Mycat+Mysql主从复制实现双机热备
一、原理简介
1、mysql主从同步(复制)概念
- master服务器将数据的改变都记录到二进制binlog日志中,只要master上的数据发生改变,则将其改变写入二进制日志;
- salve服务器会在一定时间间隔内对master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O Thread请求master二进制事件
- 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中
- 从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致
- 最后I/O Thread和SQL Thread将进入睡眠状态,等待下一次被唤醒.
(·binlog:**是二进制日志文件,用于记录mysql的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据)
需要理解:
- 从库会生成两个线程,一个I/O线程,一个SQL线程;
- I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
- 主库会生成一个log dump线程,用来给从库I/O线程传binlog;
- SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
- 主库的bin log 格式最好用row格式 能记录下修改或更新数据的对应行列ID,方便回滚以及更改。
2、Mysql支持哪些复制
- 基于语句的复制: 在主服务器执行SQL语句,在从服务器执行同样语句。
注:MySQL默认采用基于语句的复制,效率较高。一旦发现没法精确复制时, 会自动选基于行的复制。
基于行的复制: 把改变的内容复制过去,而不是把命令在从服务器上执行一遍. 从mysql5.0开始支持
混合类型的复制: 默认采用基于语句的复制,一旦发现基于语句的无法精确的复制时,就会采用基于行的复制。
二、mycat介绍
MyCat是一个开源的分布式数据库系统,是一个实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理(类似于Mysql Proxy),用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器里或者其他数据库里。
MyCat发展到目前的版本,已经不是一个单纯的MySQL代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在MyCat里,都是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
Mycat可以简单概括为
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
Mycat关键特性
- 支持SQL92标准
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群
- 支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
- 基于Nio实现,有效管理线程,高并发问题
- 支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页
- 支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询
- 支持多租户方案
- 支持分布式事务(弱xa)
- 支持全局序列号,解决分布式下的主键生成问题
- 分片规则丰富,插件化开发,易于扩展
- 强大的web,命令行监控
- 支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉
- 支持密码加密
- 支持服务降级
- 支持IP白名单
- 支持SQL黑名单、sql注入攻击拦截
- 支持分表(1.6)
- 集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)
三、Mycat工作原理
Mycat的原理并不复杂,复杂的是代码。Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分
片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
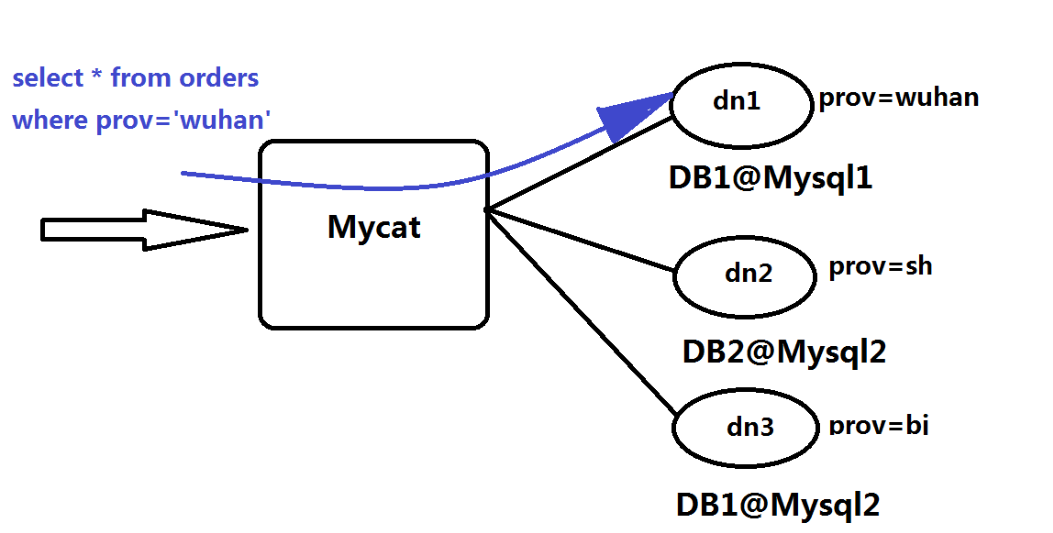
上述图片里,Orders表被分为三个分片datanode(简称dn),这三个分片是分布在两台MySQL Server上(DataHost),即datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字符串枚举方式。
当Mycat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字段的值,并匹配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以select * from Orders where prov=?语句为例,查到prov=wuhan,按照分片函数,wuhan返回dn1,于是SQL就发给了MySQL1,去取DB1上的查询结果,并返回给用户。
如果上述SQL改为select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL就会发给MySQL1与MySQL2去执行,然后结果集合并后输出给用户。但通常业务中我们的SQL会有Order By 以及Limit翻页语法,此时就涉及到结果集在Mycat端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的Jion问题,为此,Mycat提出了创新性的ER分片、全局表、HBT(Human Brain Tech)人工智能的Catlet、以及结合Storm/Spark引擎等十八般武艺的解决办法,
五、Mycat应用场景
Mycat发展到现在,适用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是几个典型的应用场景:
- 单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
- 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片;
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化;
- 报表系统,借助于Mycat的分表能力,处理大规模报表的统计;
- 替代Hbase,分析大数据;
- 作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择;
- Mycat长期路线图;
- 强化分布式数据库中间件的方面的功能,使之具备丰富的插件、强大的数据库智能优化功能、全面的系统监控能力、以及方便的数据运维工具,实现在线数据扩容、迁移等高级功能;
- 进一步挺进大数据计算领域,深度结合Spark Stream和Storm等分布式实时流引擎,能够完成快速的巨表关联、排序、分组聚合等 OLAP方向的能力,并集成一些热门常用的实时分析算法,让工程师以及DBA们更容易用Mycat实现一些高级数据分析处理功能。
- 不断强化Mycat开源社区的技术水平,吸引更多的IT技术专家,使得Mycat社区成为中国的Apache,并将Mycat推到Apache
基金会,成为国内顶尖开源项目,最终能够让一部分志愿者成为专职的Mycat开发者,荣耀跟实力一起提升。
五、Mycat不适合的应用场景
- 设计使用Mycat时有非分片字段查询,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时有分页排序,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请慎重使用Mycat,可以考虑放弃!
三、mycat+mysql搭建主从,热备
应用程序如果连接数据库大致有两种方案
2.1. 应用层解决:
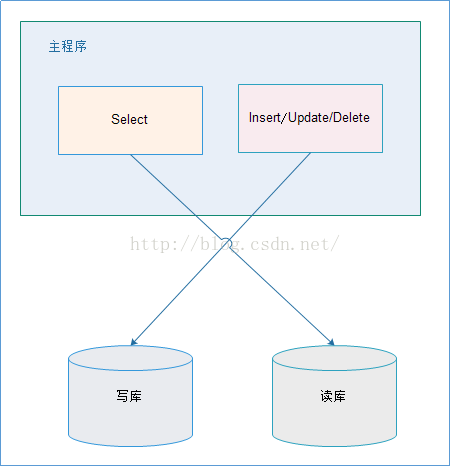
优点:
1、 多数据源切换方便,由程序自动完成;
2、 不需要引入中间件;
3、 理论上支持任何数据库;
缺点:
1、 由程序员完成,运维参与不到;
2、 不能做到动态增加数据源;
2.2. 中间件解决
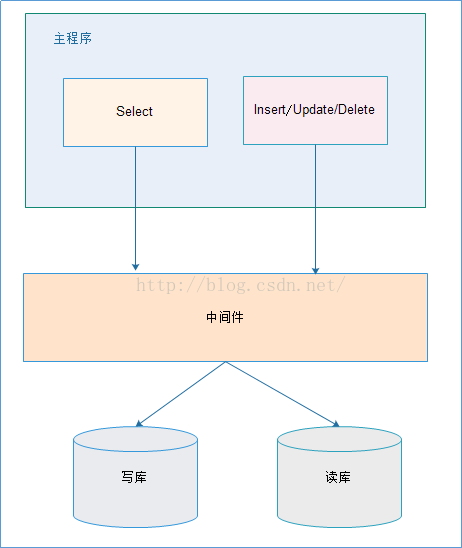
优缺点:
优点:
1、 源程序不需要做任何改动就可以实现读写分离;
2、 动态添加数据源不需要重启程序;
缺点:
1、 程序依赖于中间件,会导致切换数据库变得困难;
2、 由中间件做了中转代理,性能有所下降;
如果在项目里自动动态切换数据源的话,对代码的耦合程度好像比较高,且目前来说暂时用不到数据库分库分表技术,本文介绍用mycat+mysql来集成应用程序,
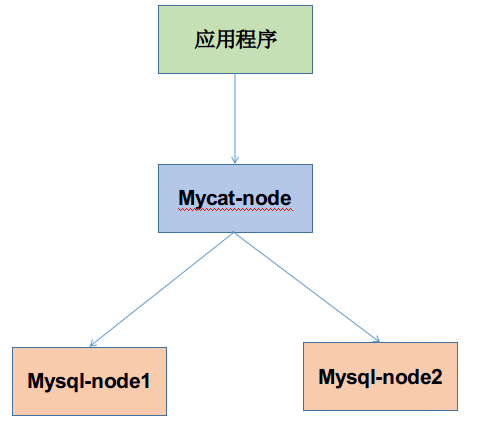
1.服务器准备:准备两台服务器或者两个虚拟机
2.在这两台服务器上分别安装好Mysql,两台服务器上mysql的用户名和密码都是root3.我们以下的配置统一称呼,MasterA和SlaveB①在MasterA服务器上给SlaveB授权使用命令连接mysql:mysql -uroot -proot执行授权命令:grant replication slave on *.* to 'root'@'SlaveB的ip ' identified by 'root';参数说明:用户名:root密码:root这样配置意思是:允许SlaveB使用用户名为root,密码为root访问MasterA的Binary log日志②开启MasterA服务器的binary log打开my.cnf配置文件,添加一下配置,使用命令编辑my.cnf这个配置文件:vi /etc/my.cnf
参数说明:
datadir:数据的存放路径
socket:mysql有两种连接方式socket和TCP/IP
server-id:搭建主从复制时不能重复
log-bin:binary log的名称
expire_logs_days:binlog日志的过期时间,达到设置的时间后会自动清理
binlog-do-db:设置哪些库的操作日志记录到binary log中
4.创建数据库
如果MasterA和SlaveB上需要创建全新的库,则直接在两个mysql上创建数据库就可以了,如果要做主从复制的数据库正在使用中,我们需要先将数据库锁住,待操作完之后再解锁使用,为的是避免两个数据库数据不是一个初态,如果两台服务器上要做主从复制的数据库的初态不是一样的那就没有意义了。
锁定数据库命令:FLUSH TABLES WITH READ LOCK;
将数据库从MasterA上导出,将导出的数据库导入到SlaveB的mysql上
查看MasterA数据库的binary位置,用于配置SlaveB:
参数说明:
File:日志名称
Position:日志偏移量
Binlog_Do_DB:记录日志的库
将刚才锁定的数据库解锁:UNLOCK TABLES;
5.配置SlaveB的mysql
使用命令vi /etc/my.cnf编辑配置文件,添加以下配置:
6.开启SlaveB的slave
7.查看SlaveB的slave线程是否开启
Slave_IO_Running为读取master的binaryLog的线程
Slave_SQL_Running为执行SQL的线程
这两个线程必须都为YES才可以实现主从复制。
三、Mycat+Mysql单向主从结果验证
1.使用navicat连接上两个mysql
2.在MasterA的mysql的库中添加一条数据,查看SlaveB的mysql库中是否同步过来,结果是同步了
3.在MasterA这台服务器上安装一个mycat,我们配置一下mycat的schema和server两个配置文件
schema:
server.xml添加以下配置:
mysql -uroot -proot -h127.0.0.1 -P8066
5.插入一条数据,结果验证是两个库中的数据会同步
6.将Master的mysql停掉,依旧通过mycat插入一条数据,数据会插入到Slave的mysql中,将Master的mysql启动,通过mycat插入一条数据到数据库,发现两个数据库之间不会同步.
四、配置两个mysql互为主从
在以上配置的基础上,将Master机器作为slave,slave的机器作为master.
1.在Slave(相对的Master)机器上连接mysql,为Master(相对的Slave)授权
grant replication slave on *.* to 'root'@'192.168.22.xxx' identified by 'root';
其中192.168.22.xxx是Master机的ip
2.查看Slave机的binarylog
3.开启Master的同步
如果出现上图的错误就先将slave停掉,再操作一遍,使用命令:STOP SLAVE,(此处命令必须为大写)开启完同步之后需要打开slave,使用命令:START SLAVE(此处命令必须为大写)。
4.在Master上查看slave的状态
五、验证互为主从搭建结果
1.navicat连接mysql之后,在数据库中直接添加一条数据,分别在两个数据库中添加一条数据,发现数据在两个数据库中同步。
2.mycat的配置不用修改,用mycat连接mysql,命令为:mysql -uroot -proot -h127.0.0.1 -P8066
3.插入一条数据,发现数据库也能同步
4.将其中一个数据库停掉,在启动着的数据库中添加一条数据,然后启动刚才停掉的数据库,发现数据同样同步到了数据库中。

若有收获,就点个赞吧
0 人点赞
