文件读写
1. 读取文件
1.1 打开文件
读取文件时,首先要打开文件,获得文件句柄。
f = open('学生信息.txt', 'r')
使用open函数,可以打开一个文件,返回文件句柄,open函数的第一个参数是文件地址,第二个参数是打开模式,打开模式详细介绍如下
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写 |
这些文件打开模式,你不必死记硬背,最常用的有r, w, a+ ,记住这几个就可以了。
1.2 读取文件内容
1.2.1 readlines
readlines 以列表的形式返回文件里的所有数据,文件有多少行,列表里就有多少个字符串,没一行的换行符也会被读取
f = open('学生信息.txt', 'r')lines = f.readlines()print(lines)
1.2.2 readline
readline一次只读取一行,如果文件特别大,readlines会一次性把数据读取到内存中,这样会非常耗费内存,而readline就不存在这样的问题,但由于一次只读取一行,所以,想要读取全部数据需要使用while循环
f = open('学生信息.txt', 'r')line = f.readline()while line:print(line)line = f.readline()
1.2.3 使用迭代
open返回的文件句柄,是一个可迭代对象,因此,你可以像迭代列表一样去迭代一个文件
f = open('学生信息.txt', 'r')for line in f:print(line)
1.2.4 关闭文件
文件打开以后一定要关闭,否则就会出现内存泄漏,关闭文件使用close方法
f = open('学生信息.txt', 'r')for line in f:print(line)f.close()
为了避免忘记close文件,还可以使用with语法,该语法可以保证在with语句块退出时可以自动关闭文件
with open('学生信息.txt', 'r') as f:for line in f:print(line)
绝对路径与相对路径
操作文件时,就会遇到绝对路径与相对路径这个问题,很多初学者都在这里栽跟头,傻傻搞不清楚,阅读完本文,你再也不会糊涂
1. 绝对路径
这是一个比较好理解的概念,绝对路径,换一种说法就是全路径,在windows下就是从盘符开始的,比如
C:\windows\system32\cmd.exe
C盘再往前已经没有文件夹了,这个路径是从根上出发的,那它就是绝对路径
2. 相对路径
相对路径,就不需要从根目录出发了,而是相对于某个文件目录的路径,那么问题来了,相对路径到底相对于谁呢?
为了弄清楚这个问题,我建一个实验文件夹,目录结构如下
test_path├── __init__.py└── mypath├── __init__.py├── data└── test.py
一共有两层文件夹,test_path在外层,mypath是内层,data文件内容为
123python
test.py文件内容为
with open("./data") as f:print(f.read())
这里就用到了相对路径—-“./data” 这里的./ 就是当前目录,那么当前目录又是什么呢? 很多教程告诉你,当前目录就是test.py所在的目录,这个答案是错误的,当前目录是启程程序的命令执行时所在的目录。
现在,我进入到 mypath文件夹中,执行test.py脚本
你可以看到,程序可以正常执行,注意,执行脚本的命令发生在mypath目录中
现在,我进入到test_path 文件夹中执行test.py脚本
程序发生了错误,因为当前执行脚本的命令是在test_path中发生的,因此,所谓的当前目录就是test_path,”./data” 则是在test_path中寻找data文件,自然找不到。
继续验证,还是在test_path目录中执行程序,但是对程序代码稍作修改
with open("./mypath/data") as f:print(f.read())
再次执行脚本
一切正常
捋一捋思路,相对路径,是相对于程序执行命令所在的目录,./ 表示的不是脚本所在的目录,而是程序执行命令所在的目录,也就是所谓的当前目录。
3. 回退一级目录
现在,你已经知道了./ 表示哪个目录,此外,你还会遇到路径中包含 ../ 的情况,这种方式表示回退一级目录
还是以刚才的实验代码为例,将data文件剪切移动到test_path目录下,将test.py脚本修改
with open("../data") as f:print(f.read())
现在进入到mypath目录下执行脚本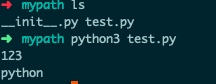
- 执行程序的命令发生在mypath目录中,mypath就是当前目录
- ../ 是回退一级目录,这样就来到了test_path目录中,而这里刚好有剪切移动过来的data文件
4. os.getcwd()
程序的工作目录,也就是前面所提到的执行程序的命令所发生的的目录,可以通过os.getcwd()方法获取到。
如果你的程序中自带了一些数据,需要在程序运行期间读取,那么千万不要用相对路径,因为你可能并不知道你的程序是在哪里被启动的,这就意味着你并不清楚程序的工作目录,这个时候,你要先获取脚本的绝对路径,然后根据脚本与数据时间的目录关系进行查找,还是以前面的实验项目为例
修改test.py脚本test_path├── __init__.py└── mypath├── __init__.py├── data└── test.py
程序通过os.path模块,获取到了data文件的绝对地址,这时候,不管在哪个目录下启动程序,程序都可以正常执行import osfile_path = os.path.abspath(__file__) # 先通过abspath方法获取当前脚本的绝对路径print(file_path)file_path = os.path.dirname(file_path) # 获取当前路径print(file_path)with open(os.path.join(file_path, 'data')) as f:print(f.read())

5种python常用读写文件方法精讲
python读写文件需要先使用open函数获得文件对象,open函数中有一个 mode参数,默认为’r’ ,在不同的应用场景下,要选择不同的模式,下表是mode参数的可选值列表
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写 |
模式虽然很多,但常用的只有前5种,学会这5种,其余的,也就融会贯通了。
1. w 和 wb模式
这两个模式都是写文件时用的模式,不同之处在于,w是以文本文件格式打开文件进行写, wb模式是以二进制格式打开文件进行写操作,那么他们之间的区别是什么呢,下面用一段代码来说明
text = '学习python'f = open('data', 'w')f.write(text)f.close()f = open('data_byte', 'wb')b_text = text.encode(encoding='utf-8')f.write(b_text)f.close()
区别只有一处,如果是以wb模式打开,使用write方法时,只能传入bytes类型的数据,因此需要使用encode方法先将str转成bytes类型数据。
打开写好的两个文件,其实,他们在内容上是没有区别的
既然他们没有区别,有何必弄出两个来呢? 原来有些数据,本身就是二进制的,而且不能也务必要转成字符串类型,那么这种数据写入文件就需要以wb的模式打开文件,下面就是一个具体的例子
import pickleclass Stu:def __init__(self, name, age):self.name = nameself.age = agestu = Stu('小明', 15)f = open('stu_obj', 'wb')pickle.dump(stu, f)f.close()
上面的代码里,将stu对象序列化到文件中,这种场景下,就需要以wb模式打开文件。
2. r 和 rb模式
r与w相对应,rb与wb模式相对应,想要将上面的例子中写入到文件中的stu对象读取出来,就需要使用下面的代码
f = open('stu_obj', 'rb')stu = pickle.load(f)f.close()print(stu)
如果你用r模式打开并读取数据,程序不会报错,但是你无法还原stu对象,如果感兴趣,你可以自己运行上面的代码,打开stu_obj文件,你看到的是下面的内容
我这里之所以用图片,是因为如果将这段文字复制到我的编辑器中,有一部分无法显示。
3. a 模式,追加模式
使用w模式时,如果文件已经存在,那么再次打开后,文件里原有的内容就会消失,因为打开后,文件指针指向了文件开始的地方,写数据就会从这里写。
如果你希望文件二次打开写入数据时,数据能从文件的末尾开始写,这样原有的内容可以保留下来,那么你需要用a的模式打开
sqlite数据库
sqlite是一款非常流行的轻型数据库,在手机端,许多app的数据就存储在sqlite中。相比于mysql,oracle, postgresql等数据库,我最喜欢它的地方在于,使用sqlite无需复杂的安装和配置,在python环境下,直接使用即可。
1、 python连接sqlite
只需两行代码,就可以连接到sqlite数据库
import sqlite3conn = sqlite3.connect('test.db')
如果test.db这个文件不存在,则上面的代码会创建它并连接,如果存在则直接连接。
除了创建文件外,还可以在内存中创建数据
import sqlite3conn = sqlite3.connect(":memory:")
2、创建表
下面的代码将创建一个张user表
import sqlite3conn = sqlite3.connect('test.db')cursor = conn.cursor()table_sql = """create table user(id INTEGER PRIMARY KEY autoincrement NOT NULL ,name text NOT NULL,age INTEGER NOT NULL)"""cursor.execute(table_sql)conn.commit() # 一定要提交,否则不会执行sqlconn.close()
sqlite一共有5中数据类型可以定义
| 类型 | 描述 |
|---|---|
| NULL | NULL 值 |
| INTEGER | 带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中 |
| REAL | 浮点值,存储为 8 字节的 IEEE 浮点数字。 |
| TEXT | 字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储 |
| BLOB | blob 数据,完全根据它的输入存储 |
3. insert数据
import sqlite3conn = sqlite3.connect('test.db')cursor = conn.cursor()sql_lst = ["insert into user(name, age)values('lili', 18)","insert into user(name, age)values('poly', 19)","insert into user(name, age)values('lilei', 30)"]for sql in sql_lst:cursor.execute(sql)conn.commit()conn.close()
4. 查询
先看一个简单的示例
import sqlite3conn = sqlite3.connect('test.db')conn.row_factory = sqlite3.Rowcursor = conn.cursor()sql = "select * from user"cursor.execute(sql)rows = cursor.fetchall() # 获取全部数据for row in rows:print(row.keys(), tuple(row))conn.close()
运行结果
['id', 'name', 'age'] (1, 'lili', 18)['id', 'name', 'age'] (2, 'poly', 19)['id', 'name', 'age'] (3, 'lilei', 30)
- row.keys() 返回列的名字
- tuple(row) 获取tuple形式的数据
如果想以字典形式获取数据,则需要指定工厂方法,也就是一个解析数据的函数,将元组类型数据转换为字典类型数据。
import sqlite3conn = sqlite3.connect('test.db')def dict_factory(cursor, row):d = {}for idx, col in enumerate(cursor.description):d[col[0]] = row[idx]return dconn.row_factory = dict_factorycursor = conn.cursor()sql = "select * from user"cursor.execute(sql)rows = cursor.fetchall() # 获取全部数据for row in rows:print(row)conn.close()
4. update数据
import sqlite3conn = sqlite3.connect('test.db')def dict_factory(cursor, row):d = {}for idx, col in enumerate(cursor.description):d[col[0]] = row[idx]return dconn.row_factory = dict_factorycursor = conn.cursor()# 修改数据update_sql = "update user set age = 22 where id = 1"cursor.execute(update_sql)conn.commit()sql = "select * from user"cursor.execute(sql)rows = cursor.fetchall() # 获取全部数据for row in rows:print(row)conn.close()
5. 删除
import sqlite3conn = sqlite3.connect('test.db')def dict_factory(cursor, row):d = {}for idx, col in enumerate(cursor.description):d[col[0]] = row[idx]return dconn.row_factory = dict_factorycursor = conn.cursor()# 删除数据delete_sql = "delete from user where id = 1"cursor.execute(delete_sql)conn.commit()sql = "select * from user"cursor.execute(sql)rows = cursor.fetchall() # 获取全部数据for row in rows:print(row)conn.close()
6. 批量插入, executemany
如果你有大量数据需要写入,那么不建议你使用execute,因为每一次执行execute,都要和数据库进行一次数据交互,而批量执行则可以免去这种频繁的数据交互。
import sqlite3conn = sqlite3.connect('test.db')def dict_factory(cursor, row):d = {}for idx, col in enumerate(cursor.description):d[col[0]] = row[idx]return dconn.row_factory = dict_factorycursor = conn.cursor()# 批量执行sql = "insert into user(name, age)values(?, ?)"user_lst = [('lili', 18), ('poly', 19), ('lilei', 30)]cursor.executemany(sql, user_lst)sql = "select * from user"cursor.execute(sql)rows = cursor.fetchall() # 获取全部数据for row in rows:print(row)conn.close()
序列化
1 什么是序列化
将数据转换为可以通过网络传输或者可以存储到本地磁盘的数据格式(xml,json或特定格式字符串)的过程称之为序列化,反之,称之为反序列化。
不同编程语言有各自的数据类型,同样是int类型,不同的编程语言里,其存储方式是不一样的。那么不同编程语言编写的系统如果想进行通信,就必须使用一种双方都认可的数据格式传输数据,当前,最为流行的就是json数据格式。
2 pickle
pickle是python的原生模块,它实现了对python对象的序列化和反序列化的二进制协议,由于采用的是二进制协议,因此,pickle序列化后的内容,是无法像json序列化后的内容一样正常查看的。
2.1 序列化示例
import pickledata = {'name': 'lilei','age': 18}# 序列化到文本中f = open('person', 'wb')pickle.dump(data, f)f.close()
虽然,pickle也提供了dumps方法,但返回的是byte类型数据,而不是字符串。经过实际测试,使用str函数将byte类型数据转成字符串的过程,可能会出错,这些byte数据不是从字符串转而来的,个别位置无法用utf-8进行编码,因此为了避免这类问题,不推荐你使用dumps方法。
import pickledata = {'name': 'lilei','age': 18}byte_str = pickle.dumps(data)print(byte_str)string = str(byte_str, encoding='utf8')
2.2 pickle反序列化
import picklef = open('person', 'rb')data = pickle.load(f)f.close()print(data)
程序运行结果
{'name': 'lilei', 'age': 18}
2.3 序列化对象
pickle不只能对标准数据类型进行序列化,就连用户自定义的对象也可以进行序列化
import pickleclass Person(object):def __init__(self):self.name = 'lilei'self.age = 18person = Person()# 序列化f = open('person', 'wb')pickle.dump(person, f)f.close()# 反序列化f = open('person', 'rb')data = pickle.load(f)f.close()print(type(data))print(data.name)print(data.age)
程序输出结果
<class '__main__.Person'>lilei18
这里有一个地方需要特别注意,使用pickle反序列化用户自定义对象时,必须保证可以访问到用户自定义的类,这样,pickle才能构造出这个类的对象。
3 json 模块
json是非常通用,非常流行的数据格式,几乎被所有语言所接纳。
下表,是python数据类型和json数据类型之间的映射关系
| python | json |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
3.1 json序列化示例
import jsondata = {'name': 'lilei','age': 18}f = open('person', 'w')json.dump(data, f)f.close()string = json.dumps(data)print(string)
不论是转成字符串,还是序列化存储到文件中,其内容都是可以看得懂的
{"name": "lilei", "age": 18}
3.2 json反序列化
import jsondata = '{"name": "lilei", "age": 18}'data = json.loads(data)print(data)with open('person', 'r') as f:data = json.load(f)print(data)
程序输出结果
{'name': 'lilei', 'age': 18}{'name': 'lilei', 'age': 18}
4 msgpack
msgpack 是一种和json很相似,但是速度更快,体积更小的二进制序列化数据格式,这是它的官方 https://msgpack.org/
想要使用这种数据格式进行序列化,需要安装msgpack-python模块
pip3 install msgpack-python
4.1 使用示例
'name': 'lili','age': 18,'score': 100}# 和json进行序列化数据大小对比msg_str = msgpack.packb(stu)print(msg_str)print(len(msg_str))json_str = json.dumps(stu)json_str = bytes(json_str, encoding = "utf8")print(json_str)print(len(json_str))# 反序列化data = msgpack.unpackb(msg_str)print(data)
程序输出结果
b'\x83\xa4name\xa4lili\xa3age\x12\xa5scored'23b'{"name": "lili", "age": 18, "score": 100}'41{b'name': b'lili', b'age': 18, b'score': 100}
可以看到,msgpack序列化后的数据,其体积比json序列化后的要小很多,这样,在网络传输上就会更快。
4.2 json与msgpack性能对比
4.2.1 体积对比
import msgpackimport jsondata = {'count': 100,'price': 29832.09,'desc': 'MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it’s faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves','desc_cn': "MessagePack 是一个高效的二进制序列化格式。它让你像JSON一样可以在各种语言之间交换数据。但是它比JSON更快、更小。小的整数会被编码成一个字节,短的字符串仅仅只需要比它的长度多一字节的大小",'bool': True}data = [data for i in range(10)]json_str = json.dumps(data)print(len(json_str))msg_str = msgpack.dumps(data)print(len(msg_str))
程序执行结果
87406001
4.2.2 序列化速度比较
import msgpackimport jsonimport timedata = {'count': 100,'price': 29832.09,'desc': 'MessagePack is an efficient binary serialization format. It lets you exchange data among multiple languages like JSON. But it’s faster and smaller. Small integers are encoded into a single byte, and typical short strings require only one extra byte in addition to the strings themselves','desc_cn': "MessagePack 是一个高效的二进制序列化格式。它让你像JSON一样可以在各种语言之间交换数据。但是它比JSON更快、更小。小的整数会被编码成一个字节,短的字符串仅仅只需要比它的长度多一字节的大小",'bool': True}data = [data for i in range(10)]t1 = time.time()for i in range(100000):json_str = json.dumps(data)t2 = time.time()for i in range(100000):msg_str = msgpack.dumps(data)t3 = time.time()print(t2-t1)print(t3-t2)
程序执行结果
6.3208360671997070.9859249591827393
速度上,msgpack快了6倍,更快的速度,更小的体积。

若有收获,就点个赞吧
0 人点赞
