图解Kafkfa
Kafka 是主流的消息流系统,其中的概念还是比较多的,下面通过图示的方式来梳理一下 Kafka 的核心概念,以便在我们的头脑中有一个清晰的认识。1. 基础部分Kafka 是一套流处理系统,可以让后端服务轻松的相互沟通,是微服务架构中常用的组件。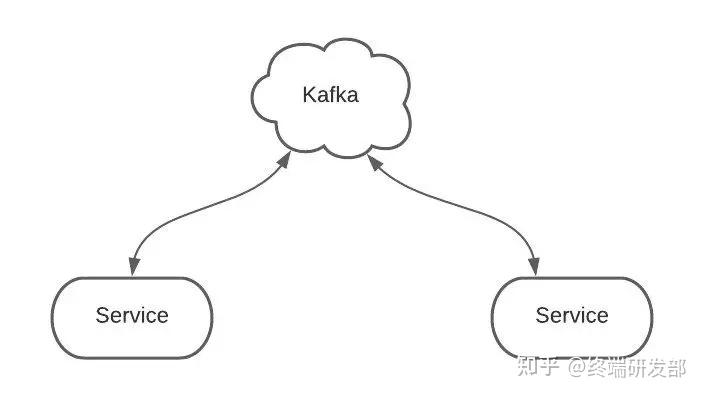
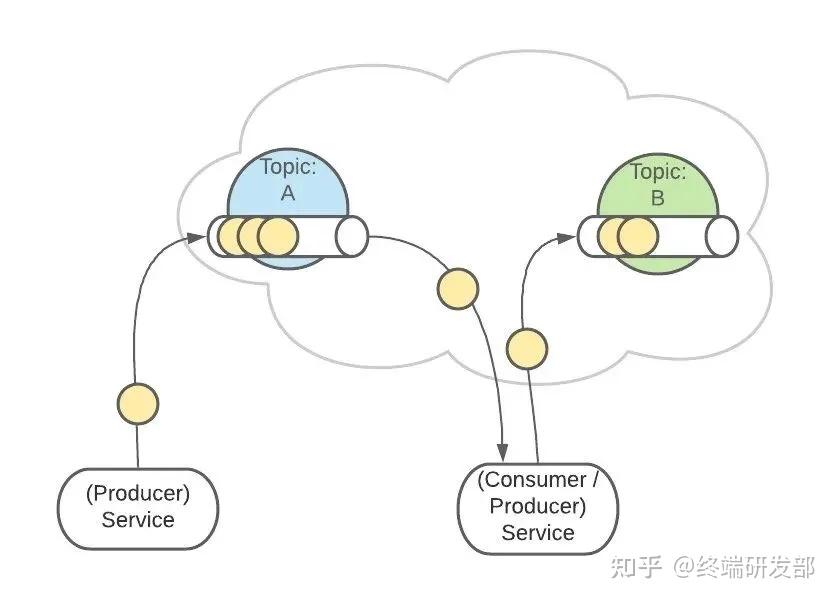
2. 生产者消费者生产者服务 Producer 向 Kafka 发送消息,消费者服务 Consumer 监听 Kafka 接收消息。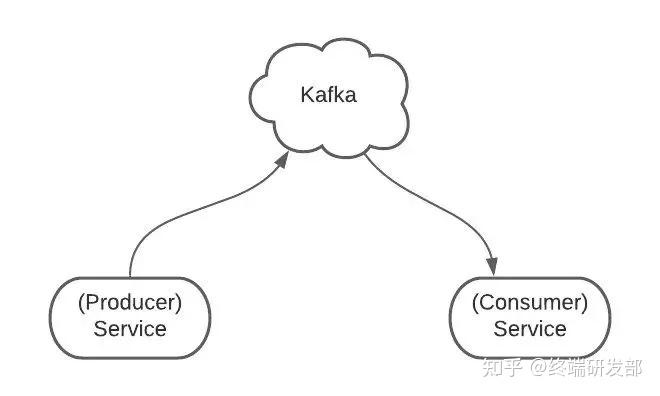
一个服务可以同时为生产者和消费者。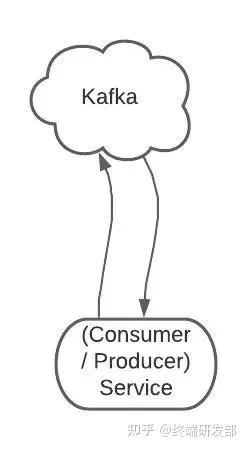
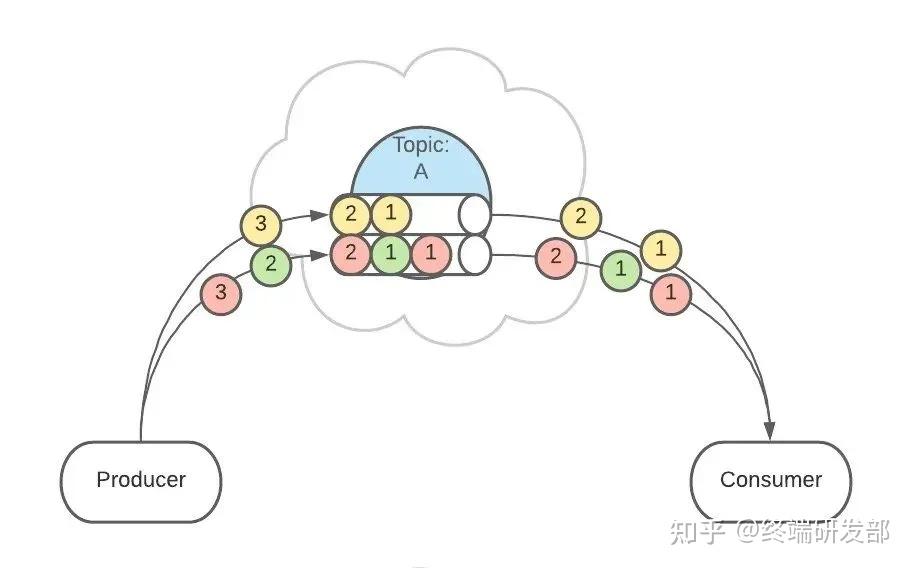
3. Topics 主题Topic 是生产者发送消息的目标地址,是消费者的监听目标。
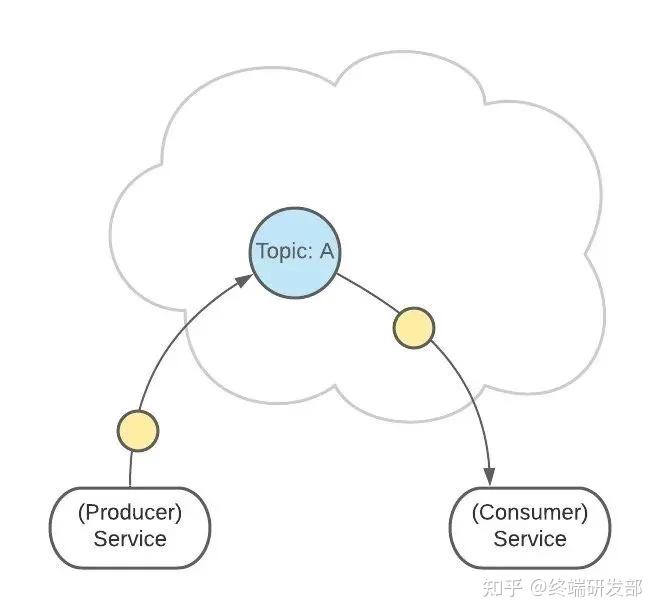 一个服务可以监听、发送多个 Topics。
一个服务可以监听、发送多个 Topics。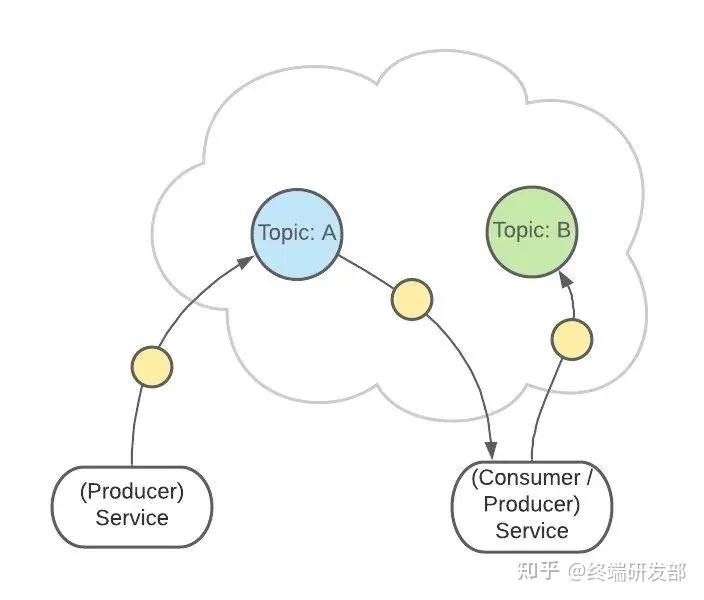 Kafka 中有一个【consumer-group(消费者组)】的概念。这是一组服务,扮演一个消费者。
Kafka 中有一个【consumer-group(消费者组)】的概念。这是一组服务,扮演一个消费者。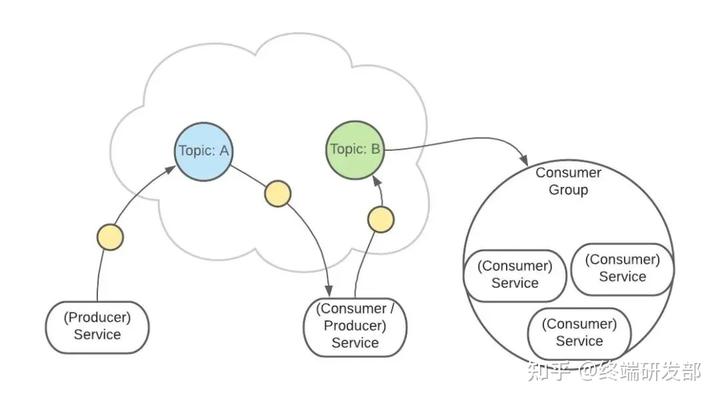 如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务。
如果是消费者组接收消息,Kafka 会把一条消息路由到组中的某一个服务。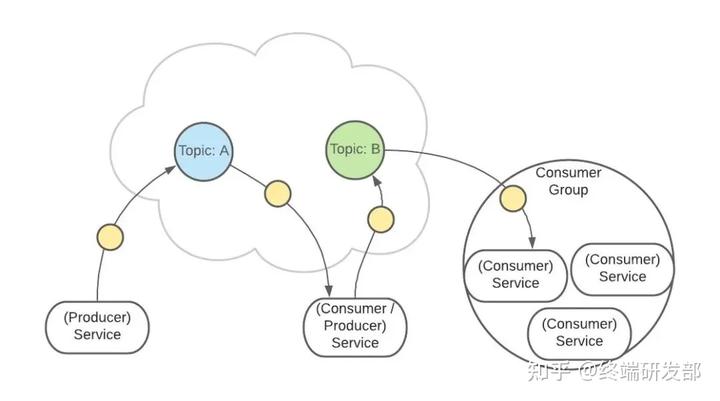 这样有助于消息的负载均衡,也方便扩展消费者。Topic 扮演一个消息的队列。首先,一条消息发送了。
这样有助于消息的负载均衡,也方便扩展消费者。Topic 扮演一个消息的队列。首先,一条消息发送了。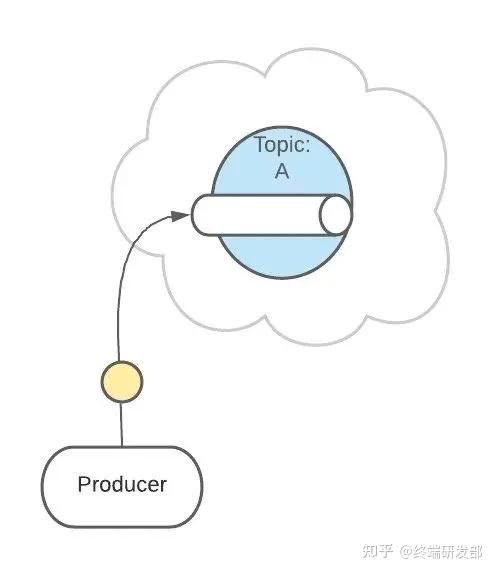 然后,这条消息被记录和存储在这个队列中,不允许被修改。
然后,这条消息被记录和存储在这个队列中,不允许被修改。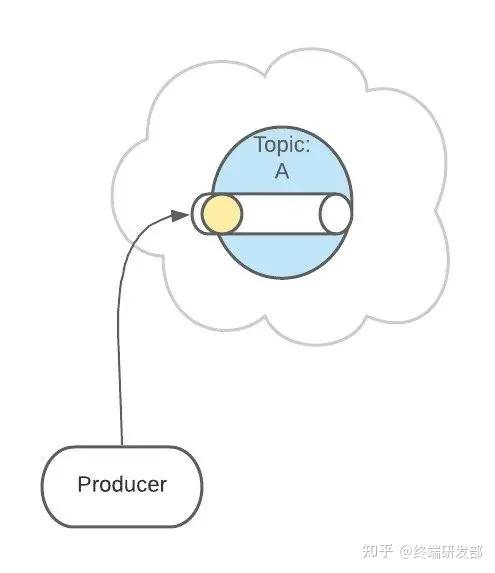 接下来,消息会被发送给此 Topic 的消费者。但是,这条消息并不会被删除,会继续保留在队列中。
接下来,消息会被发送给此 Topic 的消费者。但是,这条消息并不会被删除,会继续保留在队列中。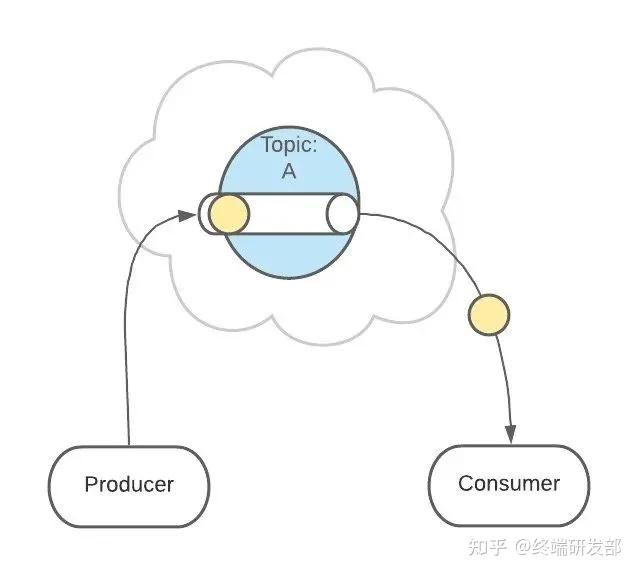 继续发送消息。
继续发送消息。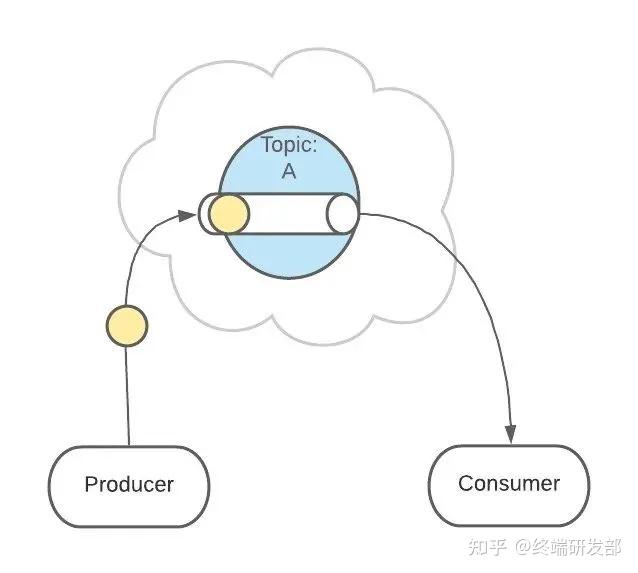 像之前一样,这条消息会发送给消费者、不允许被改动、一直呆在队列中。(消息在队列中能呆多久,可以修改 Kafka 的配置)
像之前一样,这条消息会发送给消费者、不允许被改动、一直呆在队列中。(消息在队列中能呆多久,可以修改 Kafka 的配置)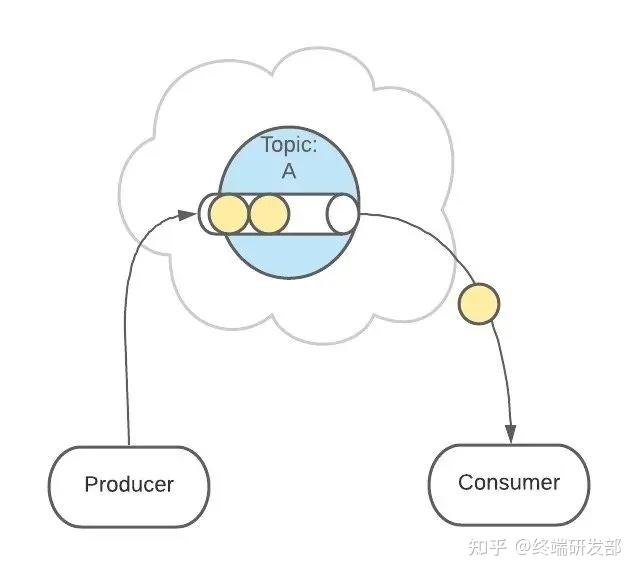
 4. Partitions 分区上面 Topic 的描述中,把 Topic 看做了一个队列,实际上,一个 Topic 是由多个队列组成的,被称为【Partition(分区)】。这样可以便于 Topic 的扩展。
4. Partitions 分区上面 Topic 的描述中,把 Topic 看做了一个队列,实际上,一个 Topic 是由多个队列组成的,被称为【Partition(分区)】。这样可以便于 Topic 的扩展。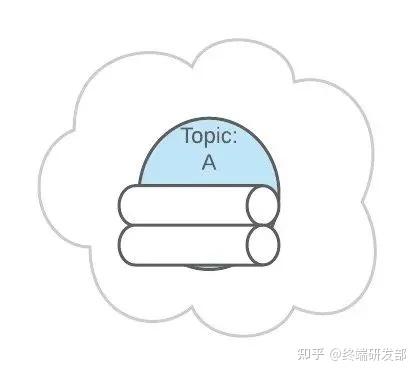 生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition。
生产者发送消息的时候,这条消息会被路由到此 Topic 中的某一个 Partition。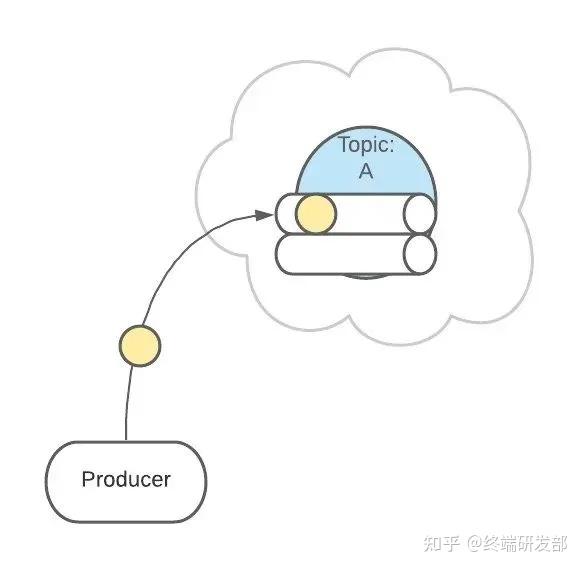 消费者监听的是所有分区。
消费者监听的是所有分区。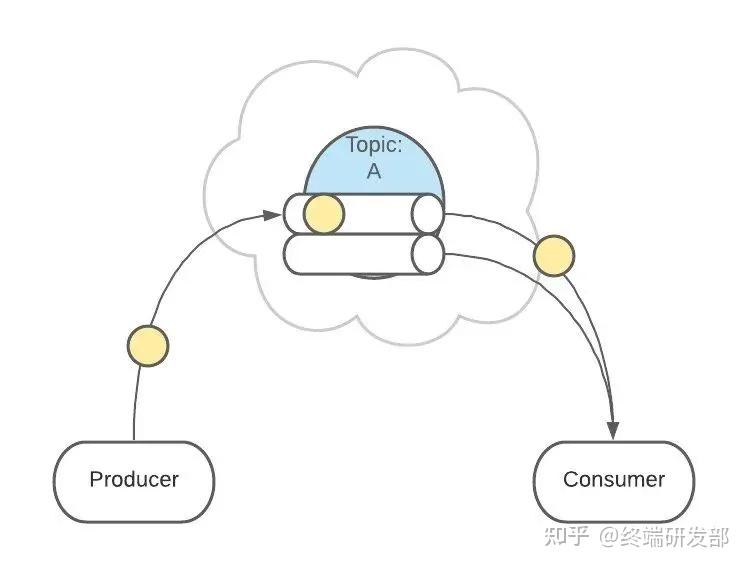 生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略。
生产者发送消息时,默认是面向 Topic 的,由 Topic 决定放在哪个 Partition,默认使用轮询策略。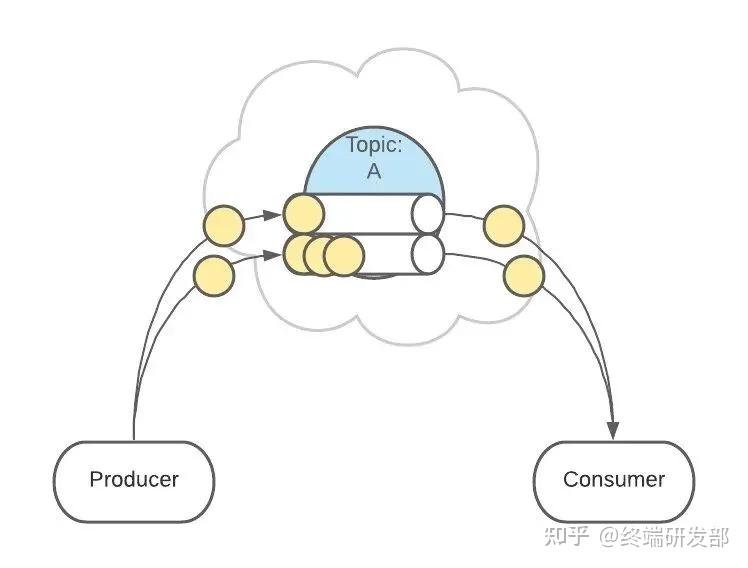 也可以配置 Topic,让同类型的消息都在同一个 Partition。例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。例如,用户1发送了3条消息:A、B、C,默认情况下,这3条消息是在不同的 Partition 中(如 P1、P2、P3)。在配置之后,可以确保用户1的所有消息都发到同一个分区中(如 P1)。
也可以配置 Topic,让同类型的消息都在同一个 Partition。例如,处理用户消息,可以让某一个用户所有消息都在一个 Partition。例如,用户1发送了3条消息:A、B、C,默认情况下,这3条消息是在不同的 Partition 中(如 P1、P2、P3)。在配置之后,可以确保用户1的所有消息都发到同一个分区中(如 P1)。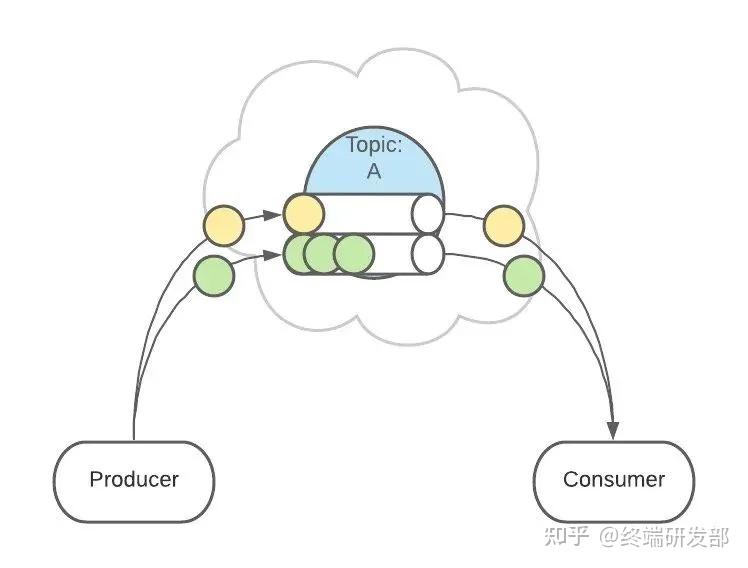 这个功能有什么用呢?这是为了提供消息的【有序性】。消息在不同的 Partition 是不能保证有序的,只有一个 Partition 内的消息是有序的。
这个功能有什么用呢?这是为了提供消息的【有序性】。消息在不同的 Partition 是不能保证有序的,只有一个 Partition 内的消息是有序的。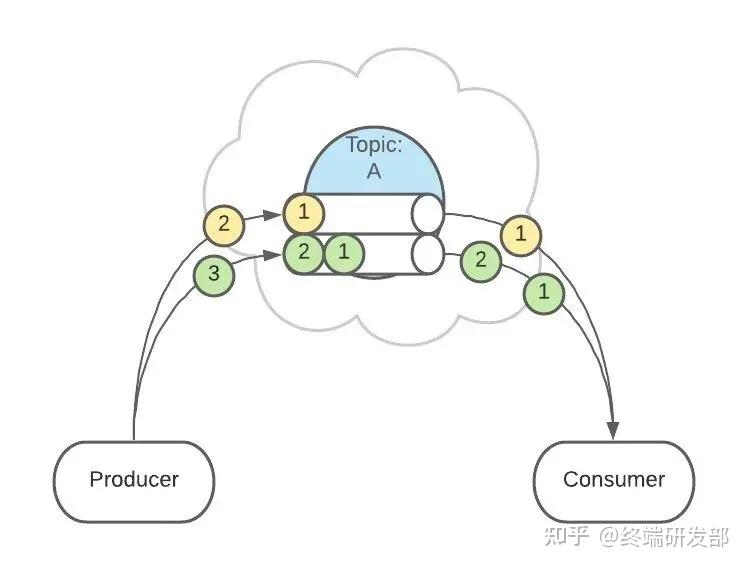
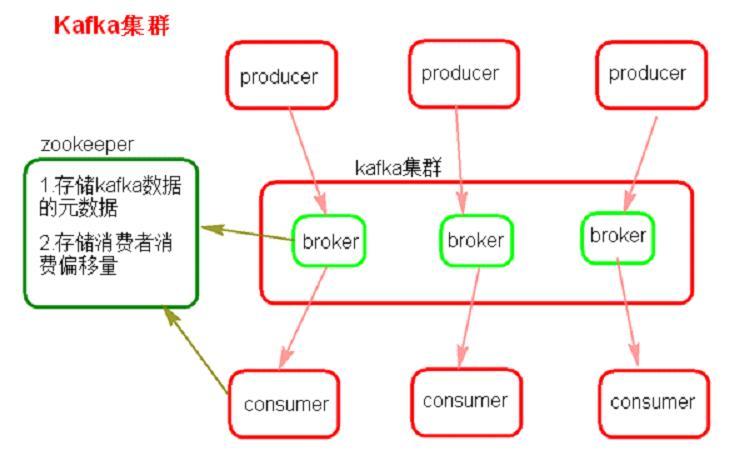
5. 架构
Kafka 是集群架构的,ZooKeeper是重要组件。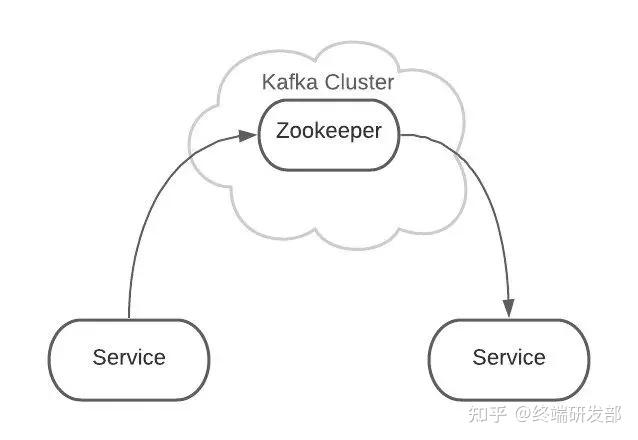 ZooKeeper 管理者所有的 Topic 和 Partition。Topic 和 Partition 存储在 Node 物理节点中,ZooKeeper负责维护这些 Node。
ZooKeeper 管理者所有的 Topic 和 Partition。Topic 和 Partition 存储在 Node 物理节点中,ZooKeeper负责维护这些 Node。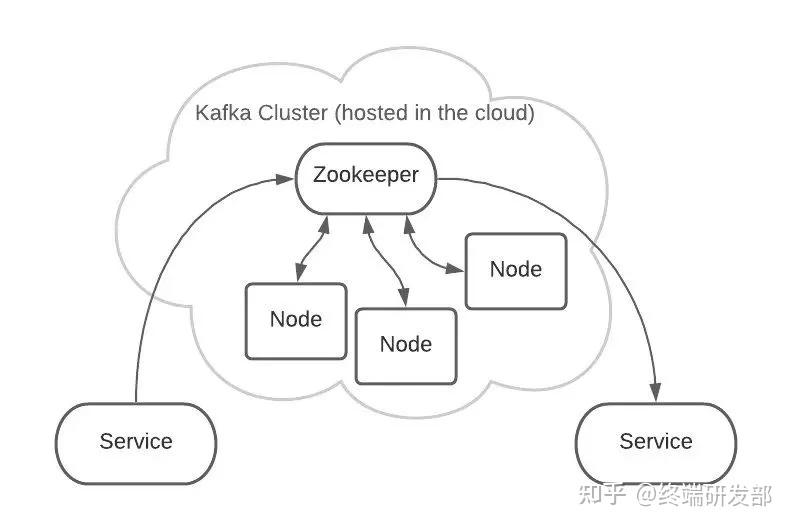 例如,有2个 Topic,各自有2个 Partition。
例如,有2个 Topic,各自有2个 Partition。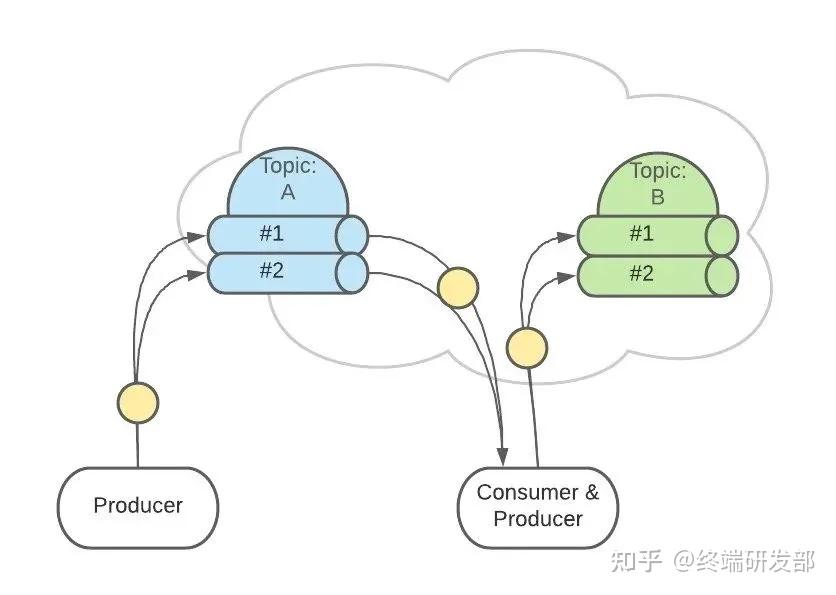 这是逻辑上的形式,但在 Kafka 集群中的实际存储可能是这样的:
这是逻辑上的形式,但在 Kafka 集群中的实际存储可能是这样的: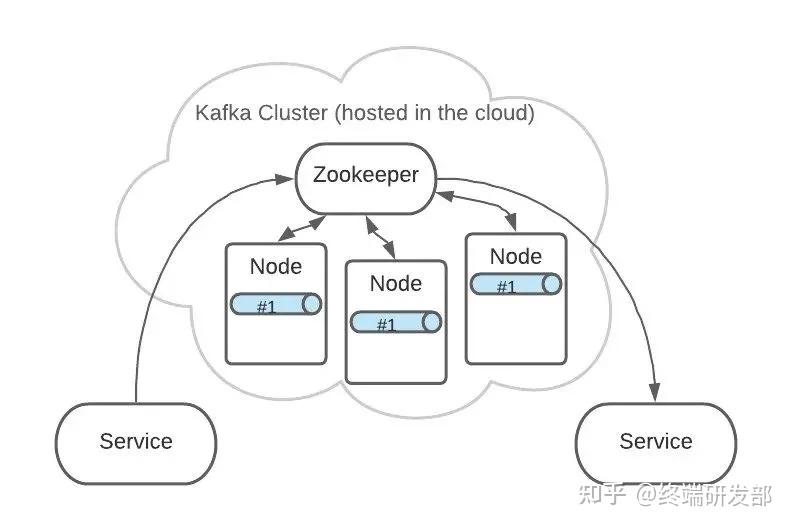 Topic A 的 Partition #1 有3份,分布在各个 Node 上。这样可以增加 Kafka 的可靠性和系统弹性。3个 Partition #1 中,ZooKeeper 会指定一个 Leader,负责接收生产者发来的消息。
Topic A 的 Partition #1 有3份,分布在各个 Node 上。这样可以增加 Kafka 的可靠性和系统弹性。3个 Partition #1 中,ZooKeeper 会指定一个 Leader,负责接收生产者发来的消息。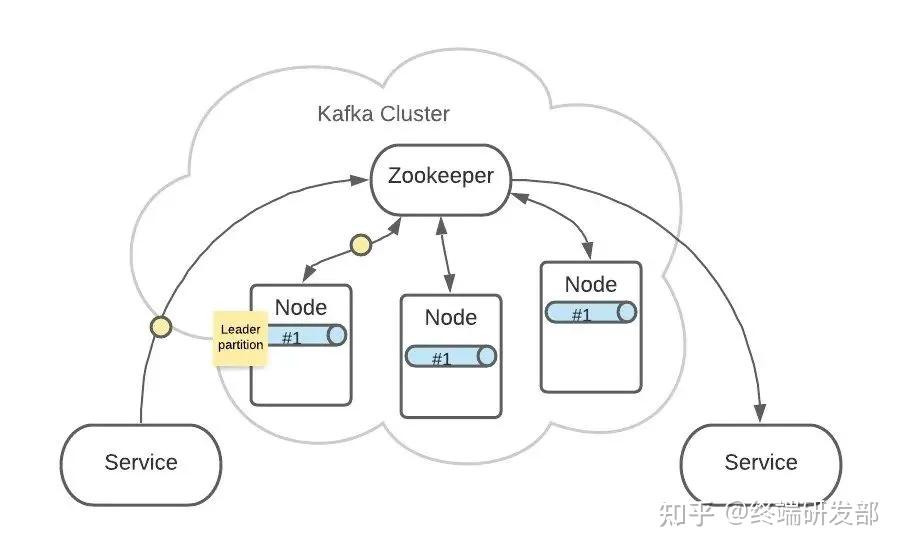 其他2个 Partition #1 会作为 Follower,Leader 接收到的消息会复制给 Follower。
其他2个 Partition #1 会作为 Follower,Leader 接收到的消息会复制给 Follower。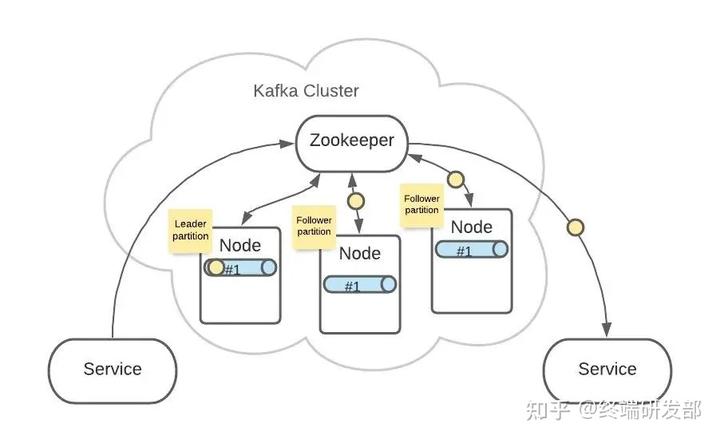 这样,每个 Partition 都含有了全量消息数据。
这样,每个 Partition 都含有了全量消息数据。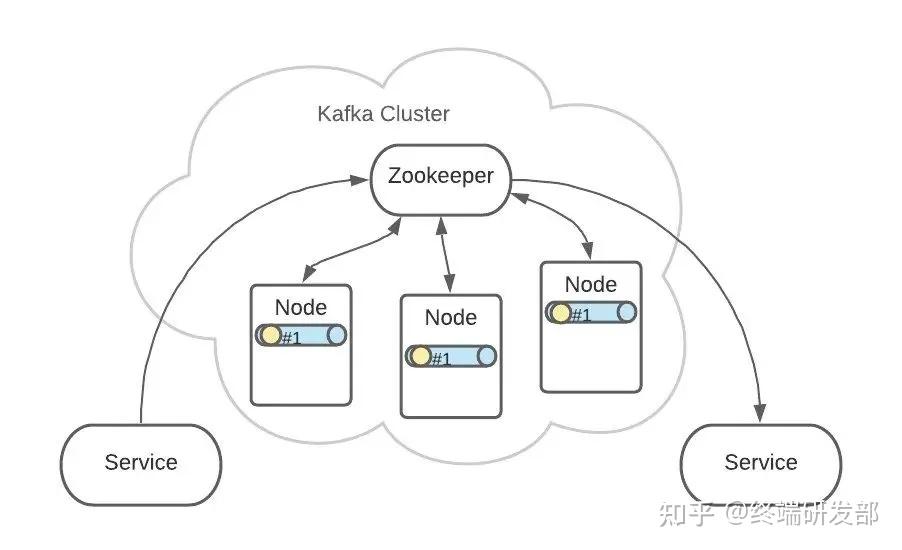 即使某个 Node 节点出现了故障,也不用担心消息的损坏。Topic A 和 Topic B 的所有 Partition 分布可能就是这样的:
即使某个 Node 节点出现了故障,也不用担心消息的损坏。Topic A 和 Topic B 的所有 Partition 分布可能就是这样的: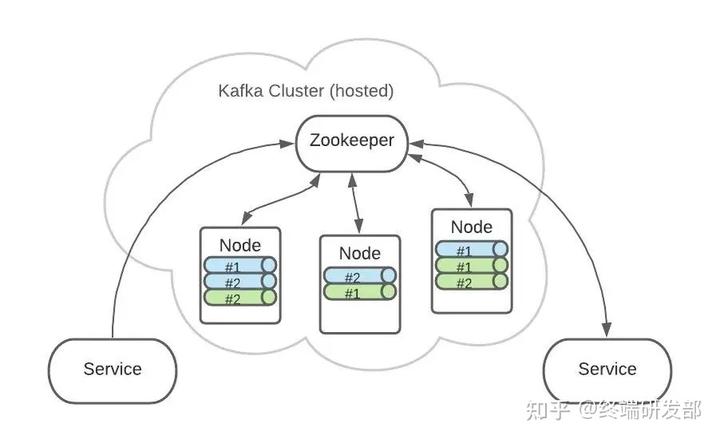
Kafka 消息是采用 Pull 模式,还是 Push 模式?
Kafka 最初考虑的问题是,customer 应该从 brokes 拉取消息还是 brokers 将消息推送到consumer,也就是 pull 还 push。在这方面,Kafka 遵循了一种大部分消息系统共同的传统的设计:producer 将消息推送到 broker,consumer 从 broker 拉取消息一些消息系统比如 Scribe 和 Apache Flume 采用了 push 模式,将消息推送到下游的consumer。
这样做有好处也有坏处:由 broker 决定消息推送的速率,对于不同消费速率的consumer 就不太好处理了。消息系统都致力于让 consumer 以最大的速率最快速的消费消息,但不幸的是,push 模式下,当 broker 推送的速率远大于 consumer 消费的速率时,consumer 恐怕就要崩溃了,最终 Kafka 还是选取了传统的 pull 模式
Pull 模式的另外一个好处是:consumer 可以自主决定是否批量的从 broker 拉取数据。Push模式必须在不知道下游 consumer 消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免 consumer 崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull 模式下,consumer 就可以根据自己的消费能力去决定这些策略
Pull 有个缺点是:如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,直到新消息到达。为了避免这点,Kafka 有个参数可以让 consumer 阻塞知道新消息到达,当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发

若有收获,就点个赞吧
0 人点赞
