微服务是由多个子系统构成的系统,每个子系统分别负责自己的业务,各个服务之间通过HTTP请求进行通讯,所以保证每个服务的可用性是整体可用性的前提,因此在一些服务提供者不可用的情况下,导致大量请求阻塞到此服务上,从而导致整个服务的不可用,以至于蔓延到整个服务的不可用,所以基于此,在微服务中提出了熔断的概念。
1、熔断器的概念
所谓的熔断,指的是在服务不可用的时候,一定时间内不在向该服务发送请求,接收到该服务的请求的时候,直接返回失败。
2、Hystrix的熔断器原理
Netflix 提供了熔断的组件 Hystrix 被大量应用在SpringCloud 的项目中。
Hystrix 不在更新,建议使用 Resilience4j [https://github.com/resilience4j/resilience4j] Resilience4j 是受Netflix的Hysrix项目启发,专门为Java 8 和函数式编程设计的轻量级容错框架。Resilicenes4j 仅使用了一个第三方开源库Vavr,Vavr不依赖其他库。相比较而言,Netflix Hysrix对Archaius存在编译依赖,Archaius有许多外部依赖,比如Guava和Apache,Commons Configuration。Resilience4j 按模块发布,可以有选择的使用其中某些功能而无需引入全部的Resilience4j 组件。
- Hystrix 会在大量请求无法响应的情况下,及时切断该服务的调用,将状态由CLOSED->OPEN,产生服务降级
- 熔断发生后,Hystrix会执行一个窗口期,当第一个窗口期到来的时候5,会放出一半的请求过去,称之为HALD-OPEN
- 如果熔断器的请求全程成功,则服务熔断状态关闭,否则重新进入OPEN状态,重新计算窗口期
2.1、执行流程
熔断器的执行原理如下图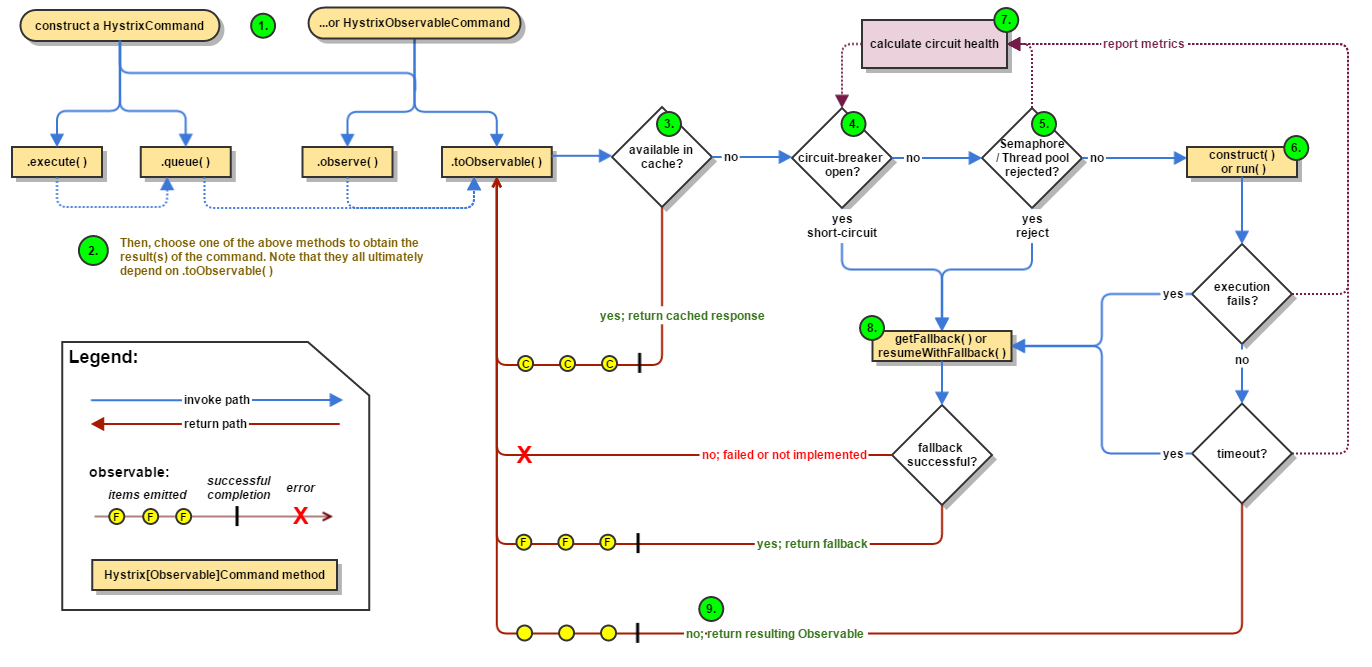
- 首先在向一个服务发送一个请求的时候用,首先会创建一个
HystrixCommand或者HystrixIbserverCommand的对象,此对象用于保存请求依赖的信息 - 此命令有是四种执行方法
- execute 该方法是阻塞的,从依赖请求中接收到单个响应(或者出错时抛出异常)。
- queue —从依赖请求中返回一个包含单个响应的Future对象。
- observe —订阅一个从依赖请求中返回的代表响应的Observable对象。
- toObservable —返回一个Observable对象,只有当你订阅它时,它才会执行Hystrix命令并发射响应。
K value = command.execute();Future<K> fValue = command.queue();Observable<K> ohValue = command.observe(); //hot observableObservable<K> ocValue = command.toObservable(); //cold observable
- 检查是够有缓存
- 回路器是否是开启的,开启的话,直接直接Fallback方法或者其实现
- 线程池、队列、信号量是否已满 ,拒绝的话直接跳转到第8步骤
- 开始执行,直接失败,跳转到第8步骤,直接成功返回 Observable
- 执行结束,计算回路指标,用于决断当前回路状态
- 获取FallBack,从流程图中可以看到以下情况会出现执行FallBack的情况
- 当前回路处于熔断状态
- 线程池和队列或者信号量已满
- 发送请求失败,或者请求超时
2.2、资源隔离技术
Hystrxi负责维护多个资源,各个资源自建有自己的资源池,如果其中一个服务资源池耗尽,不应该影响其他资源的调用,因此各个资源之间的隔离就先的非常重要。
Hystrix 采用了 Bulkhead Partition 舱壁隔离技术,来将外部依赖进行资源隔离,进而避免任何外部依赖的故障导致本服务崩溃。舱壁隔离,是说将船体内部空间区隔划分成若干个隔舱,一旦某几个隔舱发生破损进水,水流不会在其间相互流动,如此一来船舶在受损时,依然能具有足够的浮力和稳定性,进而减低立即沉船的危险。
Hystrix实现资源的隔离的方式主要用: 线程池和信号量隔离。默认使用线程池进行资源隔离。
- 线程池隔离: 适合大部分场景,实现资源的调用和隔离 以及解决超时的问题,使用线程池的线程去调用服务。
- 限号量隔离: 适合访问量非常的大的服务,底层不在使用大量线程实现,而是使用Web容器的线程去执行,信号量有多少就允许多个Web容器的线程通过。

若有收获,就点个赞吧
0 人点赞
