RDD编程模型
MapReduce编程模型

DAG编程模型

RDD是什么
Resilient Distributed Datasets 弹性分布式数据集
- Resilient: 弹性的、可容错的,一种容错的内存计算数据抽象
- Distributed:通过多个分区将数据分散在不同节点
- Datasets:数据集:一种数据抽象集合
物理上:
- RDD是一组记录的集合。
- 一个RDD可以分成多个分区, 每个分区是不可变的,分散在 集群的各个地方
逻辑上:
- RDD是一个编程的数据抽象, 可以对它进行各自操作。
- RDD操作都是高阶函数,这些 操作内部都是并发执行
-
RDD操作
RDD依赖
窄依赖:父RDD和子RDDpartition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的,不会有shuffle产生。父RDD的一个分区去到了子RDD的一个分区
- 宽依赖:父RDD与子RDD partition之间的关系是一对多,会有shuffle的产生。父RDD的一个分区的数据去到了子RDD的不同分区里面。
- 宽依赖会将pipeline划分为不同步stage,放在不同的task上去执行


RDD容错
当pipeline中其中的task出现故障挂机的时候,RDD可以自动恢复的能力。依赖的是RDD中的依赖(血缘)关系。
如RDD2中的Partition3发生故障后,可以基于依赖关系,由RDD的Partiton3重新计算。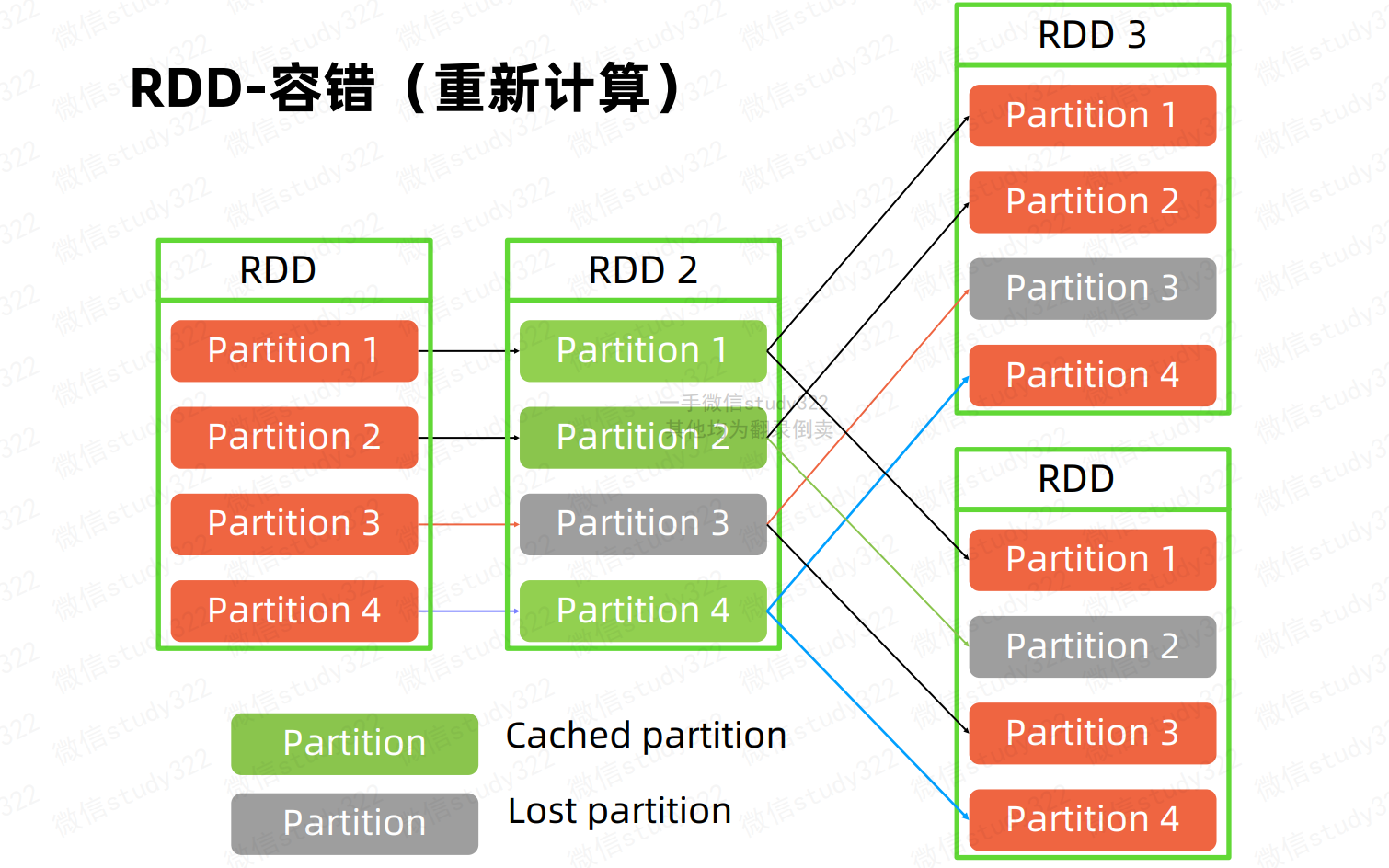
Spark Core架构和原理
Spark运行架构
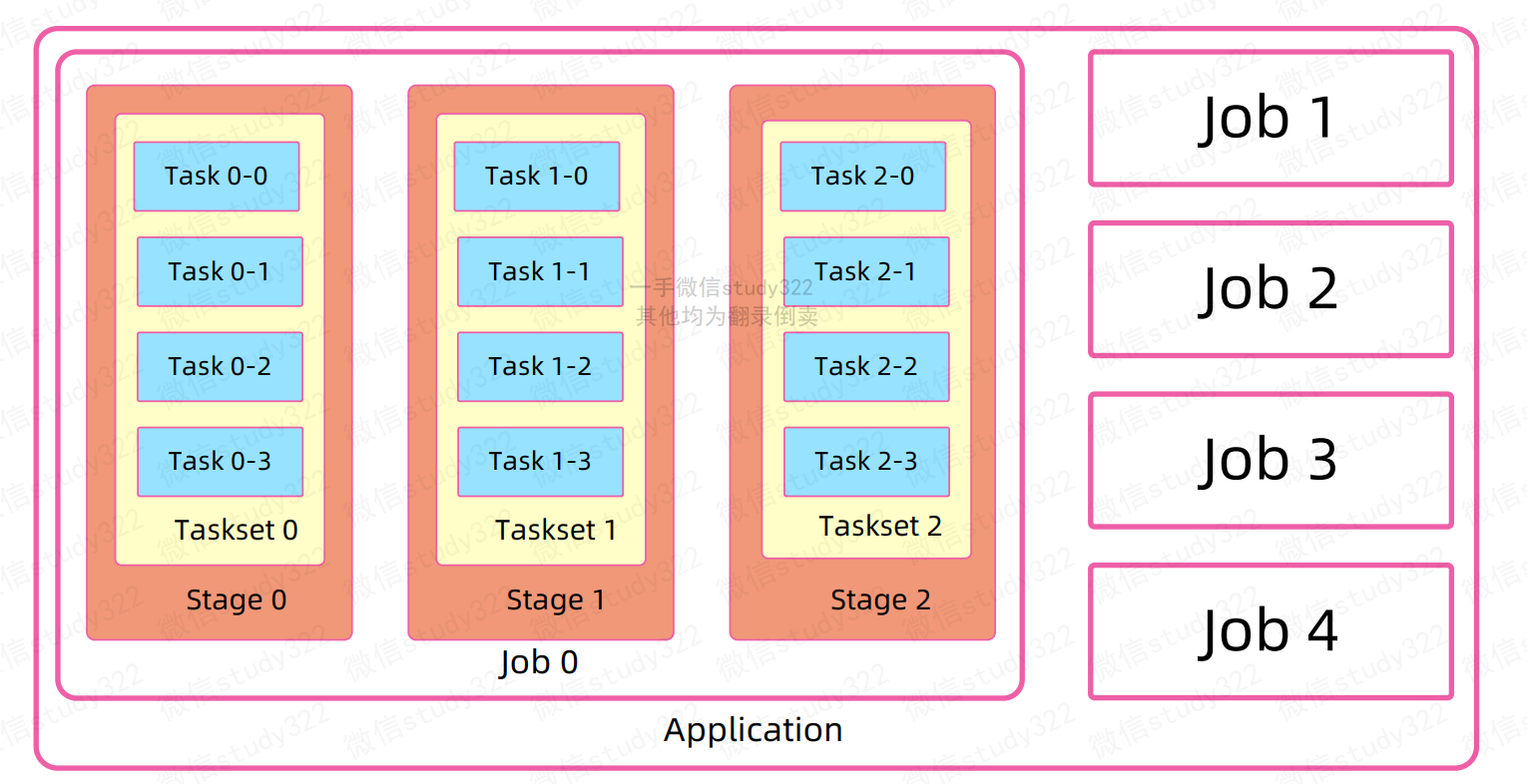
Job/Stage/Task
任务提交流程
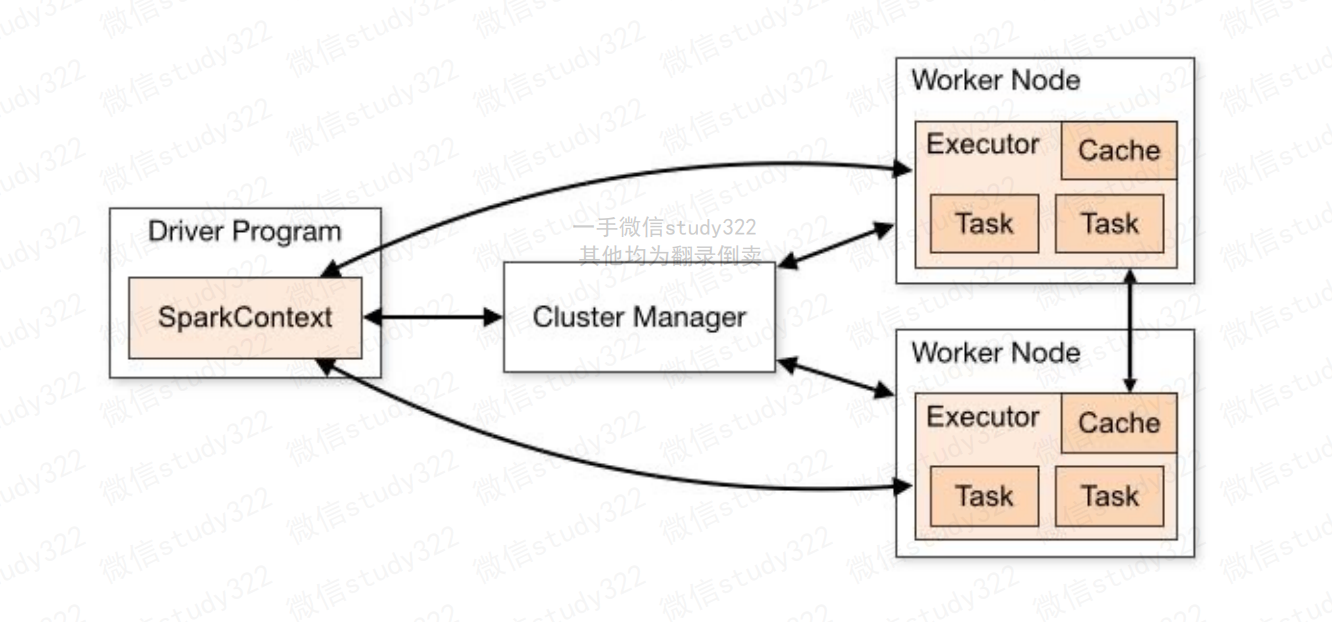
- Application:表示你的应用程序
- Driver:表示main()函数,创建SparkContext。由SparkContext负责与ClusterManager通信,进行资源的申请,任务的分配和监控等。程序执行完毕后关闭SparkContext
- Executor:某个Application运行在Worker节点上的一个进程,该进程负责运行某些task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,这样,每个CoarseGrainedExecutorBackend能并行运行Task的数据就取决于分配给它的CPU的个数。
- Worker:集群中可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的worker节点,在Spark on Yarn模式中指的就是NodeManager节点。
- Task:在Executor进程中执行任务的工作单元,多个Task组成一个Stage
- Job:包含多个Task组成的并行计算,是由Action行为触发的
- Stage:每个Job会被拆分很多组Task,作为一个TaskSet,其名称为Stage
- DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系
- TaskScheduler:将TaskSet提交给Worker(集群)运行,每个Executor运行什么Task就是在此处分配的。
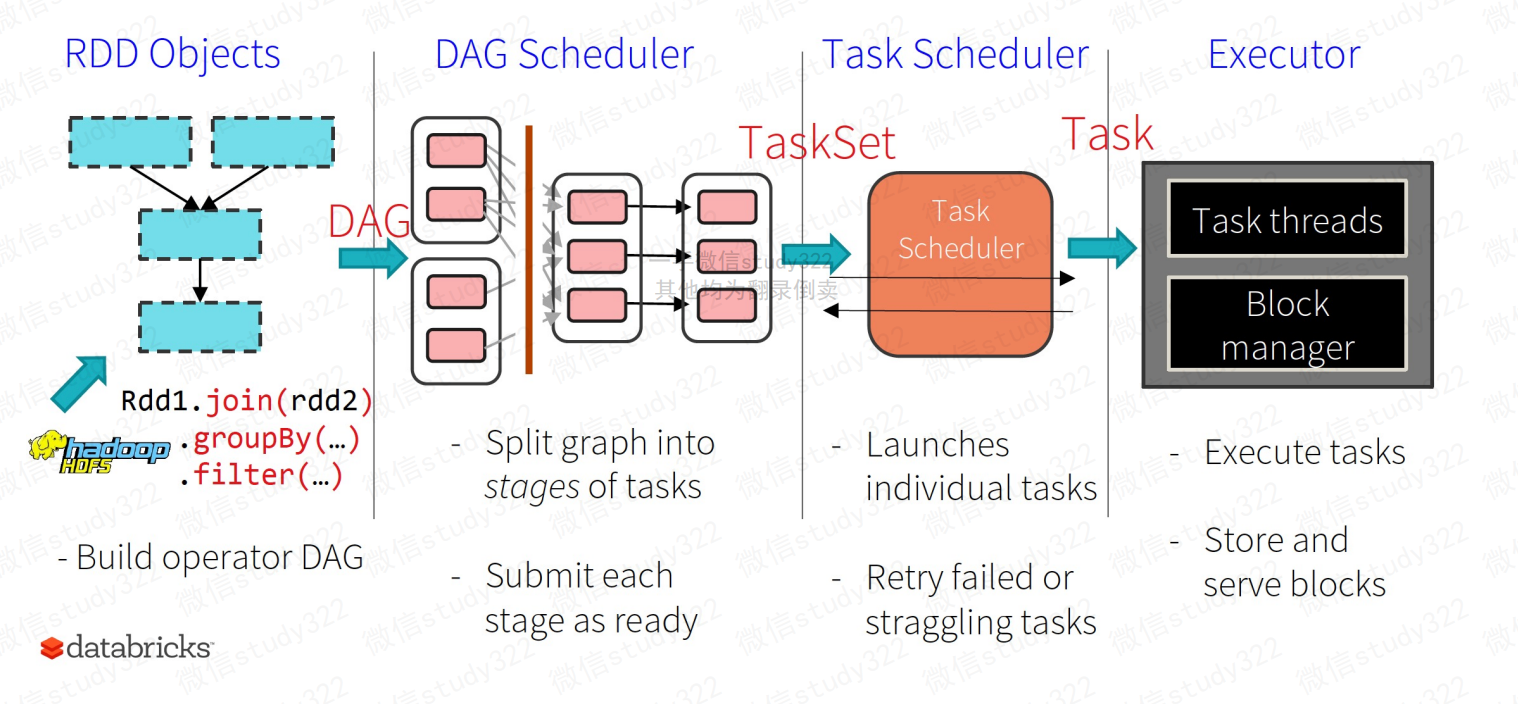

流程
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task
- Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
-
总结

Spark Shuffle
shuffle只发生在两个stage之间
-
shuffle读写
Shuffle分为shuffle write阶段(map side)和shuffle read阶段(reduce side)。
- Write阶段(map side) 的任务个数是根据RDD的分区数决定的。 假设从HDFS中读取数据,那么RDD分区个数由该数据集的block数决定,也就是一个 split对应生成RDD的一个partition。
- Read阶段(reduce side)的任务个数是通过配置spark.sql.shuffle.partitions决定的。
- Shuffle中间的数据交互
- Write阶段(map side) 会将状态以及Shuffle文件的位置等信息封装到MapStatue对象 中,然后发送给Driver。
- Read阶段(reduce side)会从Driver拉取MapStatue,解析后开始执行reduce操作。
Spark1.2前使用HashShuffle算法,1.2之后主要使用SortShuffle。
HashShuffle
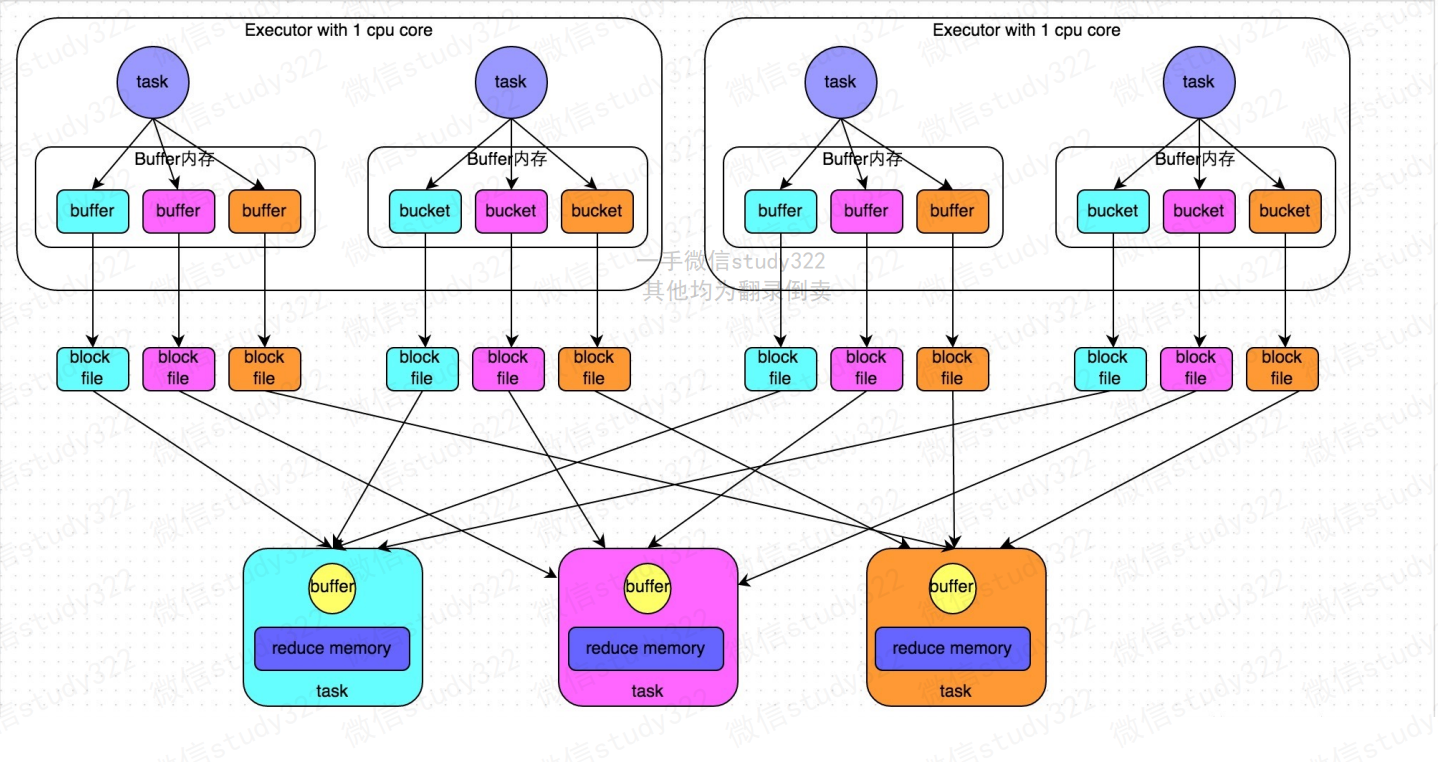
Shuffle read阶段,从各个节点上通过网络拉取到reduce任务所在的节点,然后进行key的 聚合或连接等操作。 一般来说,拉取Shuffle中间结果的过程是一边拉取一边聚合的。每个 shuffle read task都会有一个自己的buffer缓冲区,每次只能拉取与buffer缓冲区相同大 小的数据,然后在内存中进行聚合。聚合完一批数据后,再拉取下一批数据,直到最后将 所有数据到拉取完,得到最终的结果
Shuffle write阶段,每个task根据记录的Key进行哈希取模操作(hash(key) % reduceNum),相同结果的记录会写到同一个磁盘文件中。会先将数据写入内存缓冲区, 当内存缓冲填满之后,才会溢写(spill)到磁盘文件中
优化后的HashShuffle

将spark.shuffle.consolidateFiles设为true,shuffle write阶段并不会为每个task创建 reduceNum个文件,而是一个cpu core具有一个逻辑上shuffleFileGroup,每个Group 会生成reduceNum个文件,这样大量减少了shuffle中间文件个数
SortShuffle
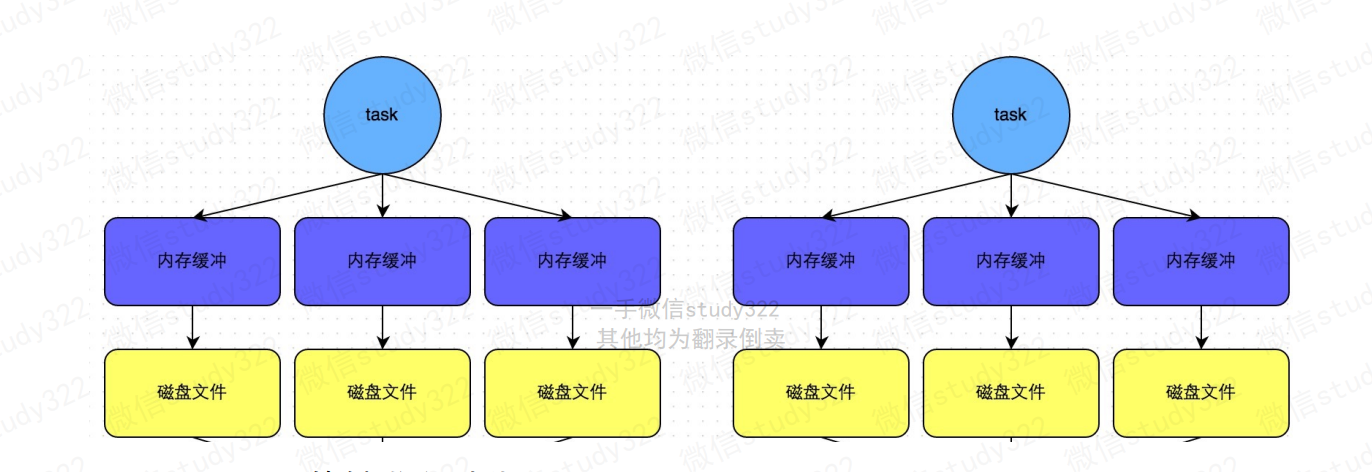
普通机制
Task的数据会先写入一个内存数据结构中,当内存满了之后,会根据 Key进行排序,然后分批溢写到本地磁盘(示例图演示为3批次)。 溢写过程只会产生2个磁盘文件,一个是数据文件,一个是索引文件 (其中标识了各个task的数据在文件中的start offset与end offset)
bypass
BypassSortShuffle的触发条件为:shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold(默认200)
不是聚合类的shuffle算子(比如reduceByKey)
网络IO:shuffle将数据从内存中移出
- 数据通过网络传输必须序列化及反序列化
- CPU:为了减少数据的网络传输而进行压缩
-
Shuffle优化原则
减少shuffle的数据量
- 部分预聚合函数
- 避免shuffle
- 数据预分布:比如Local Join
- Map Join(广播join)
shuffle参数优化
shuffle参数官网)数据倾斜及其优化


若有收获,就点个赞吧
0 人点赞
