概念
作用
按照key进行分组,返回的新的RDD, key是就是key, value是key里面的内容
分组的时候也可以指定分区器或者分区个数(默认使用的是HashPartitioner)
在groupByKey算子执行的时候,可能会shuffle操作.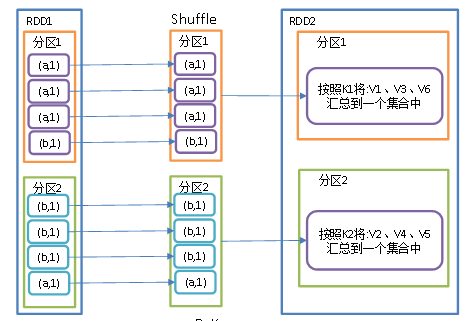
1. 基于当前的实现, groupByKey必须在内存中持有所有的键值对. 如果一个key有太多的value, 则会导致内存溢出(OutOfMemoryError)
2. 所以这操作非常耗资源, 如果分组的目的是为了在每个key上执行聚合操作(比如: sum 和 average), 则应该使用PairRDDFunctions.aggregateByKey 或者PairRDDFunctions.reduceByKey, 因为他们有更好的性能(会先在分区进行预聚合)
wordCount案例
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}/*** Desc: 转换算子-groupByKey* -根据key对RDD中的元素进行分组*/object Transformation_groupByKey {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")val sc: SparkContext = new SparkContext(conf)//创建RDDval rdd = sc.makeRDD(List(("a", 1), ("b", 5), ("a", 5), ("b", 2)))val groupRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()groupRDD.collect().foreach(println)/*输出:(a,CompactBuffer(1, 5))(b,CompactBuffer(5, 2))*/val resRDD: RDD[(String, Int)] = groupRDD.map {case (key, datas) => { //模式匹配.对元祖的value进行求和就可以了.(key, datas.sum)}}resRDD.collect().foreach(println)/*输出:(a,6)(b,7)*/sc.stop()}}
wordCount案例第二种写法
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}object Transformation_groupByKey {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("GroupByKey").setMaster("local[2]")val sc: SparkContext = new SparkContext(conf)val rdd1 = sc.parallelize(Array("hello", "hello", "world", "hello", "hello"))val wordOne = rdd1.map((_, 1))val wordOneGrouped = wordOne.groupByKey().mapValues(_.sum)wordOneGrouped.collect.foreach(println)/*输出(hello,4)(world,1)*/sc.stop()}}

若有收获,就点个赞吧
0 人点赞
