参考:https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
https://km.sankuai.com/page/203146076
spark对比mr的优化地方
1、Spark相较于MapReduce速度快的最主要原因就在于,MapReduce的计算模型太死板,必须是map-reduce模式,有时候即使完成一些诸如过滤之类的操作,也必须经过map-reduce过程,这样就必须经过shuffle过程。而MapReduce的shuffle过程是最消耗性能的,因为shuffle中间的过程必须基于磁盘来读写。而Spark的shuffle虽然也要基于磁盘,但是其大量transformation操作,比如单纯的map或者filter等操作,可以直接基于内存进行pipeline操作,速度性能自然大大提升。
2、spark设计了一些缓存,在迭代计算上会比MR更快速(算法类任务更容易获益)
(spark的DAG调度,可以很好的保存每个stage的血缘关系,并能根据血缘关系递归式的回溯,容错机制优于mapreduce,但并不认为这个特性可以更快)
3、MR中的一个task是一个进程,创建销毁开销大,spark中一个task是一个线程
4、钨丝计划(Tungsten)(参考:ETL on spark 性能优化)https://blog.csdn.net/u011564172/article/details/71170176
大致的内容如下
Memory Management and Binary Processing: off-heap管理内存,降低对象的开销和消除JVM GC带来的延时。
Cache-aware computation: 优化存储,提升CPU L1/ L2/L3缓存命中率。
Code generation: 优化Spark SQL的代码生成部分,提升CPU利用率。
上述第一点和内存管理相关,是本篇文章关注的重点。
为什么Tungsten关注内存和CPU
从硬件角度,网路带宽和磁盘读写都有大幅度提升,例如10Gbps的网络设备和SSD,使用SSD存储数据的公司在逐步增多,并且价格在可接受范围。
从软件角度,Spark做了许多降低网络传输和磁盘IO方面的工作,例如就近执行、序列化等。
此外,databricks的研究也表明CPU是主要的瓶颈,参考Spark Performance Analysis。
spark和mr的区别
与MapReduce完全不一样的是,MapReduce它必须将所有的数据都写入本地磁盘文件以后,才能启动reduce操作,来拉取数据。为什么?因为mapreduce要实现默认的根据key的排序!所以要排序,肯定得写完所有数据,才能排序,然后reduce来拉取。
但是Spark不需要,spark默认情况下,是不会对数据进行排序的。因此ShuffleMapTask每写入一点数据,ResultTask就可以拉取一点数据,然后在本地执行我们定义的聚合函数和算子,进行计算。
spark这种机制的好处在于,速度比mapreduce快多了。但是也有一个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的,很方便。但是spark中,由于这种实时拉取的机制,因此提供不了直接处理key对应的values的算子,只能通过groupByKey,先shuffle,有一个MapPartitionsRDD,然后用map算子,来处理每个key对应的values。就没有mapreduce的计算模型那么方便。
spark:
基本概念
Driver:表示main()函数,创建SparkContext。由SparkContext负责与ClusterManager通信,进行资源的申请,任务的分配和监控等。程序执行完毕后关闭SparkContext
Executor:某个Application运行在Worker节点上的一个进程,该进程负责运行某些task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,这样,每个CoarseGrainedExecutorBackend能并行运行Task的数据就取决于分配给它的CPU的个数。
Worker:集群中可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的worker节点,在Spark on Yarn模式中指的就是NodeManager节点。
Task:在Executor进程中执行任务的工作单元,多个Task组成一个Stage
Job:包含多个Task组成的并行计算,是由Action行为触发的
Stage:每个Job会被拆分很多组Task,作为一个TaskSet,其名称为Stage
DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系
TaskScheduler:将TaskSet提交给Worker(集群)运行,每个Executor运行什么Task就是在此处分配的。
计算流程:在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码了。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用
- 其实区分宽窄依赖主要就是看父RDD的一个Partition的流向,要是流向一个的话就是窄依赖,流向多个的话就是宽依赖。看图理解:

Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个task可能都会从上一个stage的task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。spark的job是根据action算子来进行划分。
spark运行流程以及平台后续rss优化图:
Spark Shuffle发展史
在Spark的版本的发展,ShuffleManager在不断迭代,变得越来越先进。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而由大量的磁盘IO操作影响了性能。因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。SortShuffleManager相较于HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
Hash shuffle
HashShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是合并的运行机制。
合并机制主要是通过复用buffer来优化Shuffle过程中产生的小文件的数量。Hash shuffle是不具有排序的Shuffle。
普通机制的Hash shuffle
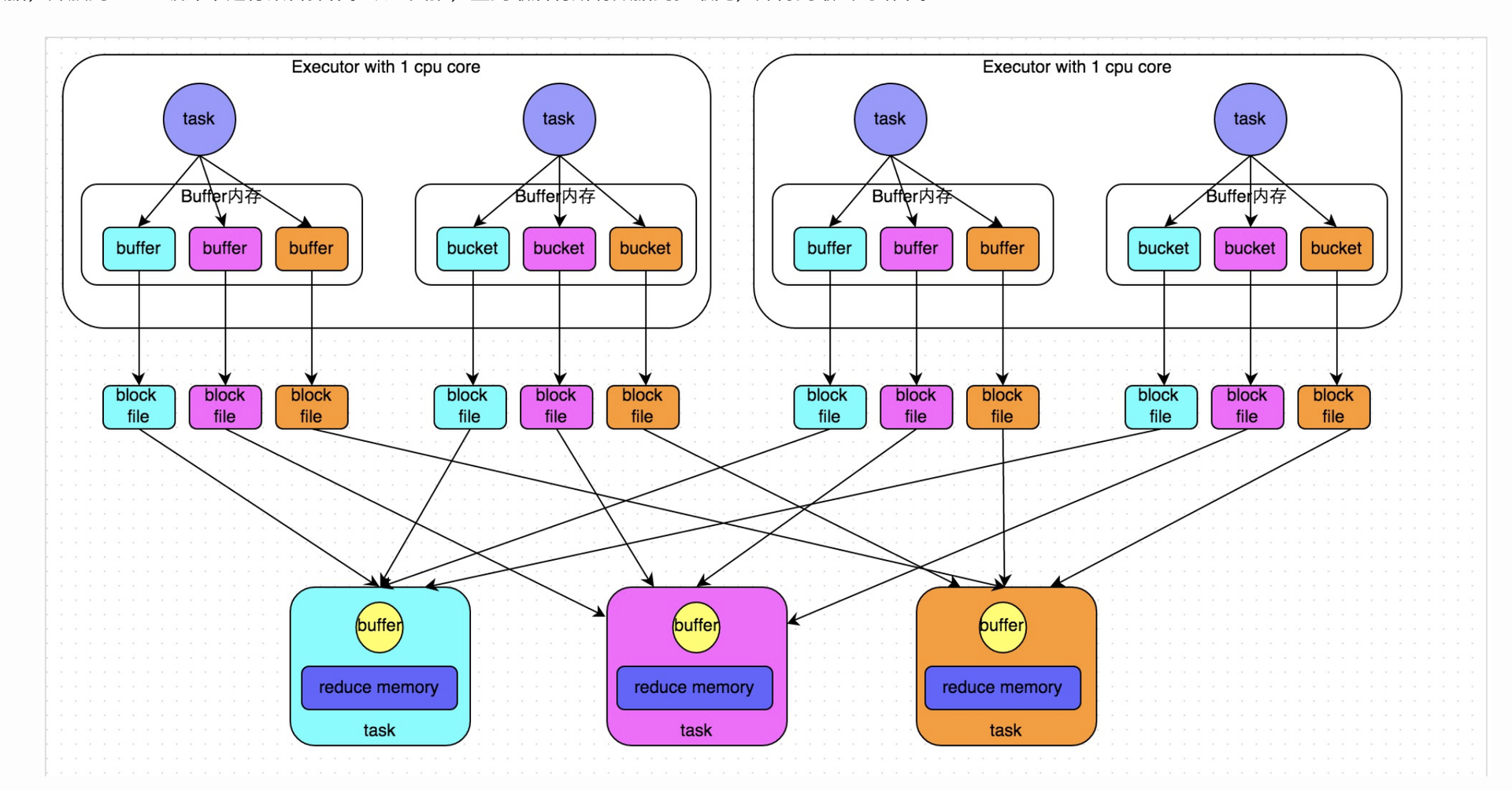
图解:
这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
图中有3个 Reducer,从Task 开始那边各自把自己进行 Hash 计算(分区器:hash/numreduce取模),分类出3个不同的类别,每个 Task 都分成3种类别的数据,想把不同的数据汇聚然后计算出最终的结果,所以Reducer 会在每个 Task 中把属于自己类别的数据收集过来,汇聚成一个同类别的大集合,每1个 Task 输出3份本地文件,这里有4个 Mapper Tasks,所以总共输出了4个 Tasks x 3个分类文件 = 12个本地小文件。
1:shuffle write阶段
主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey,groupByKey),而将每个task处理的数据按key进行“分区”。所谓“分区”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于reduce端的stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?很简单,下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。比如下一个stage总共有100个task,那么当前stage的每个task都要创建100份磁盘文件。如果当前stage有50个task,总共有10个Executor,每个Executor执行5个Task,那么每个Executor上总共就要创建500个磁盘文件,所有Executor上会创建5000个磁盘文件。由此可见,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
2:shuffle read阶段
shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给Reduce端的stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
注意:
1).buffer起到的是缓存作用,缓存能够加速写磁盘,提高计算的效率,buffer的默认大小32k。
分区器:根据hash/numRedcue取模决定数据由几个Reduce处理,也决定了写入几个buffer中
block file:磁盘小文件,从图中我们可以知道磁盘小文件的个数计算公式:
block file=MR
2).M为map task的数量,R为Reduce的数量,一般Reduce的数量等于buffer的数量,都是由分区器决定的
Hash shuffle普通机制的问题
1).Shuffle前在磁盘上会产生海量的小文件,建立通信和拉取数据的次数变多,此时会产生大量耗时低效的 IO 操作 (因為产生过多的小文件)
2).可能导致OOM,大量耗时低效的 IO 操作 ,导致写磁盘时的对象过多,读磁盘时候的对象也过多,这些对象存储在堆内存中,会导致堆内存不足,相应会导致频繁的GC,GC会导致OOM。由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
合并机制的Hash shuffle(优化后的Hash shuffle)
合并机制就是复用buffer,开启合并机制的配置是spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。
这里还是有4个Tasks,数据类别还是分成3种类型,因为Hash算法会根据你的 Key 进行分类,在同一个进程中,无论是有多少过Task,都会把同样的Key放在同一个Buffer里,然后把Buffer中的数据写入以Core数量为单位的本地文件中,(一个Core只有一种类型的Key的数据),每1个Task所在的进程中,分别写入共同进程中的3份本地文件,这里有4个Mapper Tasks,所以总共输出是 2个Cores x 3个分类文件 = 6个本地小文件。
图解:
开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的。一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已有的shuffleFileGroup,包括其中的磁盘文件。也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
假设第二个stage有100个task,第一个stage有50个task,总共还是有10个Executor,每个Executor执行5个task。那么原本使用未经优化的HashShuffleManager时,每个Executor会产生500个磁盘文件,所有Executor会产生5000个磁盘文件的。但是此时经过优化之后,每个Executor创建的磁盘文件的数量的计算公式为:CPU core的数量 下一个stage的task数量。也就是说,每个Executor此时只会创建100个磁盘文件,所有Executor只会创建1000个磁盘文件。
注意:
1).启动HashShuffle的合并机制ConsolidatedShuffle的配置:
spark.shuffle.consolidateFiles=true
2).block file=CoreR
Core为CPU的核数,R为Reduce的数量
Hash shuffle合并机制的问题
如果 Reducer 端的并行任务或者是数据分片过多的话则 Core Reducer Task 依旧过大,也会产生很多小文件。
Sort shuffle
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
Sort shuffle的普通机制
图解:
写入内存数据结构
该图说明了普通的SortShuffleManager的原理。在该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
注意:
shuffle中的定时器:定时器会检查内存数据结构的大小,如果内存数据结构空间不够,那么会申请额外的内存,申请的大小满足如下公式:
applyMemory=nowMenory2-oldMemory
申请的内存=当前的内存情况2-上一次的内存情况
意思就是说内存数据结构的大小的动态变化,如果存储的数据超出内存数据结构的大小,将申请内存数据结构存储的数据2-内存数据结构的设定值的内存大小空间。申请到了,内存数据结构的大小变大,内存不够,申请不到,则发生溢写
排序
在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。
溢写
排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。
merge
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
SortShuffleManager由于有一个磁盘文件merge的过程,因此大大减少了文件数量。比如第一个stage有50个task,总共有10个Executor,每个Executor执行5个task,而第二个stage有100个task。由于每个task最终只有一个磁盘文件,因此此时每个Executor上只有5个磁盘文件,所有Executor只有50个磁盘文件。
注意:
1)block file= 2M
一个map task会产生一个索引文件和一个数据大文件
2) mr>2m(r>2):SortShuffle会使得磁盘小文件的个数再次的减少
*Sort shuffle的bypass机制
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。
2)不是聚合类的shuffle算子(比如reduceByKey)。
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。

若有收获,就点个赞吧
0 人点赞
