1 基础知识
1.1 内存结构
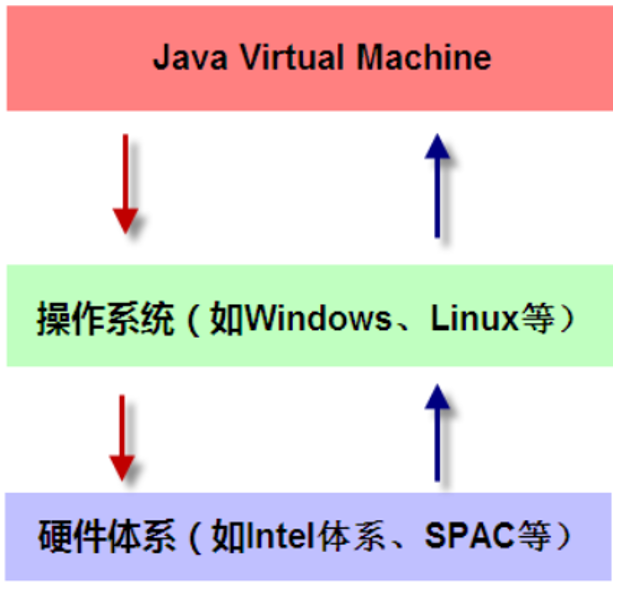
JVM是运行在操作系统之上的,他与硬件没有直接的交互。
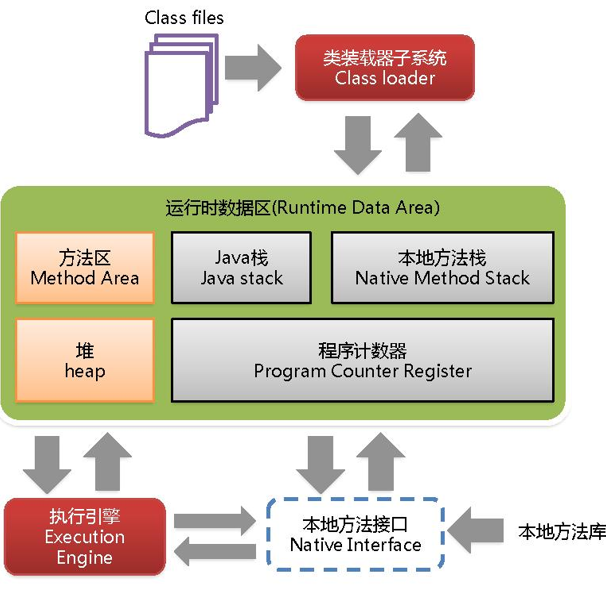
- Class Loader类加载器:
负责加载class文件,class文件在文件开头有特定的文件标示(cafebabe),并且ClassLoader只负责class文件的加载,至于他是否可以允许,则由Execution Engine决定 - Execution Engine执行引擎: 负责解释命令,提交操作系统执行
- Native Interface 本地接口:
Java语言本身不能对操作系统底层进行访问和操作,但是可以通过JNI接口调用其他语言来实现对底层的访问。 - Native Method Stack 本地方法栈:
java在内存中专门开辟了一块区域处理标记为native的代码,他的具体做法是Native Method Stack中登记native方法,在Execution Engine执行时加载native libraies。
Runtime Data Area 运行数据区
- Method Area方法区
方法区被所有线程共享,所有字段和方法字节码、以及一些特殊方法如构造函数,接口代码也在此定义。简单说,所有定义的方法的信息都保存在该区域,此区属于共享区间。用来保存装载的类的元结构信息。
静态变量+常量+类信息+运行时常量池存放在方法区(jdk1.8 后字符串常量池实际放在堆内存中)
实例变量存在堆内存中 - PC Register 程序计数器
每个线程都有一个程序计数器,就是一个指针,指向方法区中的方法字节码(下一个将要执行的指令代码),有执行引擎读取下一条指令,是一个非常小的内存空间,可以忽略不记 - Java Stack 栈
栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题(但是可能会内存溢出),只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。基本类型的变量、实例方法、引用类型变量都是在函数的栈内存中分配
栈管运行,堆管存储
1.2 栈(Stak)
栈也叫栈内存,主管Java程序的运行,是在线程创建时创建,它的生命期是跟随线程的生命期,线程结束栈内存也就释放,对于栈来说不存在垃圾回收问题,只要线程一结束该栈就Over,生命周期和线程一致,是线程私有的。基本类型的变量、实例方法、引用类型变量都是在函数的栈内存中分配
1.2.1 栈存储什么
先进后出,后进先出即为栈
栈帧(Frame Data)中主要保存3类数据
- 局部变量表(Local Variables):输入参数和输出参数以及方法内的变量;
- 操作数栈(Operand Stack):记录出栈、入栈的操作;
- 动态链接(DynamicLinking)(或指向运行时常量池的方法引用)
- 方法返回地址(Return Address) (或方法正常退出或异常退出的定义)
1.2.2 栈运行原理
栈中的数据都是以栈帧(Stack Frame)的格式存在,栈帧是一个内存去块,是一个数据集,是一个有关方法(Method)和运行期数据的数据集,
当一个方法A被调用时就产生一个栈帧F1,并被压入到栈中,
A方法调用了B方法,于是产生栈帧F2也被压入到栈,
B方法调用了C方法,于是产生栈帧F3也被压入到栈。。。
执行完毕后,先弹出F3,再弹出F2,再弹出F1.。。。
遵循“先进后出/后进先出”的原则。
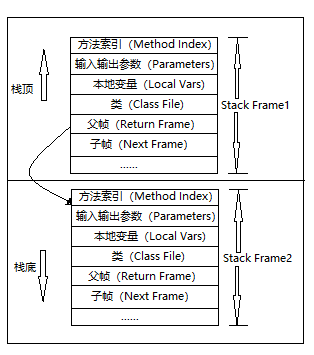
图示在一个栈中有两个栈:
栈2是最先被调用的方法,先入栈,
然后方法2调用了方法1,栈帧1处于栈顶的位置,
栈帧2处于栈底,执行完毕后,依次弹出栈帧1和栈帧2,
线程结束,栈释放。
每执行一个方法都会产生一个栈帧,保存到栈(后进先出)的顶部,顶部栈就是当前的方法,该方法执行完毕后会自动将此栈帧出栈。
1.3 堆(Heap)
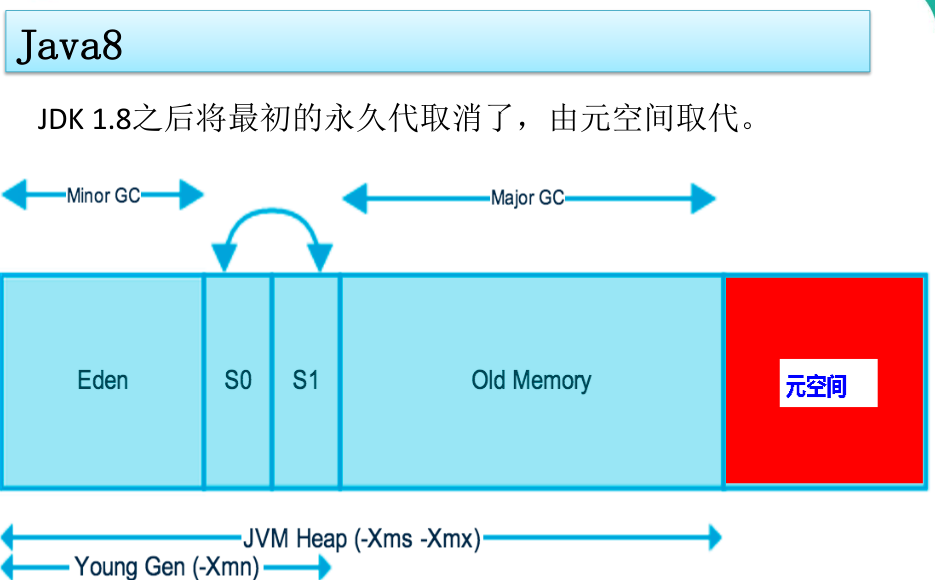
1.3.1 堆内存示意图

1.3.2 新生区
新生区是类的诞生、成长、消亡的区域,一个类再这里产生,应用,最后被垃圾回收器收集,结束生命。新生区又分为两部分:伊甸区(Eden Space)和幸存者区(Survivor Space),所有的类都是再伊甸区被new出来。幸存区有两个:0区和1区。当伊甸园的空间用完是,程序有需要创建对象,JVM的垃圾回收器将对伊甸园区进行垃圾回收(Minor GC),将伊甸园区中的不再被其他对象所引用的对象进行销毁。然后将伊甸园区中的生于对象移动到幸存0区,若幸存0区也满了,再对该区进行垃圾回收,然后移动到1区。如果1区也满了,再移动到养老区。若养老区也满了,那么这时候将产生MajorGC(FullGC),进行养老区的内存清理。若养老区执行了FullGC后发现依然无法进行对象保存,就会产生OOM异常(OutOfMemoryError)。
- 如果出现
java.lang.OutOfMemoryError:Java heap space异常,说明java虚拟机的堆内存不够。原因有二:- Java虚拟机的对内存设置不够,可以通过参数-Xms、-Xmx来调整
默认最大内存是机器的四分之一大小 - 代码中创建了大量大对象,并且长时间不能被垃圾收集器收集(存在被引用)
- Java虚拟机的对内存设置不够,可以通过参数-Xms、-Xmx来调整
JDK1.8之后,永久代取消了,由元空间取代
1.3.3 养老区
养老区用于保存从新生区筛选出来的JAVA对象,一般池对象都在这个区域活跃。
1.4.4 永久区
永久存储区是一个常驻内存区域,用于存放JDK自身所携带的Class,Interface的元数据,也就是说它存储的是运行环境必须的类信息,被装载进此区域的数据是不会被垃圾回收器回收掉的(并不绝对),关闭JVM才会释放此区域所占用的内存。
- 如果出现
java.lang.OutOfMemoryError:PermGen space,说明是Java虚拟机对永久带Perm内存设置不够,一般出现这种情况,都是程序启动需要加载大量的第三方jar包。例如在一个Tomcat下部署了太多的应用。或者大量动态反射生成的类不断被加载,最终导致Perm区被沾满。- Jdk1.6之前:有永久代,常量值1.6在方法区
- Jdk1.6:有永久代,但已经逐步“去永久代”,常量池1.6在堆
- Jdk1.8之后:无永久代,常量池1.8在元空间
1.4.5 小总结
逻辑上堆由新生代、养老代、元空间构成、实际上堆只有新生和养老代;方法区就是永久代,永久代是方法区的实现
- 方法区(Method Area)和堆一样,是各个线程共享的内存区域,它用于存储虚拟机加载的类信息、普通常量、静态常量、编译器编译后的代码等,虽然JVM规范将方法去描述为堆的一个逻辑部分,但他却还有一个别名叫做Non-Heap(非堆),目的就是要和堆分开。
- 对于HotSpot虚拟机,很多开发者习惯将方法区成为“永久代”,但严格本质上说两者不同,或者说使用永久代来实现方法区而已,永久代是方法区(相当于一个接口Interface)的一个实现,JDK1.6的版本中,已经将原本放在永久代的字符串常量池移走。
- 常量池(Constant Pool)是方法区的一部分,Class文件除了有类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池,这部分内容将在类加载后进入方法区的运行时常量池中存放
1.4 JVM垃圾收集(Java Garbage Collection)
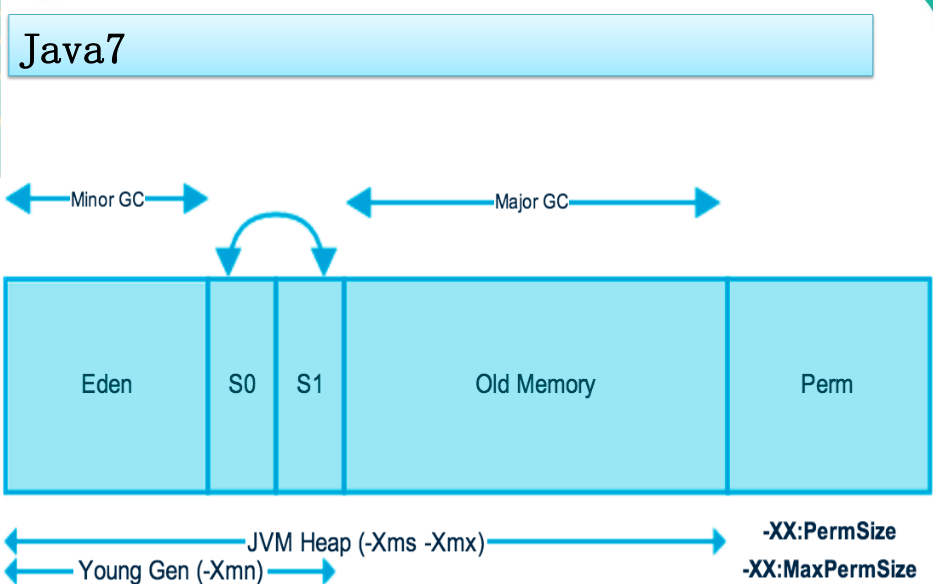
1.4.1 堆内存调优简介
| -Xms | 设置初始分配大小,默认为物理内存的“1/64” |
|---|---|
| -Xmx | 最大分配内存,默认为物理内存的“1/4” |
| -XX:+PrintGCDetails | 输出详细的GC处理日志 |
1.5 GC三大算法
1.5.1 GC算法总体概述
JVM在进行GC时,并非每次都对上面三个内存区域一起回收的,大部分时候回收的都是指新生代。
因此GC按照回收的区域又分了两种类型,一种是普通GC(MinorGC),一种时全局GC(FullGC)
- 普通GC:只针对新生代区域的GC
- 全局GC:针对年老代的GC,偶尔伴随对新生代的GC以及堆永久代的GC。
1.5.2 复制算法:MinorGC(普通GC)
新生代使用的MinorGC,这种GC算法采用的是复制算法(Copying),频繁使用
复制—>清空—>互换
1.5.2.1 原理
MinorGC会把Eden中的所有或的对象都移到Survivor区域中,如果Survivor区中放不下,那么剩下的活的对象就被移到Old Generation中,也即一旦收集后,Eden区就变成空的了。
当对象在Eden(包括一个Survivor区域,这里假设是from区域)出生后,在经过一次MinorGC后,如果对象还存活,并且能够被另外一块Survivor区域所容纳(上面已经假设为from区域,这里应为to区域,即to区域又足够的内存空间来存储Eden和from区域中存活的对象),则使用复制算法将这些仍然还存活的对象复制到另外一块Survivor区域(即to区)中,然后清理所有使用过的Eden以及Survivor区域(即from区),并且讲这些对象的年龄设置为1,以后对象在Survivor区没熬过一次MinorGC,就将对象的年龄+1,当对象的年龄达到某个值时(默认15,通过-XX:MaxTenuringThreshold来设定参数),这些对象就会成为老年代。
-XX:MaxTenuringThreshold设置对象在新生代中存活的次数
1.5.2.2 解释
HotSpot JVM把年轻代分为了三部分:1个Eden区和两个Survivor区,默认比例是8:1:1,一般情况下,新创建的对象都会被分配到Eden区,这些对象经过第一次的MinorGC后,如果仍然存活,将会被移到Survivor区。对象Survivor区中每熬过一次MinorGC,年龄就增加一岁,当他的年龄增加到一定程度时,就会被移动到年老代中。因为年轻代中的对象基本都是朝生夕死(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将活着的对象复制到另外一块上面。复制算法不会产生内存碎片。
复制要交换,谁空谁是to
1.5.3.3 劣势
复制算法弥补了标记清除算法中,内存布局混乱的缺点。
- 浪费了一般的内存,太要命了
- 如果对象的存活率很高,我们可以极端一点,假设是100%存活率,那么我们需要将所有对象都复制一遍,并将所有引用地址重置一遍。复制这一工作所花费的时间,在对象存活率达到一定程度是,将会变的不可忽视。所以从以上描述不难看出,复制算法想要使用,最起码对象的存活率要非常低才行,而且最重要的是,我们必须要客服50%的内存的浪费
1.5.3 标记清除/标记整理算法:FullGC又叫MajorGC(全局GC)
老年代一般是由标记清除或者是标记清除与标记整理的混合实现
1.5.3.1 标记清除(Mark-Sweep)
1.5.3.1.1 原理
- 标记(mark)
从根集合开始扫描,对存活的对象进行标记 - 清除(Sweep)
扫描整个内存空间,回收未被标记的对象,使用free-list记录可以区域。
1.5.3.1.2 劣势
- 效率低(递归与全堆对象遍历),而且在进行GC的时候,需要停止应用程序,这会导致用户体验非常差劲
- 清理出来的空闲内存不是连续的,我们的死亡对象都是随机的出现在内存的各个角落,限制把他们清除之后,内存的布局自然会乱七八糟,而为了应付这一点,JVM不得不维持一个内存的空闲列表,这又是一种开销,而且在分配数组对象的时候,寻找连续的内存空间会不太好找。
1.5.3.2 标记整理(Mark-Compact)
1.5.3.2.1 原理
- 标记
与标记-清除一样 - 压缩整理
再次扫描,并往一段滑动存活对象
1.5.3.2.2 劣势
效率不高,不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上说,效率要低于复制算法
1.5.4 小总结
- 内存效率:复制算法>标记清除算法>标记整理算法
- 内存整齐度:复制算法=标记整理算法>标记清除算法
- 内存利用率:标记整理算法=标记清除算法>复制算法
分代收集算法
引用计数法:
- 缺点:每次对对象赋值时均要维护引用计数器,且计数器本身也有一定的消耗
-
1.3 New关键字
我们都知道,一个类为对象提供了蓝图,你从一个类创建一个对象。以下语句从createobjectdemo程序创建一个对象并将其赋值给一个引用变量:
Point originOne = new Point(23, 94);
- Rectangle rectOne = new Rectangle(originOne, 100, 200);
- Rectangle rectTwo = new Rectangle(50, 100);
第一行创建了一个 Point 类的对象,第二个和第三个线创建一个Rectangle 矩形类的对象。
这些陈述中的每一个都有三个部分(详细讨论):
- 声明Declaration:粗体代码是将变量名称与对象类型关联的变量声明。这部分内容存在虚拟机栈上。详见jvm篇。
- 实例化Instantiating :new关键字是一个java运算符,它用来创建对象。对象正常情况存在堆上。
- 初始化Initialization:new运算符,随后调用构造函数,初始化新创建的对象。
声明一个变量来指向一个对象,即引用
在此之前,你知道,要声明一个变量,你需要写:type name;
这将告诉编译器你将使用name引用一个type类型的对象。用一个原始变量,这个声明也保留了适当的内存量的变量。
你也可以在自己的行上声明一个引用变量。例如:Point originone;
如果你只是声明一个像originone这样的引用变量,其价值将待定,直到有一个对象真正被创造和分配给它。只是简单地声明一个引用变量而并没有创建一个对象。对于这样,你需要使用new运算符。在你的代码中使用它之前,你必须指定一个对象给originone。否则,你会得到一个编译器错误——-空指针异常。
处于这种状态的变量,目前没有引用任何的对象,可以说明如下(变量名,originone,一个引用没指向任何对象)。
实例化一个类对象
- new运算符实例化一个类对象,通过给这个对象分配内存并返回一个指向该内存的引用。new运算符也调用了对象的构造函数。
- 注意:“实例化一个类的对象”的意思就是“创建对象”。创建对象时,你正在创造一个类的“实例”,因而“实例化”一个类的对象。
- new运算符需要一个单一的,后缀参数,需要调用构造函数。构造函数的名称提供了需要实例化类的名称。
- new运算符返回它所创建的对象的引用。此引用通常被分配给一个合适的类型的变量,如:Point originone =new Point(23,94);
- 由new运算符返回的引用可以不需要被赋值给变量。它也可以直接使用在一个表达式中。例如: int height = new Rectangle().height;
初始化一个类对象
这是Point类的代码
public class Point {public int x = 0;public int y = 0;//constructorpublic Point(int a, int b) {x = a;y = b;}}
这个类包含一个单一的构造函数。你可以识别一个构造函数,因为它的声明使用与类具有相同的名称,它没有返回类型。在Point类构造函数的参数是两个整数参数,如代码声明(int a,int b)。下面的语句提供了94和23作为这些参数的值:Point originOne = new Point(23, 94); //结果可描述为下图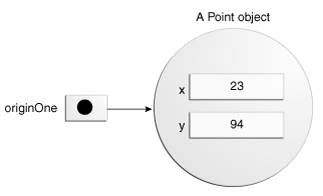
这是Rectangle类,包含4个版本的构造方法
public class Rectangle {public int width = 0;public int height = 0;public Point origin;// four constructorspublic Rectangle() {origin = new Point(0, 0);}public Rectangle(Point p) {origin = p;}public Rectangle(int w, int h) {origin = new Point(0, 0);width = w;height = h;}public Rectangle(Point p, int w, int h) {origin = p;width = w;height = h;}// a method for moving the rectanglepublic void move(int x, int y) {origin.x = x;origin.y = y;}// a method for computing the area of the rectanglepublic int getArea() {return width * height;}}
每个构造函数都允许你为矩形的起始值、宽度和高度提供初始值,同时使用原始类型和引用类型。如果一个类有多个构造函数,它们必须有不同的签名。java编译器区分构造函数基于参数的数量和类型。当java编译器遇到下面的代码,它知道在矩形类,需要一点争论,后面跟着两个整数参数调用构造函数: Rectangle rectOne = new Rectangle(originOne, 100, 200);
结果可描述为下图: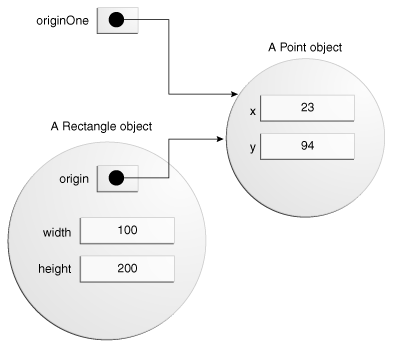
总结:
- Java关键字new是一个运算符。与+、-、*、/等运算符具有相同或类似的优先级。
- 创建一个Java对象需要三部:声明引用变量、实例化、初始化对象实例。
- 实例化:就是“创建一个Java对象”——-分配内存并返回指向该内存的引用。
- 初始化:就是调用构造方法,对类的实例数据赋初值。
- Java对象内存布局:包括对象头和实例数据。见JVM相关文档。
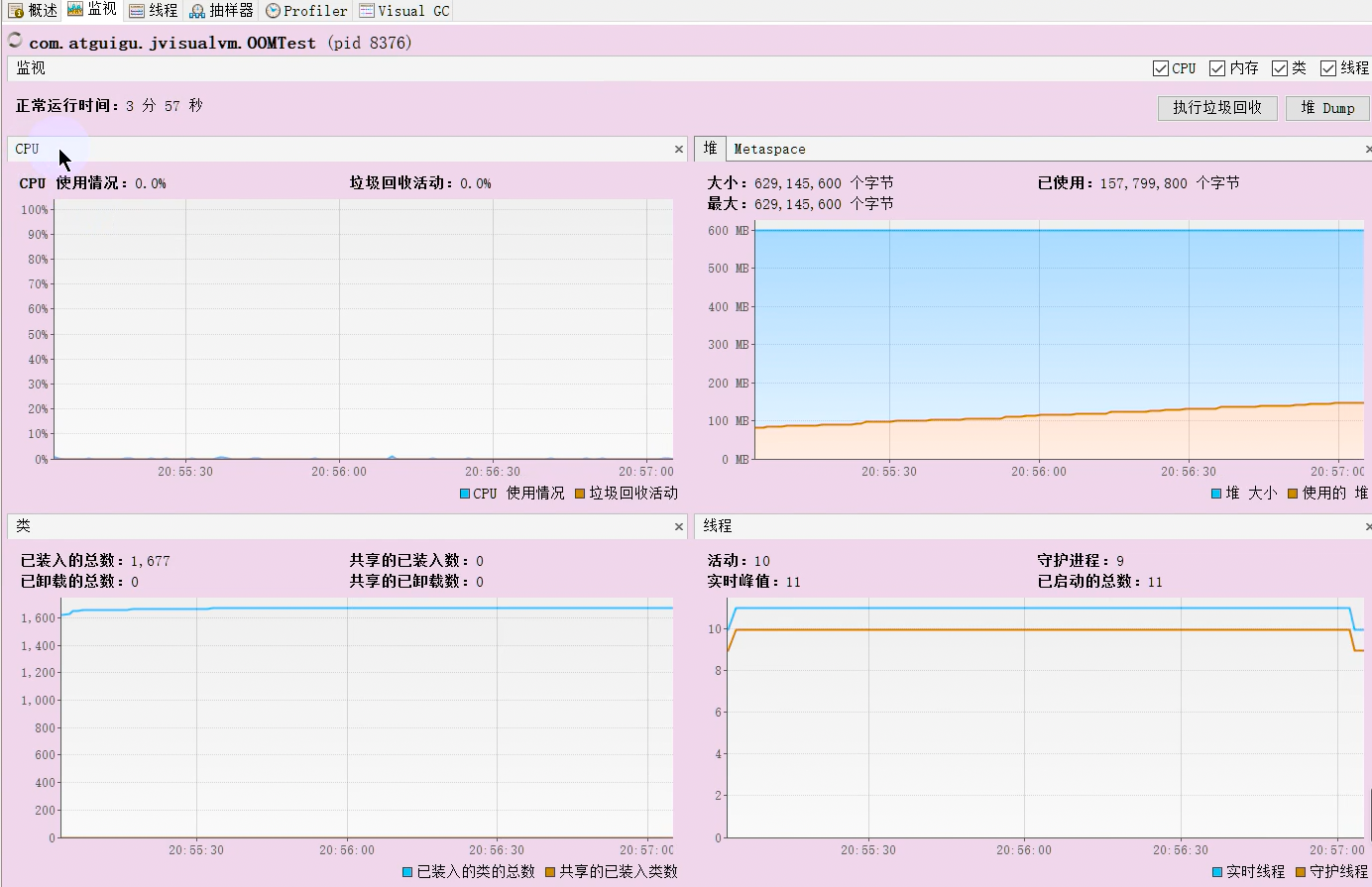
2 Visual VM(开发环境)
Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具。它集成了多个JDK命令行工具,使用Visual VM可用于显示虚拟机进程及进程的配置和环境信息(jps,jinfo),监视应用程序的CPU、GC、堆、方法区及线程的信息(jstat、jstack)等,甚至代替JConsole。在JDK 6 Update 7以后,Visual VM便作为JDK的一部分发布(VisualVM 在JDK/bin目录下)即:它完全免费。
主要功能:
- 1.生成/读取堆内存/线程快照
- 2.查看JVM参数和系统属性
- 3.查看运行中的虚拟机进程
- 4.程序资源的实时监控
- 5.JMX代理连接、远程环境监控、CPU分析和内存分析
官方地址:https://visualvm.github.io/index.html

3 Arthas(测试/正式环境可用)
上述工具都必须在服务端项目进程中配置相关的监控参数,然后工具通过远程连接到项目进程,获取相关的数据。这样就会带来一些不便,比如线上环境的网络是隔离的,本地的监控工具根本连不上线上环境。并且类似于Jprofiler这样的商业工具,是需要付费的。
那么有没有一款工具不需要远程连接,也不需要配置监控参数,同时也提供了丰富的性能监控数据呢?
阿里巴巴开源的性能分析神器Arthas应运而生。
Arthas是Alibaba开源的Java诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪Java代码;实时监控JVM状态。Arthas 支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
- 怎么快速定位应用的热点,生成火焰图?
官方地址:https://arthas.aliyun.com/doc/quick-start.html
安装方式:如果速度较慢,可以尝试国内的码云Gitee下载。
wget https://io/arthas/arthas-boot.jarwget https://arthas/gitee/io/arthas-boot.jar
Arthas只是一个java程序,所以可以直接用java -jar运行。
除了在命令行查看外,Arthas目前还支持 Web Console。在成功启动连接进程之后就已经自动启动,可以直接访问 http://127.0.0.1:8563/ 访问,页面上的操作模式和控制台完全一样。
基础指令
quit/exit 退出当前 Arthas客户端,其他 Arthas喜户端不受影响stop/shutdown 关闭 Arthas服务端,所有 Arthas客户端全部退出help 查看命令帮助信息cat 打印文件内容,和linux里的cat命令类似echo 打印参数,和linux里的echo命令类似grep 匹配查找,和linux里的gep命令类似tee 复制标隹输入到标准输出和指定的文件,和linux里的tee命令类似pwd 返回当前的工作目录,和linux命令类似cs 清空当前屏幕区域session 查看当前会话的信息reset 重置增强类,将被 Arthas增强过的类全部还原, Arthas服务端关闭时会重置所有增强过的类version 输出当前目标Java进程所加载的 Arthas版本号history 打印命令历史keymap Arthas快捷键列表及自定义快捷键
jvm相关
dashboard 当前系统的实时数据面板thread 查看当前JVM的线程堆栈信息jvm 查看当前JVM的信息sysprop 查看和修改JVM的系统属性sysem 查看JVM的环境变量vmoption 查看和修改JVM里诊断相关的optionperfcounter 查看当前JVM的 Perf Counter信息logger 查看和修改loggergetstatic 查看类的静态属性ognl 执行ognl表达式mbean 查看 Mbean的信息heapdump dump java heap,类似jmap命令的 heap dump功能
class/classloader相关
sc 查看JVM已加载的类信息-d 输出当前类的详细信息,包括这个类所加载的原始文件来源、类的声明、加载的Classloader等详细信息。如果一个类被多个Classloader所加载,则会出现多次-E 开启正则表达式匹配,默认为通配符匹配-f 输出当前类的成员变量信息(需要配合参数-d一起使用)-X 指定输出静态变量时属性的遍历深度,默认为0,即直接使用toString输出sm 查看已加载类的方法信息-d 展示每个方法的详细信息-E 开启正则表达式匹配,默认为通配符匹配jad 反编译指定已加载类的源码mc 内存编译器,内存编译.java文件为.class文件retransform 加载外部的.class文件, retransform到JVM里redefine 加载外部的.class文件,redefine到JVM里dump dump已加载类的byte code到特定目录classloader 查看classloader的继承树,urts,类加载信息,使用classloader去getResource-t 查看classloader的继承树-l 按类加载实例查看统计信息-c 用classloader对应的hashcode来查看对应的 Jar urls
monitor/watch/trace相关
monitor 方法执行监控,调用次数、执行时间、失败率-c 统计周期,默认值为120秒watch 方法执行观测,能观察到的范围为:返回值、抛出异常、入参,通过编写groovy表达式进行对应变量的查看-b 在方法调用之前观察(默认关闭)-e 在方法异常之后观察(默认关闭)-s 在方法返回之后观察(默认关闭)-f 在方法结束之后(正常返回和异常返回)观察(默认开启)-x 指定输岀结果的属性遍历深度,默认为0trace 方法内部调用路径,并输出方法路径上的每个节点上耗时-n 执行次数限制stack 输出当前方法被调用的调用路径tt 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
其他
jobs 列出所有jobkill 强制终止任务fg 将暂停的任务拉到前台执行bg 将暂停的任务放到后台执行grep 搜索满足条件的结果plaintext 将命令的结果去除ANSI颜色wc 按行统计输出结果options 查看或设置Arthas全局开关profiler 使用async-profiler对应用采样,生成火焰图
4 Eclipse MAT(开发/测试/正式)
4.1 JVM Heap Dump(堆转储文件)的生成
正如Thread Dump文件记录了当时JVM中线程运行的情况一样,Heap Dump记录了JVM中堆内存运行的情况。
可以通过以下几种方式生成Heap Dump文件:
4.1.1 使用 jmap 命令生成
jmap 命令是JDK提供的用于生成堆内存信息的工具,可以执行下面的命令生成Heap Dump:
jmap -dump:live,format=b,file=heap-dump.bin <pid>
其中的pid是JVM进程的id,heap-dump.bin是生成的文件名称,在执行命令的目录下面。推荐此种方法。
4.1.2 使用 JConsole 生成
JConsole是JDK提供的一个基于GUI查看JVM系统信息的工具,既可以管理本地的JVM,也可以管理远程的JVM,可以通过下图的 dumpHeap 按钮生成 Heap Dump文件。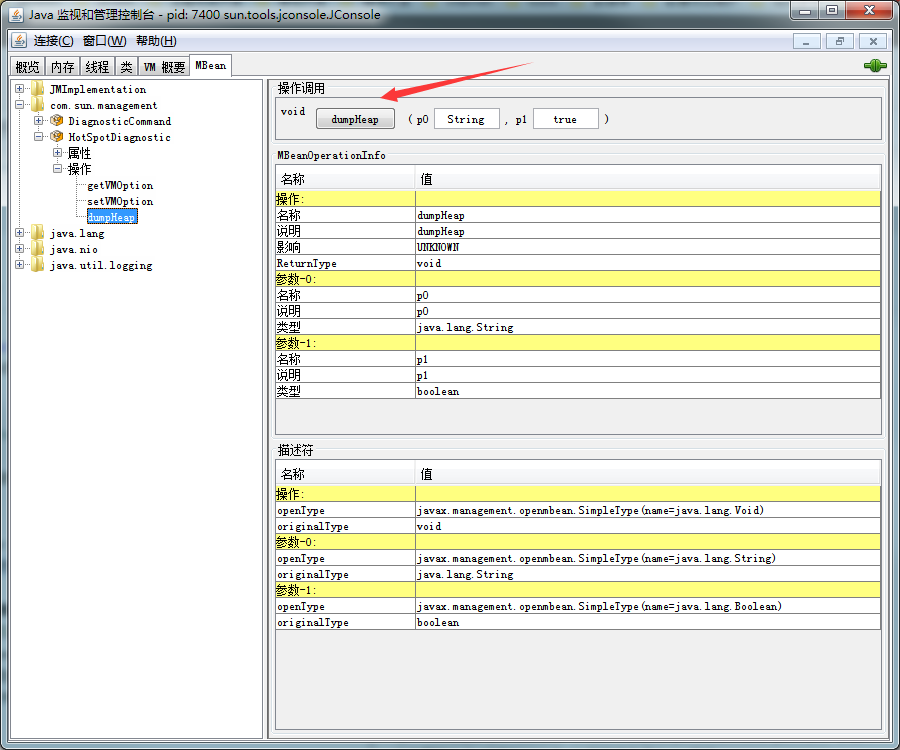
4.1.3 在JVM中增加参数生成(我们采用的方式)
在JVM的配置参数中可以添加 -XX:+HeapDumpOnOutOfMemoryError 参数,当应用抛出 OutOfMemoryError 时自动生成dump文件;
在JVM的配置参数中添加 -Xrunhprof:head=site 参数,会生成java.hprof.txt 文件,不过这样会影响JVM的运行效率,不建议在生产环境中使用(未亲测)。
MAT(Memory Analyzer Tool)工具是一款功能强大的Java堆内存分析器。可以用于查找内存泄漏以及查看内存消耗情况。MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。
MAT可以分析heap dump文件。在进行内存分析时,只要获得了反映当前设备内存映像的hprof文件,通过MAT打开就可以直观地看到当前的内存信息。一般说来,这些内存信息包含:
- 所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值。
- 所有的类信息,包括classloader、类名称、父类、静态变量等
- GCRoot到所有的这些对象的引用路径
- 线程信息,包括线程的调用栈及此线程的线程局部变量(TLS)
MAT 不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如Sun,HP,SAP 所采用的 HPROF 二进制堆存储文件,以及 IBM的 PHD 堆存储文件等都能被很好的解析。
最吸引人的还是能够快速为开发人员生成内存泄漏报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没有简单到一键完成的程度,很多内存问题还是需要我们从MAT展现给我们的信息当中通过经验和直觉来判断才能发现。
官方地址: https://www.eclipse.org/mat/downloads.php
4.2 Memory Analyzer的安装和使用
如前文所述,Eclipse Memory Analyzer(简称MAT)是一个功能丰富且操作简单的JVM Heap Dump分析工具,可以用来辅助发现内存泄漏减少内存占用。
使用 Memory Analyzer 来分析生产环境的 Java 堆转储文件,可以从数以百万计的对象中快速计算出对象的 Retained Size,查看是谁在阻止垃圾回收,并自动生成一个 Leak Suspect(内存泄露可疑点)报表。
4.2.1 下载与安装
Eclipse Memory Analyzer(MAT)支持两种安装方式,一是Eclipse插件的方式,另外一个就是独立运行的方式,建议使用独立运行的方式。
在 http://www.eclipse.org/mat/downloads.php 下载安装MAT,启动之后打开 File - Open Heap Dump… 菜单,然后选择生成的Heap DUmp文件,选择 “Leak Suspects Report”,然后点击 “Finish” 按钮。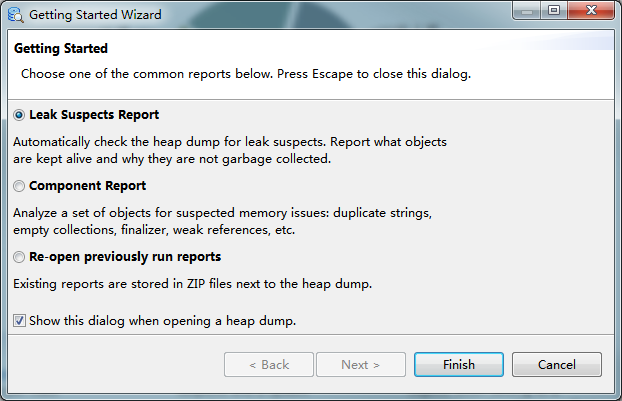
4.2.2 主界面
第一次打开因为需要分析dump文件,所以需要等待一段时间进行分析,分析完成之后dump文件目录下面的文件信息如下: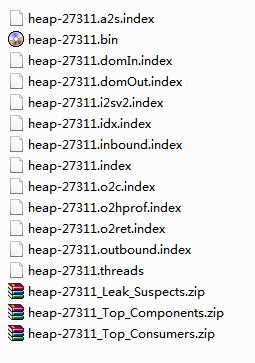
上图中 heap-27311.bin 文件是原始的Heap Dump文件,zip文件是生成的html形式的报告文件。
打开之后,主界面如下所示: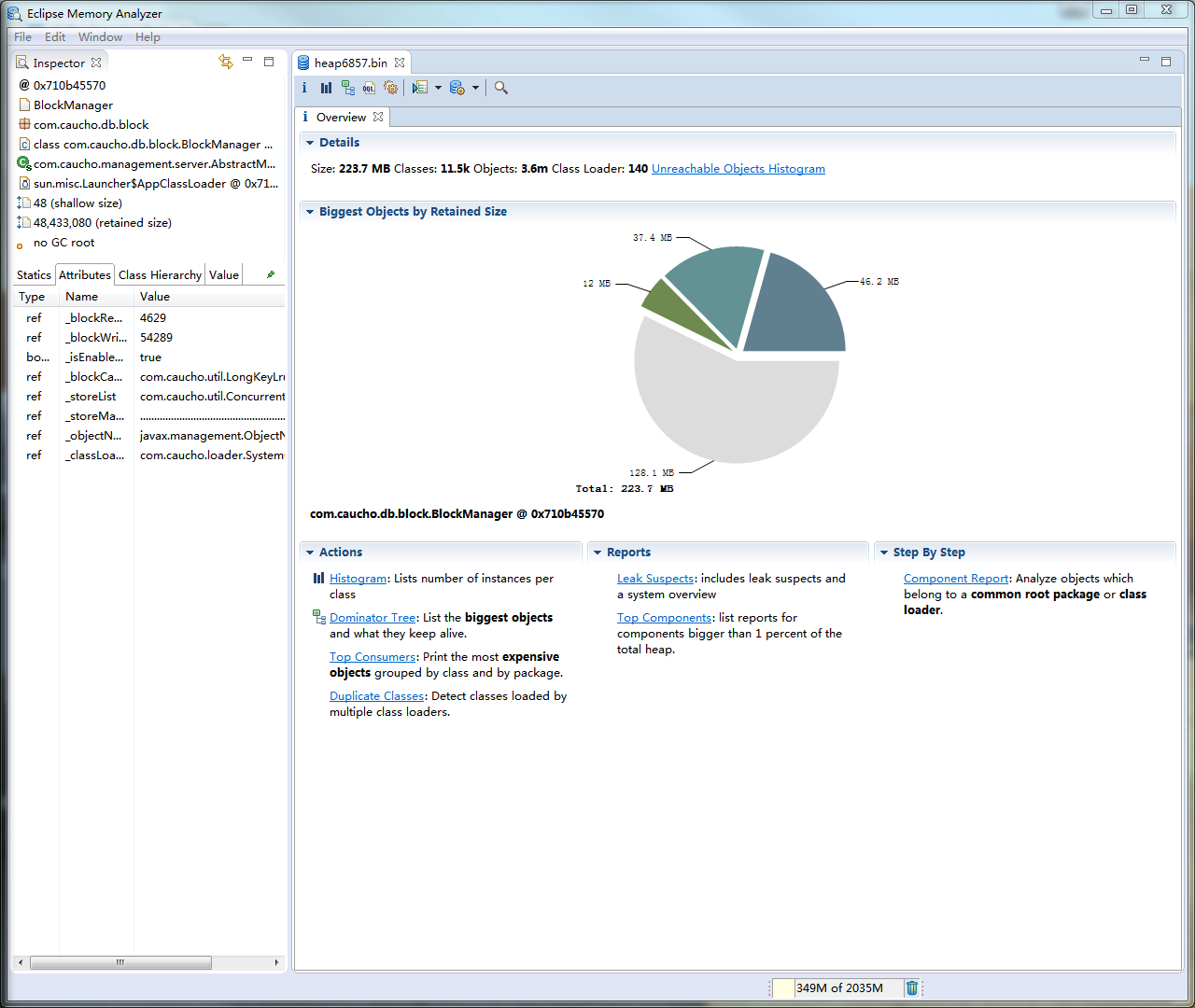
接下来介绍界面中常用到的功能:
 Overview
Overview
Overview视图,即概要界面,显示了概要的信息,并展示了MAT常用的一些功能。
- Details 显示了一些统计信息,包括整个堆内存的大小、类(Class)的数量、对象(Object)的数量、类加载器(Class Loader)的数量。
- Biggest Objects by Retained Size 使用饼图的方式直观地显示了在JVM堆内存中最大的几个对象,当光标移到饼图上的时候会在左边Inspector和Attributes窗口中显示详细的信息。
- Actions 这里显示了几种常用到的操作,算是功能的快捷方式,包括 Histogram、Dominator Tree、Top Consumers、Duplicate Classes,具体的含义和用法见下面;
- Reports 列出了常用的报告信息,包括 Leak Suspects和Top Components,具体的含义和内容见下;
- Step By Step 以向导的方式引导使用功能。
 Histogram
Histogram
直方图,可以查看每个类的实例(即对象)的数量和大小 Dominator Tree
Dominator Tree
支配树,列出Heap Dump中处于活跃状态中的最大的几个对象,默认按 retained size进行排序,因此很容易找到占用内存最多的对象。 OQL
OQL
MAT提供了一个对象查询语言(OQL),跟SQL语言类似,将类当作表、对象当作记录行、成员变量当作表中的字段。通过OQL可以方便快捷的查询一些需要的信息,是一个非常有用的工具。 Thread Overview
Thread Overview
此工具可以查看生成Heap Dump文件的时候线程的运行情况,用于线程的分析。 Run Expert System Test
Run Expert System Test
可以查看分析完成的HTML形式的报告,也可以打开已经产生的分析报告文件,子菜单项如下图所示:
常用的主要有Leak Suspects和Top Components两种报告:
- Leak Suspects 可以说是非常常用的报告了,该报告分析了 Heap Dump并尝试找出内存泄漏点,最后在生成的报告中对检测到的可疑点做了详细的说明;
- Top Components 列出占用总堆内存超过1%的对象。
 Open Query Browser
Open Query Browser
提供了在分析过程中用到的工具,通常都集成在了右键菜单中,在后面具体举例分析的时候会做详细的说明。如下图:
这里仅针对在 Overview 界面中的 Acations中列出的两项进行说明:
- Top Consumers 按类、类加载器和包分别进行查询,并以饼图的方式列出最大的几个对象。菜单打开方式如下:
Duplicate Classes 列出被加载多次的类,结果按类加载器进行分组,目标是加载同一个类多次被类加载器加载。使用该工具很容易找到部署应用的时候使用了同一个库的多个版本。菜单打开方式如下图:
 Find Object by address
Find Object by address
通过十六进制的地址查找对应的对象,见下图:
4.3 使用MAT的Histogram和Dominator Tree定位溢出源
4.3.1 基础概念
4.3.1.1Shallow Heap 和 Retained Heap
Shallow Heap表示对象本身占用内存的大小,不包含对其他对象的引用,也就是对象头加成员变量(不是成员变量的值)的总和。
Retained Heap是该对象自己的Shallow Heap,并加上从该对象能直接或间接访问到对象的Shallow Heap之和。换句话说,Retained Heap是该对象GC之后所能回收到内存的总和。
把内存中的对象看成下图中的节点,并且对象和对象之间互相引用。这里有一个特殊的节点GC Roots,这就是reference chain的起点。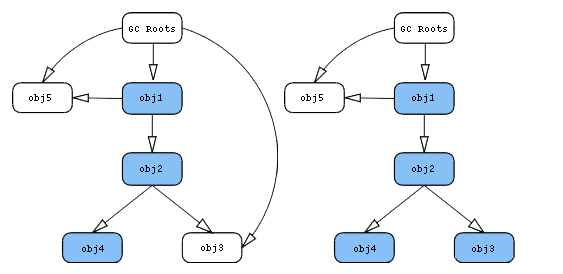
从obj1入手,上图中蓝色节点代表仅仅只有通过obj1才能直接或间接访问的对象。因为可以通过GC Roots访问,所以左图的obj3不是蓝色节点;而在右图却是蓝色,因为它已经被包含在retained集合内。所以对于左图,obj1的retained size是obj1、obj2、obj4的shallow size总和;右图的retained size是obj1、obj2、obj3、obj4的shallow size总和。obj2的retained size可以通过相同的方式计算。
4.3.1.2 对象引用(Reference)
对象引用按从最强到最弱有如下级别,不同的引用(可到达性)级别反映了对象的生命周期:
- 强引用(Strong Ref):通常我们编写的代码都是强引用,于此相对应的是强可达性,只有去掉强可达性,对象才能被回收。
- 软引用(Soft Ref):对应软可达性,只要有足够的内存就一直保持对象,直到发现内存不足且没有强引用的时候才回收对象。
- 弱引用(Weak Ref):比软引用更弱,当发现不存在强引用的时候会立即回收此类型的对象,而不需要等到内存不足。通过java.lang.ref.WeakReference和java.util.WeakHashMap类实现。
- 虚引用(Phantom Ref):根本不会在内存中保持该类型的对象,只能使用虚引用本身,一般用于在进入finalize()方法后进行特殊的清理过程,通过java.lang.ref.PhantomReference实现。
4.3.1.3 GC Roots和Reference Chain
JVM在进行GC的时候是通过使用可达性来判断对象是否存活,通过GC Roots(GC根节点)的对象作为起始点,从这些节点开始进行向下搜索,搜索所走过的路径成为Reference Chain(引用链),当一个对象到GC Roots没有任何引用链相连(用图论的话来说就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。
如下图所示,对象object 5、object 6、object 7虽然互相有关联,它们的引用并不为0,但是它们到GC Roots是不可达的,因此它们将会被判定为是可回收的对象。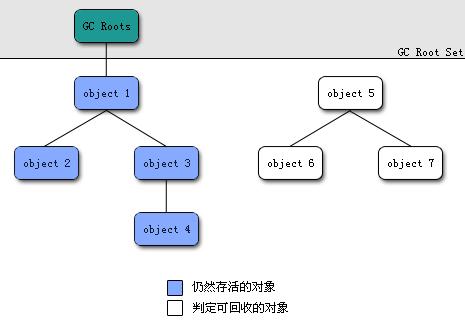
4.3.2 Histogram(直方图)视图
点击工具栏上的 图标可以打开Histogram(直方图)视图,可以列出每个类产生的实例数量,以及所占用的内存大小和百分比。主界面如下图所示:
图标可以打开Histogram(直方图)视图,可以列出每个类产生的实例数量,以及所占用的内存大小和百分比。主界面如下图所示: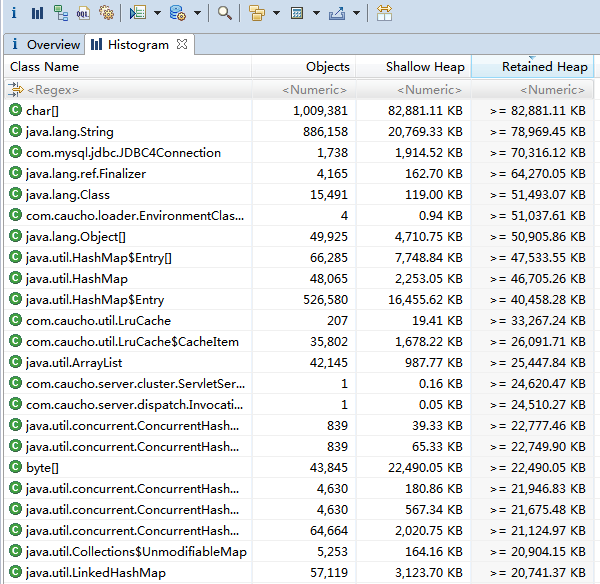
图中Shallow Heap 和 Retained Heap分别表示对象自身不包含引用的大小和对象自身并包含引用的大小,具体请参考下面 Shallow Heap 和 Retained Heap 部分的内容。默认的大小单位是 Bytes,可以在 Window - Preferences 菜单中设置单位,图中设置的是KB。
通过直方图视图可以很容易找到占用内存最多的几个类(通过Retained Heap排序),还可以通过其他方式进行分组(见下图)。
如果存在内存溢出,时间久了溢出类的实例数量或者内存占比会越来越多,排名也越来越靠前。可以点击工具类上的 图标进行对比,通过多次对比不同时间点下的直方图对比就很容易把溢出的类找出来。
图标进行对比,通过多次对比不同时间点下的直方图对比就很容易把溢出的类找出来。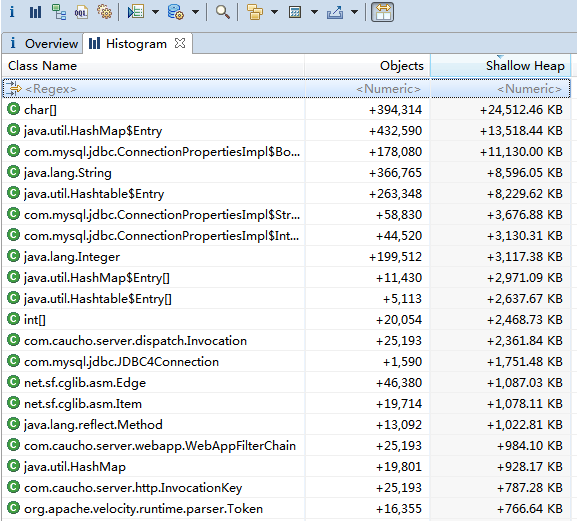
还有一种对比直方图的方式,首先通过 Window 菜单打开 Navigation History 视图,选中直方图右键并选中 Add to Compare Basket项目,将直方图添加到 Compare Basket 中。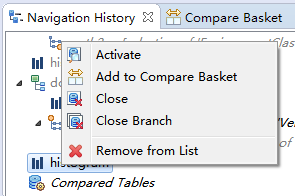
然后在 Compare Basket 中点击右上角的 按钮,可以分别列出对比的所有结果,见下图:
按钮,可以分别列出对比的所有结果,见下图: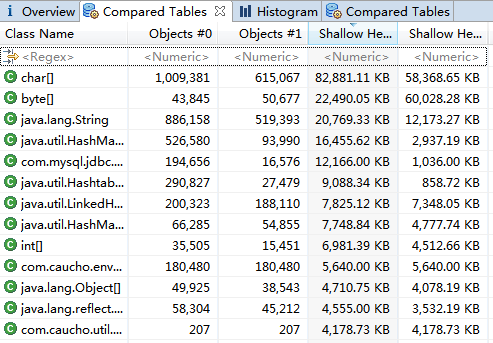
并且在上面的可以设置不同的对比方式。
4.3.3 Dominator Tree视图
点击工具栏上的 图标可以打开Dominator Tree(支配树)视图,在此视图中列出了每个对象(Object Instance)与其引用关系的树状结构,同时包含了占用内存的大小和百分比。
图标可以打开Dominator Tree(支配树)视图,在此视图中列出了每个对象(Object Instance)与其引用关系的树状结构,同时包含了占用内存的大小和百分比。
通过Dominator Tree视图可以很容易的找出占用内存最多的几个对象(根据Retained Heap或Percentage排序),和Histogram类似,可以通过不同的方式进行分组显示:
4.3.4 定位溢出源
Histogram视图和Dominator Tree视图的角度不同,前者是基于类的角度,后者是基于对象实例的角度,并且可以更方便的看出其引用关系。
首先,在两个视图中找出疑似溢出的对象或者类(可以通过Retained Heap排序,并且可以在Class Name中输入正则表达式的关键词只显示指定的类名),然后右键选择Path To GC Roots(Histogram中没有此项)或Merge Shortest Paths to GC Roots,然后选择 exclude all phantom/weak/soft etc. reference: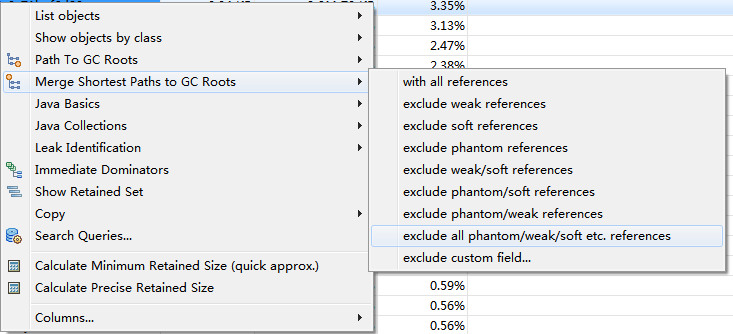
GC Roots意为GC根节点,其含义见上面的 GC Roots和Reference Chain 部分,后面的 exclude all phantom/weak/soft etc. reference 意思是排除虚引用、弱引用和软引用,即只剩下强引用,因为除了强引用之外,其他的引用都可以被JVM GC掉,如果一个对象始终无法被GC,就说明有强引用存在,从而导致在GC的过程中一直得不到回收,最终就内存溢出了。
通过结果就可以很方便的定位到具体的代码,然后分析是什么原因无法释放该对象,比如被缓存了或者没有使用单例模式等等。
下面是执行的结果: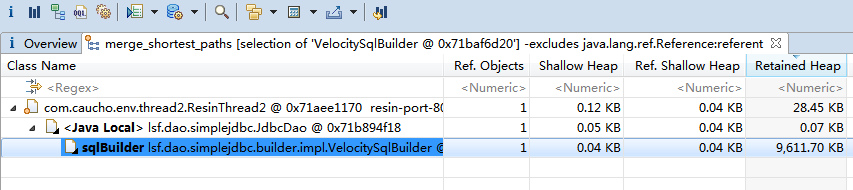
上图中保留了大量的VelocitySqlBulder的外部引用,后来查看了代码,原来每次调用的时候都实例化一个新的对象,由于VelocitySqlBulder类是无状态的工具类,因此修改为单例方式就可以解决这个问题。4.3.5 后续观察
根据上面分析的结果对问题进行处理之后,再对照之前的操作,看看对象是否还再持续增长,如果没有就说明这个地方的问题已经解决了。
最后再用 jstat 持续跟踪一段时间,看看Old和Perm区的内存是否最终稳定在一个范围之内,如果长时间稳定在一个范围说明溢出问题得到了解决,否则还要继续进行分析和处理,一直到稳定为止。4.4 使用 Eclipse Memory Analyzer实例
我选取了2021-01-31 药房erp后台一直报内存溢出的实例。
下面列举分析过程4.4.1 概述
对于大型 JAVA 应用程序来说,再精细的测试也难以堵住所有的漏洞,即便我们在测试阶段进行了大量卓有成效的工作,很多问题还是会在生产环境下暴露出来,并且很难在测试环境中进行重现。JVM 能够记录下问题发生时系统的部分运行状态,并将其存储在堆转储 (Heap Dump) 文件中,从而为我们分析和诊断问题提供了重要的依据。
通常内存泄露分析被认为是一件很有难度的工作,一般由团队中的资深人士进行。不过,今天我们要介绍的 MAT(Eclipse Memory Analyzer)被认为是一个”傻瓜式”的堆转储文件分析工具,你只需要轻轻点击一下鼠标就可以生成一个专业的分析报告。和其他内存泄露分析工具相比,MAT 的使用非常容易,基本可以实现一键到位,即使是新手也能够很快上手使用。
MAT 的使用是如此容易,你是不是也很有兴趣来亲自感受下呢,那么第一步我们先来安装 MAT。4.4.2 准备环境和测试数据
我们使用的是 Eclipse Memory Analyzer V0.8,Sun JDK 84.4.2.1安装 MAT
和其他插件的安装非常类似,MAT 支持两种安装方式,一种是”单机版”的,也就是说用户不必安装 Eclipse IDE 环境,MAT 作为一个独立的 Eclipse RCP 应用运行;另一种是”集成版”的,也就是说 MAT 也可以作为 Eclipse IDE 的一部分,和现有的开发平台集成。
集成版的安装需要借助 Update Manager。(直接在上一步安装单机版本即可,集成版本暂时不考虑)
单机版的安装方式非常简单,用户只需要下载相应的安装包,然后解压缩即可运行,这也是被普遍采用的一种安装方式。在下面的例子里,我们使用的也是单机版的 MAT。具体的下载要求和地址可参见其产品下载页面: http://www.eclipse.org/mat/downloads.php 。
另外,如果你需要用 MAT 来分析 IBM JVM 生成的 dump 文件的话,还需要额外安装 IBM Diagnostic Tool Framework ,具体的下载和安装配置步骤请参见:http://www.ibm.com/developerworks/java/jdk/tools/dtfj.html 。4.4.2.2 配置环境参数
安装完成之后,为了更有效率的使用 MAT,我们还需要做一些配置工作。因为通常而言,分析一个堆转储文件需要消耗很多的堆空间,为了保证分析的效率和性能,在有条件的情况下,我们会建议分配给 MAT 尽可能多的内存资源。你可以采用如下两种方式来分配内存更多的内存资源给 MAT。
一种是修改启动参数 MemoryAnalyzer.exe -vmargs -Xmx4g
另一种是编辑文件 MemoryAnalyzer.ini,在里面添加类似信息 -vmargs – Xmx4g。
至此,MAT 就已经成功地安装配置好了,开始进入实战吧。4.4.2.3 获得堆转储文件
巧妇难为无米之炊,我们首先需要获得一个堆转储文件。为了方便,本文采用的是 Sun JDK 8。通常来说,只要你设置了如下所示的 JVM 参数:
-XX:+HeapDumpOnOutOfMemoryError ```bash nohup java -jar -Xms512m -Xmx512m -XX:+HeapDumpOnOutOfMemoryError yf-0.0.1-SNAPSHOT.jar —spring.config.location=application-dev.ymlyyf.file 2>&1 &
JVM 就会在发生内存泄露时抓拍下当时的内存状态,也就是我们想要的堆转储文件。<br />如果你不想等到发生崩溃性的错误时才获得堆转储文件,也可以通过设置如下 JVM 参数来按需获取堆转储文件。<br />-XX:+HeapDumpOnCtrlBreak<br />除此之外,还有很多的工具,例如 [JMap](http://java.sun.com/j2se/1.5.0/docs/tooldocs/share/jmap.html) ,JConsole 都可以帮助我们得到一个堆转储文件。本文实例就是使用 JMap 直接获取了 Eclipse Galileo 进程的堆转储文件。您可以使用如下命令:<br />JMap -dump:format=b,file=<dumpfile> <pid><br />不过,您需要了解到,不同厂家的 JVM 所生成的堆转储文件在数据存储格式以及数据存储内容上有很多区别, MAT 不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如 Sun, HP, SAP 所采用的 HPROF 二进制堆存储文件,以及 IBM 的 PHD 堆存储文件等都能被很好的解析(您需要安装额外的插件,请参考 [相关说明](http://www.ibm.com/developerworks/java/jdk/tools/dtfj.html) ,本文不作详细解释)。<br />万事俱备,接下来,我们就可以开始体验一键式的堆存储分析功能了。<br />下图即为正式环境内存溢出时自动生成的dump文件实例。<br />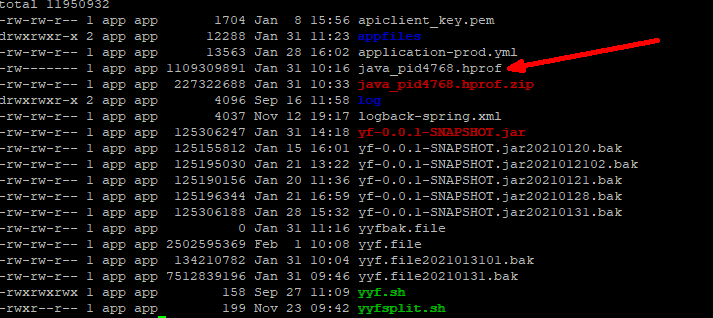<a name="yOsiK"></a>### 4.4.3 生成分析报告首先,启动前面安装配置好的 Memory Analyzer tool , 然后选择菜单项 File- Open Heap Dump 来加载需要分析的堆转储文件。文件加载完成后,你可以看到如图 4 所示的界面:<a name="g4uq9"></a>##### 图 4. 概览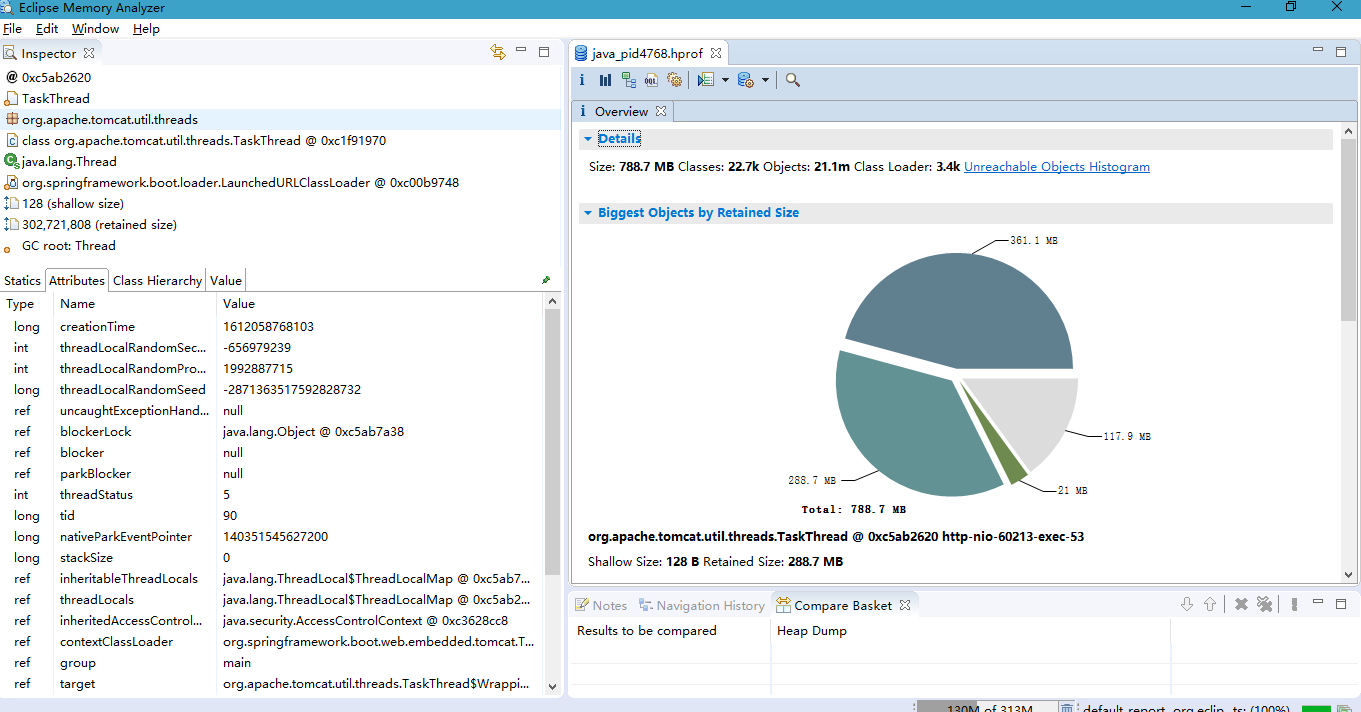<br />通过上面的概览,我们对内存占用情况有了一个总体的了解。先检查一下 MAT 生成的一系列文件。<a name="k5B1t"></a>##### 图 5. 文件列表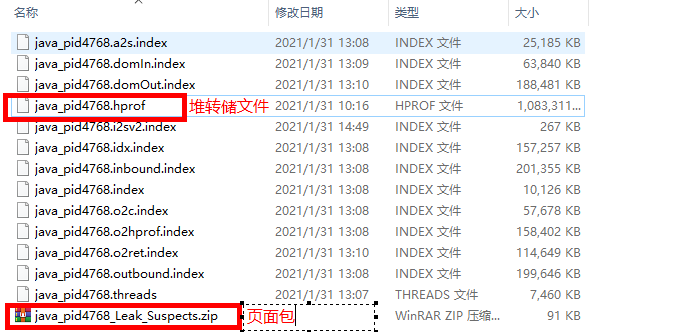可以看到 MAT 工具提供了一个很贴心的功能,将报告的内容压缩打包到一个 zip 文件,并把它存放到原始堆转储文件的存放目录下,这样如果您需要和同事一起分析这个内存问题的话,只需要把这个小小的 zip 包发给他就可以了,不需要把整个堆文件发给他。并且整个报告是一个 HTML 格式的文件,用浏览器就可以轻松打开。<br />接下来我们就可以来看看生成的报告都包括什么内容,能不能帮我们找到问题所在吧。您可以点击工具栏上的 Leak Suspects 菜单项来生成内存泄露分析报告,也可以直接点击饼图下方的 Reports->Leak Suspects 链接来生成报告。<a name="kVy2C"></a>##### 图 6. 工具栏菜单<a name="0f9l3"></a>### 4.4.4 分析三步曲通常我们都会采用下面的”三步曲”来分析内存泄露问题:<br />首先,对问题发生时刻的系统内存状态获取一个整体印象。<br />第二步,找到最有可能导致内存泄露的元凶,通常也就是消耗内存最多的对象<br />接下来,进一步去查看这个内存消耗大户的具体情况,看看是否有什么异常的行为。<br />下面将用一个基本的例子来展示如何采用”三步曲”来查看生产的分析报告。<a name="NGkkJ"></a>#### 4.4.4.1查看报告之一:内存消耗的整体状况<a name="iMZbh"></a>##### 图 7. 内存泄露分析报告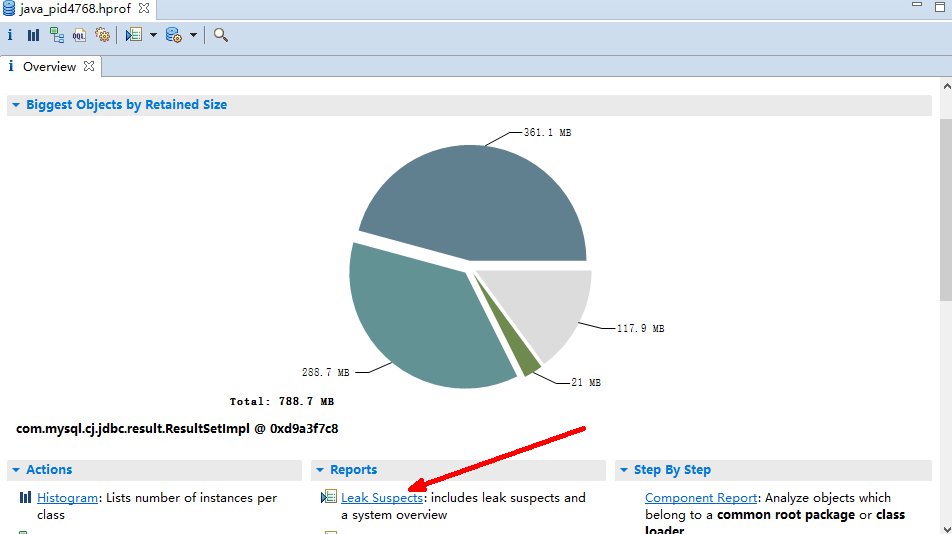<br />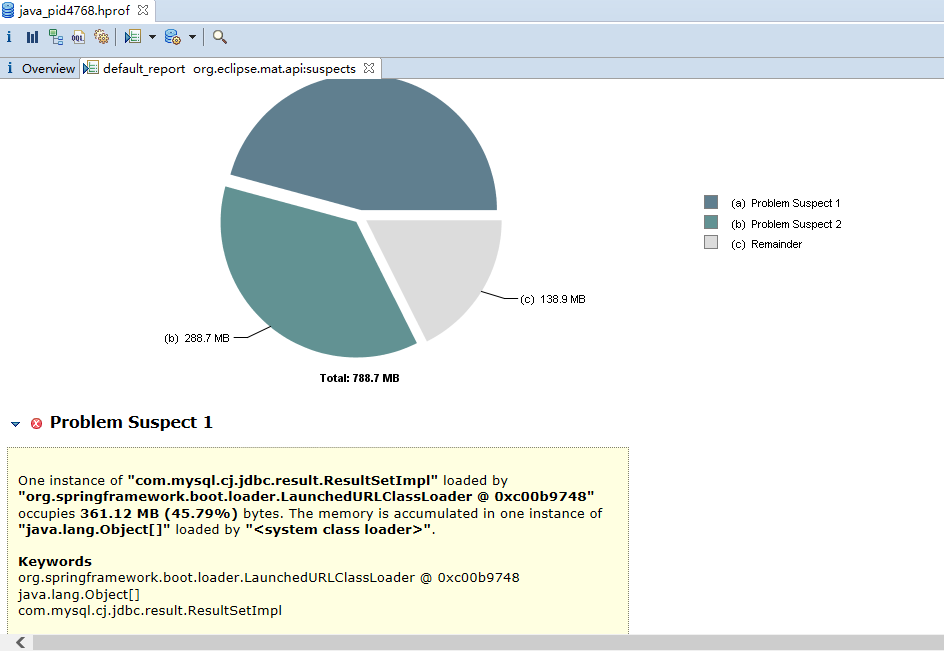<br />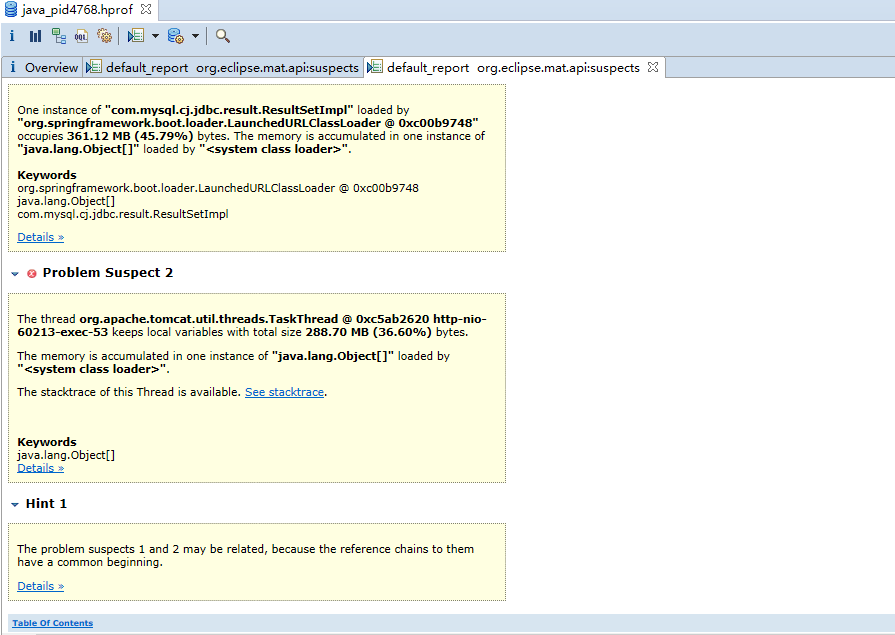<br />如图 7 所示,在报告上最醒目的就是一张简洁明了的饼图,从图上我们可以清晰地看到一个两个可疑对象消耗了系统大概70% 的内存。<br />在图的下方还有对这个可疑对象的进一步描述。我们可以看到内存是由 com.mysql.cj.jdbc.result.ResultSetImpl 的实例和org.apache.tomcat.util.threads.TaskThread消耗的,而且hint1写明这两个实例有关联关系,因为出发点是一样的。这段描述非常短,但是能获取到很多线索,比如是哪个类占用了绝大多数的内存,它属于哪个组件等等。<br />接下来,我们应该进一步去分析问题,为什么数据库的返回集合和他的关联会占据了系统 70% 的内存,谁阻止了垃圾回收机制对它的回收。<a name="fR4Gk"></a>#### 4.4.4.2 查看报告之二:分析问题的所在首先我们简单回顾下 JAVA 的内存回收机制,内存空间中垃圾回收的工作由垃圾回收器 (Garbage Collector,GC) 完成的,它的核心思想是:对虚拟机可用内存空间,即堆空间中的对象进行识别,如果对象正在被引用,那么称其为存活对象,反之,如果对象不再被引用,则为垃圾对象,可以回收其占据的空间,用于再分配。<br />在垃圾回收机制中有一组元素被称为根元素集合,它们是一组被虚拟机直接引用的对象,比如,正在运行的线程对象,系统调用栈里面的对象以及被 system class loader 所加载的那些对象。堆空间中的每个对象都是由一个根元素为起点被层层调用的。因此,一个对象还被某一个存活的根元素所引用,就会被认为是存活对象,不能被回收,进行内存释放。因此,我们可以通过分析一个对象到根元素的引用路径来分析为什么该对象不能被顺利回收。如果说一个对象已经不被任何程序逻辑所需要但是还存在被根元素引用的情况,我们可以说这里存在内存泄露。<br />现在,让我们开始真正的寻找内存泄露之旅,点击”Details ”链接,可以看到如图 8 所示对可疑对象 1 的详细分析报告。<a name="hmJC1"></a>##### 图 8. 可疑对象 1 的详细分析报告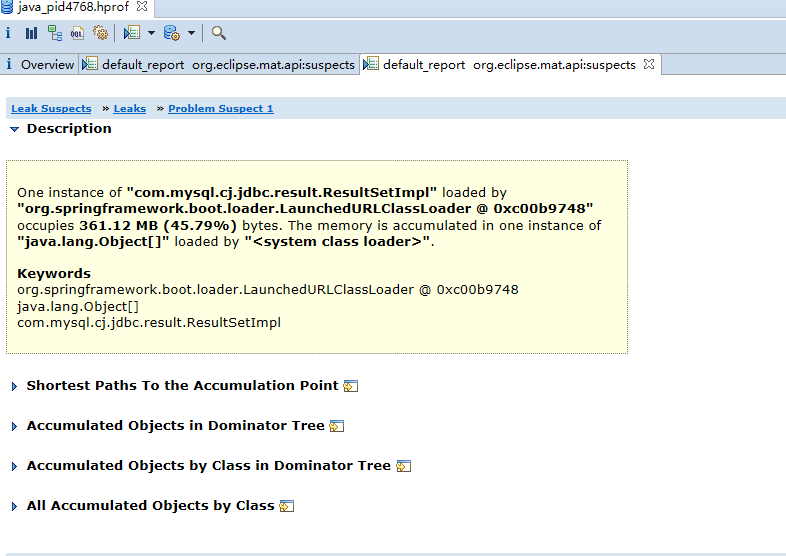1. 我们查看下从 GC 根元素到内存消耗聚集点的最短路径:<a name="9yPru"></a>##### 图 9. 从根元素到内存消耗聚集点的最短路径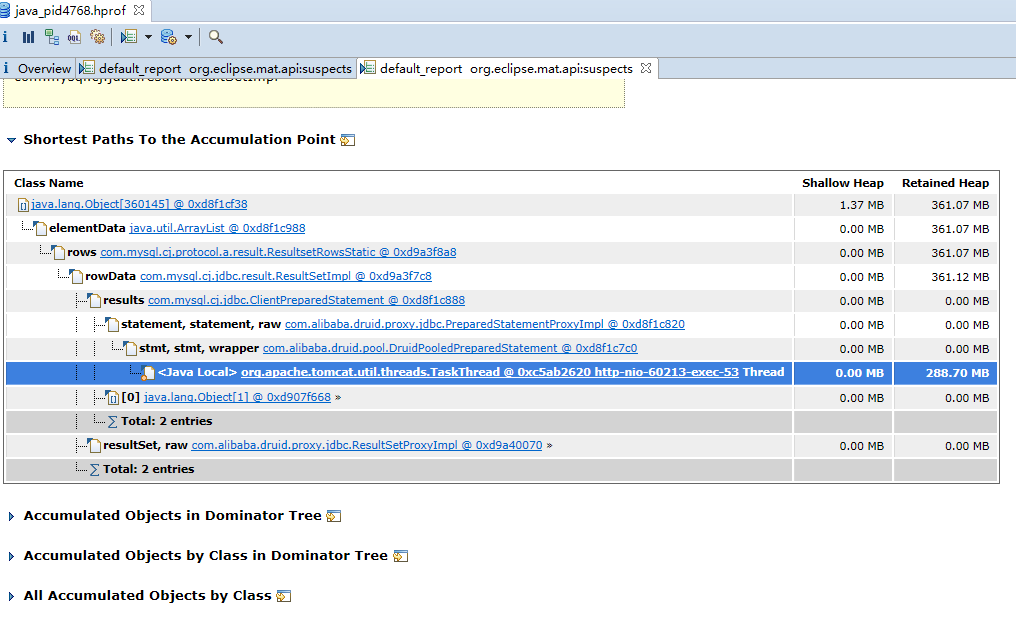<br />我们可以很清楚的看到整个引用链,内存聚集点是一个拥有大量对象的List集合,如果你对代码比较熟悉的话,相信这些信息应该能给你提供一些找到内存泄露的思路了。<br />接下来,我们再继续看看,这个对象集合里到底存放了什么,为什么会消耗掉如此多的内存。<a name="doHhN"></a>##### 图 10. 内存消耗聚集对象信息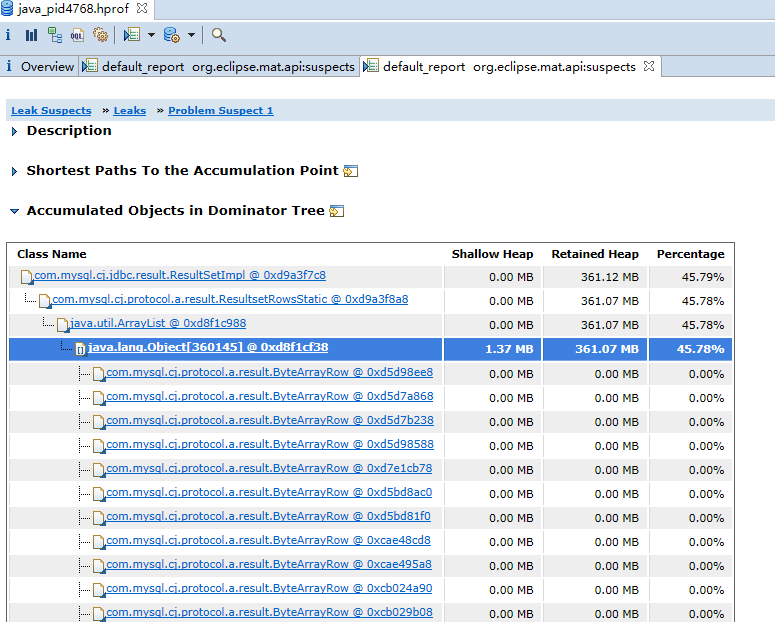<br />在这张图上,我们可以清楚的看到,这个对象集合中保存了大量数据库返回集合对象的引用,(com.mysql.cj.jdbc.result.ResultSetImpl这个类就是数据库返回信息的保存类)就是它导致的内存泄露。<br />然后我们再分析第二大块未回收的内存<br />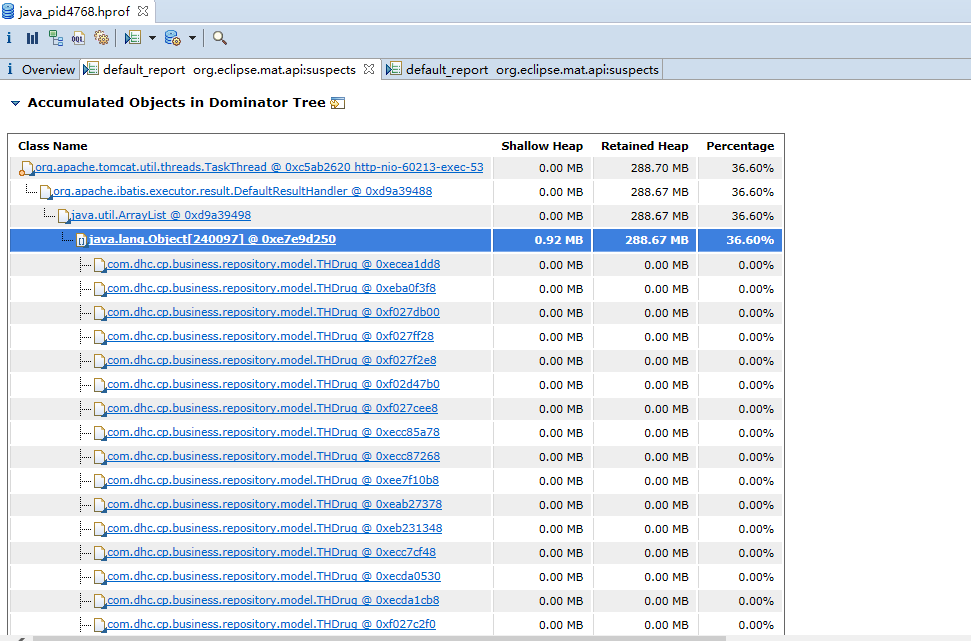<br />发现这个是tHDrug这个model的引用,再结合hint1提示的这两个内存块有关联关系,所以我们有理由确认数据库返回的集合就是t_h_drug 这个表的信息。<br />现在问题比较好确认了,医保库的查询正常是不会返回大批量数据的,所以一定是有哪个功能导致了大数据查询。正常如果对业务代码比较熟悉的话可以直接通过业务逻辑检查确认。但是更迅速准确的方法还是通过内存溢出期间的日志来定位。<br />对这个错误的排查我的思路是:既然是大数据查询,那么可以怀疑一定有一条查询全部医保库的sql,所以只要找到溢出前后大概几分钟范围内的这条sql就能获取到更明确的信息。```xml2021-01-31 09:31:52.004 INFO "sql":"select ... from GAC1 a inner join t_drug b on a.GAC51= b.id left join t_drug_insurance c on b.id = c.drug_id where a.GAC01 = '542771783095291904'"}2021-01-31 09:31:52.006 INFO "sql":"select ... from t_h_drug"}
果然,通过排查找到了一条符合条件的sql,通过对比mapper.xml可以找到对应接口,再找接口的调用关系最终定位到医保预结算信息转换的位置,少了一个判断,导致传入的查询条件为空。最终导致查询出了整个医保库。
清单 1. 内存泄漏的代码段
Gac1 model = this.gac1Mapper.selectById(detailDto.getGac01());if (model == null) {throw new BusinessRuntimeException("400", "查无此药品信息");}// 获取医保信息THDrugSelectListInDTO inDTO = new THDrugSelectListInDTO();// 20201222 医保库查询只用医保编码inDTO.setA001(model.getInsurancebm());// inDTO.setA014(model.getGac06());List<THDrugSelectListOutDTO> tDrugList = this.tHDrugService.selectList(inDTO);// 如果查询不到则报错if (tDrugList == null || tDrugList.size() == 0) {throw new BusinessRuntimeException("400", model.getGac06() + "药品不在医保内,请联系管理员");}
最终加上校验修改为:
Gac1 model = this.gac1Mapper.selectById(detailDto.getGac01());if (model == null) {throw new BusinessRuntimeException("400", "查无此药品信息");}// 20210131 补充对医保码的判断 如果不存在医保码 返回异常if (StringUtil.isEmpty(model.getInsurancebm())) {throw new BusinessRuntimeException("400", model.getGac06() + "药品不在医保内或者药房手动设置了不关联医保药品。");}// 获取医保信息THDrugSelectListInDTO inDTO = new THDrugSelectListInDTO();// 20201222 医保库查询只用医保编码inDTO.setA001(model.getInsurancebm());// inDTO.setA014(model.getGac06());List<THDrugSelectListOutDTO> tDrugList = this.tHDrugService.selectList(inDTO);// 如果查询不到则报错if (tDrugList == null || tDrugList.size() == 0) {throw new BusinessRuntimeException("400", model.getGac06() + "药品不在医保内,请联系管理员");}

若有收获,就点个赞吧
0 人点赞
