- TPS吞吐量Throughput:系统在单位时间内处理请求的数据
- QPS每秒查询率Query Per Second:对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
- 并发用户数:系统可以同时承载的正常使用系统功能的用户的数量。
- RT响应时间:系统对请求作出响应的时间
单机MySql—>集群MySql 的演进
- A.主从复制:用多机集群解决读写压力,主库写bin-log,然后从库对主库做一个订阅,bin-log里有数据变更记录时,通过IO传输到从库的relay-log,再根据relay-log更新从库的数据。
- B.主从切换:高可用性,主机宕机时从机可以顶上,解决故障转移问题
- C.分库分表:解决容量问题。
垂直拆分:从业务上把原先一个大的数据库拆分成多个小的数据库
水平拆分:数据取模拆分,比如100W拆成5份,每份20W。
- D.分布式事务:解决集群上的一致性问题。
强一致性XA:数据库本身支持XA协议,封装使用。
弱一致性/柔性事务:在业务代码里引用三方库或者实现分布式一致性的设计,比如TCC,Saga。
A.主从复制
1.bin-log:
格式
- ROW行模式
- Statement:sql文
- Mixed:结合上面两种
查看命令
确定数据文件夹:show variables like ‘%datadir%’;
进入文件夹[/usr/local/var/mysql],mysql-bin开头的文件都是bin-log文件
查看bin-log命令:mysqlbinlog -vv mysql-bin.000002
内容格式
1.像个BASE64二进制的数据。
2.具体的SQL:insert/update/delete
2.主从复制方式
异步复制
传统主从复制—2000年,MySQL 3.23.15版本引入了 Replication。
主库完全不能感知从库的执行状态,如果网络或机器故障,会造成数据不一致。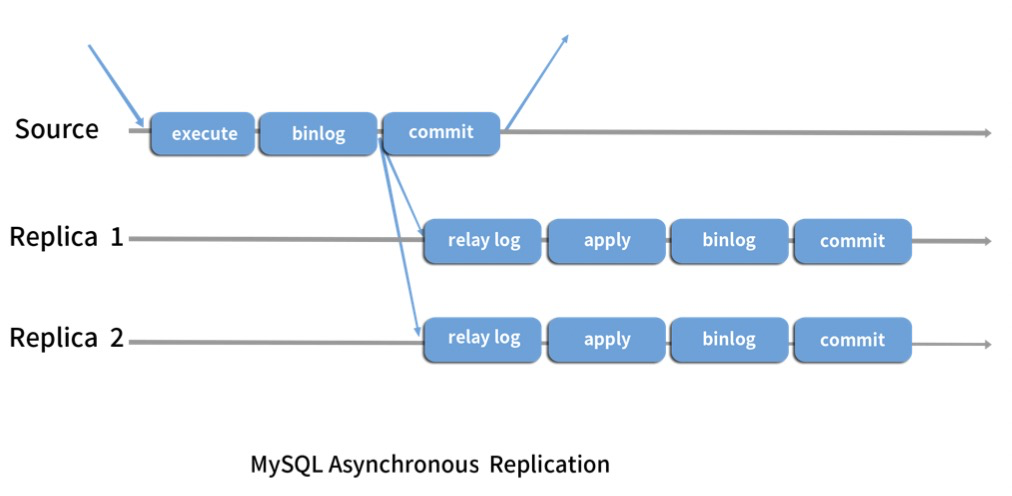
半同步复制:
需要启用插件,主库在超时范围内感知到至少一个从库返回的relay-log接收完成的状态。保证Source和Replica最终一致性。
如果超时未接收到任何从库的完整状态,则恢复到异步复制模式,不再等待从库的返回状态。避免主库的处理速度被从库所拖累。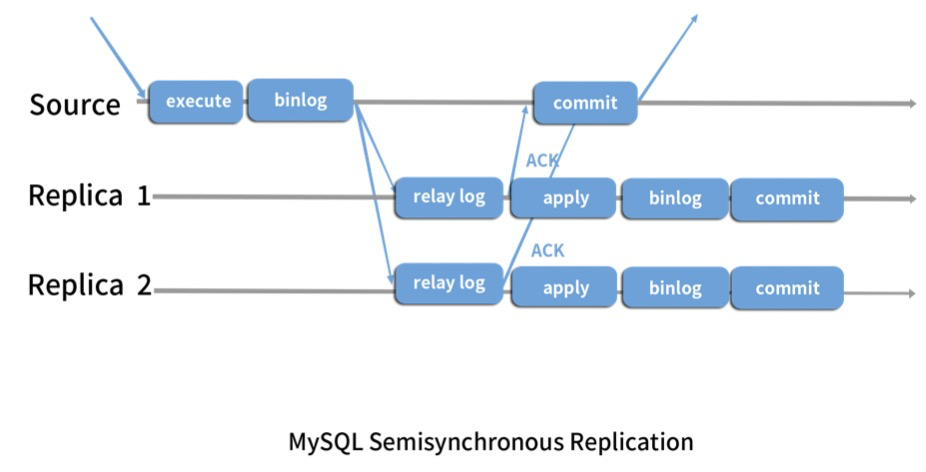
组复制MGR:
MySql Group Replication,基于分布式Paxos协议实现组复制,保证数据一致性。可以自行设置一个主库或者多个主库。靠certiry验证步骤避免冲突。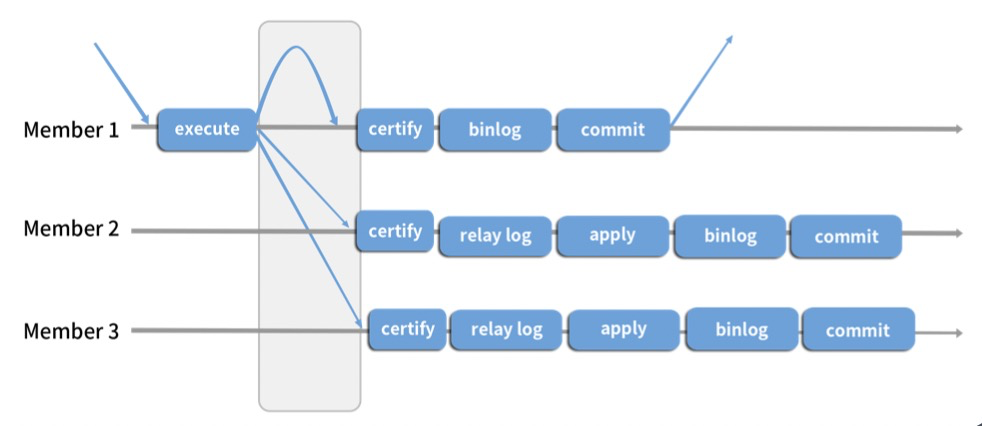
3.主从库设置举例(一主一从)
可以从预习资料的md文件中获取。
遇到问题可以show warning排查。
创建两个数据库:
- 在datadir指定的data/mysql文件夹下建立两个子文件夹[mysql1,mysql2]
- 在子文件夹下建立my.cnf/my.ini文件
- my.cnf/my.ini文件的关键设置点:
```
[mysqld]
Only allow connections from localhost ========= mysql1 =========
bind-address = 127.0.0.1 port = 3316 server-id = 1 datadir = /当前子文件夹mysql1路径/data socket = /随意指定路径/随意指定文件名mysql3316.sock
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES log_bin=mysql-bin binlog-format=Row
```[mysqld]# Only allow connections from localhost ========= mysql2 =========bind-address = 127.0.0.1port = 3326server-id = 2datadir = /当前子文件夹mysql2路径/datasocket = /随意指定路径/随意指定文件名mysql3326.socksql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLESlog_bin=mysql-binbinlog-format=Row
- 进入两个对应的子文件夹下,执行初始化命令(此初始化命令非安全地表示root账号密码可以为空)
mysqld -defaults -file=my.cnf —initialize-insecure
- 确认对应的data文件夹下生成了数据库配置文件
- 执行启动数据库命令:mysqld -defaults -file=my.cnf
- 确认对应的端口号3316/3326启动成功
- 连接数据库命令:mysql -h127.0.0.1 -P 3316 -uroot
- 确认连接成功:show variables like ‘%port%’;
配置主数据库(在主库上执行)
- 创建账号:CREATE USER ‘repl’@’%’ IDENTIFIED BY ‘123456’; # 密码是123456
- 给账号授权:GRANT REPLICATION SLAVE ON . TO ‘repl’@’%’;
- 刷新生效权限:flush privileges;
- 查看当前主库状态:show master status;
查询结果中,字段File为bin-log名,字段Position表示偏移量
- 创建自定义数据库:create schema db;
- 确定数据库创建成功:show schemas;
复制到从数据库(在从库上执行)
CHANGE MASTER TOMASTER_HOST='localhost',MASTER_PORT=3316,MASTER_USER='repl',MASTER_PASSWORD='123456',MASTER_LOG_FILE='mysql-bin.000002', # 最初查看的主库状态.FileMASTER_LOG_POS=855; # 最初查看的主库状态.Position偏移量
- 启动从库:start slave;
- 查看从库状态:show slave status\G
- Slave_IO_Running:Yes,Slave_SQL_Running:Yes
- 接下来可以在主库进行数据的增删改,同时发现从库会同步主库的操作结果。
主从关系建立后不想同步
- set SQL_LOG_BIN=0; # 暂时关闭bin-log
- 执行相关操作
- set SQL_LOG_BIN=1; # 恢复开启bin-log
课程视频翻车warning的解决方式
翻车原因:版本8里使用了密码验证
- 确认mysql配置文件中默认加密方式:default_authentication_plugin=mysql_native_password
- 密码加密方式查询:select host,user,plugin from mysql.user;
- 查询结果:caching_sha2_password
- 修改密码加密方式:ALTER USER ‘repl’@’%’ IDENTIFIED WITH mysql_native_password BY ‘123456’;
- 刷新生效权限:flush privileges;
4.主从数据的局限性
- 主从延迟问题:如果主从连接延迟较高,会导致从库里的数据更新不及时,取出为脏数据。
- 应用侧需要配合读写分离框架:
- 不解决高可用问题:主从复制模式,如果主库宕机,从库不能自动升级为主库。必须使用一定的工具来实现。
B.读写分离
1.中间件
ShardingSphere-jdbc 5.0.0-alpha
ShardingSphere-proxy 5.0.0-alpha
C.MySql高可用性
1.高可用定义:
高可用意味着,更少的不可服务时间。一般用服务水平协议SLA/SLO 衡量。
(SLA=系统全年可用时间比率)
1年 = 365天 = 8760小时
- 99 = 8760 1% = 8760 0.01 = 87.6小时(不可用时间)
- 99.9 = 8760 0.1% = 8760 0.001 = 8.76小时
- 99.99 = 8760 0.0001 = 0.876小时 = 0.876 60 = 52.6分钟 (很难达到)
- 99.999 = 8760 0.00001 = 0.0876小时 = 0.0876 60 = 5.26分钟
后面的分布式课程讲稳定性,注意关系和区别。
2.高可用方案
手动切换主从库:主库挂掉,需要人工干预改参数把从库改成主库,导致数据可能不一致。且代码和配置有侵入性。
- 解决方案1:中间层[LVS代理+Keepalived工具]实现多个节点的探活+请求路由。配置数据库的VIP/DNS来实现不需要改变数据库配置。问题点:人工干预手工调整VIP/DNS,需要大量脚本配置定义。
- 解决方案2:MHV(Master High Availability)软件。基于Perl语言开发,一般能在30s内实现主从切换,直接通过SSH复制主节点的日志。如果主库服务器还能访问,则比较主库日志和从库reply日志的一致性,自动补齐从库缺失的差异数据,再提升从库为主库。问题点:不只配置mysql账号信息,还需要配置LINUX机器的SSH信息,至少3台机器来保证高效可用性。
- 解决方案3:MGR(MySql Group Replication)MySQL内部实现组复制。不需要外部做任何操作和配置。问题点:主从切换状态存在DB中,需要读取DB来获取主从切换信息。还是需要中间层,配置LVS/VIP/DNS(可以用MySql的内部工具:MySQL InnoDB Cluster)。
3.MGR特点:
- 高一致性:基于分布式 Paxos 协议实现组复制,保证数据一致性;
- 高容错性:自动检测机制,只要不是大多数节点都宕机就可以继续工作,小于半数容易出现脑裂,内置防脑裂保护机制;
- 高扩展性:节点的增加与移除会自动更新组成员信息,新节点加入后,自动从其他时间节点同步增量数据,直到与其他数据一致;
- 高灵活性:提供单主模式和多主模式,单主模式在主库宕机后能够自动选主,所有写入都在主节点进行,多主模式支持多节点写入。
- 可用场景:弹性复制,数据高可用分片
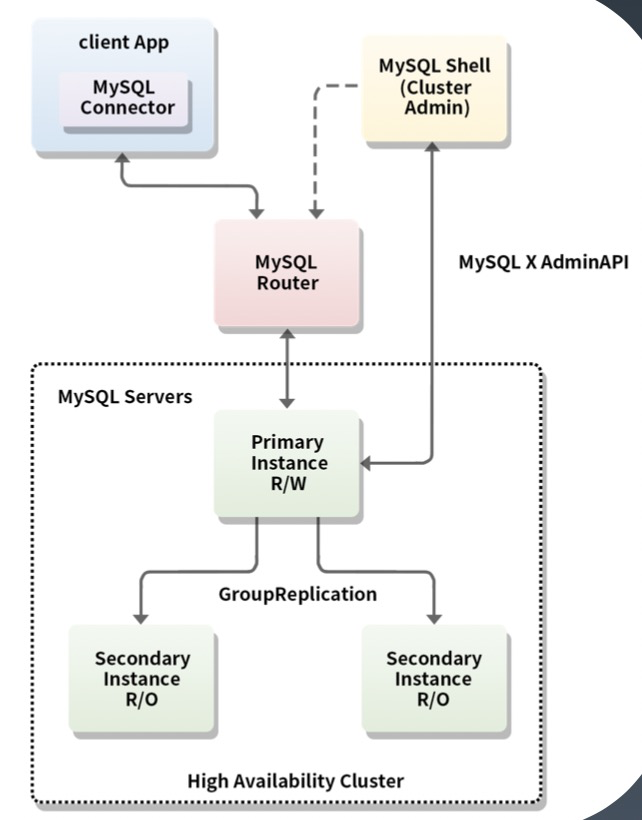
4.官方解决方案MySql InnoDB Cluster
MySql官方自带的高可用框架,完整的数据库层,高可用解决方案。
组件:
- MGR:提供DB的扩展,自动故障转移。
- MySQL Router:轻量级中间件,提供应用程序连接目标的故障转移,负载均衡。
- MySQL Shell:新的MySQL客户端,多种接口模式。可以设置群组复制级Router。
5.三方解决方案Orchestrator编排器
一款高可用和复制拓扑管理工具。支持复制拓扑结构的调整,自动故障转移和手动主从切换等。 后段数据库 MySQL 或 SQLite 存储元数据,并提供 Web 界面展示 MySQL 复制的拓扑关系及状态, 通过 Web 可更改 MySQL 实例的复制关系和部分配置信息,同时也提供命令行和 API 接口,方便运维 管理。基于Go语言开发,实现了中间件本身的高可用。
特点:
- 自动发现 MySQL 的复制拓扑,并且在 Web 上展示;
- 重构复制关系,可以在 Web 进行拖图来进行复制关系变更;
- 检测主异常,并可以自动或手动恢复,通过 Hooks 进行自定义脚本;
- 支持命令行和 Web 界面管理复制
优势:能直接在UI界面拖拽改变主从关系

若有收获,就点个赞吧
0 人点赞
