介绍
Tunny 是生成和管理 goroutine 池的工具,使用同步 API 限制来自任意数量的 goroutine 的工作,它有如下特点:
- 一个 worker 拥有一个 goroutine。
- 任意时刻都可以安全地改变 goroutine 池的大小,即使有 goroutine 正在运行。
- 支持限时处理请求,若在指定时间内未处理完毕则返回错误。
- 允许通过实现 tunny.Worker 接口来自定义 worker ,精确控制每个 goroutine 的状态。
- 积压的作业不保证会被按顺序处理,虽然目前的实现确实会让积压的作业按 FIFO 的顺序处理,但是这种行为并不是标准,不应该被依赖。
源码分析
Tunny 的结构
先看看定义的结构体和接口,从宏观上有个基本了解。
Pool
// Pool is a struct that manages a collection of workers, each with their own// goroutine. The Pool can initialize, expand, compress and close the workers,// as well as processing jobs with the workers synchronously.type Pool struct {queuedJobs int64 // 排队的作业ctor func() Worker // Worker 的构造函数workers []*workerWrapper // 一组 workerWrapperreqChan chan workRequest // 传输请求的管道workerMut sync.Mutex // 一把互斥锁}
Pool 结构管理一组 workers,每个 worker 都有一个自己的 goroutine,Pool 支持对 workers 数量进行初始化、扩大、缩小、关闭,并且使用 workers 同步处理作业,Pool 里使用了其他类型 Worker, workerWrapper, workRequest,分别看看它们是什么。
Worker
// Worker is an interface representing a Tunny working agent. It will be used to// block a calling goroutine until ready to process a job, process that job// synchronously, interrupt its own process call when jobs are abandoned, and// clean up its resources when being removed from the pool.//// Each of these duties are implemented as a single method and can be averted// when not needed by simply implementing an empty func.type Worker interface {// Process will synchronously perform a job and return the result.// Process 同步地执行一个作业并返回结果Process(interface{}) interface{}// BlockUntilReady is called before each job is processed and must block the// calling goroutine until the Worker is ready to process the next job.// BlockUntilReady 会在每个作业被执行之前调用,并且会阻塞执行该作业BlockUntilReady()// Interrupt is called when a job is cancelled. The worker is responsible// for unblocking the Process implementation.// Interrupt 会在一个作业被取消时调用。Worker 负责解除阻塞的 ProcessInterrupt()// Terminate is called when a Worker is removed from the processing pool// and is responsible for cleaning up any held resources.// Terminate 在一个 Worker 被移出协程池时被调用,并且负责回收资源Terminate()}
Worker 是接口类型,定义了一组方法,因此某个类型想要实现 Worker 接口,就必须实现它定义的所有方法,若某个类型实现了 Worker 的所有方法,则该类型就拥有了 Worker 类型。
小贴士:约定 Worker 为接口,worker 为 Worker 的一个实例,workers 是一组实例。
workerWrapper
// workerWrapper takes a Worker implementation and wraps it within a goroutine// and channel arrangement. The workerWrapper is responsible for managing the// lifetime of both the Worker and the goroutine.// workerWrapper 封装了一个 Worker 实例,一个 goroutine 和一组管道// 并且负责管理它们的生命周期workerWrapper struct {worker Worker // Worker 实例interruptChan chan struct{}// reqChan is NOT owned by this type, it is used to send requests for work.// reqChan 不属于 workerWrapper(属于 Pool),用来传递请求reqChan chan<- workRequest// closeChan can be closed in order to cleanly shutdown this worker.// closeChan 可以被关闭,目的是关闭这个 workercloseChan chan struct{}// closedChan is closed by the run() goroutine when it exits.// closedChan 会在 run() goroutine 结束时被其关闭closedChan chan struct{}}
因为原本的 Worker 只是个接口,没有与 Pool 进行通信的能力,因此 workerWrapper 才会封装一个 worker,一个 goroutine(在 workerWrapper 的方法中)和一组管道(用于与 Pool 通信),然后利用管道接收来自 Pool 的请求,调用 Worker 实例里的处理函数处理请求。
workRequest
// workRequest is a struct containing context representing a workers intention// to receive a work payload.// workRequest 是一个包含上下文的结构,上下文表示type workRequest struct {// jobChan is used to send the payload to this worker.// jobChan 用于 Pool 把 payload 发给该 worker(payload 是真正要执行的作业)jobChan chan<- interface{}// retChan is used to read the result from this worker.// retChan 用于把该 worker 的处理结果传给 PoolretChan <-chan interface{}// interruptFunc can be called to cancel a running job. When called it is no// longer necessary to read from retChan.// interruptFunc 用于取消一个执行中的作业,调用后不再需要从 retChan 中读取处理结果interruptFunc func()}
workRequest 是请求的上下文,包含了两个管道,一个用于接收来自 Pool 的 payload(真正要执行的作业),一个用于把处理结果传回给 Pool,Pool 通过请求上下文来传递作业和接收作业处理结果。
作业处理流程
通过以上了解,不难知道 Tunny 的工作原理是由 Pool 管理了一组 Worker,通过 reqChan 向它们传递请求并取得处理结果。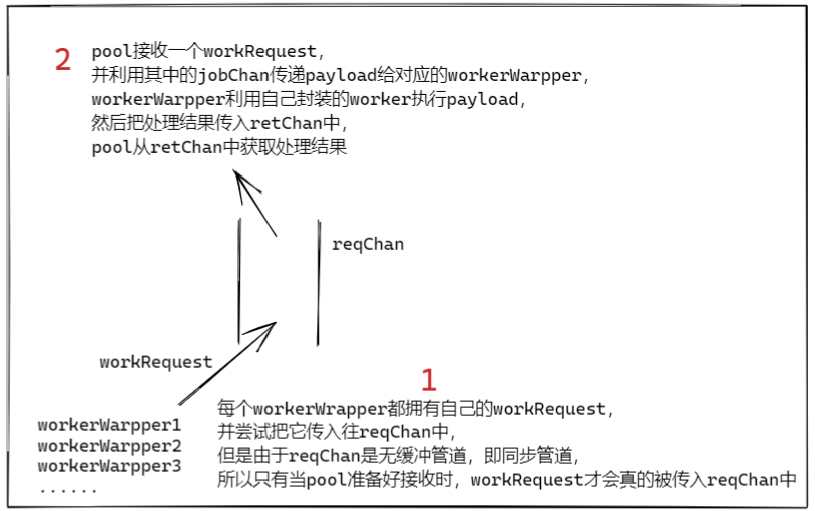
图1:大致的处理流程
worker 的类型
通过分析 Tunny 的结构得知,真正处理作业的是 Worker 里的 Process 方法,我们可以自定义一个类型去实现 Worker 接口,而 Tunny 已经为我们实现了两种 worker 类型:closureWorker 和 callbackWorker
closureWorker
// closureWorker is a minimal Worker implementation that simply wraps a// func(interface{}) interface{}type closureWorker struct {processor func(interface{}) interface{}}func (w *closureWorker) Process(payload interface{}) interface{} {// payload 就是要处理的作业// processor 是真正用于处理作业的方法return w.processor(payload)}func (w *closureWorker) BlockUntilReady() {}func (w *closureWorker) Interrupt() {}func (w *closureWorker) Terminate() {}
closureWorker 要求真正处理作业的方法 processor 的类型是 func(interface{}) interface{},对作业 Payload 的类型没有限制(payload 是 interface{} 类型,是任何类型的“祖先”)
callbackWorker
// callbackWorker is a minimal Worker implementation that attempts to cast// each job into func() and either calls it if successful or returns// ErrJobNotFunc.type callbackWorker struct{}func (w *callbackWorker) Process(payload interface{}) interface{} {f, ok := payload.(func())if !ok {return ErrJobNotFunc}f() // 执行 payload 代表的函数return nil}func (w *callbackWorker) BlockUntilReady() {}func (w *callbackWorker) Interrupt() {}func (w *callbackWorker) Terminate() {}
callbackWorker 要求作业 payload 的类型必须是 func(),即没有参数也没有返回值的一个函数。
因此 callbackWorker 的 Process 实际上就是负责执行 payload 代表的函数。
Pool 的构造函数
Pool 有 3 种构造函数,每种对应一种 Worker 类型,对应关系如下:
- New:自定义 Worker 类型
- NewFunc:closureWorker
- NewCallback:callbackWorker
NewFunc 和 NewCallback 最终都是通过调用 New 实现的。
New
// New creates a new Pool of workers that starts with n workers. You must// provide a constructor function that creates new Worker types and when you// change the size of the pool the constructor will be called to create each new// Worker.func New(n int, ctor func() Worker) *Pool {p := &Pool{ctor: ctor,reqChan: make(chan workRequest),}p.SetSize(n) // 生成具有与 Pool 通信能力的 workerreturn p}
New 方法是最通用的 Pool 构造函数,它要求传入两个参数:
- n 表示要创建 worker 的个数。
- ctor 表示 worker 的构造函数。
使用 New 需要自己定义一个类型然后实现 Worker 接口,像 closureWorker 和 callbackWorker 那样。
生成具有与 Pool 通信能力的 worker 的方法是 SetSize。
NewFunc
// NewFunc creates a new Pool of workers where each worker will process using// the provided func.func NewFunc(n int, f func(interface{}) interface{}) *Pool {return New(n, func() Worker {return &closureWorker{processor: f,}})}
NewFunc 是创建拥有 n 个 closureWorker 的 Pool 构造函数,它要求两个参数:
- n 表示要创建 closureWorker 的个数。
- f 表示作业的处理函数。
NewCallback
// NewCallback creates a new Pool of workers where workers cast the job payload// into a func() and runs it, or returns ErrNotFunc if the cast failed.func NewCallback(n int) *Pool {return New(n, func() Worker {return &callbackWorker{}})}
NewCallback 用于创建拥有 n 个 callbackWorker 的 Pool ,它要求一个参数:
- n 表示要创建 closureWorker 的个数。
小贴士:为什么叫回调呢?用一个生活例子理解回调“我要求你帮我做一件事,你不确定什么时候能做完,但是我有其他事要做,没空等你做完,所以我给你留了电话号码,等你做完了再打电话通知我”。类比到协程池,外部告诉 Pool 这里有个 payload 要做,然后外部就去处理其他事了,留下 payload 代表的函数用于等你做完后告诉外部。
Tunny 提供的其他管理方法
介绍里提到过 Tunny 是一个用于生成和管理 goroutine 池的工具,上面介绍了如何生成 Pool 实例,接下来介绍它提供的其他管理 goroutine 的方法。
SetSize:控制 worker 的数量
// SetSize changes the total number of workers in the Pool. This can be called// by any goroutine at any time unless the Pool has been stopped, in which case// a panic will occur.func (p *Pool) SetSize(n int) {// 改变 Pool 大小时必须上锁// 避免多个协程并发改变 Pool 大小的竞争问题p.workerMut.Lock()defer p.workerMut.Unlock()lWorkers := len(p.workers) // 当前已有的 worker 数量// 相同则不需要改变if lWorkers == n {return}// 要增加// Add extra workers if N > len(workers)for i := lWorkers; i < n; i++ {p.workers = append(p.workers, newWorkerWrapper(p.reqChan, p.ctor()))}// 要减少// Asynchronously stop all workers > Nfor i := n; i < lWorkers; i++ {p.workers[i].stop()}// Synchronously wait for all workers > N to stopfor i := n; i < lWorkers; i++ {p.workers[i].join()}// Remove stopped workers from slicep.workers = p.workers[:n]}
函数逻辑:
- 当要设置的 worker 数量恰好等于当前 worker 的数量,则函数结束;
- 当要设置的 worker 数量大于当前 worker 的数量,则通过第 1 个 for 循环增加 worker 的数量,不会执行下面两个 for 循环;
- 当要设置的 worker 数量小于当前 worker 的数量,则跳过第 1 个 for 循环,通过第 2, 3 个 for 循环减少worker 的数量。
第 19 行 ctor 方法已经生成了 Worker 实例,但不具备与 Pool 通信能力,深入探索 newWorkerWrapper 如何生成具有与 Pool 通信能力的 Worker 实例。
增加逻辑 newWorkerWrapper
func newWorkerWrapper(reqChan chan<- workRequest,worker Worker,) *workerWrapper {w := workerWrapper{worker: worker,interruptChan: make(chan struct{}),reqChan: reqChan,closeChan: make(chan struct{}),closedChan: make(chan struct{}),}go w.run()return &w}
代码分析:
- Pool 把发送请求的管道 reqChan 和 Worker 实例传递给 newWorkerWrapper,workerWrapper 通过封装 worker 和复用 Pool 的 reqChan 使其具备了和 Pool 的通信能力。
- 第 13 行是最重要的一行代码,它验证了前面说到的一句话“每个 Worker 都拥有自己的 goroutine”
核心 run
这是处理请求的核心部分,需要结合 Pool 的 Process 方法分析
func (w *workerWrapper) run() {jobChan, retChan := make(chan interface{}), make(chan interface{})// 处理完要回收资源defer func() {w.worker.Terminate()close(retChan)close(w.closedChan)}()for {// NOTE: Blocking here will prevent the worker from closing down.w.worker.BlockUntilReady()select {case w.reqChan <- workRequest{ // 尝试往 reqChan 里传入请求jobChan: jobChan,retChan: retChan,interruptFunc: w.interrupt,}:select {case payload := <-jobChan:result := w.worker.Process(payload)select {case retChan <- result:case <-w.interruptChan:w.interruptChan = make(chan struct{})}case _, _ = <-w.interruptChan:w.interruptChan = make(chan struct{})}case <-w.closeChan:return}}}
// Process will use the Pool to process a payload and synchronously return the// result. Process can be called safely by any goroutines, but will panic if the// Pool has been stopped.func (p *Pool) Process(payload interface{}) interface{} {atomic.AddInt64(&p.queuedJobs, 1)request, open := <-p.reqChanif !open {panic(ErrPoolNotRunning)}request.jobChan <- payloadpayload, open = <-request.retChanif !open {panic(ErrWorkerClosed)}atomic.AddInt64(&p.queuedJobs, -1)return payload}
代码分析:
- 前面提到 Pool 与所有的 worker 通过共用 reqChan 来传递请求和处理结果。
- run 的核心部分是 for 循环及其内部 3 重 select 嵌套。
- 第一重 select 中所有 worker 尝试往 reqChan 中传入 workRequest,对应 Process 的第 7 行从 reqChan 中接收 workRequest。
- 第二重 select 中某个 worker(被 Pool 拿走 workRequest 对应的那个 worker,前面提到每个 worker 都有自己的 workRequest)尝试从 jobChan 中接收 payload 并执行,对应 Process 的第 12 行 Pool 尝试往 jobChan 中发送 payload。
- 第三重 select 中该 worker 尝试往 retChan 发送处理结果,对应 Process 的第 14 行。
- 注意这里并没有分析 BlockUntilReady 带来的影响,因为 Tunny 实现的 closureWorker 和 callbackWorker 都把它实现为空函数。
通过分析发现当 Pool 有作业要处理时,会随机选中一个 worker,同时处理多个作业并不能保证处理顺序。
GetSize:获取 worker 的数量
// GetSize returns the current size of the pool.func (p *Pool) GetSize() int {// 上锁p.workerMut.Lock()defer p.workerMut.Unlock()return len(p.workers)}
代码分析:在分析 Pool 结构时,Pool 是通过一个切片来管理一组 worker 的 workers []*workerWrapper,因此对 workers 切片求长度即可 len(p.workers),
注意:求切片长度时要上锁,避免别的协程进行 SetSize 操作。
Close:关闭 Pool
// Close will terminate all workers and close the job channel of this Pool.func (p *Pool) Close() {p.SetSize(0)close(p.reqChan)}
Close 通过 SetSize 来减少 worker 数量,然后关闭请求管道 reqChan。
减少逻辑 stop & join
func (w *workerWrapper) stop() {close(w.closeChan)}func (w *workerWrapper) join() {<-w.closedChan}
stop 关闭了 worker 的 closeChan,在 run 中被接收到(第一重 selecet 的第二个 case),通过 return 终止了 worker 开启的 goroutine。
join 操作让每个 worker 从 closedChan 里接收一个数据,由于 closedChan 是同步管道,在源码只有在 run 函数结束时在 defer 里面的有一个 close(w.closedChan) 会触发一次广播式通知(nil + false),因此逻辑上是这样的:stop 会执行 defer 里 close(w.closedChan) 进行广播通知,然后每个 worker 从里面接收到管道已关闭消息。
QueueLength:获取等待作业队列长度
// QueueLength returns the current count of pending queued jobs.func (p *Pool) QueueLength() int64 {return atomic.LoadInt64(&p.queuedJobs)}
Tunny 并没有显示维护等待作业队列,而是通过维护一个 queuedJobs 变量来表示当前积压的作业数。
当调用 Process 处理一个作业时,若 Pool 里已经没有空闲的 worker 了,那么就会阻塞在 Process 的 request, open := <-p.reqChan语句。
Process
// Process will use the Pool to process a payload and synchronously return the// result. Process can be called safely by any goroutines, but will panic if the// Pool has been stopped.func (p *Pool) Process(payload interface{}) interface{} {atomic.AddInt64(&p.queuedJobs, 1)request, open := <-p.reqChanif !open {panic(ErrPoolNotRunning) // Pool 已关闭}request.jobChan <- payloadpayload, open = <-request.retChanif !open {panic(ErrWorkerClosed) // worker 已关闭}atomic.AddInt64(&p.queuedJobs, -1)return payload}
Process 在上文已经结合了 run 来解析正常的请求处理流程,这里需要注意的点:
- 处理前后通过原子加维护
queuedJobs变量。 - 两次从管道取数据都有额外的错误判断。
ProcessTimed
// ProcessTimed will use the Pool to process a payload and synchronously return// the result. If the timeout occurs before the job has finished the worker will// be interrupted and ErrJobTimedOut will be returned. ProcessTimed can be// called safely by any goroutines.func (p *Pool) ProcessTimed(payload interface{},timeout time.Duration,) (interface{}, error) {atomic.AddInt64(&p.queuedJobs, 1)defer atomic.AddInt64(&p.queuedJobs, -1)tout := time.NewTimer(timeout) // 打开计时器var request workRequestvar open boolselect {case request, open = <-p.reqChan:if !open {return nil, ErrPoolNotRunning}case <-tout.C:return nil, ErrJobTimedOut}select {case request.jobChan <- payload:case <-tout.C:request.interruptFunc()return nil, ErrJobTimedOut}select {case payload, open = <-request.retChan:if !open {return nil, ErrWorkerClosed}case <-tout.C:request.interruptFunc()return nil, ErrJobTimedOut}tout.Stop()return payload, nil}
ProcessTimed 在 Process 的基础上增加了计时器,每次都通过 select 判断是否已经超时。
满足特定场景:设置请求处理所需的最大时间,即这么多时间内必须要处理完,否则报错。
ProcessCtx
// ProcessCtx will use the Pool to process a payload and synchronously return// the result. If the context cancels before the job has finished the worker will// be interrupted and ErrJobTimedOut will be returned. ProcessCtx can be// called safely by any goroutines.func (p *Pool) ProcessCtx(ctx context.Context, payload interface{}) (interface{}, error) {atomic.AddInt64(&p.queuedJobs, 1)defer atomic.AddInt64(&p.queuedJobs, -1)var request workRequestvar open boolselect {case request, open = <-p.reqChan:if !open {return nil, ErrPoolNotRunning}case <-ctx.Done():return nil, ctx.Err()}select {case request.jobChan <- payload:case <-ctx.Done():request.interruptFunc()return nil, ctx.Err()}select {case payload, open = <-request.retChan:if !open {return nil, ErrWorkerClosed}case <-ctx.Done():request.interruptFunc()return nil, ctx.Err()}return payload, nil}
ProcessCtx 在 Process 的基础上增加了 context 是请求的上下文是否被取消的判定。
若请求的上下文被取消了,那么该请求也就不用处理了,通过 request.interruptFunc() 停止。
Tunny 应用实战

若有收获,就点个赞吧
0 人点赞
