RDD的全称为Resiliennt Distributed Datasets,是一个弹性、可复原的分布式数据集,是Spark中最基本的抽象,是一个不可变的、有多个分区的、可以并行计算的集合。
事实上,RDD并不装真正要计算的数据,而装的是描述信息,描述从哪读取数据,调用什么方法,传入什么函数,以及依赖关系等。
Spark程序开发者最终会与RDD接口打交道。Spark与 MapReduce的不同点就在于Spark提供了更加丰富的操作给最终程序开发者,而不只局限于Map和 Reduce两个操作。开发者可以利用Spark接口非常容易地编写出复杂的数据处理流水线,所以本章将会具体介绍RDD的基本概念,以及RDD的所有接口。
一、Hello World
var sc = new SparkContext("spark://localhost:7077", "Hello world!", "YOUR_SPARK_HOME", "YOUR_APP_JAR")var file = sc.textFile("hdfs:root/Log")var filterRDD = file.filter(_.contains("Hello World!"))filterRDD.cache()filterRDD.count()
var sc = new SparkContext("spark://localhost:7077", "Hello world!", "YOUR_SPARK_HOME", "YOUR_APP_JAR")
对于所有的Spark程序而言,要进行任何操作,首先要创建一个Spark的上下文,在创建上下文的过程中,程序会向集群申请资源以及构建相应的运行环境。
一般来说,创建SparkContext对象需要传入四个变量,
- 第一变量就是这个Spark程序运行的集群地址,比如“spark://localhost:7077”(假设集群在本地启动监听7077端口);
- 第二个参数就是Spark程序的标识;
- 第三个参数需要指明Spark安装的路径;
- 第四个参数需要传入这个 Spark程序的jar包路径。
var file = sc.textFile("hdfs:root/Log")
通过sc变量,利用textFile接口从HDFS文件系统中读入Log文件,返回一个变量file。
var filterRDD = file.filter(_.contains("Hello World!"))
对file变量进行过滤操作,传入的参数是一个 function对象,function的原型p: (A)=> Boolean,对于file 中的每一行字符串判断是否含有“HelloWorld”字符串,生成新的变量filterRDD。
filterRDD.cache()
对filterRDD进行cache操作,以便后续操作重用filterRDD这个变量。
filterRDD.count()
对filterRDD进行count计数操作,最后返回包含“Hello World”字符串的文本行数。
重要概念
- 弹性分布式数据集RDD ( Resilient Distributed DataSets)
file和filterRDD变量都是RDD。
- 创建操作(creation operation)
RDD的初始创建都是由SparkContext来负责的,将内存中的集合或者外部文件系统作为输入源。
- 转换操作( transformation operation)
将一个RDD通过一定的操作变换成另一个 RDD,比如 file这个RDD通过一个 filter 操作变换成filterRDD,所以filter就是一个转换操作。
- 控制操作(control operation)
对RDD进行持久化,可以让RDD保存在磁盘或者内存中,以便后续重复使用。比如 cache接口默认将filterRDD缓存在内存中。
- 行动操作(action operation)
由于Spark是惰性计算 ( lazy computing)的,所以对于任何RDD进行行动操作,都会触发Spark作业的运行,从而产生最终的结果。例如,我们对filterRDD进行的count操作就是一个行动操作。Spark中的行动操作基本分为两类,一类的操作结果变成Scala集合或者标量,另一类就将RDD保存到外部文件或者数据库系统中。
对于一个Spark 数据处理程序而言,一般情况下RDD与操作之间的关系如下图所示,经过输入操作(创建操作)、转换操作、控制操作、输出操作(行动操作)来完成一个作业。当然在一个Spark应用程序中,可以有多个行动操作,也就是有多个作业存在,这些会在 Spark调度章节中进行详细描述。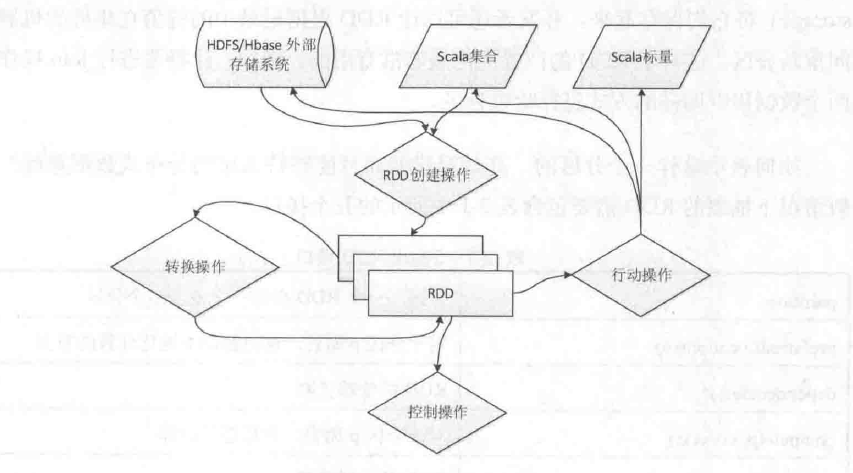
二、Spark RDD
RDD是弹性分布式数据集,即一个 RDD代表一个被分区的只读数据集。一个RDD的生成只有两种途径,一是来自于内存集合和外部存储系统,另一种是通过转换操作来自于其他RDD,比如 map、 filter、join,等等。
RDD没必要随时被实例化,由于RDD 的接口只支持粗粒度的操作(即一个操作会被应用在 RDD的所有数据上),所有只要通过记录下这些作用在RDD之上的转换操作,来构建 RDD的继承关系 ( lineage),就可以有效地进行容错处理,而不需要将实际的RDD 数据进行记录拷贝。这对于RDD来说是一项非常强大的功能,也即是在一个Spark程序中,我们所用到的每一个 RDD,在丢失或者操作失败后都是可以重建的。
应用程序开发者还可以对RDD进行另外两个方面的控制操作:持久化和分区。开发者可以指明他们需要重用哪些RDD,然后选择一种存储策略(如in-memorystorage)将它们保存起来。开发者还可以让RDD根据记录中的键值在集群的机器之间重新分区。
这对于RDD的位置优化是非常有用的。例如,让将要进行join操作的两个数据集以同样的方式进行哈希分区。
一般情况下抽象的RDD需要包含以下五个接口。
| partition | 分区,一个RDD会有一个或多个分区 |
|---|---|
| preferredLocations(p) | 对于分区P而言,返回数据本地化计算的节点 |
| dependencies() | RDD的依赖关系 |
| compute(p,context) | 对于分区P而言,进行迭代计算 |
| partitioner() | RDD的分区函数 |
1、RDD分区(partition)
既然RDD是一个分区的数据集,那么RDD肯定具备分区的属性,对于一个RDD而言,分区的多少涉及对这个 RDD进行并行计算的粒度,每一个RDD分区的计算操作都在一个单独的任务中被执行。对于RDD的分区而言,用户可以自行指定多少分区,如果没有指定,那么将会使用默认值。
可以利用 RDD的成员变量 partitions所返回的partition数组的大小来查询一个RDD 被划分的分区数。程序2-2(Spark shell可以通过./bin/spark-shell命令来启动)将scala 中的1~100的数组转换为RDD,第二个参数就可以指定分区数。

2、RDD优先位置(preferredLocations)
RDD优先位置属性与Spark 中的调度相关,返回的是此RDD的每个 partition所存储的位置,按照“移动数据不如移动计算”的理念,在Spark进行任务调度的时候,尽可能地将任务分配到数据块所存储的位置。
以从 Hadoop中读取数据生成RDD为例,preferredLocations返回每一个数据块所在的机器名或者P地址,如果每一块数据是多份存储的,那么就会返回多个机器地址。
在程序2-4中首先通过SparkContext的 TextFile函数读取一个17G的文件bigfile,生成了一个类型为 MappedRDD的rdd,然后通过rdd 的依赖关系找到原始的hadoopRDD, hadoopRDD 的 partition 的个数是254个,对于第一个partition ( index为0)而言,其preferredLocations返回了三个机器地址,以便后续调度的程序根据这个地址更加有效地分配任务。
3、RDD依赖关系(dependencies)
dependencies顾名思义就是依赖的意思,由于 RDD是粗粒度的操作数据集,每一个转换操作都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系,在Spark中存在两种类型的依赖,即窄依赖(Narrow Dependencies )和宽依赖(Wide Dependencies)。
- 窄依赖:每一个父RDD的分区最多只被子RDD的一个分区所使用
- 宽依赖:多个子RDD的分区会依赖于同一个父RDD的分区
要明确地区分这两种依赖关系有两个方面的原因:
- 第一,窄依赖可以在集群的一个节点上如流水线一般地执行,可以计算所有父RDD 的分区,相反的,宽依赖需要取得父RDD的所有分区上的数据进行计算,将会执行类似于MapReduce一样的Shuffle 操作。
- 第二,对于窄依赖来说,节点计算失败后的恢复会更加有效,只需要重新计算对应的父RDD的分区,而且可以在其他的节点上并行地计算,相反的,在有宽依赖的继承关系中,一个节点的失败将会导致其父RDD的多个分区重新计算,这个代价是非常高的。
4、RDD分区计算(compute)
对于 Spark中每个RDD的计算都是以partition(分区)为单位的,而且RDD中的compute函数都是在对迭代器进行复合,不需要保存每次计算的结果。
在程序2-7中,对于rdd变量而言,是一个被分成两个分区的1~10集合,在rdd上连续进行转换操作map和 filter,由于compute函数只返回相应分区数据的迭代器,所以只有最终实例化时才能显示出两个分区的最终计算结果。
5、RDD分区函数(partitoner)
partitioner就是RDD分区函数,目前在Spark中实现了两种类型的分区函数,即**HashPatitioner**(哈希分区)和**RangePatitioner **(区域分区),且partitioner这个属性只存在于(K,V)类型的RDD中,对于非(K,V)类型的partitioner 的值就是None,partitioner函数既决定了RDD本身的分区数量,也可作为其父RDD Shuffle输出(MapOutput)中每个分区进行数据切割的依据。

若有收获,就点个赞吧
0 人点赞
