HashMap 简介
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。
JDK1.8 之后 HashMap 的组成多了红黑树,在满足下面两个条件之后,会执行链表转红黑树操作,以此来加快搜索速度。
- 链表长度大于阈值(默认为 8)
- HashMap 数组长度超过 64
性能
性能是映射表中的一个重要问题,当在get()中使用线性搜索时,执行速度会相当的慢,而这正是HashMap提高速度的地方。HashMap使用特殊的值,称作散列码,来取代对键的缓慢搜索。散列码是“相对唯一”的、用以代表对象的int值,它是通过将该对象的某些信息进行转换而生成的。hashcode()是根类Object中的方法,因此所有java对象都能产生散列码。HashMap就是使用对象的hashCode()进行快速查询的,此方法能够显著提高性能。
下面是基本的Map实现。如果没有其他的限制,HashMap就应该成为你的默认选择,因为它对速度进行了优化。其他实现强调了其他的特性,因此都不如HashMap快。
HashMap Map基于散列表的实现(它取代了Hashtable)。插入和查询“键值对”的开销是固 定的。可以通过构造器设置容量和负载因子,以调整容器的性能。
LinkedHashMap 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,或者是 最近最少使用(LRU)的次序。只比HashMap慢一点;而在迭代访问时反而更快,因为 它使用链表维护内部次序。
TreeMap 基于红黑树的实现。查看“键”或“键值对”时,它们会被排序(次序由 Comparable或Comparator决定)。TreeMap的特点在于,所得到的结果是经过排序 的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
WeakHashMap 弱键(weak key)映射,允许释放映射所指向的对象;这是为解决某类特殊问题而 设计的,如果映射之外没有引用指向某个“键”,则此“键”可以被垃圾收集器回收。
ConcurrentHashMap 一种线程安全的Map,它不涉及同步加锁。
IdentityHashMap 使用==代替equals()对“键”进行比较的散列映射。专为解决特殊问题而设计的
任何键都必须具有一个equals()方法;如果键被用于散列Map,那么它必须还具有恰当的hashCode()方法;如果键被用于TreeMap,那么它必须实现Comparable。
为速度而散列(HashMap原理)
散列的价值在于速度:散列使得查询得以快速进行。
存储一组元素最快的数据结构是数组,所以使用它来表示键的信息。数组并不保存键本身。而是通过键对象生成一个数字,将其作为数组的下标。这个数字就是散列码,由定义在Object中的、且可能由你的类覆盖的hashCode()方法(在计算机科学的术语中称为散列函数 )生成。
为解决数组容量被固定的问题,不同的键可以产生相同的下标。也就是说,可能会有冲突 。因此,数组多大就不重要了,任何键总能在数组中找到它的位置。
于是查询一个值的过程首先就是计算散列码,然后使用散列码查询数组。如果能够保证没有冲突(如果值的数量是固定的,那么就有可能),那可就有了一个完美的散列函数 ,但是这种情况只是特例。通常,冲突由外部链接处理:数组并不直接保存值,而是保存值得list。然后对list中的值使用equals()方法进行线性的查询。这部分的查询自然会比较慢,但是,如果散列函数好的话,数组的每个位置就只有较少的值。因此,不是查询整个list,而是快速地跳到数组的某个位置,只对很少的元素进行比较。这便是HashMap会如此快的原因。
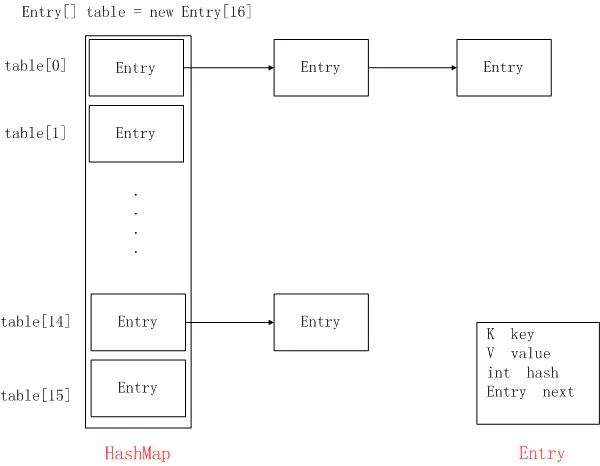
HashMap结构图

若有收获,就点个赞吧
0 人点赞
