Spark SQL中的树
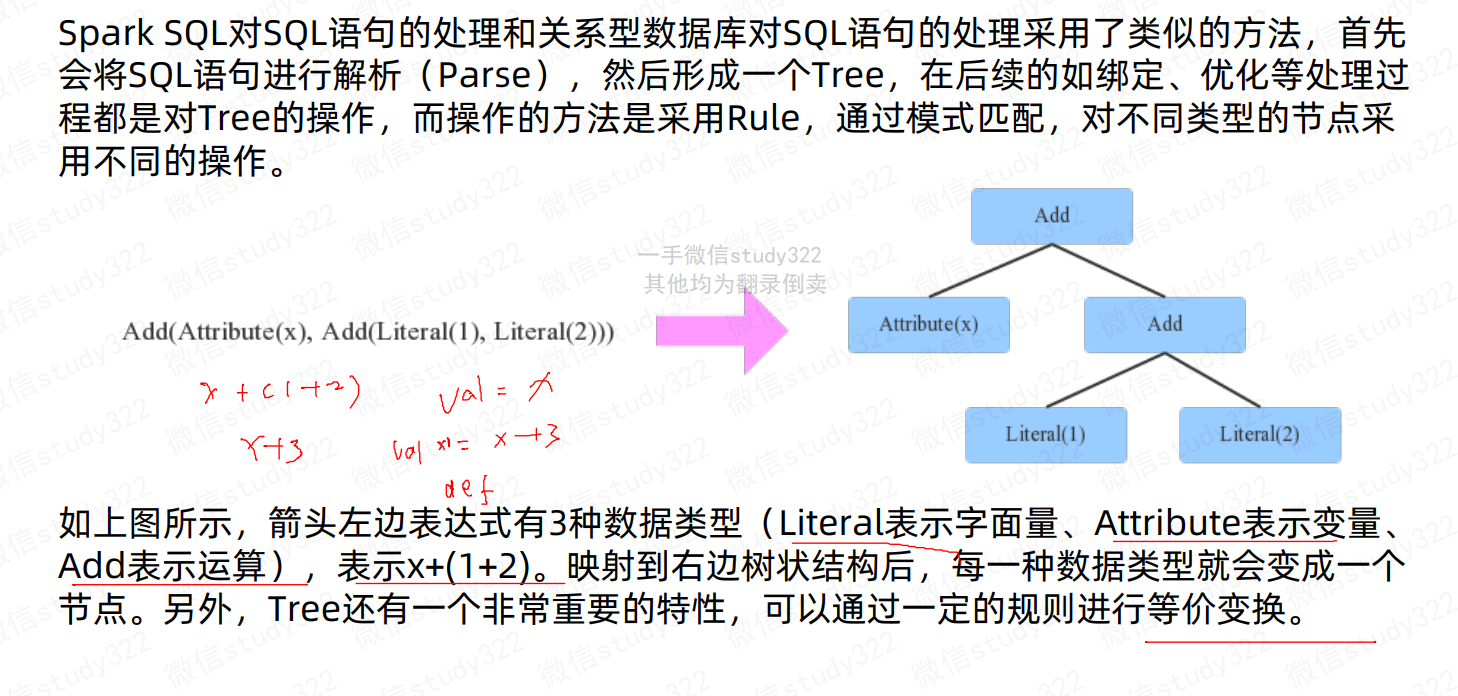
在数据库解析(Parse)SQL语句的时候,会将SQL语句转换成一个树型结构(抽象语法树)来进行处理,如下面一个查询,会形成一个含有多个节点(TreeNode )的Tree,然后在后续的处理过程中对该Tree进行一系列的操作。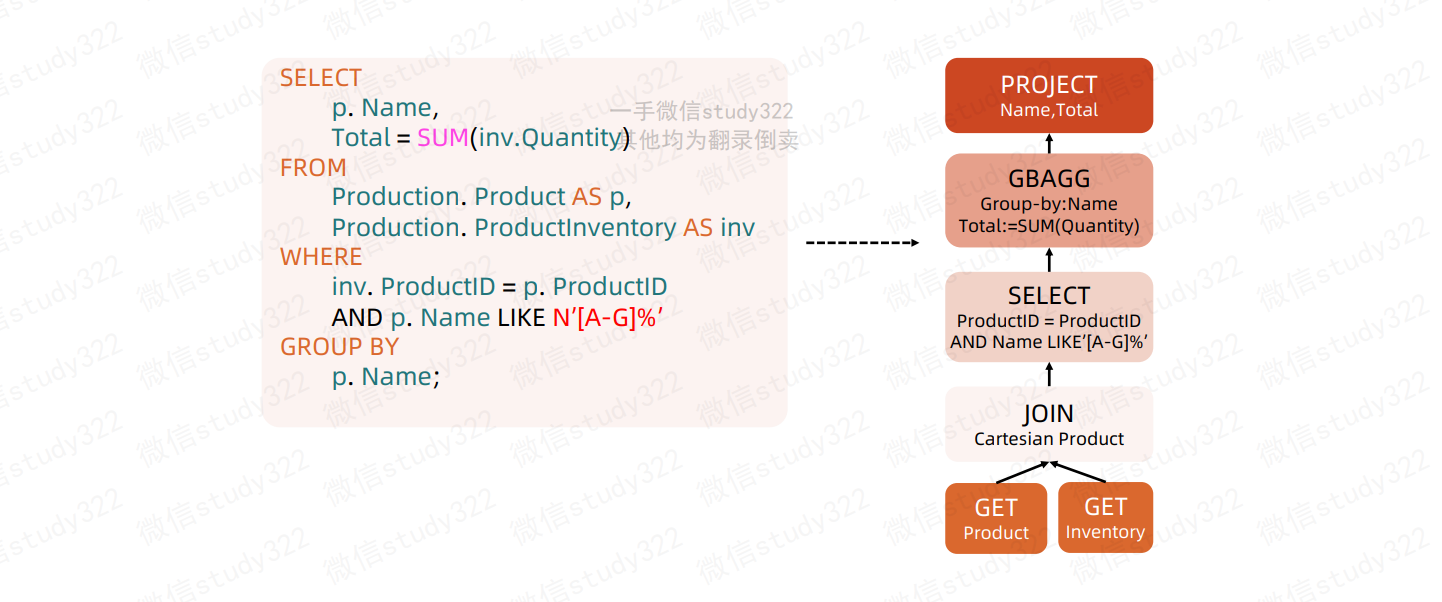
Spark SQL Tree
 s
s
TreeNode
TreeNode是Spark SQL中所有树节点的基类,定义了通用集合操作和树遍历接口。
表达式(expression)
表达式(expression):由变量(attribute)、字面量(literal)、运算符(operator) 组成的一个式子, 通常要有一个结果。
int b = 10; // b为变量,10为字面量,=为赋值运算符
在Expression类中,主要定义了5个方面的操作,包括基本属性、核心操作、输入输出、 字符串表达式和等价性判断。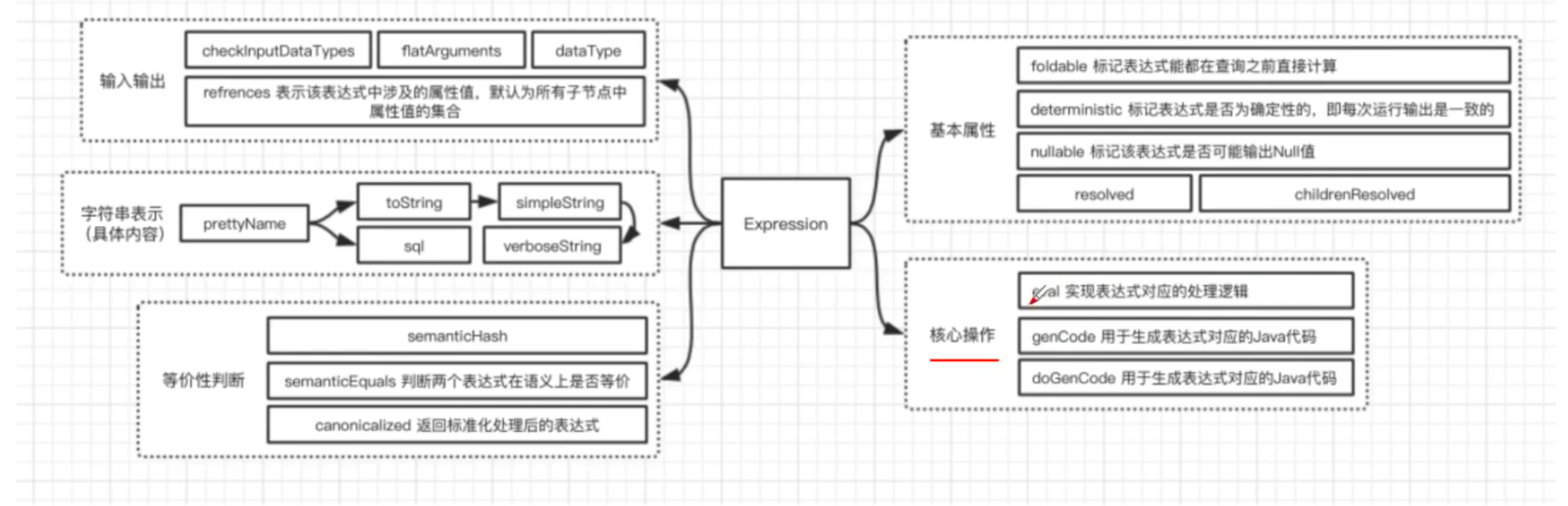
Spark Parser
ANTLR
- 词法分析器又称Scanner、Lexer或Tokenizer。词法分析器的工作是分析量化那些本来 毫无意义的字符流,将他们翻译成离散的字符组(也就是一个一个的Token),包括关 键字、标识符、符号(symbols)和操作符供语法分析器使用。
- 语法分析器又称编译器。在分析字符流的时候,Lexer不关心所生成的单个Token的语法 意义及其与上下文之间的关系。语法分析器则将收到的Token组织起来,并转换成为目 标语言语法定义所允许的序列。
树分析器可以用于对语法分析生成的抽象语法树进行遍历,并能执行一些相关的操作
抽象语法树
词法分析生成Token流
- 语法分析生成语法树
下图是一个示例性的SQL语句(有两张表,其中people表主要存储用户基本信息, score表存储用户的各种成绩),通过Parser解析后的AST语法树。
逻辑计划树
生成语法树之后,使用AstBuilder将语法树转换成LogicalPlan,这个LogicalPlan也被 称为Unresolved LogicalPlan。解析后的逻辑计划如下: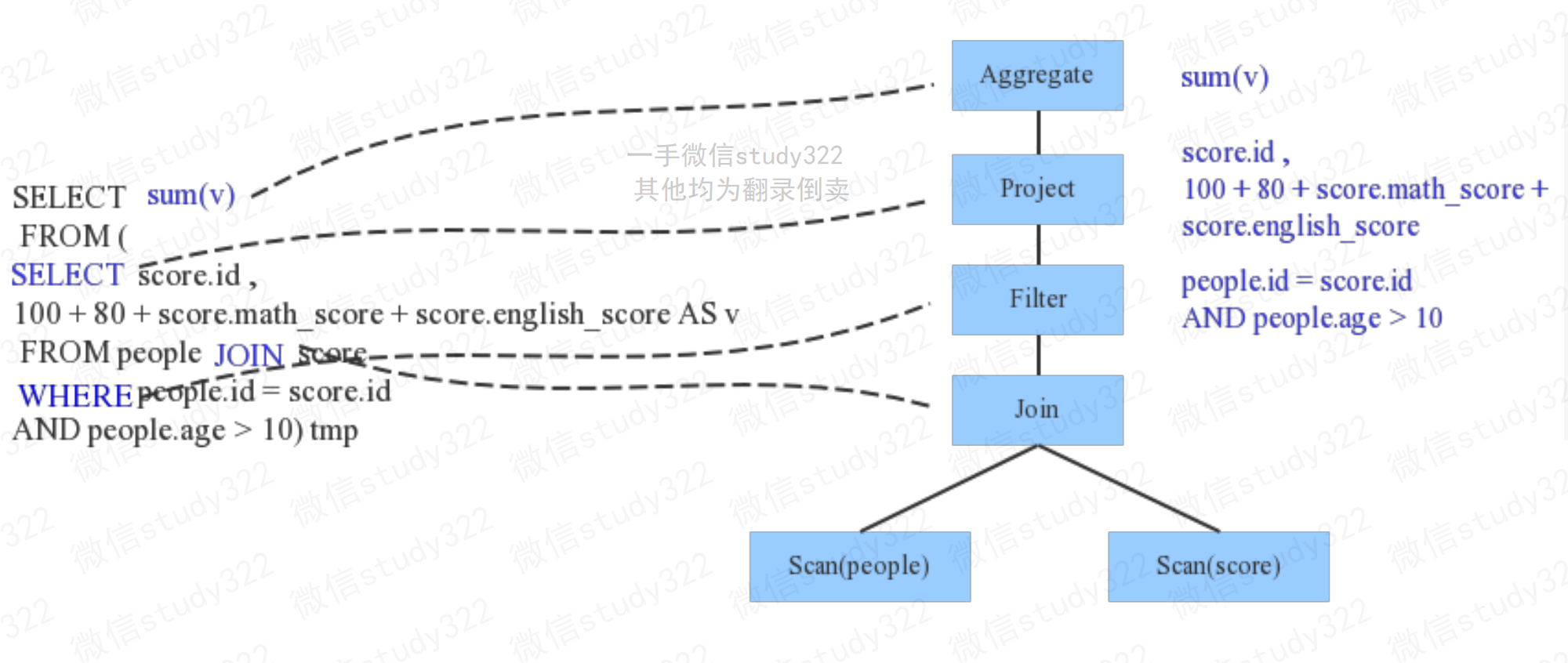
逻辑计划优化
- 优化器是整个Catalyst的核心,优化器分为基于规则优化和基于代价优化两种。
- 基于规则的优化策略实际上就是对语法树进行一次遍历,对模式匹配能够满足特定规 则的节点进行相应的等价转换。因此,基于规则优化说到底就是一棵树等价地转换为 另一棵树。
SQL中经典的优化规则有很多,下文结合示例介绍三种比较常见的规则:谓词下推 (将过滤尽可能地下沉到数据源端)、常量累加(比如1 + 2事先计算好)和列剪枝 (减少读取不必要的列)
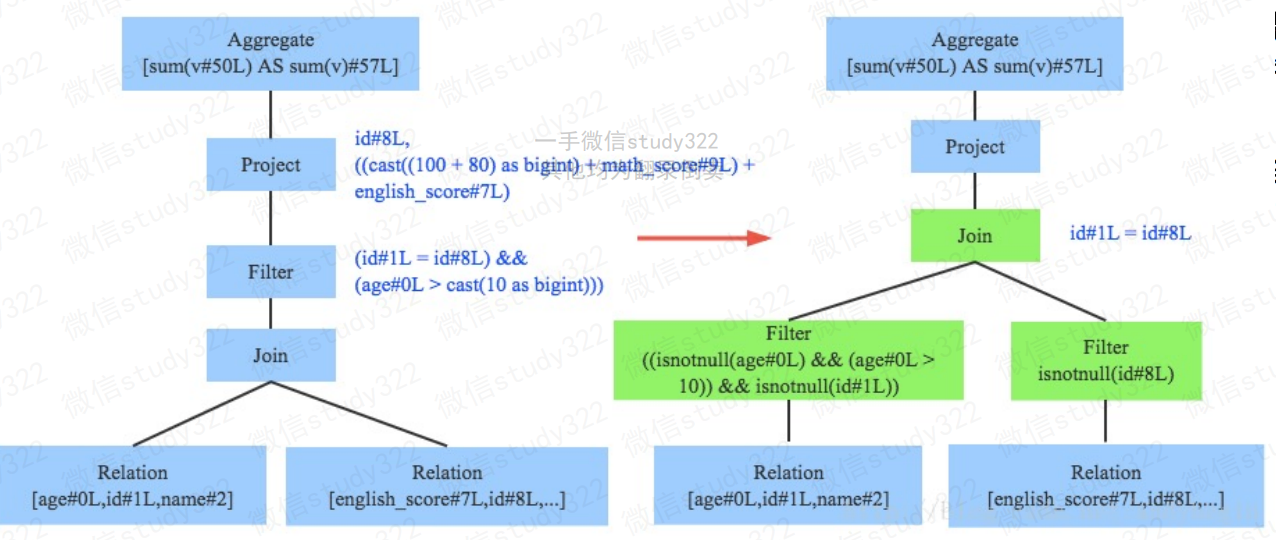
谓词下推(Predicate Pushdown)
过滤条件尽可能地下推到底层,最好是数据源(也就是将where后的条件尽量下推到底层)
- 例如,语法树中两个表先做join,之后再使用age>10对结果进行过滤。join算子通常是 一个非常耗时的算子,耗时多少一般取决于参与join的两个表的大小,如果能够减少参 与join两表的大小,就可以大大降低join算子所需时间。
- 谓词下推能将过滤条件下推到join之前进行,如图中过滤条件age>0以及id!=null两个条 件就分别下推到了join之前。这样,系统在扫描数据的时候就对数据进行了过滤,参与 join的数据量将会得到显著的减少,join耗时必然也会降低
常量累加(Constant Folding)
-
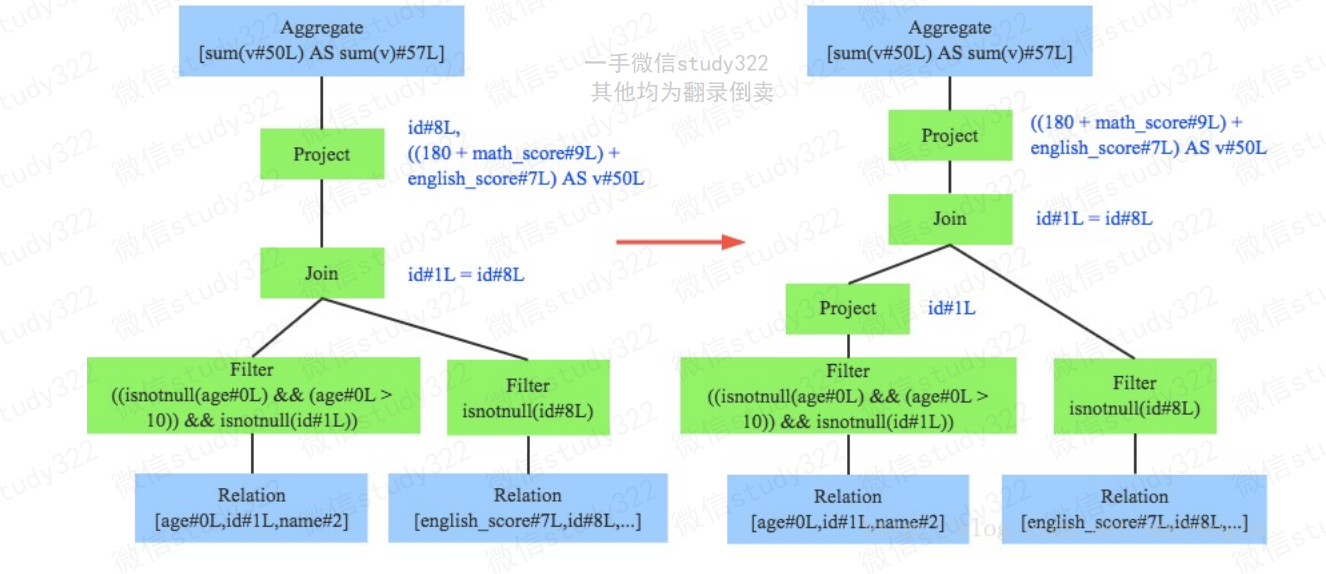
列剪枝(Column Pruning)
列值裁剪是另一个经典的规则,示例中对于people表来说,并不需要扫描它的所有列值, 而只需要id列,所以在扫描people之后需要将其他列进行裁剪,只留下列id。这个优化 一方面大幅度减少了网络、内存数据量消耗,另一方面对于列存格式(Parquet)来说 大大提高了扫描效率。
HiveCatalog
- Unresolved LogicalPlan仅仅是一种数据结构,不包含任何数据信息,比如不知道数据源、数据类型、不同的列来自于哪张表等。接下来我们需要对其进行“数据绑定”。数据绑定需要用到Catalog。
Catalog主要用于各种函数资源信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。
物理计划
Analyzer模块结合Catalog进行绑定,生成Resolved LogicalPlan
- 优化后的逻辑计划并不知道如何执行,例如算子节点Relation(实际上是LogicalRelation)虽然代表本次查询会从一张确定的表中获取数据,如 marketing.buyers,但是这张表是什么类型的表(Hive还是HBase),如何获取 (JDBC还是读HDFS文件),数据分布是什么样的(Bucketed还是HashDistributed) 此时并不清楚。
- 需要将逻辑计划树转换成物理计划树,以获取真实的物理属性。例如,Relation算子 变为FileSourceScanExec,Join算子变为SortMergeJoinExec。

join策略的选择
策略的选择会按照效率从高到低的优先级来排:
- broadcast hash join a. 先根据broadcast hint来判断 b. 其次是广播阈值
- hash join a. spark.sql.join.preferSortMergeJoin配置项为false b. 右表能够作为build table,构建本地HashMap(先右后左) c. 右表的数据量比左表小很多(3倍)
sort merge join a. 如果上面两种策略都不符合,并且参与join的key是可以排序的
SparkThriftServer
Spark ThriftServer是一个JDBC接口,用户可以通过JDBC连接ThriftServer来访问Spark SQL的数据。连接后可以直接通过编写SQL语句访问Spark SQL的数据。
社区开源项目 incubator-kyuubi)
AQE和DPP加速
Adaptive Query Execution
早期Spark:先构建“执行计划”再“执行”,即便使用CBO技术,因为UDF、压缩率等因素 的存在,Spark无法找出最佳的执行计划。
-
缺少AQE时
设置Shuffle分区数(reducer个数),spark.sql.shuffle.partition(默认200).如果Partition数设置的太小:造成并发度低,任务跑的慢,OOM ; 如果Partition数设置的太大:造成调度压力大,大量小文件,随机IO
- 选择Join算子类型:默认的Broadcast阈值是10MB。对于复杂的查询,join会使用中间结果作为输入,此时Spark SQL无法获得,准确的数据量,从而进行错误的估算。能进行BCJ的也被错误的执行成SMJ。
-
开启AQE
AQE自动设置Reducer数
- 数据倾斜
- 自动调整Join策略
Dynamic Partition Pruning
DPP)

若有收获,就点个赞吧
0 人点赞
