Redis缓存
前言
穿透是redis中不存在,不是过期了
击穿是大量请求访问同一个redis的一个失效的key,访问的一瞬间他失效了,请求来到了mysql数据库
雪崩是访问很多的失效的key
1.缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效(有但失效)或redis发生故障后重启时(缓存中还没有数据),所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
缓存雪崩其实有点像“升级版的缓存击穿”,缓存击穿是⼀个热点 key,缓存雪崩是⼀组热点 key
举个例子:咱们都知道,redis是分布式缓存中间件,是用来做缓存的。如果没有redis,服务请求都去找mysql,如果是在大量的请求下,mysql是非常累的,因为mysql的并发性能并不是很好。所有就让redis当小弟,mysql当大哥,给mysql服务。redis咱们都知道叫内存数据库,它的全部都是在内存是做操作,所有它的性能是非常快的。这样的话所有的请求都会先询问Redis。如果redis没有的话,再去mysql去查询,然后放在Redis里面。如果redis里面有的话,就直接返回了。所以Redis就会拦截大量的请求,这样Mysql就会节省很多的工作。所以这个mysql就非常闲,没事干。而所有的工作都让redis来做了。但是如果到了双十一,这边有满减活动,那边有发红包的活动,那边又有金币抵现金的活动。活动进行了很多个,这些活动都放在了redis里面。但是恰巧在同一时间同时失效了。
`那它为什么会失效呢?`
因为在平时使用redis的时候都会设置一个过期时间。比如说所有的学生名单,我们给他设置为10秒,如果在10秒内你高频的访问学生名单,从redis里拿就可以了。如果过了10秒,你要访问学生名单,就要先去数据库里拿,然后再访问redis了。现在都知道了每个数据都会设置过期时间,就像刚才所说的,很多很多活动,都在这个redis里面保存数据了。如果你习惯把过期时间都设置为10秒,如果时间一到,所有的活动请求的数据都没有了。这时候redis没有的话,所有的请求都会到达mysql。mysql已经当大哥很久没有工作过了,这时来了这么多的请求,一下子就给mysql干趴下了。因为同一时间失效,就会造成雪崩。
解决方案:
- 把缓存数据的过期时间设置成随机数,防止同一时间大量数据过期现象发生。例如:a活动设置10秒,b活动设置了20秒,c活动设置了30秒。那么在10秒的时候只有a活动失效了,b,c活动没有过期,这样就防止所有了大量缓存在同一时间失效了。这样活动a失效了,它自己去访问mysql的话,mysql是能应付归来的。
- 给每一个缓存数据增加相应的缓存标记,记录缓存是否失效,如果缓存标记失效,则更新数据缓 存。(比较消耗性能,要时刻监听缓存标记,但会很快把缓存不上来,防止请求打到数据库上)
- 缓存预热(在启动系统(服务)之前可以先启动接口,把热点数据先放到缓存上去)
- 互斥锁 (查到一个缓存发现失效了,在查数据库时把缓存的键锁起来,查完数据库后再把数据放到缓存中再释放这个锁,避免大量请求对同一个键进行操作(让其排队))
- 如果你是缓存数据库分布式部署的话,可以将热点数据均匀分布在不同的缓存数据库中。
- 可以设置热点数据永远不过期,但是你说这样的话不可以全部都设置吗,那显然是不能的。你要这样设置的话,本身redis很牛,你这样你设置,他就不牛了。都设置的话,redis会被撑爆的,本来性能很高,这样一设置就变低了。毕竟内存要比硬盘小的多得多。比如说京东618,我们可以把家电设置成热点数据,然后这个618过了以后,那么你就可以找运维的工作人员,把redis里面的618的数据进行手动删除。这个和抖音热门类似,今天你是热门,明天就不一样了。
2.缓存穿透
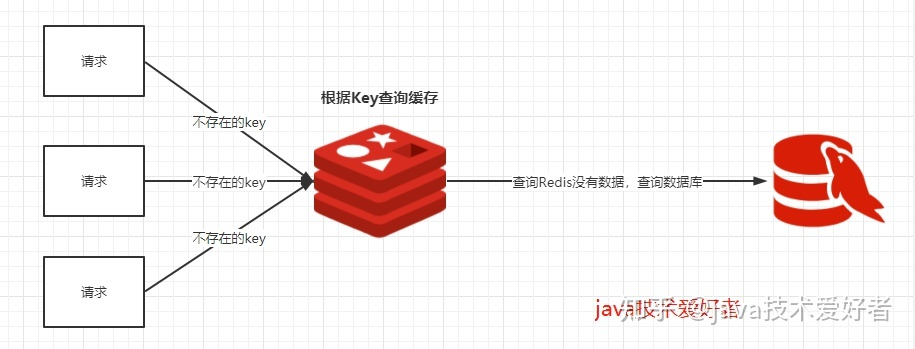
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。(通常这种现象来自攻击,因正常用户请求一次没有后就不会再连续请求) 此时,缓存起不到作⽤,请求每次都会⾛到数据库,流量⼤时数据库可能会被打挂。此时缓存就好像 被“穿透”了⼀样,起不到任何作⽤。
举个例子:大家都知道,正常这个id是都是正整数。那你传一个-10,redis里面肯定没有,这样就会去数据库查了。这样的话,这个缓存redis就根本起不了作用。这个请求会直接穿透到数据库,流量大的时候直接就给干死了。假如我把这个userid=-10写一个死循环,给它循环一千万次。这样请求的话,redis是起不到效果的,全部到数据库身上了。那数据库接受了这一千万次的请求,那么数据库直接就崩了。数据库性能其实很差的,它没有办法处理这么多请求。怎么解决?
解决方案:
- 接口层增加校验{参数校验},如用户鉴权校验,id做基础校验,id<=0的直接拦截(从业务层面可明显判断出这个数据不可能存在,就不用去访问数据库了)
- 缓存空值:从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null(针对同一个key的攻击就无效了,被缓存拦截,全部返回null),缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户 反复用同一个id暴力攻击
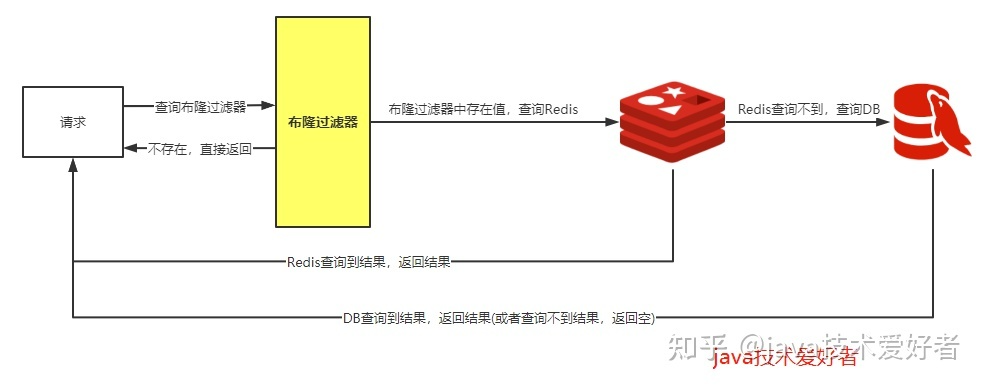
- 采用布隆过滤器(Java中可以实现,redis中也提供了现成的布隆过滤器),将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据一定会被这个 bitmap 拦截掉,但是存在的数据不一定真的存在bitmap中,从而避免了对底层存储系统的查询压力
3.缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存(同一个键)没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查 数据库。
举个例子:比如一个神枪手对着铁门每次都打一个地方,连开5枪,到第5枪的时候瞬间把铁门击穿了。比如潜水艇破了一个洞,会瞬间涌进大量的水。
解决方案
- 设置热点数据永远不过期。(但仍然要维护他,若数据修改或删除也要去修改缓存)这个解决方案不仅只靠程序员,还要靠运维。你要给运维讲这个问题没有什么好的解决方案,我们准备把热点数据设置成永远不过期,一个月之后再让运维删掉。
- 加互斥锁(key过期了,去查数据库,加一个cas自旋锁,只让一个线程去查,其他线程不去查而进行自旋,查到了再去利用cas更新key,释放锁)
布隆过滤器
简介:布隆过滤器(BloomFilter)是由一个叫“布隆”的小伙子在1970年提出的,它是一个很长的二进制向量(或者说位数组即BitMap位图)和一系列随机映射函数(哈希函数)两部分组成的数据结构,是⼀种空间效率极⾼的概率型算法和数据 结构。主要用于判断一个元素是否在一个集合中。
特点:特点:判断不存在的,则⼀定不存在;判断存在的,⼤概率存在,但也有⼩概率不存 在。并且这个概率是可控的,我们可以让这个概率变⼩或者变⾼,取决于⽤⼾本⾝的需求。
优点:相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高(查询快O(k)恒定时间搜索,其中k是哈希函数的数量,测试不存在将非常快。)位数组(bit数组)中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
缺点:其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
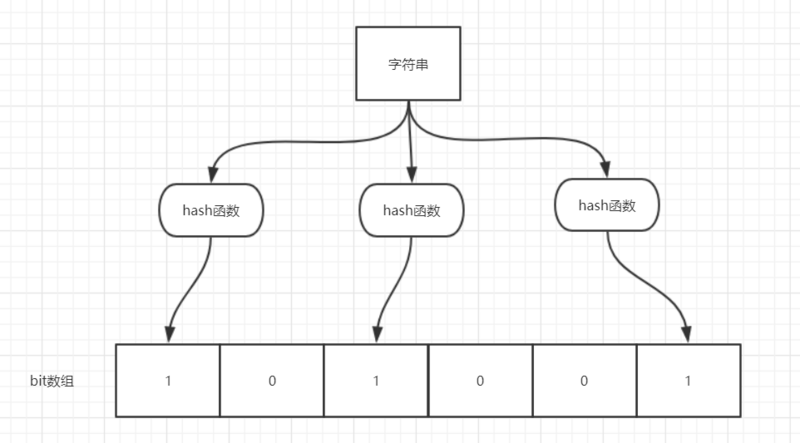
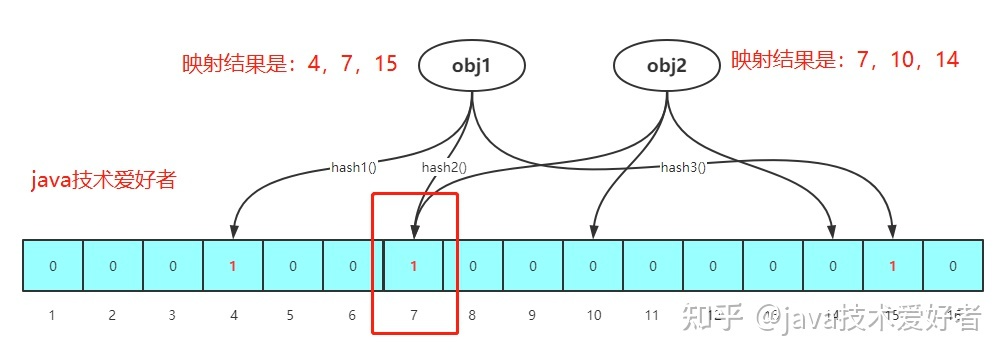
应用于缓存穿透

若有收获,就点个赞吧
0 人点赞
