支持Flink计算的全部核心实现,为上层API提供基础服务,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。将DataSteam和DataSet转成统一的可执行的Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的;
- API层:Flink支持Scala、Java和Python多语言开发。DataStream、DataSet、Table、SQL API,作为分布式数据处理框架,Flink同时提供了支撑计算和批计算的接口,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,也提供比较低级的Process Function API,用户可以直接操作状态和时间等底层数据;
- 扩展库:Flink 还包括用于复杂事件处理的CEP,机器学习库FlinkML,图处理库Gelly等。
【注意】:Flink 1.12中舍弃了DataSet,而是使用DataStream做流批一体式处理。
1.1.2 Flink基石
Flink流行的原因主要在于其四个基石:Checkpoint、State、Time和Window
- Checkpoint(最重要特性):Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义;
- State:提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能够自动享受到这种一致性的语义;
- Time:除此之外,Flink还实现了Watermark的机制(这个概念在StructedStreaming中有提到过),能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据;
- Window:另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
1.1.3 应用场景
Flink可以用于任何流计算场景,比如数据的实时处理、实时数据的监控以及实时数仓的构建等。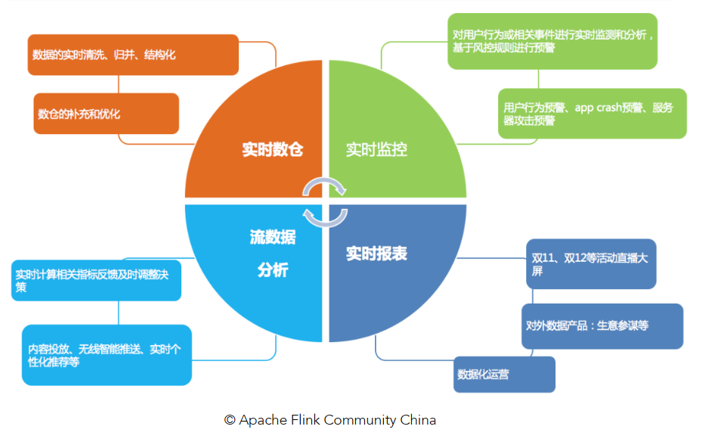
主要集中在以下三大场景:
- 事件驱动应用(Event-driven Applications):
- 事件驱动型应用从计算存储分离的传统应用基础上进化而来,是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作;
- 在传统架构中,应用需要读写远程事务型数据库。相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据;
- 示例:业务流程监控、异常检测等。
- 数据分析:从海量数据中分析得到有价值的信息;
数据管道:
下载安装包;
- 上传安装包到node01并解压:
- (这里由于scala 2.12版本的不支持Shell,所以用的2.11)
- rz -e
tar -zxvf flink-1.12.0-bin-scala_2.11.tgz
mv flink-1.12.0 /export/servers/ - 创建软连接(不创建也行)
- ln -s flink-1.12.0 flink-1.12
- 测试
- 准备测试文件:这里直接使用export中的words.txt作为测试文件
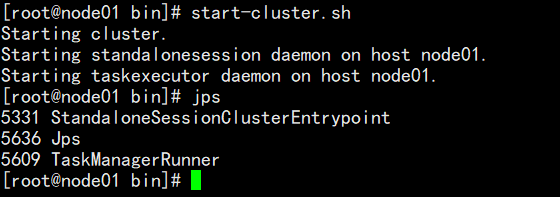
- 启动本地集群:
- /export/servers/flink-1.12/bin/start-cluster.sh
- 通过jps命令可以看到多了两个进程TaskManagerRunner和StandaloneSessionClusterEntrypoint
- 访问Flink的WebUI
- WebUI的地址是:http://node01:8081;
- Slots在Flink中可以理解为资源组,Flink通过将任务划分为子任务并且将这些子任务分配到Slot来并行执行程序。
- 执行官方示例
- /export/servers/flink-1.12/bin/flink run /export/servers/flink-1.12/examples/batch/WordCount.jar —input /export/words.txt —output /export/out
- 停止Flink
- /export/servers/flink-1.12/bin/stop-cluster.sh

【补充】:
Flink的shell交互命令:
- 启动命令:
- /export/servers/flink-1.12/bin/start-scala-shell.sh local
- 执行示例:
- benv.readTextFile(“/export/words.txt”).flatMap(.split(“ “)).map((,1)).groupBy(0).sum(1).print()
- 结果如下图所示:

1.2.2 Standalone独立集群模式
1.2.2.1 原理
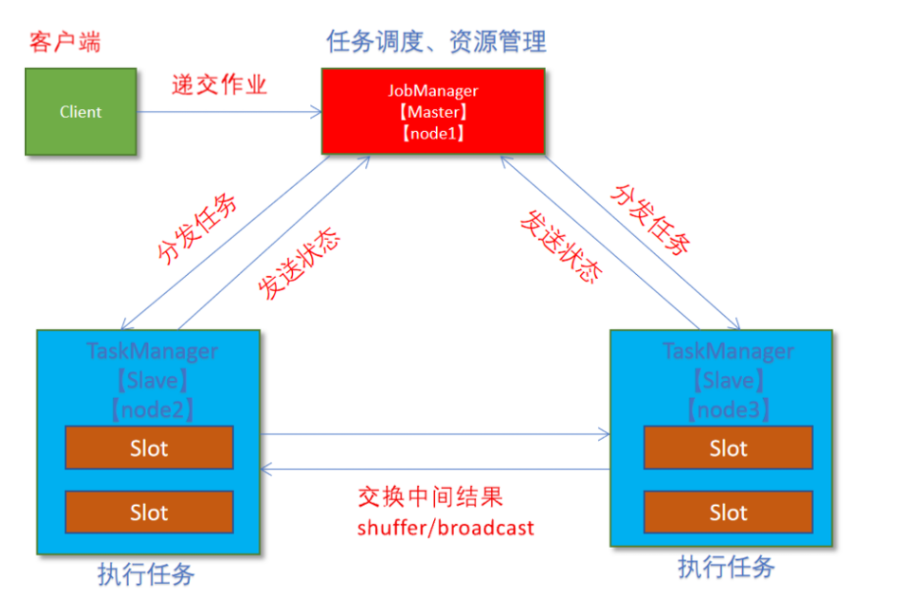
1.2.2.2 部署步骤与测试
- 集群规划
- node01(Master + Slave):JobManager + TaskManager
- node02(Slave):TaskManager
- node03(Slave):TaskManager
- 修改配置文件flink-conf.yaml
- vim /export/servers/flink-1.12/conf/flink-conf.yaml
- 然后将以下内容加入到配置文件中:
- jobmanager.rpc.address: node01
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
# 历史服务器
jobmanager.archive.fs.dir: hdfs://node01:8020/flink/completed-jobs/
historyserver.web.address: node01
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://node1:8020/flink/completed-jobs/ - 修改masters
- vim /export/servers/flink-1.12/conf/masters
- 在文件中添加如下内容:
- node01:8081
- 修改workers
- vim /export/server/flink/conf/workers
- 然后添加如下内容:
- node01
node02
node03 - 添加HADOOP_CONF_DIR环境变量
- 在三台虚拟机上执行以下操作
- vim /etc/profile
- 添加如下内容
- export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
- 分发:
- for i in {2..3}; do scp -r flink-1.12.0 node0$i:$PWD; done
- 激活环境变量:在每台虚拟机上执行以下命令
- source /etc/profile
然后来测试一下,首先在node01上启动集群
/export/servers/flink-1.12/bin/start-cluster.sh
然后启动历史服务器:
/export/servers/flink-1.12/bin/historyserver.sh start
访问Flink UI界面
执行官方测试案例
/export/servers/flink-1.12/bin/flink run /export/servers/flink-1.12/examples/batch/WordCount.jar —input /export/words.txt —output /export/out
1.2.3 Standalone-HA高可用独立集群模式
1.2.3.1 原理
高可用的主要目的是在node01故障时,用一个备用的Master node02顶上来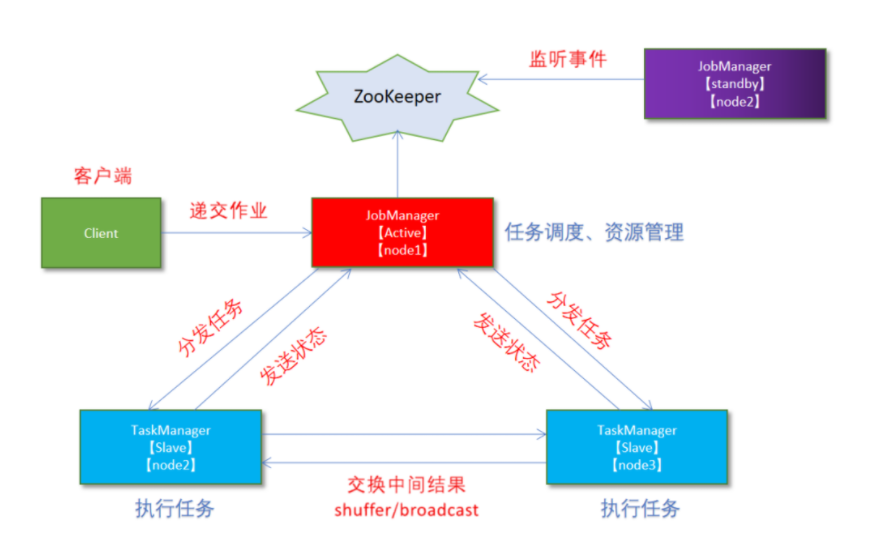
1.2.3.2 部署步骤
- 集群规划
- node01(Master + Slave):JobManager + TaskManager
- node02(Master + Slave):JobManager + TaskManager
- node03(Slave):TaskManager
- 启动Zookeeper
- zkServer.sh status
zkServer.sh stop
zkServer.sh start - 启动HDFS
- /export/servers/hadoop-2.7.5/sbin/start-dfs.sh
- 停止Flink集群
- /export/servers/flink-1.12/bin/stop-cluster.sh
- 修改配置文件flink-conf.yaml
- 在node01的flink-conf.yaml中增加如下内容:
- state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://node01:8020/flink-checkpoints
high-availability: zookeeper
high-availability.storageDir: hdfs://node01:8020/flink/ha/
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181 - 修改Masters
- vim /export/servers/flink-1.12/conf/masters
- 增加如下内容:
- node01:8081
node02:8081 - 分发
- scp -r /export/servers/flink-1.12.0/conf/flink-conf.yaml node02:/export/servers/flink-1.12.0/conf/
scp -r /export/servers/flink-1.12.0/conf/flink-conf.yaml node03:/export/servers/flink-1.12.0/conf/
scp -r /export/servers/flink-1.12.0/conf/masters node02:/export/servers/flink-1.12.0/conf/
scp -r /export/servers/flink-1.12.0/conf/masters node03:/export/servers/flink-1.12.0/conf/
- 修改node02上的flink-conf.yaml
- 在node01的flink-conf.yaml中修改如下内容:
- jobmanager.rpc.address: node02
然后测试一下:
- 首先重新启动Flink集群
- /export/servers/flink-1.12.0/bin/start-cluster.sh
- 使用JPS查看相关的进程:

- 发现没有相关进程,这里是因为在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar包,具体可以通过查看日志得到,命令如下:
- cat /export/servers/flink-1.12.0/log/flink-root-standalonesession-0-node01.log

- 所以需要在官网中下载对应的jar包并放入Flink的lib目录下,使Flink能够支持对Hadoop的操作,下载地址如下:
- 然后将其上传到Flink的lib目录并分发即可:
- for i in {2..3}; do scp -r flink-shaded-hadoop-2-uber-2.7.5-10.0.jar node0$i:$PWD; done
- 然后重新启动集群,再查看一下进程:
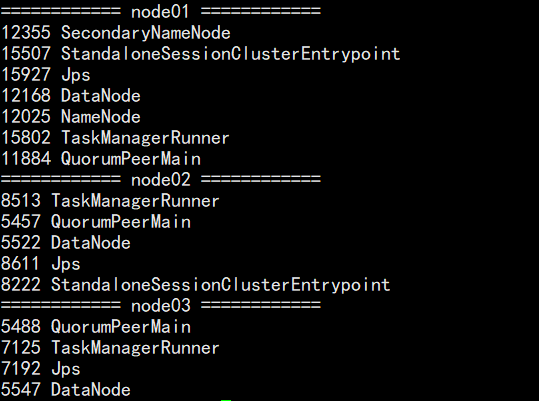
- 可以看到现在的就有那几个进程了。
- 现在执行wordcount程序:
- /export/servers/flink-1.12/bin/flink run /export/servers/flink-1.12/examples/batch/WordCount.jar
- Kill掉其中一个Master,这里选择Kill node01
kill -9 3522
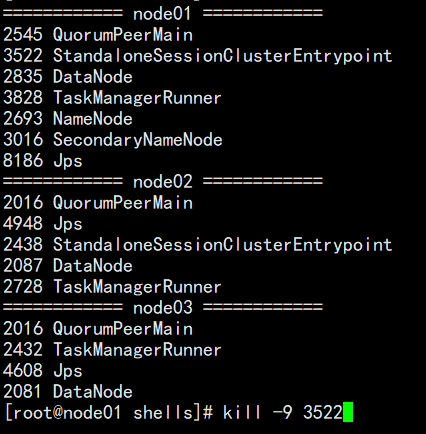
- 重新执行WordCount程序,发现还是可以成功运行,只是此时Master变为了node02
- /export/servers/flink-1.12/bin/flink run /export/servers/flink-1.12/examples/batch/WordCount.jar
1.2.4 Flink-On-Yarn模式
1.2.4.1 原理
Flink在实际开发中主要使用的是Flink-On-Yarn模式,主要原因如下:
- Yarn的资源可以按需使用,提高集群的资源利用率;
- Yarn的任务有优先级,可以根据优先级运行作业;
- 基于Yarn调度系统,能够自动化地处理各个角色的Failover(容错):
- ○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控;
- ○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器;
- ○ 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager。
1.2.4.2 Flink与Yarn交互的方式和过程
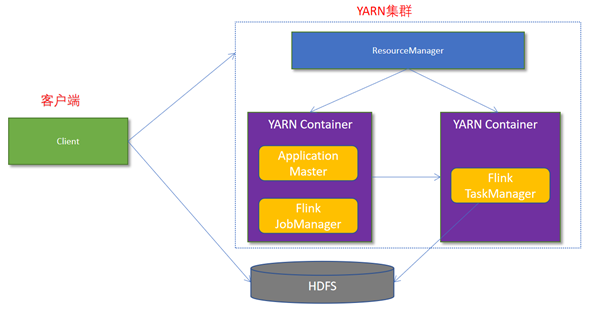
具体的过程如下: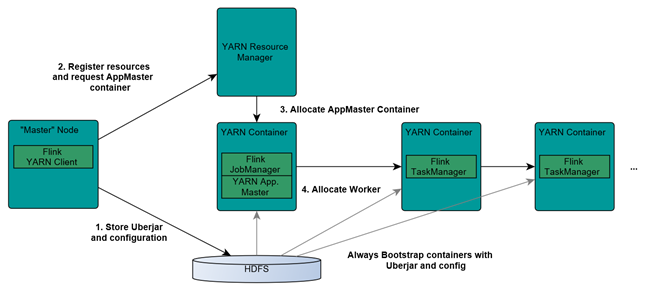
- Client上传jar包和配置文件到HDFS集群上;
- Client 向Yarn ResourceManager 提交任务并申请资源;
- ResourceManager 分配 Container 资源并启动 ApplicationMaster,然后 AppMaster 加载 Flink 的 Jar 包和配置构建环境,启动JobManager;
- JobManager和ApplicationMaster运行在同一个container上。一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。这个配置文件也被上传到HDFS上。此外,AppMaster容器也提供了Flink的web服务接口。YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager;
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
1.2.4.3 两种部署模式
- Session模式:在Yarn集群中启动Flink集群,并重复使用该集群

- 特点:需要事先申请资源,启动 JobManager和TaskManager;
- 优点:不需要每次提交作业申请资源,而是用已经申请好的资源,从而提高执行效率;
- 缺点:作业执行完毕后,资源不会被释放,因此会一直占用资源;
- 适用场景:适合小作业比较多,并且作业提交频繁的场景。
- Pre-Job模式:针对每一个Flink任务,都去启动一个独立的Flink集群,不能重复使用该Yarn集群
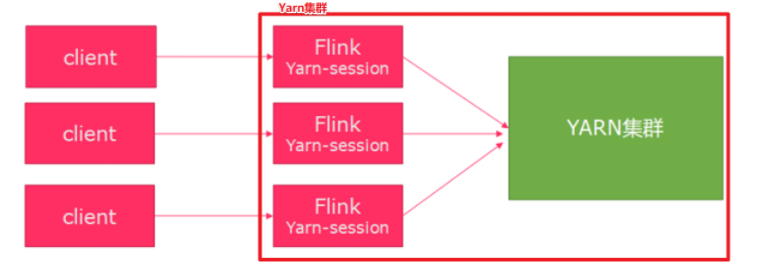
- 特点:每一次提交作业都要申请资源;
- 优点:作业运行完成时资源会立刻释放,不会一直占用系统资源;
- 缺点:每次作业提交都需要申请资源,会影响执行效率;
- 适用场景:适合大作业或作业提交较少的场景。
1.2.4.4 配置
- 关闭YARN的内存检查(三台都要做,其实在之前Spark的学习中已经做了)
- vim /export/servers/hadoop-2.7.5/etc/hadoop/yarn-site.xml
- 修改或增加如下内容:
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
- /export/servers/flink-1.12/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
- 参数说明:
- -n:表示申请2个容器,这里指的就是多少个taskmanager;
- -tm:表示每个TaskManager的内存大小;
- -s:表示每个TaskManager的slots数量;
- -d:表示以后台程序方式运行
- 查看WebUI界面:http://node01:8088/cluster
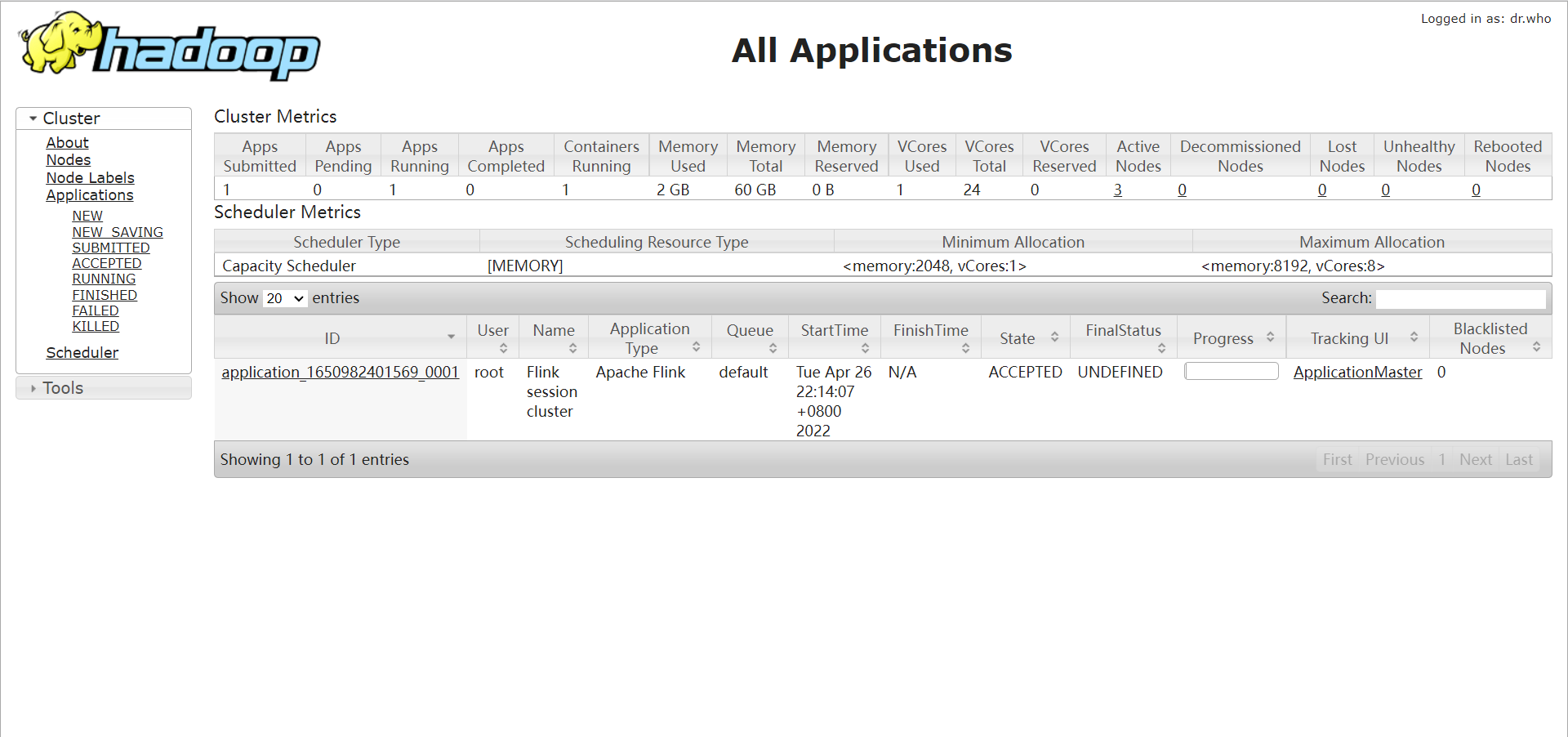
- 使用 flink run 提交命令
- /export/servers/flink-1.12/bin/flink run /export/servers/flink-1.12/examples/batch/WordCount.jar
- 通过上方的ApplicationMaster可以进入Flink的管理界面
-
1.2.4.5.2 分离模式(实际开发中常用)
直接提交job即可,命令如下:
- /export/servers/flink-1.12/bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 /export/servers/flink-1.12/examples/batch/WordCount.jar
- 参数说明如下:
- -m:jobmanager的地址
- -yjm 1024 :指定jobmanager的内存信息
- -ytm 1024 :指定taskmanager的内存信息

【补充】:
Flink查看参数帮助的命令:
/export/servers/flink-1.12/bin/flink —help
1.3 Flink入门案例
1.3.1 Flink的编程模型
一个成熟的Flink应用程序应该包含以下三个部分:
- Source
- Transdormation
- Sink

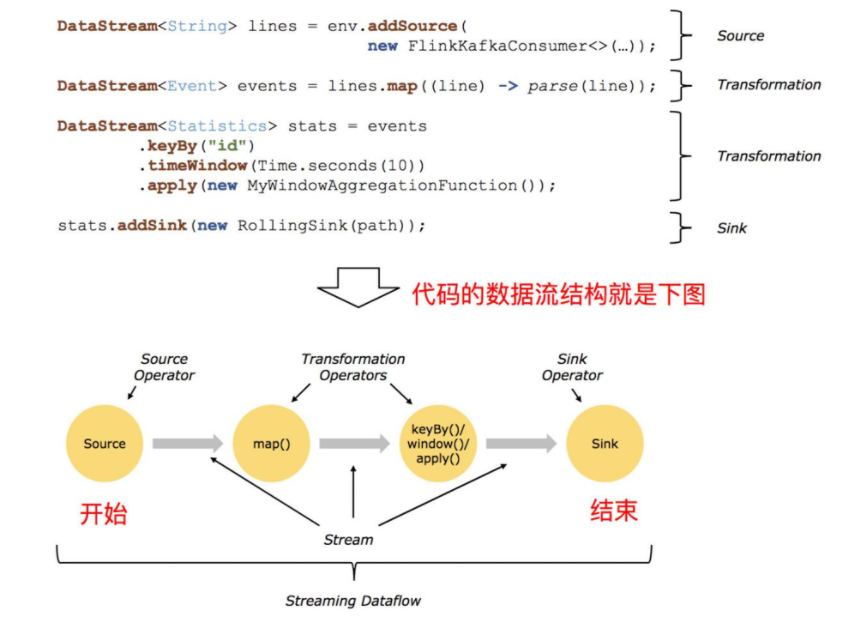
1.3.2 Flink编程前准备
导入相关的pom依赖,可根据实际的需求去掉没必要的依赖:
<properties><br /> <encoding>UTF-8</encoding><br /> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><br /> <maven.compiler.source>1.8</maven.compiler.source><br /> <maven.compiler.target>1.8</maven.compiler.target><br /> <java.version>1.8</java.version><br /> <scala.version>2.12</scala.version><br /> <flink.version>1.12.0</flink.version><br /> </properties><dependencies><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-clients_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-scala_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-java</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-streaming-scala_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-streaming-java_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-table-api-scala-bridge_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-table-api-java-bridge_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <!-- flink执行计划,这是1.9版本之前的--><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-table-planner_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <!-- blink执行计划,1.11+默认的--><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-table-planner-blink_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-table-common</artifactId><br /> <version>${flink.version}</version><br /> </dependency><!--<dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-cep_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency>--><!-- flink连接器--><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-connector-kafka_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-sql-connector-kafka_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-connector-jdbc_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-csv</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-json</artifactId><br /> <version>${flink.version}</version><br /> </dependency><!-- <dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-connector-filesystem_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency>--><br /> <!--<dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-jdbc_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency>--><br /> <!--<dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-parquet_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency>--><br /> <!--<dependency><br /> <groupId>org.apache.avro</groupId><br /> <artifactId>avro</artifactId><br /> <version>1.9.2</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.parquet</groupId><br /> <artifactId>parquet-avro</artifactId><br /> <version>1.10.0</version><br /> </dependency>--><dependency><br /> <groupId>org.apache.bahir</groupId><br /> <artifactId>flink-connector-redis_2.11</artifactId><br /> <version>1.0</version><br /> <exclusions><br /> <exclusion><br /> <artifactId>flink-streaming-java_2.11</artifactId><br /> <groupId>org.apache.flink</groupId><br /> </exclusion><br /> <exclusion><br /> <artifactId>flink-runtime_2.11</artifactId><br /> <groupId>org.apache.flink</groupId><br /> </exclusion><br /> <exclusion><br /> <artifactId>flink-core</artifactId><br /> <groupId>org.apache.flink</groupId><br /> </exclusion><br /> <exclusion><br /> <artifactId>flink-java</artifactId><br /> <groupId>org.apache.flink</groupId><br /> </exclusion><br /> </exclusions><br /> </dependency><dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-connector-hive_2.12</artifactId><br /> <version>${flink.version}</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.hive</groupId><br /> <artifactId>hive-metastore</artifactId><br /> <version>2.1.0</version><br /> </dependency><br /> <dependency><br /> <groupId>org.apache.hive</groupId><br /> <artifactId>hive-exec</artifactId><br /> <version>2.1.0</version><br /> </dependency><dependency><br /> <groupId>org.apache.flink</groupId><br /> <artifactId>flink-shaded-hadoop-2-uber</artifactId><br /> <version>2.7.5-10.0</version><br /> </dependency><dependency><br /> <groupId>org.apache.hbase</groupId><br /> <artifactId>hbase-client</artifactId><br /> <version>2.1.0</version><br /> </dependency><dependency><br /> <groupId>mysql</groupId><br /> <artifactId>mysql-connector-java</artifactId><br /> <version>5.1.38</version><br /> <!--<version>8.0.20</version>--><br /> </dependency><!-- 高性能异步组件:Vertx--><br /> <dependency><br /> <groupId>io.vertx</groupId><br /> <artifactId>vertx-core</artifactId><br /> <version>3.9.0</version><br /> </dependency><br /> <dependency><br /> <groupId>io.vertx</groupId><br /> <artifactId>vertx-jdbc-client</artifactId><br /> <version>3.9.0</version><br /> </dependency><br /> <dependency><br /> <groupId>io.vertx</groupId><br /> <artifactId>vertx-redis-client</artifactId><br /> <version>3.9.0</version><br /> </dependency><!-- 日志 --><br /> <dependency><br /> <groupId>org.slf4j</groupId><br /> <artifactId>slf4j-log4j12</artifactId><br /> <version>1.7.7</version><br /> <scope>runtime</scope><br /> </dependency><br /> <dependency><br /> <groupId>log4j</groupId><br /> <artifactId>log4j</artifactId><br /> <version>1.2.17</version><br /> <scope>runtime</scope><br /> </dependency><dependency><br /> <groupId>com.alibaba</groupId><br /> <artifactId>fastjson</artifactId><br /> <version>1.2.44</version><br /> </dependency><dependency><br /> <groupId>org.projectlombok</groupId><br /> <artifactId>lombok</artifactId><br /> <version>1.18.2</version><br /> <scope>provided</scope><br /> </dependency><!-- 参考:[https://blog.csdn.net/f641385712/article/details/84109098-->](https://blog.csdn.net/f641385712/article/details/84109098--%3E)<br /> <!--<dependency><br /> <groupId>org.apache.commons</groupId><br /> <artifactId>commons-collections4</artifactId><br /> <version>4.4</version><br /> </dependency>--><br /> <!--<dependency><br /> <groupId>org.apache.thrift</groupId><br /> <artifactId>libfb303</artifactId><br /> <version>0.9.3</version><br /> <type>pom</type><br /> <scope>provided</scope><br /> </dependency>--><br /> <!--<dependency><br /> <groupId>com.google.guava</groupId><br /> <artifactId>guava</artifactId><br /> <version>28.2-jre</version><br /> </dependency>--></dependencies><build><br /> <sourceDirectory>src/main/java</sourceDirectory><br /> <plugins><br /> <!-- 编译插件 --><br /> <plugin><br /> <groupId>org.apache.maven.plugins</groupId><br /> <artifactId>maven-compiler-plugin</artifactId><br /> <version>3.5.1</version><br /> <configuration><br /> <source>1.8</source><br /> <target>1.8</target><br /> <!--<encoding>${project.build.sourceEncoding}</encoding>--><br /> </configuration><br /> </plugin><br /> <plugin><br /> <groupId>org.apache.maven.plugins</groupId><br /> <artifactId>maven-surefire-plugin</artifactId><br /> <version>2.18.1</version><br /> <configuration><br /> <useFile>false</useFile><br /> <disableXmlReport>true</disableXmlReport><br /> <includes><br /> <include>**/*Test.*</include><br /> <include>**/*Suite.*</include><br /> </includes><br /> </configuration><br /> </plugin><br /> <!-- 打包插件(会包含所有依赖) --><br /> <plugin><br /> <groupId>org.apache.maven.plugins</groupId><br /> <artifactId>maven-shade-plugin</artifactId><br /> <version>2.3</version><br /> <executions><br /> <execution><br /> <phase>package</phase><br /> <goals><br /> <goal>shade</goal><br /> </goals><br /> <configuration><br /> <filters><br /> <filter><br /> <artifact>*:*</artifact><br /> <excludes><br /> <!--<br /> zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF --><br /> <exclude>META-INF/*.SF</exclude><br /> <exclude>META-INF/*.DSA</exclude><br /> <exclude>META-INF/*.RSA</exclude><br /> </excludes><br /> </filter><br /> </filters><br /> <transformers><br /> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><br /> <!-- 设置jar包的入口类(可选) --><br /> <mainClass></mainClass><br /> </transformer><br /> </transformers><br /> </configuration><br /> </execution><br /> </executions><br /> </plugin><br /> </plugins><br /> </build>
1.3.3 DataStream实现WordCount——批处理形式
package org.example.datastream;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.flink.api.java.tuple.Tuple2;
public class Wordcount_Batch {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 准备源数据<br /> DataStreamSource<String> lines = env.fromElements("hadoop spark flink", "hadoop spark", "hadoop");// 转换// 1. 切分数据<br /> /*<br /> @FunctionalInterface<br /> public interface FlatMapFunction<T, O> extends Function, Serializable {<br /> void flatMap(T value, Collector<O> out) throws Exception;<br /> }<br /> */<br /> DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {<br /> @Override<br /> public void flatMap(String value, Collector<String> out) throws Exception {<br /> // value就是每一行<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> out.collect(word);<br /> }<br /> }<br /> });// 2.记为1<br /> /*<br /> @FunctionalInterface<br /> public interface MapFunction<T, O> extends Function, Serializable {<br /> O map(T value) throws Exception;<br /> }<br /> */<br /> DataStream<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public Tuple2<String, Integer> map(String value) throws Exception {<br /> return Tuple2.of(value, 1);<br /> }<br /> });// 3.分组<br /> /*<br /> @FunctionalInterface<br /> public interface KeySelector<IN, KEY> extends Function, Serializable {<br /> KEY getKey(IN value) throws Exception;<br /> }<br /> */<br /> KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);// 4.聚合<br /> SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);// 数据下沉<br /> result.print();// 由于是用流做批,所以要启动并等待结束<br /> env.execute();<br /> }<br />}
1.3.4 DataStream实现WordCount——流处理形式
package org.example.datastream;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Wordcount_Stream {
public static void main(String[] args) throws Exception {
// 准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 准备源数据<br /> DataStreamSource<String> lines = env.socketTextStream("node01", 9999);// 转换// 1. 切分数据<br /> /*<br /> @FunctionalInterface<br /> public interface FlatMapFunction<T, O> extends Function, Serializable {<br /> void flatMap(T value, Collector<O> out) throws Exception;<br /> }<br /> */<br /> DataStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {<br /> @Override<br /> public void flatMap(String value, Collector<String> out) throws Exception {<br /> // value就是每一行<br /> String[] arr = value.split(" ");<br /> for (String word : arr) {<br /> out.collect(word);<br /> }<br /> }<br /> });// 2.记为1<br /> /*<br /> @FunctionalInterface<br /> public interface MapFunction<T, O> extends Function, Serializable {<br /> O map(T value) throws Exception;<br /> }<br /> */<br /> DataStream<Tuple2<String, Integer>> wordAndOne = words.map(new MapFunction<String, Tuple2<String, Integer>>() {<br /> @Override<br /> public Tuple2<String, Integer> map(String value) throws Exception {<br /> return Tuple2.of(value, 1);<br /> }<br /> });// 3.分组<br /> /*<br /> @FunctionalInterface<br /> public interface KeySelector<IN, KEY> extends Function, Serializable {<br /> KEY getKey(IN value) throws Exception;<br /> }<br /> */<br /> KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);// 4.聚合<br /> SingleOutputStreamOperator<Tuple2<String, Integer>> result = grouped.sum(1);// 数据下沉<br /> result.print();// 由于是用流做批,所以要启动并等待结束<br /> env.execute();<br /> }<br />}
1.3.5 DataStream实现WordCount——Lambda形式
package org.example.datastream;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class Wordcount_Lambda {
public static void main(String[] args) throws Exception {
// 准备环境<br /> StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// env.setRuntimeMode(RuntimeExecutionMode.BATCH); // 注意:使用DataStream实现批处理<br /> // env.setRuntimeMode(RuntimeExecutionMode.STREAMING); // 注意:使用DataStream实现流处理<br /> env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); // 注意:使用DataStream根据数据源自动选择使用流还是批// 数据源<br /> DataStreamSource<String> lines = env.fromElements("hadoop spark flink", "hadoop spark", "hadoop");// 转换操作,这里用类似Scala的写法<br /> // 这里需要显示记录泛型<br /> SingleOutputStreamOperator<String> words = lines.flatMap(<br /> (String value, Collector<String> out) -><br /> // :: 用于将方法转成函数<br /> Arrays.stream(value.split(" ")).forEach(out::collect)<br /> ).returns(Types.STRING);SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(<br /> (String value) -> Tuple2.of(value, 1)<br /> ).returns(Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);SingleOutputStreamOperator<Tuple2<String, Integer>> res = grouped.sum(1);// 下沉数据<br /> res.print();// 启动并等待停止<br /> env.execute();<br /> }<br />}<br />【注意】:<br />由于DataStream既可以处理流,也可以处理批,因此可以通过如下代码根据数据自动判断:<br />env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
1.3.6 DataStream实现WordCount——上传到Yarn执行
- 写代码:
- package org.example.datastream;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.lang.reflect.Parameter;
import java.util.Arrays;
public class WordcountOn_Yarn {
public static void main(String[] args) throws Exception {
// 配置相关的参数
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String output = “”;
if (parameterTool.has(“output”)) {
output = parameterTool.get(“output“);
System.out.println(“使用指定的输出路径:” + output);
} else {
output = “hdfs://node01:8020/wordcount/flinkoutput“;
System.out.println(“使用默认的输出路径:” + output);
}
// 准备环境<br /> StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 数据源<br /> DataStreamSource<String> lines = env.fromElements("hadoop spark flink", "hadoop spark", "hadoop");// 转换操作,这里用类似Scala的写法<br /> // 这里需要显示记录泛型<br /> SingleOutputStreamOperator<String> words = lines.flatMap(<br /> (String value, Collector<String> out) -><br /> // :: 用于将方法转成函数<br /> Arrays.stream(value.split(" ")).forEach(out::collect)<br /> ).returns(Types.STRING);SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.map(<br /> (String value) -> Tuple2.of(value, 1)<br /> ).returns(Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> grouped = wordAndOne.keyBy(t -> t.f0);SingleOutputStreamOperator<Tuple2<String, Integer>> res = grouped.sum(1);// 下沉数据<br /> // res.print();<br /> System.setProperty("HADOOP_USER_NAME", "root");<br /> res.writeAsText(output + System.currentTimeMillis()).setParallelism(1);// 启动并等待停止<br /> env.execute();<br /> }<br />}
- 打包:
- image-20220426231212681
- 改名,上传到Node01中的对应文件夹,并执行如下命令来运行程序:
- /export/servers/flink-1.12/bin/flink run -Dexecution.runtime-mode=BATCH -m yarn-cluster -yjm 1024 -ytm 1024 -c org.example.datastream.Wordcount_On_Yarn /export/test/Flink_WordCount.jar —output hdfs://node01:8020/wordcount/output_xx
1.4 Flink原理
1.4.1 Flink角色分工
实际生产中Flink都是在集群运行,运行的过程中主要有以下几个角色参与:
- JobManager:管理集群,负责任务调度、协调Checkpoints、协调故障恢复和收集Job的状态信息,并管理Flink中的从节点TaskManager;
- TaskManager:负责执行实际的运算,即Flink Job中的一组Task。此外,TaskManager还是节点的管理员,它负责把该节点上的服务器信息比如内存、磁盘、任务运行情况等向JobManager 汇报;
- Client:客户端,用于提交用户编写好的Flink程序。
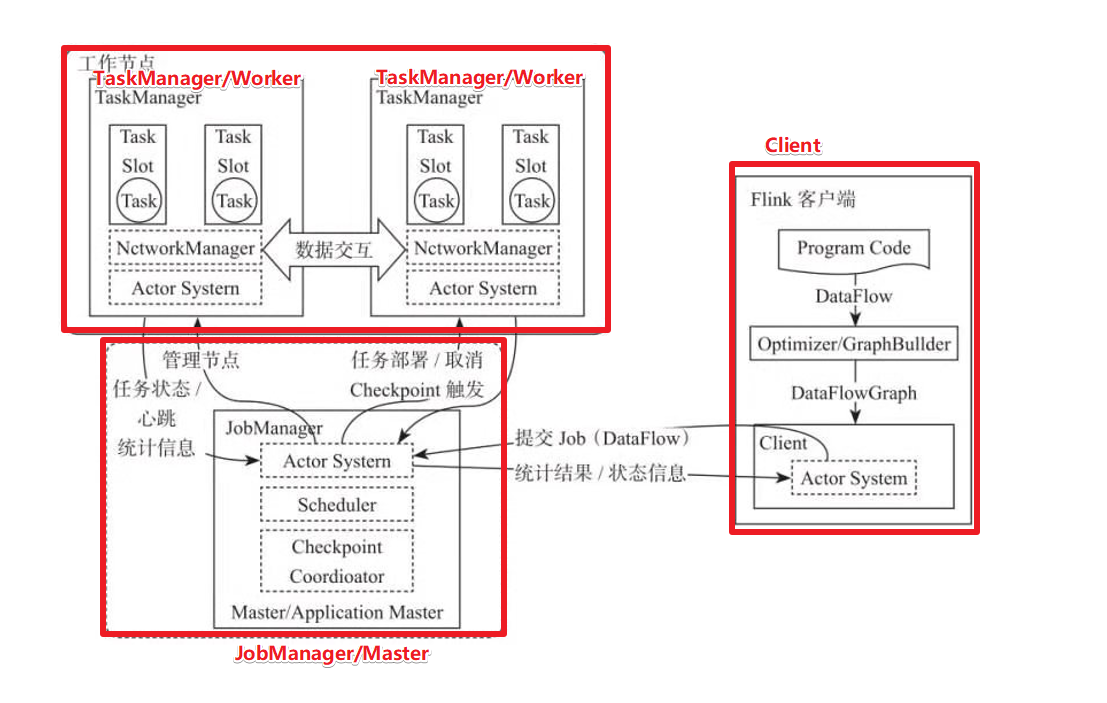
1.4.2 Flink执行流程
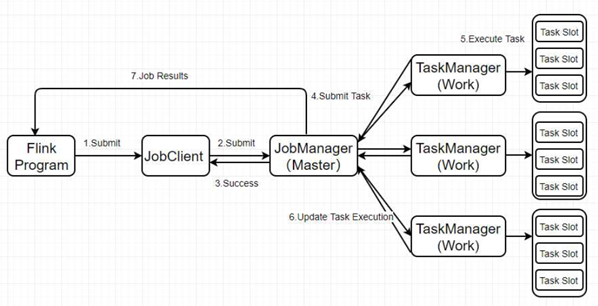
1.4.2.1 Standalone
1.4.2.2 on Yarn(面试重点)
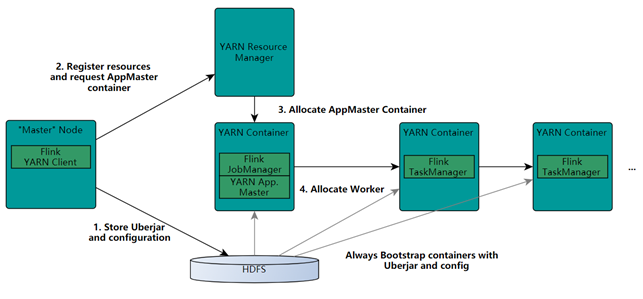
- Client向HDFS上传Flink的Jar包和配置;
- Client向Yarn ResourceManager提交任务并申请资源
- ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager;
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager;
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
1.4.3 Flink 数据流
1.4.3.1 Dataflow、Operator、Partition、SubTask、Parallelism
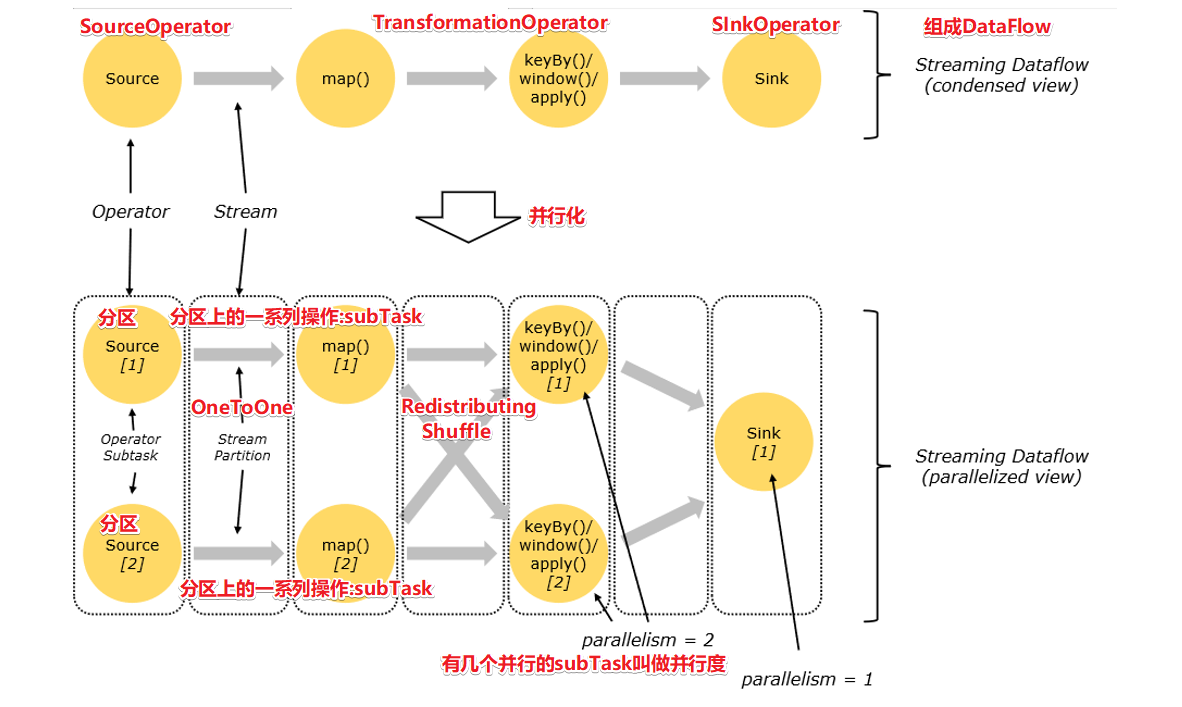
- 数据流(Dataflow):Flink程序在执行时会被映射为一个数据流模型;
- 算子(Operator):数据流模型中的每一个操作,分为Source、Transformation和Sink;
- 分区(Partition):数据流模型是分布式且并行的,执行过程中会形成1~n个分区;
- 子任务(SubTask):由于多个分区中的任务是并行的,每一个都是独立运行在一个线程中,这个任务称为子任务;
- 并行度(Paralleism):指最多可以同时执行的子任务数或分区数。
1.4.3.2 Operator传递模式
数据在两个算子中传递时有两种模式(面试考点,类似于Spark的宽窄依赖):
- One to One 模式:
- 两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;
- 如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性;
- 类似于Spark中的窄依赖。
- Redistributing 模式:
- 这种模式会改变数据的分区数;
- 每个一个Operator Subtask会根据选择transformation把数据发送到不同的目标Subtasks,比如 keyBy() 会通过 hashcode 重新分区,broadcast() 和 rebalance() 方法会随机重新分区;
- 类似于Spark中的宽依赖。
1.4.3.3 Operator Chain
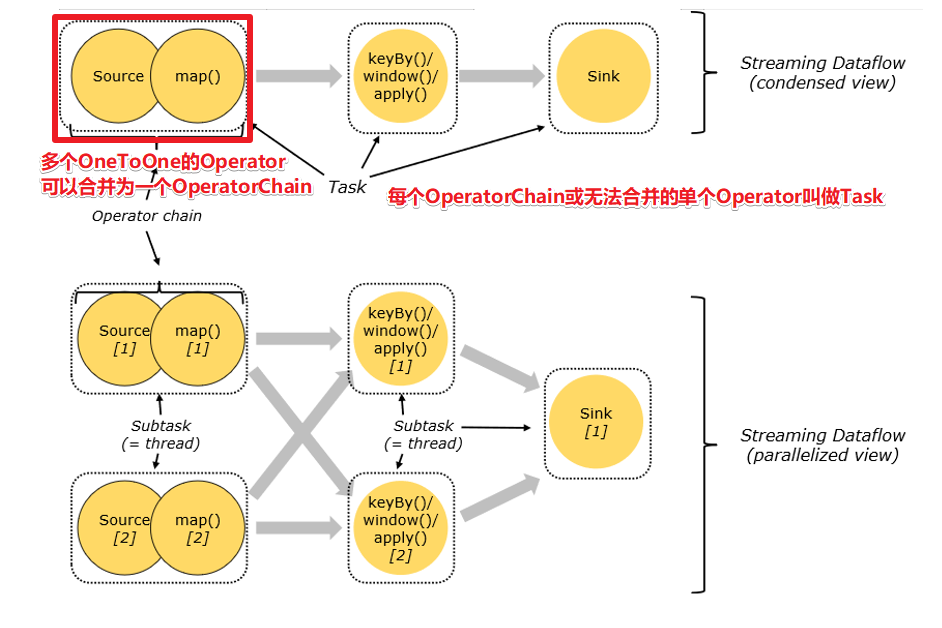
客户端在提交任务时会对Operator进行优化,能进行合并的Operator将会合并为一个Operator Chain,即执行连,每个执行链会在TaskManager上一个独立的线程中执行—就是SubTask。这部分有点类似于Spark中对于窄依赖的流水线优化。
1.4.3.4 TaskSlot 和 Slot Sharing
1.4.3.4.1 任务槽(TaskSlot)
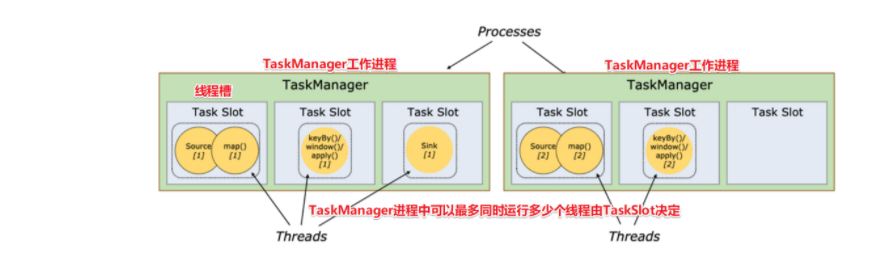
- 每个TaskManager是一个JVM的进程;
- 任务槽的提出主要是为了控制一个TaskManager(worker)能接收多少个task,限制了一个TaskManager工作进程中可以同时运行多少个工作线程;
- TaskSlot 是一个 TaskManager 中的最小资源分配单位,一个 TaskManager 中有多少个 TaskSlot 就意味着能支持多少并发的Task处理。
1.4.3.4.2 槽共享(Slot Sharing)
- Flink允许子任务共享任务槽,即使它们是不同任务(阶段)的子任务(subTask),只要它们来自同一个作业。比如图左下角中的map和keyBy和sink 在一个 TaskSlot 里执行以达到资源共享的目的;
- 允许共享槽主要有以下好处:
- 资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它;
- 有了任务槽共享,可以提高资源的利用率。
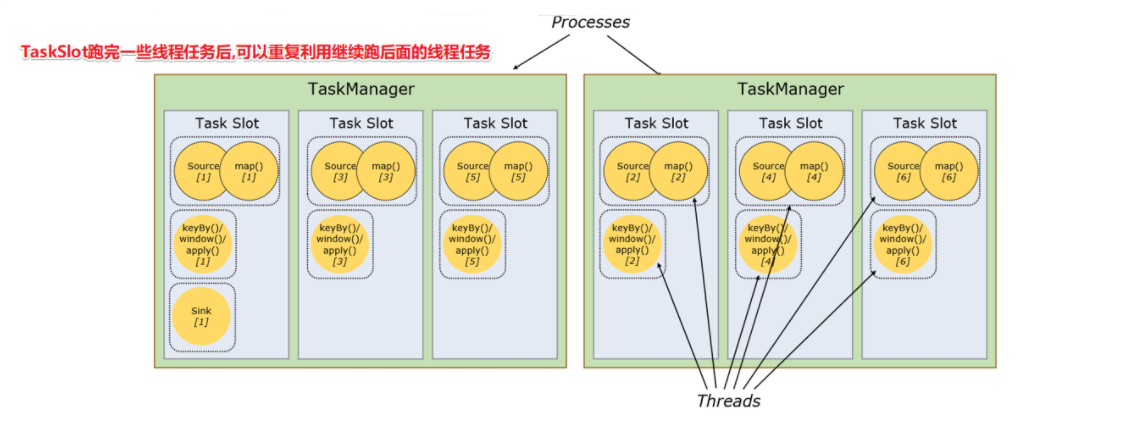
【注意】:
- slot是静态的概念,是指taskmanager具有的并发执行能力;
- parallelism是动态的概念,是指程序运行时实际使用的并发能力。
1.4.4 Flink运行组件
Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作:
- 作业管理器(JobManager):分配任务、调度 checkpoint 做快照;
- 任务管理器(TaskManager):主要执行计算任务的
- 资源管理器(ResourceManager):管理分配资源(TaskManager的slot)
分发器(Dispatcher):方便递交任务的接口,WebUI
1.4.5 Flink执行图
Flink中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。具体如下图所示:
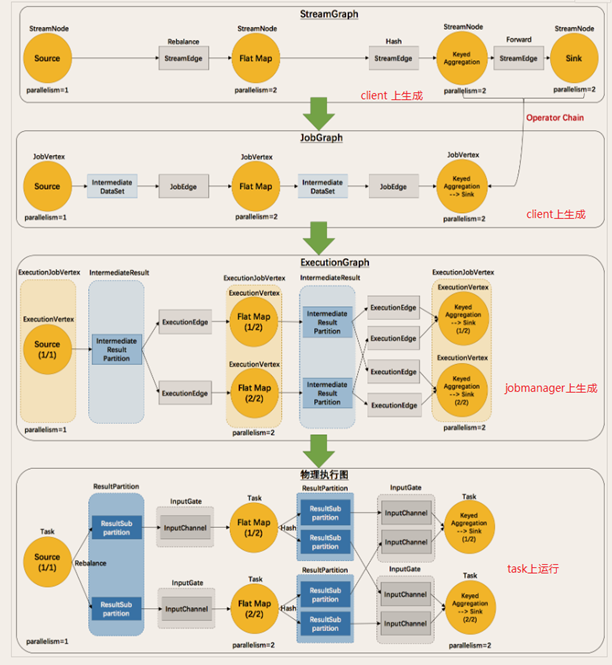
对执行图的简单理解如下:StreamGraph(流程化):最初的程序执行逻辑流程,也就是算子间的前后关系,是在客户端上生成的;
- JobGraph(流程优化合并):将OneToOne的Operator合并为OperatorChain,同样也是在客户端上生成的;
- ExecutionGraph(并行化):将JobGraph根据代码中设置的并行度和请求的资源进行并行化规划,这是在JobManager中实现的;
- 物理执行图(落实执行线程化):将ExecutionGraph的并行计划落实到具体的TaskManager上,将具体的Subtask落实到TaskSlot单独执行。

若有收获,就点个赞吧
0 人点赞
