错误和异常
1. 错误
你经常会遇见的错误是语法错误,初学者掌握知识不扎实,经常会写出一些语法错误而不自知,一旦报错,就慌的一笔,下面是一个常见的错误语法示例
a = “python”print(a)
如果你经常犯语法错误,那么要认真的复习一下基础语法了,语法并不是需要动脑子思考的知识,你只需记住它就好。
不要老是说理解就好了,编程需要的是准确无误,每一行代码都不能出错,需要你做到精确的理解和记忆,这是所有工科专业的特点,文科专业,你大概理解一些,然后考试的时候自由发挥,自圆其说就好,但工科专业要的是准确无误的答案,可供你自由发挥的地方并不多,即便是实际应用时,你所谓的灵活也必须建立在准确无误的基础语法之上。
语法错误,在程序解析阶段就会被发现。
2. 异常
你的程序没有语法错误,但在运行期间仍然报错了,这种在运行期间发生的错误就是异常。
下面是几个比较典型的异常
示例1,ZeroDivisionError
def test(a, b):print(a/b)if __name__ == '__main__':test(10, 5)test(10, 0)
示例2, UnboundLocalError
def test(a, b):if a > 5:c = 10print(b / c)if __name__ == '__main__':test(6, 3)test(3, 2)
示例3 ,TypeError
def test(a, b):print(a+b)if __name__ == '__main__':test(1, 3)test('1', 3)
2.1 异常在什么时候发生?
仔细观察上面的三个异常示例,你会发现一个有趣的现象,异常并不总是发生,每一个例子中,第一次调用函数的时候,函数是可以正确执行的,但是第二次调用时,由于各种各样的原因,都发生了错误。
和语法错误不同,在程序解析阶段,异常不会发生,因为此时,程序还没有正式运行,而在运行时,也不一定就会报错,只有遇到特定情况时才会发生错误,所以,才叫它异常,大部分情况下,程序都是可以正常执行的,偶尔,由于某个特殊原因导致程序发生了错误。
一个程序员,在写程序的时候,要考虑很多,基于过往的经验,他会刻意的处理一些边界情况或者特殊情况,以避免发生错误。
3. 异常类继承关系
对于错误和异常,不要过于担心,他们并不是无穷无尽的,python的异常类是有限的,发生错误时耐心分析,认真总结,错误就会越来越少
BaseException+-- SystemExit+-- KeyboardInterrupt+-- GeneratorExit+-- Exception+-- StopIteration+-- StopAsyncIteration+-- ArithmeticError| +-- FloatingPointError| +-- OverflowError| +-- ZeroDivisionError+-- AssertionError+-- AttributeError+-- BufferError+-- EOFError+-- ImportError+-- ModuleNotFoundError+-- LookupError| +-- IndexError| +-- KeyError+-- MemoryError+-- NameError| +-- UnboundLocalError+-- OSError| +-- BlockingIOError| +-- ChildProcessError| +-- ConnectionError| | +-- BrokenPipeError| | +-- ConnectionAbortedError| | +-- ConnectionRefusedError| | +-- ConnectionResetError| +-- FileExistsError| +-- FileNotFoundError| +-- InterruptedError| +-- IsADirectoryError| +-- NotADirectoryError| +-- PermissionError| +-- ProcessLookupError| +-- TimeoutError+-- ReferenceError+-- RuntimeError| +-- NotImplementedError| +-- RecursionError+-- SyntaxError| +-- IndentationError| +-- TabError+-- SystemError+-- TypeError+-- ValueError| +-- UnicodeError| +-- UnicodeDecodeError| +-- UnicodeEncodeError| +-- UnicodeTranslateError+-- Warning+-- DeprecationWarning+-- PendingDeprecationWarning+-- RuntimeWarning+-- SyntaxWarning+-- UserWarning+-- FutureWarning+-- ImportWarning+-- UnicodeWarning+-- BytesWarning+-- ResourceWarning
捕获异常
一旦发生异常,程序就会终止,这是非常糟糕的事情,这种糟糕体现在两方面
- 即便发生了异常,业务上可以忽略它,那么程序应当继续执行
- 程序终止,使得异常的信息没有被保留下来,不利于问题的分析和总结
为了提高程序的健壮性和解决问题,可以将异常捕获,根据业务要求来做对应的处理
1. try
python中,捕获异常使用try … except …这种语法来捕捉异常,下面是一个异常捕获的示例
def test(a, b):try:print(a/b)except ZeroDivisionError:print("0不能作分母")if __name__ == '__main__':test(10, 5)test(10, 0)
那些你担心不安全的代码,就可以放在try子句中,也就是try和except之间。
2. except
except 可以指定想要捕获的异常,比如上面的例子中,代码想捕获ZeroDivisionError 异常,如果try子句中发生了别的异常,这个except 就不会捕捉。
这样做,是希望能够针对不同的异常做不同的处理,你可以一次性指定想要捕获的所有异常,比如下面的代码
def test(a, b):try:print(a/b)except (ZeroDivisionError, ValueError):return Noneif __name__ == '__main__':test(10, 5)test(10, 0)
也可以逐个捕捉
def test(a, b):try:print(a/b)except ZeroDivisionError:print('0不能做分母')except ValueError:print("类型错误")else:print('什么异常都没发生')if __name__ == '__main__':test(10, 5)test(10, 0)
try … except … else这种语法,当没有异常发生时,就会执行else语句块里的代码。
如果你对于异常还不熟悉,不知道该捕获哪些异常,则可以用下面的写法
def test(a, b):try:print(a/b)except:print('发生异常')if __name__ == '__main__':test(10, 5)test(10, 0)
如果你什么异常都不指定,那么任何异常都会被捕捉,但这不是一个好的写法,因为这意味着,你根本不了解你的程序,因为不了解,你连可能发生的异常是什么都不清楚,这是很致命的,你不了解你自己写出来的程序,还怎么指望它能正常工作?
3. finally
你可以在finally语句块里做清理操作,因为不论try子句里是否发生异常,也不论你在except语句块里做了什么操作,总之,最终一定会执行finally语句块里的代码,这就保证了这里的代码最后一定会被执行,所以,清理收尾的工作一定会进行。
你可以在这里输出日志,你可以做任何你想做的事情。
def divide(x, y):try:result = x / yexcept ZeroDivisionError:print("division by zero!")else:print("result is", result)finally:print("executing finally clause")if __name__ == '__main__':divide(10, 5)divide(10, 0)
主动抛异常
1. 抛异常
有时,程序需要主动抛出异常,因为某些情况下,你需要反馈消息给更上层的调用者,告诉它有一些异常情况发生,而你抛出异常的地方,没有能力处理它,因此需要向上抛出异常。
这种情况为什么不让系统自己抛出异常呢?一个原因是上层的调用者本身就希望能够捕获有别于系统异常的自定义异常,二来,有些情况下,程序的逻辑是没有异常的,但是,从业务角度考虑,的确是一个不寻常的情况,因此需要我们主动抛出异常。
下面是抛出异常的一个例子
def divide(x, y):if y == 0:raise ZeroDivisionError("0不能做分母")return x/yif __name__ == '__main__':divide(10, 5)divide(10, 0)
抛出异常时,你可以指定抛出哪个异常,如果你不想指定,那么可以抛出异常Exception, 它是所有异常的父类
def divide(x, y):if y == 0:raise Exception("0不能做分母")return x/yif __name__ == '__main__':divide(10, 5)divide(10, 0)
2. 自定义异常类
在程序里引入自定义的异常类,可以让代码更具可读性,同时对异常的划分更加精细,那么在处理异常时也就更加具有针对性,自定义异常继承自Exception,或者那些类本身就继承自Exception
import requestsclass HttpCodeException(Exception):passdef get_html(url, headers):res = requests.get(url, headers=headers)print(res.status_code)if res.status_code != 200:raise HttpCodeExceptionreturn res.texttry:text = get_html("http://www.coolpython.net", {})print(text)except HttpCodeException:print("状态码不是200")
异常信息分析与收集
1. 异常信息分析
程序异常崩溃时会提供非常详细的错误信息,掌握正确的分析方法,就可以快速定位问题并解决问题,下面这段代码会引发异常导致程序终止
def func_tet():func_sum('4', 3)def func_sum(a, b):value = a + breturn valuefunc_tet()
运行这段程序,异常信息如下
我将异常信息分为两部分,分析时,先关注最后一行绿色框内的信息,这里的信息明确的指明了异常的类型和异常的解释信息,这是我们分析问题的第一步,随着经验的积累,你很容就能通过异常信息分析出为何会发生异常。
异常信息的第二部分,就是蓝色框内的内容,是调用堆栈信息,详细的记录了程序的执行路径,最后一行正是错误发生的位置。
现在,既有出错代码的位置,又有错误的类型与解释,如果还是不能找出问题,那么,可以百度了,百度时将最后一行绿色框里的内容作为搜索词进行搜索,可以找到大量文章。
2. 异常信息收集
traceback模块可以准确获得有关异常的信息,这在稍大点的项目里非常有用。
在大一点的项目里,需要记录程序运行的日志,那些异常日志非常非常重要,将有助于你发现系统的问题。
import tracebackdef divide(x, y):try:return x/yexcept:msg = traceback.format_exc()print(msg)if __name__ == '__main__':#print(divide(10, 5))print(divide(10, 0))
traceback.format_exc() 可以获取有关异常的详细信息,这些信息就是平时你的程序遇到bug时报出来的那些异常信息
Traceback (most recent call last):File "/Users/kwsy/PycharmProjects/pythonclass/mytest/test.py", line 4, in dividereturn x/yZeroDivisionError: division by zero
有了这些信息,你就清楚的知道错误发生在哪里,异常的类型是什么,你甚至可以在日志里将函数的入参写入到日志中,这样,更加有助于你解决问题。
19个常见的python错误和异常
错误总是不可避免,尤其是在初学阶段,本文收集整理了1个常见的python错误
1. 忘记添加:
在if, elif, else, for, while, class,或者使用def定义函数的名称后面忘记添加:,就会引发 SyntaxError
if 3 > 4print('ok')
这是一种非常明显的错误,大多数编辑器在你写代码的时候就会用红色的波浪线提示你
2. 误将 = 当做 ==
a = 4if a = 4:print('ok')
即便是多年编程经验的老手也会偶尔犯这种错误,写的太着急了,就少打了一个=,得到的自然也是SyntaxError
3. 错误的缩进空格数量
if 1==1:print('1')print('2')
这段代码将引发错误“IndentationError: unindent does not match any outer indentation level” ,一次缩进是4个空格,这一点务必要牢记
4. 错误使用range函数
lst = [1, 2, 3]for i in range(lst):print(lst[i])
这段代码的本意是通过索引来遍历列表,但错误的使用了range函数,引发了错误“TypeError: ‘list’ object cannot be interpreted as an integer”, 正确的做法如下
lst = [1, 2, 3]for i in range(len(lst)):print(lst[i])
5. 尝试修改字符串的内容
字符串是不可变对象,无法修改字符串里的内容,下面的代码将会引发错误“TypeError: ‘str’ object does not support item assignment”
s = "i like python"s[0] = 'I'print(s[0])
6. 尝试将非字符串数据与字符串连接
print('I have ' + 3 + " books")
上面的代码尝试将字符串与int类型数据连接在一起,由于他们类型不同,会导致错误“TypeError: must be str, not int”
7. 字符串缺少引号
print('hello world)
创建字符串可以是用一对单引号,或者一对双引号,或者一对”””, 上面的代码会引发错误“SyntaxError: EOL while scanning string literal”
8. 使用未定义的变量
sname = "lilei"print('my name is ' + name)
print语句中需要用到的变量name事先并没有被定义,就会引发错误“NameError: name ‘name’ is not defined”
9. 调用对象没有的方法
string = 'PYTHON'# 经过一些操作后,string变成了Nonestring = Noneprint(string.lower())
string原本是字符串,但进过一些操作后,变成了其他对象,可能是int,或者None,不论变成什么,总是它都不再是字符串,没有了lower方法,这时你再去调用lower方法就会报错“AttributeError: ‘NoneType’ object has no attribute ‘lower’”
10. 访问不存在的索引
lst = [1, 2, 3]print(lst[6])
列表最大的索引是2,代码里尝试访问索引6就会引发索引错误“IndexError: list index out of range”
11. 使用一个不存在的key
需要通过key来操作字典,如果key不存在,就会引发错误“KeyError”
dic = {'name': 'lili','age': 14}print(dic['sex'])
12. 使用保留字做变量
class = 'python'print(class)
python的保留字不能作为变量,上面的代码会引发错误“SyntaxError”
13. 使用不存在的内置函数
lst = [1, 2, 3]print(avg(lst))
14. 在函数内修改全局不可变对象
这是一个比较复杂的错误,先来看下面的代码
a = 10def func():print(a)func()
程序正常执行,可以输出10,对代码稍作修改
a = 10def func():print(a)a = 20func()
多了一行a = 20后,再次运行代码就会报错“UnboundLocalError: local variable ‘a’ referenced before assignment”,为什么会这样呢?a原本是一个全局变量,在第一段代码里可以正常访问,但是第二段代码里尝试对变量a进行修改,一旦有了修改这个动作,解释器就认为变量a是一个局部变量,而不在是全局变量。那么在a = 20这条语句之前尝试输出a的内容就会报错因为在执行print(a)时,局部变量a还不存在。
15. 修改range的返回值
lst = range(10)lst[0] = 20print(lst)
range函数创建一个整数序列,但这个序列并不是列表,而是一个迭代器,无法使用索引来进行任何操作,否则就会引发错误”TypeError: ‘range’ object does not support item assignment”
16. 使用 ++ 或 —操作
a = 0a++print(a)
很多语言都支持 ++ 操作,但很遗憾python并不支持,上面的代码会报错“SyntaxError: invalid syntax”,上面的代码可以修改成这样
a = 0a += 1print(a)
17. 函数调用时参数数量错误
错误1
def func(a, b):return a + bprint(func(4))
错误2
def func(a, b):return a + bprint(func(4, 4, 5))
函数需要两个参数,错误1里在调用函数时只提供了1个参数,错误2里提供了3个错误,都会引发TypeError,错误内容分别是“TypeError: func() missing 1 required positional argument: ‘b’” 和 “TypeError: func() takes 2 positional arguments but 3 were given”
18. 缺少安装包
import requests
如果你并没有安装requests库,程序在执行时就会报错“ImportError: No module named requests”,不要慌,使用pip安装就好了
19. 文件路径错误
f = open('a.txt')print(f.read())
如果根本不存在a.txt这个文件,那么就会报错“FileNotFoundError: [Errno 2] No such file or directory: ‘a.txt’”, 打开一个不存在的文件,就会引发FileNotFoundError。这个错误,对于初学者来说来烦恼了,尤其是windows用户,他们有时候会信誓旦旦的说,这个文件存在啊!
程序是不会骗人的,它说不存在,就一定是不存在,你的文件地址一定是错了,检查一下路径里究竟用的是/ 还是 \, 另外检查一下是不是隐藏了文件的后缀。
如何使用pycharm调试python程序
使用pycharm的调试功能,可以对程序进行调试,也就debug。 调试功能主要包括设置断点, 单步执行, 查看调用栈信息, 查看变量的值,调试功能让程序在某一行代码上暂停,通过对这一刻的上下文环境进行检查,可以定位程序出问题的原因。
调试程序是程序员的日常,再牛逼的人,也不可能一次性把程序写对,因此,写完一个函数或者一段代码后,你需要测试自己的代码,如果有问题,就必须进行调试,也就是debug。
对于初学者,debug更有意义,通过debug你可以了解程序的执行过程,如何进行循环,为何break,if条件判断是否成立,运行过程中的每一个变量值如何变化,可以非常确定的讲,如果你不会debug,那么,永远都做不好编程。
1. 断点
只有在debug状态下,断点才会起作用,所谓断点,就是一处你希望程序暂停的地方。我们希望程序不要那么快的执行完,设置一个断点,程序运行到这里,就会停下来,之后,你就可以单步调试,所谓单步调试,就是你让程序执行一行,它就执行一行。
断点的设置非常容易,以pycharm为例,只需要左键点击代码左侧标识代码行数的区域即可
左键点击红框内的区域,就会出现一个小红点,再次点击,小红点会消失,这就是一处断点
2. debug模式运行
想要单步调试程序,需要进入debug模式运行程序
第一种方法,通过Run 找出下拉菜单,然后点击debug
第二种方法,右键点击代码区域,点击debug
3. debug工具使用

上图就是进入到debug模式后的界面,有三个重要区域需要你关注
3.1 调试区域

常用的功能键有5个
第1个功能键是 step over,你点击一下,程序就会执行一行
第2个功能键是 step into,如果这一行有函数,点击它就会进入到函数中
第3个功能键是 step into my code,如果这一行有函数,既有第三方库的函数,也有自己编写的函数,那么会优先进入到自己的函数里
第4个功能键是step out,就是从函数里退出来
第5个功能键是run to cursor,就是直接运行到下一处断点
3.2 调用栈区域

先看左侧的两个红框内的按钮
绿色箭头的按钮是resume progrom,是恢复程序执行,如果后续代码没有断点了,程序就会正常执行直到结束。
红方块的按钮是 stop,停止程序。
调用栈区域展示的,是调用栈的信息,通过它就能知道从程序开始运行到当前代码,经过了哪些调用关系
3.3 变量查看区域

变量查看区域,可以查看当前程序里的每一个变量的值,非常的方便,不仅如此,还可以自己添加表达式,查看自己关注的值,比如绿色框内的1%2 就是我通过左侧红色框内的+按钮添加上去的,添加的时候,写完表达式后,要点击回车才能完成添加。
除了这里可以查看变量的值,在程序页面里,debug模式下,鼠标滑动到变量上,也可以查看变量的值
除了pycharm提供的调试工具,还可以使用python提供的pdb,不过是命令行的,不如图形界面友好,还有一个ipdb,比pdb高级一些,有高亮显示,学会了debug,程序的运行结果和自己期望的不一致时,就可以单步跟踪调试啦,再也不用四处求人解答了
如何使用pudb在终端调试python代码
pudb是一款可以在终端调试python代码的工具,debug是写代码的必备技能,pudb提供了语法高亮,断点,调用栈,命令行等功能,在终端下可以非常方便的对python代码进行调试。
- 1是代码区域
- 2是命令行区域,你可以在这里主动查看各个变量的数据,如果对这个命令行功能不满意,还可以通过 !键进入到python交互式解释器来进行操作
- 3是变量区域,可以观察变量的变化情况
- 4是栈区域,可以查看栈的信息
只要屏幕上的光标不在第2个区域,快捷键都可以使用。使用ctrl + p 可以进入到工具设置界面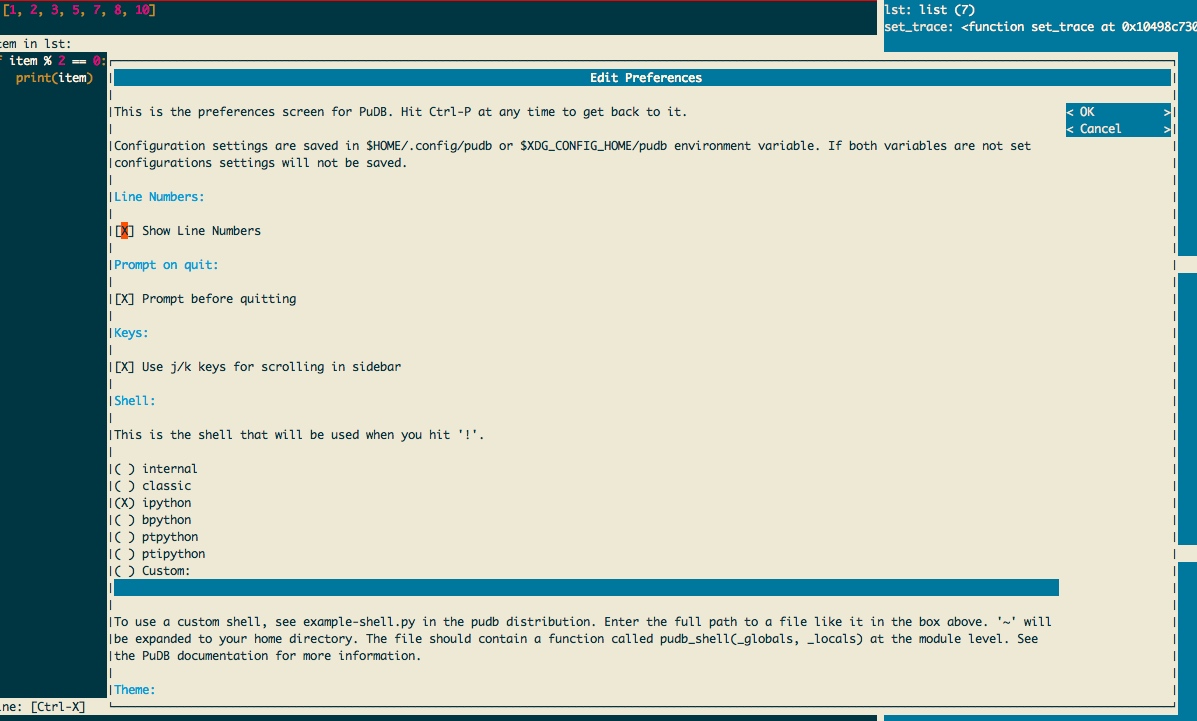
shift+? 可以进入help界面
详细的介绍了工具的快捷键,如何运行下一步,如果跳出当前函数等等
功能强大就不说了,关键安装使用还特别方便
pip install pudb
使用示例代码
from pudb import set_traceset_trace()lst = [1, 2, 3, 5, 7, 8, 10]for item in lst:if item % 2 == 0:print(item)
重点关注前两行代码, set_trace()设置断点
启动工具调试代码的命令如下
pudb3 test.py
有了这个工具,再也不担心在linux下调试代码了

若有收获,就点个赞吧
0 人点赞
