使用背景:
公司一直想有一种一站式解决数据转换、数据质量管理、数据开发,流程调度、可视化等功能的数据中台组件,之前我接触到的是阿里的dataworks,由于种种原因,没有选择dataworks。也就是在去年的这个时候,我接触到了linkis和wedatasphere等大数据组件,并且在去年就已经在生产中使用。因为我们公司在前不久hadoop版本进行了升级,带来了一些不兼容的情况,我这边升级后使用的是hadoop3.0.0和spark2.4.3。
问题解决:
linkis1.0官方下载的编译好的二进制包对应的各组件版本是:hadoop-2.7.3、hive-2.3.3,spark-2.4.3,如果你几种组件的大版本相同应该是可以编译和安装成功的,这个不兼容不是linkis的原因,主要是spark2官方没有提供hadoop3对应的二进制包,spark2官方提供的最大的二进制包是hadoop2.7
我这边先使用hadoop3.0.0,spark2.4.3对linkis进行编译,编译顺利完成,具体编译参考linkis官方文档。上图讲述说spark2官方没有提供hadoop3的二进制包,那我这边就尝试使用上图的spark2.4.3-hadoop2.7的包,看看linkis是否兼容,实验验证是不兼容,报的错如下图:Unable to instantiate SparkSession with Hive Support beacause Hive Class are not found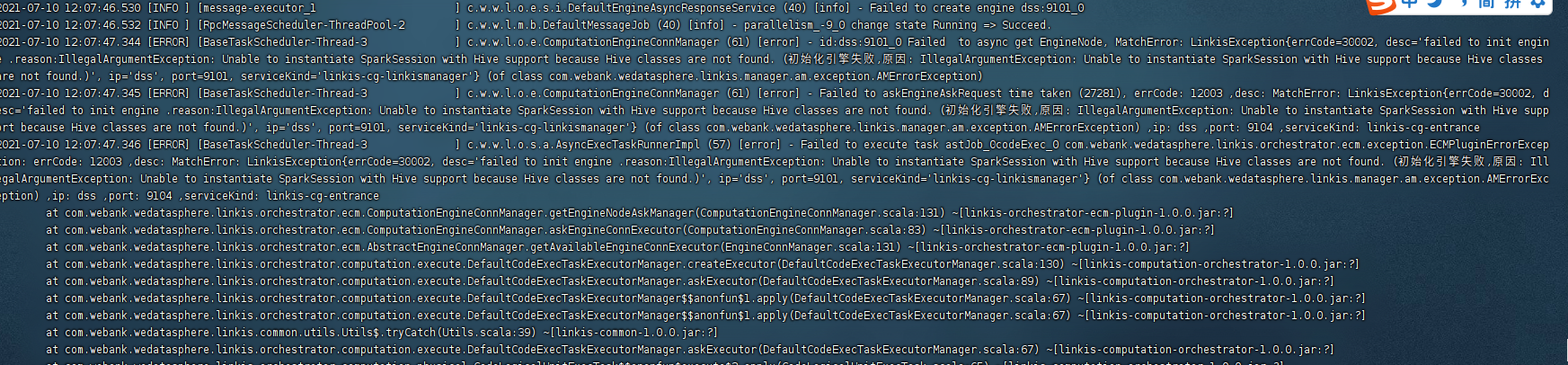
既然不兼容,那我们就自己编译spark的源码,源码下载地址:spark-2.4.3.tgz
解压后,cd 进入spark_home目录,然后使用以下命令编译
./dev/make-distribution.sh —name hadoop-3.0.0 —tgz -Phadoop-3.0 -Dhadoop.version=3.0.0 -Phive -Phive-thriftserver -Pyarn
编译完成后,启动spark-sql发现错误,Unrecognized Hadoop major version number:3.0.0,通过查看spark源码发现是ShimLoader中的getMajorVersion方法,hadoop版本大于3的直接报异常:Unrecognized Hadoop major version number:3.0.0
| public static String getMajorVersion() { // 获取hadoop版本号,在复现环境中,这边即3.0.0; final String vers = VersionInfo.getVersion(); final String[] parts = vers.split(“\\.”); if (parts.length < 2) { throw new RuntimeException(“Illegal Hadoop Version: “ + vers + “ (expected A.B.* format)”); } // 从这边来看,hadoop 3.x的版本便会抛出IllegalArgumentException. switch (Integer.parseInt(parts[0])) { case 1: { return ShimLoader.HADOOP20SVERSIONNAME; } case 2: { return ShimLoader.HADOOP23VERSIONNAME; } default: { throw new IllegalArgumentException(“Unrecognized Hadoop major version number: “ + vers); } } } |
|---|
其对应的jar包是hive-exec:1.2.1.spark2,但是spark官方并没有提供hive2版本的jar包,那只能自己修改源码进行编译,git clone hive-spark2到本地,github地址https://github.com/leongu-tc/hive-spark2,找到ShimLoader类,并且修改getMajorVersion方法:修改如下:
| public static String getMajorVersion() { String vers = VersionInfo.getVersion(); String[] parts = vers.split(“\\.”); if (parts.length < 2) { throw new RuntimeException(“Illegal Hadoop Version: “ + vers + “ (expected A.B.* format)”); } else { switch(Integer.parseInt(parts[0])) { case 2: case 3: return HADOOP23VERSIONNAME; default: throw new IllegalArgumentException(“Unrecognized Hadoop major version number: “ + vers); } } } |
|---|
只需要编译hive-exec就可以了,然后从新编译spark2.4.3的源码,然后按照正常配置就可以使用了。
感谢:
非常感谢linkis团队队员,也欢迎大家加入到共同建设linkis的队伍中来。

若有收获,就点个赞吧
0 人点赞
