def glom():RDD[Array[T]]
glom算子效果和flatMap(func)效果是相反的.
作用: 将RDD中每一个分区的元素合并成一个数组,形成新的 RDD 类型是RDD[Array[T]]
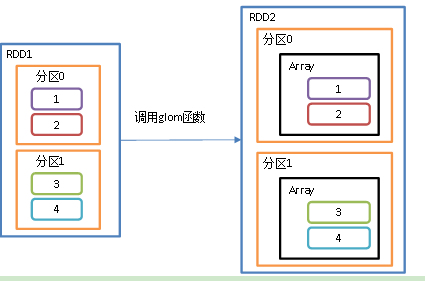
假如说我有个RDD1,RDD1里面有两个分区,两个分区分别放1 2 和 3 4. 经过glom算子之后就得到一个新的RDD2, RDD2还是两个分区,分区号没变,还是原来的分区号,此时每个分区的数据都合并成一个数组了, 数组里面是原来分区的值,.
比如说之前分区0里面的数据是 1 2 , 调用glom算子之后,分区0里面的数据是 array(1,2)了.
案例
/*** -将RDD一个分区中的元素,组合成一个新的数组*/object Spark04_Transformation_glom222 {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//2个分区val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)//给每个分区的元素的值变成数组var rddglom = rdd.glom()//var mappartitionsRDD = rddglom.mapPartitionsWithIndex {(index, datas) => {datas}}var array: Array[Array[Int]] = mappartitionsRDD.collect()// 获取第一个分区的元素,是个数组,按逗号变成字符串println(array(0).mkString(",")) //输出: 1,2,3//获取第二个分区的元素,是个数组,按逗号变成字符串println(array(1).mkString(",")) //输出: 4,5,6// 关闭连接sc.stop()}}
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** -将RDD一个分区中的元素,组合成一个新的数组*/object Spark04_Transformation_glom {def main(args: Array[String]): Unit = {//创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)// 以分区为单位输出每个分区的元素.println("------------没有glom之前------------")rdd.mapPartitionsWithIndex {(index, datas) => {println(index + "--->" + datas.mkString(","))//给数组展示出来.datas}}.collect()/*0--->1,2,31--->4,5,6*/println("------------调用glom之后------------")val newRDD: RDD[Array[Int]] = rdd.glom()newRDD.mapPartitionsWithIndex {(index, datas) => {println(index + "--->" + datas.next().mkString(","))datas}}.collect()/*0--->1,2,31--->4,5,6*/// 关闭连接sc.stop()}}
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Spark04_Transformation_glom222 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("Glom").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)val list1 = List(30, 50, 70, 60, 10, 20)val rdd1: RDD[Int] = sc.parallelize(list1, 2)// val rdd2 = rdd1.glom().map(x => x.toList)val rdd2 = rdd1.glom().map(_.toList)// 一个分区组成一个数组rdd2.collect.foreach(println)//输出: List(30, 50, 70)//List(60, 10, 20)sc.stop()}}

若有收获,就点个赞吧
0 人点赞
