Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core中提供了Spark最基础与最核心的功能
- Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
- Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
由上面的信息可以获知,Spark出现的时间相对较晚,并且主要功能主要是用于数据计算,所以其实Spark一直被认为是Hadoop 框架的升级版。
生态体系
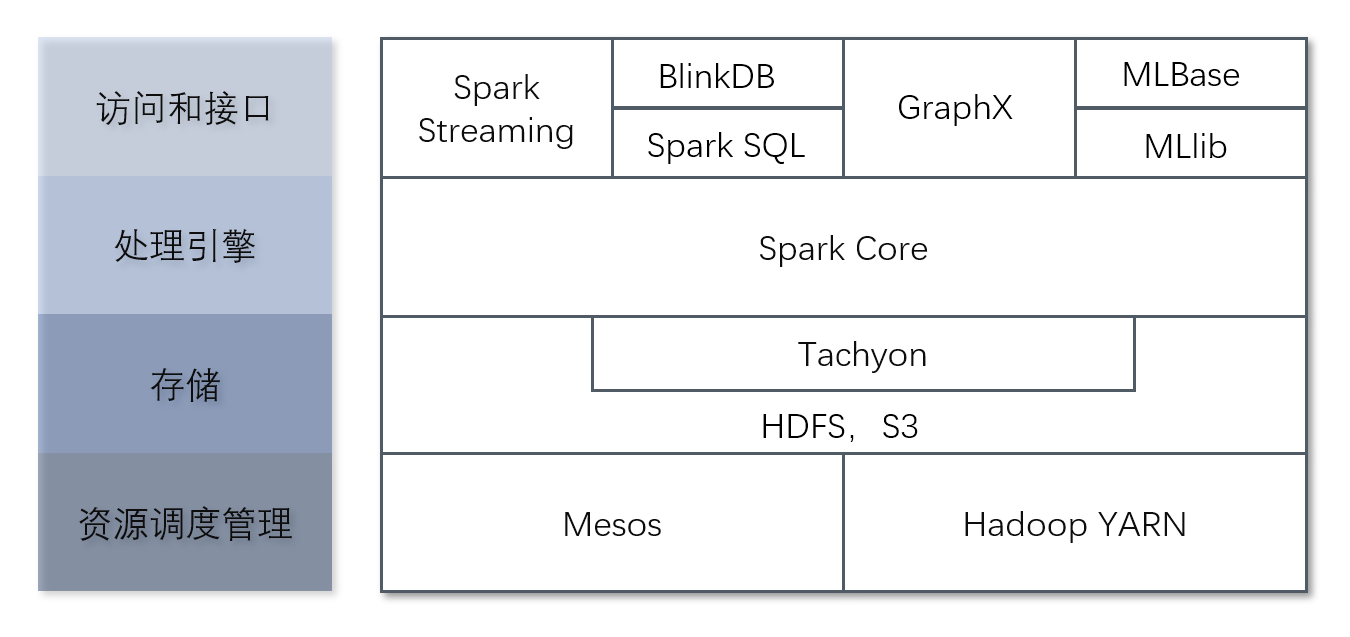
- Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的。
- Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
- Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark Streaming基于微批量方式的计算和处理,可以用于处理实时的流数据。它使用DStream,简单来说是一个弹性分布式数据集(RDD)系列,处理实时数据。数据可以从Kafka,Flume,Kinesis或TCP套接字等众多来源获取,并且可以使用由高级函数(如 map,reduce,join 和 window)开发的复杂算法进行流数据处理。最后,处理后的数据可以被推送到文件系统,数据库和实时仪表板。
- Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
- Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库。

若有收获,就点个赞吧
0 人点赞
