Hystrix简介
Hystrix的概念和设计目的
在分布式环境中,许多服务依赖项中的一些必然会失败,比如:超时、异常、服务器宕机。如果这些失败不做处理而是长时间的等待或抛出调用方无法处理的异常,就会导致服务调用方的线程长时间、不必要地被占用,从而在分布式系统中蔓延而导致雪崩。而Hystrix是一个延迟和容错的库,就是用来防止这些问题发生的,它能在某个微服务出现故障之后即使做出合理的处理,会给调用方返回一个备选响应(FallBack),从而不会导致整体服务失败,避免级联故障,提供整个分布式系统的弹性。
Hystrix被设计的目目的是:
- 对通过第三方客户端库访问的依赖项(通常是通过网络)的延迟和故障进行保护和控制
- 在复杂的分布式系统中阻止级联故障
- 快速失败,快速恢复
- 回退,尽可能优雅地降级
- 启用近实时监控、警报和操作控制
虽然Hystrix由于某些原因已经进入停更维护阶段,但是其设计思想是服务治理板块的顶峰,后来许多替代品几乎都是借鉴Hystrix的设计思想。
Hystrix实现的主要功能
Hystrix主要有三个功能:服务降级(FallBack)、服务熔断(Break)、服务限流(FlowLimit),而这三个功能也是微服务高可用的三大利器。
服务降级
服务降级就是在微服务的调用链路中,其中某一个节点出现比如过度延时、服务器宕机、异常等情况后,也就是原服务不能在正常的提供时,就需要有一个“保底”服务,这个“保底”服务能给用户一些“友好的提示”,不至于让用户一直等待或者出现非常难看的报错页面。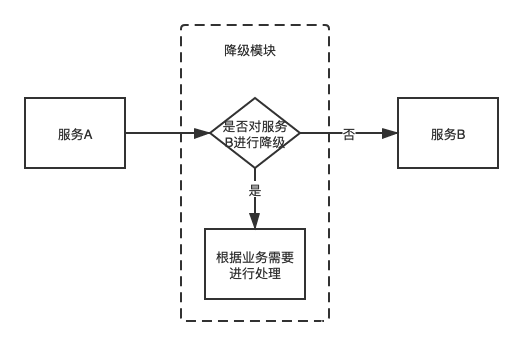
服务熔断
服务熔断是服务方的一种自我保护机制,当服务方出现宕机、压力过大、不能提供正常服务……服务方就会拒绝调用者的调用并给出友好提示,就好比“保险丝”。熔断的好处就是不会因为一个服务的故障而导致整个微服务的瘫痪。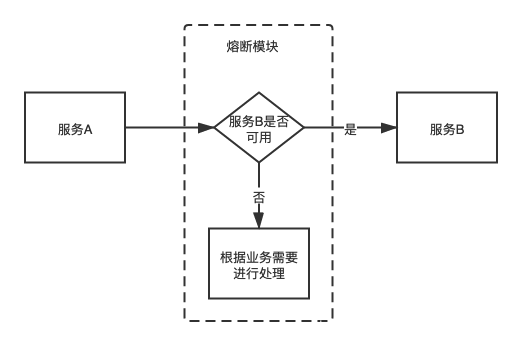
服务限流
当一个微服务承受高并发时,难以短时间内处理如此多的请求,也就是请求已经超过该服务的处理范围,这时候就需要对请求进行限流,可能让请求“排队”,也可能直接丢弃请求。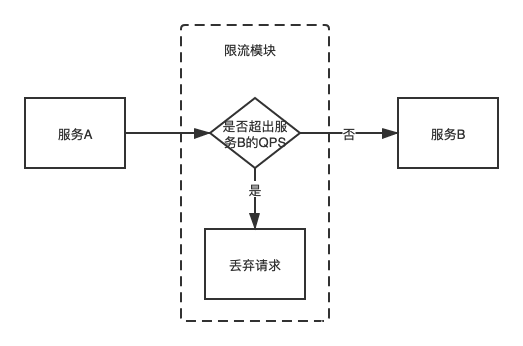
服务降级

若有收获,就点个赞吧
0 人点赞
