- 100万字java面试题大全
- 第⼀章:Java基础
- 1.1、面向对象的三个基本特征?
- 1.2、访问修饰符public ,private ,protected ,以及不写 (default) 时的区别?
- 1.3、下⾯两个代码块能正常编译和执⾏吗?
- 1.4、基础考察 ,指出下题的输出结果
- 1.5、⽤最有效率的⽅法计算2乘以8?
- 1.6、&和&&的区别?
- 1.7、String 是 Java 基本数据类型吗?
- 1.8、String 类可以继承吗?
- 1.9、String和StringBuilder、StringBuffer的区别?
- 1.10、String s = new String(“xyz”) 创建了⼏个字符串对象?
- 1.11、String s = “xyz” 和 String s = new String(“xyz”) 区别?
- 1.12、== 和 equals 的区别是什么?
- 1.13、两个对象的 hashCode() 相同,则 equals() 也⼀定为 true,对吗?
- 1.14、什么是反射?
- 1.15、深拷⻉和浅拷⻉区别是什么?
- 1.16、并发和并⾏有什么区别?
- 1.17、当⼀个对象被当作参数传递到⼀个⽅法后,此⽅法可改变这个对象 的属性,并可返回变化后的结果,那么这⾥到底是值传递还是引⽤传递?
- 1.18、重载(Overload)和重写(Override)的区别?
- 1.19、构造器是否可被重写?
- 1.20、为什么不能根据返回类型来区分重载?
- 1.21、Java 静态变量和成员变量的区别
- 1.22、是否可以从⼀个静态(static)⽅法内部发出对⾮静态(nonstatic)⽅法的调⽤?
- 1.23、初始化考察,请指出下⾯程序的运⾏结果。
- 1.24、抽象类(abstract class)和接⼝(interface)有什么区别
- 1.25、Java 中的 final 关键字有哪些⽤法?
- 1.26、阐述 final、finally、finalize 的区别。
- 1.27、try、catch、finally 考察,请指出下⾯程序的运⾏结果(1)
- 1.28、try、catch、finally 考察,请指出下⾯程序的运⾏结果(2)
- 1.29、try、catch、finally 考察3,请指出下⾯程序的运⾏结果(3)
- 1.30、Error 和 Exception 有什么区别?
- 1.31、JDK1.8之后有哪些新特性?
- 1.32、Java的多态表现在哪里
- 1.33、接⼝有什么用
- 1.34、说说http,https协议
- 1.35、tcp/ip协议簇
- 1.36、tcp,udp区别
- 1.37、⽤过哪些加密算法:对称加密,⾮对称加密算法
- 1.38、说说tcp三次握⼿,四次挥⼿
- 1.40、cookie和session的区别,分布式环境怎么保存用户状态
- 1.41、Git,svn区别
- 1.42、ThreadLocal可以⽤来共享数据吗
- 1.43、bio,nio,aio的区别
- 1.44、nio框架:dubbo的实现原理;
- 第⼆章:JVM
- 第三章:集合
- 3.1:有用过ArrayList吗? 它是做什么用的
- 3.2:ArrayList线程不安全,为什么还要去⽤?
- 3.3:ArrayList线程不安全,为什么还要去用?
- 3.4:ArrayList(int initialCapacity)会不会初始化数组⼤⼩?
- 3.5:ArrayList底层是⽤数组实现,但数组⻓度是有限的,如何实现扩容?
- 3.6:ArrayList1.7之前和1.7及以后的区别?
- 3.7:为什么ArrayList增删⽐较慢,增删是如何做的?
- 3.8:ArrayList插⼊和删除数据⼀定慢吗?
- 3.9:ArrayList如何删除数据?
- 3.10:ArrayList适合做队列吗?
- 3.11:数组适合做队列吗?
- 3.12:ArrayList和LinkedList两者的遍历性能孰优孰劣?
- 3.13:了解数据结构中的HashMap吗?介绍下他的结构和底层原理
- 3.14:那你清楚HashMap的插⼊数据的过程吗?
- 3.15:刚才你提到HashMap的初始化,那HashMap怎么设定初始容量⼤ ⼩的?
- 3.16:你提到hash函数,你知道HashMap的hash函数是如何设计的?
- 3.17:1.8相⽐1.7,做了哪些优化?
- 3.18:HashMap怎么实现扩容的?
- 3.19:插⼊数据时扩容的重新hash是怎么做的?
- 3.20:为什么重写equals⽅法后还要重写hashCode⽅法
- 3.21:HashMap在多线程使⽤场景下会存在线程安全问题,怎么处理?
- 3.22:Collections.synchronizedMap()如何实现线程安全
- 3.23:Hashtable的性能为什么不好?
- 3.24:Hashtable和HashMap有什么区别?
- 3.25:什么是fail-safe和fail-fast
- 3.26:ConcurrentHashMap的数据结构是怎么样?
- 3.27:Segment如何实现扩容?
- 3.28:ConcurrentHashMap在JDK1.8版本的数据结构是什么样的?
- 3.29: CAS是什么?
- 3.30:ConcurrentHashMap效率为什么⾼
- 第四章:并发编程
- 4.1、wait() 和 sleep() ⽅法的区别
- 4.2、线程的 sleep() ⽅法和 yield() ⽅法有什么区别?
- 4.3、线程的 join() ⽅法是⼲啥⽤的?
- 4.4、编写多线程程序有⼏种实现⽅式?
- 4.5、Thread 调⽤ start() ⽅法和调⽤ run() ⽅法的区别?
- 4.6、线程的状态流转
- 4.7、synchronized 和 Lock 的区别
- 4.8、为什么说 synchronized 是⼀种悲观锁?乐观锁的实现原理⼜是什 么?什么是CAS,它有什么特性
- 4.9、synchronized 各种加锁场景的作⽤范围
- 4.10、如何检测死锁?
- 4.11、怎么预防死锁?
- 4.12、为什么要使⽤线程池?直接new个线程不是很舒服?
- 4.13、线程池的核⼼属性有哪些?
- 4.14、说下线程池的运作流程
- 4.15、线程池有⼏种状态,每个状态分别代表什么含义?
- 4.16、线程池中的状态之间是怎么流转的
- 4.17、线程池有哪些队列?
- 4.18、使⽤队列有什么需要注意的吗?
- 4.19、线程池有哪些拒绝策略?
- 4.20、线程只能在任务到达时才启动吗
- 4.21、核⼼线程怎么实现⼀直存活?
- 4.22、⾮核⼼线程如何实现在 keepAliveTime 后死亡?
- 4.23、⾮核⼼线程能成为核⼼线程吗?
- 4.24、如何终⽌线程池?
- 4.25、Executors 提供了哪些创建线程池的⽅法?
- 4.26、线程池⾥有个 ctl,你知道它是如何设计的吗?
- 4.27、ctl 为什么这么设计?有什么好处吗?
- 4.28、在我们实际使⽤中,线程池的⼤⼩配置多少合适?
- 4.30、计算机的内存模型
- 4.31、Java内存模型JMM
- 4.32、可⻅性解决⽅案-加锁
- 4.33、JMM数据同步
- 4.34、使⽤Volatile保证可⻅性
- 4.35、Volatile不能保证原⼦性
- 4.36、Volatile保证有序性-指令重排
- 4.37、Volatile指令重排语义
- 4.38、MESI缓存⼀致性协议
- 4.39、Synchronized
- 4.40、Synchronized锁的膨胀升级过程
- 4.41、膨胀升级
- 4.42、Synchronized的底层实现逻辑
- 4.43、Monitor监视器锁
- 4.44、ReentrantLock介绍
- 4.45、公平锁和⾮公平锁
- 4.46、AbstractQueuedSynchronizer类的关键属性
- 第五章:MySQL
- 5.1、MySQL 的事务隔离级别有哪些?分别⽤于解决什么问题?
- 5.2、MySQL 的可重复读怎么实现的?
- 5.3、MVCC 解决了幻读了没有?
- 5.4、经常有⼈说 Repeatable Read 解决了幻读是什么情况?
- 5.5、什么是索引?
- 5.6、常⻅的索引类型有哪些?
- 5.7、为什么MySQL数据库要⽤B+树存储索引?⽽不⽤红⿊树、B树、 Hash?
- 5.8、MySQL 中的索引叶⼦节点存放的是什么?
- 5.9、什么是聚簇索引(聚集索引)?
- 5.10、什么是回表查询?
- 5.11、⾛普通索引,⼀定会出现回表查询吗?
- 5.12、那你知道什么是覆盖索引(索引覆盖)吗?
- 5.13、联合索引(复合索引)的底层实现?最佳左前缀原则?
- 5.14、union 和 union all 的区别
- 5.15、B+树中⼀个节点到底多⼤合适?
- 5.16、那 MySQL 中B+树的⼀个节点⼤⼩为多⼤呢
- 5.17、什么⼀个节点为1⻚就够了?
- 5.18、什么是 Buffer Pool?
- 5.19、InnoDB 四⼤特性知道吗?
- 5.20、请说⼀下共享锁和排他锁?
- 5.21、请说⼀下数据库的⾏锁和表锁?
- 5.23、InnoDB 锁的算法有哪⼏种?
- 5.24、MySQL 如何实现悲观锁和乐观锁?
- 5.25、InnoDB 和 MyISAM 的区别?
- 5.26、存储引擎的选择?
- 5.27、explain ⽤过吗,有哪些字段分别是啥意思
- 5.28、explain 主要关注哪些字段?
- 5.29、type 中有哪些常⻅的值
- 5.30、如何做慢 SQL 优化?
- 5.31、说说 MySQL 的主从复制
- 5.32、异步复制,主库宕机后,数据可能丢失?
- 5.33、主库写压⼒⼤,从库复制很可能出现延迟?
- 5.34、msyql优化经验
- 5.35、mysql的语句优化;
- 第六章:Spring
- 6.1、Spring IoC 的容器构建流程?
- 6.2、Spring Bean 的⽣命周期
- 6.3、BeanFactory 和 FactoryBean 的区别?
- 6.4、BeanFactory 和 ApplicationContext 的区别?
- 6.5、Spring 的 AOP 是怎么实现的?
- 6.6、多个AOP的顺序怎么定?
- 6.7、Spring 的 AOP 有哪⼏种创建代理的⽅式?
- 6.8、JDK 动态代理和 Cglib 代理的区别
- 6.9、JDK 动态代理为什么只能对实现了接⼝的类⽣成代理?
- 6.10、Spring 的事务传播⾏为有哪些
- 6.11、Spring 的事务隔离级别?
- 6.12、Spring 的事务隔离级别是如何做到和数据库不⼀致的?
- 6.13、Spring 事务的实现原理?
- 6.14、Spring 怎么解决循环依赖的问题?
- 6.15、Spring 能解决构造函数循环依赖吗?
- 6.16、Spring 三级缓存解决循环依赖
- 6.17、 @Resource 和 @Autowire 的区别?
- 6.18、 @Autowire 怎么使⽤名称来注⼊?
- 6.19、 @PostConstruct 修饰的⽅法⾥⽤到了其他 bean 实例,会有问题 吗?
- 6.20、bean 的 init-method 属性指定的⽅法⾥⽤到了其他 bean 实例,会 有问题吗?
- 6.21、要在 Spring IoC 容器构建完毕之后执⾏⼀些逻辑,怎么实现?
- 6.22、Spring 中的常⻅扩展点有哪些?
- 6.23、Spring中如何让两个bean按顺序加载?
- 6.24、mybatis
- 6.25、使⽤ Mybatis 时,调⽤ DAO接⼝时是怎么调⽤到 SQL 的?
- 6.26、springmvc的核⼼是什么,请求的流程是怎么处理的,控制反转怎 么实现的
- 6.27、Hibernate
- 第七章:Redis
- 7.1、Redis 是单线程还是多线程?.
- 7.2、为什么 Redis 是单线程?
- 7.3、Redis 为什么使⽤单进程、单线程也很快?
- 7.4、Redis 在项⽬中的使⽤场景
- 7.5、Redis 常⻅的数据结构
- 7.6、Sorted Set底层数据结构
- 7.7、Sorted Set 为什么同时使⽤字典和跳跃表?
- 7.8、Sorted Set 为什么使⽤跳跃表,⽽不是红⿊树?
- 7.9、Hash 对象底层结构
- 7.10、Hash 对象的扩容流程
- 7.11、渐进式 rehash 的优点
- 7.12、rehash 流程在数据量⼤的时候会有什么问题吗(Hash 对象的扩容 流程在数据量⼤的时候会有什么问题吗)
- 7.13、Redis 的⽹络事件处理器(Reactor 模式)
- 7.14、Redis 删除过期键的策略(缓存失效策略、数据过期策略)
- 7.15、Redis 的内存淘汰(驱逐)策略
- 7.16、Redis 的 LRU 算法怎么实现的?
- 7.17、Redis 的持久化机制有哪⼏种,各⾃的实现原理和优缺点?
- 7.18、为什么需要 AOF 重写?
- 7.19、介绍下 AOF 重写的过程、AOF 后台重写存在的问题、如何解决 AOF 后台重写存在的数据不⼀致问题?
- 7.20、RDB、AOF、混合持久,我应该⽤哪⼀个?
- 7.21、同时开启RDB和AOF,服务重启时如何加载?
- 7.22、Redis 怎么保证⾼可⽤、有哪些集群模式?
- 7.23、主从复制
- 7.24、哨兵
- 7.25、集群模式
- 7.26、集群选举
- 7.27、如何保证集群在线扩容的安全性?(Redis 集群要增加分⽚,槽的 迁移怎么保证⽆损)
- 7.28、Redis 事务的实现
- 7.29、Redis 的 Java 客⼾端有哪些?官⽅推荐哪个?
- 7.30、Redis ⾥⾯有1亿个 key,其中有 10 个 key 是包含 java,如何将它 们全部找出来
- 7.31、使⽤过 Redis 做消息队列么?
- 7.32、Redis 和 Memcached 的⽐较
- 7.33、Redis 实现分布式锁
- 7.34、Redis 分布式锁过期了,还没处理完怎么办?
- 7.35、守护线程续命的⽅案有什么问题吗?
- 7.36、RedLock
- 7.37、使⽤缓存时,先操作数据库 or 先操作缓存
- 7.38、为什么是让缓存失效,⽽不是更新缓存?
- 7.39、如何保证数据库和缓存的数据⼀致性?
- 7.40、缓存穿透
- 7.41、布隆过滤器
- 7.42、缓存击穿
- 7.43、缓存雪崩
- 第⼋章:分布式
- 8.1、分布式都有哪些内容?
- 8.2、分布式有哪些理论?
- 8.3、Dubbo 和 Spring Cloud 有什么区别?
- 8.4、什么是RPC?为什么要有 RPC,HTTP 不好么?
- 8.5、如果让你设计⼀个 RPC 框架,如何设计?
- 8.6、请说⼀下服务暴露的流程?
- 8.7、服务引⼊的流程是什么?
- 8.8、服务调⽤的流程是什么?
- 8.9、什么是SPI?
- 8.10、Dubbo 不⽤ JDK 的 SPI,⽽是要⾃⼰实现
- 8.11、Dubbo 为什么默认⽤ Javassist?
- 8.12、为什么需要锁?
- 8.13、为什么需要分布式锁?
- 8.14、实现分布式锁的⽅式
- 8.15、分布式锁如何实现?
- 8.16、分布式锁如何选型?
- 8.17、Zookeeper做为注册中⼼,主要存储哪些数据?存储在哪⾥?
- 8.18、Zookeeper 和 Eureka 的区别
- 8.19、Kafka相对其他消息队列,有什么特点?
- 8.20、Kafka ⾼效⽂件存储设计特点有哪些?
- 8.21、Kafka的ISR机制是什么?
- 8.22、Kafka 如何解决数据丢失问题?
- 8.23、MQ的原理是什么
- 8.24、MQ的持久化是怎么做的
- 8.25、zookeeper是什么
- 8.26、Zookeeper哪⾥⽤到
- 8.27、zookeeper的选主过程
- 8.28、zookeeper集群之间如何通讯
- 8.29、你们的zookeeper的节点加密是⽤的什么⽅式;
- 8.30、linux相关命令
- 8.31、⼤型⽹站在架构上应当考虑哪些问题?
- 8.32、你⽤过的⽹站前端优化的技术有哪些?
- 8.33、什么是XSS攻击?什么是SQL注⼊攻击?什么是CSRF攻击?
- 8.34、什么是领域模型(domain model)?贫⾎模型(anaemic domain model)和充⾎模型(rich domain model)有什么区别?
- 第九章:设计模式
- 第⼀章:Java基础
100万字java面试题大全
第⼀章:Java基础
1.1、面向对象的三个基本特征?
继承: 让某个类型的对象获得另⼀个类型的对象的属性和⽅法。继承就是⼦类继承⽗类的特征和⾏为 ,使得⼦类对象 ( 实例) 具有⽗类的实例域和⽅法 ,或⼦类从⽗类继承⽅法 ,使得⼦类具有⽗类相同的⾏为。
封装: 隐藏部分对象的属性和实现细节 ,对数据的访问只能通过外公开的接⼝ 。通过这种⽅式 ,对象 对内部数据提供了不同级别的保护 ,以防⽌程序中⽆关的部分意外的改变或错误的使⽤了对象的私有 部分。
多态:对于同⼀个⾏为 ,不同的⼦类对象具有不同的表现形式。
多态存在的3个条件:继承,重写,父类引用指向子类对象
举个简单的例⼦: 英雄联盟⾥⾯我们按下 Q 键这个动作:
• 对于亚索 ,就是斩钢闪
• 对于提莫 ,就是致盲吹箭
• 对于剑圣 ,就是阿尔法突袭
同⼀个事件发⽣在不同的对象上会产⽣不同的结果。
下⾯再举个简单的例⼦帮助⼤家理解 ,这个例⼦可能不是完全准确 ,但是依然是可以帮助我们理解的。
public class Animal { / 动物public void sleep() {System.out.println("躺着睡");}}class Horse extends Animal { / ⻢ 是⼀种动物public void sleep() {System.out.println("站着睡");}}class Cat extends Animal { / 猫 是⼀种动物private int age;public int getAge() {return age + 1;}@Overridepublic void sleep() {System.out.println("四脚朝天的睡");}}
在这个例⼦中:
House 和 Cat 都是 Animal ,所以他们都继承了Animal , 同时也从 Animal 继承了 sleep 这个⾏为。
在 Cat ⾥ ,将 age 属性定义为 private ,外界⽆法直接访问 ,要获取 Cat 的 age 信息只能通过 getAge ⽅法 ,从⽽对外隐藏了 age 属性 ,这个就叫做封装。 当然 ,这边 age 只是个例⼦ ,实际使⽤中可能是 ⼀个复杂很多的对象。但是针对 sleep 这个⾏为 , House 和Cat 进⾏了重写 ,有了不同的表现形式 ( 实现), 这个我们称为 多态。
1.2、访问修饰符public ,private ,protected ,以及不写 (default) 时的区别?
| 修饰符 | 本类 | 本包 | 不同包的子类 | 同一个工程 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | |
| default | √ | √ | ||
| private | √ |
类的成员不写访问修饰符默认为default ,默认对于同⼀个包的其他类相当于公开 ( public),对于不是同⼀个包的其他类相当于私有 ( private) 。
受保护 ( protected) 对⼦类相当于公开 ,对于不是同⼀个包没有⽗⼦关系的类相当于私有。
Java中 ,外部类的修饰符只能是public或默认 ,类的成员 (包括内部类) 的修饰符可以是以上四种。
1.3、下⾯两个代码块能正常编译和执⾏吗?
// 代码块1short s1 = 1; s1 = s1 + 1;// 代码块2short s1 = 1; s1 += 1;
代码块1编译报错 ,错误原因是:不兼容的类型: 从int转换到short可能会有损失”。
代码块2正常编译和执⾏。
我们将代码块2进⾏编译,字节码如下:
public class com.joonwhee.open.demo.Convert {public com.joonwhee.open.demo.Convert();Code:0: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnpublic static void main(java.lang.String[]);Code:0: iconst_1 // 将int类型值1⼊(操作数)栈1: istore_1 // 将栈顶int类型值保存到局部变量1中2: iload_1 // 从局部变量1中装载int类型值⼊栈3: iconst_1 // 将int类型值1⼊栈4: iadd // 将栈顶两int类型数相加,结果⼊栈5: i2s // 将栈顶int类型值截断成short类型值,后带符号扩展成int类型值⼊栈。6: istore_1 // 将栈顶int类型值保存到局部变量1中7: return}
可以看到字节码中包含了 i2s 指令,该指令⽤于将 int 转成 short。i2s 是 int to short 的缩写。 其实,s1 += 1 相当于 s1 = (short)(s1 + 1),有兴趣的可以⾃⼰编译下这两⾏代码的字节码,你会发现 是⼀摸⼀样的。
1.4、基础考察 ,指出下题的输出结果
public static void main(String[] args) {Integer a = 128, b = 128, c = 127, d = 127;System.out.println(a == b);System.out.println(c == d);}
答案是:false,true。 执⾏ Integer a = 128,相当于执⾏:Integer a = Integer.valueOf(128),基本类型⾃动转换为包装类 的过程称为⾃动装箱(autoboxing)。
public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}
在 Integer 中引⼊了 IntegerCache 来缓存⼀定范围的值,IntegerCache 默认情况下范围 为:-128~127。 本题中的 127 命中了 IntegerCache,所以 c 和 d 是相同对象,⽽ 128 则没有命中,所以 a 和 b 是不同对象。但是这个缓存范围时可以修改的,可能有些⼈不知道。可以通过JVM启动参数: -XX:AutoBoxCacheMax= 来修改上限值,如下图所⽰:

1.5、⽤最有效率的⽅法计算2乘以8?
2 << 3。(左移 相当于乘以2的⼏次幂 n << m 相当于n乘2的m次幂)
进阶:通常情况下,可以认为位运算是性能最⾼的。但是,其实编译器现在已经“⾮常聪明了”,很多指令编译器都能⾃⼰做优化。所以在实际实⽤中,我们⽆需特意去追求实⽤位运算,这样不仅会导 致代码可读性很差,⽽且某些⾃作聪明的优化反⽽会误导编译器,使得编译器⽆法进⾏更好的优化。
1.6、&和&&的区别?
&&:逻辑与运算符。当运算符左右两边的表达式都为 true,才返回 true。同时具有短路性,如果第 ⼀个表达式为 false,则直接返回 false。
static boolean f1() { System.out.println( "function f1 called." ); return true;}static boolean f2() { System.out.println( "function f2 called." ); return false; }if ( false && f1() ) {} // f1不会被调⽤if ( true || f2() ){} // f2不会被调⽤
&:逻辑与运算符、按位与运算符。
以开关开灯论: 有这样两个开关,0为开关关闭,1为开关打开。 与运算进⾏的是这样的算法: 0&0=0,0&1=0,1&0=0,1&1=1 在与运算中两个开关是串联的,如果我们要开灯,需要两个开关都打开灯才会打开。 理解为A 与B都打开,则开灯,所以是1&1=1,任意⼀个开关没打开,都不开灯,所以其他运算都是0。 按位与运算符:⽤于⼆进制的计算,只有对应的两个⼆进位均为1时,结果位才为1 ,否则为0。 逻辑与运算符:& 在⽤于逻辑与时,和 && 的区别是不具有短路性。所在通常使⽤逻辑与运算符都会 使⽤ &&,⽽ & 更多的适⽤于位运算
1.7、String 是 Java 基本数据类型吗?
答:不是。
Java 中的基本数据类型只有8个:byte、short、int、long、float、double、char、 boolean;除了基本类型(primitive type),剩下的都是引⽤类型(reference type)。 基本数据类型:数据直接存储在栈上 引⽤数据类型区别:数据存储在堆上,栈上只存储引⽤地址。
1.8、String 类可以继承吗?
不⾏。String 类使⽤ final 修饰,⽆法被继承。
1.9、String和StringBuilder、StringBuffer的区别?
String:String 的值被创建后不能修改,任何对 String 的修改都会引发新的 String 对象的⽣成。
StringBuffer:跟 String 类似,但是值可以被修改,使⽤ synchronized 来保证线程安全。
StringBuilder:StringBuffer 的⾮线程安全版本,没有使⽤ synchronized,具有更⾼的性能,推荐 优先使⽤
1.10、String s = new String(“xyz”) 创建了⼏个字符串对象?
⼀个或两个。
如果字符串常量池已经有“xyz”,则是⼀个;否则,两个。
当字符串常量池没有 “xyz”,此时会创建如下两个对象:
1. ⼀个是字符串字⾯量 "xyz" 所对应的、驻留(intern)在⼀个全局共享的字符串常量池中的实例,此时该实例也是在堆中,字符串常量池只放引⽤。2.另⼀个是通过 new String() 创建并初始化的,内容与"xyz"相同的实例,也是在堆中两个对象,一个是静态存储区的”xyz”,一个是用new创建在堆上的对象。
String类:表示不可改变的字符串,当前对象创建完毕之后,该对象的内容(字符序列)是不能改变的,一旦内容改变就是一个新的对象。
String对象的创建:
1):直接赋一个字面量: String str1 = “ABCD”;
2):通过构造器构造:String str = new String(“ABCD”);
————————————————
版权声明:本文为CSDN博主「成长的小牛233」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/dreamzuora/article/details/79464081
1.11、String s = “xyz” 和 String s = new String(“xyz”) 区别?
两个语句都会先去字符串常量池中检查是否已经存在 “xyz”,如果有则直接使⽤,如果没有则会在 常量池中创建 “xyz” 对象。
另外,String s = new String(“xyz”) 还会通过 new String() 在堆⾥创建⼀个内容与 “xyz” 相同的对象 实例。 所以前者其实理解为被后者的所包含。
1.12、== 和 equals 的区别是什么?
==:运算符,⽤于⽐较基础类型变量和引⽤类型变量。
对于基础类型变量,⽐较的变量保存的值是否相同,类型不⼀定要相同。
对于引⽤类型变量,⽐较的是两个对象的地址是否相同。
short s1 = 1; long l1 = 1;// 结果:true。类型不同,但是值相同System.out.println(s1 == l1);
Integer i1 = new Integer(1);Integer i2 = new Integer(1);// 结果:false。通过new创建,在内存中指向两个不同的对象System.out.println(i1 == i2);
equals:Object 类中定义的⽅法,通常⽤于⽐较两个对象的值是否相等。 equals 在 Object ⽅法中其实等同于 ==,但是在实际的使⽤中,equals 通常被重写⽤于⽐较两个对 象的值是否相同。
Integer i1 = new Integer(1);Integer i2 = new Integer(1);// 结果:true。两个不同的对象,但是具有相同的值System.out.println(i1.equals(i2));// Integer的equals重写⽅法public boolean equals(Object obj) {if (obj instanceof Integer) {// ⽐较对象中保存的值是否相同return value == ((Integer)obj).intValue();}return false;}
1.13、两个对象的 hashCode() 相同,则 equals() 也⼀定为 true,对吗?
不对。hashCode() 和 equals() 之间的关系如下:
当有 a.equals(b) == true 时,则 a.hashCode() == b.hashCode() 必然成⽴,
反过来,当 a.hashCode() == b.hashCode() 时,a.equals(b) 不⼀定为 true
1.14、什么是反射?
反射是指在运⾏状态中,对于任意⼀个类都能够知道这个类所有的属性和⽅法;并且对于任意⼀个对 象,都能够调⽤它的任意⼀个⽅法;这种动态获取信息以及动态调⽤对象⽅法的功能称为反射机制。
反射涉及到四个核⼼类:
• java.lang.Class.java:类对象;
• java.lang.reflect.Constructor.java:类的构造器对象;
•java.lang.reflect.Method.java:类的⽅法对象;
• java.lang.reflect.Field.java:类的属性对象;
反射有什么⽤?
• 操作因访问权限限制的属性和⽅法;
• 实现⾃定义注解;
• 动态加载第三⽅jar包;
• 按需加载类,节省编译和初始化APK的时间;
反射⼯作原理
当我们编写完⼀个Java项⽬之后,每个java⽂件都会被编译成⼀个.class⽂件,这些Class对象承载了 这个类的所有信息,包括⽗类、接⼝、构造函数、⽅法、属性等,这些class⽂件在程序运⾏时会被 ClassLoader加载到虚拟机中。当⼀个类被加载以后,Java虚拟机就会在内存中⾃动产⽣⼀个Class对 象。我们通过new的形式创建对象实际上就是通过这些Class来创建,只是这个过程对于我们是不透 明的⽽已。
反射的⼯作原理就是借助Class.java、Constructor.java、Method.java、Field.java这四个类在程序 运⾏时动态访问和修改任何类的⾏为及状态。
1.15、深拷⻉和浅拷⻉区别是什么?
数据分为基本数据类型和引⽤数据类型。基本数据类型:数据直接存储在栈中;引⽤数据类型:存储 在栈中的是对象的引⽤地址,真实的对象数据存放在堆内存⾥。
浅拷⻉:对于基础数据类型:直接复制数据值;对于引⽤数据类型:只是复制了对象的引⽤地址,新 旧对象指向同⼀个内存地址,修改其中⼀个对象的值,另⼀个对象的值随之改变。深拷⻉:对于基础数据类型:直接复制数据值;对于引⽤数据类型:开辟新的内存空间,在新的内存 空间⾥复制⼀个⼀模⼀样的对象,新⽼对象不共享内存,修改其中⼀个对象的值,不会影响另⼀个对 象。深拷⻉相⽐于浅拷⻉速度较慢并且花销较⼤。 举个例⼦这就好⽐两兄弟⼤家买⾐服可以⼀⼈⼀套,然后房⼦⼤家住在⼀套房⼦⾥(浅拷⻉),当两 个⼈成家⽴业了,房⼦分开了⼀⼈⼀套互不影响(深拷⻉)
1.16、并发和并⾏有什么区别?
并发:两个或多个事件在同⼀时间间隔发⽣。
并⾏:两个或者多个事件在同⼀时刻发⽣。
并⾏是真正意义上,同⼀时刻做多件事情,⽽并发在同⼀时刻只会做⼀件事件,只是可以将时间切 碎,交替做多件事情。
并⾏在多处理器系统中存在,⽽并发可以在单处理器和多处理器系统中都存在,并发能够在单处理器 系统中存在是因为并发是并⾏的假象,并⾏要求程序能够同时执⾏多个操作,⽽并发只是要求程序假 装同时执⾏多个操作(每个⼩时间⽚执⾏⼀个操作,多个操作快速切换执⾏)。
当系统有⼀个以上 CPU 时,则线程的操作有可能⾮并发。当⼀个 CPU 执⾏⼀个线程时,另⼀个 CPU 可以执⾏另⼀个线程,两个线程互不抢占 CPU 资源,可以同时进⾏,这种⽅式我们称之为并⾏ (Parallel)。
并发编程的⽬标是充分的利⽤处理器的每⼀个核,以达到最⾼的处理性能
1.17、当⼀个对象被当作参数传递到⼀个⽅法后,此⽅法可改变这个对象 的属性,并可返回变化后的结果,那么这⾥到底是值传递还是引⽤传递?
值传递。Java 中只有值传递,对于对象参数,值的内容是对象的引⽤。
1.18、重载(Overload)和重写(Override)的区别?
⽅法的重载和重写都是实现多态的⽅式,区别在于前者实现的是编译时的多态性,⽽后者实现的是运 ⾏时的多态性。
重载:⼀个类中有多个同名的⽅法,但是具有有不同的参数列表(参数类型不同、参数个数不同或者 ⼆者都不同)。
重写:发⽣在⼦类与⽗类之间,⼦类对⽗类的⽅法进⾏重写,参数都不能改变,返回值类型可以不相 同,但是必须是⽗类返回值的派⽣类。即外壳不变,核⼼重写!重写的好处在于⼦类可以根据需要,定义特定于⾃⼰的⾏为。
1.19、构造器是否可被重写?
Constructor 不能被 override(重写),但是可以 overload(重载),所以你可以看到⼀个类中有多 个构造函数的情况
1.20、为什么不能根据返回类型来区分重载?
如果我们有两个⽅法如下,当我们调⽤:test(1) 时,编译器⽆法确认要调⽤的是哪个?
// ⽅法1int test(int a);// ⽅法2long test(int a);
⽅法的返回值只是作为⽅法运⾏之后的⼀个“状态”,但是并不是所有调⽤都关注返回值,所以不能 将返回值作为重载的唯⼀区分条件。
1.21、Java 静态变量和成员变量的区别
public class Demo {/*** 静态变量:⼜称类变量,static修饰*/public static String STATIC_VARIABLE = "静态变量";/*** 实例变量:⼜称成员变量,没有static修饰*/public String INSTANCE_VARIABLE = "实例变量";}
成员变量存在于堆内存中。静态变量存在于⽅法区中
成员变量与对象共存亡,随着对象创建⽽存在,随着对象被回收⽽释放。静态变量与类共存亡,随着 类的加载⽽存在,随着类的消失⽽消失。
成员变量所属于对象,所以也称为实例变量。静态变量所属于类,所以也称为类变量。
成员变量只能被对象所调⽤ 。静态变量可以被对象调⽤,也可以被类名调⽤
1.22、是否可以从⼀个静态(static)⽅法内部发出对⾮静态(nonstatic)⽅法的调⽤?
区分两种情况,发出调⽤时是否显⽰创建了对象实例。
1)没有显⽰创建对象实例:不可以发起调⽤,⾮静态⽅法只能被对象所调⽤,静态⽅法可以通过对 象调⽤,也可以通过类名调⽤,所以静态⽅法被调⽤时,可能还没有创建任何实例对象。因此通过静 态⽅法内部发出对⾮静态⽅法的调⽤,此时可能⽆法知道⾮静态⽅法属于哪个对象
public class Demo {public static void staticMethod() {// 直接调⽤⾮静态⽅法:编译报错instanceMethod();}public void instanceMethod() {System.out.println("⾮静态⽅法");}}
2)显⽰创建对象实例:可以发起调⽤,在静态⽅法中显⽰的创建对象实例,则可以正常的调⽤。
public class Demo {public static void staticMethod() {// 先创建实例对象,再调⽤⾮静态⽅法:成功执⾏Demo demo = new Demo();demo.instanceMethod();}public void instanceMethod() {System.out.println("⾮静态⽅法");}}
1.23、初始化考察,请指出下⾯程序的运⾏结果。
public class InitialTest {public static void main(String[] args) {A ab = new B();ab = new B();}}class A {static { // ⽗类静态代码块System.out.print("A");}public A() { // ⽗类构造器System.out.print("a");}}class B extends A {static { // ⼦类静态代码块System.out.print("B");}public B() { // ⼦类构造器System.out.print("b");}}
执⾏结果:ABabab,两个考察点:
1)静态变量只会初始化(执⾏)⼀次。
2)当有⽗类时,完整的初始化顺序为:⽗类静态变量(静态代码块)->⼦类静态变量(静态代码 块)->⽗类⾮静态变量(⾮静态代码块)->⽗类构造器 ->⼦类⾮静态变量(⾮静态代码块)->⼦类构 造器 。
1.24、抽象类(abstract class)和接⼝(interface)有什么区别
1)抽象类只能单继承,接⼝可以多实现。
2)抽象类可以有构造⽅法,接⼝中不能有构造⽅法。
3)抽象类中可以有成员变量,接⼝中没有成员变量,只能有常量(默认就是 public static final)
4)抽象类中可以包含⾮抽象的⽅法,在 Java 7 之前接⼝中的所有⽅法都是抽象的,在 Java 8 之 后,接⼝⽀持⾮抽象⽅法:default ⽅法、静态⽅法等。Java 9 ⽀持私有⽅法、私有静态⽅法。
5)抽象类中的抽象⽅法类型可以是任意修饰符,Java 8 之前接⼝中的⽅法只能是 public 类型,Java 9 ⽀持 private 类型。
设计思想的区别:
接⼝是⾃上⽽下的抽象过程,接⼝规范了某些⾏为,是对某⼀⾏为的抽象。我需要这个⾏为,我就去 实现某个接⼝,但是具体这个⾏为怎么实现,完全由⾃⼰决定。
抽象类是⾃下⽽上的抽象过程,抽象类提供了通⽤实现,是对某⼀类事物的抽象。我们在写实现类的 时候,发现某些实现类具有⼏乎相同的实现,因此我们将这些相同的实现抽取出来成为抽象类,然后 如果有⼀些差异点,则可以提供抽象⽅法来⽀持⾃定义实现。
⽹上看到有个说法,挺形象的: 普通类像亲爹 ,他有啥都是你的。 抽象类像叔伯,有⼀部分会给你,还能指导你做事的⽅法。 接⼝像⼲爹,可以给你指引⽅法,但是做成啥样得你⾃⼰努⼒实现
1.25、Java 中的 final 关键字有哪些⽤法?
修饰类:该类不能再派⽣出新的⼦类,不能作为⽗类被继承。因此,⼀个类不能同时被声明为 abstract 和 final。
修饰⽅法:该⽅法不能被⼦类重写。
修饰变量:该变量必须在声明时给定初值,⽽在以后只能读取,不可修改。 如果变量是对象,则指的 是引⽤不可修改,但是对象的属性还是可以修改的
public class FinalDemo {// 不可再修改该变量的值public static final int FINAL_VARIABLE = 0;// 不可再修改该变量的引⽤,但是可以直接修改属性值public static final User USER = new User();public static void main(String[] args) {// 输出:User(id=0, name=null, age=0)System.out.println(USER);// 直接修改属性值USER.setName("test");// 输出:User(id=0, name=test, age=0)System.out.println(USER);}}
1.26、阐述 final、finally、finalize 的区别。
其实是三个完全不相关的东西,只是⻓的有点像。
final : 最终的。
finally:finally 是对 Java 异常处理机制的最佳补充,通常配合 try、catch 使⽤,⽤于存放那些⽆论 是否出现异常都⼀定会执⾏的代码。在实际使⽤中,通常⽤于释放锁、数据库连接等资源,把资源释放⽅法放到 finally 中,可以⼤⼤降低程序出错的⼏率。
finalize:Object 中的⽅法,在垃圾收集器将对象从内存中清除出去之前做必要的清理⼯作。 finalize()⽅法仅作为了解即可,在 Java 9 中该⽅法已经被标记为废弃,并添加新的 java.lang.ref.Cleaner,提供了更灵活和有效的⽅法来释放资源。这也侧⾯说明了,这个⽅法的设计 是失败的,因此更加不能去使⽤它。
1.27、try、catch、finally 考察,请指出下⾯程序的运⾏结果(1)
public class TryDemo {public static void main(String[] args) {System.out.println(test());}public static int test() {try {return 1;} catch (Exception e) {return 2;} finally {System.out.print("3");}}}
执⾏结果:31。
相信很多同学应该都做对了,try、catch。finally 的基础⽤法,在 return 前会先执⾏ finally 语句 块,所以是先输出 finally ⾥的 3,再输出 return 的 1
1.28、try、catch、finally 考察,请指出下⾯程序的运⾏结果(2)
public class TryDemo {public static void main(String[] args) {System.out.println(test1());}public static int test1() {try {return 2;} finally {return 3;}}}
执⾏结果:3。
这题有点意思,但也不难,try 返回前先执⾏ finally,结果 finally ⾥不按套路出牌,直接 return 了, ⾃然也就⾛不到 try ⾥⾯的 return 了
finally ⾥⾯使⽤ return 仅存在于⾯试题中,实际开发中千万不要这么⽤
1.29、try、catch、finally 考察3,请指出下⾯程序的运⾏结果(3)
public class TryDemo {public static void main(String[] args) {System.out.println(test1());}public static int test1() {int i = 0;try {i = 2;return i;} finally {i = 3;}}}
执⾏结果:2。
这边估计有不少同学会以为结果应该是 3,因为我们知道在 return 前会执⾏ finally,⽽ i 在 finally 中 被修改为 3 了,那最终返回 i 不是应该为 3 吗?
这边的根本原因是,在执⾏ finally 之前,JVM 会先将 i 的结果暂存起来,然后 finally 执⾏完毕后, 会返回之前暂存的结果,⽽不是返回 i,所以即使这边 i 已经被修改为 3,最终返回的还是之前暂存起 来的结果 2。
这边其实根据字节码可以很容易看出来,在进⼊ finally 之前,JVM 会使⽤ iload、istore 两个指令, 将结果暂存,在最终返回时在通过 iload、ireturn 指令返回暂存的结果。
1.30、Error 和 Exception 有什么区别?
Error 和 Exception 都是 Throwable 的⼦类,⽤于表⽰程序出现了不正常的情况。区别在于: Error 表⽰系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情况下的⼀种严重问 题,⽐如内存溢出,不可能指望程序能处理这样的情况
Exception 表⽰需要捕捉或者需要程序进⾏处理的异常,是⼀种设计或实现问题,也就是说,它表⽰ 如果程序运⾏正常,从不会发⽣的情况。
1.31、JDK1.8之后有哪些新特性?
1)接⼝默认⽅法:Java 8 允许我们给接⼝添加⼀个⾮抽象的⽅法实现,只需要使⽤ default 关键字 即可。
从Java 8开始,引⼊了接⼝默认⽅法,这样的好处也是很明显的,⾸先解决了 Java8 以前版本接⼝兼 容性问题,同时对于我们以后的程序开发,也可以在接⼝⼦类中直接使⽤接⼝默认⽅法,⽽不再需要 在各个⼦类中各⾃实现响应接⼝⽅法。
public interface IMathOperation {/*** 定义接⼝默认⽅法 ⽀持⽅法形参*/default void print(){System.out.println("这是数值运算基本接⼝。。。");}/*** 定义静态默认⽅法*/static void version(){System.out.println("这是1.0版简易计算器");}}
public class MathOperationImpl implements IMathOperation {@Overridepublic int add(int a, int b) {// ⼦类中可以直接调⽤⽗类接⼝默认⽅法IMathOperation.super.print();// 调⽤⽗类静态默认⽅法IMathOperation.version();return a+b;}}
2)Lambda 表达式和函数式接⼝:Lambda 表达式本质上是⼀段匿名内部类,也可以是⼀段可以传 递的代码。Lambda 允许把函数作为⼀个⽅法的参数(函数作为参数传递到⽅法中),使⽤ Lambda 表达式使代码更加简洁,但是也不要滥⽤,否则会有可读性等问题,《Effective Java》作者 Josh Bloch 建议使⽤ Lambda 表达式最好不要超过3⾏。
匿名内部类
@Testpublic void test1(){Comparator<Integer> com = new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return Integer.compare(o1, o2);}};TreeSet<Integer> treeSet = new TreeSet<>(com);}
Lambda 表达式
Comparator<Integer> com = (x, y) -> Integer.compare(x, y)
函数式接⼝
Lambda表达式需要函数式接⼝的⽀持,所以,我们有必要来说说什么是函数式接⼝。 只包含⼀个抽象⽅法的接⼝,称为函数式接⼝。 可以通过 Lambda 表达式来创建该接⼝的对 象。(若 Lambda表达式抛出⼀个受检异常,那么该异常需要在⽬标接⼝的抽象⽅法上进⾏声明)。 可以在任意函数式接⼝上使⽤ @FunctionalInterface 注解,这样做可以检查它是否是⼀个函数式接 ⼝,同时 javadoc 也会包含⼀条声明,说明这个接⼝是⼀个函数式接⼝
@FunctionalInterfacepublic interface MyFunc <T> {public T getValue(T t);}public String handlerString(MyFunc<String> myFunc, String str){return myFunc.getValue(str);}@Testpublic void test6(){String str = handlerString((s) -> s.toUpperCase(), "binghe");System.out.println(str);//输出结果BINGHE}
3)Stream API:⽤函数式编程⽅式在集合类上进⾏复杂操作的⼯具,配合Lambda表达式可以⽅便 的对集合进⾏处理。Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进⾏的操作,可以 执⾏⾮常复杂的查找、过滤和映射数据等操作。使⽤Stream API 对集合数据进⾏操作,就类似于使 ⽤ SQL 执⾏的数据库查询。也可以使⽤ Stream API 来并⾏执⾏操作。简⽽⾔之,Stream API 提供了 ⼀种⾼效且易于使⽤的处理数据的⽅式
List<Teacher> teacherList = new ArrayList<>();teacherList.add(new Teacher("张磊",22,"zl"));teacherList.add(new Teacher("李鹏",36,"lp"));teacherList.add(new Teacher("刘敏",50,"lm"));teacherList.add(new Teacher("宋亚楠",62,"syn"));teacherList.add(new Teacher("彩彬",18,"cb"));//filter 过滤List<Teacher> list = teacherList.stream().filter(x -> x.getAge() > 30).collect(Collectors.toList());//joining拼接 所有⽼师姓名拼接成字符串String nameJoin = teacherList.stream().map(Teacher::getName).collect(Collectors.joining(","));//排序List sortList = teacherList.stream().sorted(Comparator.comparing(Teacher::getAge).reversed()).collect(Collectors.toList());System.out.println(nameJoin);System.out.println(list);System.out.println("按年龄降序: "+sortList)/*输出结果*[Teacher(name=李鹏, age=36, nikeName=lp), Teacher(name=刘敏, age=50,nikeName=lm), Teacher(name=宋亚楠, *age=62, nikeName=syn)]*张磊,李鹏,刘敏,宋亚楠,彩彬*按年龄降序: [Teacher(name=宋亚楠, age=62, nikeName=syn), Teacher(name=刘敏,age=50, nikeName=lm), *Teacher(name=李鹏, age=36, nikeName=lp), Teacher(name=张磊, age=22, nikeName=zl), Teacher(name=彩彬, age=18, nikeName=cb)]*/
4)⽅法引⽤:⽅法引⽤提供了⾮常有⽤的语法,可以直接引⽤已有Java类或对象(实例)的⽅法或构造器。与lambda联合使⽤,⽅法引⽤可以使语⾔的构造更紧凑简洁,减少冗余代码。
⽅法引⽤就是操作符“::”将⽅法名和对象或类的名字分隔开来
。 如下三种使⽤情况:
• 对象::实例⽅法• 类::静态⽅法• 类::实例⽅法
(x) -> System.out.println(x);//等同于 System.out::printlnBinaryOperator<Double> bo = (x, y) -> Math.pow(x, y);//等同于 BinaryOperator<Double> bo = Math::pow;
5)⽇期时间API:Java 8 引⼊了新的⽇期时间API改进了⽇期时间的管理。在Java 8之前,所有关于 时间和⽇期的API都存在各种使⽤⽅⾯的缺陷,主要有:
Java的java.util.Date和java.util.Calendar类易⽤性差,不⽀持时区,⽽且他们都不是线程安全 的;⽤于格式化⽇期的类DateFormat被放在java.text包中,它是⼀个抽象类,所以我们需要实例化 ⼀个SimpleDateFormat对象来处理⽇期格式化,并且DateFormat也是⾮线程安全,这意味着 如果你在多线程程序中调⽤同⼀个DateFormat对象,会得到意想不到的结果。
对⽇期的计算⽅式繁琐,⽽且容易出错,因为⽉份是从0开始的,从Calendar中获取的⽉份 需要加⼀才能表⽰当前⽉份。 i. 由于以上这些问题,出现了⼀些三⽅的⽇期处理框架,例如Joda-Time,date4j等开源项⽬。但是, Java需要⼀套标准的⽤于处理时间和⽇期的框架,于是Java 8中引⼊了新的⽇期API。新的⽇期API是 JSR-310规范的实现,Joda-Time框架的作者正是JSR-310的规范的倡导者,所以能从Java 8的⽇期 API中看到很多Joda-Time的特性。 Java 8的⽇期和时间类包含LocalDate 、 LocalTime 、 Instant 、 Duration 以及 Period ,这些类都包含在 java.time 包中,下⾯我们看看这些类的⽤法
6)Optional 类:著名的 NullPointerException 是引起系统失败最常⻅的原因。很久以前 Google Guava 项⽬引⼊了 Optional 作为解决空指针异常的⼀种⽅式,不赞成代码被 null 检查的代码污染, 期望程序员写整洁的代码。受Google Guava的⿎励,Optional 现在是Java 8库的⼀部分。
7)新⼯具:新的编译⼯具,如:Nashorn引擎 jjs、 类依赖分析器 jdeps。
1.32、Java的多态表现在哪里
多态要有动态绑定,否则就不是多态,⽅法重载也不是多态(因为⽅法重载是编译期决定好的,没有后期也 就是运⾏期的动态绑定) 当满⾜这三个条件 1.有继承 2. 有重写 3. 要有⽗类引⽤指向⼦类对象
1.33、接⼝有什么用
1、重要性:在Java语⾔中, abstract class 和interface 是⽀持抽象类定义的两种机制。正是由于这 两种机制的存在,才赋予了Java强⼤的 ⾯向对象能⼒。
2、简单、规范性:如果⼀个项⽬⽐较庞⼤,那么就需要⼀个能理清所有业务的架构师来定义⼀些主 要的接⼝,这些接⼝不仅告诉开发⼈员你需要实现那些业务,⽽且也将命名规范限制住了(防⽌⼀些 开发⼈员随便命名导致别的程序员⽆法看明⽩)。
3、维护、拓展性:⽐如你要做⼀个画板程序,其中⾥⾯有⼀个⾯板类,主要负责绘画功能,然后你 就这样定义了这个类。
可是在不久将来,你突然发现这个类满⾜不了你了,然后你⼜要重新设计这个类,更糟糕是你可能要 放弃这个类,那么其他地⽅可能有引⽤他,这样修改起来很⿇烦。
如果你⼀开始定义⼀个接⼝,把绘制功能放在接⼝⾥,然后定义类时实现这个接⼝,然后你只要⽤这 个接⼝去引⽤实现它的类就⾏了,以后要换的话只不过是引⽤另⼀个类⽽已,这样就达到维护、拓展 的⽅便性。
4、安全、严密性:接⼝是实现软件松耦合的重要⼿段,它描叙了系统对外的所有服务,⽽不涉及任何具体的实现细节。这样就⽐较安全、严密⼀些(⼀般软件服务商考虑的⽐较多)
1.34、说说http,https协议
HTTPS(Secure Hypertext Transfer Protocol)安全超⽂本传输协议:
它是⼀个安全通信通道,它基于HTTP开发,⽤于在客⼾计算机和服务器之间交换信息,它使⽤安全套接字层(SSL)进⾏信息交换,简单来说它是HTTP的安全版。
它是由Netscape开发并内置于其浏览器中,⽤于对数据进⾏压缩和解压操作,并返回⽹络上传送回 的结果。HTTPS实际上应⽤了Netscape的安全全套接字层(SSL)作为HTTP应⽤层的⼦层.(HTTPS使⽤端⼝443,⽽不是像HTTP那样使⽤端⼝80来和TCP/IP进⾏通信。)SSL使⽤40 位关键字作为RC4流加密算法,这对于商业信息的加密是合适的。
HTTPS和SSL⽀持使⽤X.509数字认证,如果需要的话⽤⼾可以确认发送者是谁。总的来说,HTTPS 协议是由SSL+HTTP协议构建的可进⾏加密传输、⾝份认证的⽹络协议要⽐http协议安全。
在URL前加https://前缀表明是⽤SSL加密的,你的电脑与服务器之间收发的信息传输将更加安全。 Web服务器启⽤SSL需要获得⼀个服务器证书并将该证书与要使⽤SSL的服务器绑定。
HTTPS和HTTP的区别:
https协议需要到ca申请证书,⼀般免费证书很少,需要交费。
http是超⽂本传输协议,信息是明⽂传输,https 则是具有安全性的ssl加密传输协议。
http和https使⽤的是完全不同的连接⽅式⽤的端⼝也不⼀样,前者是80,后者是443。
http的连接很简单,是⽆状态的。
HTTPS协议是由SSL+HTTP协议构建的可进⾏加密传输、⾝份认证的⽹络协议 要⽐http协议安全。
HTTPS解决的问题:
1 . 信任主机的问题
采⽤https 的server 必须从CA 申请⼀个⽤于证明服务器⽤途类型的证书. 该证书只有⽤于对应的 server 的时候,客⼾端才信任此主机. 所以⽬前所有的银⾏系统⽹站,关键部分应⽤都是https 的.
客⼾通过信任该证书,从⽽信任了该主机. 其实这样做效率很低,但是银⾏更侧重安全. 这⼀点对我们 没有任何意义,我们的server ,采⽤的证书不管⾃⼰issue 还是从公众的地⽅issue, 客⼾端都是⾃⼰⼈, 所以我们也就肯定信任该server.
2 . 通讯过程中的数据的泄密和被窜改
- ⼀般意义上的https, 就是 server 有⼀个证书.
- 主要⽬的是保证server 就是他声称的server. 这个跟第⼀点⼀样. b) 服务端和客⼾端之间的所有通讯,都是加密的.
- 具体讲,是客⼾端产⽣⼀个对称的密钥,通过server 的证书来交换密钥. ⼀般意义上的握⼿过程.
- 所有的信息往来就都是加密的. 第三⽅即使截获,也没有任何意义.因为他没有密钥. 当然窜改也 就没有什么意义了.
2). 少许对客⼾端有要求的情况下,会要求客⼾端也必须有⼀个证书.
a) 这⾥客⼾端证书,其实就类似表⽰个⼈信息的时候,除了⽤⼾名/密码, 还有⼀个CA 认证过的⾝份. 应为个⼈证书⼀般来说别⼈⽆法模拟的,所有这样能够更深的确认⾃⼰的⾝份.
b) ⽬前少数个⼈银⾏的专业版是这种做法,具体证书可能是拿U盘作为⼀个备份的载体.
3 .HTTPS ⼀定是繁琐的. a) 本来简单的http协议,⼀个get⼀个response. 由于https 要还密钥和确认加密算法的需要.单握⼿就需要6/7 个往返.
i. 任何应⽤中,过多的round trip 肯定影响性能.
b) 接下来才是具体的http协议,每⼀次响应或者请求, 都要求客⼾端和服务端对会话的内容做加密/解 密.
i. 尽管对称加密/解密效率⽐较⾼,可是仍然要消耗过多的CPU,为此有专⻔的SSL 芯⽚. 如果CPU性能⽐较低的话,肯定会降低性能,从⽽不能为serve 更多的请求.
ii. 加密后数据量的影响. 所以,才会出现那么多的安全认证提⽰
1.35、tcp/ip协议簇
TCP/IP协议簇是Internet的基础,也是当今最流⾏的组⽹形式。TCP/IP是⼀组协议的代名词,包括许多别的协议,组成了TCP/IP协议簇。
其中⽐较重要的有SLIP协议、PPP协议、IP协议、ICMP协议、ARP协议、TCP协议、UDP协议、FTP 协议、DNS协议、SMTP协议等。TCP/IP协议并不完全符合OSI的七层参考模型。
传统的开放式系统互连参考模型,是⼀种通信协议的7层抽象的参考模型,其中每⼀层执⾏某⼀特定 任务。该模型的⽬的是使各种硬件在相同的层次上相互通信。
⽽TCP/IP通讯协议采⽤了4层的层级结构,每⼀层都呼叫它的下⼀层所提供的⽹络来完成⾃⼰的需求
SLIP协议编辑
SLIP提供在串⾏通信线路上封装IP分组的简单⽅法,使远程⽤⼾通过电话线和MODEM能⽅便地接⼊ TCP/IP⽹络。SLIP是⼀种简单的组帧⽅式,但使⽤时还存在⼀些问题。
⾸先,SLIP不⽀持在连接过程中的动态IP地址分配,通信双⽅必须事先告知对⽅IP地址,这给没有固 定IP地址的个⼈⽤⼾上INTERNET⽹带来了很⼤的不便。
其次,SLIP帧中⽆校验字段,因此链路层上⽆法检测出差错,必须由上层实体或具有纠错能⼒ MODEM来解决传输差错问题。
PPP协议编辑 为了解决SLIP存在的问题,在串⾏通信应⽤中⼜开发了PPP协议。PPP协议是⼀种有效的点对点通信 协议,它由串⾏通信线路上的组帧⽅式,⽤于建⽴、配制、测试和拆除数据链路的链路控制协议LCP 及⼀组⽤以⽀持不同⽹络层协议的⽹络控制协议NCPs三部分组成。 PPP中的LCP协议提供了通信双⽅进⾏参数协商的⼿段,并且提供了⼀组NCPs协议,使得PPP可以⽀ 持多种⽹络层协议,如IP,IPX,OSI等。另外,⽀持IP的NCP提供了在建⽴链接时动态分配IP地址的功 能,解决了个⼈⽤⼾上INTERNET⽹的问题。
IP协议编辑
即互联⽹协议(Internet Protocol),它将多个⽹络连成⼀个互联⽹,可以把⾼层的数据以多个数据包 的形式通过互联⽹分发出去。IP的基本任务是通过互联⽹传送数据包,各个IP数据包之间是相互独⽴ 的。
ICMP协议编辑
即互联⽹控制报⽂协议。从IP互联⽹协议的功能,可以知道IP 提供的是⼀种不可靠的⽆连接报⽂分组 传送服务。
若路由器或主机发⽣故障时⽹络阻塞,就需要通知发送主机采取相应措施。为了使互联⽹能报告差 错,或提供有关意外情况的信息,在IP层加⼊了⼀类特殊⽤途的报⽂机制,即ICMP。
分组接收⽅利⽤ICMP来通知IP模块发送⽅,进⾏必需的修改。ICMP通常是由发现报⽂有问题的站产 ⽣的,例如可由⽬的主机或中继路由器来发现问题并产⽣的ICMP。
如果⼀个分组不能传送,ICMP便可以被⽤来警告分组源,说明有⽹络,主机或端⼝不可达。ICMP也 可以⽤来报告⽹络阻塞。
ARP协议编辑
即地址转换协议。在TCP/IP⽹络环境下,每个主机都分配了⼀个32位的IP地址,这种互联⽹地址是在 ⽹际范围标识主机的⼀种逻辑地址。为了让报⽂在物理⽹上传送,必须知道彼此的物理地址。
这样就存在把互联⽹地址变换成物理地址的转换问题。这就需要在⽹络层有⼀组服务将 IP地址转换为 相应物理⽹络地址,这组协议即ARP。
TCP协议编辑
即传输控制协议,它提供的是⼀种可靠的数据流服务。当传送受差错⼲扰的数据,或举出⽹络故障, 或⽹络负荷太重⽽使⽹际基本传输系统不能正常⼯作时,就需要通过其他的协议来保证通信的可靠。
TCP就是这样的协议。TCP采⽤“带重传的肯定确认”技术来实现传输的可靠性。并使⽤“滑动窗 ⼝”的流量控制机制来提⾼⽹络的吞吐量。TCP通信建⽴实现了⼀种“虚电路”的概念。
双⽅通信之前,先建⽴⼀条链接然后双⽅就可以在其上发送数据流。这种数据交换⽅式能提⾼效率, 但事先建⽴连接和事后拆除连接需要开销。
UDP协议编辑
即⽤⼾数据包协议,它是对IP协议组的扩充,它增加了⼀种机制,发送⽅可以区分⼀台计算机上的多 个接收者。每个UDP报⽂除了包含数据外还有报⽂的⽬的端⼝的编号和报⽂源端⼝的编号,从⽽使 UDP软件可以把报⽂递送给正确的接收者,然后接收者要发出⼀个应答。
由于UDP的这种扩充,使得在两个⽤⼾进程之间递送数据包成为可能。我们频繁使⽤的OICQ软件正 是基于UDP协议和这种机制。
FTP协议编辑
即⽂件传输协议,它是⽹际提供的⽤于访问远程机器的协议,它使⽤⼾可以在本地机与远程机之间进 ⾏有关⽂件的操作。FTP⼯作时建⽴两条TCP链接,分别⽤于传送⽂件和⽤于传送控制。
FTP采⽤客⼾/服务器模式?它包含客⼾FTP和服务器FTP。客⼾FTP启动传送过程,⽽服务器FTP对其 作出应答。
DNS协议编辑
即域名服务协议,它提供域名到IP地址的转换,允许对域名资源进⾏分散管理。DNS最初设计的⽬的 是使邮件发送⽅知道邮件接收主机及邮件发送主机的IP地址,后来发展成可服务于其他许多⽬标的协 议
SMTP协议编辑
即简单邮件传送协议互联⽹标准中的电⼦邮件是⼀个简单的基于⽂本的协议,⽤于可靠、有效地数据 传输。SMTP作为应⽤层的服务,并不关⼼它下⾯采⽤的是何种传输服务,
它可通过⽹络在TXP链接上传送邮件,或者简单地在同⼀机器的进程之间通过进程通信的通道来传送 邮件,这样,邮件传输就独⽴于传输⼦系统,可在TCP/IP环境或X.25协议环境中传输邮件
1.36、tcp,udp区别
TCP(Transmission Control Protocol,传输控制协议)是⾯向连接的协议,也就是说,在收发数据 前,必须和对⽅建⽴可靠的连接。⼀个TCP连接必须要经过三次“对话”才能建⽴起来,其中的过程 ⾮常复杂,只简单的描述下这三次对话的简单过程:
主机A向主机B发出连接请求数据包:“我想给你发数据,可以吗?”,这是第⼀次对话;主机B向主 机A发送同意连接和要求同步(同步就是两台主机⼀个在发送,⼀个在接收,协调⼯作)的数据 包:“可以,你什么时候发?”,这是第⼆次对话;
主机A再发出⼀个数据包确认主机B的要求同步:“我现在就发,你接着吧!”,这是第三次对话。三 次“对话”的⽬的是使数据包的发送和接收同步,经过三次“对话”之后,主机A才向主机B正式发送 数据
UDP(User Data Protocol,⽤⼾数据报协议)
(1) UDP是⼀个⾮连接的协议,传输数据之前源端和终端不建⽴连接,当它想传送时就简单地去抓 取来⾃应⽤程序的数据,并尽可能快地把它扔到⽹络上。
在发送端,UDP传送数据的速度仅仅是受应⽤程序⽣成数据的速度、计算机的能⼒和传输带宽的限 制;在接收端,UDP把每个消息段放在队列中,应⽤程序每次从队列中读⼀个消息段。
(2) 由于传输数据不建⽴连接,因此也就不需要维护连接状态,包括收发状态等,因此⼀台服务机 可同时向多个客⼾机传输相同的消息。
(3) UDP信息包的标题很短,只有8个字节,相对于TCP的20个字节信息包的额外开销很⼩。
(4) 吞吐量不受拥挤控制算法的调节,只受应⽤软件⽣成数据的速率、传输带宽、源端和终端主机 性能的限制。
(5)UDP使⽤尽最⼤努⼒交付,即不保证可靠交付,因此主机不需要维持复杂的链接状态表(这⾥ ⾯有许多参数)。
(6)UDP是⾯向报⽂的。发送⽅的UDP对应⽤程序交下来的报⽂,在添加⾸部后就向下交付给IP 层。既不拆分,也不合并,⽽是保留这些报⽂的边界,因此,应⽤程序需要选择合适的报⽂⼤⼩。
我们经常使⽤“ping”命令来测试两台主机之间TCP/IP通信是否正常,其实“ping”命令的原理就是 向对⽅主机发送UDP数据包,然后对⽅主机确认收到数据包,如果数据包是否到达的消息及时反馈回 来,那么⽹络就是通的。
UDP的包头结构:
源端⼝ 16位
⽬的端⼝ 16位
⻓度 16位
校验和 16位
⼩结: TCP与UDP的区别:
1 .基于连接与⽆连接;
2 .对系统资源的要求(TCP较多,UDP少);
3 .UDP程序结构较简单;
4 .流模式与数据报模式 ;
5 .TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证
1.37、⽤过哪些加密算法:对称加密,⾮对称加密算法
对称加密是最快速、最简单的⼀种加密⽅式,加密(encryption)与解密(decryption)⽤的是同样 的密钥(secret key)。对称加密有很多种算法,由于它效率很⾼,所以被⼴泛使⽤在很多加密协议 的核⼼当中。
对称加密通常使⽤的是相对较⼩的密钥,⼀般⼩于256 bit。因为密钥越⼤,加密越强,但加密与解密 的过程越慢。如果你只⽤1 bit来做这个密钥,那⿊客们可以先试着⽤0来解密,不⾏的话就再⽤1解;
但如果你的密钥有1 MB⼤,⿊客们可能永远也⽆法破解,但加密和解密的过程要花费很⻓的时间。密 钥的⼤⼩既要照顾到安全性,也要照顾到效率,是⼀个trade-off
常⻅对称加密算法 DES算法,3DES算法,TDEA算法,Blowfish算法,RC5算法,IDEA算法 ⾮对称加密为数据的加密与解密提供了⼀个⾮常安全的⽅法,它使⽤了⼀对密钥,公钥(public key)和私钥(private key)。
私钥只能由⼀⽅安全保管,不能外泄,⽽公钥则可以发给任何请求它的⼈。⾮对称加密使⽤这对密钥 中的⼀个进⾏加密,⽽解密则需要另⼀个密钥。
⽐如,你向银⾏请求公钥,银⾏将公钥发给你,你使⽤公钥对消息加密,那么只有私钥的持有⼈—银 ⾏才能对你的消息解密。与对称加密不同的是,银⾏不需要将私钥通过⽹络发送出去,因此安全性⼤ ⼤提⾼。
⽬前最常⽤的⾮对称加密算法是RSA算法 Elgamal、背包算法、Rabin、HD,ECC(椭圆曲线加密算 法)
1.38、说说tcp三次握⼿,四次挥⼿
据段:”我已收到回复,我现在要开始传输实际数据了
这样3次握⼿就完成了,主机A和主机B 就可以传输数据了.
3次握⼿的特点
没有应⽤层的数据
SYN这个标志位只有在TCP建产连接时才会被置1
握⼿完成后SYN标志位被置0
TCP建⽴连接要进⾏3次握⼿,⽽断开连接要进⾏4次
1 当主机A完成数据传输后,将控制位FIN置1,提出停⽌TCP连接的请求
2 主机B收到FIN后对其作出响应,确认这⼀⽅向上的TCP连接将关闭,将ACK置1
3 由B 端再提出反⽅向的关闭请求,将FIN置1
4 主机A对主机B的请求进⾏确认,将ACK置1,双⽅向的关闭结束.
由TCP的三次握⼿和四次断开可以看出,TCP使⽤⾯向连接的通信⽅式,⼤⼤提⾼了数据通信的可靠性, 使发送数据端
和接收端在数据正式传输前就有了交互,为数据正式传输打下了可靠的基础
名词解释
ACK TCP报头的控制位之⼀,对数据进⾏确认.确认由⽬的端发出,⽤它来告诉发送端这个序列号之前的 数据段 都收到了
.⽐如,确认号为X,则表⽰前X-1个数据段都收到了,只有当ACK=1时,确认号才有效,当ACK=0时, 确认号⽆效,这时会要求重传数据,保证数据的完整性.
SYN 同步序列号,TCP建⽴连接时将这个位置1
FIN 发送端完成发送任务位,当TCP完成数据传输需要断开时,提出断开连接的⼀⽅将这位置1
TCP的包头结构:
源端⼝ 16位
⽬标端⼝ 16位
序列号 32位
回应序号 32位
TCP头⻓度 4位
reserved 6位
控制代码 6位
窗⼝⼤⼩ 16位
偏移量 16位
校验和 16位
选项 32位(可选)
这样我们得出了TCP包头的最⼩⻓度,为20字节
1.40、cookie和session的区别,分布式环境怎么保存用户状态
1、session保存在服务器,客⼾端不知道其中的信息;cookie保存在客⼾端,服务器能够知道其中的 信息。
2、session中保存的是对象,cookie中保存的是字符串。
3、session不能区分路径,同⼀个⽤⼾在访问⼀个⽹站期间,所有的session在任何⼀个地⽅都可以 访问到。⽽cookie中如果设置了路径参数,那么同⼀个⽹站中不同路径下的cookie互相是访问不到 的。
4、session需要借助cookie才能正常。如果客⼾端完全禁⽌cookie,session将失效。 分布式Session的⼏种实现⽅式
• 1 .基于数据库的Session共享
• 2 .基于NFS共享⽂件系统
• 3 .基于memcached 的session,如何保证 memcached 本⾝的⾼可⽤性?
• 4 . 基于resin/tomcat web容器本⾝的session复制机制
• 5 . 基于TT/Redis 或 jbosscache 进⾏ session 共享。
• 6 . 基于cookie 进⾏session共享
1.41、Git,svn区别
GIT是分布式的,SVN不是:这是GIT和其它⾮分布式的版本控制系统,例如SVN,CVS等,最核⼼的 区
GIT把内容按元数据⽅式存储,⽽SVN是按⽂件
GIT分⽀和SVN的分⽀不同:
分⽀在SVN中⼀点不特别,就是版本库中的另外的⼀个⽬录。如果你想知道是否合并了⼀个分⽀,你 需要⼿⼯运⾏像这样的命令svn propget svn:mergeinfo,来确认代码是否被合并。
然⽽,处理GIT的分⽀却是相当的简单和有趣。你可以从同⼀个⼯作⽬录下快速的在⼏个分⽀间切 换。你很容易发现未被合并的分⽀,你能简单⽽快捷的合并这些⽂件
GIT没有⼀个全局的版本号,⽽SVN有
GIT的内容完整性要优于SVN
1.42、ThreadLocal可以⽤来共享数据吗
ThreadLocal是基于线程对象的,类似于⼀个map ,key为当前线程对象,所以它可以在同线程内共享数 据
1.43、bio,nio,aio的区别
IO的⽅式通常分为⼏种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO
一、BIO
在JDK1.4出来之前,我们建⽴⽹络连接的时候采⽤BIO模式,需要先在服务端启动⼀个 ServerSocket,然后在客⼾端启动Socket来对服务端进⾏通信,
默认情况下服务端需要对每个请求建⽴⼀堆线程等待请求,⽽客⼾端发送请求后,先咨询服务端是 否有线程相应,如果没有则会⼀直等待或者遭到拒绝请求,如果有的话,客⼾端会线程在等待请求结束后才继续执⾏
⼆、NIO NIO本⾝是基于事件驱动思想来完成的,其主要想解决的是BIO的⼤并发问题: 在使⽤同步I/O的⽹ 络应⽤中,如果要同时处理多个客⼾端请求,或是在客⼾端要同时和多个服务器进⾏通讯,就必须使 ⽤多线程来处理。
也就是说,将每⼀个客⼾端请求分配给⼀个线程来单独处理。这样做虽然可以达到我们的要求,但 同时⼜会带来另外⼀个问题。由于每创建⼀个线程,就要为这个线程分配⼀定的内存空间(也叫⼯作 存储器),⽽且操作系统本⾝也对线程的总数有⼀定的限制。
如果客⼾端的请求过多,服务端程序可能会因为不堪重负⽽拒绝客⼾端的请求,甚⾄服务器可能会 因此⽽瘫痪。
NIO基于Reactor,当socket有流可读或可写⼊socket时,操作系统会相应的通知引⽤程序进⾏处 理,应⽤再将流读取到缓冲区或写⼊操作系统。
也就是说,这个时候,已经不是⼀个连接就要对应⼀个处理线程了,⽽是有效的请求,对应⼀个线 程,当连接没有数据时,是没有⼯作线程来处理的。
BIO与NIO⼀个⽐较重要的不同,是我们使⽤BIO的时候往往会引⼊多线程,每个连接⼀个单独的线 程;⽽NIO则是使⽤单线程或者只使⽤少量的多线程,每个连接共⽤⼀个线程。
NIO的最重要的地⽅是当⼀个连接创建后,不需要对应⼀个线程,这个连接会被注册到多路复⽤器 上⾯,所以所有的连接只需要⼀个线程就可以搞定,
当这个线程中的多路复⽤器进⾏轮询的时候,发现连接上有请求的话,才开启⼀个线程进⾏处 理,也就是⼀个请求⼀个线程模式
在NIO的处理⽅式中,当⼀个请求来的话,开启线程进⾏处理,可能会等待后端应⽤的资源(JDBC 连接等),其实这个线程就被阻塞了,当并发上来的话,还是会有BIO⼀样的问题。
HTTP/1.1出现后,有了Http⻓连接,这样除了超时和指明特定关闭的http header外,这个链接 是⼀直打开的状态的,这样在NIO处理中可以进⼀步的进化,在后端资源中可以实现资源池或者队 列,
当请求来的话,开启的线程把请求和请求数据传送给后端资源池或者队列⾥⾯就返回,并且在全局 的地⽅保持住这个现场(哪个连接的哪个请求等),这样前⾯的线程还是可以去接受其他的请求,
⽽后端的应⽤的处理只需要执⾏队列⾥⾯的就可以了,这样请求处理和后端应⽤是异步的.当后端处 理完,到全局地⽅得到现场,产⽣响应,这个就实现了异步处理。
三、AIO
与NIO不同,当进⾏读写操作时,只须直接调⽤API的read或write⽅法即可。这两种⽅法均为异步 的,对于读操作⽽⾔,当有流可读取时,操作系统会将可读的流传⼊read⽅法的缓冲区,并通知应⽤ 程序;
对于写操作⽽⾔,当操作系统将write⽅法传递的流写⼊完毕时,操作系统主动通知应⽤程序。 即 可以理解为,read/write⽅法都是异步的,完成后会主动调⽤回调函数。
在JDK1.7中,这部分内容被称作NIO.2,主要在Java.nio.channels包下增加了下⾯四个异步通道:
AsynchronousSocketChannelAsynchronousServerSocketChannelAsynchronousFileChannelAsynchronousDatagramChannel
其中的read/write⽅法,会返回⼀个带回调函数的对象,当执⾏完读取/写⼊操作后,直接调⽤回调函 数。
BIO是⼀个连接⼀个线程。
NIO是⼀个请求⼀个线程。
AIO是⼀个有效请求⼀个线程。
先来个例⼦理解⼀下概念,以银⾏取款为例:
同步 : ⾃⼰亲⾃出⻢持银⾏卡到银⾏取钱(使⽤同步IO时,Java⾃⼰处理IO读写);
异步 : 委托⼀⼩弟拿银⾏卡到银⾏取钱,然后给你(使⽤异步IO时,Java将IO读写委托给OS处理, 需要将数据缓冲区地址和⼤⼩传给OS(银⾏卡和密码),OS需要⽀持异步IO操作API);
阻塞 : ATM排队取款,你只能等待(使⽤阻塞IO时,Java调⽤会⼀直阻塞到读写完成才返回);
非阻塞 : 柜台取款,取个号,然后坐在椅⼦上做其它事,等号⼴播会通知你办理,没到号你就不能 去,你可以不断问⼤堂经理排到了没有,⼤堂经理如果说还没到你就不能去(使⽤非阻塞IO时,如果不能读写Java调⽤会⻢上返回,当IO事件分发器会通知可读写时再继续进⾏读写,不断循环直到读写 完成)
Java对BIO、NIO、AIO的⽀持:
Java BIO : 同步并阻塞,服务器实现模式为⼀个连接⼀个线程,即客⼾端有连接请求时服务器端就 需要启动⼀个线程进⾏处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线 程池机制改善。
java NIO : 同步⾮阻塞,服务器实现模式为⼀个请求⼀个线程,即客⼾端发送的连接请求都会注册 到多路复⽤器上,多路复⽤器轮询到连接有I/O请求时才启动⼀个线程进⾏处理。
Java AIO(NIO.2) : 异步⾮阻塞,服务器实现模式为⼀个有效请求⼀个线程,客⼾端的I/O请求都是由 OS先完成了再通知服务器应⽤去启动线程进⾏处理,
BIO、NIO、AIO适⽤场景分析:
BIO⽅式适⽤于连接数⽬⽐较⼩且固定的架构,这种⽅式对服务器资源要求⽐较⾼,并发局限于应⽤ 中,JDK1.4以前的唯⼀选择,但程序直观简单易理解。
NIO⽅式适⽤于连接数⽬多且连接⽐较短(轻操作)的架构,⽐如聊天服务器,并发局限于应⽤中, 编程⽐较复杂,JDK1.4开始⽀持。
AIO⽅式使⽤于连接数⽬多且连接⽐较⻓(重操作)的架构,⽐如相册服务器,充分调⽤OS参与并发 操作,编程⽐较复杂,JDK7开始⽀持。
另外,I/O属于底层操作,需要操作系统⽀持,并发也需要操作系统的⽀持,所以性能⽅⾯不同操作 系统差异会⽐较明显。
在⾼性能的I/O设计中,有两个⽐较著名的模式Reactor和Proactor模式,其中Reactor模式⽤于同步 I/O,⽽Proactor运⽤于异步I/O操作。
在⽐较这两个模式之前,我们⾸先的搞明⽩⼏个概念,什么是阻塞和⾮阻塞,什么是同步和异步,同 步和异步是针对应⽤程序和内核的交互⽽⾔的,
同步指的是⽤⼾进程触发IO操作并等待或者轮询的去查看IO操作是否就绪,⽽异步是指⽤⼾进程触 发IO操作以后便开始做⾃⼰的事情,⽽当IO操作已经完成的时候会得到IO完成的通知。
⽽阻塞和⾮阻塞是针对于进程在访问数据的时候,根据IO操作的就绪状态来采取的不同⽅式,说⽩ 了是⼀种读取或者写⼊操作函数的实现⽅式,阻塞⽅式下读取或者写⼊函数将⼀直等待,⽽⾮阻塞⽅ 式下,读取或者写⼊函数会⽴即返回⼀个状态值。
⼀般来说I/O模型可以分为:同步阻塞,同步⾮阻塞,异步阻塞,异步⾮阻塞IO
同步阻塞IO:在此种⽅式下,⽤⼾进程在发起⼀个IO操作以后,必须等待IO操作的完成,只有当真正 完成了IO操作以后,⽤⼾进程才能运⾏。JAVA传统的IO模型属于此种⽅式!
同步⾮阻塞IO:在此种⽅式下,⽤⼾进程发起⼀个IO操作以后边可返回做其它事情,但是⽤⼾进程需 要时不时的询问IO操作是否就绪,这就要求⽤⼾进程不停的去询问,从⽽引⼊不必要的CPU资源浪 费。其中⽬前JAVA的NIO就属于同步⾮阻塞IO
异步阻塞IO:此种⽅式下是指应⽤发起⼀个IO操作以后,不等待内核IO操作的完成,等内核完成IO操 作以后会通知应⽤程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问IO是 否完成,那么为什么说是阻塞的呢?因为此时是通过select系统调⽤来完成的,⽽select函数本⾝的 实现⽅式是阻塞的,⽽采⽤select函数有个好处就是它可以同时监听多个⽂件句柄,从⽽提⾼系统的 并发性!
异步⾮阻塞IO:在此种模式下,⽤⼾进程只需要发起⼀个IO操作然后⽴即返回,等IO操作真正的完成 以后,应⽤程序会得到IO操作完成的通知,此时⽤⼾进程只需要对数据进⾏处理就好了,不需要进⾏ 实际的IO读写操作,
因为真正的IO读取或者写⼊操作已经由内核完成了。⽬前Java中还没有⽀持此种IO模型
1.44、nio框架:dubbo的实现原理;
client⼀个线程调⽤远程接⼝,⽣成⼀个唯⼀的ID(⽐如⼀段随机字符串,UUID等),Dubbo是使⽤ AtomicLong从0开始累计数字的
将打包的⽅法调⽤信息(如调⽤的接⼝名称,⽅法名称,参数值列表等),和处理结果的回调对象 callback,全部封装在⼀起,组成⼀个对象object
向专⻔存放调⽤信息的全局ConcurrentHashMap⾥⾯put(ID, object)
将ID和打包的⽅法调⽤信息封装成⼀对象connRequest,使⽤IoSession.write(connRequest)异步发 送出去
当前线程再使⽤callback的get()⽅法试图获取远程返回的结果,在get()内部,则使⽤synchronized 获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调⽤callback的wait() ⽅法,释放callback上的锁,让当前线程处于等待状态。
服务端接收到请求并处理后,将结果(此结果中包含了前⾯的ID,即回传)发送给客⼾端,客⼾端 socket连接上专⻔监听消息的线程收到消息,分析结果,取到ID,再从前⾯的ConcurrentHashMap ⾥⾯get(ID),从⽽找到callback,将⽅法调⽤结果设置到callback对象⾥。
监听线程接着使⽤synchronized获取回调对象callback的锁(因为前⾯调⽤过wait(),那个线程已释 放callback的锁了),再notifyAll(),唤醒前⾯处于等待状态的线程继续执⾏(callback的get()⽅法 继续执⾏就能拿到调⽤结果了),⾄此,整个过程结束。
当前线程怎么让它“暂停”,等结果回来后,再向后执⾏?
答:先⽣成⼀个对象obj,在⼀个全局map⾥put(ID,obj)存放起来,再⽤synchronized获取obj 锁,再调⽤obj.wait()让当前线程处于等待状态,然后另⼀消息监听线程等到服 务端结果来了 后,再map.get(ID)找到obj,再⽤synchronized获取obj锁,再调⽤obj.notifyAll()唤醒前⾯处于等待 状态的线程。
正如前⾯所说,Socket通信是⼀个全双⼯的⽅式,如果有多个线程同时进⾏远程⽅法调⽤,这时建⽴ 在client server之间的socket连接上会有很多双⽅发送的消息传递,前后顺序也可能是乱七⼋糟的, server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先 哪个线程调⽤的?
答:使⽤⼀个ID,让其唯⼀,然后传递给服务端,再服务端⼜回传回来,这样就知道结果是原先哪 个线程的了
第⼆章:JVM
2.1、介绍下Java内存区域(运⾏时数据区)
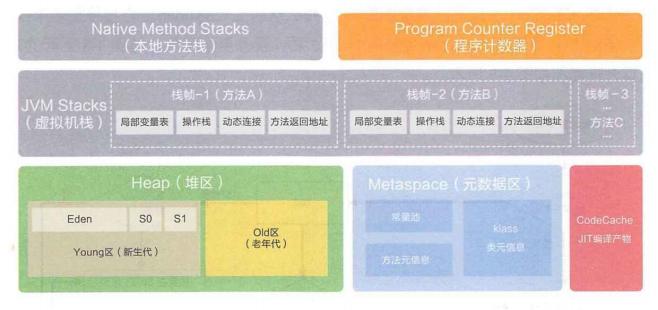
1)程序计数器(Program Counter Register)
⼀块较⼩的内存空间,可以看作当前线程所执⾏的字节码的行号指⽰器。如果线程正在执⾏的是⼀个 Java⽅法,这个计数器记录的是正在执⾏的虚拟机字节码指令的地址;如果正在执⾏的是Native⽅ 法,这个计数器值则为空。
2)Java虚拟机栈(Java Virtual Machine Stacks)
与程序计数器⼀样,Java虚拟机栈也是线程私有的,它的⽣命周期与线程相同。虚拟机栈描述的是 Java⽅法执⾏的内存模型:每个⽅法在执⾏的同时都会创建⼀个栈帧⽤于存储局部变量表、操作数 栈、动态链接、⽅法出⼝等信息。每⼀个⽅法从调⽤直⾄执⾏完成的过程,就对应着⼀个栈帧在虚拟 机栈中⼊栈到出栈的过程。
3)本地⽅法栈(Native Method Stack)
本地⽅法栈与虚拟机栈所发挥的作⽤是⾮常相似的,它们之间的区别不过是虚拟机栈为虚拟机执⾏ Java⽅法(也就是字节码)服务,⽽本地⽅法栈则为虚拟机使⽤到的Native⽅法服务。
4)Java堆(Java Heap)
对⼤多数应⽤来说,Java堆是Java虚拟机所管理的内存中最⼤的⼀块。Java堆是被所有线程共享的 ⼀块内存区域,在虚拟机启动时创建。此内存区域的唯⼀⽬的就是存放对象实例,⼏乎所有的对象实 例都在这⾥分配内存。
5)元数据区(Method Area) 在JDK1.7的时候,有⼀个JVM内存区域中有⼀块⽅法区,主要存放虚拟机加载的类信息,静态变量, 常量等。JDK1.8时,移除了⽅法区的概念,⽤⼀个元数据区代替。与Java堆⼀样,是各个线程共享 的内存区域,它⽤于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数 据。⽅法区是JVM规范中定义的⼀个概念,具体放在哪⾥,不同的实现可以放在不同的地⽅。
6)运⾏时常量池(Runtime Constant Pool) 运⾏时常量池是⽅法区的⼀部分。Class⽂件中除了有类的版本、字段、⽅法、接⼝等描述信息外, 还有⼀项信息是常量池,⽤于存放编译期⽣成的各种字⾯量和符号引⽤,这部分内容将在类加载后进 ⼊⽅法区的运⾏时常量池中存放
2.2、怎么判定对象已经“死去”?
常⻅的判定⽅法有两种:引⽤计数法和可达性分析算法,HotSpot中采⽤的是可达性分析算法。
引⽤计数法 给对象中添加⼀个引⽤计数器,每当有⼀个地⽅引⽤它时,计数器值就加1;当引⽤失效时,计数器 值就减1;任何时刻计数器为0的对象就是不可能再被使⽤的。
客观地说,引⽤计数算法的实现简单,判定效率也很⾼,在⼤部分情况下它都是⼀个不错的算法,但 是主流的Java虚拟机⾥⾯没有选⽤引⽤计数算法来管理内存,其中最主要的原因是它很难解决对象之 间相互循环引⽤的问题。
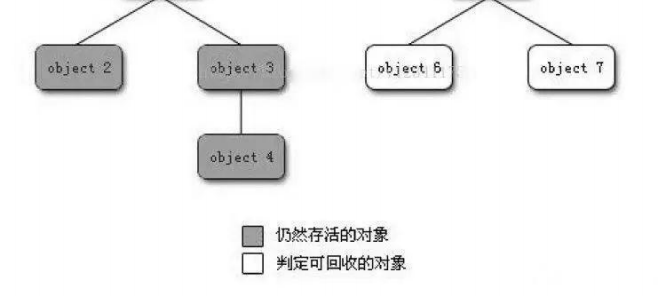
可达性分析算法 这个算法的基本思路就是通过⼀系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜 索,搜索所⾛过的路径称为引⽤链,当⼀个对象到GC Roots没有任何引⽤链相连(⽤图论的话来说, 就是从GC Roots到这个对象不可达)时,则证明此对象是不可⽤的。如下图所⽰,对象object 5、 object 6、object 7虽然互相有关联,但是它们到GC Roots是不可达的,所以它们将会被判定为是可 回收的对象
2.3、介绍下四种引⽤(强引⽤、软引⽤、弱引⽤、虚引⽤)?
强引⽤:在程序代码之中普遍存在的,类似“Object obj=new Object()”这类的引⽤,只要强引⽤还 存在,垃圾收集器永远不会回收掉被引⽤的对象。
软引⽤:⽤来描述⼀些还有⽤但并⾮必需的对象,使⽤SoftReference类来实现软引⽤,在系统将要 发⽣内存溢出异常之前,将会把这些对象列进回收范围之中进⾏第⼆次回收。
弱引⽤:⽤来描述⾮必需对象的,使⽤WeakReference类来实现弱引⽤,被弱引⽤关联的对象只能⽣ 存到下⼀次垃圾收集发⽣之前。
虚引⽤:是最弱的⼀种引⽤关系,使⽤PhantomReference类来实现虚引⽤,⼀个对象是否有虚引⽤ 的存在,完全不会对其⽣存时间构成影响,也⽆法通过虚引⽤来取得⼀个对象实例。为⼀个对象设置 虚引⽤关联的唯⼀⽬的就是能在这个对象被收集器回收时收到⼀个系统通知。
2.4、垃圾收集有哪些算法,各⾃的特点?
标记 - 清除算法
⾸先标记出所有需要回收的对象,在标记完成后统⼀回收所有被标记的对象。它的主要不⾜有两个: ⼀个是效率问题,标记和清除两个过程的效率都不⾼;另⼀个是空间问题,标记清除之后会产⽣⼤量 不连续的内存碎⽚,空间碎⽚太多可能会导致以后在程序运⾏过程中需要分配较⼤对象时,⽆法找到 ⾜够的连续内存⽽不得不提前触发另⼀次垃圾收集动作。
复制算法
为了解决效率问题,⼀种称为“复制”(Copying)的收集算法出现了,它将可⽤内存按容量划分为 ⼤⼩相等的两块,每次只使⽤其中的⼀块。当这⼀块的内存⽤完了,就将还存活着的对象复制到另外 ⼀块上⾯,然后再把已使⽤过的内存空间⼀次清理掉。这样使得每次都是对整个半区进⾏内存回收, 内存分配时也就不⽤考虑内存碎⽚等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简 单,运⾏⾼效。只是这种算法的代价是将内存缩⼩为了原来的⼀半,未免太⾼了⼀点。
标记 - 整理算法
根据⽼年代的特点,有⼈提出了另外⼀种“标记-整理”(Mark-Compact)算法,标记过程仍然 与“标记-清除”算法⼀样,但后续步骤不是直接对可回收对象进⾏清理,⽽是让所有存活的对象都 向⼀端移动,然后直接清理掉端边界以外的内存。
分代收集算法
当前商业虚拟机的垃圾收集都采⽤“分代收集”算法,这种算法并⽆新的⽅法,只是根据对象的存活 周期的不同将内存划分为⼏块,⼀般是把Java堆分为新⽣代和⽼年代,这样就可以根据各个年代的特 点采⽤最适当的收集算法。在新⽣代中,每次垃圾收集时都发现有⼤批对象死去,只有少量存活,那 就选⽤复制算法,只需要付出少量存活对象的复制成本就可以完成收集。⽽⽼年代中因为对象存活率 ⾼、没有额外空间对它进⾏分配担保,就必须使⽤“标记-清理”或“标记-整理”算法来进⾏回收
2.5、HotSpot为什么要分为新⽣代和⽼年代?
HotSpot根据对象存活周期的不同将内存划分为⼏块,⼀般是把Java堆分为新⽣代和⽼年代,这样就 可以根据各个年代的特点采⽤最适当的收集算法。在新⽣代中,每次垃圾收集时都发现有⼤批对象死 去,只有少量存活,那就选⽤复制算法,只需要付出少量存活对象的复制成本就可以完成收集。⽽⽼ 年代中因为对象存活率⾼、没有额外空间对它进⾏分配担保,就必须使⽤“标记—清理”或者“标记 —整理”算法来进⾏回收。
其中新⽣代⼜分为1个Eden区和2个Survivor区,通常称为From Survivor和To Survivor区
2.6、新⽣代中Eden区和Survivor区的默认⽐例
在HotSpot虚拟机中,Eden区和Survivor区的默认⽐例为8:1:1,即-XX:SurvivorRatio=8,其中 Survivor分为From Survivor和ToSurvivor,因此Eden此时占新⽣代空间的80%
2.7、HotSpot GC的分类
针对HotSpot VM的实现,它⾥⾯的GC其实准确分类只有两⼤种:
1)Partial GC:并不收集整个GC堆的模式,具体如下:
- Young GC/Minor GC:只收集新⽣代的GC。
- Old GC:只收集⽼年代的GC。只有CMS的concurrent collection是这个模式。
- Mixed GC:收集整个新⽣代以及部分⽼年代的GC,只有G1有这个模式。
2)Full GC/Major GC:收集整个GC堆的模式,包括新⽣代、⽼年代、永久代(如果存在的话)等所 有部分的模式。
FullGC是对整个堆来说的,出现Full GC的时候经常伴随⾄少⼀次的Minor GC,但⾮绝对的。Major GC的速度⼀般会⽐Minor GC慢10倍以上
2.8、HotSpot GC的触发条件?
这⾥只说常⻅的Young GC和Full GC。
Young GC:当新⽣代中的Eden区没有⾜够空间进⾏分配时会触发Young GC。
Full GC:
- 当准备要触发⼀次Young GC时,如果发现统计数据说之前Young GC的平均晋升⼤⼩⽐⽬前⽼年代 剩余的空间⼤,则不会触发Young GC⽽是转为触发Full GC。(通常情况)
- 如果有永久代的话,在永久代需要分配空间但已经没有⾜够空间时,也要触发⼀次Full GC。
- System.gc()默认也是触发Full GC。
- heap dump带GC默认也是触发Full GC。
- CMS GC时出现Concurrent Mode Failure会导致⼀次Full GC的产⽣。
2.9、Full GC后⽼年代的空间反⽽变⼩?
HotSpot的Full GC实现中,默认新⽣代⾥所有活的对象都要晋升到⽼年代,实在晋升不了才会留在新 ⽣代。假如做Full GC的时候,⽼年代⾥的对象⼏乎没有死掉的,⽽新⽣代⼜要晋升活对象上来,那么 Full GC结束后⽼年代的使⽤量⾃然就上升了。
2.10、什么情况下新⽣代对象会晋升到⽼年代?
- 如果新⽣代的垃圾收集器为Serial和ParNew,并且设置了-XX:PretenureSizeThreshold参数,当 对象⼤于这个参数值时,会被认为是⼤对象,直接进⼊⽼年代。
- Young GC后,如果对象太⼤⽆法进⼊Survivor区,则会通过分配担保机制进⼊⽼年代。
- 对象每在Survivor区中“熬过”⼀次Young GC,年龄就增加1岁,当它的年龄增加到⼀定程度(默 认为15岁,可以通过-XX:MaxTenuringThreshold设置),就将会被晋升到⽼年代中。
- 如果在Survivor区中相同年龄所有对象⼤⼩的总和⼤于Survivor空间的⼀半,年龄⼤于或等于该年 龄的对象就可以直接进⼊⽼年代,⽆须等到MaxTenuringThreshold中要求的年龄。
2.11、新⽣代垃圾回收器和⽼年代垃圾回收器都有哪些?有什么区别
• 新⽣代回收器:Serial、ParNew、Parallel Scavenge
• ⽼年代回收器:Serial Old、Parallel Old、CMS
• 整堆回收器:G1
新⽣代垃圾回收器⼀般采⽤的是复制算法,复制算法的优点是效率⾼,缺点是内存利⽤率低;⽼年代 回收器⼀般采⽤的是标记-整理的算法进⾏垃圾回收。
1)Serial收集器(复制算法): 新⽣代单线程收集器,标记和清理都是单线程,优点是简单⾼效;
2)ParNew收集器 (复制算法): 新⽣代收并⾏集器,实际上是Serial收集器的多线程版本,在多核 CPU环境下有着⽐Serial更好的表现;
3)Parallel Scavenge收集器 (复制算法): 新⽣代并⾏收集器,追求⾼吞吐量,⾼效利⽤ CPU。吞吐 量 = ⽤⼾线程时间/(⽤⼾线程时间+GC线程时间),⾼吞吐量可以⾼效率的利⽤CPU时间,尽快完成程 序的运算任务,适合后台应⽤等对交互相应要求不⾼的场景;
4)Serial Old收集器 (标记-整理算法): ⽼年代单线程收集器,Serial收集器的⽼年代版本;
5)Parallel Old收集器 (标记-整理算法): ⽼年代并⾏收集器,吞吐量优先,Parallel Scavenge收 集器的⽼年代版本;
6)CMS(Concurrent Mark Sweep)收集器(标记-清除算法): ⽼年代并⾏收集器,以获取最短回 收停顿时间为⽬标的收集器,具有⾼并发、低停顿的特点,追求最短GC回收停顿时间。对于要求服 务器响应速度的应⽤上,这种垃圾回收器⾮常适合。在启动 JVM 的参数加上“- XX:+UseConcMarkSweepGC”来指定使⽤ CMS 垃圾回收器。CMS 使⽤的是标记-清除的算法实现 的,所以在 gc 的时候回产⽣⼤量的内存碎⽚,当剩余内存不能满⾜程序运⾏要求时,系统将会出现 Concurrent Mode Failure,临时 CMS 会采⽤ Serial Old 回收器进⾏垃圾清除,此时的性能将会被降 低。
7)G1(Garbage First)收集器 (标记-整理算法): Java堆并⾏收集器,G1收集器是JDK1.7开始提供 的⼀个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产⽣内存碎⽚。此外,G1收 集器不同于之前的收集器的⼀个重要特点是:G1回收的范围是整个Java堆(包括新⽣代,⽼年代),⽽ 前六种收集器回收的范围仅限于新⽣代或⽼年代
第三章:集合
3.1:有用过ArrayList吗? 它是做什么用的
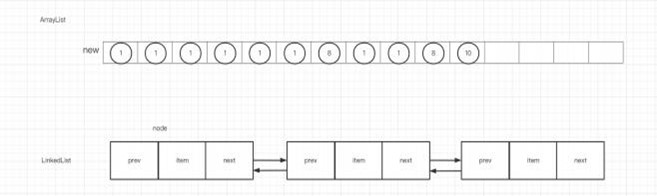
ArrayList就是数组列表,底层是数组 Object[] elementData。ArrayList在装载基本数据类型时,实 际装载的是对应的包装类。 与ArrayList类似的还有LinkedList,他们俩相⽐:
- ArrayList:查找和访问元素的速度快,新增、删除的速度慢。线程不安全,使⽤频率⾼。
- LinkedList:查找和访问元素的速度慢,新增、删除的速度快。
3.2:ArrayList线程不安全,为什么还要去⽤?
实际开发中有以下⼏种场景:
- 频繁增删:使⽤LinkedList,但是涉及到频繁增删的场景不多
- 追求线程安全:使⽤Vector。
- 普通的⽤来查询:使⽤ArrayList,使⽤的场景最多。
根据数据结构的特性,三者难以全包含,只能在相互之间做取舍。
3.3:ArrayList线程不安全,为什么还要去用?
使⽤⽆参构造创建ArrayList
/*** Default initial capacity.* 默认的初始化容量*/private static final int DEFAULT_CAPACITY = 10;/*** Shared empty array instance used for default sized empty instances. We* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when* first element is added.这个是创建的默认⼤⼩的空数组。EMPTY_ELEMENTDATA⽤于表⽰当第⼀个数据被添加时该空数组初始化的⼤⼩。*/private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/*** Constructs an empty list with an initial capacity of ten.* 构造⼀个空的List,该List具有10个容量*/public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
使⽤ArrayList空参的构造器创建集合时,数组并没有创建。当集合中添加第⼀个元素时,数组被创 建,初始化容量为4. • 使⽤有参构造创建ArrayList 有参构造创建时,如果指定了容量则会创建出指定容量⼤⼩的数组。如果指定容量为0,则⽆参构造 ⼀样。
/*** Constructs an empty list with the specified initial capacity.** @param initialCapacity the initial capacity of the list* @throws IllegalArgumentException if the specified initial capacity* is negative*/public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}
3.4:ArrayList(int initialCapacity)会不会初始化数组⼤⼩?
/*** Constructs an empty list with the specified initial capacity.** @param initialCapacity the initial capacity of the list* @throws IllegalArgumentException if the specified initial capacity* is negative*/public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}
会 初始化⼤⼩,但如果通过ArrayList的size()⽅法进⾏判断时结果依然为0,因为只有在添加元素时才 会对ArrayList的size属性+1
/*** The size of the ArrayList (the number of elements it contains).** @serial*/private int size;
3.5:ArrayList底层是⽤数组实现,但数组⻓度是有限的,如何实现扩容?
当新增元素,ArrayList放不下该元素时,触发扩容。
扩容的容量将会是原容量的1/2,也就是新容量是旧容量的1.5倍。
确定新容量确定的源码:
/*** Increases the capacity to ensure that it can hold at least the* number of elements specified by the minimum capacity argument.** @param minCapacity the desired minimum capacity*/private void grow(int minCapacity) {// overflow-conscious codeint oldCapacity = elementData.length;//新容量=旧容量+1/2旧容量int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}
执⾏扩容时使⽤系统类System的数组复制⽅法arraycopy()进⾏扩容
扩容的源码:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {@SuppressWarnings("unchecked")T[] copy = ((Object)newType == (Object)Object[].class)? (T[]) new Object[newLength]: (T[]) Array.newInstance(newType.getComponentType(), newLength);System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));return copy;}
3.6:ArrayList1.7之前和1.7及以后的区别?
1.7之前ArrayList在初始化的时候直接调⽤this(10),初始化容量为10的数组。在1.7及以后,只有第 ⼀次执⾏add⽅法向集合添加元素时才会创建容量为10的数组
3.7:为什么ArrayList增删⽐较慢,增删是如何做的?
没有指定index添加元素 直接添加到最后,如果容量不够则需要扩容
/*** Appends the specified element to the end of this list.** @param e element to be appended to this list* @return <tt>true</tt> (as specified by {@link Collection#add})*/public boolean add(E e) {ensureCapacityInternal(size + 1); // Increments modCount!!elementData[size++] = e;return true;}
如果指定了index添加元素
/*** Inserts the specified element at the specified position in this* list. Shifts the element currently at that position (if any) and* any subsequent elements to the right (adds one to their indices).** @param index index at which the specified element is to be inserted* @param element element to be inserted* @throws IndexOutOfBoundsException {@inheritDoc}*/public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size + 1); // Increments modCount!!System.arraycopy(elementData, index, elementData, index + 1,size - index);elementData[index] = element;size++;}
从源码⾥看到,是将要添加的元素位置index之后的已有元素全部拷⻉到添加到原数组index+1处,然 后再把新的数据加⼊
3.8:ArrayList插⼊和删除数据⼀定慢吗?
不⼀定,取决于删除的数据离数组末端有多远,如果离末端较近,则性能不⼀定差。
3.9:ArrayList如何删除数据?
/** Private remove method that skips bounds checking and does not* return the value removed.*/private void fastRemove(int index) {modCount++;int numMoved = size - index - 1;if (numMoved > 0)System.arraycopy(elementData, index+1, elementData, index,numMoved);elementData[--size] = null; // clear to let GC do its work}
ArrayList删除数据时同样使⽤拷⻉数组的⽅式,将要删除的位置之后的所有元素拷到当前位置,最后 再对最后⼀个位置的数据设置为null,交给gc来回收。这种删除,其实就是覆盖,如果数据量⼤,那 么效率很低。
3.10:ArrayList适合做队列吗?
队列需要遵循先进先出的原则,如果从ArrayList的数组头部⼊队列,数组尾部出队列,那么对于⼊队 列时的操作,会涉及⼤数据量的数组拷⻉,⼗分耗性能。队头队尾反⼀反也是⼀样,因此ArrayList不 适合做队列。
3.11:数组适合做队列吗?
ArrayBlockingQueue环形队列就是⽤数组来实现的。ArrayBlockingQueue的存和取操作的索引是在 当索引值等于容量值时,将索引值设置为0实现环形队列的效果,因此在这种情况下,数组适合做队 列
/*** Inserts element at current put position, advances, and signals.* Call only when holding lock.*/private void enqueue(E x) {// assert lock.getHoldCount() == 1;// assert items[putIndex] == null;final Object[] items = this.items;items[putIndex] = x;if (++putIndex == items.length)putIndex = 0;count++;notEmpty.signal();}
/*** Extracts element at current take position, advances, and signals.* Call only when holding lock.*/private E dequeue() {// assert lock.getHoldCount() == 1;// assert items[takeIndex] != null;final Object[] items = this.items;@SuppressWarnings("unchecked")E x = (E) items[takeIndex];items[takeIndex] = null;if (++takeIndex == items.length)takeIndex = 0;count--;if (itrs != null)itrs.elementDequeued();notFull.signal();return x;}
3.12:ArrayList和LinkedList两者的遍历性能孰优孰劣?
ArrayList的遍历性能明显要⽐LinkedList好,因为ArrayList存储的数据在内存中时连续的,CPU内部 缓存结构会缓存连续的内存⽚段,可以⼤幅降低读取内存的性能开销
3.13:了解数据结构中的HashMap吗?介绍下他的结构和底层原理
HashMap是由数组+链表组成的数据结构(jdk1.8中是数组+链表+红⿊树的数据结构)
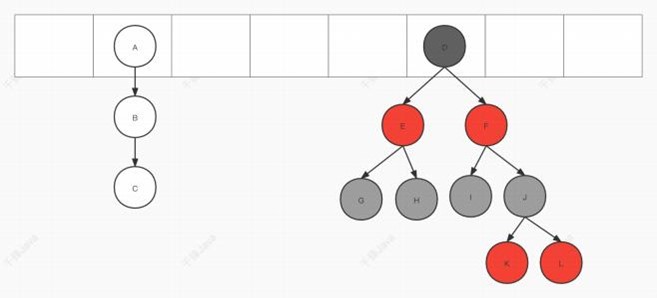
1.7 版本:根据hash(key)确定存储位置后,以链表的形式在该位置处存数据。此时数组该位置的 链表存了多个数据,因此也称为桶
存放的数据是⽤Entry描述:
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;int hash;/*** Creates new entry.*/Entry(int h, K k, V v, Entry<K,V> n) {value = v;next = n;key = k;hash = h;}
1.8 版本: 存放的数据是⽤Node描述:
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}
链表有可能过⻓,所以在满⾜以下条件时,链表会转换成红⿊树
- 链表⻓度>8
- 数组⼤⼩>=64
- 1.8版本:当红⿊树节点个数<6时转换为链表
3.14:那你清楚HashMap的插⼊数据的过程吗?
3.15:刚才你提到HashMap的初始化,那HashMap怎么设定初始容量⼤ ⼩的?
如果没有指定容量:则使⽤默认的容量为16,负载因⼦0.75
/*** Constructs an empty <tt>HashMap</tt> with the default initial capacity* (16) and the default load factor (0.75).*/public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}
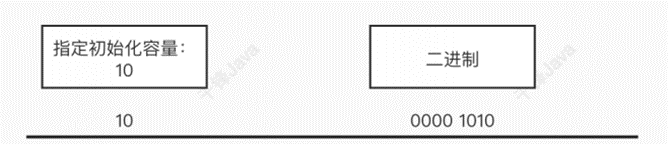
如果指定了容量,则会初始化容量为:⼤于指定容量的,最近的2的整数次⽅的数。⽐如传⼊是 10,则会初始化容量为16(2的4次⽅)
具体实现:
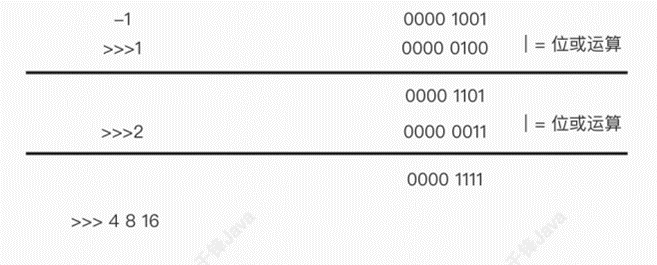
/*** Returns a power of two size for the given target capacity.*/static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
该算法的逻辑是让⾼位1的之后所有位上的数都为1,再做+1的操作,实现初始化容量为:⼤于指定容 量的,最近的2的整数次⽅的数
3.16:你提到hash函数,你知道HashMap的hash函数是如何设计的?
// jdk1.8static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}//jdk1.7 相⽐jdk1.8, jdk1.7做了四次移位和四次异或运算,效率⽐1.8要低h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);
⽤key的hashCode()与其低16位做异或运算。这个扰动函数的设计有两个原因: • 计算出来的hash值尽量分散,降级hash碰撞的概率 • ⽤位运算做算法,更加⾼效 这样答只是答了表象的东西,深层的内容是这样的: ⾸先我们要知道hash运算的⽬的是⽤来定位该数据要存放在数组的哪个位置,如何计算?
// jdk 1.8if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);// jdk 1.7static int indexFor(int h, int length) {// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";return h & (length-1);}
是通过n-1的操作与原hash值做“与”运算,其中n是数组的⻓度。相当于是更⾼效的%取模运算。⽽ n-1恰好是⼀个低位掩码。⽐如初始化⻓度是16,那n-1是15,即⼆进制的0000 1111。 此时得到了另⼀个问题的答案:那么为什么不能直接⽤key的hashCode()作为hash值,⽽⼀定要^ (h >>> 16)? 因为如果直接⽤key的hashCode()作为hash值,很容易发⽣hash碰撞。 使⽤扰动函数^ (h >>> 16),就是为了混淆原始哈希码的⾼位和低位,以此来加⼤低位的随机性。且低 位中参杂了⾼位的信息,这样⾼位的信息也作为扰动函数的关键信息

3.17:1.8相⽐1.7,做了哪些优化?
1.8除了引⼊了红⿊树,将时间复杂度由O(n)降为O(log n)以外,还将1.7的头插法改为1.8的尾插法。
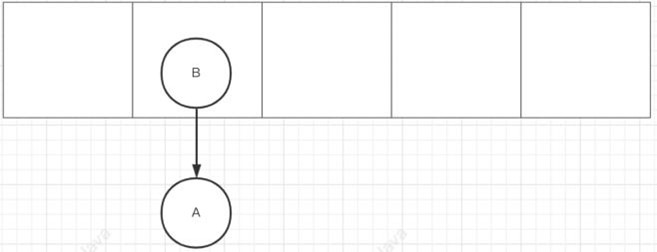
• 头插法: 作者认为,后插⼊的数据,被访问的概率更⾼,所以使⽤了头插法,但头插法会存在遍历时死循环的 情况
扩容之前:
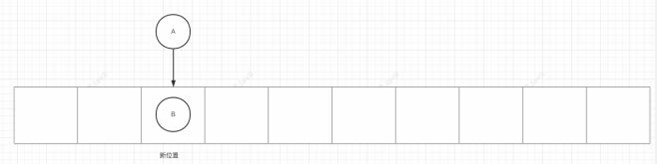
扩容之后:获得新的index,头插法会导致链表反转:
源码:
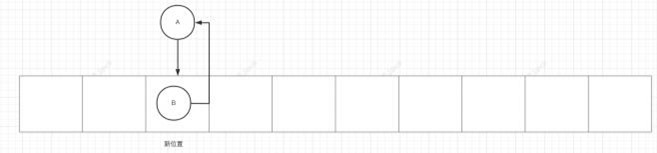
/*** Transfers all entries from current table to newTable.*/void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i]; //此处如果发⽣并发,线程1执⾏反转过程中线程2执⾏newTable[i] = e;e = next;}}}
当线程1执⾏反转过程中线程2执⾏,就可能会出现如下情况,造成链表成环的死循环问题
• 尾插法
在扩容时会保持链表元素原先的顺序,因此不会出现链表成环的死循环问题。
3.18:HashMap怎么实现扩容的?
HashMap执⾏扩容关系到两个参数:
Capacity:HashMap当前容量
loadFactor:负载因⼦(默认是0.75)
当HashMap容量达到Capacity*loadFactor时,进⾏扩容。
1.7和1.8版本的扩容区别:
• 1.7版本 先扩容,再插⼊数据。扩容时会创建⼀个为原数组的2倍⼤⼩的数组,然后将原数组的元素重新 hash,存进新数组。
• 1.8版本 先插⼊数据,再执⾏扩容。扩容时会创建⼀个为原数组的2倍⼤⼩的数组,然后将原数组的元素存进 新数组。不同的是1.8使⽤位移操作创建2倍⼤⼩的新数组
newThr = oldThr << 1;
3.19:插⼊数据时扩容的重新hash是怎么做的?
1.7:需要再做⼀次hash
/*** Adds a new entry with the specified key, value and hash code to* the specified bucket. It is the responsibility of this* method to resize the table if appropriate.** Subclass overrides this to alter the behavior of put method.*/void addEntry(int hash, K key, V value, int bucketIndex) {if ((size >= threshold) && (null != table[bucketIndex])) {resize(2 * table.length);hash = (null != key) ? hash(key) : 0;bucketIndex = indexFor(hash, table.length);}createEntry(hash, key, value, bucketIndex);}
1.8:不需要做hash,通过原⽅式获取存储位置
newTab[e.hash & (newCap - 1)] = e; 由于newCap为新数组的⼤⼩,因此在做与操作时,在没有改变key的hash的情况下,改变了与数的 值来获取新的存储位置,效率更⾼。⽽且位预算的newCap-1 实际上由于2的幂的关系,-1的操作实 际上就是在⾼位补1,效率更⾼。
3.20:为什么重写equals⽅法后还要重写hashCode⽅法
因为在put的时候,如果数据已经存在,就需要把⽼的数据return,存⼊新的数据。那如何判断数据 已存在呢?是通过先⽐较hash值,如果hash值相同,再⽤equals判断。
Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;
重写equals和hashCode⽅法的⽬的就是根据对象的属性来进⾏判断对象是否相同,⽽⾮根据对象的 内存地址来判断
public class User {private int id;private String name;@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;User user = (User) o;return id == user.id && Objects.equals(name, user.name);}@Overridepublic int hashCode() {return Objects.hash(id, name);}}
3.21:HashMap在多线程使⽤场景下会存在线程安全问题,怎么处理?
处理⽅案有以下三种:
- 使⽤Collections.synchronizedMap()创建线程安全的map集合
- 使⽤Hashtable
- 使⽤ConcurrentHashMap
鉴于效率考虑,推荐使⽤ConcurrentHashMap。
3.22:Collections.synchronizedMap()如何实现线程安全
private static class SynchronizedMap<K,V>implements Map<K,V>, Serializable {private final Map<K,V> m; // Backing Mapfinal Object mutex; // Object on which to synchronizeSynchronizedMap(Map<K,V> m) {this.m = Objects.requireNonNull(m);mutex = this; //设置当前对象互斥量}
Collections.synchronizedMap(map)创建出的SynchronizedMap对象,把当前对象作为互斥量(也 可以指定互斥量)。
之后操作该SynchronizedMap,其操作Map的⽅法都被加上了synchronized。
public int size() {synchronized (mutex) {return m.size();}}public boolean isEmpty() {synchronized (mutex) {return m.isEmpty();}}public boolean containsKey(Object key) {synchronized (mutex) {return m.containsKey(key);}}public boolean containsValue(Object value) {synchronized (mutex) {return m.containsValue(value);}}public V get(Object key) {synchronized (mutex) {return m.get(key);}}public V put(K key, V value) {synchronized (mutex) {return m.put(key, value);}}public V remove(Object key) {synchronized (mutex) {return m.remove(key);}}public void putAll(Map<? extends K, ? extends V> map) {synchronized (mutex) {m.putAll(map);}}public void clear() {synchronized (mutex) {m.clear();}}
3.23:Hashtable的性能为什么不好?
Hashtable的每个操作都使⽤了synchronized上了锁,甚⾄读的操作也上锁。
public synchronized V get(Object key) {Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return (V)e.value;}}return null;}
3.24:Hashtable和HashMap有什么区别?
Hashtable的键值不能为null,但HashMap可以为null。
HashMap在存放null的键时做了处理
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
为什么要Hashtable设计成不能为null? 因为Hashtable如果可以存null,那么有可能导致判断数据是否已存在时,没办法判断是否是null还 是不存在。
public synchronized boolean containsKey(Object key) {Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {if ((e.hash == hash) && e.key.equals(key)) {return true;}}return false;}
除此之外,Hashtable的初始化容量是11,扩容时是当前容量*2+1。
int newCapacity = (oldCapacity << 1) + 1;
3.25:什么是fail-safe和fail-fast
fail-safe:安全失败。java.util.concurrent并发包下的容器都是遵循安全失败机制。即可以在多线 程下并发修改。不会抛出并发修改的异常Concurrent Modification Exception • Fail-fast: 快速失败。Java集合在使⽤迭代器遍历时,如果遍历过程中对集合中的内容进⾏了增删 改的操作时,则会抛出并发修改的异常Concurrent Modification Exception。即使不存在并发, 也会抛出该异常,所以称之为快速失败。
@Overridepublic void forEach(BiConsumer<? super K, ? super V> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (int i = 0; i < tab.length; ++i) {for (Node<K,V> e = tab[i]; e != null; e = e.next)action.accept(e.key, e.value);}if (modCount != mc)throw new ConcurrentModificationException();}}
3.26:ConcurrentHashMap的数据结构是怎么样?
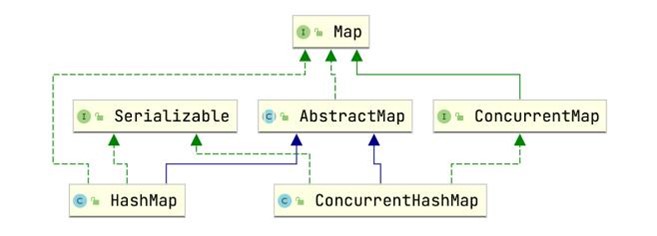
从类关系图上来看HashMap和ConcurrentHashMap都来⾃于Map,因此ConcurrentHashMap数据 结构遵循HashMap的1.7和1.8的特征。
• 1.7版本使⽤的是数组+链表结构
• 1.8版本使⽤的是数组+链表+红⿊树结构
但是ConcurrentHashMap在数组中存的元素不同。 • 1.7版本: 存⼊的数据⽤Segment类型来封装。
/*** Segments are specialized versions of hash tables. This* subclasses from ReentrantLock opportunistically, just to* simplify some locking and avoid separate construction.*/static final class Segment<K,V> extends ReentrantLock implements Serializable {...}
⼀个ConcurrentHashMap包含⼀个Segment数组,Segment⾥包含⼀个HashEntry数组,每个 HashEntry数组中是⼀个链表结构的元素,每个Segment守护着⼀个HashEntry数组⾥的元素,当对 HashEntry数组的数据进⾏修改时,必须⾸先获得与它对应的Segment锁。每个Segment元素相当于 ⼀个⼩的HashMap。 ⼀个ConcurrentHashMap中只有⼀个Segment 类型的segments数组,每个segment中只有⼀个HashEntry 类型的table数组,table数组中存放⼀个HashEntry节点。

HashEntry的内部结构:
static final class HashEntry<K,V> {final int hash;final K key;volatile V value; //加了volatile修饰,保存内存可⻅性及防⽌指令重排volatile HashEntry<K,V> next;HashEntry(int hash, K key, V value, HashEntry<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}
很显然,1.7版本的ConcurrentHashMap采⽤了分段锁(Segment)技术,其中Segment继承了 ReentrantLock。
在插⼊ConcurrentHashMap元素时,先尝试获得Segment锁,先是⾃旋获锁,如果⾃旋次数超过阈 值,则转为ReentrantLock上锁。
inal V put(K key, int hash, V value, boolean onlyIfAbsent) {HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value); /⾃旋获锁V oldValue;try {HashEntry<K,V>[] tab = table;int index = (tab.length - 1) & hash;/算出插⼊位置HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {if (e != null) {K k;if ((k = e.key) == key | |(e.hash == hash && key.equals(k))) {/判断插⼊的元素是否已存在oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}e = e.next;/不存在则遍历下⼀个}else {if (node != null)node.setNext(first);elsenode = new HashEntry<K,V>(hash, key, value, first);//创建节点int c = count + 1;if (c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);//扩容elsesetEntryAt(tab, index, node);//存⼊节点++modCount;count = c;oldValue = null;break;}}} finally {unlock();//释放锁}return oldValue;}
3.27:Segment如何实现扩容?
/*** Doubles size of table and repacks entries, also adding the* given node to new table*/@SuppressWarnings("unchecked")private void rehash(HashEntry<K,V> node) {HashEntry<K,V>[] oldTable = table;int oldCapacity = oldTable.length;int newCapacity = oldCapacity << 1;threshold = (int)(newCapacity * loadFactor);HashEntry<K,V>[] newTable =(HashEntry<K,V>[]) new HashEntry[newCapacity];int sizeMask = newCapacity - 1;for (int i = 0; i < oldCapacity ; i++) {HashEntry<K,V> e = oldTable[i];if (e != null) {HashEntry<K,V> next = e.next;int idx = e.hash & sizeMask;if (next == null) // Single node on listnewTable[idx] = e;else { // Reuse consecutive sequence at same slotHashEntry<K,V> lastRun = e;int lastIdx = idx;for (HashEntry<K,V> last = next;last != null;last = last.next) {int k = last.hash & sizeMask;if (k != lastIdx) {//如果找到不相同的hash索引位置,则继续找下⼀个,直到找到最后⼀个相同的索引位置。lastIdx = k;lastRun = last;}}//找到第⼀个后续节点新的index不变的节点。newTable[lastIdx] = lastRun;// Clone remaining nodes 第⼀个后续节点新index不变节点前所有节点均需要重新创建分配。——⽤以提升效率for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {V v = p.value;int h = p.hash;int k = h & sizeMask;HashEntry<K,V> n = newTable[k];newTable[k] = new HashEntry<K,V>(h, p.key, v, n);}}}}int nodeIndex = node.hash & sizeMask; // add the new nodenode.setNext(newTable[nodeIndex]);newTable[nodeIndex] = node;table = newTable;}
ConcurrentHashMap 的扩容是仅仅和每个Segment元素中HashEntry数组的⻓度有关,但需要扩容 时,只扩容当前Segment中HashEntry数组即可。也就是说ConcurrentHashMap中Segment[]数组 的⻓度是在初始化的时候就确定了,后⾯扩容不会改变这个⻓度
3.28:ConcurrentHashMap在JDK1.8版本的数据结构是什么样的?
1.8版本放弃了Segment,跟HashMap⼀样,⽤Node描述插⼊集合中的元素。但是Node中的val和 next使⽤了volatile来修饰,保存了内存可⻅性。与HashMap相同的是,ConcurrentHashMap1.8版 本使⽤了数组+链表+红⿊树的结构。
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;Node(int hash, K key, V val, Node<K,V> next) {this.hash = hash;this.key = key;this.val = val;this.next = next;}
同时,ConcurrentHashMap使⽤了CAS+Synchronized保证了并发的安全性。 下⾯介绍ConcurrentHashMap的put过程:
/** Implementation for put and putIfAbsent */final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());//更为分散的hash值int binCount = 0;//统计节点个数for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();//初始化数组else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//该位置没有元素,则⽤cas⾃旋获锁,存⼊节点if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bi}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);//如果ConcurrentHashMap正在扩容,则协助其转移else {V oldVal = null;synchronized (f) {//对根节点上锁if (tabAt(tab, i) == f) {if (fh >= 0) {//fh>=0 说明是链表,否则是红⿊树binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);//尾插法插⼊break;}}}else if (f instanceof TreeBin) {//红⿊树Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {//判断链表的值是否⼤于等于8,如果⼤于等于8就升级为红⿊树。if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
3.29: CAS是什么?
CAS是英⽂单词Compare and Swap的缩写,翻译过来就是⽐较并替换。CAS属于乐观锁⸺没有上 任何锁,所以线程不会阻塞,但依然会有上锁的效果。 CAS机制中使⽤了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。 更新⼀个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对 应的值修改为B。 举个例⼦: • 在内存地址V当中,存储着值为10的变量。

此时线程1想把变量的值增加1.对线程1来说,旧的预期值A=10,要修改的新值B=11。 • 在线程1要提交更新之前,另⼀个线程2抢先⼀步,把内存地址V中的变量值率先更新成了11。

线程1开始提交更新,⾸先进⾏A和地址V的实际值⽐较,发现A不等于V的实际值,提交失败。

线程1 重新获取内存地址V的当前值,并重新计算想要修改的值。此时对线程1来说,A=11, B=12。这个重新尝试的过程被称为⾃旋

这⼀次⽐较幸运,没有其他线程改变地址V的值。线程1进⾏⽐较,发现A和地址V的实际值是相等 的线程1进⾏交换,把地址V的值替换为B,也就是12。

CAS的缺点:
• CPU开销过⼤ 在并发量⽐较⾼的情况下,如果许多线程反复尝试更新某⼀个变量,却⼜⼀直更新不成功,循环往 复,会给CPU带来很到的压⼒。
• 不能保证代码块的原⼦性 CAS机制所保证的只是⼀个变量的原⼦性操作,⽽不能保证整个代码块的原⼦性。⽐如需要保证3个 变量共同进⾏原⼦性的更新,就不得不使⽤synchronized了。
• ABA问题 这是CAS机制最⼤的问题所在。
• 假设内存中有⼀个值为A的变量,存储在地址V中

此时有三个线程想使⽤CAS的⽅式更新这个变量的值,每个线程的执⾏时间有略微偏差。线程1和 线程2已经获取当前值,线程3还未获取当前值
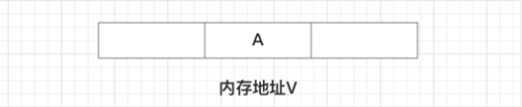

接下来,线程1先⼀步执⾏成功,把当前值成功从A更新为B;同时线程2因为某种原因被阻塞住, 没有做更新操作;线程3在线程1更新之后,获取了当前值B。
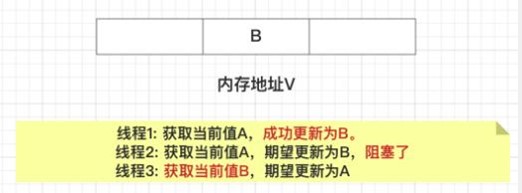
在之后,线程2仍然处于阻塞状态,线程3继续执⾏,成功把当前值从B更新成了A。
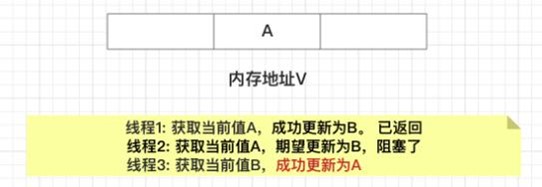
最后,线程2终于恢复了运⾏状态,由于阻塞之前已经获得了“当前值A”,并且经过compare检 测,内存地址V中的实际值也是A,所以成功把变量值A更新成了B


看起来这个例⼦没啥问题,但如果结合实际,就可以发现它的问题所在。 我们假设⼀个提款机的例⼦。假设有⼀个遵循CAS原理的提款机,⼩灰有100元存款,要⽤这个提 款机来提款50元。

由于提款机硬件出了点问题,⼩灰的提款操作被同时提交了两次,开启了两个线程,两个线程都 是获取当前值100元,要更新成50元。理想情况下,应该⼀个线程更新成功,⼀个线程更新失败, ⼩灰的存款值被扣⼀次。


线程1⾸先执⾏成功,把余额从100改成50。线程2因为某种原因阻塞。这时,⼩灰的妈妈刚好给⼩ 灰汇款50元。

线程2仍然是阻塞状态,线程3执⾏成功,把余额从50改成了100。

线程2恢复运⾏,由于阻塞之前获得了“当前值”100,并且经过compare检测,此时存款实际值 也是100,所以会成功把变量值100更新成50。

原本线程2应当提交失败,⼩灰的正确余额应该保持100元,结果由于ABA问题提交成功了。 怎么解决呢?加个版本号就可以了。 真正要做到严谨的CAS机制,在compare阶段不仅要⽐较期望值A和地址V中的实际值,还要⽐较变量 的版本号是否⼀致。假设地址V中存储着变量值A,当前版本号是01。线程1获取了当前值A和版本号 01,想要更新为B,但是被阻塞了

这时候,内存地址V中变量发⽣了多次改变,版本号提升为03,但是变量值仍然是A

随后线程1恢复运⾏,进⾏compare操作。经过⽐较,线程1所获得的值和地址的实际值都是A,但是 版本号不相等,所以这⼀次更新失败。

在数据库层⾯操作版本号:判断原来的值和版本号是否匹配,中间有别的线程修改,值可能相等,但 是版本号100%不⼀样
update a set value = newValue, vision = vision + 1 where value = #{oldValue} and vision = #{vision}
3.30:ConcurrentHashMap效率为什么⾼
因为ConcurrentHashMap的get⽅法并没有上锁。get时通过hash(key)定位到Segment上,再通过⼀ 次Hash定位到具体的HashEntry上。HashEntry的get⽅法如下:
public V get(Object key) {// key由equals()确定唯⼀性Segment<K, V> s; //HashEntry<K, V>[] tab;int h = hash(key);//h是key的hashcode⼆次散列值。 根据key的hashcode再做散列函数运算long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;//散列算法定位segement,u就是Segement数组的索引,Segment的散列运算,为了将不同key分散在不同segement.根据h获取segement的indexif ((s = (Segment<K, V>) UNSAFE.getObjectVolatile(segments, u)) != null&& (tab = s.table) != null) {// 如果u对应的segement存在,且segement中的table也存在,则获取table中的valuefor (HashEntry<K, V> e = (HashEntry<K, V>) UNSAFE.getObjectVolatile(tab,((long) (((tab.length - 1) & h)) << TSHIFT) + TBASE); e !=null; e = e.next) {K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))// 查询到对象相同或者equals相等的key则返回对应的valuereturn e.value;}}return null;}
由于HashEntry的value属性使⽤了volatile修饰,保证了内存可⻅性,每次获取都是最新值。因此整 个过程不需要加锁
第四章:并发编程
4.1、wait() 和 sleep() ⽅法的区别
来源不同:sleep() 来⾃ Thread 类,wait() 来⾃ Object 类。 对于同步锁的影响不同:sleep() 不会该表同步锁的⾏为,如果当前线程持有同步锁,那么 sleep 是不 会让线程释放同步锁的。wait() 会释放同步锁,让其他线程进⼊ synchronized 代码块执⾏。 使⽤范围不同:sleep() 可以在任何地⽅使⽤。wait() 只能在同步控制⽅法或者同步控制块⾥⾯使⽤, 否则会抛 IllegalMonitorStateException。 恢复⽅式不同:两者会暂停当前线程,但是在恢复上不太⼀样。sleep() 在时间到了之后会重新恢 复;wait() 则需要其他线程调⽤同⼀对象的 notify()/nofityAll() 才能重新恢复。
4.2、线程的 sleep() ⽅法和 yield() ⽅法有什么区别?
线程执⾏ sleep() ⽅法后进⼊超时等待(TIMED_WAITING)状态,⽽执⾏ yield() ⽅法后进⼊就绪 (READY)状态。 sleep() ⽅法给其他线程运⾏机会时不考虑线程的优先级,因此会给低优先级的线程运⾏的机会; yield() ⽅法只会给相同优先级或更⾼优先级的线程以运⾏的机会。
4.3、线程的 join() ⽅法是⼲啥⽤的?
⽤于等待当前线程终⽌。如果⼀个线程A执⾏了 threadB.join() 语句,其含义是:当前线程A等待 threadB 线程终⽌之后才从 threadB.join() 返回继续往下执⾏⾃⼰的代码
4.4、编写多线程程序有⼏种实现⽅式?
通常来说,可以认为有三种⽅式:1)继承 Thread 类;2)实现 Runnable 接⼝;3)实现 Callable 接⼝。其中,Thread 其实也是实现了 Runable 接⼝。Runnable 和 Callable 的主要区别在于是否有 返回值
4.5、Thread 调⽤ start() ⽅法和调⽤ run() ⽅法的区别?
run():普通的⽅法调⽤,在主线程中执⾏,不会新建⼀个线程来执⾏。 start():新启动⼀个线程,这时此线程处于就绪(可运⾏)状态,并没有运⾏,⼀旦得到 CPU 时间 ⽚,就开始执⾏ run() ⽅法。
4.6、线程的状态流转

⼀个线程可以处于以下状态之⼀: NEW:新建但是尚未启动的线程处于此状态,没有调⽤ start() ⽅法。 RUNNABLE:包含就绪(READY)和运⾏中(RUNNING)两种状态。线程调⽤ start() ⽅法会会进⼊ 就绪(READY)状态,等待获取 CPU 时间⽚。如果成功获取到 CPU 时间⽚,则会进⼊运⾏中 (RUNNING)状态。 BLOCKED:线程在进⼊同步⽅法/同步块(synchronized)时被阻塞,等待同步锁的线程处于此状 态。 WAITING:⽆限期等待另⼀个线程执⾏特定操作的线程处于此状态,需要被显⽰的唤醒,否则会⼀直 等待下去。例如对于 Object.wait(),需要等待另⼀个线程执⾏ Object.notify() 或 Object.notifyAll();对于 Thread.join(),则需要等待指定的线程终⽌。 TIMED_WAITING:在指定的时间内等待另⼀个线程执⾏某项操作的线程处于此状态。跟 WAITING 类似,区别在于该状态有超时时间参数,在超时时间到了后会⾃动唤醒,避免了⽆期限的等待。 TERMINATED:执⾏完毕已经退出的线程处于此状态。 线程在给定的时间点只能处于⼀种状态。这些状态是虚拟机状态,不反映任何操作系统线程状态。
4.7、synchronized 和 Lock 的区别
1)Lock 是⼀个接⼝;synchronized 是 Java 中的关键字,synchronized 是内置的语⾔实现;
2)Lock 在发⽣异常时,如果没有主动通过 unLock() 去释放锁,很可能会造成死锁现象,因此使⽤ Lock 时需要在 finally 块中释放锁;synchronized 不需要⼿动获取锁和释放锁,在发⽣异常时,会⾃动释放锁,因此不会导致死锁现象发⽣;
3)Lock 的使⽤更加灵活,可以有响应中断、有超时时间等;⽽ synchronized 却不⾏,使⽤ synchronized 时,等待的线程会⼀直等待下去,直到获取到锁;
4)在性能上,随着近些年 synchronized 的不断优化,Lock 和 synchronized 在性能上已经没有很 明显的差距了,所以性能不应该成为我们选择两者的主要原因。官⽅推荐尽量使⽤ synchronized, 除⾮ synchronized ⽆法满⾜需求时,则可以使⽤ Lock
4.8、为什么说 synchronized 是⼀种悲观锁?乐观锁的实现原理⼜是什 么?什么是CAS,它有什么特性
synchronized 显然是⼀个悲观锁,因为它的并发策略是悲观的: 不管是否会产⽣竞争,任何的数据操作都必须加锁,⽤⼾态核⼼态转换,维护锁计数器和检查是否有 被阻塞的线程需要被唤醒等操作。随着硬件指令集的发展,我们可以使⽤基于冲突检测的乐观并发策 略。先进⾏操作,如果没有其他线程征⽤数据,那么就操作成功了; 如果共享数据有征⽤,产⽣了冲突,就再进⾏其他的补偿措施。这种乐观的并发策略的许多实现不需 要线程池挂起,所以被称为⾮阻塞同步。 乐观锁的核⼼算法是 CAS(Compareand Swap,⽐较并交换),它涉及到三个操作数:内存值、 预期值、新值。并且仅当预期值和内存值相同时才将内存值修改为新值。 这样处理的逻辑是,⾸先检查某块内存的值是否跟之前读取的⼀样,如果不⼀样则表⽰此内存值已经 被别的线程更改,舍弃本次操作,否则说明期间没有其他线程对此内存值操作,可以把新值设置给此 块内存。 CAS 具有原⼦性,它的原⼦性由 CPU 硬件指令实现保证,即使⽤ JNI 调⽤ Native ⽅法调⽤由 C++ 编 写的硬件级指令,JDK中提供了 Unsafe 类执⾏这些操作。 任何技术都要找到适合的场景,都不是万能的,CAS 机制也⼀样,也有副作⽤。 问题1: 作为乐观锁的⼀种实现,当多线程竞争资源激烈的情况下,⽽且锁定的资源处理耗时,那么其他线程 就要考虑⾃旋的次数限制,避免过度的消耗 CPU。 另外,可以使⽤ LongAdder 来解决,LongAdder 以空间换时间的⽅式,来解决 CAS ⼤量失败后⻓时 间占⽤ CPU 资源,加⼤了系统性能开销的问题。 问题2: A—>B—->A 问题,假设有⼀个变量 A ,修改为B,然后⼜修改为了 A,实际已经修改过了,但 CAS 可 能⽆法感知,造成了不合理的值修改操作。 整数类型还好,如果是对象引⽤类型,包含了多个变量,那怎么办?即加个版本号或时间戳 JDK 中 java.util.concurrent.atomic 并发包下,提供了 AtomicStampedReference,通过为引⽤建 ⽴个 Stamp 类似版本号的⽅式,确保 CAS 操作的正确性.
4.9、synchronized 各种加锁场景的作⽤范围
1)作⽤于⾮静态⽅法,锁住的是对象实例(this),每⼀个对象实例有⼀个锁。
public synchronized void method() {}
2)作⽤于静态⽅法,锁住的是类的Class对象,因为Class的相关数据存储在永久代元空间,元空间 是全局共享的,因此静态⽅法锁相当于类的⼀个全局锁,会锁所有调⽤该⽅法的线程。
public static synchronized void method() {}
3)作⽤于 Lock.class,锁住的是 Lock 的Class对象,也是全局只有⼀个。
synchronized (Lock.class) {}
4)作⽤于 this,锁住的是对象实例,每⼀个对象实例有⼀个锁。
synchronized (this) {}
5)作⽤于静态成员变量,锁住的是该静态成员变量对象,由于是静态变量,因此全局只有⼀个。
ublic static Object monitor = new Object();synchronized (monitor) {}
4.10、如何检测死锁?
死锁的四个必要条件:
1)互斥条件:进程对所分配到的资源进⾏排他性控制,即在⼀段时间内某资源仅为⼀个进程所占 有。此时若有其他进程请求该资源,则请求进程只能等待。
2)请求和保持条件:进程已经获得了⾄少⼀个资源,但⼜对其他资源发出请求,⽽该资源已被其他 进程占有,此时该进程的请求被阻塞,但⼜对⾃⼰获得的资源保持不放
3)不可剥夺条件:进程已获得的资源在未使⽤完毕之前,不可被其他进程强⾏剥夺,只能由⾃⼰释 放。
4)环路等待条件:存在⼀种进程资源的循环等待链,链中每⼀个进程已获得的资源同时被 链中下⼀ 个进程所请 求。即存在⼀个处于等待状态的进程集合{Pl, P2, …, pn},其中 Pi 等待的资源被 P(i+1) 占有(i=0, 1, …, n-1),Pn 等待的资源被 P0占 有,如下图所⽰
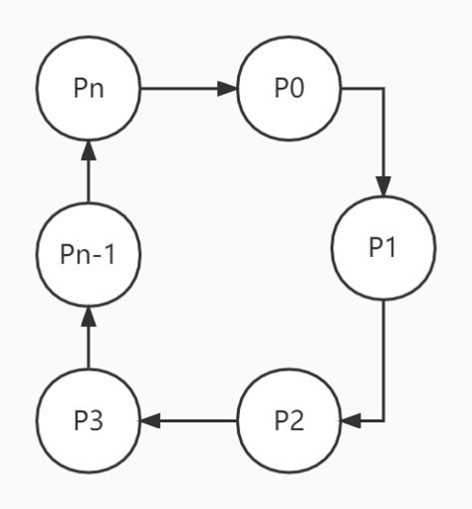
4.11、怎么预防死锁?
预防死锁的⽅式就是打破四个必要条件中的任意⼀个即可。
1)打破互斥条件:在系统⾥取消互斥。若资源不被⼀个进程独占使⽤,那么死锁是肯定不会发⽣ 的。但⼀般来说在所列的四个条件中,“互斥”条件是⽆法破坏的。因此,在死锁预防⾥主要是破坏 其他⼏个必要条件,⽽不去涉及破坏“互斥”条件。。
2)打破请求和保持条件:1)采⽤资源预先分配策略,即进程运⾏前申请全部资源,满⾜则运⾏,不 然就等待。 2)每个进程提出新的资源申请前,必须先释放它先前所占有的资源。
3)打破不可剥夺条件:当进程占有某些资源后⼜进⼀步申请其他资源⽽⽆法满⾜,则该进程必须释 放它原来占有的资源
4)打破环路等待条件:实现资源有序分配策略,将系统的所有资源统⼀编号,所有进程只能采⽤按 序号递增的形式申请资源
4.12、为什么要使⽤线程池?直接new个线程不是很舒服?
如果我们在⽅法中直接new⼀个线程来处理,当这个⽅法被调⽤频繁时就会创建很多线程,不仅会消 耗系统资源,还会降低系统的稳定性,⼀不⼩⼼把系统搞崩了,就可以直接去财务那结帐了。 如果我们合理的使⽤线程池,则可以避免把系统搞崩的窘境。总得来说,使⽤线程池可以带来以下⼏ 个好处:
• 降低资源消耗。通过重复利⽤已创建的线程,降低线程创建和销毁造成的消耗。
• 提⾼响应速度。当任务到达时,任务可以不需要等到线程创建就能⽴即执⾏。
• 增加线程的可管理型。线程是稀缺资源,使⽤线程池可以进⾏统⼀分配,调优和监控
4.13、线程池的核⼼属性有哪些?
threadFactory(线程⼯⼚):⽤于创建⼯作线程的⼯⼚。
corePoolSize(核⼼线程数):当线程池运⾏的线程少于 corePoolSize 时,将创建⼀个新线程来处 理请求,即使其他⼯作线程处于空闲状态。
workQueue(队列):⽤于保留任务并移交给⼯作线程的阻塞队列
maximumPoolSize(最⼤线程数):线程池允许开启的最⼤线程数。
handler(拒绝策略):往线程池添加任务时,将在下⾯两种情况触发拒绝策略:1)线程池运⾏状态 不是 RUNNING;2)线程池已经达到最⼤线程数,并且阻塞队列已满时。
keepAliveTime(保持存活时间):如果线程池当前线程数超过 corePoolSize,则多余的线程空闲时 间超过 keepAliveTime 时会被终⽌。
4.14、说下线程池的运作流程
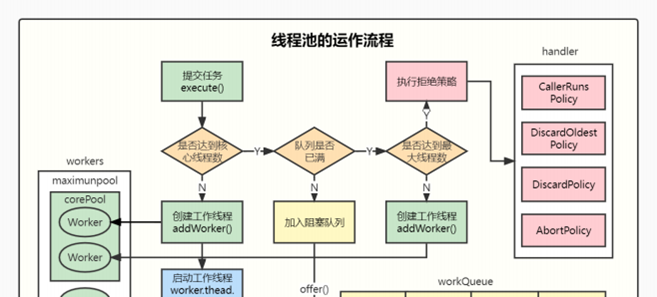
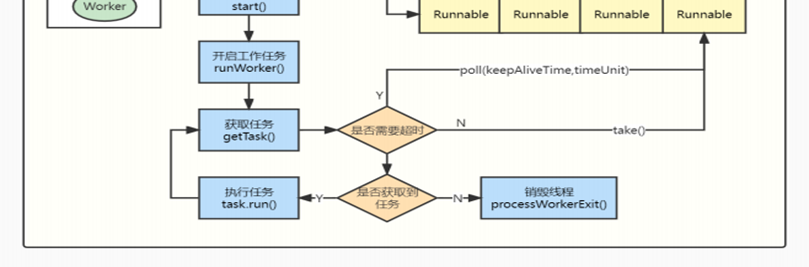
4.15、线程池有⼏种状态,每个状态分别代表什么含义?
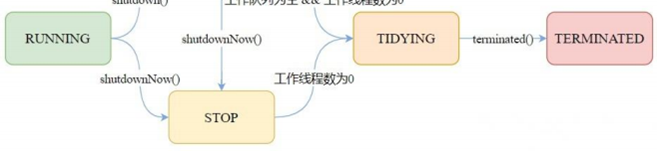
线程池⽬前有5个状态:
• RUNNING:接受新任务并处理排队的任务
• SHUTDOWN:不接受新任务,但处理排队的任务。
• STOP:不接受新任务,不处理排队的任务,并中断正在进⾏的任务。
. TIDYING:所有任务都已终⽌,workerCount 为零,线程转换到 TIDYING 状态将运⾏ terminated() 钩⼦⽅法。
• TERMINATED:terminated() 已完成
4.16、线程池中的状态之间是怎么流转的

4.17、线程池有哪些队列?
常⻅的阻塞队列有以下⼏种: ArrayBlockingQueue:基于数组结构的有界阻塞队列,按先进先出对元素进⾏排序。
LinkedBlockingQueue:基于链表结构的有界/⽆界阻塞队列,按先进先出对元素进⾏排序,吞吐量 通常⾼于 ArrayBlockingQueue。Executors.newFixedThreadPool 使⽤了该队列。
SynchronousQueue:不是⼀个真正的队列,⽽是⼀种在线程之间移交的机制。要将⼀个元素放⼊ SynchronousQueue 中,必须有另⼀个线程正在等待接受这个元素。如果没有线程等待,并且线程 池的当前⼤⼩⼩于最⼤值,那么线程池将创建⼀个线程,否则根据拒绝策略,这个任务将被拒绝。使 ⽤直接移交将更⾼效,因为任务会直接移交给执⾏它的线程,⽽不是被放在队列中,然后由⼯作线程 从队列中提取任务。只有当线程池是⽆界的或者可以拒绝任务时,该队列才有实际价值。 Executors.newCachedThreadPool使⽤了该队列。
PriorityBlockingQueue:具有优先级的⽆界队列,按优先级对元素进⾏排序。元素的优先级是通过 ⾃然顺序或 Comparator 来定义的。
4.18、使⽤队列有什么需要注意的吗?
使⽤有界队列时,需要注意线程池满了后,被拒绝的任务如何处理。
使⽤⽆界队列时,需要注意如果任务的提交速度⼤于线程池的处理速度,可能会导致内存溢出。
4.19、线程池有哪些拒绝策略?
AbortPolicy:中⽌策略。默认的拒绝策略,直接抛出 RejectedExecutionException。调⽤者可以捕 获这个异常,然后根据需求编写⾃⼰的处理代码。
DiscardPolicy:抛弃策略。什么都不做,直接抛弃被拒绝的任务。 DiscardOldestPolicy:抛弃最⽼策略。抛弃阻塞队列中最⽼的任务,相当于就是队列中下⼀个将要 被执⾏的任务,然后重新提交被拒绝的任务。如果阻塞队列是⼀个优先队列,那么“抛弃最旧的”策 略将导致抛弃优先级最⾼的任务,因此最好不要将该策略和优先级队列放在⼀起使⽤CallerRunsPolicy:调⽤者运⾏策略。在调⽤者线程中执⾏该任务。该策略实现了⼀种调节机制,该 策略既不会抛弃任务,也不会抛出异常,⽽是将任务回退到调⽤者(调⽤线程池执⾏任务的主线 程),由于执⾏任务需要⼀定时间,因此主线程⾄少在⼀段时间内不能提交任务,从⽽使得线程池有 时间来处理完正在执⾏的任务
4.20、线程只能在任务到达时才启动吗
默认情况下,即使是核⼼线程也只能在新任务到达时才创建和启动。但是我们可以使⽤ prestartCoreThread(启动⼀个核⼼线程)或 prestartAllCoreThreads(启动全部核⼼线程)⽅法来 提前启动核⼼线程
4.21、核⼼线程怎么实现⼀直存活?
阻塞队列⽅法有四种形式,它们以不同的⽅式处理操作,如下表
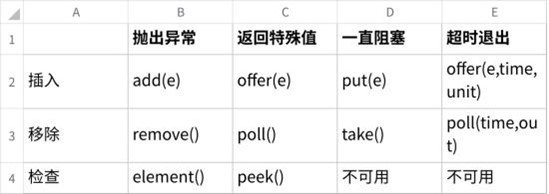
4.22、⾮核⼼线程如何实现在 keepAliveTime 后死亡?
原理同上,也是利⽤阻塞队列的⽅法,在获取任务时通过阻塞队列的 poll(time,unit) ⽅法实现的在延 迟死亡
4.23、⾮核⼼线程能成为核⼼线程吗?
虽然我们⼀直讲着核⼼线程和⾮核⼼线程,但是其实线程池内部是不区分核⼼线程和⾮核⼼线程的。 只是根据当前线程池的⼯作线程数来进⾏调整,因此看起来像是有核⼼线程于⾮核⼼线程。
4.24、如何终⽌线程池?
终⽌线程池主要有两种⽅式:
shutdown:“温柔”的关闭线程池。不接受新任务,但是在关闭前会将之前提交的任务处理完毕。
shutdownNow:“粗暴”的关闭线程池,也就是直接关闭线程池,通过 Thread#interrupt() ⽅法终 ⽌所有线程,不会等待之前提交的任务执⾏完毕。但是会返回队列中未处理的任务。
4.25、Executors 提供了哪些创建线程池的⽅法?
newFixedThreadPool:固定线程数的线程池。corePoolSize = maximumPoolSize, keepAliveTime为0,⼯作队列使⽤⽆界的LinkedBlockingQueue。适⽤于为了满⾜资源管理的需 求,⽽需要限制当前线程数量的场景,适⽤于负载⽐较重的服务器。 newSingleThreadExecutor:只有⼀个线程的线程池。corePoolSize = maximumPoolSize = 1, keepAliveTime为0, ⼯作队列使⽤⽆界的LinkedBlockingQueue。适⽤于需要保证顺序的执⾏各个 任务的场景。 newCachedThreadPool: 按需要创建新线程的线程池。核⼼线程数为0,最⼤线程数为 Integer.MAX_VALUE,keepAliveTime为60秒,⼯作队列使⽤同步移交 SynchronousQueue。该线 程池可以⽆限扩展,当需求增加时,可以添加新的线程,⽽当需求降低时会⾃动回收空闲线程。适⽤ 于执⾏很多的短期异步任务,或者是负载较轻的服务器。 newScheduledThreadPool:创建⼀个以延迟或定时的⽅式来执⾏任务的线程池,⼯作队列为 DelayedWorkQueue。适⽤于需要多个后台线程执⾏周期任务。 newWorkStealingPool:JDK 1.8 新增,⽤于创建⼀个可以窃取的线程池,底层使⽤ ForkJoinPool 实现
4.26、线程池⾥有个 ctl,你知道它是如何设计的吗?
ctl 是⼀个打包两个概念字段的原⼦整数。
1)workerCount:指⽰线程的有效数量;
2)runState:指⽰线程池的运⾏状态,有 RUNNING、SHUTDOWN、STOP、TIDYING、 TERMINATED 等状态。
int 类型有32位,其中 ctl 的低29为⽤于表⽰ workerCount,⾼3位⽤于表⽰ runState,如下图所 ⽰

例如,当我们的线程池运⾏状态为 RUNNING,⼯作线程个数为3,则此时 ctl 的原码为:1010 0000 0000 0000 0000 0000 0000 0011
4.27、ctl 为什么这么设计?有什么好处吗?
ctl 这么设计的主要好处是将对 runState 和 workerCount 的操作封装成了⼀个原⼦操作。runState 和 workerCount 是线程池正常运转中的2个最重要属性,线程池在某⼀时刻该做什么操 作,取决于这2个属性的值。 因此⽆论是查询还是修改,我们必须保证对这2个属性的操作是属于“同⼀时刻”的,也就是原⼦操 作,否则就会出现错乱的情况。如果我们使⽤2个变量来分别存储,要保证原⼦性则需要额外进⾏加 锁操作,这显然会带来额外的开销,⽽将这2个变量封装成1个 AtomicInteger 则不会带来额外的加锁 开销,⽽且只需使⽤简单的位操作就能分别得到 runState 和 workerCount。 由于这个设计,workerCount 的上限 CAPACITY = (1 << 29) - 1,对应的⼆进制原码为:0001 1111 1111 1111 1111 1111 1111 1111(不⽤数了,29个1)。 通过 ctl 得到 runState,只需通过位操作:ctl & ~CAPACITY。 (按位取反),于是“CAPACITY”的值为:1110 0000 0000 0000 0000 0000 0000 0000,只有⾼ 3位为1,与 ctl 进⾏ & 操作,结果为 ctl ⾼3位的值,也就是 runState。 通过 ctl 得到 workerCount 则更简单了,只需通过位操作:c & CAPACITY。
4.28、在我们实际使⽤中,线程池的⼤⼩配置多少合适?
要想合理的配置线程池⼤⼩,⾸先我们需要区分任务是计算密集型还是I/O密集型。 对于计算密集型,设置 线程数 = CPU数 + 1,通常能实现最优的利⽤率。 对于I/O密集型,⽹上常⻅的说法是设置 线程数 = CPU数 2 ,这个做法是可以的,但其实并不是最 优的。 在我们⽇常的开发中,我们的任务⼏乎是离不开I/O的,常⻅的⽹络I/O(RPC调⽤)、磁盘I/O(数据 库操作),并且I/O的等待时间通常会占整个任务处理时间的很⼤⼀部分,在这种情况下,开启更多 的线程可以让 CPU 得到更充分的使⽤,⼀个较合理的计算公式如下: 线程数 = CPU数 CPU利⽤率 (任务等待时间 / 任务计算时间 + 1) 例如我们有个定时任务,部署在4核的服务器上,该任务有100ms在计算,900ms在I/O等待,则线程 数约为:4 1 * (1 + 900 / 100) = 40个。 当然,具体我们还要结合实际的使⽤场景来考虑
4.29、神奇的现象
olatile是⾯试⾥⾯⼏乎必问的⼀个话题,很多朋友仅限于会⽤阶段,今天我们换个⻆度去了解 Volatile。 先来看⼀个例⼦:
package com.qf.test;public class Demo1 {public static void main(String[] args) {MyThread myThread = new MyThread();myThread.start();while(true){if(myThread.isFlag()){System.out.println("here…..");}}}}class MyThread extends Thread {private boolean flag = false;public boolean isFlag() {return flag;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}flag = true;System.out.println("flag=" + flag);}
虽然两个线程同时运⾏,第⼀个线程⼀直在循环,第⼆个线程把标记flag改成了true,但是你会发 现,控制台永远打印不了“here….”。 这是为什么呢?⾸先我们先来了解下JMM
4.30、计算机的内存模型
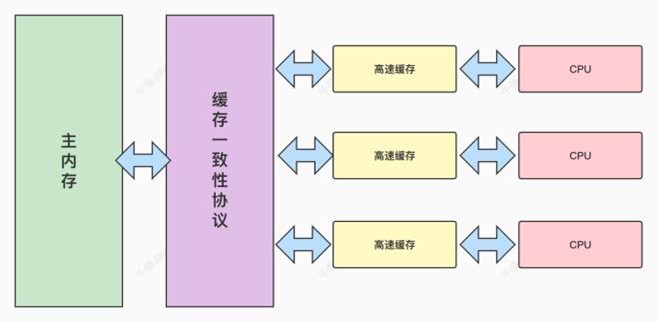
从图上可以看到,CPU和内存之间加⼊了⼀个⾼速缓存的⻆⾊。我们来分析下原因。在⽬前的计算机 中,CPU的计算速度远远⼤于计算机存储数据的速度。为了提升整体性能,在CPU和内存之间加⼊了 ⾼速缓存。 CPU将计算需要⽤到的数据暂存进缓存中。当计算结束后再将缓存中的数据存⼊到内存中。这样CPU 的运算可以在缓存中⾼速进⾏。 但是这种情况在多核CPU中会存在⼀个问题,多个CPU使⽤各⾃的⾼速缓存,但多个⾼速缓存在共享 同⼀个内存,此时就有可能⼀个CPU更新了数据,但另⼀个CPU还在操作⽼数据。导致脏数据的读写 问题,此时就需要缓存⼀致性协议来解决这个数据⼀致性的问题
4.31、Java内存模型JMM
Java Memory Model,Java内存模型是Java虚拟机规范中定义的⼀种内存模型规范,也就是说 JMM只是⼀种规范,即标准化。不同的虚拟机⼚商依据这套规范,来做底层具体的实现
计算机的内存模型帮我们简单梳理了下思路,接下来我们回到JMM。JMM做了⼀些约定和规范。

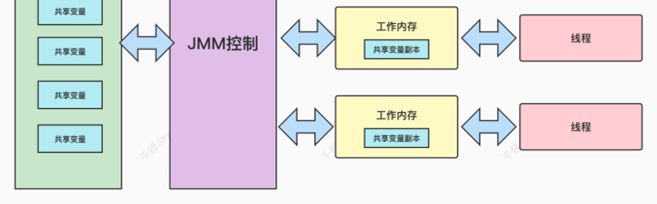
⼀段代码中的多线程,操作的共享变量,即成员变量或类变量。线程在操作共享变量时,先从主内存 中将变量拷⻉到⼯作内存中,然后线程在⾃⼰的⼯作内存中操作。线程不能访问别⼈⼯作内存中的内 容。线程间对变量值的传递是通过主内存进⾏中转。这个操作就会导致可⻅性问题,即⼀个线程更新 了共享变量,但另⼀个已经加载了数据到⾃⼰⼯作内存的线程,是没办法看到最新的变量的值。这也 是⽂章开始的那个demo出现的问题。
4.32、可⻅性解决⽅案-加锁
public class Demo2 {public static void main(String[] args) {MyThread myThread = new MyThread();myThread.start();while(true){synchronized (myThread) {if(myThread.isFlag()){System.out.println("here.....");}}}}}
为什么给代码加锁就能解决可⻅性问题呢?
4.33、JMM数据同步
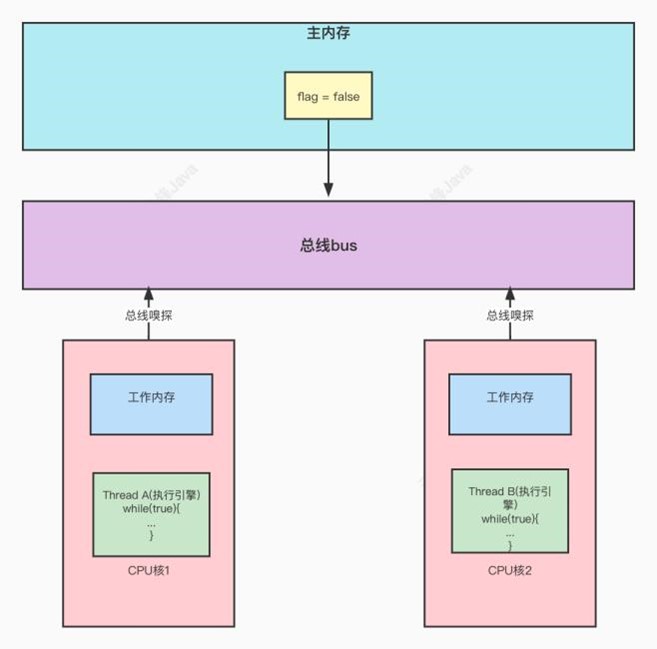
lock(锁定):作⽤于主内存的变量,把⼀个变量标记为⼀条线程独占状态 (触发总线锁)
unlock(解锁):作⽤于主内存的变量,把⼀个处于锁定状态的变量释放出来,释放后的变量才可以 被其他线程锁定
• read(读取):作⽤于主内存的变量,把⼀个变量值从主内存传输到线程的⼯作内存中,以便随后的 load动作使⽤ •
load(载⼊):作⽤于⼯作内存的变量,它把read操作从主内存中得到的变量值放⼊⼯作内存的变量 副本中 •
• use(使⽤):作⽤于⼯作内存的变量,把⼯作内存中的⼀个变量值传递给执⾏引擎
assign(赋值):作⽤于⼯作内存的变量,它把⼀个从执⾏引擎接收到的值赋给⼯作内存的变量
store(存储):作⽤于⼯作内存的变量,把⼯作内存中的⼀个变量的值传送到主内存中,以便随后 的write的操作 •
write(写⼊):作⽤于⼯作内存的变量,它把store操作从⼯作内存中的⼀个变量的值传送到主内存 的变量中
程序会按照上⾯的流程,在使⽤synchronized的代码前后,线程会获得锁,清空⼯作内存。read将 数据读到⼯作内存并load成为最新的副本,再通过store和write将数据写会主内存。⽽获取不到锁的 线程会阻塞等待,所以变量的值⼀直都是最新的
4.34、使⽤Volatile保证可⻅性
除了Synchronized外,Volatile也能保证可⻅性。
package com.qf.test;/**@author Thor@公众号 Java架构栈*/public class VisibilityVolatileDemo3 {public static void main(String[] args) {MyVolatileThread myThread = new MyVolatileThread();myThread.start();while (true) {if (myThread.isFlag()) {System.out.println("here…..");}}}}class MyVolatileThread extends Thread {private volatile boolean flag = false;public boolean isFlag() {return flag;}@Overridepublic void run() {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}flag = true;System.out.println("flag=" + flag);}}
使⽤了volatile后,操作数据的线程先从主内存中把数据读到⾃⼰的⼯作内存中。如果有线程对 volatile修饰的变量进⾏操作并且写回了主内存,则其他已读取该变量的线程中,该变量副本将会失 效。其他线程需要从主内存中重新加载⼀份最新的变量值。 Volatile保证了共享变量的可⻅性。当有的线程修改了Volatile修饰的变量值并写回到主内存后,其他 线程能⽴即看到最新的值。 但是Volatile不能保证原⼦性。
4.35、Volatile不能保证原⼦性
先看下⾯这个例⼦。
package com.qf.atomicity;import java.util.concurrent.CountDownLatch;/*** @author Thor* @公众号 Java架构栈*/public class AtomicityDemo1 {private static volatile int count = 0;public static void main(String[] args) {CountDownLatch countDownLatch = new CountDownLatch(1);for (int i = 0; i < 10; i++) {Thread thread = new Thread(() -> {try {countDownLatch.await();for (int i1 = 0; i1 < 1000; i1++) {count++;}} catch (InterruptedException e) {e.printStackTrace();}});thread.start();}try {Thread.sleep(500);countDownLatch.countDown();Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(count);}}
在这个例⼦中,并不会每次count的结果是10000,有的时候不⾜10000。于是,做如下调整
private static volatile int count = 0;
当给变量count前加上了volatile修饰后,发现结果依然有可能不⾜10000。为什么会这样,我们先来 看下count++的执⾏过程。
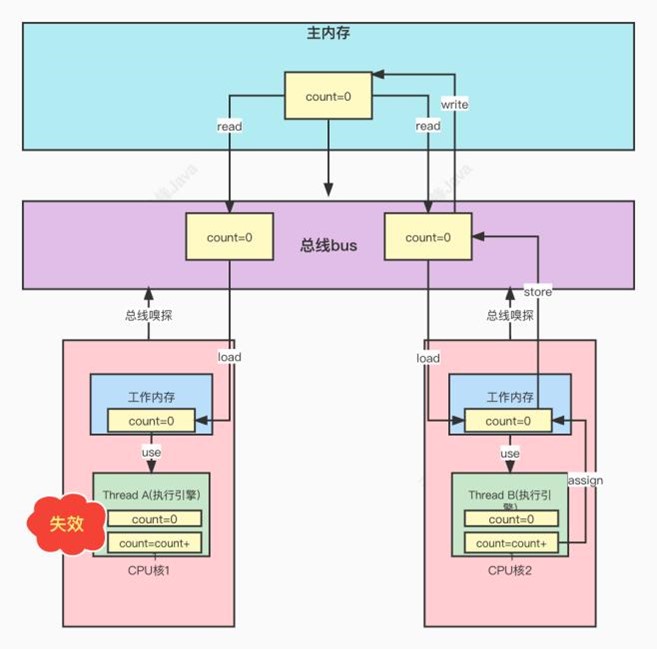
count++在执⾏引擎中被分成了两步操作:
• count = 0,先将count值初始化为0
• count=count+1,再执⾏+1操作
这两步操作在左边的线程执⾏完第⼀步,但还没执⾏第⼆步时右边的线程抢过CPU控制权开始完成+1 的操作后写⼊到主内存,于是左边的线程⼯作内存中的count副本失效了,相当于左边这⼀次+1的操 作就被覆盖掉了。
因此,Volatile不能保证原⼦性。
该如何保证原⼦性呢?⸺加锁
package com.qf.atomicity;import java.util.concurrent.CountDownLatch;/*** @author Thor* @公众号 Java架构栈*/public class AtomicityDemo1 {private static volatile int count = 0;static Object object = new Object();public static void main(String[] args) {CountDownLatch countDownLatch = new CountDownLatch(1);for (int i = 0; i < 10; i++) {Thread thread = new Thread(() -> {try {countDownLatch.await();for (int i1 = 0; i1 < 1000; i1++) {synchronized (object) {count++;}}} catch (InterruptedException e) {e.printStackTrace();}});thread.start();}try {Thread.sleep(500);countDownLatch.countDown();Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(count);
4.36、Volatile保证有序性-指令重排
我们先来看这个例⼦来了解什么是指令重排。
package com.qf.reorder;/*** @author Thor* @公众号 Java架构栈*/public class ReorderDemo {private static int x = 0, y = 0;private static int a = 0, b = 0;public static void main(String[] args) throws InterruptedException {int i=0;for(;;){i++;x=0;y=0;a=0;b=0;Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {shortWait(10000);a = 1;x = b;}});Thread t2 = new Thread(new Runnable() {@Overridepublic void run() {b = 1;y = a;});t1.start();t2.start();t1.join();t2.join();String result = "第" + i + "次 :" + x + "," + y ;System.out.println(result);if(x == 0 && y == 0) {break;}}}public static void shortWait(long interval) {long start = System.nanoTime();long end;do {end = System.nanoTime();} while (start + interval >= end);}}
在这个例⼦中,x和y的值只会有三种情况: • x=1 y=1 • x=0 y=1 • x=1 y=0 如果发⽣指令重排,才会出现第四种: • x=0 y=0


为了提⾼性能,编译器和处理器常常会对既定代码的执⾏顺序进⾏指令重排序。

as-if-serial语义
不管怎么重排序,单线程程序的执⾏结果不能被改变。编译器、runtime和处理器都必须遵守“as-ifserial语义”。 也就是说,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执⾏结 果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
使⽤Volatile禁⽌指令重排 使⽤Volatile可以禁⽌指令重排优化,从⽽避免多线程环境下程序出现乱序执⾏的现象。Volatile通过 设置内存屏障(Memory Barrier)来解决指令重排优化。
内存屏障 Java编译器会在⽣成指令系列时在适当的位置会插⼊“内存屏障指令”来禁⽌特定类型的处理器重排 序。下⾯是内存屏障指令:
Java编译器会在⽣成指令系列时在适当的位置会插⼊“内存屏障指令”来禁⽌特定类型的处理器重排 序。下⾯是内存屏障指令:

如果在指令间插⼊⼀条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说通过插⼊内存屏障禁⽌在内存屏障前后的指令执⾏重排序优化。 Memory Barrier的另外⼀个作⽤是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到 这些数据的最新版本。总之,volatile变量正是通过内存屏障实现其在内存中的语义,即可⻅性和禁 ⽌重排优化。 接下来看⼀个经典的懒汉式单例模式,可能被指令重排⽽导致错误的结果
package com.qf.reorder;/*** @author Thor* @公众号 Java架构栈*/public class Singleton {private static volatile Singleton instance;//私有的构造器private Singleton() {}public static Singleton getInstance() {//第⼀重检查锁定if (instance == null) {//同步锁定代码块synchronized (Singleton.class) {//第⼆重检查锁定if(instance==null){//注意:这⾥是⾮原⼦操作instance = new Singleton();}}}return instance;}}
如果在⾼并发场景下,因为 instance = new Singleton(); 是⾮原⼦操作,这个对象的创建要经历这么⼏个步骤:
• 分配内存空间
• 调⽤构造器来初始化实例
• 返回地址给引⽤。
如果此时发⽣了指令重排,先执⾏了分配内存空间后直接返回地址给引⽤,再进⾏初始化。此时在这 个过程中另⼀个线程抢占,虽然引⽤不为空,但对象还没有被实例化,于是报空指针异常。 可以通过加⼊volatile来防⽌指令重排
package com.qf.reorder;/*** @author Thor* @公众号 Java架构栈*/public class Singleton {//防⽌指令重排private static volatile Singleton instance;//私有的构造器private Singleton() {}public static Singleton getInstance() {//第⼀重检查锁定if (instance == null) {//同步锁定代码块synchronized (Singleton.class) {//第⼆重检查锁定if(instance==null){//注意:这⾥是⾮原⼦操作instance = new Singleton();}}}return instance;}}
那么Volatile是怎么禁⽌指令重排?
4.37、Volatile指令重排语义
为了实现volatile的内存语义,JMM会限制特定类型的编译器和处理器重排序,JMM会针对编译器制 定
volatile重排序规则表:
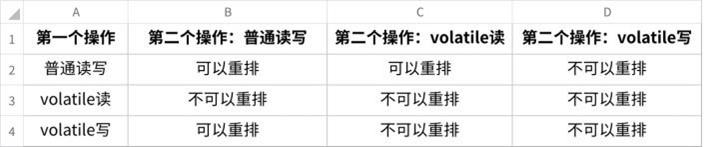
这个规则在代码中体现:
package com.qf.reorder;/*** @author Thor* @公众号 Java架构栈*/public class MemoryBarrierDemo {int a;public volatile int m1 = 1;public volatile int m2 = 2;public void readAndWrite() {int i = m1; // 第⼀个volatile读int j = m2; // 第⼆个volatile读a = i + j; // 普通写int i = m1; // 第⼀个volatile读m1 = i + 1; // 第⼀个volatile写m2 = j * 2; // 第⼆个volatile写a = i + j; // 普通写}}
4.38、MESI缓存⼀致性协议
在介绍Volatie保证可⻅性时,我们说到当两个线程在操作⼀个volatile修饰的变量时,操作数据的线 程先从主内存中把数据读到⾃⼰的⼯作内存中。如果有线程对volatile修饰的变量进⾏操作并且写回 了主内存,则其他已读取该变量的线程中,该变量副本将会失效。其他线程需要从主内存中重新加载 ⼀份最新的变量值。 那么被迫更新变量的线程是怎么知道操作的数据已被其他线程更新了呢?这就跟MESI缓存⼀致性协议 有关系。 早期技术较为落后,对总线上锁直接使⽤总线锁,也就是说CPU1访问到,CPU2⼀定不能操作,总线 锁并发性较差。MESI⽅式上锁是⽬前较为和谐的总线上锁的⽅式。
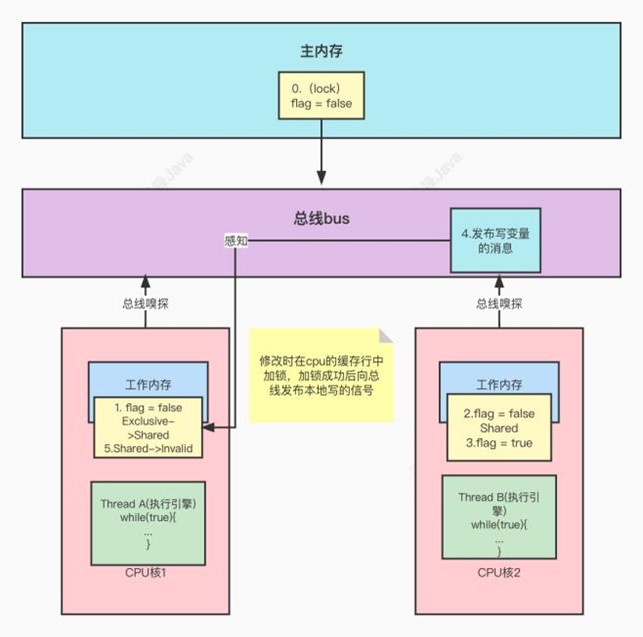
MESI协议缓存状态是四个单词的⾸字⺟: M(Modified修改):当cpu2对变量进⾏修改时,现在cpu内的缓存⾏中上锁,并向总线发信号, 此时cpu2中的变量状态为M • • E(Exclusive独享):当cpu1读取⼀个变量时,该变量在⼯作内存中的状态是E • S(Shared共享):当cpu2读取该变量时,两个cpu中该变量的状态由E转为S
I(Invalid⽆效):cpu1嗅探到变量被其他cpu修改的信号,于是将⾃⼰缓存⾏中的变量状态设置 为i,即失效。则cpu1再从内存中获取最新数据。 • 总线⻛暴 由于Volatile的MESI缓存⼀致性协议,需要不断的从主内存嗅探和cas不断循环,⽆效交互会导致总线 带宽达到峰值。所以不要⼤量使⽤Volatile,⾄于什么时候去使⽤Volatile,什么时候使⽤锁,根据场 景区分。
总结
Volatile volatile修饰符适⽤于以下场景:某个属性被多个线程共享,其中有⼀个线程修改了此属性,其他线 程可以⽴即得到修改后的值,⽐如作为触发器,实现轻量级同步。 volatile属性的读写操作都是⽆锁的,它不能替代synchronized,因为它没有提供原⼦性和互斥性。 因为⽆锁,不需要花费时间在获取锁和释放锁上,所以说它是低成本的。 volatile只能作⽤于属性,我们⽤volatile修饰属性,这样compilers就不会对这个属性做指令重排 序。 volatile提供了可⻅性,任何⼀个线程对其的修改将⽴⻢对其他线程可⻅,volatile属性不会被线程缓 存,始终从主存中读取。 volatile可以在单例双重检查中实现可⻅性和禁⽌指令重排序,从⽽保证安全性。 Volatile和Synchronized区别 volatile只能修饰实例变量和类变量,⽽synchronized可以修饰⽅法,以及代码块。 volatile保证数据的可⻅性,但是不保证原⼦性(多线程进⾏写操作,不保证线程安全)。 ⽽synchronized是⼀种排他(互斥)的机制。 volatile⽤于禁⽌指令重排序:可以解决单例双重检查对 象初始化代码执⾏乱序问题。 volatile可以看做是轻量版的synchronized,volatile不保证原⼦性,但是如果是对⼀个共享变量进⾏ 多个线程的赋值,⽽没有其他的操作,那么就可以⽤volatile来代替synchronized,因为赋值本⾝是 有原⼦性的,⽽volatile⼜保证了可⻅性,所以就可以保证线程安全了
4.39、Synchronized
在多个线程操作同⼀共享变量时,在对临界资源操作时,容易出现线程安全问题。因此需要同步机制 来解决线程安全问题与CAS乐观锁机制相同,Synchronized也能实现上锁,但Synchronized实现的是悲观锁。 Synchronized也称为内置锁或隐式锁,因为其加锁的⽅式很Lock不同,⽤了隐式上锁的⽅式。 学习Synchronized,我们重点关注以下⼏点: • Synchronized在jdk1.6版本之前性能较差,1.6及之后使⽤了锁的膨胀升级 • Synchronized的底层实现逻辑
Synchronized应⽤场景
Synchronized⼀般⽤在以下这⼏种场景: • 修饰实例⽅法,对当前实例对象(this)加锁
public synchronized void lockMethod(){System.out.println("lock method");}
修饰静态⽅法,对当前类对象(Class对象)加锁
public static synchronized void lockStaticMethod(){System.out.println("lock static method");}
修饰代码块,指定对某个对象进⾏加锁
public void lockObject(){synchronized (object){System.out.println("lock object");}}
根据锁的粒度来选择使⽤哪⼀种,⽐如使⽤静态⽅法上锁,锁的粒度是整个Class对象,如果⼤量线 程都在使⽤Class对象作为锁对象,那么锁的粒度很⼤。⽐如 System.out.println() 这种⽅式 底层是对PrintStream上锁,但PrintStream⼜是单例的,因此在代码中如果⼤量使⽤了 System.out.println() ,性能会受影响。
/*** Prints a String and then terminate the line. This method behaves as* though it invokes <code>{@link #print(String)}</code> and then* <code>{@link #println()}</code>.** @param x The <code>String</code> to be printed.*/public void println(String x) {synchronized (this) {print(x);newLine();}}
4.40、Synchronized锁的膨胀升级过程
Synchronized在1.6版本之前性能较差,在并发不严重的情况下,因为Synchronized依然对象上锁, 每个对象需要维护⼀个Monitor管程对象,管程对象需要维护⼀个Mutex互斥量对象。Mutex是由操作 系统内部的pthread线程库维护的。上锁需要通过JVM从⽤⼾态切换到内核态来调⽤底层操作系统的 指令,这样操作的性能较差。 AQS框架中的ReentrantLock锁通过Java语⾔编写,实现了可重⼊锁和公平锁,且性能⽐ Synchronized要好太多。关于ReentrantLock的逻辑在下⼀个章节介绍。 JDK1.6版本为了弥补Synchronized的性能缺陷,设计了Synchronized锁的膨胀升级。也就是根据当 前线程的竞争激烈程度,设计了不同效果的锁。

对象头
在对象的创建的过程中,涉及到以下过程

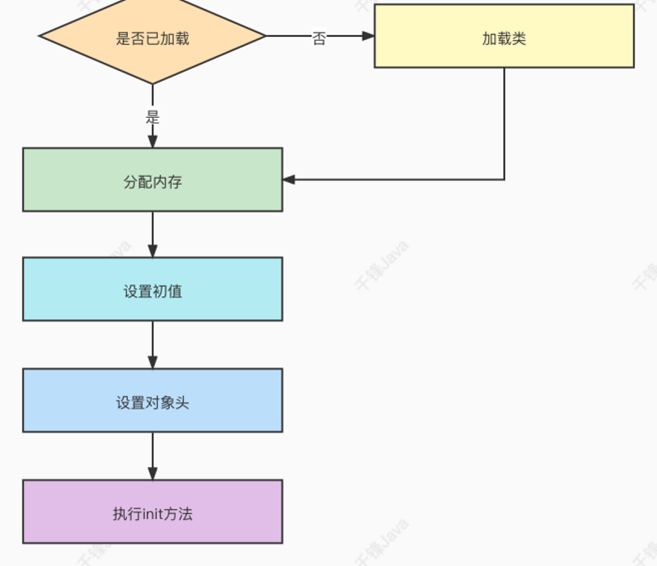
其中为对象设置对象头信息,对象头信息包含以下内容:类元信息、对象哈希码、对象年龄、锁状态 标志等。其中锁状态标志,就是当前对象属于哪⼀种锁。
• 对象头中的Mark Work 字段(32位)
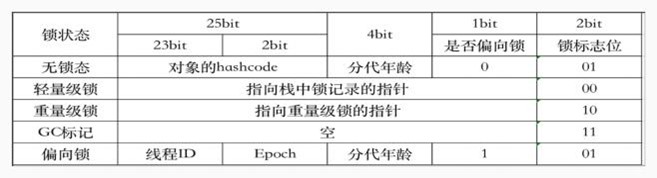
对象头中的类型指针(Klass Pointer)
类型指针⽤于指向元空间当前类的类元信息。⽐如调⽤类中的⽅法,通过类型指针找到元空间中的该 类,再找到相应的⽅法。 开启指针压缩后,类型指针只⽤4个字节存储,否则需要8个字节存储
4.41、膨胀升级
⽆锁状态:当对象锁被创建出来时,在线程获得该对象锁之前,对象处于⽆锁状态。 偏向锁:在⼤多数情况下,锁不仅不存在多线程竞争,⽽且总是由同⼀线程多次获得,因此为了 减少同⼀线程获取锁(会涉及到⼀些CAS操作,耗时)的代价⽽引⼊偏向锁。偏向锁的核⼼思想是,⼀ 旦有线程持有了这个对象,标志位修改为1,就进⼊偏向模式,同时会把这个线程的ID记录在对象 的Mark Word中。当这个线程再次请求锁时,⽆需再做任何同步操作,即获取锁的过程,这样就 省去了⼤量有关锁申请的操作,从⽽也就提供程序的性能。对于锁竞争⽐较激烈的场合,偏向锁 就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使⽤ 偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会⽴即膨胀为重量级锁,⽽是先 升级为轻量级锁
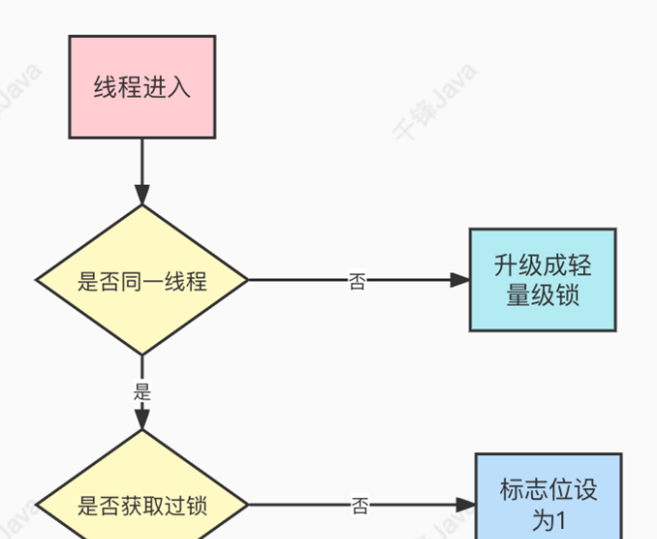
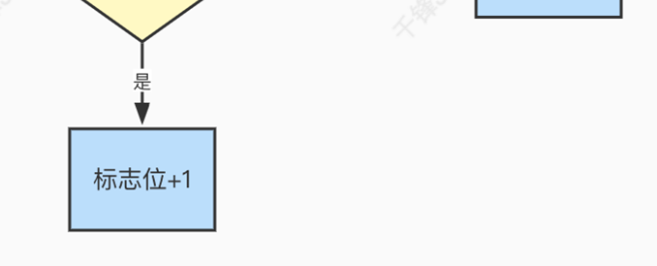
如果对象是⽆锁的,JVM会在当前线程的栈帧中建⽴⼀个Lock Record(锁记录)的空间,⽤来存放 对象的Mark Work拷⻉,然后把Lock Record中的owner属性指向当前对象。 接下来JVM会利⽤CAS尝试把对象原本的Mark Word更新回Lock Record的指针,成功就说明加锁成 功,于是改变锁标志位,执⾏相关同步操作
如果失败了,判断当前对象的Mark Word是否指向当前线程的栈帧,如果是就表⽰当前线程已经持有 该对象锁。如果不是,说明当前对象锁被其他线程持有,于是进⾏⾃旋
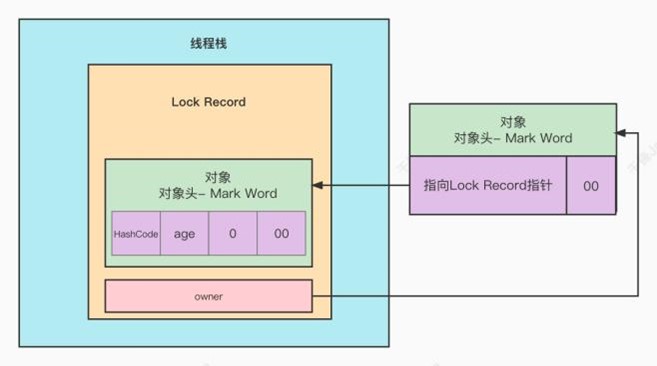
⾃旋锁:
线程通过不断的⾃旋尝试上锁,为什么要⾃旋?因为如果线程被频繁挂起,也就意味着系统在⽤⼾态 和内核态之间频繁的切换。⸺我们所有的程序都在⽤⼾空间运⾏,进⼊⽤⼾运⾏状态也就是(⽤⼾ 态),但是很多操作可能涉及内核运⾏,⽐如I/O,我们就会进⼊内核运⾏状态(内核态)。 通过⾃旋,让线程在等待时不会被挂起。⾃旋次数默认是10次,可以通过 -XX:PreBlockSpin 进⾏修改。如果⾃旋失败到达阈值,则将升级为重量级锁。 注意,锁的膨胀升级,只能升不能降,也就是说升级过程不可逆。
4.42、Synchronized的底层实现逻辑
同步代码块的上锁逻辑 先来看⼀个Java例⼦
package com.qf.intro;/*** @author Thor* @公众号 Java架构栈*/public class LockOnObjectDemo {public static Object object = new Object();private Integer count = 10;public void decrCount(){synchronized (object){--count;if(count <= 0){System.out.println("count⼩于0");return;}}}}
使⽤ javap -c LockOnObjectDemo.class 命令来看其中的信息:
public void decrCount();descriptor: ()Vflags: ACC_PUBLICCode:stack=3, locals=3, args_size=10: getstatic #4 // Field object:Ljava/lang/Object;3: dup4: astore_15: monitorenter6: aload_07: aload_08: getfield #3 // Field count:Ljava/lang/Integer;11: invokevirtual #5 // Method java/lang/Integer.intValue:()I14: iconst_115: isub16: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;19: putfield #3 // Field count:Ljava/lang/Integer;22: aload_023: getfield #3 // Field count:Ljava/lang/Integer;26: invokevirtual #5 // Method java/lang/Integer.intValue:()I29: ifgt 4332: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;35: ldc #7 // String count⼩于037: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V40: aload_141: monitorexit42: return43: aload_144: monitorexit45: goto 5348: astore_249: aload_150: monitorexit51: aload_252: athrow53: returnException table:from to target type6 42 48 any43 45 48 any48 51 48 anyLineNumberTable:line 14: 0line 15: 6line 16: 22line 17: 32line 18: 40line 20: 43line 21: 53LocalVariableTable:Start Length Slot Name Signature0 54 0 this Lcom/qf/intro/LockOnObjectDemo;StackMapTable: number_of_entries = 3frame_type = 252 /* append */offset_delta = 43locals = [ class java/lang/Object ]frame_type = 68 /* same_locals_1_stack_item */stack = [ class java/lang/Throwable ]frame_type = 250 /* chop */offset_delta = 4static {};descriptor: ()Vflags: ACC_STATICCode:stack=2, locals=0, args_size=00: new #9 // class java/lang/Object3: dup4: invokespecial #1 // Method java/lang/Object."<init>":()V7: putstatic #4 // Field object:Ljava/lang/Object;10: returnLineNumberTable:line 9: 0}SourceFile: "LockOnObjectDemo.java"
Synchronized内置锁是⼀种对象锁,作⽤粒度是对象,可以⽤来实现对临界资源的同步互斥访问, 是可重⼊的。具体的实现逻辑是通过内部对象Monitor(监视器锁)来实现。监视器锁的实现依赖底 层操作系统的Mutex Lock(互斥锁)实现。互斥锁是⼀个重量级锁,且性能较低。 Synchronized关键字被编译成字节码后,会被翻译成monitorenter和monitorexit两条指令。这两条 指令中的代码会被上锁。
4.43、Monitor监视器锁
任何⼀个对象都有⼀个Monitor与之关联,当对象的Monitor被持有后,该对象处于被锁定状态。具 体过程如下: 当我们进⼊⼀个⽅法的时候,执⾏monitorenter,就会获取当前对象的⼀个所有权,这个时候 monitor进⼊数为1,当前的这个线程就是这个monitor的owner。 • • 如果你已经是这个monitor的owner了,你再次进⼊,就会把进⼊数+1. • 当执⾏完monitorexit,对应的进⼊数就-1,直到为0,才可以被其他线程持有。 所有的互斥,其实在这⾥,就是看你能否获得monitor的所有权,⼀旦你成为owner就是获得锁者。 在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的,其主要数据结构如下(位于 HotSpot虚拟机源码ObjectMonitor.hpp⽂件,C++实现):
ObjectMonitor() {_header = NULL;_count = 0;_waiters = 0,_recursions = 0;_object = NULL;_owner = NULL;_WaitSet = NULL; // 处于wait状态的线程,加⼊到_WaitSet_WaitSetLock = 0 ;_Responsible = NULL ;_succ = NULL ;_cxq = NULL ;FreeNext = NULL ;_EntryList = NULL ; // 处于等待锁block状态的线程,加⼊到_EntryList_SpinFreq = 0 ;_SpinClock = 0 ;OwnerIsThread = 0 ;}
ObjectMonitor中有两个队列,_WaitSet 和 _EntryList,⽤来保存ObjectWaiter对象列表( 每个等 待锁的线程都会被封装成ObjectWaiter对象 ),_owner指向持有ObjectMonitor对象的线程,当多 个线程同时访问⼀段同步代码时: ⾸先会进⼊ _EntryList 集合,当线程获取到对象的monitor后,进⼊ _Owner区域并把monitor中 的owner变量设置为当前线程,同时monitor中的计数器count加1; • 若线程调⽤ wait() ⽅法,将释放当前持有的monitor,owner变量恢复为null,count⾃减1,同时 该线程进⼊WaitSet集合中等待被唤醒; • 若当前线程执⾏完毕,也将释放monitor(锁)并复位count的值,以便其他线程进⼊获取 monitor(锁); • 同时,Monitor对象存在于每个Java对象的对象头Mark Word中(存储的指针的指向), Synchronized锁便是通过这种⽅式获取锁的,也是为什么Java中任意对象可以作为锁的原因,同时 notify/notifyAll/wait等⽅法会使⽤到Monitor锁对象,所以必须在同步代码块中使⽤。监视器可以确 保监视器上的数据在同⼀时刻只会有⼀个线程在访问。 同步⽅法的上锁逻辑 先看这个例⼦
package com.qf.intro;public class LockOnMethodDemo {public static Object object = new Object();private Integer count = 10;public synchronized void decrCount() {--count;if (count <= 0) {System.out.println("count⼩于0");return;}}}
查看代码指令后:
public synchronized void decrCount();descriptor: ()Vflags: ACC_PUBLIC, ACC_SYNCHRONIZEDCode:stack=3, locals=1, args_size=10: aload_01: aload_02: getfield #3 // Field count:Ljava/lang/Integer;5: invokevirtual #4 // Method java/lang/Integer.intValue:()I8: iconst_19: isub10: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;13: putfield #3 // Field count:Ljava/lang/Integer;16: aload_017: getfield #3 // Field count:Ljava/lang/Intege20: invokevirtual #4 // Method java/lang/Integer.intValue:()I23: ifgt 3526: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;29: ldc #6 // String count⼩于031: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V34: return35: returnLineNumberTable:line 13: 0line 14: 16line 15: 26line 16: 34line 19: 35LocalVariableTable:Start Length Slot Name Signature0 36 0 this Lcom/qf/intro/LockOnMethodDemo;StackMapTable: number_of_entries = 1frame_type = 35 /* same */static {};descriptor: ()Vflags: ACC_STATICCode:stack=2, locals=0, args_size=00: new #8 // class java/lang/Object3: dup4: invokespecial #1 // Method java/lang/Object."<init>":()V7: putstatic #9 // Field object:Ljava/lang/Object;10: returnLineNumberTable:line 8: 0}
在同步⽅法⾥有⼀个标志位ACC_SYNCHRONIZED。 同步⽅法的时候,⼀旦执⾏到这个⽅法,就会先判断是否有标志位,然后,ACC_SYNCHRONIZED会 去隐式调⽤刚才的两个指令:monitorenter和monitorexit。所以归根究底,还是monitor对象的争 夺。
总结
4.44、ReentrantLock介绍
AQS AQS(AbstractQueuedSynchronizer)定义了⼀套多线程访问共享资源的同步器框架,是⼀个依赖 状态的同步器。AQS定义了很多并发中的⾏为,⽐如: • 阻塞等待队列 • 共享/独占 • 公平/⾮公平 • 可重⼊ • 允许中断 ReentrantLock介绍 ReentrantLock是基于AQS框架实现的锁,它类似于Synchronized互斥锁,可以保证线程安全。基于 AQS强⼤的并发特性和处理多线程的能⼒,ReentrantLock相⽐Synchronized,拥有更多的特性,⽐ 如⽀持⼿动加锁、解锁,⽀持公平锁等。 先来看⼀个例⼦
package com.qf.lock;import java.util.concurrent.locks.LockSupport;/*** @author Thor* @公众号 Java架构栈*/public class MyLockSupportDemo {public static void main(String[] args) {Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {Thread thread = Thread.currentThread();System.out.println(thread.getName()+":开始执⾏。");for(;;){//⾃旋System.out.println(thread.getName()+":即将park当前线程");LockSupport.park();//⽤于阻塞住线程System.out.println(thread.getName()+":当前线程已被唤醒");}}},"thread-1");t1.start();try {Thread.sleep(5000);System.out.println("准备唤醒"+t1.getName()+"线程");LockSupport.unpark(t1);//唤醒阻塞的线程} catch (InterruptedException e) {e.printStackTrace();}}
显⽰结果
thread-1:开始执⾏。thread-1:即将park当前线程准备唤醒thread-1线程thread-1:当前线程已被唤醒thread-1:即将park当前线程
从这个例⼦可以推导出,ReentrantLock的核⼼是这么⼀个逻辑: LockSupport上锁->⾃旋->队列 Reentrantlock上锁的例⼦ 接下来看下Reentrantlock上锁的例⼦
import java.util.concurrent.locks.ReentrantLock;public class MyReentrantLockDemo {public static ReentrantLock lock = new ReentrantLock(true);public static void reentrantLock(){lock.lock();System.out.println(Thread.currentThread().getName()+":,第⼀次加锁");lock.lock();System.out.println(Thread.currentThread().getName()+":,第⼆次加锁");lock.unlock();System.out.println(Thread.currentThread().getName()+":,第⼀次解锁");lock.unlock();System.out.println(Thread.currentThread().getName()+":,第⼆次解锁");}public static void main(String[] args) {Thread t0 = new Thread(new Runnable() {@Overridepublic void run() {reentrantLock();}},"t0");t0.start();try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}Thread t1 = new Thread(new Runnable() {@Overridepublic void run() {reentrantLock();}},"t1");t1.start();}}
运⾏结果:
t0:,第⼀次加锁t0:,第⼆次加锁t0:,第⼀次解锁t0:,第⼆次解锁t1:,第⼀次加锁t1:,第⼆次加锁t1:,第⼀次解锁t1:,第⼆次解锁
我们发现⼀定得是在t0线程完全释放锁后,t1线程才能获得锁
4.45、公平锁和⾮公平锁
在ReentrantLock内部定义了Sync类,Sync类继承⾃AbstractQueuedSynchronizer类。我们发现 AbstractQueuedSynchronizer是多个AQS关键类中的基类。这个类涉及到上锁的核⼼逻辑


那ReentrantLock是如何实现公平锁和⾮公平锁呢?ReentrantLock默认使⽤⾮公平锁,也可以通过 构造器来显⽰的指定使⽤公平锁。在ReentrantLock中还有两个类继承⾃Sync: • NonfairSync • FairSync 他们实现公平和⾮公平的逻辑⾮常简单,我们先看⼀下公平锁,在获锁之前,通过 !hasQueuedPredecessors() 先看下是否有⼈排队,如果没有排队则尝试获锁,如果有排队, 则进⼊排队队列
protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (!hasQueuedPredecessors() &&//判断是否之前已有线程在等待锁compareAndSetState(0, acquires)) {setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
⽽⾮公平锁⽌是没有这个判断的。也就是说,⾮公平锁的情况下,相对较晚来的线程,在尝试上锁的 时候,即使之前已经有等待锁的线程存在,它也是有可能上锁成功的
final void lock() {if (compareAndSetState(0, 1))setExclusiveOwnerThread(Thread.currentThread());elseacquire(1);}
但公平锁则是先等待的,先获得锁,后来的后获得锁。这是 hasQueuedPredecessors() ⽅法的 逻辑
public final boolean hasQueuedPredecessors() {// The correctness of this depends on head being initialized// before tail and on head.next being accurate if the current// thread is first in queue.Node t = tail; // Read fields in reverse initialization orderNode h = head;Node s;return h != t &&((s = h.next) == null || s.thread != Thread.currentThread());}
4.46、AbstractQueuedSynchronizer类的关键属性
ReentrantLock如何获得锁呢?先来看下AbstractQueuedSynchronizer类的结构
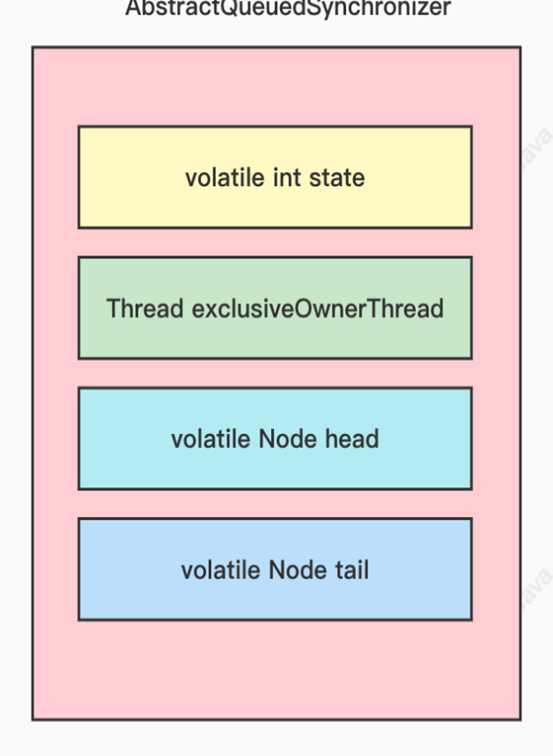
state:同步器状态变量,值为0时表⽰当前可以被加锁。值为1 时表⽰有线程占⽤,其他线程需要 进⼊到同步队列等待,同步队列是⼀个双向链表。 • • exclusiveOwnerThread:当前获取锁的线程 • head:指向基于Node类构造的队列的队头,同步队列是⼀个双向链表。 • tail:指向基于Node类构造的队列的队尾,同步队列是⼀个双向链表。 • Thread:表⽰当前线程的引⽤,⽐如需要唤醒的线程。
上锁逻辑
public final void acquire(int arg) {//1if (!tryAcquire(arg) &&//尝试加锁acquireQueued(addWaiter(Node.EXCLUSIVE), arg))//没有加锁成功,尝试⼊队列selfInterrupt();}
以公平锁上锁为例,当使⽤lock()上锁,会传⼊1作为cas对state状态量的预计值进⾏修改,前提是查 看同步队列中是否没有其他线程等待
protected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {if (!hasQueuedPredecessors() &&//查看同步队列compareAndSetState(0, acquires)) {//CAS设置state值,期望旧值为0,期望新值为1setExclusiveOwnerThread(current);return true;}}else if (current == getExclusiveOwnerThread()) {//如果上锁失败,查看是否是⾃⼰持有锁,如果是,state+1int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}
如果上锁失败,查看是否是⾃⼰持有锁,如果是则state++。 如果没有加锁成功,则尝试进⼊队列
private Node addWaiter(Node mode) {Node node = new Node(Thread.currentThread(), mode);// Try the fast path of enq; backup to full enq on failureNode pred = tail;if (pred != null) {node.prev = pred;if (compareAndSetTail(pred, node)) {pred.next = node;return node;}}enq(node);return node;}
队列的细节 虽然说当前线程已经⼊队列了,但线程还没有阻塞,接下来线程要做阻塞。
final boolean acquireQueued(final Node node, int arg) {boolean failed = true;try {boolean interrupted = false;for (;;) {/*final Node predecessor() throws NullPointerException {Node p = prev;if (p == null)throw new NullPointerException();elsereturn p;}*/final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {//阻塞之前,再抢⼀次锁,如果锁成功,头节点出队列setHead(node);p.next = null; // help GCfailed = false;return interrupted;}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())//进⾏阻塞interrupted = true;}} finally {if (failed)cancelAcquire(node);}}
什么时候被唤醒呢?在lock.unlock()中唤醒
protected final boolean tryRelease(int releases) {int c = getState() - releases;//state-1if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();boolean free = false;if (c == 0) {free = true;setExclusiveOwnerThread(null);//所属线程置空}setState(c);return free;}
唤醒线程
private void unparkSuccessor(Node node) {/** If status is negative (i.e., possibly needing signal) try* to clear in anticipation of signalling. It is OK if this* fails or if status is changed by waiting thread.*/int ws = node.waitStatus;if (ws < 0)compareAndSetWaitStatus(node, ws, 0);/** Thread to unpark is held in successor, which is normally* just the next node. But if cancelled or apparently null,* traverse backwards from tail to find the actual* non-cancelled successor.*/Node s = node.next;if (s == null || s.waitStatus > 0) {s = null;for (Node t = tail; t != null && t != node; t = t.prev)if (t.waitStatus <= 0)s = t;}if (s != null)LockSupport.unpark(s.thread);//唤醒线程}
第五章:MySQL
5.1、MySQL 的事务隔离级别有哪些?分别⽤于解决什么问题?
主要⽤于解决脏读、不可重复读、幻读。
脏读:⼀个事务读取到另⼀个事务还未提交的数据。
不可重复读:在⼀个事务中多次读取同⼀个数据时,结果出现不⼀致。
幻读:在⼀个事务中使⽤相同的 SQL 两次读取,第⼆次读取到了其他事务新插⼊的⾏。
不可重复读注重于数据的修改,⽽幻读注重于数据的插⼊
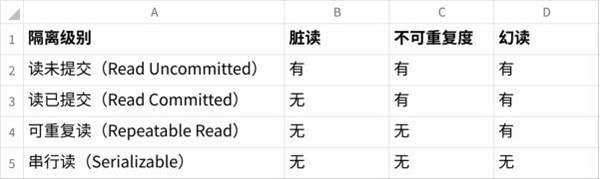
5.2、MySQL 的可重复读怎么实现的?
使⽤ MVCC 实现的,即 Mutil-Version Concurrency Control,多版本并发控制。关于 MVCC,⽐较常 ⻅的说法如下,包括《⾼性能 MySQL》也是这么介绍的。 InnoDB 在每⾏记录后⾯保存两个隐藏的列,分别保存了数据⾏的创建版本号和删除版本号。每开始 ⼀个新的事务,系统版本号都会递增。事务开始时刻的版本号会作为事务的版本号,⽤来和查询到的 每⾏记录的版本号对⽐。在可重复读级别下,MVCC是如何操作的:
SELECT:必须同时满⾜以下两个条件,才能查询到。
1)只查版本号早于当前版本的数据⾏;
2)⾏的删除版本要么未定义,要么⼤于当前事务版本号。
INSERT:为插⼊的每⼀⾏保存当前系统版本号作为创建版本号。 DELETE:为删除的每⼀⾏保存当前系统版本号作为删除版本号。UPDATE:插⼊⼀条新数据,保存当前系统版本号作为创建版本号。同时保存当前系统版本号作为原 来的数据⾏删除版本号。
MVCC 只作⽤于 RC(Read Committed)和 RR(Repeatable Read)级别,因为 RU(Read Uncommitted)总是读取最新的数据版本,⽽不是符合当前事务版本的数据⾏。⽽ Serializable 则会 对所有读取的⾏都加锁。这两种级别都不需要 MVCC 的帮助
5.3、MVCC 解决了幻读了没有?
幻读:在⼀个事务中使⽤相同的 SQL 两次读取,第⼆次读取到了其他事务新插⼊的⾏,则称为发⽣ 了幻读。
例如:
1)事务1第⼀次查询:select * from user where id < 10 时查到了 id = 1 的数据
2)事务2插⼊了 id = 2 的数据
3)事务1使⽤同样的语句第⼆次查询时,查到了 id = 1、id = 2 的数据,出现了幻读。
谈到幻读,⾸先我们要引⼊“快照读”和“当前读”的概念:
快照读:⽣成⼀个事务快照(ReadView),之后都从这个快照获取数据。普通 select 语句就是快照 读。
当前读:读取数据的最新版本。常⻅的 update/insert/delete、还有 select … for update、select … lock in share mode 都是当前读。
对于快照读,MVCC 因为因为从 ReadView 读取,所以必然不会看到新插⼊的⾏,所以天然就解决了 幻读的问题。
⽽对于当前读的幻读,MVCC 是⽆法解决的。需要使⽤ Gap Lock 或 Next-Key Lock(Gap Lock + Record Lock)来解决。
其实原理也很简单,⽤上⾯的例⼦稍微修改下以触发当前读:select * from user where id < 10 for update,当使⽤了 Gap Lock 时,Gap 锁会锁住 id < 10 的整个范围,因此其他事务⽆法插⼊ id < 10 的数据,从⽽防⽌了幻读
5.4、经常有⼈说 Repeatable Read 解决了幻读是什么情况?
SQL 标准中规定的 RR 并不能消除幻读,但是 MySQL 的 RR 可以,靠的就是 Gap 锁。在 RR 级别 下,Gap 锁是默认开启的,⽽在 RC 级别下,Gap 锁是关闭的。
5.5、什么是索引?
MySQL 官⽅对索引的定义为:索引(Index)是帮助 MySQL ⾼效获取数据的数据结构。简单的理 解,索引类似于字典⾥⾯的⽬录
5.6、常⻅的索引类型有哪些?
常⻅的索引类型有:hash、b树、b+树。
hash:底层就是 hash 表。进⾏查找时,根据 key 调⽤hash 函数获得对应的 hashcode,根据 hashcode 找到对应的数据⾏地址,根据地址拿到对应的数据。
B树:B树是⼀种多路搜索树,n 路搜索树代表每个节点最多有 n 个⼦节点。每个节点存储 key + 指向 下⼀层节点的指针+ 指向 key 数据记录的地址。查找时,从根结点向下进⾏查找,直到找到对应的 key。
B+树:B+树是b树的变种,主要区别在于:B+树的⾮叶⼦节点只存储 key + 指向下⼀层节点的指针。 另外,B+树的叶⼦节点之间通过指针来连接,构成⼀个有序链表,因此对整棵树的遍历只需要⼀次线 性遍历叶⼦结点即可
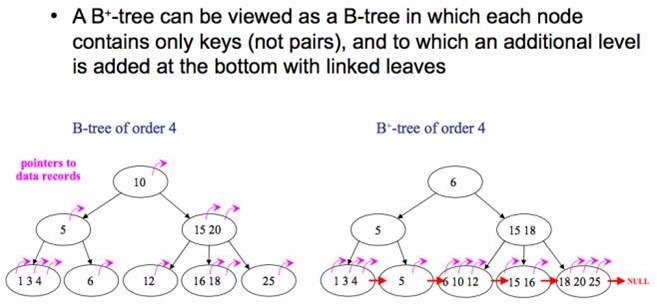
5.7、为什么MySQL数据库要⽤B+树存储索引?⽽不⽤红⿊树、B树、 Hash?
红⿊树:如果在内存中,红⿊树的查找效率⽐B树更⾼,但是涉及到磁盘操作,B树就更优了。因为红 ⿊树是⼆叉树,数据量⼤时树的层数很⾼,从树的根结点向下寻找的过程,每读1个节点,都相当于 ⼀次IO操作,因此红⿊树的I/O操作会⽐B树多的多。
hash 索引:如果只查询单个值的话,hash 索引的效率⾮常⾼。但是 hash 索引有⼏个问题:
1)不⽀持范围查询;
2)不⽀持索引值的排序操作;
3)不⽀持联合索引的最左匹配规则。
B树索引:B树索相⽐于B+树,在进⾏范围查询时,需要做局部的中序遍历,可能要跨层访问,跨层 访问代表着要进⾏额外的磁盘I/O操作;另外,B树的⾮叶⼦节点存放了数据记录的地址,会导致存放 的节点更少,树的层数变⾼
5.8、MySQL 中的索引叶⼦节点存放的是什么?
MyISAM和InnoDB都是采⽤的B+树作为索引结构,但是叶⼦节点的存储上有些不同。
MyISAM:主键索引和辅助索引(普通索引)的叶⼦节点都是存放 key 和 key 对应数据⾏的地址。在 MyISAM 中,主键索引和辅助索引没有任何区别。
InnoDB:主键索引存放的是 key 和 key 对应的数据⾏。辅助索引存放的是 key 和 key 对应的主键 值。因此在使⽤辅助索引时,通常需要检索两次索引,⾸先检索辅助索引获得主键值,然后⽤主键值 到主键索引中检索获得记录。
5.9、什么是聚簇索引(聚集索引)?
聚簇索引并不是⼀种单独的索引类型,⽽是⼀种数据存储⽅式。聚簇索引将索引和数据⾏放到了⼀ 块,找到索引也就找到了数据。因为⽆需进⾏回表操作,所以效率很⾼。 InnoDB 中必然会有,且只会有⼀个聚簇索引。通常是主键,如果没有主键,则优先选择⾮空的唯⼀ 索引,如果唯⼀索引也没有,则会创建⼀个隐藏的row_id 作为聚簇索引。⾄于为啥会只有⼀个聚簇 索引,其实很简单,因为我们的数据只会存储⼀份。 ⽽⾮聚簇索引则将数据存储和索引分开,找到索引后,需要通过对应的地址找到对应的数据⾏。 MyISAM 的索引⽅式就是⾮聚簇索引。
5.10、什么是回表查询?
InnoDB 中,对于主键索引,只需要⾛⼀遍主键索引的查询就能在叶⼦节点拿到数据。 ⽽对于普通索引,叶⼦节点存储的是 key + 主键值,因此需要再⾛⼀次主键索引,通过主键索引找到 ⾏记录,这就是所谓的回表查询,先定位主键值,再定位⾏记录
5.11、⾛普通索引,⼀定会出现回表查询吗?
不⼀定,如果查询语句所要求的字段全部命中了索引,那么就不必再进⾏回表查询。 很容易理解,有⼀个 user 表,主键为 id,name 为普通索引,则再执⾏:select id, name from user where name = ‘joonwhee’ 时,通过name 的索引就能拿到 id 和 name了,因此⽆需再回表去查数据 ⾏了
5.12、那你知道什么是覆盖索引(索引覆盖)吗?
覆盖索引是 SQL-Server 中的⼀种说法,上⾯讲的例⼦其实就实现了覆盖索引。具体的:当索引上包 含了查询语句中的所有列时,我们⽆需进⾏回表查询就能拿到所有的请求数据,因此速度会很快。
假设你定义⼀个联合索引
CREATE INDEX idx_name_age ON user(name,age);
查询名称为 joon 的年龄:
select name,age from user where name = 'joon';
上述语句中,查找的字段 name 和 age 都包含在联合索引 idx_name_age 的索引树中,这样的查询 就是覆盖索引查询
5.13、联合索引(复合索引)的底层实现?最佳左前缀原则?
联合索引底层还是使⽤B+树索引,并且还是只有⼀棵树,只是此时的排序会:⾸先按照第⼀个索引排 序,在第⼀个索引相同的情况下,再按第⼆个索引排序,依次类推。
这也是为什么有“最佳左前缀原则”的原因,因为右边(后⾯)的索引都是在左边(前⾯)的索引排 序的基础上进⾏排序的,如果没有左边的索引,单独看右边的索引,其实是⽆序的。
还是以字典为例,我们如果要查第2个字⺟为 k 的,通过⽬录是⽆法快速找的,因为⾸字⺟ A - Z ⾥⾯ 都可能包含第2个字⺟为 k 的
5.14、union 和 union all 的区别
union all:对两个结果集直接进⾏并集操作,记录可能有重复,不会进⾏排序。
union:对两个结果集进⾏并集操作,会进⾏去重,记录不会重复,按字段的默认规则排序。
因此,从效率上说,UNION ALL 要⽐ UNION 更快
5.15、B+树中⼀个节点到底多⼤合适?
1⻚或⻚的倍数最为合适。因为如果⼀个节点的⼤⼩⼩于1⻚,那么读取这个节点的时候其实也会读出 1⻚,造成资源的浪费。所以为了不造成浪费,所以把⼀个节点的⼤⼩控制在1⻚、2⻚、3⻚等倍数⻚ ⼤⼩最为合适。
这⾥说的“⻚”是 MySQL ⾃定义的单位(和操作系统类似),MySQL 的 Innodb 引擎中1⻚的默认 ⼤⼩是16k,可以使⽤命令SHOW GLOBAL STATUS LIKE ‘Innodb_page_size’ 查看
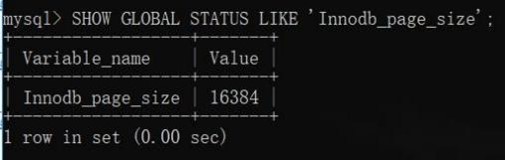
5.16、那 MySQL 中B+树的⼀个节点⼤⼩为多⼤呢
在 MySQL 中 B+ 树的⼀个节点⼤⼩为“1⻚”,也就是16k。
5.17、什么⼀个节点为1⻚就够了?
Innodb中,B+树中的⼀个节点存储的内容是: • ⾮叶⼦节点:key + 指针 • 叶⼦节点:数据⾏(key 通常是数据的主键) 对于叶⼦节点:我们假设1⾏数据⼤⼩为1k(对于普通业务绝对够了),那么1⻚能存16条数据。
对于⾮叶⼦节点:key 使⽤ bigint 则为8字节,指针在 MySQL 中为6字节,⼀共是14字节,则16k 能存放 16 1024 / 14 = 1170个。那么⼀颗⾼度为3的B+树能存储的数据为:1170 1170 * 16 = 21902400(千万级)
所以在 InnoDB 中B+树⾼度⼀般为3层时,就能满⾜千万级的数据存储。在查找数据时⼀次⻚的查找 代表⼀次IO,所以通过主键索引查询通常只需要1-3次 IO 操作即可查找到数据。千万级别对于⼀般的 业务来说已经⾜够了,所以⼀个节点为1⻚,也就是16k是⽐较合理的
5.18、什么是 Buffer Pool?
Buffer Pool 是 InnoDB 维护的⼀个缓存区域,⽤来缓存数据和索引在内存中,主要⽤来加速数据的读 写,如果 Buffer Pool 越⼤,那么 MySQL 就越像⼀个内存数据库,默认⼤⼩为 128M。
InnoDB 会将那些热点数据和⼀些 InnoDB 认为即将访问到的数据存在 Buffer Pool 中,以提升数据 的读取性能。
InnoDB 在修改数据时,如果数据的⻚在 Buffer Pool 中,则会直接修改 Buffer Pool,此时我们称这 个⻚为脏⻚,InnoDB 会以⼀定的频率将脏⻚刷新到磁盘,这样可以尽量减少磁盘I/O,提升性能
5.19、InnoDB 四⼤特性知道吗?
插⼊缓冲(insert buffer):
索引是存储在磁盘上的,所以对于索引的操作需要涉及磁盘操作。如果我们使⽤⾃增主键,那么在插 ⼊主键索引(聚簇索引)时,只需不断追加即可,不需要磁盘的随机 I/O。但是如果我们使⽤的是普 通索引,⼤概率是⽆序的,此时就涉及到磁盘的随机 I/O,⽽随机I/O的性能是⽐较差的(Kafka 官⽅ 数据:磁盘顺序I/O的性能是磁盘随机I/O的4000~5000倍)。
因此,InnoDB 存储引擎设计了 Insert Buffer ,对于⾮聚集索引的插⼊或更新操作,不是每⼀次直接 插⼊到索引⻚中,⽽是先判断插⼊的⾮聚集索引⻚是否在缓冲池(Buffer pool)中,若在,则直接插 ⼊;若不在,则先放⼊到⼀个 Insert Buffer 对象中,然后再以⼀定的频率和情况进⾏ Insert Buffer 和辅助索引⻚⼦节点的 merge(合并)操作,这时通常能将多个插⼊合并到⼀个操作中(因为在⼀个 索引⻚中),这就⼤⼤提⾼了对于⾮聚集索引插⼊的性能。
插⼊缓冲的使⽤需要满⾜以下两个条件:1)索引是辅助索引;2)索引不是唯⼀的。
因为在插⼊缓冲时,数据库不会去查找索引⻚来判断插⼊的记录的唯⼀性。如果去查找肯定⼜会有随 机读取的情况发⽣,从⽽导致 Insert Buffer 失去了意义。
⼆次写(double write):
脏⻚刷盘⻛险:InnoDB 的 page size⼀般是16KB,操作系统写⽂件是以4KB作为单位,那么每写⼀ 个 InnoDB 的 page 到磁盘上,操作系统需要写4个块。于是可能出现16K的数据,写⼊4K 时,发⽣ 了系统断电或系统崩溃,只有⼀部分写是成功的,这就是 partial page write(部分⻚写⼊)问题。 这时会出现数据不完整的问题。
这时是⽆法通过 redo log 恢复的,因为 redo log 记录的是对⻚的物理修改,如果⻚本⾝已经损坏, 重做⽇志也⽆能为⼒。
doublewrite 就是⽤来解决该问题的。doublewrite 由两部分组成,⼀部分为内存中的 doublewrite buffer,其⼤⼩为2MB,另⼀部分是磁盘上共享表空间中连续的128个⻚,即2个区(extent),⼤⼩也 是2M。
为了解决 partial page write 问题,当 MySQL 将脏数据刷新到磁盘的时候,会进⾏以下操作:
1)先将脏数据复制到内存中的 doublewrite buffer
2)之后通过 doublewrite buffer 再分2次,每次1MB写⼊到共享表空间的磁盘上(顺序写,性能很 ⾼)
3)完成第⼆步之后,⻢上调⽤ fsync 函数,将doublewrite buffer中的脏⻚数据写⼊实际的各个表空 间⽂件(离散写)。
如果操作系统在将⻚写⼊磁盘的过程中发⽣崩溃,InnoDB 再次启动后,发现了⼀个 page 数据已经 损坏,InnoDB 存储引擎可以从共享表空间的 doublewrite 中找到该⻚的⼀个最近的副本,⽤于进⾏ 数据恢复了。
⾃适应哈希索引(adaptive hash index)
哈希(hash)是⼀种⾮常快的查找⽅法,⼀般情况下查找的时间复杂度为 O(1)。但是由于不⽀持范 围查询等条件的限制,InnoDB 并没有采⽤ hash 索引,但是如果能在⼀些特殊场景下使⽤ hash 索 引,则可能是⼀个不错的补充,⽽ InnoDB 正是这么做的。
具体的,InnoDB 会监控对表上索引的查找,如果观察到某些索引被频繁访问,索引成为热数据,建 ⽴哈希索引可以带来速度的提升,则建⽴哈希索引,所以称之为⾃适应(adaptive)的。⾃适应哈希 索引通过缓冲池的 B+ 树构造⽽来,因此建⽴的速度很快。⽽且不需要将整个表都建哈希索引, InnoDB 会⾃动根据访问的频率和模式来为某些⻚建⽴哈希索引。
预读(read ahead): InnoDB 在 I/O 的优化上有个⽐较重要的特性为预读,当 InnoDB 预计某些 page 可能很快就会需要⽤ 到时,它会异步地将这些 page 提前读取到缓冲池(buffer pool)中,这其实有点像空间局部性的概 念。
空间局部性(spatial locality):如果⼀个数据项被访问,那么与它地址相邻的数据项也可能很快被 访问。
InnoDB使⽤两种预读算法来提⾼I/O性能:线性预读(linear read-ahead)和随机预读 (randomread-ahead)。 其中,线性预读以 extent(块,1个 extent 等于64个 page)为单位,⽽随机预读放到以 extent 中的 page 为单位。线性预读着眼于将下⼀个extent 提前读取到 buffer pool 中,⽽随机预读着眼于将当前 extent 中的剩余的 page 提前读取到 buffer pool 中。
线性预读(Linear read-ahead):线性预读⽅式有⼀个很重要的变量 innodb_read_ahead_threshold,可以控制 Innodb 执⾏预读操作的触发阈值。如果⼀个 extent 中 的被顺序读取的 page 超过或者等于该参数变量时,Innodb将会异步的将下⼀个 extent 读取到 buffer pool中,innodb_read_ahead_threshold 可以设置为0-64(⼀个 extend 上限就是64⻚)的 任何值,默认值为56,值越⾼,访问模式检查越严格。
随机预读(Random read-ahead): 随机预读⽅式则是表⽰当同⼀个 extent 中的⼀些 page 在 buffer pool 中发现时,Innodb 会将该 extent 中的剩余 page ⼀并读到 buffer pool中,由于随机预读⽅式 给 Innodb code 带来了⼀些不必要的复杂性,同时在性能也存在不稳定性,在6.5中已经将这种预读 ⽅式废弃。要启⽤此功能,请将配置变量设置 innodb_random_read_ahead 为ON
5.20、请说⼀下共享锁和排他锁?
共享锁⼜称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同⼀数据可以共享⼀把锁,都能 访问到数据,但是只能读不能修改。
排他锁⼜称为写锁,简称X锁,顾名思义,排他锁就是不能与其他锁并存,如⼀个事务获取了⼀个数 据⾏的排他锁,其他事务就不能再获取该⾏的其他锁,包括共享锁和排他锁,但是获取排他锁的事务 可以对数据就⾏读取和修改
常⻅的⼏种 SQL 语句的加锁情况如下:
select * from table; #不加锁update/insert/delete #排他锁select * from table where id = 1 for update; #id为索引,加排他锁select * from table where id = 1 lock in share mode; #id为索引,加共享锁
5.21、请说⼀下数据库的⾏锁和表锁?
⾏锁:操作时只锁某⼀(些)⾏,不对其它⾏有影响。开销⼤,加锁慢;会出现死锁;锁定粒度⼩, 发⽣锁冲突的概率低,并发度⾼。
表锁:即使操作⼀条记录也会锁住整个表。开销⼩,加锁快;不会出现死锁;锁定粒度⼤,发⽣锁冲 突概率⾼,并发度最低。
⻚锁:操作时锁住⼀⻚数据(16kb)。开销和加锁速度介于表锁和⾏锁之间;会出现死锁;锁定粒度 介于表锁和⾏锁之间,并发度⼀般。
InnoDB 有⾏锁和表锁,MyIsam 只有表锁
5.23、InnoDB 锁的算法有哪⼏种?
Record lock:记录锁,单条索引记录上加锁,锁住的永远是索引,⽽⾮记录本⾝。 Gap lock:间隙锁,在索引记录之间的间隙中加锁,或者是在某⼀条索引记录之前或者之后加锁,并 不包括该索引记录本⾝。
Next-key lock:Record lock 和 Gap lock 的结合,即除了锁住记录本⾝,也锁住索引之间的间隙
5.24、MySQL 如何实现悲观锁和乐观锁?
乐观锁:更新时带上版本号(cas更新)
悲观锁:使⽤共享锁和排它锁,select…lock in share mode,selectfor update。
5.25、InnoDB 和 MyISAM 的区别?
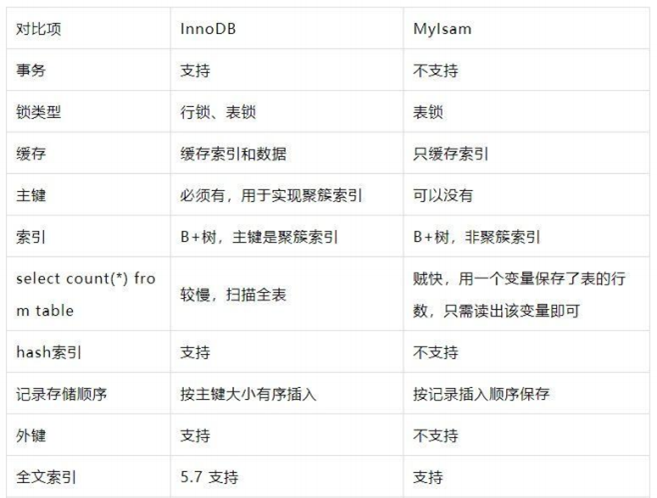

5.26、存储引擎的选择?
没有特殊情况,使⽤ InnoDB 即可。如果表中绝⼤多数都只是读查询,可以考虑 MyISAM
5.27、explain ⽤过吗,有哪些字段分别是啥意思
explain 字段有:
• id:标识符
• select_type:查询的类型
• table:输出结果集的表
• partitions:匹配的分区
• type:表的连接类型
• possible_keys:查询时,可能使⽤的索引
• key:实际使⽤的索引
• key_len:使⽤的索引字段的⻓度
• ref:列与索引的⽐较
• rows:估计要检查的⾏数
• filtered:按表条件过滤的⾏百分⽐
• Extra:附加信息
5.28、explain 主要关注哪些字段?
主要关注 type、key、row、extra 等字段。主要是看是否使⽤了索引,是否扫描了过多的⾏数,是否 出现 Using temporary、Using filesort 等⼀些影响性能的主要指标
5.29、type 中有哪些常⻅的值
按类型排序,从好到坏,常⻅的有:
const > eq_ref > ref > range > index > ALL。 const:通过主键或唯⼀键查询,并且结果只有1⾏(也就是⽤等号查询)。因为仅有⼀⾏,所以 优化器的其余部分可以将这⼀⾏中的列值视为常量。
• eq_ref:通常出现于两表关联查询时,使⽤主键或者⾮空唯⼀键关联,并且查询条件不是主键或 唯⼀键的等号查询。 •
• ref:通过普通索引查询,并且使⽤的等号查询。
• range:索引的范围查找(>=、<、in 等)。
• index:全索引扫描。
• All:全表扫描
5.30、如何做慢 SQL 优化?
⾸先要搞明⽩慢的原因是什么:是查询条件没有命中索引?还是 load 了不需要的数据列?还是数据 量太⼤?所以优化也是针对这三个⽅向来的。
⾸先⽤ explain 分析语句的执⾏计划,查看使⽤索引的情况,是不是查询没⾛索引,如果可以加索 引解决,优先采⽤加索引解决。
• 分析语句,看看是否存在⼀些导致索引失效的⽤法,是否 load 了额外的数据,是否加载了许多结 果中并不需要的列,对语句进⾏分析以及重写。
• 如果对语句的优化已经⽆法进⾏,可以考虑表中的数据量是否太⼤,如果是的话可以进⾏垂直拆 分或者⽔平拆分
5.31、说说 MySQL 的主从复制
MySQL主从复制涉及到三个线程,⼀个运⾏在主节点(Log Dump Thread),其余两个(I/O Thread,SQL Thread)运⾏在从节点,如下图所⽰
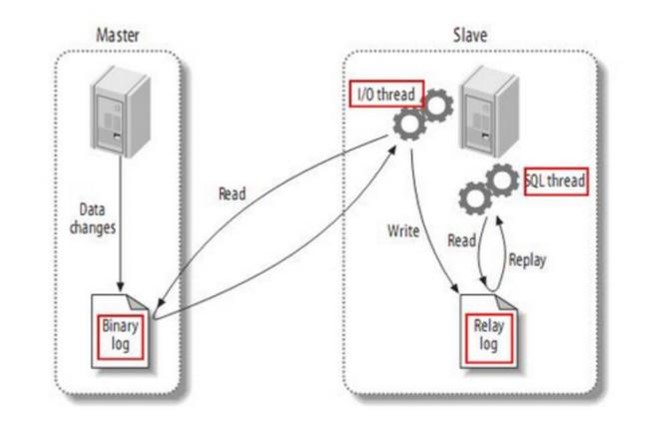
主从复制默认是异步的模式,具体过程如下。
1)从节点上的I/O 线程连接主节点,并请求从指定⽇志⽂件(bin log file)的指定位置(bin log position,或者从最开始的⽇志)之后的⽇志内容;
2)主节点接收到来⾃从节点的 I/O请求后,读取指定⽂件的指定位置之后的⽇志信息,返回给从节 点。返回信息中除了⽇志所包含的信息之外,还包括本次返回的信息的 bin-log file 以及 bin-log position;从节点的 I/O 进程接收到内容后,将接收到的⽇志内容更新到 relay log 中,并将读取到的bin log file(⽂件名)和position(位置)保存到 master-info ⽂件中,以便在下⼀次读取的时候能 够清楚的告诉 Master “我需要从某个bin-log 的个位置开始往后的⽇志内容”;
3)从节点的 SQL 线程检测到 relay-log 中新增加了内容后,会解析 relay-log 的内容,并在本数据库 中执⾏
5.32、异步复制,主库宕机后,数据可能丢失?
可以使⽤半同步复制或全同步复制。
半同步复制:
修改语句写⼊bin log后,不会⽴即给客⼾端返回结果。⽽是⾸先通过log dump 线程将 binlog 发送给 从节点,从节点的 I/O 线程收到 binlog 后,写⼊到 relay log,然后返回 ACK 给主节点,主节点收到 ACK 后,再返回给客⼾端成功
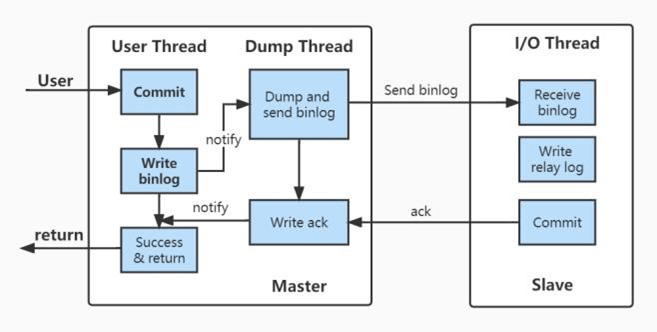
半同步复制的特点:
确保事务提交后 binlog ⾄少传输到⼀个从库
• 不保证从库应⽤完这个事务的 binlog
• 性能有⼀定的降低,响应时间会更⻓
• ⽹络异常或从库宕机,卡主主库,直到超时或从库恢复
全同步复制:主节点和所有从节点全部执⾏了该事务并确认才会向客⼾端返回成功。因为需要等待所 有从库执⾏完该事务才能返回,所以全同步复制的性能必然会收到严重的影响
5.33、主库写压⼒⼤,从库复制很可能出现延迟?
可以使⽤并⾏复制(并⾏是指从库多个SQL线程并⾏执⾏ relay log),解决从库复制延迟的问题。
MySQL 6.7 中引⼊基于组提交的并⾏复制,其核⼼思想:⼀个组提交的事务都是可以并⾏回放,因为 这些事务都已进⼊到事务的 prepare 阶段,则说明事务之间没有任何冲突(否则就不可能提交)。
判断事务是否处于⼀个组是通过 last_committed 变量,last_committed 表⽰事务提交的时候,上 次事务提交的编号,如果事务具有相同的 last_committed,则表⽰这些事务都在⼀组内,可以进⾏ 并⾏的回放
5.34、msyql优化经验
为查询缓存优化你的查询
EXPLAIN 你的 SELECT 查询
当只要⼀⾏数据时使⽤ LIMIT 1
为搜索字段建索引
在Join表的时候使⽤相当类型的例,并将其索引
千万不要 ORDER BY RAND()
避免 SELECT *
永远为每张表设置⼀个ID,使⽤数字⾃增
使⽤ ENUM ⽽不是 VARCHAR
从 PROCEDURE ANALYSE() 取得建议
尽可能的使⽤ NOT NULL
Prepared Statements很像存储过程,是⼀种运⾏在后台的SQL语句集合,我们可以从使⽤ prepare d statements 获得很多好处,⽆论是性能问题还是安全问题
⽆缓冲的查询
把IP地址存成 UNSIGNED INT
固定⻓度的表会更快
垂直分割
拆分⼤的 DELETE 或 INSERT 语句
越⼩的列会越快
选择正确的存储引擎 MyISAM 适合于⼀些需要⼤量查询的应⽤,但其对于有⼤量写操作并不是很好。甚⾄你只是需要up date⼀个字段,整个表都会被锁起来,⽽别的进程,就算是读进程都⽆法操作直到读操作完成。另外, MyISAM 对于 SELECT COUNT(*) 这类的计算是超快⽆⽐的。
InnoDB 的趋势会是⼀个⾮常复杂的存储引擎,对于⼀些⼩的应⽤,它会⽐ MyISAM 还慢。他是 它⽀持“⾏锁” ,于是在写操作⽐较多的时候,会更优秀。并且,他还⽀持更多的⾼级应⽤,⽐如:事 务
使⽤⼀个对象关系映射器(Object Relational Mapper)
⼩⼼“永久链接”
永久链接”的⽬的是⽤来减少重新创建MySQL链接的次数。当⼀个链接被创建了,它会永远处在连接的 状态,就算是数据库操作已经结束了。⽽且,⾃从我们的Apache开始重⽤它的⼦进程后——也就是说, 下⼀次的HTTP请求会重⽤Apache的⼦进程,并重⽤相同的 MySQL 链接
5.35、mysql的语句优化;
1 .对查询进⾏优化,应尽量避免全表扫描,⾸先应考虑在 where 及 order by 涉及的列上建⽴索 引。
2 .应尽量避免在 where ⼦句中使⽤!=或<>操作符,否则将引擎放弃使⽤索引⽽进⾏全表扫描。
3 .应尽量避免在 where ⼦句中对字段进⾏ null 值判断,否则将导致引擎放弃使⽤索引⽽进⾏全表 扫描,如: select id from t where num is null,可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
4 .应尽量避免在 where ⼦句中使⽤ or 来连接条件,否则将导致引擎放弃使⽤索引⽽进⾏全表扫 描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20
5 .下⾯的查询也将导致全表扫描: select id from t where name like ‘%abc%’ 若要提⾼效率,可以考虑全⽂检索。
6 .in 和 not in 也要慎⽤,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能⽤ between 就不要⽤ in 了: select id from t where num between 1 and 3
7 .如果在 where ⼦句中使⽤参数,也会导致全表扫描。因为SQL只有在运⾏时才会解析局部变量,但 优化程序不能将访问计划的选择推迟到运⾏时;它必须在编译时进⾏选择。然⽽,如果在编译时建⽴访 问计划,变量的值还是未知的,因⽽⽆法作为索引选择的输⼊项。如下⾯语句将进⾏全表扫描: select id from t where num=@num 可以改为强制查询使⽤索引: select id from t with(index(索引名)) where num=@num
8 .应尽量避免在 where ⼦句中对字段进⾏表达式操作,这将导致引擎放弃使⽤索引⽽进⾏全表扫 描。如: select id from t where num/2=100 应改为: select id from t where num=100*2
9 .应尽量避免在where⼦句中对字段进⾏函数操作,这将导致引擎放弃使⽤索引⽽进⾏全表扫描。 如: select id from t where substring(name,1,3)=’abc’—name以abc开头的id select id from t where datediff(day,createdate,’2005-11-30’)=0—‘2005-11-30’⽣成 的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30’ and createdate<’2005-12-1’
10 .不要在 where ⼦句中的“=”左边进⾏函数、算术运算或其他表达式运算,否则系统将可能⽆法正 确使⽤索引。
11 .在使⽤索引字段作为条件时,如果该索引是复合索引,那么必须使⽤到该索引中的第⼀个字段作为 条件时才能保证系统使⽤该索引,否则该索引将不会被使⽤,并且应尽可能的让字段顺序与索引顺序相 ⼀致
12 .不要写⼀些没有意义的查询,如需要⽣成⼀个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…)
13 .很多时候⽤ exists 代替 in 是⼀个好的选择: select num from a where num in(select num from b) ⽤下⾯的语句替换: select num from a where exists(select 1 from b where num=a.num)
14 .并不是所有索引对查询都有效,SQL是根据表中数据来进⾏查询优化的,当索引列有⼤量数据重复 时,SQL查询可能不会去利⽤索引,如⼀表中有字段sex,male、female⼏乎各⼀半,那么即使在sex 上建了索引也对查询效率起不了作⽤。
15 .索引并不是越多越好,索引固然可以提⾼相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑, 视具体情况⽽定。⼀个表的索引数最好不要超过6个,若太多则应考虑⼀些不常使⽤到的列上建的索引 是否有必要。
16 .应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录 的物理存储顺序,⼀旦该列值改变将导致整个表记录的顺序的调整,会耗费相当⼤的资源。若应⽤系统 需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
17 .尽量使⽤数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性 能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个⽐较字符串中每⼀个字符,⽽对于数 字型⽽⾔只需要⽐较⼀次就够了。
18 .尽可能的使⽤ varchar/nvarchar 代替 char/nchar ,因为⾸先变⻓字段存储空间⼩,可以节 省存储空间,其次对于查询来说,在⼀个相对较⼩的字段内搜索效率显然要⾼些。
19 .任何地⽅都不要使⽤ select from t ,⽤具体的字段列表代替“”,不要返回⽤不到的任何 字段。
20 .尽量使⽤表变量来代替临时表。如果表变量包含⼤量数据,请注意索引⾮常有限(只有主键索 引)。
21 .避免频繁创建和删除临时表,以减少系统表资源的消耗。
22 .临时表并不是不可使⽤,适当地使⽤它们可以使某些例程更有效,例如,当需要重复引⽤⼤型表或 常⽤表中的某个数据集时。但是,对于⼀次性事件,最好使⽤导出表。
23 .在新建临时表时,如果⼀次性插⼊数据量很⼤,那么可以使⽤ select into 代替 create tab le,避免造成⼤量 log ,以提⾼速度;如果数据量不⼤,为了缓和系统表的资源,应先create tabl e,然后insert。
24 .如果使⽤到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table , 然后 drop table ,这样可以避免系统表的较⻓时间锁定
25 .尽量避免使⽤游标,因为游标的效率较差,如果游标操作的数据超过1万⾏,那么就应该考虑改 写。
26 .使⽤基于游标的⽅法或临时表⽅法之前,应先寻找基于集的解决⽅案来解决问题,基于集的⽅法通 常更有效。
27 .与临时表⼀样,游标并不是不可使⽤。对⼩型数据集使⽤ FAST_FORWARD 游标通常要优于其他逐 ⾏处理⽅法,尤其是在必须引⽤⼏个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要⽐ 使⽤游标执⾏的速度快。如果开发时间允许,基于游标的⽅法和基于集的⽅法都可以尝试⼀下,看哪⼀ 种⽅法的效果更好。
28 .在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OF F 。⽆需在执⾏存储过程和触发器的每个语句后向客⼾端发送 DONE_IN_PROC 消息。
29 .尽量避免向客⼾端返回⼤数据量,若数据量过⼤,应该考虑相应需求是否合理。
30 .尽量避免⼤事务操作,提⾼系统并发能⼒
第六章:Spring
6.1、Spring IoC 的容器构建流程?
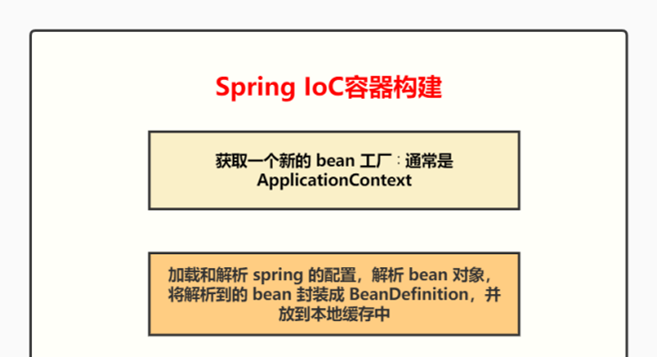
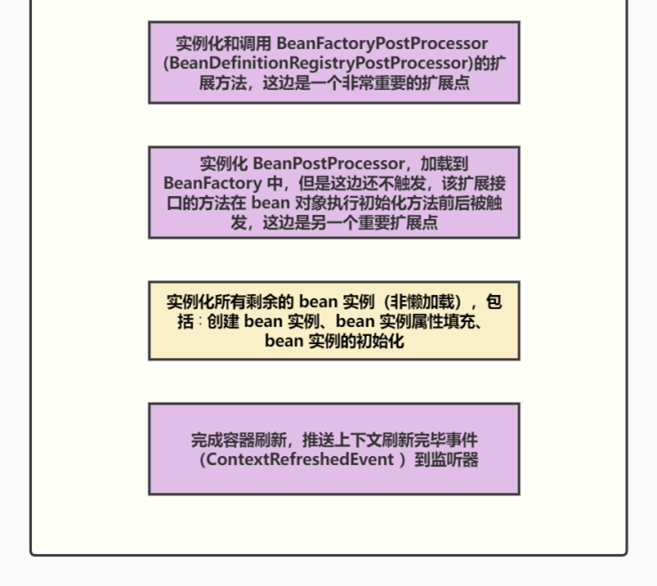
什么是IoC和DI?DI是如何实现的?
答:IoC叫控制反转,是Inversion of Control的缩写,DI(Dependency Injection)叫依赖注⼊,是 对IoC更简单的诠释。控制反转是把传统上由程序代码直接操控的对象的调⽤权交给容器,通过容器来实现对象组件的装配和管理。
所谓的”控制反转”就是对组件对象控制权的转移,从程序代码本⾝转移到了外部容器,由容器来创建 对象并管理对象之间的依赖关系。IoC体现了好莱坞原则 - “Don’t call me, we will call you”。
依赖注⼊的基本原则是应⽤组件不应该负责查找资源或者其他依赖的协作对象。配置对象的⼯作应该 由容器负责,查找资源的逻辑应该从应⽤组件的代码中抽取出来,交给容器来完成。
DI是对IoC更准确的描述,即组件之间的依赖关系由容器在运⾏期决定,形象的来说,即由容器动态 的将某种依赖关系注⼊到组件之中。
依赖注⼊可以通过setter⽅法注⼊(设值注⼊)、构造器注⼊和接⼝注⼊三种⽅式来实现,Spring⽀ 持setter注⼊和构造器注⼊,通常使⽤构造器注⼊来注⼊必须的依赖关系,对于可选的依赖关系,则 setter注⼊是更好的选择,setter注⼊需要类提供⽆参构造器或者⽆参的静态⼯⼚⽅法来创建对象
6.2、Spring Bean 的⽣命周期
bean 的⽣命周期主要有以下⼏个阶段,深⾊底的5个是⽐较重要的阶段
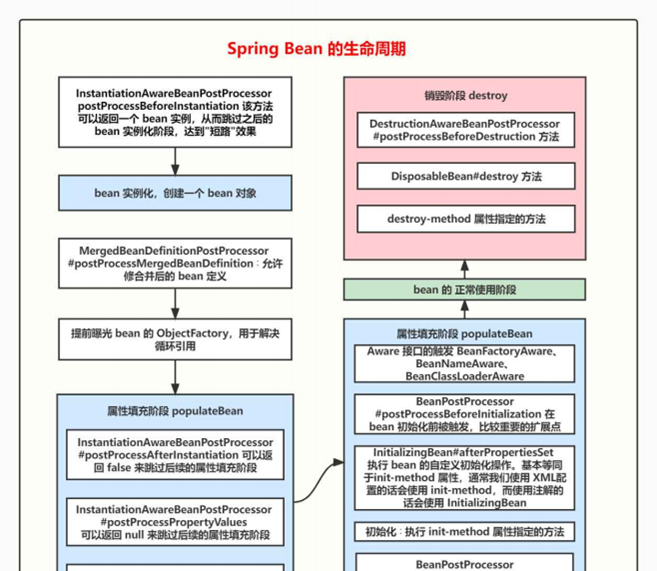

6.3、BeanFactory 和 FactoryBean 的区别?
BeanFactory:Spring 容器最核⼼也是最基础的接⼝,本质是个⼯⼚类,⽤于管理 bean 的⼯⼚,最 核⼼的功能是加载 bean,也就是 getBean ⽅法,通常我们不会直接使⽤该接⼝,⽽是使⽤其⼦接 ⼝。
FactoryBean:该接⼝以 bean 样式定义,但是它不是⼀种普通的 bean,它是个⼯⼚ bean,实现该 接⼝的类可以⾃⼰定义要创建的 bean 实例,只需要实现它的 getObject ⽅法即可。
FactoryBean 被⼴泛应⽤于 Java 相关的中间件中,如果你看过⼀些中间件的源码,⼀定会看到 FactoryBean 的⾝影
⼀般来说,都是通过 FactoryBean#getObject 来返回⼀个代理类,当我们触发调⽤时,会⾛到代理 类中,从⽽可以在代理类中实现中间件的⾃定义逻辑,⽐如:RPC 最核⼼的⼏个功能,选址、建⽴连 接、远程调⽤,还有⼀些⾃定义的监控、限流等等。
6.4、BeanFactory 和 ApplicationContext 的区别?
BeanFactory:基础 IoC 容器,提供完整的 IoC 服务⽀持。
ApplicationContext:⾼级 IoC 容器,BeanFactory 的⼦接⼝,在 BeanFactory 的基础上进⾏扩展。 包含 BeanFactory 的所有功能,还提供了其他⾼级的特性,⽐如:事件发布、国际化信息⽀持、统⼀ 资源加载策略等。正常情况下,我们都是使⽤的 ApplicationContext
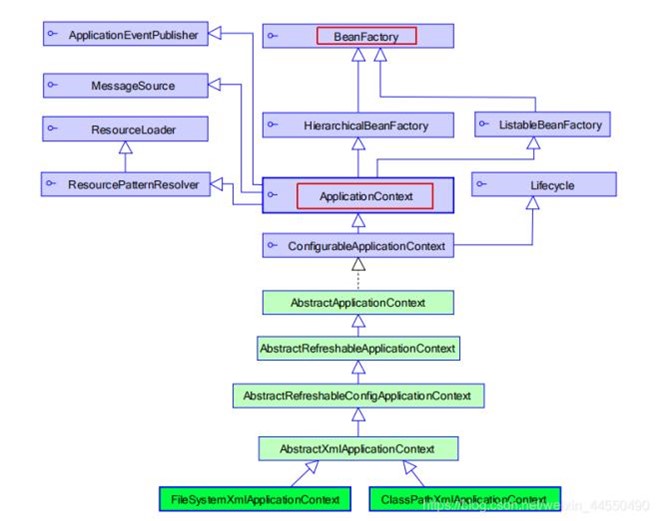
这边以电话来举个简单的例⼦:
我们家⾥使⽤的 “座机” 就类似于 BeanFactory,可以进⾏电话通讯,满⾜了最基本的需求。 ⽽现在⾮常普及的智能⼿机,iPhone、⼩⽶等,就类似于 ApplicationContext,除了能进⾏电话通 讯,还有其他很多功能:拍照、地图导航、听歌等
6.5、Spring 的 AOP 是怎么实现的?
本质是通过动态代理来实现的,主要有以下⼏个步骤。
1)获取增强器,例如被 Aspect 注解修饰的类。
2)在创建每⼀个 bean 时,会检查是否有增强器能应⽤于这个 bean,简单理解就是该 bean 是否在 该增强器指定的 execution 表达式中。如果是,则将增强器作为拦截器参数,使⽤动态代理创建 bean 的代理对象实例。
3)当我们调⽤被增强过的 bean 时,就会⾛到代理类中,从⽽可以触发增强器,本质跟拦截器类 似
你如何理解AOP中的连接点(Joinpoint)、切点(Pointcut)、增强(Advice)、引介 (Introduction)、织⼊(Weaving)、切⾯(Aspect)这些概念?
答:
a. 连接点(Joinpoint):程序执⾏的某个特定位置(如:某个⽅法调⽤前、调⽤后,⽅法抛出异常 后)。⼀个类或⼀段程序代码拥有⼀些具有边界性质的特定点,这些代码中的特定点就是连接点。 Spring仅⽀持⽅法的连接点。
b. 切点(Pointcut):如果连接点相当于数据中的记录,那么切点相当于查询条件,⼀个切点可以匹 配多个连接点。Spring AOP的规则解析引擎负责解析切点所设定的查询条件,找到对应的连接点。
c. 增强(Advice):增强是织⼊到⽬标类连接点上的⼀段程序代码。Spring提供的增强接⼝都是带⽅ 位名的,如:BeforeAdvice、AfterReturningAdvice、ThrowsAdvice等。很多资料上将增强译 为“通知”,这明显是个词不达意的翻译,让很多程序员困惑了许久。 说明: Advice在国内的很多书⾯资料中都被翻译成”通知”,但是很显然这个翻译⽆法表达其本质,有 少量的读物上将这个词翻译为”增强”,这个翻译是对Advice较为准确的诠释,我们通过AOP将横切关 注功能加到原有的业务逻辑上,这就是对原有业务逻辑的⼀种增强,这种增强可以是前置增强、后置 增强、返回后增强、抛异常时增强和包围型增强。
d. 引介(Introduction):引介是⼀种特殊的增强,它为类添加⼀些属性和⽅法。这样,即使⼀个业 务类原本没有实现某个接⼝,通过引介功能,可以动态的未该业务类添加接⼝的实现逻辑,让业务类 成为这个接⼝的实现类。
e. 织⼊(Weaving):织⼊是将增强添加到⽬标类具体连接点上的过程,AOP有三种织⼊⽅式:①编 译期织⼊:需要特殊的Java编译期(例如AspectJ的ajc);②装载期织⼊:要求使⽤特殊的类加载 器,在装载类的时候对类进⾏增强;③运⾏时织⼊:在运⾏时为⽬标类⽣成代理实现增强。Spring采 ⽤了动态代理的⽅式实现了运⾏时织⼊,⽽AspectJ采⽤了编译期织⼊和装载期织⼊的⽅式
f. 切⾯(Aspect):切⾯是由切点和增强(引介)组成的,它包括了对横切关注功能的定义,也包括 了对连接点的定义。 补充:代理模式是GoF提出的23种设计模式中最为经典的模式之⼀,代理模式是对象的结构模式,它 给某⼀个对象提供⼀个代理对象,并由代理对象控制对原对象的引⽤。 简单的说,代理对象可以完成⽐原对象更多的职责,当需要为原对象添加横切关注功能时,就可以使 ⽤原对象的代理对象。 我们在打开Office系列的Word⽂档时,如果⽂档中有插图,当⽂档刚加载时,⽂档中的插图都只是⼀ 个虚框占位符,等⽤⼾真正翻到某⻚要查看该图⽚时,才会真正加载这张图,这其实就是对代理模式 的使⽤,代替真正图⽚的虚框就是⼀个虚拟代理; Hibernate的load⽅法也是返回⼀个虚拟代理对象,等⽤⼾真正需要访问对象的属性时,才向数据库 发出SQL语句获得真实对象
6.6、多个AOP的顺序怎么定?
通过 Ordered 和 PriorityOrdered 接⼝进⾏排序。PriorityOrdered 接⼝的优先级⽐ Ordered 更⾼, 如果同时实现 PriorityOrdered 或 Ordered 接⼝,则再按 order 值排序,值越⼩的优先级越⾼
6.7、Spring 的 AOP 有哪⼏种创建代理的⽅式?
Spring 中的 AOP ⽬前⽀持 JDK 动态代理和 Cglib 代理。
通常来说:如果被代理对象实现了接⼝,则使⽤ JDK 动态代理,否则使⽤ Cglib 代理。另外,也可以 通过指定 proxyTargetClass=true 来实现强制⾛ Cglib 代理。
6.8、JDK 动态代理和 Cglib 代理的区别
1)JDK 动态代理本质上是实现了被代理对象的接⼝,⽽ Cglib 本质上是继承了被代理对象,覆盖其 中的⽅法。
2)JDK 动态代理只能对实现了接⼝的类⽣成代理,Cglib 则没有这个限制。但是 Cglib 因为使⽤继承 实现,所以 Cglib ⽆法代理被 final 修饰的⽅法或类。
3)在调⽤代理⽅法上,JDK 是通过反射机制调⽤,Cglib是通过FastClass 机制直接调⽤。FastClass 简单的理解,就是使⽤ index 作为⼊参,可以直接定位到要调⽤的⽅法直接进⾏调⽤。
4)在性能上,JDK1.7 之前,由于使⽤了 FastClass 机制,Cglib 在执⾏效率上⽐ JDK 快,但是随着 JDK 动态代理的不断优化,从 JDK 1.7 开始,JDK 动态代理已经明显⽐ Cglib 更快了。
6.9、JDK 动态代理为什么只能对实现了接⼝的类⽣成代理?
根本原因是通过 JDK 动态代理⽣成的类已经继承了 Proxy 类,所以⽆法再使⽤继承的⽅式去对类实 现代理。
6.10、Spring 的事务传播⾏为有哪些
1)REQUIRED:Spring 默认的事务传播级别,如果上下⽂中已经存在事务,那么就加⼊到事务中执 ⾏,如果当前上下⽂中不存在事务,则新建事务执⾏。
2)REQUIRES_NEW:每次都会新建⼀个事务,如果上下⽂中有事务,则将上下⽂的事务挂起,当 新建事务执⾏完成以后,上下⽂事务再恢复执⾏。
3)SUPPORTS:如果上下⽂存在事务,则加⼊到事务执⾏,如果没有事务,则使⽤⾮事务的⽅式执 ⾏。
4)MANDATORY:上下⽂中必须要存在事务,否则就会抛出异常。
5)NOT_SUPPORTED :如果上下⽂中存在事务,则挂起事务,执⾏当前逻辑,结束后恢复上下⽂的 事务。
6)NEVER:上下⽂中不能存在事务,否则就会抛出异常。
7)NESTED:嵌套事务。如果上下⽂中存在事务,则嵌套事务执⾏,如果不存在事务,则新建事 务
6.11、Spring 的事务隔离级别?
Spring 的事务隔离级别底层其实是基于数据库的,Spring 并没有⾃⼰的⼀套隔离级别。
DEFAULT:使⽤数据库的默认隔离级别。
READ_UNCOMMITTED:读未提交,最低的隔离级别,会读取到其他事务还未提交的内容,存在脏 读。
READ_COMMITTED:读已提交,读取到的内容都是已经提交的,可以解决脏读,但是存在不可重复 读。
REPEATABLE_READ:可重复读,在⼀个事务中多次读取时看到相同的内容,可以解决不可重复读, 但是存在幻读。
SERIALIZABLE:串⾏化,最⾼的隔离级别,对于同⼀⾏记录,写会加写锁,读会加读锁。在这种情 况下,只有读读能并发执⾏,其他并⾏的读写、写读、写写操作都是冲突的,需要串⾏执⾏。可以防 ⽌脏读、不可重复度、幻读,没有并发事务问题。
6.12、Spring 的事务隔离级别是如何做到和数据库不⼀致的?
⽐如数据库是可重复读,Spring 是读已提交,这是怎么实现的? Spring 的事务隔离级别本质上还是通过数据库来控制的,具体是在执⾏事务前先执⾏命令修改数据库 隔离级别,命令格式如下
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED
6.13、Spring 事务的实现原理?
Spring 事务的底层实现主要使⽤的技术:AOP(动态代理) + ThreadLocal + try/catch。 动态代理:基本所有要进⾏逻辑增强的地⽅都会⽤到动态代理,AOP 底层也是通过动态代理实现。
ThreadLocal:主要⽤于线程间的资源隔离,以此实现不同线程可以使⽤不同的数据源、隔离级别等 等。
try/catch:最终是执⾏ commit 还是 rollback,是根据业务逻辑处理是否抛出异常来决定。 Spring 事务的核⼼逻辑伪代码如下:
public void invokeWithinTransaction() {// 1.事务资源准备try {// 1.业务逻辑处理,也就是调⽤被代理的⽅法} catch (Exception e) {// 2.出现异常,进⾏回滚并将异常抛出} finally {// 现场还原:还原旧的事务信息}// 5.正常执⾏,进⾏事务的提交// 返回业务逻辑处理结果}
详细流程如下图所⽰:
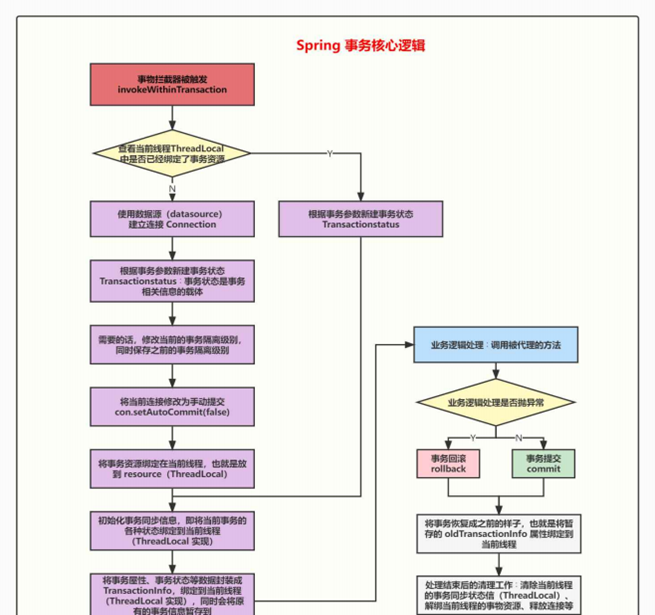

6.14、Spring 怎么解决循环依赖的问题?
Spring 是通过提前暴露 bean 的引⽤来解决的,具体如下。
Spring ⾸先使⽤构造函数创建⼀个 “不完整” 的 bean 实例(之所以说不完整,是因为此时该 bean 实例还未初始化),并且提前曝光该 bean 实例的 ObjectFactory(提前曝光就是将 ObjectFactory 放到 singletonFactories 缓存
. 通过 ObjectFactory 我们可以拿到该 bean 实例的引⽤,如果出现循环引⽤,我们可以通过缓存中的 ObjectFactory 来拿到 bean 实例,从⽽避免出现循环引⽤导致的死循环
举个例⼦:
A 依赖了 B,B 也依赖了 A,那么依赖注⼊过程如下。
• 检查 A 是否在缓存中,发现不存在,进⾏实例化
• 通过构造函数创建 bean A,并通过 ObjectFactory 提前曝光 bean A
• A ⾛到属性填充阶段,发现依赖了 B,所以开始实例化 B。
• ⾸先检查 B 是否在缓存中,发现不存在,进⾏实例化 • 通过构造函数创建 bean B,并通过 ObjectFactory 曝光创建的 bean B
• B ⾛到属性填充阶段,发现依赖了 A,所以开始实例化 A。
• 检查 A 是否在缓存中,发现存在,拿到 A 对应的 ObjectFactory 来获得 bean A,并返回。 B 继续接下来的流程,直⾄创建完毕,然后返回 A 的创建流程,A 同样继续接下来的流程,直⾄创 建完毕。
• 这边通过缓存中的 ObjectFactory 拿到的 bean 实例虽然拿到的是 “不完整” 的 bean 实例,但是由 于是单例,所以后续初始化完成后,该 bean 实例的引⽤地址并不会变,所以最终我们看到的还是完 整 bean 实例
6.15、Spring 能解决构造函数循环依赖吗?
答案是不⾏的,对于使⽤构造函数注⼊产⽣的循环依赖,Spring 会直接抛异常。
为什么⽆法解决构造函数循环依赖?
上⾯解决逻辑的第⼀句话:“⾸先使⽤构造函数创建⼀个 “不完整” 的 bean 实例”,从这句话可以 看出,构造函数循环依赖是⽆法解决的,因为当构造函数出现循环依赖,我们连 “不完整” 的 bean 实例都构建不出来
6.16、Spring 三级缓存解决循环依赖
Spring 的三级缓存其实就是解决循环依赖时所⽤到的三个缓存。
singletonObjects:正常情况下的 bean 被创建完毕后会被放到该缓存,key:beanName,value: bean 实例。
singletonFactories:上⾯说的提前曝光的 ObjectFactory 就会被放到该缓存中,key:beanName, value:ObjectFactory。
earlySingletonObjects:该缓存⽤于存放 ObjectFactory 返回的 bean,也就是说对于⼀个 bean, ObjectFactory 只会被⽤⼀次,之后就通过 earlySingletonObjects 来获取,key:beanName, value:早期 bean 实例
6.17、@Resource 和 @Autowire 的区别?
1)@Resource 和 @Autowired 都可以⽤来装配 bean
2)@Autowired 默认按类型装配,默认情况下必须要求依赖对象必须存在,如果要允许null值,可以 设置它的required属性为false。
3)@Resource 如果指定了 name 或 type,则按指定的进⾏装配;如果都不指定,则优先按名称装 配,当找不到与名称匹配的 bean 时才按照类型进⾏装配。
6.18、@Autowire 怎么使⽤名称来注⼊?
@Componentpublic class Test {@Autowired@Qualifier("userService")private UserService userService;}
6.19、@PostConstruct 修饰的⽅法⾥⽤到了其他 bean 实例,会有问题 吗?
该题可以拆解成下⾯3个问题:
1)@PostConstruct 修饰的⽅法被调⽤的时间
2)bean 实例依赖的其他 bean 被注⼊的时间,也可理解为属性的依赖注⼊时间
3)步骤2的时间是否早于步骤1:如果是,则没有问题,如果不是,则有问题 解析:
1. PostConstruct 注解被封装在 CommonAnnotationBeanPostProcessor中,具体触发时间是在postProcessBeforeInitialization ⽅法,从 doCreateBean 维度看,则是在initializeBean ⽅法⾥,属于初始化 bean 阶段。1. 属性的依赖注⼊是在 populateBean ⽅法⾥,属于属性填充阶段。2. 属性填充阶段位于初始化之前,所以本题答案为没有问题
6.20、bean 的 init-method 属性指定的⽅法⾥⽤到了其他 bean 实例,会 有问题吗?
该题同上⾯这题类似,只是将 @PostConstruct 换成了 init-method 属性。
答案是不会有问题。同上⾯⼀样,init-method 属性指定的⽅法也是在 initializeBean ⽅法⾥被触 发,属于初始化 bean 阶段
6.21、要在 Spring IoC 容器构建完毕之后执⾏⼀些逻辑,怎么实现?
1)⽐较常⻅的⽅法是使⽤事件监听器,实现 ApplicationListener 接⼝,监听 ContextRefreshedEvent 事件。
2)还有⼀种⽐较少⻅的⽅法是实现 SmartLifecycle 接⼝,并且 isAutoStartup ⽅法返回 true,则会 在 finishRefresh() ⽅法中被触发。
两种⽅式都是在 finishRefresh 中被触发,SmartLifecycle在ApplicationListener之前
6.22、Spring 中的常⻅扩展点有哪些?
1)ApplicationContextInitializer initialize ⽅法,在 Spring 容器刷新前触发,也就是 refresh ⽅法前被触发。
2)BeanFactoryPostProcessor
postProcessBeanFactory ⽅法,在加载完 Bean 定义之后,创建 Bean 实例之前被触发,通常使⽤ 该扩展点来加载⼀些⾃⼰的 bean 定义。
3)BeanPostProcessor postProcessBeforeInitialization ⽅法,执⾏ bean 的初始化⽅法前被触发; postProcessAfterInitialization ⽅法,执⾏ bean 的初始化⽅法后被触发。
该注解被封装在 CommonAnnotationBeanPostProcessor 中,具体触发时间是在 postProcessBeforeInitialization ⽅法。
5)InitializingBean
afterPropertiesSet ⽅法,在 bean 的属性填充之后,初始化⽅法(init-method)之前被触发,该⽅ 法的作⽤基本等同于 init-method,主要⽤于执⾏初始化相关操作。
6)ApplicationListener,事件监听器
onApplicationEvent ⽅法,根据事件类型触发时间不同,通常使⽤的 ContextRefreshedEvent 触发 时间为上下⽂刷新完毕,通常⽤于 IoC 容器构建结束后处理⼀些⾃定义逻辑。
该注解被封装在 DestructionAwareBeanPostProcessor 中,具体触发时间是在 postProcessBeforeDestruction ⽅法,也就是在销毁对象之前触发。
8)DisposableBean
destroy ⽅法,在 bean 的销毁阶段被触发,该⽅法的作⽤基本等同于 destroy-method,主⽤⽤于执 ⾏销毁相关操作
6.23、Spring中如何让两个bean按顺序加载?
1)使⽤ @DependsOn、depends-on
2)让后加载的类依赖先加载的类
@Componentpublic class A {@Autowireprivate B b;}
3)使⽤扩展点提前加载,例如:BeanFactoryPostProcessor
@Componentpublic class TestBean implements BeanFactoryPostProcessor {@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactoryconfigurableListableBeanFactory) throws BeansException {// 加载beanbeanFactory.getBean("a");}}
6.24、mybatis
iBATIS 的着⼒点,则在于POJO 与SQL之间的映射关系。然后通过映射配置⽂件,将SQL所需的参 数,以及返回的结果字段映射到指定POJO。 相对Hibernate“O/R”⽽⾔,iBATIS 是⼀种“Sql Mapping”的ORM实现。
Mybatis优势
MyBatis可以进⾏更为细致的SQL优化,可以减少查询字段
MyBatis容易掌握,⽽Hibernate⻔槛较⾼。
解释⼀下MyBatis中命名空间(namespace)的作⽤。
答:在⼤型项⽬中,可能存在⼤量的SQL语句,这时候为每个SQL语句起⼀个唯⼀的标识(ID)就变 得并不容易了。为了解决这个问题,在MyBatis中,可以为每个映射⽂件起⼀个唯⼀的命名空间,这 样定义在这个映射⽂件中的每个SQL语句就成了定义在这个命名空间中的⼀个ID。 只要我们能够保证每个命名空间中这个ID是唯⼀的,即使在不同映射⽂件中的语句ID相同,也不会再 产⽣冲突了。
MyBatis中的动态SQL是什么意思?
答:对于⼀些复杂的查询,我们可能会指定多个查询条件,但是这些条件可能存在也可能不存在,例 如在58同城上⾯找房⼦,我们可能会指定⾯积、楼层和所在位置来查找房源,也可能会指定⾯积、价 格、⼾型和所在位置来查找房源,此时就需要根据⽤⼾指定的条件动态⽣成SQL语句。 如果不使⽤持久层框架我们可能需要⾃⼰拼装SQL语句,还好MyBatis提供了动态SQL的功能来解决 这个问题。MyBatis中⽤于实现动态SQL的元素主要有:
- if
- choose / when / otherwise
- trim
- where
- set
- foreach
Mybatis调优⽅案
MyBatis在Session⽅⾯和Hibernate的Session⽣命周期是⼀致的,同样需要合理的Session管理机 制。MyBatis同样具有⼆级缓存机制。 MyBatis可以进⾏详细的SQL优化设计。
MyBatis缓存
MyBatis 包含⼀个⾮常强⼤的查询缓存特性,它可以⾮常⽅便地配置和定制。MyBatis 3 中的缓存实现 的很多改进都已经实现了,使得它更加强⼤⽽且易于配置。
默认情况下是没有开启缓存的,除了局部的 session 缓存,可以增强变现⽽且处理循环 依赖也是必须 的。要开启⼆级缓存,你需要在你的 SQL 映射⽂件中添加⼀⾏:
字⾯上看就是这样。这个简单语句的效果如下:
映射语句⽂件中的所有 select 语句将会被缓存。
映射语句⽂件中的所有 insert,update 和 delete 语句会刷新缓存。
缓存会使⽤ Least Recently Used(LRU,最近最少使⽤的)算法来收回。
根据时间表(⽐如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
缓存会存储列表集合或对象(⽆论查询⽅法返回什么)的 1024 个引⽤。
缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,⽽ 且可以安全地被调⽤者 修改,⽽不⼲扰其他调⽤者或线程所做的潜在修改。
所有的这些属性都可以通过缓存元素的属性来修改。
⽐如:
这个更⾼级的配置创建了⼀个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引⽤,⽽且返 回的对象被认为是只读的,因此在不同线程中的调⽤者之间修改它们会 导致冲突。可⽤的收回策略有, 默认的是 LRU:
LRU ‒ 最近最少使⽤的:移除最⻓时间不被使⽤的对象。
FIFO ‒ 先进先出:按对象进⼊缓存的顺序来移除它们。
SOFT ‒ 软引⽤:移除基于垃圾回收器状态和软引⽤规则的对象。
WEAK ‒ 弱引⽤:更积极地移除基于垃圾收集器状态和弱引⽤规则的对象
flushInterval(刷新间隔)可以被设置为任意的正整数,⽽且它们代表⼀个合理的毫秒 形式的时间段。默 认情况是不设置,也就是没有刷新间隔,缓存仅仅调⽤语句时刷新。
size(引⽤数⽬)可以被设置为任意正整数,要记住你缓存的对象数⽬和你运⾏环境的 可⽤内存资源数 ⽬。默认值是1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调⽤者返回缓 存对象的相同实 例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存 会返回缓存对象的拷⻉ (通过序列化) 。这会慢⼀些,但是安全,因此默认是 false
6.25、使⽤ Mybatis 时,调⽤ DAO接⼝时是怎么调⽤到 SQL 的?
简单点说,当我们使⽤ Spring+MyBatis 时:
1、DAO接⼝会被加载到 Spring 容器中,通过动态代理来创建
2、XML中的SQL会被解析并保存到本地缓存中,key是SQL 的 namespace + id,value 是SQL的封装
3、当我们调⽤DAO接⼝时,会⾛到代理类中,通过接⼝的全路径名,从步骤2的缓存中找到对应的 SQL,然后执⾏并返回结果
6.26、springmvc的核⼼是什么,请求的流程是怎么处理的,控制反转怎 么实现的
springmvc是基于servlet的前端控制框架,核⼼是ioc和aop(基于spring实现) 核⼼架构的具体流程步骤如下:
1、⾸先⽤⼾发送请求⸺>DispatcherServlet,前端控制器收到请求后⾃⼰不进⾏处理,⽽是委托给 其他的解析器进⾏ 处理,作为统⼀访问点,进⾏全局的流程控制;
2、DispatcherServlet⸺>HandlerMapping, HandlerMapping 将会把请求映射为 HandlerExecutionChain 对象(包含⼀个Handler 处理器(⻚⾯控制器)对象、多个 HandlerInterceptor 拦截器)对象,通过这种策略模式,很容易添加新的映射策略;
3、DispatcherServlet⸺>HandlerAdapter,HandlerAdapter 将会把处理器包装为适配器,从⽽⽀ 持多种类型的处理器,即适配器设计模式的应⽤,从⽽很容易⽀持很多类型的处理器;
4、HandlerAdapter⸺>处理器功能处理⽅法的调⽤,HandlerAdapter 将会根据适配的结果调⽤真 正的处理器的功能处 理⽅法,完成功能处理;并返回⼀个ModelAndView 对象(包含模型数据、逻辑视图名);
5、ModelAndView的逻辑视图名⸺> ViewResolver, ViewResolver 将把逻辑视图名解析为具体的 View,通过这种策 略模式,很容易更换其他视图技术;
6、View⸺>渲染,View会根据传进来的Model模型数据进⾏渲染,此处的Model实际是⼀个Map数 据结构,因此 很容易⽀持其他视图技术;
7、返回控制权给DispatcherServlet,由DispatcherServlet返回响应给⽤⼾,到此⼀个流程结束 IOC控制反转的实现是基于spring的bean⼯⼚,通过获取要创建的类的class全限定名称,反射创建对象
6.27、Hibernate
Hibernate对数据库结构提供了较为完整的封装,Hibernate的O/R Mapping实现了POJO 和数据库表 之间的映射,以及SQL 的⾃动⽣成和执⾏。程序员往往只需定义好了POJO 到数据库表的映射关系, 即可通过Hibernate 提供的⽅法完成持久层操 作。程序员甚⾄不需要对SQL 的熟练掌握, Hibernate/OJB 会根据制定的存储逻辑,⾃动⽣成对应 的SQL 并调⽤JDBC 接⼝加以执⾏。
Hibernate的调优⽅案
制定合理的缓存策略;
尽量使⽤延迟加载特性;
采⽤合理的Session管理机制;
使⽤批量抓取,设定合理的批处理参数(batch_size);
进⾏合理的O/R映射设计
- SQL优化⽅⾯
Hibernate的查询会将表中的所有字段查询出来,这⼀点会有性能消耗。Hibernate也可以⾃⼰写SQL 来指定需要查询的字段,但这样就破坏了Hibernate开发的简洁性。⽽Mybatis的SQL是⼿动编写的, 所以可以按需求指定查询的字段。
Hibernate HQL语句的调优需要将SQL打印出来,⽽Hibernate的SQL被很多⼈嫌弃因为太丑了。 MyBatis的SQL是⾃⼰⼿动写的所以调整⽅便。但Hibernate具有⾃⼰的⽇志统计。Mybatis本⾝不带 ⽇志统计,使⽤Log4j进⾏⽇志记录。
- 抓取策略
Hibernate对实体关联对象的抓取有着良好的机制。对于每⼀个关联关系都可以详细地设置是否延迟 加载,并且提供关联抓取、查询抓取、⼦查询抓取、批量抓取四种模式。 它是详细配置和处理的。
- Hibernate缓存
Hibernate⼀级缓存是Session缓存,利⽤好⼀级缓存就需要对Session的⽣命周期进⾏管理好。建议 在⼀个Action操作中使⽤⼀个Session。⼀级缓存需要对Session进⾏严格管理。
Hibernate⼆级缓存是SessionFactory级的缓存。 SessionFactory的缓存分为内置缓存和外置缓存。 内置缓存中存放的是SessionFactory对象的⼀些集合属性包含的数据(映射元素据及预定SQL语句等), 对于应⽤程序来说,它是只读的。
外置缓存中存放的是数据库数据的副本,其作⽤和⼀级缓存类似.⼆级缓存除了以内存作为存储介质外, 还可以选⽤硬盘等外部存储设备。⼆级缓存称为进程级缓存或SessionFactory级缓存, 它可以被所有session共享,它的⽣命周期伴随着SessionFactory的⽣命周期存在和消亡。
- Hibernate中SessionFactory是线程安全的吗?
Session是线程安全的吗(两个线程能够共享同⼀个 Session吗)? 答:SessionFactory对应Hibernate的⼀个数据存储的概念,它是线程安全的,可以被多个线程并发 访问。SessionFactory⼀般只会在启动的时候构建。 对于应⽤程序,最好将SessionFactory通过单例模式进⾏封装以便于访问。Session是⼀个轻量级⾮ 线程安全的对象(线程间不能共享session),它表⽰与数据库进⾏交互的⼀个⼯作单元。 Session是由SessionFactory创建的,在任务完成之后它会被关闭。Session是持久层服务对外提供的 主要接⼝。Session会延迟获取数据库连接(也就是在需要的时候才会获取)。 为了避免创建太多的session,可以使⽤ThreadLocal将session和当前线程绑定在⼀起,这样可以让 同⼀个线程获得的总是同⼀个session。Hibernate 3中SessionFactory的getCurrentSession()⽅法就 可以做到。
- Hibernate中Session的load和get⽅法的区别是什么?
答:主要有以下三项区别: ① 如果没有找到符合条件的记录,get⽅法返回null,load⽅法抛出异常。 ② get⽅法直接返回实体类对象,load⽅法返回实体类对象的代理。 ③ 在Hibernate 3之前,get⽅法只在⼀级缓存中进⾏数据查找,如果没有找到对应的数据则越过⼆级 缓存,直接发出SQL语句完成数据读取;load⽅法则可以从⼆级缓存中获取数据;从Hibernate 3开 始,get⽅法不再是对⼆级缓存只写不读,它也是可以访问⼆级缓存的。 说明:对于load()⽅法Hibernate认为该数据在数据库中⼀定存在可以放⼼的使⽤代理来实现延迟加 载,如果没有数据就抛出异常,⽽通过get()⽅法获取的数据可以不存在
Session的save()、update()、merge()、lock()、saveOrUpdate()和persist()⽅法分别是做什么 的?有什么区别?
答:Hibernate的对象有三种状态:瞬时态(transient)、持久态(persistent)和游离态 (detached),瞬时态的实例可以通过调⽤save()、persist()或者saveOrUpdate()⽅法变成持久态;
游离态的实例可以通过调⽤ update()、saveOrUpdate()、lock()或者replicate()变成持久态。save() 和persist()将会引发SQL的INSERT语句,⽽update()或merge()会引发UPDATE语句。
save()和update()的区别在于⼀个是将瞬时态对象变成持久态,⼀个是将游离态对象变为持久态。 merge()⽅法可以完成save()和update()⽅法的功能,它的意图是将新的状态合并到已有的持久化对 象上或创建新的持久化对象。
对于persist()⽅法,按照官⽅⽂档的说明:
① persist()⽅法把⼀个瞬时态的实例持久化,但是并不保证标识符被⽴刻填⼊到持久化实例中,标识 符的填⼊可能被推迟到flush的时间;
② persist()⽅法保证当它在⼀个事务外部被调⽤的时候并不触 发⼀个INSERT语句,当需要封装⼀个⻓会话流程的时候,persist()⽅法是很有必要的;
③ save()⽅法不保证第②条,它要返回标识符,所以它会⽴即执⾏INSERT语句,不管是在事务内部 还是外部。⾄于lock()⽅法和update()⽅法的区别,update()⽅法是把⼀个已经更改过的脱管状态的 对象变成持久状态;lock()⽅法是把⼀个没有更改过的脱管状态的对象变成持久状态。
- 阐述Session加载实体对象的过程?
答:Session加载实体对象的步骤是:
① Session在调⽤数据库查询功能之前,⾸先会在⼀级缓存中通过实体类型和主键进⾏查找,如果⼀ 级缓存查找命中且数据状态合法,则直接返回;
② 如果⼀级缓存没有命中,接下来Session会在当前NonExists记录(相当于⼀个查询⿊名单,如果 出现重复的⽆效查询可以迅速做出判断,从⽽提升性能)中进⾏查找,如果NonExists中存在同样的 查询条件,则返回null;
③ 如果⼀级缓存查询失败则查询⼆级缓存,如果⼆级缓存命中则直接返回;
④ 如果之前的查询都未命中,则发出SQL语句,如果查询未发现对应记录则将此次查询添加到 Session的NonExists中加以记录,并返回null;
⑤ 根据映射配置和SQL语句得到ResultSet,并创建对应的实体对象;
⑥ 将对象纳⼊Session(⼀级缓存)的管理;
⑦ 如果有对应的拦截器,则执⾏拦截器的onLoad⽅法;
⑧ 如果开启并设置了要使⽤⼆级缓存,则将数据对象纳⼊⼆级缓存;
⑨ 返回数据对象。
Query接⼝的list⽅法和iterate⽅法有什么区别?
答:
① list()⽅法⽆法利⽤⼀级缓存和⼆级缓存(对缓存只写不读),它只能在开启查询缓存的前提下使⽤ 查询缓存;iterate()⽅法可以充分利⽤缓存,如果⽬标数据只读或者读取频繁,使⽤iterate()⽅法可 以减少性能开销。
② list()⽅法不会引起N+1查询问题,⽽iterate()⽅法可能引起N+1查询问题
- 如何理解Hibernate的延迟加载机制?在实际应⽤中,延迟加载与Session关闭的⽭盾是如何处理 的?
答:延迟加载就是并不是在读取的时候就把数据加载进来,⽽是等到使⽤时再加载。Hibernate使⽤ 了虚拟代理机制实现延迟加载,我们使⽤Session的load()⽅法加载数据或者⼀对多关联映射在使⽤延 迟加载的情况下从⼀的⼀⽅加载多的⼀⽅,
得到的都是虚拟代理,简单的说返回给⽤⼾的并不是实体本⾝,⽽是实体对象的代理。代理对象在⽤ ⼾调⽤getter⽅法时才会去数据库加载数据。但加载数据就需要数据库连接。⽽当我们把会话关闭 时,数据库连接就同时关闭了。
- 延迟加载与session关闭的⽭盾⼀般可以这样处理
① 关闭延迟加载特性。这种⽅式操作起来⽐较简单,因为Hibernate的延迟加载特性是可以通过映射 ⽂件或者注解进⾏配置的,但这种解决⽅案存在明显的缺陷。 ⾸先,出现”no session or session was closed”通常说明系统中已经存在主外键关联,如果去掉延迟 加载的话,每次查询的开销都会变得很⼤。
② 在session关闭之前先获取需要查询的数据,可以使⽤⼯具⽅法Hibernate.isInitialized()判断对象 是否被加载,如果没有被加载则可以使⽤Hibernate.initialize()⽅法加载对象。
③ 使⽤拦截器或过滤器延⻓Session的⽣命周期直到视图获得数据。Spring整合Hibernate提供的 OpenSessionInViewFilter和OpenSessionInViewInterceptor就是这种做法。
- 谈⼀下你对继承映射的理解。
答:继承关系的映射策略有三种:
① 每个继承结构⼀张表(table per class hierarchy),不管多少个⼦类都⽤⼀张表。
② 每个⼦类⼀张表(table per subclass),公共信息放⼀张表,特有信息放单独的表。
③ 每个具体类⼀张表(table per concrete class),有多少个⼦类就有多少张表。 第⼀种⽅式属于单表策略,其优点在于查询⼦类对象的时候⽆需表连接,查询速度快,适合多态查 询;缺点是可能导致表很⼤。后两种⽅式属于多表策略,其优点在于数据存储紧凑,其缺点是需要进 ⾏连接查询,不适合多态查询。
- 简述Hibernate常⻅优化策略。
答:这个问题应当挑⾃⼰使⽤过的优化策略回答,常⽤的有
① 制定合理的缓存策略(⼆级缓存、查询缓存)。
② 采⽤合理的Session管理机制。
③ 尽量使⽤延迟加载特性。
④ 设定合理的批处理参数。
⑤ 如果可以,选⽤UUID作为主键⽣成器。
⑥ 如果可以,选⽤基于版本号的乐观锁替代悲观锁。
⑦ 在开发过程中, 开启hibernate.show_sql选项查看⽣成的SQL,从⽽了解底层的状况;开发完成后 关闭此选项。
⑧ 考虑数据库本⾝的优化,合理的索引、恰当的数据分区策略等都会对持久层的性能带来可观的提 升,但这些需要专业的DBA(数据库管理员)提供⽀持。
- 谈⼀谈Hibernate的⼀级缓存、⼆级缓存和查询缓存。
答:Hibernate的Session提供了⼀级缓存的功能,默认总是有效的,当应⽤程序保存持久化实体、修 改持久化实体时,Session并不会⽴即把这种改变提交到数据库,⽽是缓存在当前的Session中,除⾮ 显⽰调⽤了Session的flush()⽅法或通过close()⽅法关闭Session。通过⼀级缓存,可以减少程序与数 据库的交互,从⽽提⾼数据库访问性能。
SessionFactory级别的⼆级缓存是全局性的,所有的Session可以共享这个⼆级缓存。不过⼆级缓存 默认是关闭的,需要显⽰开启并指定需要使⽤哪种⼆级缓存实现类(可以使⽤第三⽅提供的实现)。 ⼀旦开启了⼆级缓存并设置了需要使⽤⼆级缓存的实体类,SessionFactory就会缓存访问过的该实体 类的每个对象,除⾮缓存的数据超出了指定的缓存空间。
⼀级缓存和⼆级缓存都是对整个实体进⾏缓存,不会缓存普通属性,如果希望对普通属性进⾏缓存, 可以使⽤查询缓存。查询缓存是将HQL或SQL语句以及它们的查询结果作为键值对进⾏缓存,对于同 样的查询可以直接从缓存中获取数据。查询缓存默认也是关闭的,需要显⽰开启。
- Hibernate中DetachedCriteria类是做什么的?
答:DetachedCriteria和Criteria的⽤法基本上是⼀致的,但Criteria是由Session的createCriteria() ⽅法创建的,也就意味着离开创建它的Session,Criteria就⽆法使⽤了。 DetachedCriteria不需要Session就可以创建(使⽤DetachedCriteria.forClass()⽅法创建),所以通 常也称其为离线的Criteria,在需要进⾏查询操作的时候再和Session绑定(调⽤其 getExecutableCriteria(Session)⽅法),这也就意味着⼀个DetachedCriteria可以在需要的时候和不 同的Session进⾏绑定。
- @OneToMany注解的mappedBy属性有什么作⽤
答:@OneToMany⽤来配置⼀对多关联映射,但通常情况下,⼀对多关联映射都由多的⼀⽅来维护 关联关系,例如学⽣和班级,应该在学⽣类中添加班级属性来维持学⽣和班级的关联关系(在数据库 中是由学⽣表中的外键班级编号来维护学⽣表和班级表的多对⼀关系)
如果要使⽤双向关联,在班级类中添加⼀个容器属性来存放学⽣,并使⽤@OneToMany注解进⾏映 射,此时mappedBy属性就⾮常重要。如果使⽤XML进⾏配置,可以⽤标签的inverse=”true”设 置来达到同样的效果。
第七章:Redis
7.1、Redis 是单线程还是多线程?.
这个问题应该已经看到过⽆数次了,最近 redis 6 出来之后⼜被翻出来了。
redis 5.0 之前,redis 是完全单线程的。 redis 5.0 时,redis 引⼊了多线程,但是额外的线程只是⽤于后台处理,例如:删除对象,核⼼流程 还是完全单线程的。这也是为什么有些⼈说 5.0 是单线程的,因为他们指的是核⼼流程是单线程的。
这边的核⼼流程指的是 redis 正常处理客⼾端请求的流程,通常包括:接收命令、解析命令、执⾏命 令、返回结果等。⽽在最近,redis 7.0 版本⼜⼀次引⼊了多线程概念,与 5.0 不同的是,这次的多线 程会涉及到上述的核⼼流程。redis 7.0 中,多线程主要⽤于⽹络 I/O 阶段,也就是接收命令和写回结 果阶段,⽽在执⾏命令阶段,还是由单线程串⾏执⾏。由于执⾏时还是串⾏,因此⽆需考虑并发安全 问题。值得注意的时,redis 中的多线程组不会同时存在“读”和“写”,这个多线程组只会同 时“读”或者同时“写”。redis 7.0 加⼊多线程 I/O 之后,处理命令的核⼼流程如下:
1、当有读事件到来时,主线程将该客⼾端连接放到全局等待读队列
2、读取数据:
1)主线程将等待读队列的客⼾端连接通过轮询调度算法分配给 I/O 线程处理;2)同时主线程也会⾃⼰负责处理⼀个客⼾端连接的读事件;3)当主线程处理完该连接的读事件后,会⾃旋等待所有 I/O 线程处 理完毕
3、命令执⾏:主线程按照事件被加⼊全局等待读队列的顺序(这边保证了执⾏顺序是正确的),串 ⾏执⾏客⼾端命令,然后将客⼾端连接放到全局等待写队列
4、写回结果:跟等待读队列处理类似,主线程将等待写队列的客⼾端连接使⽤轮询调度算法分配给 I/O 线程处理,同时⾃⼰也会处理⼀个,当主线程处理完毕后,会⾃旋等待所有 I/O 线程处理完毕, 最后清空队列。
⼤致流程图如下:
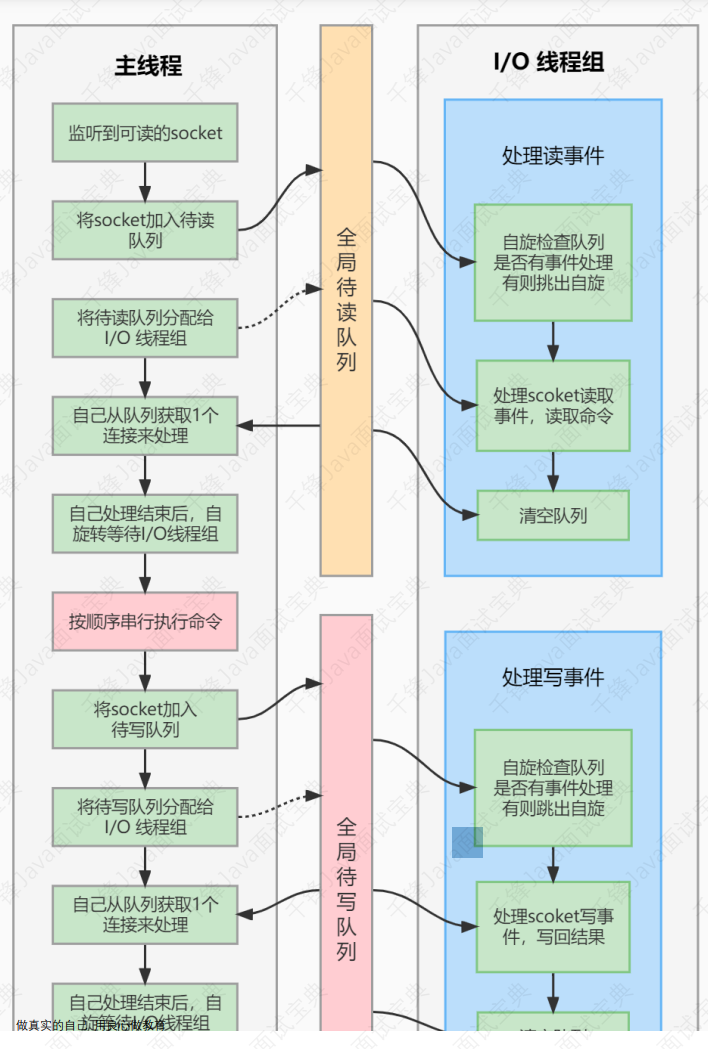

7.2、为什么 Redis 是单线程?
在 redis 7.0 之前,redis 的核⼼操作是单线程的。
因为 redis 是完全基于内存操作的,通常情况下CPU不会是redis的瓶颈,redis 的瓶颈最有可能是机 器内存的⼤⼩或者⽹络带宽。
既然CPU不会成为瓶颈,那就顺理成章地采⽤单线程的⽅案了,因为如果使⽤多线程的话会更复杂, 同时需要引⼊上下⽂切换、加锁等等,会带来额外的性能消耗。
⽽随着近些年互联⽹的不断发展,⼤家对于缓存的性能要求也越来越⾼了,因此 redis 也开始在逐渐 往多线程⽅向发展。
最近的 7.0 版本就对核⼼流程引⼊了多线程,主要⽤于解决 redis 在⽹络 I/O 上的性能瓶颈。⽽对于 核⼼的命令执⾏阶段,⽬前还是单线程的
7.3、Redis 为什么使⽤单进程、单线程也很快?
主要有以下⼏点:
1)基于内存的操作
2)使⽤了 I/O 多路复⽤模型,select、epoll 等,基于 reactor 模式开发了⾃⼰的⽹络事件处理器
3)单线程可以避免不必要的上下⽂切换和竞争条件,减少了这⽅⾯的性能消耗。
4)以上这三点是 redis 性能⾼的主要原因,其他的还有⼀些⼩优化,例如:对数据结构进⾏了优化, 简单动态字符串、压缩列表等
7.4、Redis 在项⽬中的使⽤场景
缓存(核⼼)、分布式锁(set + lua 脚本)、排⾏榜(zset)、计数(incrby)、消息队列 (stream)、地理位置(geo)、访客统计(hyperloglog)等
7.5、Redis 常⻅的数据结构
基础的5种:
• String:字符串,最基础的数据类型。
• List:列表。
• Hash:哈希对象。
• Set:集合。
• Sorted Set:有序集合,Set 的基础上加了个分值。
⾼级的4种:
HyperLogLog:通常⽤于基数统计。使⽤少量固定⼤⼩的内存,来统计集合中唯⼀元素的数量。 统计结果不是精确值,⽽是⼀个带有0.81%标准差(standard error)的近似值。所以,
HyperLogLog适⽤于⼀些对于统计结果精确度要求不是特别⾼的场景,例如⽹站的UV统计。
• Geo:redis 2.2 版本的新特性。可以将⽤⼾给定的地理位置信息储存起来, 并对这些信息进⾏操 作:获取2个位置的距离、根据给定地理位置坐标获取指定范围内的地理位置集合。
• • Bitmap:位图。
Stream:主要⽤于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久 化和主备复制功能,可以让任何客⼾端访问任何时刻的数据,并且能记住每⼀个客⼾端的访问位 置,还能保证消息不丢失
7.6、Sorted Set底层数据结构
Sorted Set(有序集合)当前有两种编码:ziplist、skiplist ziplist:使⽤压缩列表实现,当保存的元素⻓度都⼩于64字节,同时数量⼩于128时,使⽤该编码⽅ 式,否则会使⽤ skiplist。这两个参数可以通过 zset-max-ziplist-entries、zset-max-ziplist-value 来 ⾃定义修改

skiplist:zset实现,⼀个zset同时包含⼀个字典(dict)和⼀个跳跃表(zskiplist)
7.7、Sorted Set 为什么同时使⽤字典和跳跃表?
主要是为了提升性能。
单独使⽤字典:在执⾏范围型操作,⽐如 zrank、zrange,字典需要进⾏排序,⾄少需要 O(NlogN) 的时间复杂度及额外 O(N) 的内存空间。
单独使⽤跳跃表:根据成员查找分值操作的复杂度从 O(1) 上升为 O(logN)
7.8、Sorted Set 为什么使⽤跳跃表,⽽不是红⿊树?
主要有以下⼏个原因:
1)跳表的性能和红⿊树差不多。
2)跳表更容易实现和调试
7.9、Hash 对象底层结构
Hash 对象当前有两种编码:ziplist、hashtable ziplist:
使⽤压缩列表实现,每当有新的键值对要加⼊到哈希对象时,程序会先将保存了键的节点推 ⼊到压缩列表的表尾,然后再将保存了值的节点推⼊到压缩列表表尾。 因此:
1)保存了同⼀键值对的两个节点总是紧挨在⼀起,保存键的节点在前,保存值的节点在后;
2)先添加到哈希对象中的键值对会被放在压缩列表的表头⽅向,⽽后来添加的会被放在表尾⽅向

hashtable:使⽤字典作为底层实现,哈希对象中的每个键值对都使⽤⼀个字典键值来保存,跟 java 中的 HashMap 类似
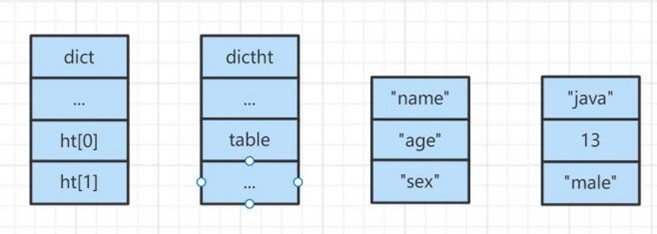
7.10、Hash 对象的扩容流程
hash 对象在扩容时使⽤了⼀种叫“渐进式 rehash”的⽅式,步骤如下:
1)计算新表 size、掩码,为新表 ht[1] 分配空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
2)将 rehash 索引计数器变量 rehashidx 的值设置为0,表⽰ rehash 正式开始。
3)在 rehash 进⾏期间,每次对字典执⾏添加、删除、査找、更新操作时,程序除了执⾏指定的操作 以外,还会触发额外的 rehash 操作,在源码中的 _dictRehashStep ⽅法。
_dictRehashStep:从名字也可以看出来,⼤意是 rehash ⼀步,也就是 rehash ⼀个索引位置。 该⽅法会从 ht[0] 表的 rehashidx 索引位置上开始向后查找,找到第⼀个不为空的索引位置,将该索 引位置的所有节点 rehash 到 ht[1],当本次 rehash ⼯作完成之后,将 ht[0] 索引位置为 rehashidx 的节点清空,同时将 rehashidx 属性的值加⼀。
4)将 rehash 分摊到每个操作上确实是⾮常妙的⽅式,但是万⼀此时服务器⽐较空闲,⼀直没有什么 操作,难道 redis 要⼀直持有两个哈希表吗? 答案当然不是的。我们知道,redis 除了⽂件事件外,还有时间事件,redis 会定期触发时间事件,这 些时间事件⽤于执⾏⼀些后台操作,其中就包含 rehash 操作:当 redis 发现有字典正在进⾏ rehash 操作时,会花费1毫秒的时间,⼀起帮忙进⾏ rehash。
5)随着操作的不断执⾏,最终在某个时间点上,ht[0] 的所有键值对都会被 rehash ⾄ ht[1],此时 rehash 流程完成,会执⾏最后的清理⼯作:释放 ht[0] 的空间、将 ht[0] 指向 ht[1]、重置 ht[1]、重 置 rehashidx 的值为 -1
7.11、渐进式 rehash 的优点
渐进式 rehash 的好处在于它采取分⽽治之的⽅式,将 rehash 键值对所需的计算⼯作均摊到对字典的 每个添加、删除、查找和更新操作上,从⽽避免了集中式 rehash ⽽带来的庞⼤计算量。
在进⾏渐进式 rehash 的过程中,字典会同时使⽤ ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进⾏期间,字典的删除、査找、更新等操作会在两个哈希表上进⾏。例如,要在字典⾥⾯査找⼀个键 的话,程序会先在 ht[0] ⾥⾯进⾏査找,如果没找到的话,就会继续到 ht[1] ⾥⾯进⾏査找,诸如此 类。
另外,在渐进式 rehash 执⾏期间,新增的键值对会被直接保存到 ht[1], ht[0] 不再进⾏任何添加操 作,这样就保证了 ht[0] 包含的键值对数量会只减不增,并随着 rehash 操作的执⾏⽽最终变成空表
7.12、rehash 流程在数据量⼤的时候会有什么问题吗(Hash 对象的扩容 流程在数据量⼤的时候会有什么问题吗)
1)扩容期开始时,会先给 ht[1] 申请空间,所以在整个扩容期间,会同时存在 ht[0] 和 ht[1],会占 ⽤额外的空间。
2)扩容期间同时存在 ht[0] 和 ht[1],查找、删除、更新等操作有概率需要操作两张表,耗时会增 加。
3)redis 在内存使⽤接近 maxmemory 并且有设置驱逐策略的情况下,出现 rehash 会使得内存占⽤ 超过 maxmemory,触发驱逐淘汰操作,导致 master/slave 均有有⼤量的 key 被驱逐淘汰,从⽽出 现 master/slave 主从不⼀致
7.13、Redis 的⽹络事件处理器(Reactor 模式)
redis 基于 reactor 模式开发了⾃⼰的⽹络事件处理器,由4个部分组成:套接字、I/O 多路复⽤程 序、⽂件事件分派器(dispatcher)、以及事件处理器
套接字:socket 连接,也就是客⼾端连接。当⼀个套接字准备好执⾏连接、写⼊、读取、关闭等操作 时, 就会产⽣⼀个相应的⽂件事件。因为⼀个服务器通常会连接多个套接字, 所以多个⽂件事件有 可能会并发地出现。
I/O 多路复⽤程序:提供 select、epoll、evport、kqueue 的实现,会根据当前系统⾃动选择最佳的 ⽅式。负责监听多个套接字,当套接字产⽣事件时,会向⽂件事件分派器传送那些产⽣了事件的套接 字。当多个⽂件事件并发出现时, I/O 多路复⽤程序会将所有产⽣事件的套接字都放到⼀个队列⾥ ⾯,然后通过这个队列,以有序、同步、每次⼀个套接字的⽅式向⽂件事件分派器传送套接字:当上 ⼀个套接字产⽣的事件被处理完毕之后,才会继续传送下⼀个套接字
⽂件事件分派器:接收 I/O 多路复⽤程序传来的套接字, 并根据套接字产⽣的事件的类型, 调⽤相应 的事件处理器。
事件处理器:事件处理器就是⼀个个函数, 定义了某个事件发⽣时, 服务器应该执⾏的动作。例 如:建⽴连接、命令查询、命令写⼊、连接关闭等等
7.14、Redis 删除过期键的策略(缓存失效策略、数据过期策略)
定时删除:在设置键的过期时间的同时,创建⼀个定时器,让定时器在键的过期时间来临时,⽴即执 ⾏对键的删除操作。对内存最友好,对 CPU 时间最不友好。
惰性删除:放任键过期不管,但是每次获取键时,都检査键是否过期,如果过期的话,就删除该键; 如果没有过期,就返回该键。对 CPU 时间最优化,对内存最不友好。
定期删除:每隔⼀段时间,默认100ms,程序就对数据库进⾏⼀次检査,删除⾥⾯的过期键。⾄ 于要 删除多少过期键,以及要检査多少个数据库,则由算法决定。前两种策略的折中,对 CPU 时间和内 存的友好程度较平衡。
Redis 使⽤惰性删除和定期删除
7.15、Redis 的内存淘汰(驱逐)策略
当 redis 的内存空间(maxmemory 参数配置)已经⽤满时,redis 将根据配置的驱逐策略 (maxmemory-policy 参数配置),进⾏相应的动作。
⽹上很多资料都是写 6 种,但是其实当前 redis 的淘汰策略已经有 8 种了,多余的两种是 Redis 5.0 新增的,基于 LFU(Least Frequently Used)算法实现的。
• noeviction:默认策略,不淘汰任何 key,直接返回错误 • allkeys-lru:在所有的 key 中,使⽤ LRU 算法淘汰部分 key
• allkeys-lfu:在所有的 key 中,使⽤ LFU 算法淘汰部分 key,该算法于 Redis 5.0 新增
• allkeys-random:在所有的 key 中,随机淘汰部分 key
• volatile-lru:在设置了过期时间的 key 中,使⽤ LRU 算法淘汰部分 key
• volatile-lfu:在设置了过期时间的 key 中,使⽤ LFU 算法淘汰部分 key,该算法于 Redis 5.0 新增
• volatile-random:在设置了过期时间的 key 中,随机淘汰部分 key
• volatile-ttl:在设置了过期时间的 key 中,挑选 TTL(time to live,剩余时间)短的 key 淘汰
7.16、Redis 的 LRU 算法怎么实现的?
Redis 在 redisObject 结构体中定义了⼀个⻓度 24 bit 的 unsigned 类型的字段(unsigned lru:LRU_BITS),在 LRU 算法中⽤来存储对象最后⼀次被命令程序访问的时间。
具体的 LRU 算法经历了两个版本。
版本1:随机选取 N 个淘汰法。
最初 Redis 是这样实现的:随机选 N(默认5) 个 key,把空闲时间(idle time)最⼤的那个 key 移 除。这边的 N 可通过 maxmemory-samples 配置项修改。
就是这么简单,简单得让⼈不敢相信了,⽽且⼗分有效。
但是这个算法有个明显的缺点:每次都是随机从 N 个⾥选择 1 个,并没有利⽤前⼀轮的历史信息。其 实在上⼀轮移除 key 的过程中,其实是知道了 N 个 key 的 idle time 的情况的,那在下⼀轮移除 key 时,其实可以利⽤上⼀轮的这些信息。这也是 Redis 2.0 的优化思想。
版本2:Redis 2.0 对 LRU 算法进⾏改进,引⼊了缓冲池(pool,默认16)的概念。
当每⼀轮移除 key 时,拿到了 N(默认5)个 key 的 idle time,遍历处理这 N 个 key,如果 key 的 idle time ⽐ pool ⾥⾯的 key 的 idle time 还要⼤,就把它添加到 pool ⾥⾯去。
当 pool 放满之后,每次如果有新的 key 需要放⼊,需要将 pool 中 idle time 最⼩的⼀个 key 移除。 这样相当于 pool ⾥⾯始终维护着还未被淘汰的 idle time 最⼤的 16 个 key。
当我们每轮要淘汰的时候,直接从 pool ⾥⾯取出 idle time 最⼤的 key(只取1个),将之淘汰掉。
整个流程相当于随机取 5 个 key 放⼊ pool,然后淘汰 pool 中空闲时间最⼤的 key,然后再随机取 5 个 key放⼊ pool,继续淘汰 pool 中空闲时间最⼤的 key,⼀直持续下去。
在进⼊淘汰前会计算出需要释放的内存⼤⼩,然后就⼀直循环上述流程,直⾄释放⾜够的内存
7.17、Redis 的持久化机制有哪⼏种,各⾃的实现原理和优缺点?
Redis 的持久化机制有:RDB、AOF、混合持久化(RDB+AOF,Redis 5.0引⼊)。
1)RDB
描述:类似于快照。在某个时间点,将 Redis 在内存中的数据库状态(数据库的键值对等信息)保存 到磁盘⾥⾯。RDB 持久化功能⽣成的 RDB ⽂件是经过压缩的⼆进制⽂件。
命令:有两个 Redis 命令可以⽤于⽣成 RDB ⽂件,⼀个是 SAVE,另⼀个是 BGSAVE。
开启:使⽤ save point 配置,满⾜ save point 条件后会触发 BGSAVE 来存储⼀次快照
save point 格式:save ,含义是 Redis 如果在 seconds 秒内数据发 ⽣了 changes 次改变,就保存快照⽂件。例如 Redis 默认就配置了以下3个:
save 900 1 #900秒内有1个key发⽣了变化,则触发保存RDB⽂件save 300 10 #300秒内有10个key发⽣了变化,则触发保存RDB⽂件save 60 10000 #60秒内有10000个key发⽣了变化,则触发保存RDB⽂件
关闭:1)注释掉所有save point 配置可以关闭 RDB 持久化。2)在所有 save point 配置后增加: save “”,该配置可以删除所有之前配置的 save point
save ""
SAVE:⽣成 RDB 快照⽂件,但是会阻塞主进程,服务器将⽆法处理客⼾端发来的命令请求,所以通 常不会直接使⽤该命令。
BGSAVE:fork ⼦进程来⽣成 RDB 快照⽂件,阻塞只会发⽣在 fork ⼦进程的时候,之后主进程可以 正常处理请求,详细过程如下图:
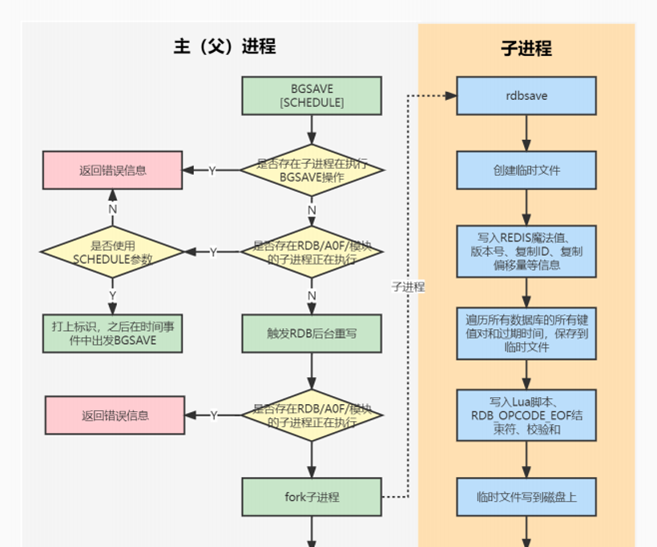
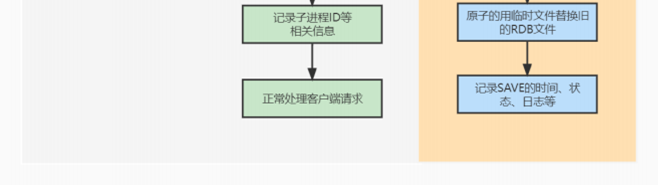
fork:在 Linux 系统中,调⽤ fork() 时,会创建出⼀个新进程,称为⼦进程,⼦进程会拷⻉⽗进程的 page table。如果进程占⽤的内存越⼤,进程的 page table 也会越⼤,那么 fork 也会占⽤更多的时 间。如果 Redis 占⽤的内存很⼤,那么在 fork ⼦进程时,则会出现明显的停顿现象。
RDB 的优点
1)RDB ⽂件是是经过压缩的⼆进制⽂件,占⽤空间很⼩,它保存了 Redis 某个时间点的数据集,很 适合⽤于做备份。 ⽐如说,你可以在最近的 24 ⼩时内,每⼩时备份⼀次 RDB ⽂件,并且在每个⽉的 每⼀天,也备份⼀个 RDB ⽂件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版 本。
2)RDB ⾮常适⽤于灾难恢复(disaster recovery):它只有⼀个⽂件,并且内容都⾮常紧凑,可以 (在加密后)将它传送到别的数据中⼼
3)RDB 可以最⼤化 redis 的性能。⽗进程在保存 RDB ⽂件时唯⼀要做的就是 fork 出⼀个⼦进程,然 后这个⼦进程就会处理接下来的所有保存⼯作,⽗进程⽆须执⾏任何磁盘 I/O 操作。
4)RDB 在恢复⼤数据集时的速度⽐ AOF 的恢复速度要快。
RDB 的缺点
1)RDB 在服务器故障时容易造成数据的丢失。RDB 允许我们通过修改 save point 配置来控制持久化 的频率。但是,因为 RDB ⽂件需要保存整个数据集的状态, 所以它是⼀个⽐较重的操作,如果频率 太频繁,可能会对 Redis 性能产⽣影响。所以通常可能设置⾄少5分钟才保存⼀次快照,这时如果 Redis 出现宕机等情况,则意味着最多可能丢失5分钟数据。
2)RDB 保存时使⽤ fork ⼦进程进⾏数据的持久化,如果数据⽐较⼤的话,fork 可能会⾮常耗时,造 成 Redis 停⽌处理服务N毫秒。如果数据集很⼤且 CPU ⽐较繁忙的时候,停⽌服务的时间甚⾄会到⼀ 秒。
3)Linux fork ⼦进程采⽤的是 copy-on-write 的⽅式。在 Redis 执⾏ RDB 持久化期间,如果 client 写⼊数据很频繁,那么将增加 Redis 占⽤的内存,最坏情况下,内存的占⽤将达到原先的2倍。刚 fork 时,主进程和⼦进程共享内存,但是随着主进程需要处理写操作,主进程需要将修改的⻚⾯拷⻉ ⼀份出来,然后进⾏修改。极端情况下,如果所有的⻚⾯都被修改,则此时的内存占⽤是原先的2 倍。
2)AOF
描述:保存 Redis 服务器所执⾏的所有写操作命令来记录数据库状态,并在服务器启动时,通过重新 执⾏这些命令来还原数据集。
开启:AOF 持久化默认是关闭的,可以通过配置:appendonly yes 开启。
关闭:使⽤配置 appendonly no 可以关闭 AOF 持久化。
AOF 持久化功能的实现可以分为三个步骤:命令追加、⽂件写⼊、⽂件同步。
命令追加:当 AOF 持久化功能打开时,服务器在执⾏完⼀个写命令之后,会将被执⾏的写命令追加 到服务器状态的 aof 缓冲区(aof_buf)的末尾。
⽂件写⼊与⽂件同步:可能有⼈不明⽩为什么将 aof_buf 的内容写到磁盘上需要两步操作,这边简单 解释⼀下。
Linux 操作系统中为了提升性能,使⽤了⻚缓存(page cache)。当我们将 aof_buf 的内容写到磁盘 上时,此时数据并没有真正的落盘,⽽是在 page cache 中,为了将 page cache 中的数据真正落 盘,需要执⾏ fsync / fdatasync 命令来强制刷盘。这边的⽂件同步做的就是刷盘操作,或者叫⽂件刷 盘可能更容易理解⼀些。
serverCron 时间事件中会触发 flushAppendOnlyFile 函数,该函数会根据服务器配置的 appendfsync 参数值,来决定是否将 aof_buf 缓冲区的内容写⼊和保存到 AOF ⽂件。
appendfsync 参数有三个选项:
always:每处理⼀个命令都将 aof_buf 缓冲区中的所有内容写⼊并同步到AOF ⽂件,即每个命令 都刷盘
everysec:将 aof_buf 缓冲区中的所有内容写⼊到 AOF ⽂件,如果上次同步 AOF ⽂件的时间距离 现在超过⼀秒钟, 那么再次对 AOF ⽂件进⾏同步, 并且这个同步操作是异步的,由⼀个后台线程 专⻔负责执⾏,即每秒刷盘1次。
no:将 aof_buf 缓冲区中的所有内容写⼊到 AOF ⽂件, 但并不对 AOF ⽂件进⾏同步, 何时同步 由操作系统来决定。即不执⾏刷盘,让操作系统⾃⼰执⾏刷盘。
AOF 的优点
AOF ⽐ RDB可靠。你可以设置不同的 fsync 策略:no、everysec 和 always。默认是 everysec, 在这种配置下,redis 仍然可以保持良好的性能,并且就算发⽣故障停机,也最多只会丢失⼀秒钟 的数据。
AOF⽂件是⼀个纯追加的⽇志⽂件。即使⽇志因为某些原因⽽包含了未写⼊完整的命令(⽐如写⼊ 时磁盘已满,写⼊中途停机等等), 我们也可以使⽤ redis-check-aof ⼯具也可以轻易地修复这种 问题。
当 AOF⽂件太⼤时,Redis 会⾃动在后台进⾏重写:重写后的新 AOF ⽂件包含了恢复当前数据集 所需的最⼩命令集合。整个重写是绝对安全,因为重写是在⼀个新的⽂件上进⾏,同时 Redis 会 继续往旧的⽂件追加数据。当新⽂件重写完毕,Redis 会把新旧⽂件进⾏切换,然后开始把数据写 到新⽂件上。
AOF ⽂件有序地保存了对数据库执⾏的所有写⼊操作以 Redis 协议的格式保存, 因此 AOF ⽂件的 内容⾮常容易被⼈读懂, 对⽂件进⾏分析(parse)也很轻松。如果你不⼩⼼执⾏了 FLUSHALL 命令把所有数据刷掉了,但只要 AOF ⽂件没有被重写,那么只要停⽌服务器, 移除 AOF ⽂件末尾 的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执⾏之前的状态。
AOF 的缺点
对于相同的数据集,AOF ⽂件的⼤⼩⼀般会⽐ RDB ⽂件⼤。
根据所使⽤的 fsync 策略,AOF 的速度可能会⽐ RDB 慢。通常 fsync 设置为每秒⼀次就能获得⽐ 较⾼的性能,⽽关闭 fsync 可以让 AOF 的速度和 RDB ⼀样快。
AOF 在过去曾经发⽣过这样的 bug :因为个别命令的原因,导致 AOF ⽂件在重新载⼊时,⽆法将 数据集恢复成保存时的原样。(举个例⼦,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug ) 。虽然这种 bug 在 AOF ⽂件中并不常⻅, 但是相较⽽⾔, RDB ⼏乎是不可能出现这种 bug 的。
混合持久化
**描述**:混合持久化并不是⼀种全新的持久化⽅式,⽽是对已有⽅式的优化。混合持久化只发⽣于 AOF 重写过程。使⽤了混合持久化,重写后的新 AOF ⽂件前半段是 RDB 格式的全量数据,后半段是 AOF 格式的增量数据。整体格式为:[RDB file][AOF tail]**开启**:混合持久化的配置参数为 aof-use-rdb-preamble,配置为 yes 时开启混合持久化,在 redis 4 刚引⼊时,默认是关闭混合持久化的,但是在 redis 5 中默认已经打开了。**关闭**:使⽤ aof-use-rdb-preamble no 配置即可关闭混合持久化。混合持久化本质是通过 AOF 后台重写(bgrewriteaof 命令)完成的,不同的是当开启混合持久化时,fork 出的⼦进程先将当前全量数据以 RDB ⽅式写⼊新的 AOF ⽂件,然后再将 AOF 重写缓冲区(aof_rewrite_buf_blocks)的增量命令以 AOF ⽅式写⼊到⽂件,写⼊完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF ⽂件替换旧的的 AOF ⽂件。**优点**:结合 RDB 和 AOF 的优点, 更快的重写和恢复。**缺点**:AOF ⽂件⾥⾯的 RDB 部分不再是 AOF 格式,可读性差
7.18、为什么需要 AOF 重写?
AOF 持久化是通过保存被执⾏的写命令来记录数据库状态的,随着写⼊命令的不断增加,AOF ⽂件中 的内容会越来越多,⽂件的体积也会越来越⼤。
如果不加以控制,体积过⼤的 AOF ⽂件可能会对 Redis 服务器、甚⾄整个宿主机造成影响,并且 AOF ⽂件的体积越⼤,使⽤ AOF ⽂件来进⾏数据还原所需的时间就越多。
举个例⼦, 如果你对⼀个计数器调⽤了 100 次 INCR , 那么仅仅是为了保存这个计数器的当前值, AOF ⽂件就需要使⽤ 100 条记录。
然⽽在实际上, 只使⽤⼀条 SET 命令已经⾜以保存计数器的当前值了, 其余 99 条记录实际上都是多 余的。
为了处理这种情况, Redis 引⼊了 AOF 重写:可以在不打断服务端处理请求的情况下, 对 AOF ⽂件 进⾏重建(rebuild)
7.19、介绍下 AOF 重写的过程、AOF 后台重写存在的问题、如何解决 AOF 后台重写存在的数据不⼀致问题?
描述:Redis ⽣成新的 AOF ⽂件来代替旧 AOF ⽂件,这个新的 AOF ⽂件包含重建当前数据集所需的 最少命令。具体过程是遍历所有数据库的所有键,从数据库读取键现在的值,然后⽤⼀条命令去记录 键值对,代替之前记录这个键值对的多条命令。
命令:有两个 Redis 命令可以⽤于触发 AOF 重写,⼀个是 BGREWRITEAOF 、另⼀个是 REWRITEAOF 命令;
开启:AOF 重写由两个参数共同控制,auto-aof-rewrite-percentage 和 auto-aof-rewrite-minsize,同时满⾜这两个条件,则触发 AOF 后台重写 BGREWRITEAOF
// 当前AOF⽂件⽐上次重写后的AOF⽂件⼤⼩的增⻓⽐例超过100auto-aof-rewrite-percentage 100// 当前AOF⽂件的⽂件⼤⼩⼤于64MBauto-aof-rewrite-min-size 64mb
关闭:auto-aof-rewrite-percentage 0,指定0的百分⽐,以禁⽤⾃动AOF重写功能
auto-aof-rewrite-percentage 0
REWRITEAOF:进⾏ AOF 重写,但是会阻塞主进程,服务器将⽆法处理客⼾端发来的命令请求,通 常不会直接使⽤该命令。
BGREWRITEAOF:fork ⼦进程来进⾏ AOF 重写,阻塞只会发⽣在 fork ⼦进程的时候,之后主进程可 以正常处理请求。
REWRITEAOF 和 BGREWRITEAOF 的关系与 SAVE 和 BGSAVE 的关系类似。
AOF 后台重写存在的问题
AOF 后台重写使⽤⼦进程进⾏从写,解决了主进程阻塞的问题,但是仍然存在另⼀个问题:⼦进程在 进⾏ AOF 重写期间,服务器主进程还需要继续处理命令请求,新的命令可能会对现有的数据库状态 进⾏修改,从⽽使得当前的数据库状态和重写后的 AOF ⽂件保存的数据库状态不⼀致。
如何解决 AOF 后台重写存在的数据不⼀致问题
为了解决上述问题,Redis 引⼊了 AOF 重写缓冲区(aof_rewrite_buf_blocks),这个缓冲区在服务 器创建⼦进程之后开始使⽤,当 Redis 服务器执⾏完⼀个写命令之后,它会同时将这个写命令追加到 AOF 缓冲区和 AOF 重写缓冲区。 这样⼀来可以保证:
1、现有 AOF ⽂件的处理⼯作会如常进⾏。这样即使在重写的中途发⽣停机,现有的 AOF ⽂件也还是 安全的。
2、从创建⼦进程开始,也就是 AOF 重写开始,服务器执⾏的所有写命令会被记录到 AOF 重写缓冲区 ⾥⾯。
这样,当⼦进程完成 AOF 重写⼯作后,⽗进程会在 serverCron 中检测到⼦进程已经重写结束,则会 执⾏以下⼯作:
1、将 AOF 重写缓冲区中的所有内容写⼊到新 AOF ⽂件中,这时新 AOF ⽂件所保存的数据库状态将 和服务器当前的数据库状态⼀致。
2、对新的 AOF ⽂件进⾏改名,原⼦的覆盖现有的 AOF ⽂件,完成新旧两个 AOF ⽂件的替换。 之后,⽗进程就可以继续像往常⼀样接受命令请求了
7.20、RDB、AOF、混合持久,我应该⽤哪⼀个?
⼀般来说, 如果想尽量保证数据安全性, 你应该同时使⽤ RDB 和 AOF 持久化功能,同时可以开启混 合持久化。
如果你⾮常关⼼你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使⽤ RDB 持久 化。
如果你的数据是可以丢失的,则可以关闭持久化功能,在这种情况下,Redis 的性能是最⾼的。
使⽤ Redis 通常都是为了提升性能,⽽如果为了不丢失数据⽽将 appendfsync 设置为 always 级别 时,对 Redis 的性能影响是很⼤的,在这种不能接受数据丢失的场景,其实可以考虑直接选择 MySQL 等类似的数据库。
7.21、同时开启RDB和AOF,服务重启时如何加载?
简单来说,如果同时启⽤了 AOF 和 RDB,Redis 重新启动时,会使⽤ AOF ⽂件来重建数据集,因为 通常来说, AOF 的数据会更完整。
⽽在引⼊了混合持久化之后,使⽤ AOF 重建数据集时,会通过⽂件开头是否为“REDIS”来判断是否 为混合持久化。
完整流程如下图所⽰:


7.22、Redis 怎么保证⾼可⽤、有哪些集群模式?
主从复制、哨兵模式、集群模式
7.23、主从复制
在当前最新的 Redis 7.0 中,主从复制的完整过程如下:
1)开启主从复制 通常有以下三种⽅式:
• 在 slave 直接执⾏命令:slaveof
• 在 slave 配置⽂件中加⼊:slaveof
• 使⽤启动命令:—slaveof
注:在 Redis 6.0 之后,slaveof 相关命令和配置已经被替换成 replicaof,例如 replicaof 。
为了兼容旧版本,通过配置的⽅式仍然⽀持 slaveof,但是通过命令的⽅式则不⾏ 了
**2)建⽴套接字(socket)连接**slave 将根据指定的 IP 地址和端⼝,向 master 发起套接字(socket)连接,master在接受(accept) slave 的套接字连接之后,为该套接字创建相应的客⼾端状态,此时连接建⽴完成。**3)发送PING命令**slave 向 master 发送⼀个 PING 命令,以检査套接字的读写状态是否正常、 master能否正常处理命令请求。**4)⾝份验证**slave 向 master 发送 AUTH password 命令来进⾏⾝份验证。**5)发送端⼝信息**在⾝份验证通过后后, slave 将向 master 发送⾃⼰的监听端⼝号, master 收到后记录在 slave 所对应的客⼾端状态的 slave_listening_port 属性中**6)发送IP地址**如果配置了 slave_announce_ip,则 slave 向 master 发送 slave_announce_ip 配置的 IP 地址, master 收到后记录在 slave 所对应的客⼾端状态的 slave_ip 属性。该配置是⽤于解决服务器返回内⽹ IP 时,其他服务器⽆法访问的情况。可以通过该配置直接指定公⽹ IP。**7)发送CAPA**CAPA 全称是 capabilities,这边表⽰的是同步复制的能⼒。slave 会在这⼀阶段发送capa 告诉 master ⾃⼰具备的(同步)复制能⼒, master 收到后记录在 slave 所对应的客⼾端状态的 slave_capa 属性。**8)数据同步**slave 将向 master 发送 PSYNC 命令, master 收到该命令后判断是进⾏部分重同步还是完整重同步,然后根据策略进⾏数据的同步。**9)命令传播**当完成了同步之后,就会进⼊命令传播阶段,这时 master 只要⼀直将⾃⼰执⾏的写命令发送给 slave ,⽽ slave 只要⼀直接收并执⾏ master 发来的写命令,就可以保证 master 和slave ⼀直保持⼀致了
以部分重同步为例,主从复制的核⼼步骤流程图如下
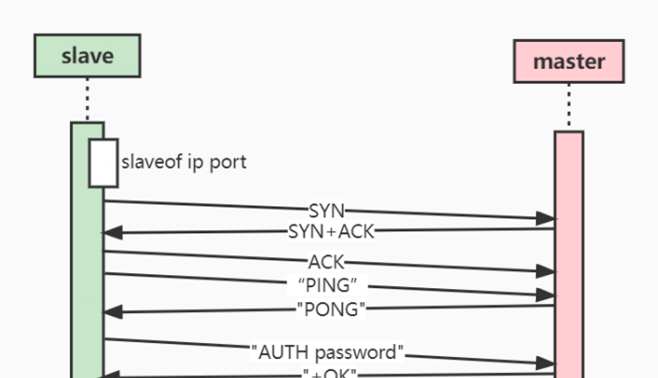
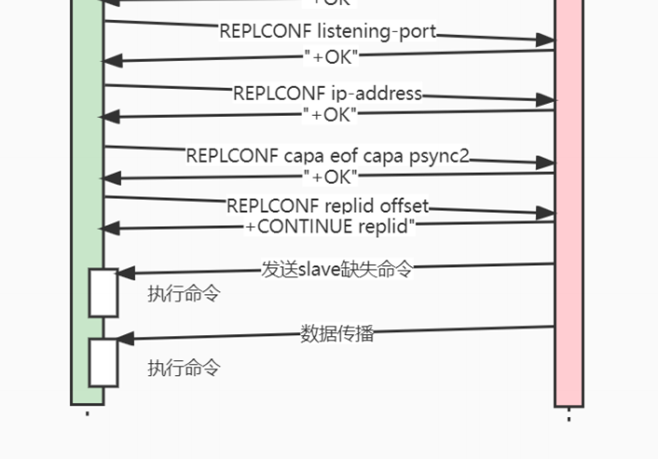
7.24、哨兵
哨兵(Sentinel) 是 Redis 的⾼可⽤性解决⽅案:由⼀个或多个 Sentinel 实例组成的
Sentinel 系统 可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器。 Sentinel 可以在被监视的主服务器进⼊下线状态时,⾃动将下线主服务器的某个从服务器升级为新的 主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。
1)哨兵故障检测
检查主观下线状态
在默认情况下,Sentinel 会以每秒⼀次的频率向所有与它创建了命令连接的实例(包括主服务器、从 服务器、其他 Sentinel 在内)发送 PING 命令,并通过实例返回的 PING 命令回复来判断实例是否在 线。
如果⼀个实例在 down-after-miliseconds 毫秒内,连续向 Sentinel 返回⽆效回复,那么 Sentinel 会 修改这个实例所对应的实例结构,在结构的 flags 属性中设置 SRI_S_DOWN 标识,以此来表⽰这个 实例已经进⼊主观下线状态。
检查客观下线状态
当 Sentinel 将⼀个主服务器判断为主观下线之后,为了确定这个主服务器是否真的下线了,它会向同 样监视这⼀服务器的其他 Sentinel 进⾏询问,看它们是否也认为主服务器已经进⼊了下线状态(可以 是主观下线或者客观下线)。
当 Sentinel 从其他 Sentinel 那⾥接收到⾜够数量(quorum,可配置)的已下线判断之后,Sentinel 就会将服务器置为客观下线,在 flags 上打上 SRI_O_DOWN 标识,并对主服务器执⾏故障转移操 作。
2)哨兵故障转移流程
当哨兵监测到某个主节点客观下线之后,就会开始故障转移流程。核⼼流程如下:
- 发起⼀次选举,选举出领头 Sentinel
- 领头 Sentinel 在已下线主服务器的所有从服务器⾥⾯,挑选出⼀个从服务器,并将其升级为新的 主服务器。
- 领头 Sentinel 将剩余的所有从服务器改为复制新的主服务器。
- 领头 Sentinel 更新相关配置信息,当这个旧的主服务器重新上线时,将其设置为新的主服务器的 从服务器
7.25、集群模式
哨兵模式最⼤的缺点就是所有的数据都放在⼀台服务器上,⽆法较好的进⾏⽔平扩展。 为了解决哨兵模式存在的问题,集群模式应运⽽⽣。在⾼可⽤上,集群基本是直接复⽤的哨兵模式的 逻辑,并且针对⽔平扩展进⾏了优化。
集群模式具备的特点如下:
- 采取去中⼼化的集群模式,将数据按槽存储分布在多个 Redis 节点上。集群共有 16384 个槽,每 个节点负责处理部分槽。
- 使⽤ CRC16 算法来计算 key 所属的槽:crc16(key,keylen) & 16383。
- 所有的 Redis 节点彼此互联,通过 PING-PONG 机制来进⾏节点间的⼼跳检测。
- 分⽚内采⽤⼀主多从保证⾼可⽤,并提供复制和故障恢复功能。在实际使⽤中,通常会将主从分 布在不同机房,避免机房出现故障导致整个分⽚出问题,下⾯的架构图就是这样设计的。
- 客⼾端与 Redis 节点直连,不需要中间代理层(proxy)。客⼾端不需要连接集群所有节点,连接 集群中任何⼀个可⽤节点即可
7.26、集群选举
故障转移的第⼀步就是选举出新的主节点,以下是集群选举新的主节点的⽅法:
1)当从节点发现⾃⼰正在复制的主节点进⼊已下线状态时,会发起⼀次选举:将 currentEpoch(配 置纪元)加1,然后向集群⼴播⼀条 CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST 消息,要求 所有收到这条消息、并且具有投票权的主节点向这个从节点投票。
2)其他节点收到消息后,会判断是否要给发送消息的节点投票,判断流程如下:
当前节点是 slave,或者当前节点是 master,但是不负责处理槽,则当前节点没有投票权,直接 返回。
请求节点的 currentEpoch ⼩于当前节点的 currentEpoch,校验失败返回。因为发送者的状态与 当前集群状态不⼀致,可能是⻓时间下线的节点刚刚上线,这种情况下,直接返回即可。
当前节点在该 currentEpoch 已经投过票,校验失败返回。
请求节点是 master,校验失败返回。
请求节点的 master 为空,校验失败返回。
请求节点的 master 没有故障,并且不是⼿动故障转移,校验失败返回。因为⼿动故障转移是可以 在 master 正常的情况下直接发起的。
上⼀次为该master的投票时间,在cluster_node_timeout的2倍范围内,校验失败返回。这个⽤ 于使获胜从节点有时间将其成为新主节点的消息通知给其他从节点,从⽽避免另⼀个从节点发起 新⼀轮选举⼜进⾏⼀次没必要的故障转移
请求节点宣称要负责的槽位,是否⽐之前负责这些槽位的节点,具有相等或更⼤的 configEpoch,如果不是,校验失败返回
如果通过以上所有校验,那么主节点将向要求投票的从节点返回⼀条 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,表⽰这个主节点⽀持从节点成为新的主节点
3)每个参与选举的从节点都会接收 CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK 消息,并根据⾃⼰收到了多少条这种消息来统计⾃⼰获得了多少个主节点的⽀持。4)如果集群⾥有N个具有投票权的主节点,那么当⼀个从节点收集到⼤于等于N/2+1 张⽀持票时,这个从节点就会当选为新的主节点。因为在每⼀个配置纪元⾥⾯,每个具有投票权的主节点只能投⼀次票,所以如果有 N个主节点进⾏投票,那么具有⼤于等于 N/2+1 张⽀持票的从节点只会有⼀个,这确保了新的主节点只会有⼀个。5)如果在⼀个配置纪元⾥⾯没有从节点能收集到⾜够多的⽀持票,那么集群进⼊⼀个新的配置纪元,并再次进⾏选举,直到选出新的主节点为⽌
这个选举新主节点的⽅法和选举领头 Sentinel 的⽅法⾮常相似,因为两者都是基于 Raft 算法的领头 选举(leader election)⽅法来实现的
7.27、如何保证集群在线扩容的安全性?(Redis 集群要增加分⽚,槽的 迁移怎么保证⽆损)
例如:集群已经对外提供服务,原来有3分⽚,准备新增2个分⽚,怎么在不下线的情况下,⽆损的从 原有的3个分⽚指派若⼲个槽给这2个分⽚? Redis 使⽤了 ASK 错误来保证在线扩容的安全性。 在槽的迁移过程中若有客⼾端访问,依旧先访问源节点,源节点会先在⾃⼰的数据库⾥⾯査找指定的 键,如果找到的话,就直接执⾏客⼾端发送的命令。 如果没找到,说明该键可能已经被迁移到⽬标节点了,源节点将向客⼾端返回⼀个 ASK 错误,该错误 会指引客⼾端转向正在导⼊槽的⽬标节点,并再次发送之前想要执⾏的命令,从⽽获取到结果
7.28、Redis 事务的实现
⼀个事务从开始到结束通常会经历以下3个阶段:
1)事务开始:multi 命令将执⾏该命令的客⼾端从⾮事务状态切换⾄事务状态,底层通过 flags 属性 标识
2)命令⼊队:当客⼾端处于事务状态时,服务器会根据客⼾端发来的命令执⾏不同的操作: • exec、discard、watch、multi 命令会被⽴即执⾏ • 其他命令不会⽴即执⾏,⽽是将命令放⼊到⼀个事务队列,然后向客⼾端返回 QUEUED 回复。
3)事务执⾏:当⼀个处于事务状态的客⼾端向服务器发送 exec 命令时,服务器会遍历事务队列,执 ⾏队列中的所有命令,最后将结果全部返回给客⼾端。 不过 redis 的事务并不推荐在实际中使⽤,如果要使⽤事务,推荐使⽤ Lua 脚本,redis 会保证⼀ 个 Lua 脚本⾥的所有命令的原⼦性
7.29、Redis 的 Java 客⼾端有哪些?官⽅推荐哪个?
Redis 官⽹展⽰的 Java 客⼾端如下图所⽰,其中官⽅推荐的是标星的3个:Jedis、Redisson 和 lettuce
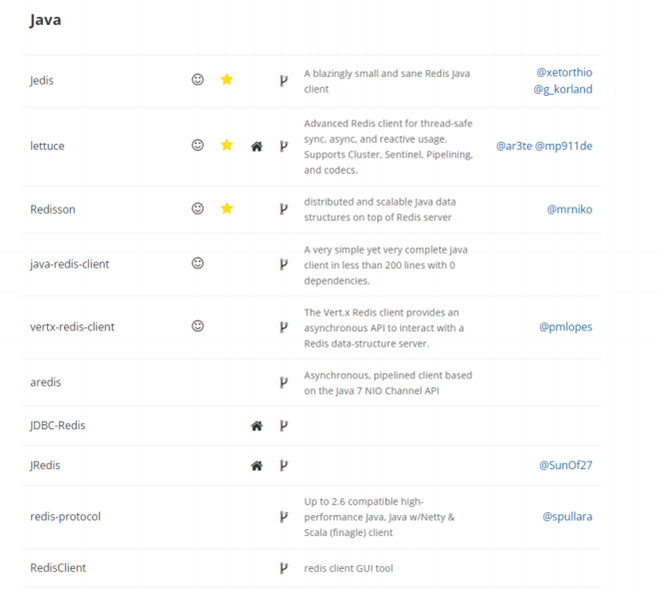
7.30、Redis ⾥⾯有1亿个 key,其中有 10 个 key 是包含 java,如何将它 们全部找出来
1)keys java 命令,该命令性能很好,但是在数据量特别⼤的时候会有性能问题
2)scan 0 MATCH java 命令,基于游标的迭代器,更好的选择 SCAN 命令是⼀个基于游标的迭代器(cursor based iterator): SCAN 命令每次被调⽤之后, 都会 向⽤⼾返回⼀个新的游标, ⽤⼾在下次迭代时需要使⽤这个新游标作为 SCAN 命令的游标参数, 以 此来延续之前的迭代过程
当 SCAN 命令的游标参数被设置为 0 时, 服务器将开始⼀次新的迭代, ⽽当服务器向⽤⼾返回值为 0 的游标时, 表⽰迭代已结束
7.31、使⽤过 Redis 做消息队列么?
Redis 本⾝提供了⼀些组件来实现消息队列的功能,但是多多少少都存在⼀些缺点,相⽐于市⾯上成 熟的消息队列,例如 Kafka、Rocket MQ 来说并没有优势,因此⽬前我们并没有使⽤ Redis 来做消息 队列。
关于 Redis 做消息队列的常⻅⽅案主要有以下:
1)Redis 6.0 之前可以使⽤ List(blocking)、Pub/Sub 等来实现轻量级的消息发布订阅功能组件, 但是这两种实现⽅式都有很明显的缺点,两者中相对完善的 Pub/Sub 的主要缺点就是消息⽆法持久 化,如果出现⽹络断开、Redis 宕机等,消息就会被丢弃。
2)为了解决 Pub/Sub 模式等的缺点,Redis 在 6.0 引⼊了全新的 Stream,Stream 借鉴了很多 Kafka 的设计思想,有以下⼏个特点:
提供了消息的持久化和主备复制功能,可以让任何客⼾端访问任何时刻的数据,并且能记住每⼀ 个客⼾端的访问位置,还能保证消息不丢失。
• 引⼊了消费者组的概念,不同组接收到的数据完全⼀样(前提是条件⼀样),但是组内的消费者 则是竞争关系。
• Redis Stream 相⽐于 pub/sub 已经有很明显的改善,但是相⽐于 Kafka,其实没有优势,同时存 在:尚未经过⼤量验证、成本较⾼、不⽀持分区(partition)、⽆法⽀持⼤规模数据等问题
7.32、Redis 和 Memcached 的⽐较
1)数据结构:memcached ⽀持简单的 key-value 数据结构,⽽ redis ⽀持丰富的数据结构: String、List、Set、Hash、SortedSet 等。
2)数据存储:memcached 和 redis 的数据都是全部在内存中。 ⽹上有⼀种说法 “当物理内存⽤完时,Redis可以将⼀些很久没⽤到的 value 交换到磁盘,同时在内 存中清除”,这边指的是 redis ⾥的虚拟内存(Virtual Memory)功能,该功能在 Redis 1.0 被引 ⼊,但是在 Redis 1.4 中被默认关闭,并标记为废弃,⽽在后续版中被完全移除。
3)持久化:memcached 不⽀持持久化,redis ⽀持将数据持久化到磁盘
4)灾难恢复:实例挂掉后,memcached 数据不可恢复,redis 可通过 RDB、AOF 恢复,但是还是 会有数据丢失问题
5)事件库:memcached 使⽤ Libevent 事件库,redis ⾃⼰封装了简易事件库 AeEvent
6)过期键删除策略:memcached 使⽤惰性删除,redis 使⽤惰性删除+定期删除
7)内存驱逐(淘汰)策略:memcached 主要为 LRU 算法,redis 当前⽀持8种淘汰策略,⻅本⽂第 16题
8)性能⽐较
按“CPU 单核” 维度⽐较:由于 Redis 只使⽤单核,⽽ Memcached 可以使⽤多核,所以在⽐较 上:在处理⼩数据时,平均每⼀个核上 Redis ⽐ Memcached 性能更⾼,⽽在 100k 左右的⼤数据 时, Memcached 性能要⾼于 Redis。
• 按“实例”维度进⾏⽐较:由于 Memcached 多线程的特性,在 Redis 7.0 之前,通常情况下 Memcached 性能是要⾼于 Redis 的,同时实例的 CPU 核数越多,Memcached 的性能优势越 ⼤。 •
• ⾄于⽹上说的 redis 的性能⽐ memcached 快很多,这个说法就离谱
7.33、Redis 实现分布式锁
1)加锁 加锁通常使⽤ set 命令来实现,伪代码如下
set key value PX milliseconds NX
⼏个参数的意义如下:
key、value:键值对
PX milliseconds:设置键的过期时间为 milliseconds 毫秒。
NX:只在键不存在时,才对键进⾏设置操作。SET key value NX 效果等同于 SETNX key value。
PX、expireTime 参数则是⽤于解决没有解锁导致的死锁问题。因为如果没有过期时间,万⼀程序员 写的代码有 bug 导致没有解锁操作,则就出现了死锁,因此该参数起到了⼀个“兜底”的作⽤。
NX 参数⽤于保证在多个线程并发 set 下,只会有1个线程成功,起到了锁的“唯⼀”性。
2)解锁
解锁需要两步操作:
1)查询当前“锁”是否还是我们持有,因为存在过期时间,所以可能等你想解锁的时候,“锁”已 经到期,然后被其他线程获取了,所以我们在解锁前需要先判断⾃⼰是否还持有“锁”2)如果“锁”还是我们持有,则执⾏解锁操作,也就是删除该键值对,并返回成功;否则,直接返 回失败。 由于当前 Redis 还没有原⼦命令直接⽀持这两步操作,所以当前通常是使⽤ Lua 脚本来执⾏解锁操 作,Redis 会保证脚本⾥的内容执⾏是⼀个原⼦操作。 脚本代码如下,逻辑⽐较简单
if redis.call("get",KEYS[1]) == ARGV[1]thenreturn redis.call("del",KEYS[1])elsereturn 0end
两个参数的意义如下:
KEYS[1]:我们要解锁的 key ARGV[1]:
我们加锁时的 value,⽤于判断当“锁”是否还是我们持有,如果被其他线程持有了, value 就会发⽣变化。
上述⽅法是 Redis 当前实现分布式锁的主流⽅法,可能会有⼀些⼩优区别,但是核⼼都是这个思路。 看着好像没啥⽑病,但是真的是这个样⼦吗?让我们继续往下看
7.34、Redis 分布式锁过期了,还没处理完怎么办?
为了防⽌死锁,我们会给分布式锁加⼀个过期时间,但是万⼀这个时间到了,我们业务逻辑还没处理 完,怎么办?
⾸先,我们在设置过期时间时要结合业务场景去考虑,尽量设置⼀个⽐较合理的值,就是理论上正常 处理的话,在这个过期时间内是⼀定能处理完毕的。
之后,我们再来考虑对这个问题进⾏兜底设计。
关于这个问题,⽬前常⻅的解决⽅法有两种:
1.守护线程“续命”:额外起⼀个线程,定期检查线程是否还持有锁,如果有则延⻓过期时间。 Redisson ⾥⾯就实现了这个⽅案,使⽤“看⻔狗”定期检查(每1/3的锁时间检查1次),如果线 程还持有锁,则刷新过期时间。
2.超时回滚:当我们解锁时发现锁已经被其他线程获取了,说明此时我们执⾏的操作已经是“不安 全”的了,此时需要进⾏回滚,并返回失败
同时,需要进⾏告警,⼈为介⼊验证数据的正确性,然后找出超时原因,是否需要对超时时间进⾏优 化等等
7.35、守护线程续命的⽅案有什么问题吗?
Redisson 使⽤看⻔狗(守护线程)“续命”的⽅案在⼤多数场景下是挺不错的,也被⼴泛应⽤于⽣ 产环境,但是在极端情况下还是会存在问题。
问题例⼦如下:
线程1⾸先获取锁成功,将键值对写⼊ redis 的 master 节点
在 redis 将该键值对同步到 slave 节点之前,master 发⽣了故障
. redis 触发故障转移,其中⼀个 slave 升级为新的 master
. 此时新的 master 并不包含线程1写⼊的键值对,因此线程2尝试获取锁也可以成功拿到锁
. 此时相当于有两个线程获取到了锁,可能会导致各种预期之外的情况发⽣,例如最常⻅的脏数据 解决⽅法:上述问题的根本原因主要是由于 redis 异步复制带来的数据不⼀致问题导致的,因此解决 的⽅向就是保证数据的⼀致
当前⽐较主流的解法和思路有两种:1)Redis 作者提出的 RedLock;2)Zookeeper 实现的分布式锁
7.36、RedLock
⾸先,该⽅案也是基于⽂章开头的那个⽅案(set加锁、lua脚本解锁)进⾏改良的,所以 antirez 只 描述了差异的地⽅,⼤致⽅案如下。
假设我们有 N 个 Redis 主节点,例如 N = 5,这些节点是完全独⽴的,我们不使⽤复制或任何其他隐 式协调系统,为了取到锁,客⼾端应该执⾏以下操作:
- 获取当前时间,以毫秒为单位。
- 依次尝试从5个实例,使⽤相同的 key 和随机值(例如UUID)获取锁。当向Redis 请求获取锁时, 客⼾端应该设置⼀个超时时间,这个超时时间应该⼩于锁的失效时间。例如你的锁⾃动失效时间为10秒,则超时时间应该在 5-50 毫秒之间。这样可以防⽌客⼾端在试图与⼀个宕机的 Redis 节点 对话时⻓时间处于阻塞状态。如果⼀个实例不可⽤,客⼾端应该尽快尝试去另外⼀个Redis实例请 求获取锁。
- 客⼾端通过当前时间减去步骤1记录的时间来计算获取锁使⽤的时间。当且仅当从⼤多数 (N/2+1,这⾥是3个节点)的Redis节点都取到锁,并且获取锁使⽤的时间⼩于锁失效时间时,锁 才算获取成功。
- . 如果取到了锁,其真正有效时间等于初始有效时间减去获取锁所使⽤的时间(步骤3计算的结 果)。
- . 如果由于某些原因未能获得锁(⽆法在⾄少N/2+1个Redis实例获取锁、或获取锁的时间超过了有 效时间),客⼾端应该在所有的Redis实例上进⾏解锁(即便某些Redis实例根本就没有加锁成 功,防⽌某些节点获取到锁但是客⼾端没有得到响应⽽导致接下来的⼀段时间不能被重新获取 锁)。
可以看出,该⽅案为了解决数据不⼀致的问题,直接舍弃了异步复制,只使⽤ master 节点,同时由 于舍弃了 slave,为了保证可⽤性,引⼊了 N 个节点,官⽅建议是 5
该⽅案看着挺美好的,但是实际上我所了解到的在实际⽣产上应⽤的不多,主要有两个原因:1)该⽅案的成本似乎有点⾼,需要使⽤5个实例;2)该⽅案⼀样存在问题。该⽅案主要存以下问题
- 严重依赖系统时钟。如果线程1从3个实例获取到了锁,但是这3个实例中的某个实例的系统时间⾛ 的稍微快⼀点,则它持有的锁会提前过期被释放,当他释放后,此时⼜有3个实例是空闲的,则线 程2也可以获取到锁,则可能出现两个线程同时持有锁了。
- . 如果线程1从3个实例获取到了锁,但是万⼀其中有1台重启了,则此时⼜有3个实例是空闲的,则 线程2也可以获取到锁,此时⼜出现两个线程同时持有锁了。
针对以上问题其实后续也有⼈给出⼀些相应的解法,但是整体上来看还是不够完美,所以⽬前实际应 ⽤得不是那么多
7.37、使⽤缓存时,先操作数据库 or 先操作缓存
1)先操作数据库
案例如下,有两个并发的请求,⼀个写请求,⼀个读请求,流程如下
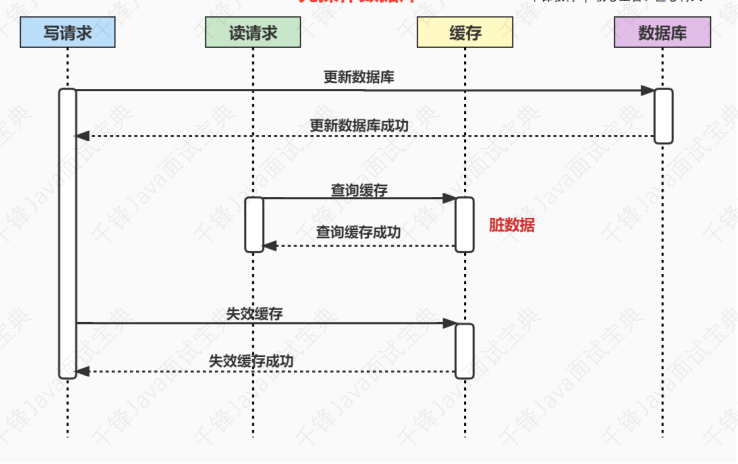
可能存在的脏数据时间范围:更新数据库后,失效缓存前。这个时间范围很⼩,通常不会超过⼏毫 秒。
2)先操作缓存
案例如下,有两个并发的请求,⼀个写请求,⼀个读请求,流程如下
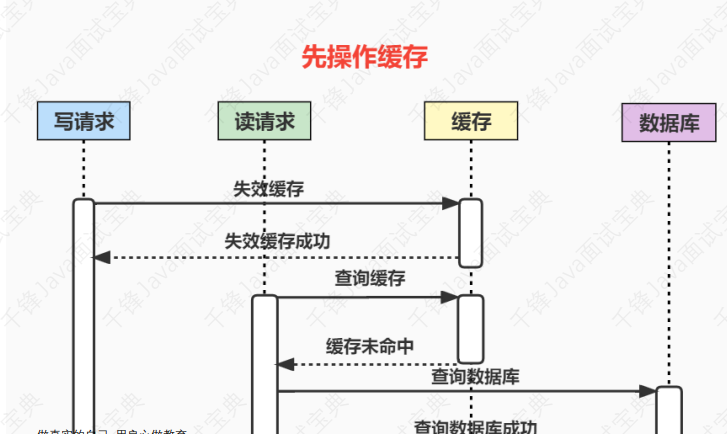
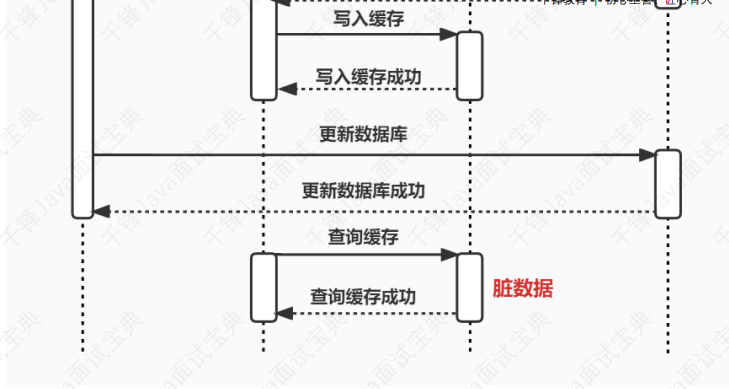
可能存在的脏数据时间范围:更新数据库后,下⼀次对该数据的更新前。这个时间范围不确定性很 ⼤,情况如下:
• 如果下⼀次对该数据的更新⻢上就到来,那么会失效缓存,脏数据的时间就很短。
• 如果下⼀次对该数据的更新要很久才到来,那这期间缓存保存的⼀直是脏数据,时间范围很⻓。
结论:通过上述案例可以看出,先操作数据库和先操作缓存都会存在脏数据的情况。但是相⽐之下, 先操作数据库,再操作缓存是更优的⽅式,即使在并发极端情况下,也只会出现很⼩量的脏数据
7.38、为什么是让缓存失效,⽽不是更新缓存?
1)更新缓存
案例如下,有两个并发的写请求,流程如下
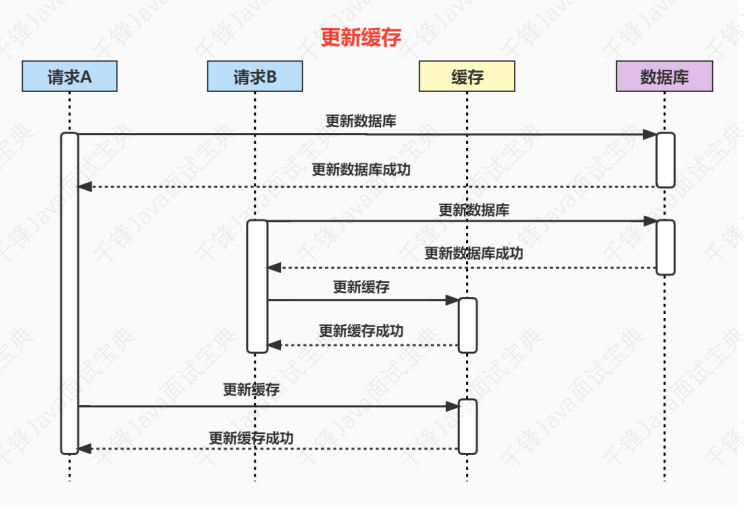
分析:数据库中的数据是请求B的,缓存中的数据是请求A的,数据库和缓存存在数据不⼀致。
2)失效(删除)缓存
案例如下,有两个并发的写请求,流程如下
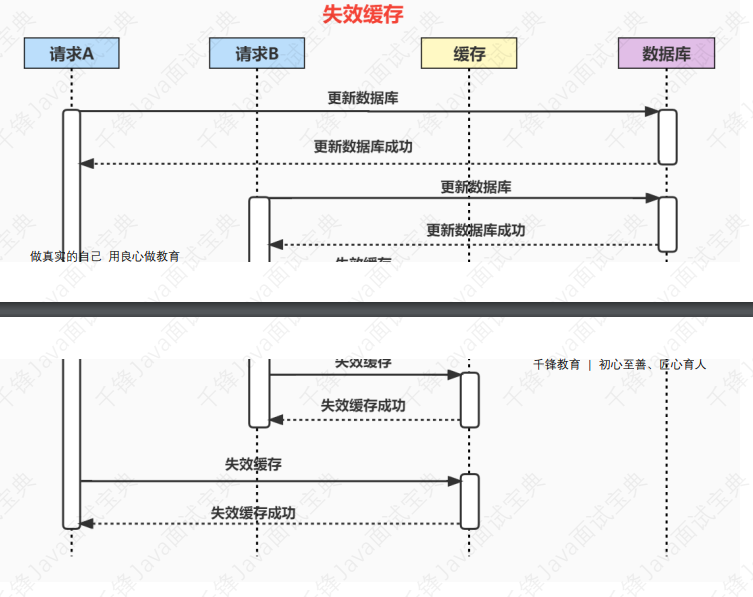
分析:由于是删除缓存,所以不存在数据不⼀致的情况。
结论:通过上述案例,可以很明显的看出,失效缓存是更优的⽅式
7.39、如何保证数据库和缓存的数据⼀致性?
在上⽂的案例中,⽆论是先操作数据库,还是先操作缓存,都会存在脏数据的情况,有办法避免吗?
答案是有的,由于数据库和缓存是两个不同的数据源,要保证其数据⼀致性,其实就是典型的分布式 事务场景,可以引⼊分布式事务来解决,常⻅的有:2PC、TCC、MQ事务消息等。 但是引⼊分布式事务必然会带来性能上的影响,这与我们当初引⼊缓存来提升性能的⽬的是相违背 的。
所以在实际使⽤中,通常不会去保证缓存和数据库的强⼀致性,⽽是做出⼀定的牺牲,保证两者数据 的最终⼀致性。
如果是实在⽆法接受脏数据的场景,则⽐较合理的⽅式是放弃使⽤缓存,直接⾛数据库。 保证数据库和缓存数据最终⼀致性的常⽤⽅案如下:
1)更新数据库,数据库产⽣ binlog
2)监听和消费 binlog,执⾏失效缓存操作。
3)如果步骤2失效缓存失败,则引⼊重试机制,将失败的数据通过MQ⽅式进⾏重试,同时考虑是否 需要引⼊幂等机制
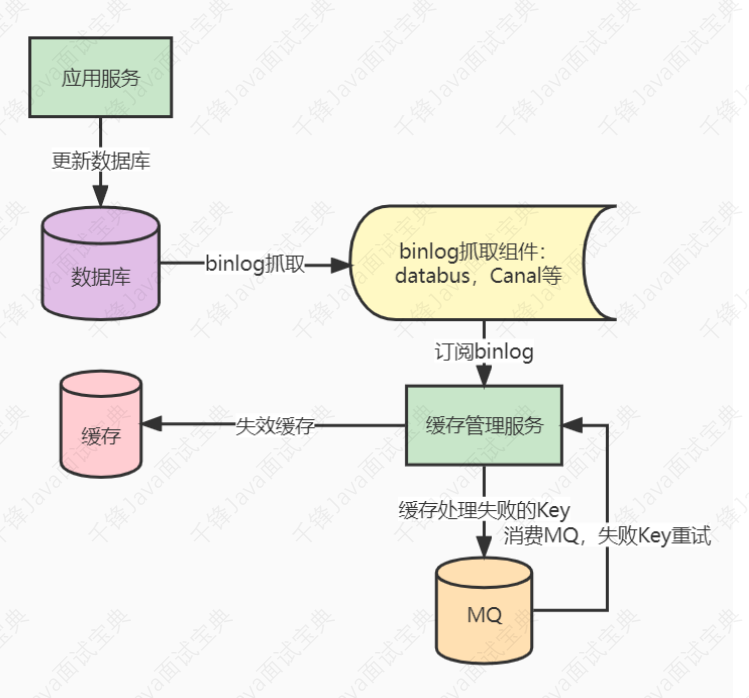
兜底:当出现未知的问题时,及时告警通知,
⼈为介⼊处理。 ⼈为介⼊是终极⼤法,那些外表看着光鲜艳丽的应⽤,其背后⼤多有⼀群苦逼的程序员,在不断的修 复各种脏数据和bug。
7.40、缓存穿透
描述:访问⼀个缓存和数据库都不存在的 key,此时会直接打到数据库上,并且查不到数据,没法写 缓存,所以下⼀次同样会打到数据库上。
此时,缓存起不到作⽤,请求每次都会⾛到数据库,流量⼤时数据库可能会被打挂。此时缓存就好像 被“穿透”了⼀样,起不到任何作⽤。
解决⽅案:
1)接⼝校验。在正常业务流程中可能会存在少量访问不存在 key 的情况,但是⼀般不会出现⼤量的 情况,所以这种场景最⼤的可能性是遭受了⾮法攻击。可以在最外层先做⼀层校验:⽤⼾鉴权、数据 合法性校验等,例如商品查询中,商品的ID是正整数,则可以直接对⾮正整数直接过滤等等。
2)缓存空值。当访问缓存和DB都没有查询到值时,可以将空值写进缓存,但是设置较短的过期时 间,该时间需要根据产品业务特性来设置。
3)布隆过滤器。使⽤布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进⼀步查询缓存和数据库
7.41、布隆过滤器
布隆过滤器的特点是判断不存在的,则⼀定不存在;判断存在的,⼤概率存在,但也有⼩概率不存 在。并且这个概率是可控的,我们可以让这个概率变⼩或者变⾼,取决于⽤⼾本⾝的需求。
布隆过滤器由⼀个 bitSet 和 ⼀组 Hash 函数(算法)组成,是⼀种空间效率极⾼的概率型算法和数据 结构,主要⽤来判断⼀个元素是否在集合中存在。
在初始化时,bitSet 的每⼀位被初始化为0,同时会定义 Hash 函数,例如有3组 Hash 函数: hash1、hash2、hash3。
写⼊流程
当我们要写⼊⼀个值时,过程如下,以“Java”为例:
1)⾸先将“Java”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)将 bitSet 的这3个下标标记为1。 假设我们还有另外两个值:C 和 C#,按上⾯的流程跟 3组 Hash 函数分别计算,结果如下: C :Hash 函数计算 bitSet 下标为:1、7、11 C# :Hash 函数计算 bitSet 下标为:4、10、11
查询流程
当我们要查询⼀个值时,过程如下,同样以“Java”为例::
1)⾸先将“Java”跟3组 Hash 函数分别计算,得到 bitSet 的下标为:1、7、10。
2)查看 bitSet 的这3个下标是否都为1,如果这3个下标不都为1,则说明该值必然不存在,如果这3 个下标都为1,则只能说明可能存在,并不能说明⼀定存在。 其实上图的例⼦已经说明了这个问题了,当我们只有值“Java”和“C#”时,bitSet 下标为1的有: 1、4、7、10、11。
当我们⼜加⼊值“C”时,bitSet 下标为1的还是这5个,所以当 bitSet 下标为1的为:1、4、7、 10、11 时,我们⽆法判断值“C”存不存在。
其根本原因是,不同的值在跟 Hash 函数计算后,可能会得到相同的下标,所以某个值的标记位,可 能会被其他值给标上了。
这也是为啥布隆过滤器只能判断某个值可能存在,⽆法判断必然存在的原因。但是反过来,如果该值 根据 Hash 函数计算的标记位没有全部都为1,那么则说明必然不存在,这个是肯定的。
降低这种误判率的思路也⽐较简单:
• ⼀个是加⼤ bitSet 的⻓度,这样不同的值出现“冲突”的概率就降低了,从⽽误判率也降低。
• 提升 Hash 函数的个数,Hash 函数越多,每个值对应的 bit 越多,从⽽误判率也降低。 布隆过滤器的误判率还有专⻔的推导公式,有兴趣的可以去搜相关的⽂章和论⽂查看
7.42、缓存击穿
描述:某⼀个热点 key,在缓存过期的⼀瞬间,同时有⼤量的请求打进来,由于此时缓存过期了,所 以请求最终都会⾛到数据库,造成瞬时数据库请求量⼤、压⼒骤增,甚⾄可能打垮数据库。
解决⽅案:
1)加互斥锁。在并发的多个请求中,只有第⼀个请求线程能拿到锁并执⾏数据库查询操作,其他的 线程拿不到锁就阻塞等着,等到第⼀个线程将数据写⼊缓存后,直接⾛缓存。 关于互斥锁的选择,⽹上看到的⼤部分⽂章都是选择 Redis 分布式锁,因为这个可以保证只有⼀个请 求会⾛到数据库,这是⼀种思路。 但是其实仔细想想的话,这边其实没有必要保证只有⼀个请求⾛到数据库,只要保证⾛到数据库的请 求能⼤⼤降低即可,所以还有另⼀个思路是 JVM 锁。 JVM 锁保证了在单台服务器上只有⼀个请求⾛到数据库,通常来说已经⾜够保证数据库的压⼒⼤⼤降 低,同时在性能上⽐分布式锁更好。 需要注意的是,⽆论是使⽤“分布式锁”,还是“JVM 锁”,加锁时要按 key 维度去加锁。 我看⽹上很多⽂章都是使⽤⼀个“固定的 key”加锁,这样会导致不同的 key 之间也会互相阻塞,造 成性能严重损耗。 使⽤ redis 分布式锁的伪代码,仅供参考
public Object getData(String key) throws InterruptedException {Object value = redis.get(key);// 缓存值过期if (value == null) {// lockRedis:专⻔⽤于加锁的redis;// "empty":加锁的值随便设置都可以if (lockRedis.set(key, "empty", "PX", lockExpire, "NX")) {try {// 查询数据库,并写到缓存,让其他线程可以直接⾛缓存value = getDataFromDb(key);redis.set(key, value, "PX", expire);} catch (Exception e) {// 异常处理} finally {// 释放锁lockRedis.delete(key);}} else {// sleep50ms后,进⾏重试Thread.sleep(50);return getData(key);}}return value;}
2)热点数据不过期。直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。 这种⽅式适⽤于⽐较极端的场景,例如流量特别特别⼤的场景,使⽤时需要考虑业务能接受数据不⼀ 致的时间,还有就是异常情况的处理,不要到时候缓存刷新不上,⼀直是脏数据,那就凉了
7.43、缓存雪崩
描述:⼤量的热点 key 设置了相同的过期时间,导在缓存在同⼀时刻全部失效,造成瞬时数据库请求 量⼤、压⼒骤增,引起雪崩,甚⾄导致数据库被打挂。
缓存雪崩其实有点像“升级版的缓存击穿”,缓存击穿是⼀个热点 key,缓存雪崩是⼀组热点 key。
解决⽅案:
1)过期时间打散。既然是⼤量缓存集中失效,那最容易想到就是让他们不集中⽣效。可以给缓存的 过期时间时加上⼀个随机值时间,使得每个 key 的过期时间分布开来,不会集中在同⼀时刻失效
2)热点数据不过期。该⽅式和缓存击穿⼀样,也是要着重考虑刷新的时间间隔和数据异常如何处理 的情况。
3)加互斥锁。该⽅式和缓存击穿⼀样,按 key 维度加锁,对于同⼀个 key,只允许⼀个线程去计 算,其他线程原地阻塞等待第⼀个线程的计算结果,然后直接⾛缓存即可
第⼋章:分布式
8.1、分布式都有哪些内容?
分布式分为分布式缓存(Redis)、分布式锁(Redis或Zookeeper)、分布式服务(Dubbo或 SpringCloud)、分布式服务协调(Zookeeper)、分布式消息队列(Kafka、RabbitMq)、分布式 Session、分布式事务、分布式搜索(elastaticSearch)等
8.2、分布式有哪些理论?
CAP、BASE。
分布式CAP理论,任何⼀个分布式系统都⽆法同时满⾜Consistency(⼀致性)、Availability(可⽤ 性)、Partition tolerance(分区容错性) 这三个基本需求。最多只能满⾜其中两项。Partition tolerance(分区容错性) 是必须的,因此⼀般是CP,或者AP。
BASE是Basically Available(基本可⽤)、Soft state(软状态)和Eventually consistent(最终⼀ 致性)三个短语的简写,BASE是对CAP中⼀致性和可⽤性权衡的结果,其来源于对⼤规模互联⽹系 统分布式实践的结论,是基于CAP定理逐步演化⽽来的,其核⼼思想是即使⽆法做到强⼀致性 (Strong consistency),但每个应⽤都可以根据⾃⾝的业务特点,采⽤适当的⽅式来使系统达到最 终⼀致性(Eventual consistency)。
8.3、Dubbo 和 Spring Cloud 有什么区别?
1)通信⽅式不同
1、Dubbo 使⽤的是 RPC 通信,⽽ Spring Cloud 使⽤的是 HTTP RESTFul ⽅式。
2、Dubbo 由于是⼆进制的传输,占⽤带宽会更少(基于netty等);SpringCloud 是http协议传 输,带宽会⽐较较多,同时使⽤http协议(http+restful api)⼀般会使⽤JSON报⽂,消耗会更⼤。
3、Dubbo 的开发难度较⼤,原因是 Dubbo 的jar包依赖(存在代码级别的强依赖)问题很多⼤型⼯ 程⽆法解决;SpringCloud的接⼝协议约定⽐较⾃由且松散,需要有强有⼒的⾏政措施来限制接⼝⽆ 序升级。
4、Dubbo 的改进是通过 Dubbofilter ,很多东西没有,需要⾃⼰继承,如监控,如⽇志,如限流, 如追踪。 Spring Cloud具有配置管理、服务发现、断路器、智能路由、微代理、控制总线、⼀次性token、全 局锁、选主、分布式会话和集群状态等,满⾜了构建微服务所需的所有解决⽅案。
2)组成部分不同
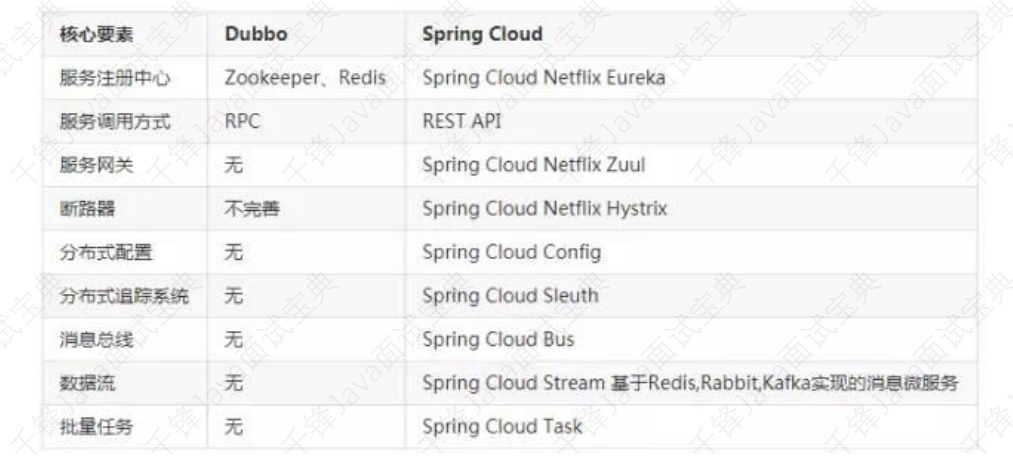
8.4、什么是RPC?为什么要有 RPC,HTTP 不好么?
RPC 就是 Remote Procedure Call,远程过程调⽤,它相对应的是本地过程调⽤。
RPC 和 HTTP 就不是⼀个层级的东西,所以严格意义上这两个没有可⽐性,也不应该来作⽐较。 HTTP 只是传输协议,协议只是规范了⼀定的交流格式,⽽且 RPC 是早于 HTTP 的,所以真要问也是 问有 RPC 为什么还要 HTTP。
RPC 对⽐的是本地过程调⽤,是⽤来作为分布式系统之间的通信,它可以⽤ HTTP 来传输,也可以基 于 TCP ⾃定义协议传输。
HTTP 协议⽐较冗余,所以 RPC ⼤多都是基于 TCP ⾃定义协议,定制化的才是最适合⾃⼰的。
当然也有基于 HTTP 协议的 RPC 框架,毕竟 HTTP 是公开的协议,⽐较通⽤,像 HTTP2 已经做了相 应的压缩了,⽽且系统之间的调⽤都在内⽹,所以说影响也不会很⼤
8.5、如果让你设计⼀个 RPC 框架,如何设计?
⾸先需要实现⾼性能的⽹络传输,可以采⽤ Netty 来实现,不⽤⾃⼰重复造轮⼦,然后需要⾃定义协 议,毕竟远程交互都需要遵循⼀定的协议,然后还需要定义好序列化协议,⽹络的传输毕竟都是⼆进 制流传输的。
然后可以搞⼀套描述服务的语⾔,即 IDL(Interface description language),让所有的服务都⽤ IDL 定义,再由框架转换为特定编程语⾔的接⼝,这样就能跨语⾔了。
此时最近基本的功能已经有了,但是只是最基础的,⼯业级的话⾸先得易⽤,所以框架需要把上述的 细节对使⽤者进⾏屏蔽,让他们感觉不到本地调⽤和远程调⽤的区别,所以需要代理实现。
然后还需要实现集群功能,因此的要服务发现、注册等功能,所以需要注册中⼼,当然细节还是需要 屏蔽的。
最后还需要⼀个完善的监控机制,埋点上报调⽤情况等等,便于运维
8.6、请说⼀下服务暴露的流程?
服务的暴露起始于 Spring IOC 容器刷新完毕之后,会根据配置参数组装成 URL, 然后根据 URL 的 参数来进⾏本地或者远程调⽤。
会通过 proxyFactory.getInvoker ,利⽤ javassist 来进⾏动态代理,封装真的实现类,然后 再通过 URL 参数选择对应的协议来进⾏ protocol.export,默认是 Dubbo 协议
在第⼀次暴露的时候会调⽤ createServer 来创建 Server,默认是 NettyServer。 然后将 export 得到的 exporter 存⼊⼀个 Map 中,供之后的远程调⽤查找,然后会向注册中⼼注册 提供者的信息
8.7、服务引⼊的流程是什么?
服务的引⼊时机有两种,第⼀种是饿汉式,第⼆种是懒汉式。
饿汉式就是加载完毕就会引⼊,懒汉式是只有当这个服务被注⼊到其他类中时启动引⼊流程,默认是 懒汉式。
会先根据配置参数组装成 URL ,⼀般⽽⾔我们都会配置的注册中⼼,所以会构建 RegistryDirectory 向注册中⼼注册消费者的信息,并且订阅提供者、配置、路由等节点。
得知提供者的信息之后会进⼊ Dubbo 协议的引⼊,会创建 Invoker ,期间会包含 NettyClient,来进 ⾏远程通信,最后通过 Cluster 来包装 Invoker,默认是 FailoverCluster,最终返回代理类
8.8、服务调⽤的流程是什么?
调⽤某个接⼝的⽅法会调⽤之前⽣成的代理类,然后会从 cluster 中经过路由的过滤、负载均衡机制 选择⼀个 invoker 发起远程调⽤,此时会记录此请求和请求的 ID 等待服务端的响应。
服务端接受请求之后会通过参数找到之前暴露存储的 map,得到相应的 exporter ,然后最终调⽤真 正的实现类,再组装好结果返回,这个响应会带上之前请求的 ID。
消费者收到这个响应之后会通过 ID 去找之前记录的请求,然后找到请求之后将响应塞到对应的 Future 中,唤醒等待的线程,最后消费者得到响应,⼀个流程完毕。
关键的就是 cluster、路由、负载均衡,然后 Dubbo 默认是异步的,所以请求和响应是如何对应上 的
8.9、什么是SPI?
不论是从 Dubbo 协议,还是 cluster ,什么 export ⽅法等等⽆处不是 SPI 的影⼦,所以如果是问 Dubbo ⽅⾯的问题,问 SPI 是⽏庸置疑的,因为源码⾥ SPI ⽆处不在,⽽且 SPI 也是 Dubbo 可扩展 性的基⽯
SPI 是 Service Provider Interface,主要⽤于框架中,框架定义好接⼝,不同的使⽤者有不同的需 求,因此需要有不同的实现,⽽ SPI 就通过定义⼀个特定的位置,Java SPI 约定在 Classpath 下的 META-INF/services/ ⽬录⾥创建⼀个以服务接⼝命名的⽂件,然后⽂件⾥⾯记录的是此 jar 包提供的 具体实现类的全限定名。
所以就可以通过接⼝找到对应的⽂件,获取具体的实现类然后加载即可,做到了灵活的替换具体的实 现类。
8.10、Dubbo 不⽤ JDK 的 SPI,⽽是要⾃⼰实现
因为 Java SPI 在查找扩展实现类的时候遍历 SPI 的配置⽂件并且将实现类全部实例化,假设⼀个实 现类初始化过程⽐较消耗资源且耗时,但是你的代码⾥⾯⼜⽤不上它,这就产⽣了资源的浪费。
因此 Dubbo 就⾃⼰实现了⼀个 SPI,给每个实现类配了个名字,通过名字去⽂件⾥⾯找到对应的实 现类全限定名然后加载实例化,按需加载
8.11、Dubbo 为什么默认⽤ Javassist?
速度快,且字节码⽣成⽅便。
ASM ⽐ Javassist 更快,但是没有快⼀个数量级,⽽Javassist 只需⽤字符串拼接就可以⽣成字节码, ⽽ ASM 需要⼿⼯⽣成,成本较⾼,⽐较⿇烦
8.12、为什么需要锁?
原因其实很简单:因为我们想让同⼀时刻只有⼀个线程在执⾏某段代码。
因为如果同时出现多个线程去执⾏,可能会带来我们不想要的结果,可能是数据错误,也可能是服务 宕机等等。
以淘宝双11为例,在0点这⼀刻,如果有⼏⼗万甚⾄上百万的⼈同时去查看某个商品的详情,这时候 会触发商品的查询,如果我们不做控制,全部⾛到数据库去,那是有可能直接将数据库打垮的。
这个时候⼀个⽐较常⽤的做法就是进⾏加锁,只让1个线程去查询,其他线程待等待这个线程的查询 结果后,直接拿结果。在这个例⼦中,锁⽤于控制访问数据库的流量,最终起到了保护系统的作⽤
再举个例⼦,某平台做活动“秒杀茅台”,假如活动只秒杀1瓶,但是同时有10万⼈在同⼀时刻去 抢,如果底层不做控制,有10000个⼈抢到了,额外的9999瓶平台就要⾃⼰想办法解决了。此时,我 们可以在底层通过加锁或者隐式加锁的⽅式来解决这个问题。
此外,锁也经常⽤来解决并发下的数据安全⽅⾯的问题,这⾥就不⼀⼀举例了
8.13、为什么需要分布式锁?
分布式锁是锁的⼀种,通常⽤来跟 JVM 锁做区别。
JVM 锁就是我们常说的 synchronized、Lock。
JVM 锁只能作⽤于单个 JVM,可以简单理解为就是单台服务器(容器),⽽对于多台服务器之间,
JVM 锁则没法解决,这时候就需要引⼊分布式锁
8.14、实现分布式锁的⽅式
实现分布式锁的⽅式其实很多,只要能保证对于抢夺“锁”的系统来说,这个东西是唯⼀的,那么就 能⽤于实现分布式锁。
举个简单的例⼦,有⼀个 MySQL 数据库 Order,Order 库⾥有个 Lock 表只有⼀条记录,该记录有个 状态字段 lock_status,默认为0,表⽰空闲状态,可以修改为1,表⽰成功获取锁。我们的订单系统 部署在100台服务器上,这100台服务器可以在“同⼀时刻”对上述的这1条记录执⾏修改,修改内容 都是从0修改为1,但是 MysQL 会保证最终只会有1个线程修改成功。因此,这条记录其实就可以⽤于 做分布式锁。
常⻅实现分布式锁的⽅式有:数据库、Redis、Zookeeper。这其中⼜以 Redis 最为常⻅
8.15、分布式锁如何实现?
RedLock
⾸先,该⽅案也是基于之前的那个⽅案(set加锁、lua脚本解锁)进⾏改良的,所以 antirez 只描述 了差异的地⽅,⼤致⽅案如下。
假设我们有 N 个 Redis 主节点,例如 N = 5,这些节点是完全独⽴的,我们不使⽤复制或任何其他隐 式协调系统,为了取到锁,客⼾端应该执⾏以下操作
1、获取当前时间,以毫秒为单位。
2、依次尝试从5个实例,使⽤相同的 key 和随机值(例如UUID)获取锁。当向Redis 请求获取锁 时,客⼾端应该设置⼀个超时时间,这个超时时间应该⼩于锁的失效时间。例如你的锁⾃动失效时间 为10秒,则超时时间应该在 5-50 毫秒之间。这样可以防⽌客⼾端在试图与⼀个宕机的 Redis 节点对 话时⻓时间处于阻塞状态。如果⼀个实例不可⽤,客⼾端应该尽快尝试去另外⼀个Redis实例请求获 取锁。
3、客⼾端通过当前时间减去步骤1记录的时间来计算获取锁使⽤的时间。当且仅当从⼤多数 (N/2+1,这⾥是3个节点)的Redis节点都取到锁,并且获取锁使⽤的时间⼩于锁失效时间时,锁才 算获取成功。
4、如果取到了锁,其有效时间等于有效时间减去获取锁所使⽤的时间(步骤3计算的结果)。
5、如果由于某些原因未能获得锁(⽆法在⾄少N/2+1个Redis实例获取锁、或获取锁的时间超过了有 效时间),客⼾端应该在所有的Redis实例上进⾏解锁(即便某些Redis实例根本就没有加锁成功,防 ⽌某些节点获取到锁但是客⼾端没有得到响应⽽导致接下来的⼀段时间不能被重新获取锁)。
可以看出,该⽅案为了解决数据不⼀致的问题,直接舍弃了异步复制,只使⽤ master 节点,同时由 于舍弃了 slave,为了保证可⽤性,引⼊了 N 个节点,官⽅建议是 。
该⽅案看着挺美好的,但是实际上我所了解到的在实际⽣产上应⽤的不多,主要有两个原因:
1)该 ⽅案的成本似乎有点⾼,需要使⽤5个实例;
2)该⽅案⼀样存在问题。
该⽅案主要存以下问题:
1)严重依赖系统时钟。如果线程1从3个实例获取到了锁,但是这3个实例中的某个实例的系统时间⾛ 的稍微快⼀点,则它持有的锁会提前过期被释放,当他释放后,此时⼜有3个实例是空闲的,则线程2 也可以获取到锁,则可能出现两个线程同时持有锁了。
2)如果线程1从3个实例获取到了锁,但是万⼀其中有1台重启了,则此时⼜有3个实例是空闲的,则 线程2也可以获取到锁,此时⼜出现两个线程同时持有锁了。
针对以上问题其实后续也有⼈给出⼀些相应的解法,但是整体上来看还是不够完美,所以⽬前实际应 ⽤得不是那么多。
Zookeeper 实现分布式锁
Zookeeper 的分布式锁实现⽅案如下:
1)创建⼀个锁⽬录 /locks,该节点为持久节点
2)想要获取锁的线程都在锁⽬录下创建⼀个临时顺序节点
3)获取锁⽬录下所有⼦节点,对⼦节点按节点⾃增序号从⼩到⼤排序
4)判断本节点是不是第⼀个⼦节点,如果是,则成功获取锁,开始执⾏业务逻辑操作;如果不是, 则监听⾃⼰的上⼀个节点的删除事件
5)持有锁的线程释放锁,只需删除当前节点即可。
6)当⾃⼰监听的节点被删除时,监听事件触发,则回到第3步重新进⾏判断,直到获取到锁
由于 Zookeeper 保证了数据的强⼀致性,因此不会存在之前 Redis ⽅案中的问题,整体上来看还是 ⽐较不错的。
Zookeeper 的主要问题在于性能不如 Redis 那么好,当申请锁和释放锁的频率较⾼时,会对集群造成 压⼒,此时集群的稳定性可⽤性能可能⼜会遭受挑战
8.16、分布式锁如何选型?
当前主流的⽅案有两种:
1)Redis 的 set 加锁+lua 脚本解锁⽅案, ⾄于是不是⽤守护线程续命可以结合⾃⼰的场景去决定, 个⼈建议还是可以使⽤的。
2)Zookeeper ⽅案 通常情况下,对于数据的安全性要求没那么⾼的,可以采⽤ Redis 的⽅案,对数据安全性要求⽐较⾼ 的可以采⽤ Zookeeper 的⽅案
8.17、Zookeeper做为注册中⼼,主要存储哪些数据?存储在哪⾥?
ip、端⼝,还有⼼跳机制。数据存储在Zookeeper的节点上⾯。
8.18、Zookeeper 和 Eureka 的区别
Eureka和Zookeeper都是CAP定理中的实现,Eureka(保证AP),Zookeeper(保证CP)。
Zookeeper保证CP,当向注册中⼼查询服务列表时,我们可以容忍注册中⼼返回的是⼏分钟以前的注 册信息,但不能接受服务直接down掉不可⽤。也就是说服务注册功能对可⽤性的要求要⾼于⼀致 性、但是zk会出现这样⼀种情况当master节点因为⽹络故障与其他节点失去联系时,剩余节点会重新 进⾏leader选举。问题在于,选举leader的时间太⻓,30〜120s.选举期间整个zk集群都是不可⽤ 的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因⽹络问题使得zk集群失去master节点 是较⼤概率会发⽣的事,虽然服务能够最终恢复,但是漫⻓的选举时间导致的注册⻓期不可⽤是不能 容忍的。
Eureka吸取了Zookeeper的经验,因此在设计时就优先保证可⽤性。Eureka各个节点都是平等的, ⼏个节点挂掉不会影响正常节点的⼯作剩余的节点依然可以提供注册和查询服务。⽽Eureka的客⼾端 在向某个Eureka注册或时如果发现连接⽣败,则会⾃动切换⾄其它节点,只要有⼀台Eureka还在就能保证注册服务可⽤(保证可⽤性)只不过查到的信息可能不是最新的(不保证强⼀致性)。除此之 外,Eureka还有⼀种⾃我保护机制如果在15分钟内超过85%的节点都没有正常的⼼跳,那么Eureka 就认为客⼾端与注册中⼼出现了⽹络故障,此时会出现以下⼏种情况∶
1)Eureka不再从注册列表中移除因为⻓时间没收到⼼跳⽽应该过期的服务
2)Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点 依然可⽤)
3)当⽹络稳定时,当前实例新的注册信息会被同步到其它节点中 因此,Eureka可以很好的应对因⽹络故障导致部分节点失去联系的情况,⽽不会像zookeeper那样使 整个注册服务瘫痪。
Zookeeper的设计理念就是分布式协调服务,保证数据(配置数据,状态数据)在多个服务系统之间 保证⼀致性,这也不难看出Zookeeper是属于CP特性(Zookeeper的核⼼算法是ZAB,保证分布式系 统下,数据如何在多个服务之间保证数据同步)。Eureka是吸取Zookeeper问题的经验,先保证可⽤ 性。
8.19、Kafka相对其他消息队列,有什么特点?
持久化:Kafka的持久化能⼒⽐较好,通过磁盘持久化。⽽RabbitMQ是通过内存持久化的。
吞吐量:Rocket的并发量⾮常⾼。
消息处理:RabbitMQ的消息不⽀持批量处理,⽽RocketMQ和Kafka⽀持批量处理。
⾼可⽤:RabbitMQ采⽤主从模式。Kafka也是主从模式,通过Zookeeper管理,选举Leader,还有 Replication副本。
事务:RocketMQ⽀持事务,⽽Kafka和RabbitMQ不⽀持
8.20、Kafka ⾼效⽂件存储设计特点有哪些?
1)Kafka 把 topic 中⼀个 parition ⼤⽂件分成多个⼩⽂件段,通过多个⼩⽂件段,就容易定 期清除或删除已经消费完⽂件,减少磁盘占⽤。
2)通过索引信息可以快速定位 message 和确定 response 的最⼤⼤⼩。
3)通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。
4)通过索引⽂件稀疏存储,可以⼤幅降低 index ⽂件元数据占⽤空间⼤⼩。

8.21、Kafka的ISR机制是什么?
Kafka的核⼼机制,就是ISR机制。
这个机制简单来说,就是会⾃动给每个Partition维护⼀个ISR列表,这个列表⾥⼀定会有Leader,然 后还会包含跟Leader保持同步的Follower。也就是说,只要Leader的某个Follower⼀直跟他保持数 据同步,那么就会存在于ISR列表⾥。
但是如果Follower因为⾃⾝发⽣⼀些问题,导致不能及时的从Leader同步数据过去,那么这个 Follower就会被认为是“out-of-sync”,从ISR列表⾥踢出去。所以⼤家先得明⽩这个ISR是什么, 说⽩了,就是Kafka⾃动维护和监控哪些Follower及时的跟上了Leader的数据同步
8.22、Kafka 如何解决数据丢失问题?
1、每个Partition都⾄少得有1个Follower在ISR列表⾥,跟上了Leader的数据同步。
2、每次写⼊数据的时候,都要求⾄少写⼊Partition Leader成功,同时还有⾄少⼀个ISR⾥的 Follower也写⼊成功,才算这个写⼊是成功了
3、如果不满⾜上述两个条件,那就⼀直写⼊失败,让⽣产系统不停的尝试重试,直到满⾜上述两个 条件,然后才能认为写⼊成功
4、按照上述思路去配置相应的参数,才能保证写⼊Kafka的数据不会丢失 好!现在咱们来分析⼀下上⾯⼏点要求
第⼀条,必须要求⾄少⼀个Follower在ISR列表⾥
那必须的啊,要是Leader没有Follower了,或者是Follower都没法及时同步Leader数据,那么这个 事⼉肯定就没法弄下去了。
第⼆条,每次写⼊数据的时候,要求leader写⼊成功以外,⾄少⼀个ISR⾥的Follower也写成功。⼤ 家看下⾯的图,这个要求就是保证说,每次写数据,必须是leader和follower都写成功了,才能算是 写成功,保证⼀条数据必须有两个以上的副本。这个时候万⼀leader宕机,就可以切换到那个 follower上去,那么Follower上是有刚写⼊的数据的,此时数据就不会丢失了
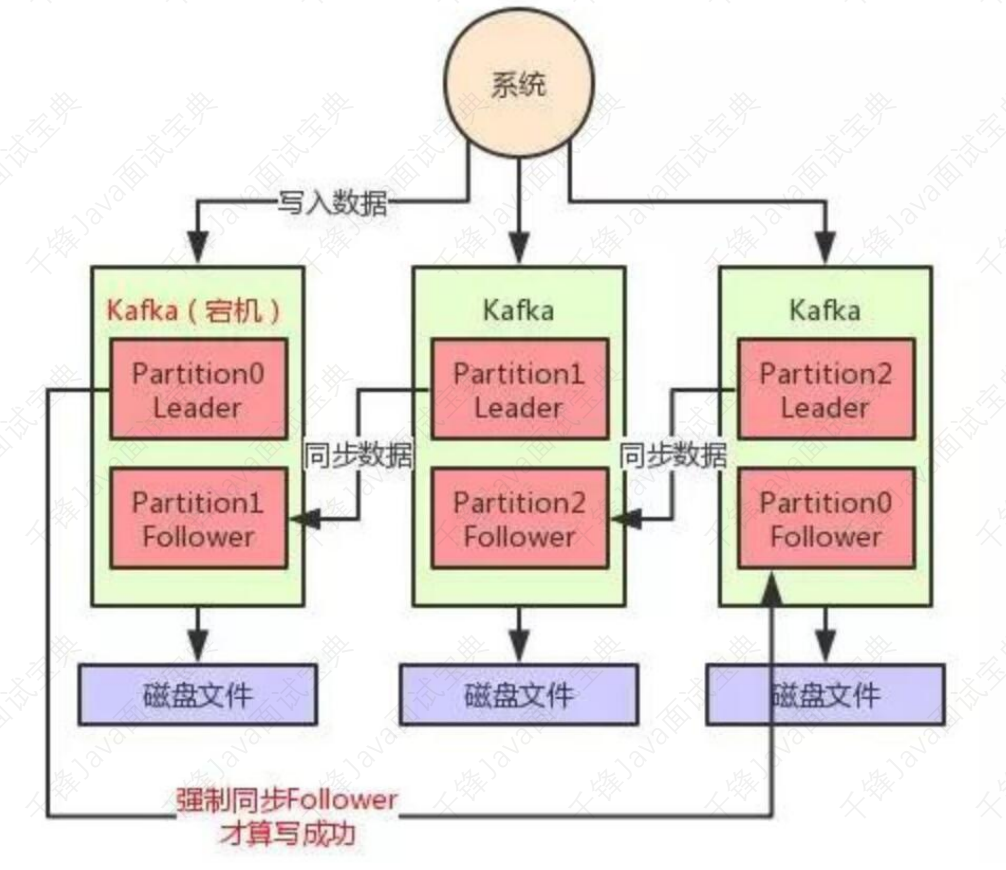
8.23、MQ的原理是什么
消息队列技术是分布式应⽤间交换信息的⼀种技术。消息队列可驻留在内存或磁盘上,队列存储消息直 到它们被应⽤程序读⾛。通过消息队列,应⽤程序可独⽴地执⾏—它们不需要知道彼此的位置、或在 继续执⾏前不需要等待接收程序接收此消息。
在分布式计算环境中,为了集成分布式应⽤,开发者需要对异构⽹络环境下的分布式应⽤提供有效的 通信⼿段。为了管理需要共享的信息,对应⽤提供公共的信息交换机制是重要的
消息队列为构造以同步或异步⽅式实现的分布式应⽤提供了松耦合⽅法。消息队列的API调⽤被嵌⼊ 到新的或现存的应⽤中,通过消息发送到内存或基于磁盘的队列或从它读出⽽提供信息交换。消息队 列可⽤在应⽤中以执⾏多种功能,⽐如要求服务、交换信息或异步处理等。
中间件是⼀种独⽴的系统软件或服务程序,分布式应⽤系统借助这种软件在不同的技术之间共享资 源,管理计算资源和⽹络通讯。它在计算机系统中是⼀个关键软件,它能实现应⽤的互连和互操作 性,能保证系统的安全、可靠、⾼效的运⾏。
中间件位于⽤⼾应⽤和操作系统及⽹络软件之间,它为应⽤提供了公⽤的通信⼿段,并且独⽴于⽹络 和操作系统。
中间件为开发者提供了公⽤于所有环境的应⽤程序接⼝,当应⽤程序中嵌⼊其函数调⽤,它便可利⽤ 其运⾏的特定操作系统和⽹络环境的功能,为应⽤执⾏通信功能。
如果没有消息中间件完成信息交换,应⽤开发者为了传输数据,必须要学会如何⽤⽹络和操作系统软 件的功能,编写相应的应⽤程序来发送和接收信息,且交换信息没有标准⽅法,每个应⽤必须进⾏特 定的编程从⽽和多平台、不同环境下的⼀个或多个应⽤通信。
例如,为了实现⽹络上不同主机系统间的通信,将要求具备在⽹络上如何交换信息的知识(⽐如⽤ TCP/IP的socket程序设计);为了实现同⼀主机内不同进程之间的通讯,将要求具备操作系统的消息 队列或命名管道(Pipes)等知识。
MQ的通讯模式
- 点对点通讯:点对点⽅式是最为传统和常⻅的通讯⽅式,它⽀持⼀对⼀、⼀对多、多对多、多对⼀ 等多种配置⽅式,⽀持树状、⽹状等多种拓扑结构。
- 多点⼴播:MQ适⽤于不同类型的应⽤。其中重要的,也是正在发展中的是”多点⼴播”应⽤,即能 够将消息发送到多个⽬标站点(Destination List)。 可以使⽤⼀条MQ指令将单⼀消息发送到多个⽬标站点,并确保为每⼀站点可靠地提供信息。MQ不仅 提供了多点⼴播的功能,⽽且还拥有智能消息分发功能,在将⼀条消息发送到同⼀系统上的多个⽤⼾ 时,MQ将消息的⼀个复制版本和该系统上接收者的名单发送到⽬标MQ系统。 ⽬标MQ系统在本地复制这些消息,并将它们发送到名单上的队列,从⽽尽可能减少⽹络的传输量。
- 发布/订阅(Publish/Subscribe)模式:发布/订阅功能使消息的分发可以突破⽬的队列地理指向的限 制,使消息按照特定的主题甚⾄内容进⾏分发,⽤⼾或应⽤程序可以根据主题或内容接收到所需要的 消息。 发布/订阅功能使得发送者和接收者之间的耦合关系变得更为松散,发送者不必关⼼接收者的⽬的地 址,⽽接收者也不必关⼼消息的发送地址,⽽只是根据消息的主题进⾏消息的收发。 在MQ家族产品中,MQ Event Broker是专⻔⽤于使⽤发布/订阅技术进⾏数据通讯的产品,它⽀持基 于队列和直接基于TCP/IP两种⽅式的发布和订阅。
- 群集(Cluster):为了简化点对点通讯模式中的系统配置,MQ提供Cluster(群集)的解决⽅案。群集 类似于⼀个域(Domain),群集内部的队列管理器之间通讯时,不需要两两之间建⽴消息通道,⽽是 采⽤群集(Cluster)通道与其它成员通讯,从⽽⼤⼤简化了系统配置
8.24、MQ的持久化是怎么做的
以ActiveMq为例
ActiveMQ消息持久化⽅式,分别是:⽂件、mysql数据库、oracle数据库
a.⽂件持久化:
ActiveMQ默认的消息保存⽅式,⼀般如果没有修改过其他持久化⽅式的话可以不⽤修改配置⽂ 件
如果是修改过的,打开盘符:\apache-activemq-版本号\conf\activemq.xml,然后找到<persistenceAdapter>节点,将其替换成以下代码段<persistenceAdapter><kahaDB directory="${activemq.base}/data/kahadb"/></persistenceAdapter>然后修改配置⽂件(此处演⽰为spring+ActiveMQ),找到消息发送者所对应的JmsTemplate配置代码块,增加以下配置<!-- 是否持久化 DeliveryMode.NON_PERSISTENT=1:⾮持久 ; DeliveryMode.PERSISTENT=2:持久 --><property name="deliveryMode" value="2" />以下是JmsTemplate配置完整版<!-- Spring提供的JMS⼯具类,它可以进⾏消息发送、接收等 --><bean id="jmsTemplateOne" class="org.springframework.jms.core.JmsTemplate"><property name="connectionFactory" ref="connectionFactory"/><!-- 设置默认的消息⽬的地--><property name="defaultDestination" ref="queueDestination"/><property name="receiveTimeout" value="10000" /><!-- 是否持久化 DeliveryMode.NON_PERSISTENT=1:⾮持久 ; DeliveryMode.PERSISTENT=2:持久 --><property name="deliveryMode" value="2" /></bean>
这样就算配置完成了⽂件持久化⽅式了,重启项⽬和ActiveMQ,发送⼀定消息队列之后关闭 ActiveMQ服务,再启动,你可以看到之前发送的消息未消费的依然保持在⽂件⾥⾯,继续让监听者 消费
b.MySQL持久化
⾸先需要把MySql的驱动放到ActiveMQ的Lib⽬录下,我⽤的⽂件名字是:mysql-connectorjava-5.1.27.jar
然后打开盘符:\apache-activemq-版本号\conf\activemq.xml,然后找到 节点,将其替换成以下代码段
<persistenceAdapter><jdbcPersistenceAdapter dataDirectory="${activemq.base}/data" dataSource="#derby-ds"/></persistenceAdapter>在配置⽂件中的broker节点外增加以下代码<bean id="derby-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="com.mysql.jdbc.Driver"/><property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/><property name="username" value="root"/><property name="password" value="123456"/><property name="maxActive" value="200"/><property name="poolPreparedStatements" value="true"/></bean>
这样就算完成了mysql持久化配置了,验证⽅式同a,打开mysql数据库你能看到三张表,分别 是:activemq_acks,activemq_lock,activemq_msgs。
c.Oracle持久化
oracle的配置和mysql⼀样,在Lib⽬录下,放⼊oracle的驱动包,然后配置⼀下配置⽂件即可
<bean id="derby-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"><property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/><property name="url" value="jdbc:oracle:thin:@localhsot:1521:orcl"/><property name="username" value="activemq"/><property name="password" value="amqadmin"/><property name="maxActive" value="200"/><property name="poolPreparedStatements" value="true"/></bean>
8.25、zookeeper是什么
ZooKeeper 顾名思义 动物园管理员,他是拿来管⼤象(Hadoop) 、 蜜蜂(Hive) 、 ⼩猪(Pig) 的管理 员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项⽬中都采⽤到了 Zookeeper。
ZooKeeper是⼀个分布式的,开放源码的分布式应⽤程序协调服务,ZooKeeper是以Fast Paxos算法 为基础,实现同步服务,配置维护和命名服务等分布式应⽤
8.26、Zookeeper哪⾥⽤到
Zookeeper是针对⼤型分布式系统的⾼可靠的协调系统。由这个定义我们知道zookeeper是个协调系 统,作⽤的对象是分布式系统。为什么分布式系统需要⼀个协调系统了?理由如下:
开发分布式系统是件很困难的事情,其中的困难主要体现在分布式系统的“部分失败”。“部分失 败”是指信息在⽹络的两个节点之间传送时候,如果⽹络出了故障,发送者⽆法知道接收者是否收到 了这个信息,⽽且这种故障的原因很复杂,接收者可能在出现⽹络错误之前已经收到了信息,也可能 没有收到,⼜或接收者的进程死掉了。
发送者能够获得真实情况的唯⼀办法就是重新连接到接收者,询问接收者错误的原因,这就是分布式 系统开发⾥的“部分失败”问题。 Zookeeper就是解决分布式系统“部分失败”的框架。
Zookeeper不是让分布式系统避免“部分失 败”问题,⽽是让分布式系统当碰到部分失败时候,可以正确的处理此类的问题,让分布式系统能正 常的运⾏。
下⾯我要讲讲zookeeper的实际运⽤场景:
场景⼀:有⼀组服务器向客⼾端提供某种服务(例如:我前⾯做的分布式⽹站的服务端,就是由四台 服务器组成的集群,向前端集群提供服务),我们希望客⼾端每次请求服务端都可以找到服务端集群 中某⼀台服务器,这样服务端就可以向客⼾端提供客⼾端所需的服务。
对于这种场景,我们的程序中⼀定有⼀份这组服务器的列表,每次客⼾端请求时候,都是从这份列表 ⾥读取这份服务器列表。那么这分列表显然不能存储在⼀台单节点的服务器上,否则这个节点挂掉 了,整个集群都会发⽣故障,我们希望这份列表时⾼可⽤的
⾼可⽤的解决⽅案是:这份列表是分布式存储的,它是由存储这份列表的服务器共同管理的,如果存 储列表⾥的某台服务器坏掉了,其他服务器⻢上可以替代坏掉的服务器,并且可以把坏掉的服务器从 列表⾥删除掉,让故障服务器退出整个集群的运⾏,⽽这⼀切的操作⼜不会由故障的服务器来操作, ⽽是集群⾥正常的服务器来完成。
这是⼀种主动的分布式数据结构,能够在外部情况发⽣变化时候主动修改数据项状态的数据机构。 Zookeeper框架提供了这种服务。这种服务名字就是:统⼀命名服务,它和javaEE⾥的JNDI服务很 像。
场景⼆:分布式锁服务。当分布式系统操作数据,例如:读取数据、分析数据、最后修改数据。在分 布式系统⾥这些操作可能会分散到集群⾥不同的节点上,那么这时候就存在数据操作过程中⼀致性的 问题,如果不⼀致,我们将会得到⼀个错误的运算结果,在单⼀进程的程序⾥,⼀致性的问题很好解 决,但是到了分布式系统就⽐较困难,
因为分布式系统⾥不同服务器的运算都是在独⽴的进程⾥,运算的中间结果和过程还要通过⽹络进⾏ 传递,那么想做到数据操作⼀致性要困难的多。Zookeeper提供了⼀个锁服务解决了这样的问题,能 让我们在做分布式数据运算时候,保证数据操作的⼀致性。
场景三:配置管理。在分布式系统⾥,我们会把⼀个服务应⽤分别部署到n台服务器上,这些服务器 的配置⽂件是相同的(例如:我设计的分布式⽹站框架⾥,服务端就有4台服务器,4台服务器上的程 序都是⼀样,配置⽂件都是⼀样),
如果配置⽂件的配置选项发⽣变化,那么我们就得⼀个个去改这些配置⽂件,如果我们需要改的服务 器⽐较少,这些操作还不是太⿇烦,如果我们分布式的服务器特别多,⽐如某些⼤型互联⽹公司的 hadoop集群有数千台服务器,那么更改配置选项就是⼀件⿇烦⽽且危险的事情。
这时候zookeeper就可以派上⽤场了,我们可以把zookeeper当成⼀个⾼可⽤的配置存储器,把这样 的事情交给zookeeper进⾏管理,我们将集群的配置⽂件拷⻉到zookeeper的⽂件系统的某个节点 上,然后⽤zookeeper监控所有分布式系统⾥配置⽂件的状态,
⼀旦发现有配置⽂件发⽣了变化,每台服务器都会收到zookeeper的通知,让每台服务器同步 zookeeper⾥的配置⽂件,zookeeper服务也会保证同步操作原⼦性,确保每个服务器的配置⽂件都 能被正确的更新。
场景四:为分布式系统提供故障修复的功能。集群管理是很困难的,在分布式系统⾥加⼊了 zookeeper服务,能让我们很容易的对集群进⾏管理。
集群管理最⿇烦的事情就是节点故障管理,zookeeper可以让集群选出⼀个健康的节点作为master, master节点会知道当前集群的每台服务器的运⾏状况,⼀旦某个节点发⽣故障,master会把这个情 况通知给集群其他服务器,从⽽重新分配不同节点的计算任务。
Zookeeper不仅可以发现故障,也会对有故障的服务器进⾏甄别,看故障服务器是什么样的故障,如 果该故障可以修复,zookeeper可以⾃动修复或者告诉系统管理员错误的原因让管理员迅速定位问 题,修复节点的故障。
⼤家也许还会有个疑问,master故障了,那怎么办了?zookeeper也考虑到了这点,zookeeper内部 有⼀个“选举领导者的算法”,master可以动态选择,当master故障时候,zookeeper能⻢上选出 新的master对集群进⾏管理
下⾯我要讲讲zookeeper的特点:
zookeeper是⼀个精简的⽂件系统。这点它和hadoop有点像,但是zookeeper这个⽂件系统是管理 ⼩⽂的,⽽hadoop是管理超⼤⽂件的。
zookeeper提供了丰富的“构件”,这些构件可以实现很多协调数据结构和协议的操作。例如:分布 式队列、分布式锁以及⼀组同级节点的“领导者选举”算法。
zookeeper是⾼可⽤的,它本⾝的稳定性是相当之好,分布式集群完全可以依赖zookeeper集群的管 理,利⽤zookeeper避免分布式系统的单点故障的问题。
zookeeper采⽤了松耦合的交互模式。这点在zookeeper提供分布式锁上表现最为明显,zookeeper 可以被⽤作⼀个约会机制,让参⼊的进程不在了解其他进程的(或⽹络)的情况下能够彼此发现并进 ⾏交互,参⼊的各⽅甚⾄不必同时存在,只要在zookeeper留下⼀条消息,在该进程结束后,另外⼀ 个进程还可以读取这条信息,从⽽解耦了各个节点之间的关系。
zookeeper为集群提供了⼀个共享存储库,集群可以从这⾥集中读写共享的信息,避免了每个节点的 共享操作编程,减轻了分布式系统的开发难度。
zookeeper的设计采⽤的是观察者的设计模式,zookeeper主要是负责存储和管理⼤家关⼼的数据, 然后接受观察者的注册,⼀旦这些数据的状态发⽣变化,Zookeeper 就将负责通知已经在 Zookeeper 上注册的那些观察者做出相应的反应,从⽽实现集群中类似 Master/Slave 管理模式
8.27、zookeeper的选主过程
1 . 接收投票消息。投票消息会包括id,zxid,epoch,state,这四种信息,分别代表
Id: 唯⼀标识⼀台机器,存储在myid⽂件中
Zxid: 标识了本机想要选举谁为leader,是本机⽬前所⻅到的最⼤的id值
Epoch: 逻辑时钟。⽤于判断选举是否过期
State: 本机的状态信息(包括looking,leading,following,observing)
2 .判断PeerState状态,如果是looking状态,则继续.如果是leading,foolowing,observing则⾛别的 流程
3 .收到票后,会判断发送过来的逻辑时钟是否⼤于⽬前的逻辑时钟,如果是说明集群已经进⼊了新⼀ 轮的投票了。
4 .清空投票箱。因为这个之前的投票都是上⼀次投票期间维护的。
5 . 如果等于⽬前的逻辑时钟,说明是当前的,则更新最⼤的leader id和提案id 判断是否需要更新当前⾃⼰的选举情况.在这⾥是根据选举leader id,保存的最⼤数据id来进⾏判断的, 这两种数据之间对这个选举结果的影响的权重关系是:⾸先看数据id,数据id⼤者胜出;其次再判断 leader id,leader id⼤者胜出
判读投票结果代码
6 . 发送通知,通知其他的QuorumPeer更新leader信息.同时将更新后的leader信息放⼊投票箱 检查是否已经接收到了所有服务器的投票代码参考。如果是的,则设置⾃⼰的选择结果 如果没有接收到所有服务器的投票,那判读这个leadId是否得到了⼀半以后的服务器的投票代码参 考,如果是则返回
以上流程描述的是在zookeeper中,参考使⽤的算法是FastLeaderElection 在zookeeper的的选主的流程,另外还提供了LeaderElection和AuthFastLeaderElection的实现
LeaderElection的实现⽐较简单。以(id,zxid)做为投票的依据.并且它的实现是同步的,需要等待所有 服务器返回后再统计结果。
⽽相⽐FastLeaderElection是每次收到回复都会计算投票结果,效率上会⽐LeaderElection更好⼀ 些
8.28、zookeeper集群之间如何通讯
Zookeeper的通信架构
在Zookeeper整个系统中,有3中⻆⾊的服务,client、Follower、leader。其中client负责发起应⽤ 的请求,Follower接受client发起的请求,参与事务的确认过程,在leader crash后的leader选择。
⽽leader主要承担事务的协调,当然leader也可以承担接收客⼾请求的功能,为了⽅便描述,后⾯的 描述都是client与Follower之间的通信,如果Zookeeper的配置⽀持leader接收client的请求,client 与leader的通信跟client与Follower的通信模式完全⼀样。
Follower与leader之间的⻆⾊可能在某⼀时刻进⾏转换。⼀个Follower在leader crash掉以后可能被 集群(Quorum)的Follower选举为leader。⽽⼀个leader在crash后,再次加⼊集群(Quorum)将 作为Follower⻆⾊存在。
在⼀个集群(Quorum)中,除了在选举leader的过程中没有Follower和leader的区分外,其他任何时 刻都只有1个leader和多个Follower。Client、Follower和leader之间的通信架构如下:
Client与Follower之间
为了使客⼾端具有较⾼的吞吐量,Client与Follower之间采⽤NIO的通信⽅式。当client需要与 Zookeeper service打交道时,⾸先读取配置⽂件确定集群内的所有server列表,按照⼀定的load balance算法选取⼀个Follower作为⼀个通信⽬标。
这样client和Follower之间就有了⼀条由NIO模式构成的通信通道。这条通道会⼀直保持到client关闭 session或者因为client或Follower任⼀⽅因某种原因异常中断通信连接。正常情况下, client与 Follower在没有请求发起的时候都有⼼跳检测
Follower与leader之间
Follower与leader之间的通信主要是因为Follower接收到像(create, delete, setData, setACL, createSession, closeSession, sync)这样⼀些需要让leader来协调最终结果的命令,将会导致 Follower与leader之间产⽣通信
由于leader与Follower之间的关系式⼀对多的关系,⾮常适合client/server模式,因此他们之间是采 ⽤c/s模式,由leader创建⼀个socket server,监听各Follower的协调请求。
集群在选择leader过程中
由于在选择leader过程中没有leader,在集群中的任何⼀个成员都需要与其他所有成员进⾏通信,当 集群的成员变得很⼤时,这个通信量是很⼤的。
选择leader的过程发⽣在Zookeeper系统刚刚启动或者是leader失去联系后,选择leader过程中将不 能处理⽤⼾的请求,为了提⾼系统的可⽤性,⼀定要尽量减少这个过程的时间。选择哪种⽅式让他们 可⽤快速得到选择结果呢?
Zookeeper在这个过程中采⽤了策略模式,可⽤动态插⼊选择leader的算法。系统默认提供了3种选 择算法,AuthFastLeaderElection,FastLeaderElection,LeaderElection。
其中AuthFastLeaderElection和LeaderElection采⽤UDP模式进⾏通信,⽽FastLeaderElection仍然 采⽤tcp/ip模式。在Zookeeper新的版本中,新增了⼀个learner⻆⾊,减少选择leader的参与⼈数。 使得选择过程更快。
⼀般说来Zookeeper leader的选择过程都⾮常快,通常<200ms。
Zookeeper的通信流程
要详细了解Zookeeper的通信流程,我们⾸先得了解Zookeeper提供哪些客⼾端的接⼝,我们按照具 有相同的通信流程的接⼝进⾏分组:
Zookeeper系统管理命令 Zookeeper的系统管理接⼝是指⽤来查看Zookeeper运⾏状态的⼀些命令,他们都是具有4字⺟构成 的命令格式。主要包括:
ruok:发送此命令可以测试zookeeper是否运⾏正常。
dump:dump server端所有存活session的Ephemeral(临时)node信息。
stat:获取连接server的服务器端的状态及连接该server的所有客服端的状态信息。
reqs: 获取当前客⼾端已经提交但还未返回的请求。
stmk:开启或关闭Zookeeper的trace level.
gtmk:获取当前Zookeeper的trace level是否开启。
envi: 获取Zookeeper的java相关的环境变量。
srst:重置server端的统计状态 当⽤⼾发送这些命令的到server时,由于这些请求只与连接的server相关,没有业务处理逻辑,⾮常 简单。Zookeeper对这些命令采⽤最快的效率进⾏处理。这些命令发送到server端只占⽤⼀个4字节 的int类型来表⽰不同命令,没有采⽤字符串处理。当服务器端接收到这些命令,⽴刻返回结果。
Session创建
任何客⼾端的业务请求都是基于session存在的前提下。Session是维持client与Follower之间的⼀条 通信通道,并维持他们之间从创建开始后的所有状态
当启动⼀个Zookeeper client的时候,⾸先按照⼀定的算法查找出follower, 然后与Follower建⽴起 NIO连接。当连接建⽴好后,发送create session的命令,让server端为该连接创建⼀个维护该连接状 态的对象session。当server收到create session命令,先从本地的session列表中查找看是否已经存 在有相同sessionId,
则关闭原session重新创建新的session。创建session的过程将需要发送到Leader,再由leader通知 其他follower,⼤部分Follower都将此操作记录到本地⽇志再通知leader后,leader发送commit命 令给所有Follower,
连接客⼾端的Follower返回创建成功的session响应。Leader与Follower之间的协调过程将在后⾯的 做详细讲解。当客⼾端成功创建好session后,其他的业务命令就可以正常处理了。
Zookeeper查询命令
Zookeeper查询命令主要⽤来查询服务器端的数据,不会更改服务器端的数据。所有的查询命令都可 以即刻从client连接的server⽴即返回,不需要leader进⾏协调,因此查询命令得到的数据有可能是 过期数据。
但由于任何数据的修改,leader都会将更改的结果发布给所有的Follower,因此⼀般说来,Follower 的数据是可以得到及时的更新。这些查询命令包括以下这些命令:
exists:判断指定path的node是否存在,如果存在则返回true,否则返回false.
getData:从指定path获取该node的数据 getACL:获取指定path的ACL。
getChildren:获取指定path的node的所有孩⼦结点。
所有的查询命令都可以指定watcher,通过它来跟踪指定path的数据变化。⼀旦指定的数据发⽣变化 (create,delete,modified,children_changed),服务器将会发送命令来回调注册的watcher. Watcher详细的讲解将在Zookeeper的Watcher中单独讲解。
Zookeeper修改命令
Zookeeper修改命令主要是⽤来修改节点数据或结构,或者权限信息。任何修改命令都需要提交到 leader进⾏协调,协调完成后才返回。修改命令主要包括:
1 . createSession:请求server创建⼀个session
2 . create:创建⼀个节点
3 . delete:删除⼀个节点
4 . setData:修改⼀个节点的数据
5 . setACL:修改⼀个节点的ACL
6 . closeSession:请求server关闭session
我们根据前⾯的通信图知道,任何修改命令都需要leader协调。 在leader的协调过程中,需要3次 leader与Follower之间的来回请求响应。并且在此过程中还会涉及事务⽇志的记录,更糟糕的情况是 还有take snapshot的操作。因此此过程可能⽐较耗时。但Zookeeper的通信中最⼤特点是异步的
如果请求是连续不断的,Zookeeper的处理是集中处理逻辑,然后批量发送,批量的⼤⼩也是有控制 的。如果请求量不⼤,则即刻发送。这样当负载很⼤时也能保证很⼤的吞吐量,时效性也在⼀定程度 上进⾏了保证。
zookeeper server端的业务处理-processor链
Zookeeper通过链式的processor来处理业务请求,每个processor负责处理特定的功能。不同的 Zookeeper⻆⾊的服务器processor链是不⼀样的,以下分别介绍standalone Zookeeper server, leader和Follower不同的processor链。
Zookeeper中的processor
AckRequestProcessor:当leader从向Follower发送proposal后,Follower将发送⼀个Ack响应, leader收到Ack响应后,将会调⽤这个Processor进⾏处理。它主要负责检查请求是否已经达到了多数 Follower的确认,如果满⾜条件,则提交commitProcessor进⾏commit处理
CommitProcessor:从commited队列中处理已经由leader协调好并commit的请求或者从请求队列 中取出那些⽆需leader协调的请求进⾏下⼀步处理。
FinalRequestProcessor:任何请求的处理都需要经过这个processor,这是请求处理的最后⼀个 Processor,主要负责根据不同的请求包装不同的类型的响应包。当然Follower与leader之间协调后 的请求由于没有client连接,将不需要发送响应(代码体现在if (request.cnxn == null) {return;})。
FollowerRequestProcessor:Follower processor链上的第⼀个,主要负责将修改请求和同步请求发 往leader进⾏协调。
PrepRequestProcessor:在leader和standalone server上作为第⼀Processor,主要作⽤对于所有 的修改命令⽣成changelog。
ProposalRequestProcessor:leader⽤来将请求包装为proposal向Follower请求确认。
SendAckRequestProcessor:Follower⽤来向leader发送Ack响应的处理。
SyncRequestProcessor:负责将已经commit的事务写到事务⽇志以及take snapshot.
ToBeAppliedRequestProcessor:负责将tobeApplied队列的中request转移到下⼀个请求进⾏处理
8.29、你们的zookeeper的节点加密是⽤的什么⽅式;
ZK的节点有5种操作权限:
CREATE、READ、WRITE、DELETE、ADMIN 也就是 增、删、改、查、管理权限,这5种权限简写为 crwda(即:每个单词的⾸字符缩写)
注:这5种权限中,delete是指对⼦节点的删除权限,其它4种权限指对⾃⾝节点的操作权限 ⾝份的认证有4种⽅式:
world:默认⽅式,相当于全世界都能访问
auth:代表已经认证通过的⽤⼾(cli中可以通过addauth digest user:pwd 来添加当前上下⽂中的授 权⽤⼾)
digest:即⽤⼾名:密码这种⽅式认证,这也是业务系统中最常⽤的
ip:使⽤Ip地址认证
设置访问控制:
⽅式⼀:(推荐)
1)增加⼀个认证⽤⼾ addauth digest ⽤⼾名:密码明⽂ eg. addauth digest user1:password1
2)设置权限 setAcl /path auth:⽤⼾名:密码明⽂:权限 eg. setAcl /test auth:user1:password1:cdrwa
3)查看Acl设置 getAcl /path
⽅式⼆: setAcl /path digest:⽤⼾名:密码密⽂:权限 注:这⾥的加密规则是SHA1加密,然后base64编码
8.30、linux相关命令
如何获取java进程的pid
pgrep -l java
如何获取某个进程的⽹络端⼝号;
netstat/lsofnetstat命令⽤于显⽰与IP、TCP、UDP和ICMP协议相关的统计数据,⼀般⽤于检验本机各端⼝的⽹络连接情况-a 显⽰⼀个所有的有效连接信息列表(包括已建⽴的连接,也包括监听连接请求的那些连接)-n 显⽰所有已建⽴的有效连接-t tcp协议-u udp协议-l 查询正在监听的程序-p 显⽰正在使⽤socket的程序识别码和程序名称例如:netstat -ntupl|grep processname如何只查询tomcat的连接?netstat -na|grep ESTAB |grep 80 |wc-lnetstat -na|grep ESTAB |grep 8080 |wc-l常⽤端⼝介绍:端⼝:21服务:FTP服务器所开放的端⼝,⽤于上传、下载。端⼝: 22服务:ssh端⼝: 80服务:HTTP ⽤于⽹⻚浏览端⼝:389服务:LDAP ILS 轻型⽬录访问协议和NetMeetingInternet Locator Server端⼝:443服务:⽹⻚浏览端⼝ 能提供加密和通过安全端⼝传输的另⼀种HTTP端⼝:8080服务:代理端⼝打开终端,执⾏如下命令,查看各进程占⽤端⼝情况:# ps -ef|wc -l //查看后台运⾏的进程总数# ps -fu csvn //查看csvn进程# netstat -lntp //查看开启了哪些端⼝# netstat -r //本选项可以显⽰关于路由表的信息# netstat -a //本选项显⽰⼀个所有的有效连接信息列表# netstat -an|grep 8080# netstat -na|grep -i listen //可以看到⽬前系统侦听的端⼝号# netstat -antup //查看已建⽴的连接进程,所占⽤的端⼝。netstat -anp|grep1487lsof -i:1487查看哪些进程打开了指定端⼝1487
如何实时打印⽇志;
tail -f messages
如何统计某个字符串⾏数;
要统计⼀个字符串出现的次数,这⾥现提供⾃⼰常⽤两种⽅法:1. 使⽤vim统计⽤vim打开⽬标⽂件,在命令模式下,输⼊:%s/objStr//gn即可2. 使⽤grep:grep -o objStr filename|wc -l如果是多个字符串出现次数,可使⽤:grep -o ‘objStr1\|objStr2' filename|wc -l #直接⽤\| 链接起来即可
8.31、⼤型⽹站在架构上应当考虑哪些问题?
答:
分层:分层是处理任何复杂系统最常⻅的⼿段之⼀,将系统横向切分成若⼲个层⾯,每个层⾯只承担 单⼀的职责,然后通过下层为上层提供的基础设施和服务以及上层对下层的调⽤来形成⼀个完整的复 杂的系统。
计算机⽹络的开放系统互联参考模型(OSI/RM)和Internet的TCP/IP模型都是分层结构,⼤型⽹站的 软件系统也可以使⽤分层的理念将其分为持久层(提供数据存储和访问服务)、业务层(处理业务逻 辑,系统中最核⼼的部分)和表⽰层(系统交互、视图展⽰)。
需要指出的是:(1)分层是逻辑上的划分,在物理上可以位于同⼀设备上也可以在不同的设备上部 署不同的功能模块,这样可以使⽤更多的计算资源来应对⽤⼾的并发访问;(2)层与层之间应当有 清晰的边界,这样分层才有意义,才更利于软件的开发和维护。
分割:分割是对软件的纵向切分。我们可以将⼤型⽹站的不同功能和服务分割开,形成⾼内聚低耦合 的功能模块(单元) 。
在设计初期可以做⼀个粗粒度的分割,将⽹站分割为若⼲个功能模块,后期还可以进⼀步对每个模 块进⾏细粒度的分割,这样⼀⽅⾯有助于软件的开发和维护,另⼀⽅⾯有助于分布式的部署,提供⽹ 站的并发处理能⼒和功能的扩展。
分布式:除了上⾯提到的内容,⽹站的静态资源(JavaScript、CSS、图⽚等)也可以采⽤独⽴分布 式部署并采⽤独⽴的域名,这样可以减轻应⽤服务器的负载压⼒,也使得浏览器对资源的加载更快
数据的存取也应该是分布式的,传统的商业级关系型数据库产品基本上都⽀持分布式部署,⽽新⽣的 NoSQL产品⼏乎都是分布式的。当然,⽹站后台的业务处理也要使⽤分布式技术,例如查询索引的构 建、数据分析等,这些业务计算规模庞⼤,可以使⽤Hadoop以及MapReduce分布式计算框架来处 理。
集群:集群使得有更多的服务器提供相同的服务,可以更好的提供对并发的⽀持。
缓存:所谓缓存就是⽤空间换取时间的技术,将数据尽可能放在距离计算最近的位置。使⽤缓存是⽹ 站优化的第⼀定律。我们通常说的CDN、反向代理、热点数据都是对缓存技术的使⽤。
异步:异步是实现软件实体之间解耦合的⼜⼀重要⼿段。异步架构是典型的⽣产者消费者模式,⼆者 之间没有直接的调⽤关系,只要保持数据结构不变,彼此功能实现可以随意变化⽽不互相影响,这对 ⽹站的扩展⾮常有利。
使⽤异步处理还可以提⾼系统可⽤性,加快⽹站的响应速度(⽤Ajax加载数据就是⼀种异步技术), 同时还可以起到削峰作⽤(应对瞬时⾼并发)。”;能推迟处理的都要推迟处理”是⽹站优化的 第⼆定律,⽽异步是践⾏⽹站优化第⼆定律的重要⼿段。
冗余:各种服务器都要提供相应的冗余服务器以便在某台或某些服务器宕机时还能保证⽹站可以正常 ⼯作,同时也提供了灾难恢复的可能性。冗余是⽹站⾼可⽤性的重要保证
8.32、你⽤过的⽹站前端优化的技术有哪些?
答:
① 浏览器访问优化
: - 减少HTTP请求数量:合并CSS、合并javascript、合并图⽚(CSS Sprite)
- 使⽤浏览器缓存:通过设置HTTP响应头中的Cache-Control和Expires属性,将CSS、JavaScript、 图⽚等在浏览器中缓存,当这些静态资源需要更新时,可以更新HTML⽂件中的引⽤来让浏览器重新 请求新的资源
- 启⽤压缩
- CSS前置,JavaScript后置
- 减少Cookie传输
- ② CDN加速:CDN(Content Distribute Network)的本质仍然是缓存,将数据缓存在离⽤⼾最近的 地⽅,CDN通常部署在⽹络运营商的机房,不仅可以提升响应速度,还可以减少应⽤服务器的压⼒。 当然,CDN缓存的通常都是静态资源。
- ③ 反向代理:反向代理相当于应⽤服务器的⼀个⻔⾯,可以保护⽹站的安全性,也可以实现负载均衡 的功能,当然最重要的是它缓存了⽤⼾访问的热点资源,可以直接从反向代理将某些内容返回给⽤⼾ 浏览器
8.33、什么是XSS攻击?什么是SQL注⼊攻击?什么是CSRF攻击?
XSS(Cross Site Script,跨站脚本攻击)是向⽹⻚中注⼊恶意脚本在⽤⼾浏览⽹⻚时在⽤⼾浏览器 中执⾏恶意脚本的攻击⽅式。
跨站脚本攻击分有两种形式:反射型攻击(诱使⽤⼾点击⼀个嵌⼊恶意脚本的链接以达到攻击的⽬ 标,⽬前有很多攻击者利⽤论坛、微博发布含有恶意脚本的URL就属于这种⽅式)和持久型攻击(将 恶意脚本提交到被攻击⽹站的数据库中,⽤⼾浏览⽹⻚时,恶意脚本从数据库中被加载到⻚⾯执⾏,
QQ邮箱的早期版本就曾经被利⽤作为持久型跨站脚本攻击的平台)。XSS虽然不是什么新鲜玩意,但 是攻击的⼿法却不断翻新,防范XSS主要有两⽅⾯:消毒(对危险字符进⾏转义)和HttpOnly(防范 XSS攻击者窃取Cookie数据)。
SQL注⼊攻击是注⼊攻击最常⻅的形式(此外还有OS注⼊攻击(Struts 2的⾼危漏洞就是通过OGNL 实施OS注⼊攻击导致的)),当服务器使⽤请求参数构造SQL语句时,恶意的SQL被嵌⼊到SQL中交 给数据库执⾏。
SQL注⼊攻击需要攻击者对数据库结构有所了解才能进⾏,攻击者想要获得表结构有多种⽅式:
(1)如果使⽤开源系统搭建⽹站,数据库结构也是公开的(⽬前有很多现成的系统可以直接搭建论 坛,电商⽹站,虽然⽅便快捷但是⻛险是必须要认真评估的);
(2)错误回显(如果将服务器的错误信息直接显⽰在⻚⾯上,攻击者可以通过⾮法参数引发⻚⾯错 误从⽽通过错误信息了解数据库结构,Web应⽤应当设置友好的错误⻚,⼀⽅⾯符合最⼩惊讶原则, ⼀⽅⾯屏蔽掉可能给系统带来危险的错误回显信息);
(3)盲注。防范SQL注⼊攻击也可以采⽤消毒的⽅式,通过正则表达式对请求参数进⾏验证,此 外,参数绑定也是很好的⼿段,这样恶意的SQL会被当做SQL的参数⽽不是命令被执⾏,JDBC中的 PreparedStatement就是⽀持参数绑定的语句对象,从性能和安全性上都明显优于Statement。
CSRF攻击(Cross Site Request Forgery,跨站请求伪造)是攻击者通过跨站请求,以合法的⽤⼾⾝ 份进⾏⾮法操作(如转账或发帖等)。CSRF的原理是利⽤浏览器的Cookie或服务器的Session,盗取 ⽤⼾⾝份,
其原理如下图所⽰。
防范CSRF的主要⼿段是识别请求者的⾝份,主要有以下⼏种⽅式:
(1)在表单中添加令牌(token);
(2)验证码;
(3)检查请求头中的Referer(前⾯提到防图⽚盗链接也是⽤的这种⽅式)。
令牌和验证都具有⼀次消费性的特征,因此在原理上⼀致的,但是验证码是⼀种糟糕的⽤⼾体验,不 是必要的情况下不要轻易使⽤验证码,⽬前很多⽹站的做法是如果在短时间内多次提交⼀个表单未获 得成功后才要求提供验证码,这样会获得较好的⽤⼾体验
8.34、什么是领域模型(domain model)?贫⾎模型(anaemic domain model)和充⾎模型(rich domain model)有什么区别?
答:领域模型是领域内的概念类或现实世界中对象的可视化表⽰,⼜称为概念模型或分析对象模型, 它专注于分析问题领域本⾝,发掘重要的业务领域概念,并建⽴业务领域概念之间的关系。贫⾎模型
是指使⽤的领域对象中只有setter和getter⽅法(POJO),所有的业务逻辑都不包含在领域对象中⽽ 是放在业务逻辑层。
有⼈将我们这⾥说的贫⾎模型进⼀步划分成失⾎模型(领域对象完全没有业务逻辑)和贫⾎模型(领 域对象有少量的业务逻辑),我们这⾥就不对此加以区分了。
充⾎模型将⼤多数业务逻辑和持久化放在领域对象中,业务逻辑(业务⻔⾯)只是完成对业务逻辑的 封装、事务和权限等的处理
第九章:设计模式
9.1、说下你知道的设计模式有哪些?
下⾯ 3 种类型中各挑⼏个常⻅的或者你⽤过的说就能够了。
创建性模式:
单例模式、⼯⼚模式、抽象⼯⼚模式、建造者模式、原型模式
结构型模式:
适配器模式、桥接模式、装饰模式、组合模式、外观模式、享元模式,代理模式
⾏为型模式:
模板⽅法模式、命令模式、迭代器模式、观察者模式、中介者模式、备忘录模式、接解释器模式、状 态模式、策略模式、职责链模式、访问者模式
9.2、⼯⼚⽅法模式和抽象⼯⼚模式有什么区别?
⼯⼚⽅法模式:
⼀个抽象产品类,能够派⽣出多个具体产品类。 ⼀个抽象⼯⼚类,能够派⽣出多个具体⼯⼚类。每⼀ 个具体⼯⼚类只能建⽴⼀个具体产品类的实例。
• 抽象⼯⼚模式:
多个抽象产品类,每⼀个抽象产品类能够派⽣出多个具体产品类。 ⼀个抽象⼯⼚类,能够派⽣出多个 具体⼯⼚类。每⼀个具体⼯⼚类能够建⽴多个具体产品类的实例。
• 区别:
⼯⼚⽅法模式只有⼀个抽象产品类,⽽抽象⼯⼚模式有多个。⼯⼚⽅法模式的具体⼯⼚类只能建⽴⼀ 个具体产品类的实例,⽽抽象⼯⼚模式能够建⽴多个
9.3、JDK 中⽤到了哪些设计模式?
⼏乎每⼀种设计模式都被⽤到了 JDK 的源码中,下⾯列举⼀些常⻅的:
抽象⼯⼚模式
javax.xml.parsers.DocumentBuilderFactory#newInstance()javax.xml.transform.TransformerFactory#newInstance()
建造者模式
java.lang.StringBuilder#append()java.lang.StringBuffer#append()
原型模式
java.lang.Object#clone()
适配器模式
java.util.Arrays#asList()java.util.Collections#list()
装饰器模式
IO 流的⼦类
java.util.Collections#synchronizedXXX()
享元模式
java.lang.Integer#valueOf(int)
代理模式
java.lang.reflect.Proxyjavax.inject.Inject
责任链模式
java.util.logging.Logger#log()javax.servlet.Filter#doFilter()
1)单例设计模式 : Spring 中的 Bean 默认都是单例的;
2)代理设计模式 : Spring AOP 功能的实现;
3)⼯⼚设计模式 : Spring 使⽤⼯⼚模式经过 BeanFactory、ApplicationContext 建⽴ Bean 对象;
4)模板⽅法模式 : Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操 做的类,它们就使⽤到了模板模式;
5)装饰器设计模式 : 咱们的项⽬须要链接多个数据库,并且不⼀样的客⼾在每次访问中根据须要会去 访问不⼀样的数据库。这种模式让咱们能够根据客⼾的需求可以动态切换不⼀样的数据源;
6)观察者模式:Spring 事件驱动模型就是观察者模式很经典的⼀个应⽤;
7)适配器模式:Spring AOP 的加强或通知(Advice)使⽤到了适配器模式、SpringMVC 中也是⽤ 到了适配器模式适配 Controller
9.5、设计模式六⼤原则是什么?
1)单⼀职责原则:⼀个⽅法 ⼀个类只负责⼀个职责,各个职责的程序改动,不影响其它程序。
2)开闭原则:对扩展开放,对修改关闭。即在不修改⼀个软件实体的基础上去扩展其余功能。
3)⾥⽒代换原则:在软件系统中,⼀个能够接受基类对象的地⽅必然能够接受⼀个⼦类对象。
4)依赖倒转原则:针对于接⼝编程,依赖于抽象⽽不依赖于具体
5)接⼝隔离原则:使⽤多个隔离的接⼝取代⼀个统⼀的接⼝。下降类与类之间的耦合度。
6)迪⽶特原则:⼀个实体应当尽可能少的与其余实体之间发⽣相互做⽤,使得系统功能模块相对独 ⽴。
9.6、单例模式的优缺点?
优势:
因为在系统内存中只存在⼀个对象,所以能够节约系统资源,对于⼀些须要频繁建⽴和销毁的对象单 例模式⽆疑能够提升系统的性能。
• 缺点:
因为单例模式中没有抽象层,所以单例类的扩展有很⼤的困难。滥⽤单例将带来⼀些负⾯问题,如为 了节省资源将数据库链接池对象设计为的单例类,可能会致使共享链接池对象的程序过多⽽出现链接 池溢出;若是实例化的对象⻓时间不被利⽤,系统会认为是垃圾⽽被回收,这将致使对象状态的丢 失
9.7、请⼿写⼀下单例模式?
- 懒汉式:⽤到时再去建⽴
public class Singleton{private static Singleton instance;private Singleton(){};public static synchronized Singleton getInstance(){if(instance == null){instance = new Singleton();}return instance;}}
- 饿汉式:初始化时即建⽴,⽤到时直接返回
public class Singleton{private static Singleton instance = new Singleton();private Singleton(){};public static Singleton getInstance(){return instance;}}
静态内部类【推荐】
public class Singleton{private static class SingletonHolder{private static final Singleton INSTTANCE = new Singleton();}private Singleton(){};public static final Singleton getInstance(){return SingletonHolder.INSTTANCE;}}
双重校验锁【推荐】
public class Singleton{private volatile static Singleton singleton;private Singleton(){};public static Singleton getSingleton(){if(singleton == null){synchronized(Singleton.class){if(singleton == null){singleton = new Singleton();}}}return singleton;}}
9.8、请说⼀下观察者模式。
消息队列(MQ),⼀种能实现⽣产者到消费者单向通信的通信模型,这也是现在常⽤的主流中间 件。常⻅有 RabbitMQ、ActiveMQ、Kafka等 他们的特点也有很多⽐如 解偶、异步、⼴播、削峰 等 等多种优势特点。
在设计模式中也有⼀种模式能有效的达到解偶、异步的特点,那就是观察者模式⼜称为发布订阅模 式。
举⼀个例⼦,就好⽐微信朋友圈,以当前个⼈作为订阅者,好友作为主题。⼀个⼈发⼀条动态朋友圈 出去,他的好友都能看到这个朋友圈,并且可以在⾃主选择点赞或者评论。
Subject(主题): 主要由类实现的可观察的接⼝,通知观察者使⽤attach⽅法,以及取消观察的 detach⽅法。 •
• ConcreteSubject(具体主题): 是⼀个实现主题接⼝的类,处理观察者的变化
• Observe(观察者): 观察者是⼀个抽象类或接⼝,根据主题中的更改⽽进⾏更新
public interface Subject {// 添加订阅关系void attach(Observer observer);// 移除订阅关系void detach(Observer observer);// 通知订阅者void notifyObservers(String message);}
先创建⼀个主题定义,定义添加删除关系以及通知订阅者
public class ConcreteSubject implements Subject {// 订阅者容器private List<Observer> observers = new ArrayList<Observer>();@Overridepublic void attach(Observer observer) {// 添加订阅关系observers.add(observer);}@Overridepublic void detach(Observer observer) {// 移除订阅关系observers.remove(observer);}@Overridepublic void notifyObservers(String message) {// 通知订阅者们for (Observer observer : observers) {observer.update(message);}}}
其次再创建的具体主题,并且构建⼀个容器来维护订阅关系,⽀持添加删除关系,以及通知订阅者
public interface Observer {// 处理业务逻辑void update(String message);}
创建⼀个观察者接⼝,⽅便我们管理
public class FriendOneObserver implements Observer {@Overridepublic void update(String message) {// 模拟处理业务逻辑System.out.println("FriendOne 知道了你发动态了" + message);}}
最后就是创建具体的观察者类,实现观察者接⼝的update⽅法,处理本⾝的业务逻辑
public class test {public static void main(String[] args) {ConcreteSubject subject = new ConcreteSubject();// 这⾥假设是添加好友subject.attach(new FriendOneObserver());FriendTwoObserver twoObserver = new FriendTwoObserver();subject.attach(twoObserver);// 发送朋友圈动态subject.notifyObservers("第⼀个朋友圈消息");// 输出结果: FriendOne 知道了你发动态了第⼀个朋友圈消息// FriendTwo 知道了你发动态了第⼀个朋友圈消息// 这⾥发现 twoObserver 是个推荐卖茶叶的,删除好友subject.detach(twoObserver);subject.notifyObservers("第⼆个朋友圈消息");// 输出结果:FriendOne 知道了你发动态了第⼆个朋友圈消息}}
最后就是看测试结果了,通过ConcreteSubject 维护了⼀个订阅关系,在通过notifyObservers ⽅法 通知订阅者之后,观察者都获取到消息从⽽处理⾃⼰的业务逻辑
9.9、请说⼀下策略模式。
定义⼀系列算法,封装每个算法,并使他们可以互换,不同的策略可以让算法独⽴于使⽤它们的客⼾ ⽽变化。 策略模式是属于⾏为型设计模式,主要是针对不同的策略做出对应⾏为,达到⾏为解偶
• Strategy(抽象策略):抽象策略类,并且定义策略执⾏⼊⼝
• ConcreteStrategy(具体策略):实现抽象策略,实现algorithm⽅法
• Context(环境):运⾏特定的策略类。
举个例⼦,汽⻋的不同档(concreteStrategy)就好⽐不同的策略,驾驶者选择⼏档则汽⻋按⼏档的速 度前进,整个选择权在驾驶者(context)⼿中
public interface GearStrategy {// 定义策略执⾏⽅法void algorithm(String param);}
这⾥是⽤接⼝的形式,还有⼀种⽅式可以⽤抽象⽅法abstract来写也是⼀样的。具体就看⼤家⾃⼰ 选择了。public abstract class GearStrategyAbstract { // 定义策略执⾏⽅法 abstract void algorithm(String param);}
public class GearStrategyOne implements GearStrategy {@Overridepublic void algorithm(String param) {System.out.println("当前档位" + param);}}
其次定义具体档位策略,实现algorithm⽅法
public class Context {// 缓存所有的策略,当前是⽆状态的,可以共享策略类对象private static final Map<String, GearStrategy> strategies = new HashMap<>();// 第⼀种写法static {strategies.put("one", new GearStrategyOne());}public static GearStrategy getStrategy(String type) {if (type == null || type.isEmpty()) {throw new IllegalArgumentException("type should not be empty.");}return strategies.get(type);}// 第⼆种写法public static GearStrategy getStrategySecond(String type) {if (type == null || type.isEmpty()) {throw new IllegalArgumentException("type should not be empty.");}if (type.equals("one")) {return new GearStrategyOne();}return null;}public static void main(String[] args) {// 测试结果GearStrategy strategyOne = Context.getStrategy("one");strategyOne.algorithm("1档");// 结果:当前档位1档GearStrategy strategyTwo = Context.getStrategySecond("one");strategyTwo.algorithm("1档");// 结果:当前档位1档}}
最后就是实现运⾏时环境(Context),你可以定义成StrategyFactory,但都是⼀个意思。 在main⽅法⾥⾯的测试demo,可以看到通过不同的type类型,可以实现不同的策略,这就是策略模 式主要思想
在Context⾥⾯定义了两种写法:
第⼀种是维护了⼀个strategies的Map容器。⽤这种⽅式就需要判断每种策略是否可以共享使⽤, 它只是作为算法的实现。
• 第⼆种是直接通过有状态的类,每次根据类型new⼀个新的策略类对象。这个就需要根据实际业 务场景去做的判断


若有收获,就点个赞吧
0 人点赞
