- 一、Java基础(语言、集合框架、OOP、设计模式等)
- 1. HashMap和Hashtable的区别
- 2. java的线程安全
- 3. java集合框架(常用)
- 3.1 List集合和Set集合
- 3.2 ArrayList、LinkedList、Vector的区别
- 3.3 Map集合
- 3.4 为什么使用ConcurrentHashMap而不是HashMap或Hashtable?
- 3.5 Collection 和 Collections的区别
- 3.6 Map、Set、List、Queue、Stack的特点与用法
- 3.7 HashMap的工作原理
- 3.8 Map的实现类的介绍
- 3.9 LinkedList 和 PriorityQueue 的区别
- 3.10 线程安全的集合类。Vector、Hashtable、Properties和Stack、ConcurrentHashMap
- 3.11 BlockingQueue
- 3.12 如何对一组对象进行排序
- 4. ArrayList
- 5. final关键字
- 6. 接口与抽象类
- 6.1 一个子类只能继承一个抽象类,但能实现多个接口
- 6.2 抽象类可以有构造方法,接口没有构造方法
- 6.3 抽象类可以有普通成员变量,接口没有普通成员变量
- 6.4 抽象类和接口都可有静态成员变量,抽象类中静态成员变量访问类型任意,接口只能public static final(默认)
- 6.5 抽象类可以没有抽象方法,抽象类可以有普通方法,接口中都是抽象方法
- 6.6 抽象类可以有静态方法,接口不能有静态方法
- 6.7 抽象类中的方法可以是public、protected;接口方法只有public abstract
- 7. 抽象类和最终类
- 8.异常
- 9. 关于finally
- 10. 受检查异常和运行时异常
- 10.1 粉红色的是受检查的异常(checked exceptions)
- 其必须被try…catch语句块所捕获, 或者在方法签名里通过throws子句声明。受检查的异常必须在编译时被捕捉处理,命名为Checked Exception是因为Java编译器要进行检查, Java虚拟机也要进行检查, 以确保这个规则得到遵守。
- 常见的checked exception:ClassNotFoundException IOException FileNotFoundException EOFException
- 10.2 绿色的异常是运行时异常(runtime exceptions),
- 需要程序员自己分析代码决定是否捕获和处理,比如空指针,被0除…
- 常见的runtime exception:NullPointerException ArithmeticException ClassCastException IllegalArgumentException IllegalStateException IndexOutOfBoundsException NoSuchElementException
- 10.3 而声明为Error的,则属于严重错误,如系统崩溃、虚拟机错误、动态链接失败等,这些错误无法恢复或者不可能捕捉,将导致应用程序中断,Error不需要捕获。
- 11. this & super
- 11.1 super出现在父类的子类中。有三种存在方式
- 11.2 this() & super()在构造方法中的区别
- 12. 修饰符一览
- 13. 构造内部类和静态内部类对象
- 14. 序列化
- 15.正则表达式
- 16. 面向对象的五大基本原则(solid)
- 17. 面向对象设计其他原则
- 18. null可以被强制转型为任意类型的对象
- 19.代码执行次序
- 20. 数组复制方法
- 21. 多态
- 22. Java文件
- 23. Java移位运算符
- 24. 形参&实参
- 25. IO流一览
- 26. 局部变量为什么要初始化
- 27. Java语言的鲁棒性
- 28. Java语言特性
- 29. 包装类的equals()方法不处理数据转型,必须类型和值都一样才相等。
- 30. 子类可以继承父类的静态方法!但是不能覆盖。因为静态方法是在编译时确定了,不能多态,也就是不能运行时绑定。
- 31. Java语法糖
- 32. Java 中应该使用什么数据类型来代表价格?
- 33. 怎么将 byte 转换为 String?
- 34. Java 中怎样将 bytes 转换为 long 类型?
- 35. 我们能将 int 强制转换为 byte 类型的变量吗?如果该值大于 byte 类型的范围,将会出现什么现象?
- 36. 存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为 C 么?如 C = © B;
- 37. 哪个类包含 clone 方法?是 Cloneable 还是 Object?
- 38. Java 中 ++ 操作符是线程安全的吗?
- 39. a = a + b 与 a += b 的区别
- 40. 我能在不进行强制转换的情况下将一个 double 值赋值给 long 类型的变量吗?
- 41. 3*0.1 == 0.3 将会返回什么?true 还是 false?
- 42. int 和 Integer 哪个会占用更多的内存?
- 43. 为什么 Java 中的 String 是不可变的(Immutable)?
- 44. 我们能在 Switch 中使用 String 吗?
- 45. Java 中的构造器链是什么?
- 46. 枚举类
- 48. 什么是不可变对象(immutable object)?Java 中怎么创建一个不可变对象?
- 49. 我们能创建一个包含可变对象的不可变对象吗?
- 50. List和Set
- 51. poll() 方法和 remove() 方法的区别?
- 52. Java 中 LinkedHashMap 和 PriorityQueue 的区别是什么?
- 53. ArrayList 与 LinkedList 的区别?
- 54. 用哪两种方式来实现集合的排序?
- 55. Java 中怎么打印数组?
- 56. Java 中的 LinkedList 是单向链表还是双向链表?
- 57. Java 中的 TreeMap 是采用什么树实现的?
- 58. Java 中的 HashSet,内部是如何工作的?
- 59. 写一段代码在遍历 ArrayList 时移除一个元素?
- 60. 我们能自己写一个容器类,然后使用 for-each 循环吗?
- 61. ArrayList 和 HashMap 的默认大小是多数?
- 62. 有没有可能两个不相等的对象有有相同的 hashcode?
- 63. 两个相同的对象会有不同的的 hash code 吗?
- 64. 我们可以在 hashcode() 中使用随机数字吗?
- 65. Java 中,Comparator 与 Comparable 有什么不同?
- 66. 为什么在重写 equals 方法的时候需要重写 hashCode 方法?
- 67. “a==b”和”a.equals(b)”有什么区别?
- 68. a.hashCode() 有什么用?与 a.equals(b) 有什么关系?
- 69. final、finalize 和 finally 的不同之处?
- 70. Java 中的编译期常量是什么?使用它又什么风险?
- 71. 说出几点 Java 中使用 Collections 的最佳实践
- 72. 静态内部类与顶级类有什么区别?
- 73. Java 中,Serializable 与 Externalizable 的区别?
- 74. 说出 JDK 1.7 中的三个新特性?
- 75. 说出 5 个 JDK 1.8 引入的新特性?
- 76. 接口是什么?为什么要使用接口而不是直接使用具体类?
- 78. 除了单例模式,你在生产环境中还用过什么设计模式?
- 79. 你能解释一下里氏替换原则吗?
- 81. 适配器模式是什么?什么时候使用?
- 82. 构造器注入和 setter 依赖注入,那种方式更好?
- 83. 依赖注入和工厂模式之间有什么不同?
- 84. 适配器模式和装饰器模式有什么区别?
- 85. 适配器模式和代理模式之前有什么不同?
- 86. 什么是模板方法模式?
- 87. 什么时候使用访问者模式?
- 88. 什么时候使用组合模式?
- 89. 继承和组合之间有什么不同?
- 90. 描述 Java 中的重载和重写?
- 91. OOP 中的 组合、聚合和关联有什么区别?
- 92. 给我一个符合开闭原则的设计模式的例子?
- 93. 什么时候使用享元模式(蝇量模式)?
- 94. Java 中如何格式化一个日期?如格式化为 ddMMyyyy 的形式?
- 95. Java 中,怎么在格式化的日期中显示时区?
- 97. Java 中,如何计算两个日期之间的差距?
- 98. Java 中,如何将字符串 YYYYMMDD 转换为日期?
- 99. 说出几条 Java 中方法重载的最佳实践?
- 100. 说出 5 条 IO 的最佳实践
- 101. Object有哪些公用方法?
- 102. equals与==的区别
- 103. String、StringBuffer与StringBuilder的区别
- 104. switch能否用String做参数
- 105. 封装、继承、多态
- 106. Comparable和Comparator接口区别
- 107. 与Java集合框架相关的有哪些最好的实践
- 108. IO和NIO简述
- 二、Java高级(JavaEE、框架、服务器、工具等)
- 1. Servlet
- 1.9 HttpServletResponse完成一些的功能
- 2. JSP
- 3. Tomcat
- 4. struts
- 5. Hibernate的7大鼓励措施
- 6. Hibernate延迟加载
- 7. Java 中,DOM 和 SAX 解析器有什么不同?
- 8. Java 中,Maven 和 ANT 有什么区别?
- 9. 解析XML不同方式对比
- 10. Nginx相关
- 11. XML与JSON对比和区别
- 三、多线程和并发
- 四、Java虚拟机
- 五、数据库(Sql、MySQL、Redis等)
- 六、算法与数据结构
- 七、计算机网络
- 八、操作系统(OS基础、Linux等)
- 九、其他
Java基础知识点总结
大纲
一、Java基础(语言、集合框架、OOP、设计模式等)
二、Java高级(JavaEE、框架、服务器、工具等)
三、多线程和并发
四、Java虚拟机
五、数据库(Sql、MySQL、Redis等)
六、算法与数据结构
七、计算机网络
八、操作系统(OS基础、Linux等)
九、其他
一、Java基础(语言、集合框架、OOP、设计模式等)
1. HashMap和Hashtable的区别
Hashtable是基于陈旧的Dictionary的Map接口的实现,而HashMap是基于哈希表的Map接口的实现
从方法上看,HashMap去掉了Hashtable的contains方法
HashTable是同步的(线程安全),而HashMap线程不安全,效率上HashMap更快
HashMap允许空键值,而Hashtable不允许
HashMap的iterator迭代器执行快速失败机制,也就是说在迭代过程中修改集合结构,除非调用迭代器自身的remove方法,否则以其他任何方式的修改都将抛出并发修改异常。而Hashtable返回的Enumeration不是快速失败的。
注:Fast-fail机制:在使用迭代器的过程中有其它线程修改了集合对象结构或元素数量,都将抛出ConcurrentModifiedException,但是抛出这个异常是不保证的,我们不能编写依赖于此异常的程序。
2. java的线程安全
Vector、Stack、HashTable、ConcurrentHashMap、Properties
3. java集合框架(常用)
Collection - List - ArrayList
Collection - List - LinkedList
Collection - List - Vector
Collection - List - Vector - Stack
Collection - Set - HashSet
Collection - Set - TreeSet
Collection - List - LinkedHashSet
Map - HashMap
Map - TreeMap
Map - HashTable
Map - LinkedHashMap
Map - ConcurrentHashMap
3.1 List集合和Set集合
List中元素存取是有序的、可重复的;Set集合中元素是无序的,不可重复的。
CopyOnWriteArrayList:COW的策略,即写时复制的策略。适用于读多写少的并发场景
Set集合元素存取无序,且元素不可重复。
HashSet不保证迭代顺序,线程不安全;LinkedHashSet是Set接口的哈希表和链接列表的实现,保证迭代顺序,线程不安全。
TreeSet:可以对Set集合中的元素排序,元素以二叉树形式存放,线程不安全。
3.2 ArrayList、LinkedList、Vector的区别
首先它们均是List接口的实现。
ArrayList、LinkedList的区别
1.随机存取:ArrayList是基于可变大小的数组实现,LinkedList是链接列表的实现。这也就决定了对于随机访问的get和set的操作,ArrayList要优于LinkedList,因为LinkedList要移动指针。
2.插入和删除:LinkedList要好一些,因为ArrayList要移动数据,更新索引。
3.内存消耗:LinkedList需要更多的内存,因为需要维护指向后继结点的指针。
Vector从JDK 1.0起就存在,在1.2时改为实现List接口,功能与ArrayList类似,但是Vector具备线程安全。
3.3 Map集合
Hashtable:基于Dictionary类,线程安全,速度快。底层是哈希表数据结构。是同步的。
不允许null作为键,null作为值。
Properties:Hashtable的子类。用于配置文件的定义和操作,使用频率非常高,同时键和值都是字符串。
HashMap:线程不安全,底层是数组加链表实现的哈希表。允许null作为键,null作为值。HashMap去掉了contains方法。
注意:HashMap不保证元素的迭代顺序。如果需要元素存取有序,请使用LinkedHashMap
TreeMap:可以用来对Map集合中的键进行排序。
ConcurrentHashMap:是JUC包下的一个并发集合。
3.4 为什么使用ConcurrentHashMap而不是HashMap或Hashtable?
HashMap的缺点:主要是多线程同时put时,如果同时触发了rehash操作,会导致HashMap中的链表中出现循环节点,进而使得后面get的时候,会死循环,CPU达到100%,所以在并发情况下不能使用HashMap。让HashMap同步:Map m = Collections.synchronizeMap(hashMap);而Hashtable虽然是同步的,使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap的原理:
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因在于所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap的结构:
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入互斥锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,当对某个HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
ConcurrentHashMap的构造、get、put操作:
构造函数:传入参数分别为 1、初始容量,默认16 2、装载因子 装载因子用于rehash的判定,就是当ConcurrentHashMap中的元素大于装载因子*最大容量时进行扩容,默认0.75 3、并发级别 这个值用来确定Segment的个数,Segment的个数是大于等于concurrencyLevel的第一个2的n次方的数。比如,如果concurrencyLevel为12,13,14,15,16这些数,则Segment的数目为16(2的4次方)。默认值为static final int DEFAULT_CONCURRENCY_LEVEL = 16;。理想情况下ConcurrentHashMap的真正的并发访问量能够达到concurrencyLevel,因为有concurrencyLevel个Segment,假如有concurrencyLevel个线程需要访问Map,并且需要访问的数据都恰好分别落在不同的Segment中,则这些线程能够无竞争地自由访问(因为他们不需要竞争同一把锁),达到同时访问的效果。这也是为什么这个参数起名为“并发级别”的原因。默认16.
初始化的一些动作:
初始化segments数组(根据并发级别得到数组大小ssize),默认16
初始化segmentShift和segmentMask(这两个全局变量在定位segment时的哈希算法里需要使用),默认情况下segmentShift为28,segmentMask为15
初始化每个Segment,这一步会确定Segment里HashEntry数组的长度.
put操作:
1、判断value是否为null,如果为null,直接抛出异常。
2、key通过一次hash运算得到一个hash值。将得到hash值向右按位移动segmentShift位,然后再与segmentMask做&运算得到segment的索引j。即segmentFor方法
3、使用Unsafe的方式从Segment数组中获取该索引对应的Segment对象。向这个Segment对象中put值,这个put操作也基本是一样的步骤(通过&运算获取HashEntry的索引,然后set)。
get操作:
1、和put操作一样,先通过key进行hash确定应该去哪个Segment中取数据。
2、使用Unsafe获取对应的Segment,然后再进行一次&运算得到HashEntry链表的位置,然后从链表头开始遍历整个链表(因为Hash可能会有碰撞,所以用一个链表保存),如果找到对应的key,则返回对应的value值,如果链表遍历完都没有找到对应的key,则说明Map中不包含该key,返回null。
定位Segment的hash算法:(hash >>> segmentShift) & segmentMask
定位HashEntry所使用的hash算法:int index = hash & (tab.length - 1);
注:
1.tab为HashEntry数组
2.ConcurrentHashMap既不允许null key也不允许null value
3.5 Collection 和 Collections的区别
Collection是集合类的上级接口,子接口主要有Set 和List、Queue
Collections是针对集合类的一个辅助类,提供了操作集合的工具方法:一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
3.6 Map、Set、List、Queue、Stack的特点与用法
Set集合类似于一个罐子,”丢进”Set集合里的多个对象之间没有明显的顺序。 List集合代表元素有序、可重复的集合,集合中每个元素都有其对应的顺序索引。 Stack是Vector提供的一个子类,用于模拟”栈”这种数据结构(LIFO后进先出) Queue用于模拟”队列”这种数据结构(先进先出 FIFO)。 Map用于保存具有”映射关系”的数据,因此Map集合里保存着两组值。
3.7 HashMap的工作原理
HashMap维护了一个Entry数组,Entry内部类有key,value,hash和next四个字段,其中next也是一个Entry类型。可以将Entry数组理解为一个个的散列桶。每一个桶实际上是一个单链表。当执行put操作时,会根据key的hashcode定位到相应的桶。遍历单链表检查该key是否已经存在,如果存在,覆盖该value,反之,新建一个新的Entry,并放在单链表的头部。当通过传递key调用get方法时,它再次使用key.hashCode()来找到相应的散列桶,然后使用key.equals()方法找出单链表中正确的Entry,然后返回它的值。
3.8 Map的实现类的介绍
HashMap基于散列表来的实现,即使用hashCode()进行快速查询元素的位置,显著提高性能。插入和查询“键值对”的开销是固定的。可以通过设置容量和装载因子,以调整容器的性能。
LinkedHashMap, 类似于HashMap,但是迭代遍历它时,保证迭代的顺序是其插入的次序,因为它使用链表维护内部次序。此外可以在构造器中设定LinkedHashMap,使之采用LRU算法。使没有被访问过的元素或较少访问的元素出现在前面,访问过的或访问多的出现在后面。这对于需要定期清理元素以节省空间的程序员来说,此功能使得程序员很容易得以实现。
TreeMap, 是基于红黑树的实现。同时TreeMap实现了SortedMap接口,该接口可以确保键处于排序状态。所以查看“键”和“键值对”时,所有得到的结果都是经过排序的,次序由自然排序或提供的Comparator决定。SortedMap接口拥有其他额外的功能,如:返回当前Map使用的Comparator比较强,firstKey(),lastKey(),headMap(toKey),tailMap(fromKey)以及可以返回一个子树的subMap()方法等。
WeakHashMap,表示弱键映射,WeakHashMap 的工作与正常的 HashMap 类似,但是使用弱引用作为 key,意思就是当 key 对象没有任何引用时,key/value 将会被回收。
ConcurrentHashMap, 在HashMap基础上分段锁机制实现的线程安全的HashMap。
IdentityHashMap 使用==代替equals() 对“键”进行比较的散列映射。专为解决特殊问题而设计。
HashTable:基于Dictionary类的Map接口的实现,它是线程安全的。
3.9 LinkedList 和 PriorityQueue 的区别
它们均是Queue接口的实现。拥有FIFO的特点,它们的区别在于排序行为。LinkedList 支持双向列表操作,
PriorityQueue 按优先级组织的队列,元素的出队次序由元素的自然排序或者由Comparator比较器指定。
3.10 线程安全的集合类。Vector、Hashtable、Properties和Stack、ConcurrentHashMap
3.11 BlockingQueue
Java.util.concurrent.BlockingQueue是一个队列,在进行获取元素时,它会等待队列变为非空;当在添加一个元素时,它会等待队列中的可用空间。BlockingQueue接口是Java集合框架的一部分,主要用于实现生产者-消费者模式。我们不需要担心等待生产者有可用的空间,或消费者有可用的对象,因为它都在BlockingQueue的实现类中被处理了。Java提供了集中BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,、SynchronousQueue等。
3.12 如何对一组对象进行排序
如果需要对一个对象数组进行排序,我们可以使用Arrays.sort()方法。如果我们需要排序一个对象列表,我们可以使用Collections.sort()方法。排序时是默认根据元素的自然排序(使用Comparable)或使用Comparator外部比较器。Collections内部使用数组排序方法,所有它们两者都有相同的性能,只是Collections需要花时间将列表转换为数组。
4. ArrayList
无参构造 容量为10
ArrayList(Collections<?extends E> c)构造包含指定collection的元素的列表
ArrayList(int initialCapacity) 指定初始容量
5. final关键字
final修饰的变量是常量,必须进行初始化,可以显示初始化,也可以通过构造进行初始化,如果不初始化编译会报错。
6. 接口与抽象类
6.1 一个子类只能继承一个抽象类,但能实现多个接口
6.2 抽象类可以有构造方法,接口没有构造方法
6.3 抽象类可以有普通成员变量,接口没有普通成员变量
6.4 抽象类和接口都可有静态成员变量,抽象类中静态成员变量访问类型任意,接口只能public static final(默认)
6.5 抽象类可以没有抽象方法,抽象类可以有普通方法,接口中都是抽象方法
6.6 抽象类可以有静态方法,接口不能有静态方法
6.7 抽象类中的方法可以是public、protected;接口方法只有public abstract
7. 抽象类和最终类
抽象类可以没有抽象方法, 最终类可以没有最终方法
最终类不能被继承, 最终方法不能被重写(可以重载)
8.异常
相关的关键字 throw、throws、try…catch、finally
throws 用在方法签名上, 以便抛出的异常可以被调用者处理
throw 方法内部通过throw抛出异常
try 用于检测包住的语句块, 若有异常, catch子句捕获并执行catch块
9. 关于finally
finally不管有没有异常都要处理
当try和catch中有return时,finally仍然会执行,finally比return先执行
不管有木有异常抛出, finally在return返回前执行
finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的
注意:finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值
finally不执行的几种情况:程序提前终止如调用了System.exit, 病毒,断电
10. 受检查异常和运行时异常
10.1 粉红色的是受检查的异常(checked exceptions)
其必须被try…catch语句块所捕获, 或者在方法签名里通过throws子句声明。受检查的异常必须在编译时被捕捉处理,命名为Checked Exception是因为Java编译器要进行检查, Java虚拟机也要进行检查, 以确保这个规则得到遵守。
常见的checked exception:ClassNotFoundException IOException FileNotFoundException EOFException
10.2 绿色的异常是运行时异常(runtime exceptions),
需要程序员自己分析代码决定是否捕获和处理,比如空指针,被0除…
常见的runtime exception:NullPointerException ArithmeticException ClassCastException IllegalArgumentException IllegalStateException IndexOutOfBoundsException NoSuchElementException
10.3 而声明为Error的,则属于严重错误,如系统崩溃、虚拟机错误、动态链接失败等,这些错误无法恢复或者不可能捕捉,将导致应用程序中断,Error不需要捕获。
11. this & super
11.1 super出现在父类的子类中。有三种存在方式
super.xxx(xxx为变量名或对象名)意思是获取父类中xxx的变量或引用
super.xxx(); (xxx为方法名)意思是直接访问并调用父类中的方法
super() 调用父类构造
注:super只能指代其直接父类
11.2 this() & super()在构造方法中的区别
调用super()必须写在子类构造方法的第一行, 否则编译不通过
super从子类调用父类构造, this在同一类中调用其他构造
均需要放在第一行
尽管可以用this调用一个构造器, 却不能调用2个
this和super不能出现在同一个构造器中, 否则编译不通过
this()、super()都指的对象,不可以在static环境中使用
本质this指向本对象的指针。super是一个关键字
12. 修饰符一览
修饰符 类内部 同一个包 子类 任何地方
private yes
default yes yes
protected yes yes yes
public yes yes yes yes
13. 构造内部类和静态内部类对象
public class Enclosingone {public class Insideone {}public static class Insideone{}}
public class Test {public static void main(String[] args) {// 构造内部类对象需要外部类的引用Enclosingone.Insideone obj1 = new Enclosingone().new Insideone();// 构造静态内部类的对象Enclosingone.Insideone obj2 = new Enclosingone.Insideone();}}
静态内部类不需要有指向外部类的引用。但非静态内部类需要持有对外部类的引用。非静态内部类能够访问外部类的静态和非静态成员。静态内部类不能访问外部类的非静态成员,只能访问外部类的静态成员。
14. 序列化
声明为static和transient类型的数据不能被序列化, 反序列化需要一个无参构造函数
序列化参见我的笔记Java-note-序列化.md
15.正则表达式
详情见:正则表达式
https://www.yuque.com/zhegeshaonianyoudiandou/ik45ux/ahk4dd
16. 面向对象的五大基本原则(solid)
S单一职责SRP:Single-Responsibility Principle
一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合,高内聚在面向对象原则的引申,将职责定义为引起变化的原因,以提高内聚性减少引起变化的原因。
O开放封闭原则OCP:Open-Closed Principle
软件实体应该是可扩展的,而不是可修改的。对扩展开放,对修改封闭
L里氏替换原则LSP:Liskov-Substitution Principle
子类必须能够替换其基类。这一思想表现为对继承机制的约束规范,只有子类能够替换其基类时,才能够保证系统在运行期内识别子类,这是保证继承复用的基础。
I接口隔离原则ISP:Interface-Segregation Principle
使用多个小的接口,而不是一个大的总接口
D依赖倒置原则DIP:Dependency-Inversion Principle
依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者共同依赖于抽象。抽象不依赖于具体,具体依赖于抽象。
17. 面向对象设计其他原则
封装变化
少用继承 多用组合
针对接口编程 不针对实现编程
为交互对象之间的松耦合设计而努力
类应该对扩展开发 对修改封闭(开闭OCP原则)
依赖抽象,不要依赖于具体类(依赖倒置DIP原则)
密友原则:只和朋友交谈(最少知识原则,迪米特法则)
说明:一个对象应当对其他对象有尽可能少的了解,将方法调用保持在界限内,只调用属于以下范围的方法:
该对象本身(本地方法)对象的组件 被当作方法参数传进来的对象 此方法创建或实例化的任何对象
别找我(调用我) 我会找你(调用你)(好莱坞原则)
一个类只有一个引起它变化的原因(单一职责SRP原则)
18. null可以被强制转型为任意类型的对象
19.代码执行次序
多个静态成员变量, 静态代码块按顺序执行
单个类中: 静态代码 -> main方法 -> 构造块 -> 构造方法
构造块在每一次创建对象时执行
涉及父类和子类的初始化过程
a.初始化父类中的静态成员变量和静态代码块
b.初始化子类中的静态成员变量和静态代码块
c.初始化父类的普通成员变量和构造代码块(按次序),再执行父类的构造方法(注意父类构造方法中的子类方法覆盖)
d.初始化子类的普通成员变量和构造代码块(按次序),再执行子类的构造方法
20. 数组复制方法
for逐一复制
System.arraycopy() -> 效率最高native方法
Arrays.copyOf() -> 本质调用arraycopy
clone方法 -> 返回Object[],需要强制类型转换
21. 多态
Java通过方法重写和方法重载实现多态
方法重写是指子类重写了父类的同名方法
方法重载是指在同一个类中,方法的名字相同,但是参数列表不同
22. Java文件
.java文件可以包含多个类,唯一的限制就是:一个文件中只能有一个public类, 并且此public类必须与
文件名相同。而且这些类和写在多个文件中没有区别。
23. Java移位运算符
java中有三种移位运算符
<< :左移运算符,x << 1,相当于x乘以2(不溢出的情况下),低位补0
>> :带符号右移,x >> 1,相当于x除以2,正数高位补0,负数高位补1
>>> :无符号右移,忽略符号位,空位都以0补齐
参见我的GitHub,https://github.com/gao1741857805/Demo.git
24. 形参&实参
形式参数可被视为local variable.形参和局部变量一样都不能离开方法。只有在方法中使用,不会在方法外可见。
形式参数只能用final修饰符,其它任何修饰符都会引起编译器错误。但是用这个修饰符也有一定的限制,就是在方法中不能对参数做任何修改。不过一般情况下,一个方法的形参不用final修饰。只有在特殊情况下,那就是:方法内部类。一个方法内的内部类如果使用了这个方法的参数或者局部变量的话,这个参数或局部变量应该是final。
形参的值在调用时根据调用者更改,实参则用自身的值更改形参的值(指针、引用皆在此列),也就是说真正被传递的是实参。
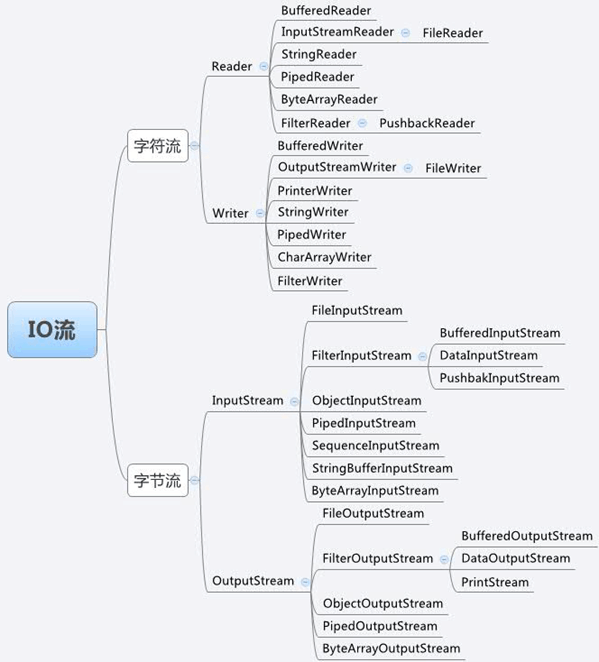
25. IO流一览
26. 局部变量为什么要初始化
局部变量是指类方法中的变量,必须初始化。局部变量运行时被分配在栈中,量大,生命周期短,如果虚拟机给每个局部变量都初始化一下,是一笔很大的开销,但变量不初始化为默认值就使用是不安全的。出于速度和安全性两个方面的综合考虑,解决方案就是虚拟机不初始化,但要求编写者一定要在使用前给变量赋值。
27. Java语言的鲁棒性
Java在编译和运行程序时,都要对可能出现的问题进行检查,以消除错误的产生。它提供自动垃圾收集来进行内存管理,防止程序员在管理内存时容易产生的错误。通过集成的面向对象的例外处理机制,在编译时,Java揭示出可能出现但未被处理的异常,帮助程序员正确地进行选择以防止系统的崩溃。另外,Java在编译时还可捕获类型声明中的许多常见错误,防止动态运行时不匹配问题的出现。
28. Java语言特性
Java致力于检查程序在编译和运行时的错误
Java虚拟机实现了跨平台接口
类型检查帮助检查出许多开发早期出现的错误
Java自己操纵内存减少了内存出错的可能性
Java还实现了真数组,避免了覆盖数据的可能
29. 包装类的equals()方法不处理数据转型,必须类型和值都一样才相等。
30. 子类可以继承父类的静态方法!但是不能覆盖。因为静态方法是在编译时确定了,不能多态,也就是不能运行时绑定。
31. Java语法糖
Java7的switch用字符串 - hashcode方法 switch用于enum枚举
伪泛型 - List原始类型
自动装箱拆箱 - Integer.valueOf和Integer.intValue
foreach遍历 - Iterator迭代器实现
条件编译
enum枚举类、内部类
可变参数 - 数组
断言语言
try语句中定义和关闭资源
32. Java 中应该使用什么数据类型来代表价格?
如果不是特别关心内存和性能的话,使用BigDecimal,否则使用预定义精度的 double 类型。
33. 怎么将 byte 转换为 String?
可以使用 String 接收 byte[] 参数的构造器来进行转换,需要注意的点是要使用的正确的编码,否则会使用平台默认编码,这个编码可能跟原来的编码相同,也可能不同。
34. Java 中怎样将 bytes 转换为 long 类型?
String接收bytes的构造器转成String,再Long.parseLong
35. 我们能将 int 强制转换为 byte 类型的变量吗?如果该值大于 byte 类型的范围,将会出现什么现象?
是的,我们可以做强制转换,但是 Java 中 int 是 32 位的,而 byte 是 8 位的,所以,如果强制转化是,int 类型的高 24 位将会被丢弃,byte 类型的范围是从 -128 到 127。
36. 存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为 C 么?如 C = © B;
可以,向下转型。但是不建议使用,容易出现类型转型异常.
37. 哪个类包含 clone 方法?是 Cloneable 还是 Object?
java.lang.Cloneable 是一个标示性接口,不包含任何方法,clone 方法在 object 类中定义。并且需要知道 clone() 方法是一个本地方法,这意味着它是由 c 或 c++ 或 其他本地语言实现的。
38. Java 中 ++ 操作符是线程安全的吗?
不是线程安全的操作。它涉及到多个指令,如读取变量值,增加,然后存储回内存,这个过程可能会出现多个线程交差。还会存在竞态条件(读取-修改-写入)。
39. a = a + b 与 a += b 的区别
+= 隐式的将加操作的结果类型强制转换为持有结果的类型。如果两这个整型相加,如 byte、short 或者 int,首先会将它们提升到 int 类型,然后在执行加法操作。
byte a = 127;
byte b = 127;
b = a + b; // error : cannot convert from int to byte
b += a; // ok
(因为 a+b 操作会将 a、b 提升为 int 类型,所以将 int 类型赋值给 byte 就会编译出错)
40. 我能在不进行强制转换的情况下将一个 double 值赋值给 long 类型的变量吗?
不行,你不能在没有强制类型转换的前提下将一个 double 值赋值给 long 类型的变量,因为 double 类型的范围比 long 类型更广,所以必须要进行强制转换。
41. 3*0.1 == 0.3 将会返回什么?true 还是 false?
false,因为有些浮点数不能完全精确的表示出来。
42. int 和 Integer 哪个会占用更多的内存?
Integer 对象会占用更多的内存。Integer 是一个对象,需要存储对象的元数据。但是 int 是一个原始类型的数据,所以占用的空间更少。
43. 为什么 Java 中的 String 是不可变的(Immutable)?
Java 中的 String 不可变是因为 Java 的设计者认为字符串使用非常频繁,将字符串设置为不可变可以允许多个客户端之间共享相同的字符串。更详细的内容参见答案。
44. 我们能在 Switch 中使用 String 吗?
从 Java 7 开始,我们可以在 switch case 中使用字符串,但这仅仅是一个语法糖。内部实现在 switch 中使用字符串的 hash code。
45. Java 中的构造器链是什么?
当你从一个构造器中调用另一个构造器,就是Java 中的构造器链。这种情况只在重载了类的构造器的时候才会出现。
46. 枚举类
JDK1.5出现 每个枚举值都需要调用一次构造函数
48. 什么是不可变对象(immutable object)?Java 中怎么创建一个不可变对象?
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer及其它包装类。
如何在Java中写出Immutable的类?
要写出这样的类,需要遵循以下几个原则:
1)immutable对象的状态在创建之后就不能发生改变,任何对它的改变都应该产生一个新的对象。
2)Immutable类的所有的属性都应该是final的。
3)对象必须被正确的创建,比如:对象引用在对象创建过程中不能泄露(leak)。
4)对象应该是final的,以此来限制子类继承父类,以避免子类改变了父类的immutable特性。
5)如果类中包含mutable类对象,那么返回给客户端的时候,返回该对象的一个拷贝,而不是该对象本身(该条可以归为第一条中的一个特例)
49. 我们能创建一个包含可变对象的不可变对象吗?
是的,我们是可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。最常见的例子就是对象中包含一个日期对象的引用。
50. List和Set
List 是一个有序集合,允许元素重复。它的某些实现可以提供基于下标值的常量访问时间,但是这不是 List 接口保证的。Set 是一个无序集合。
51. poll() 方法和 remove() 方法的区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
52. Java 中 LinkedHashMap 和 PriorityQueue 的区别是什么?
PriorityQueue 保证最高或者最低优先级的的元素总是在队列头部,但是 LinkedHashMap 维持的顺序是元素插入的顺序。当遍历一个 PriorityQueue 时,没有任何顺序保证,但是 LinkedHashMap 课保证遍历顺序是元素插入的顺序。
53. ArrayList 与 LinkedList 的区别?
最明显的区别是 ArrrayList 底层的数据结构是数组,支持随机访问,而 LinkedList 的底层数据结构书链表,不支持随机访问。使用下标访问一个元素,ArrayList 的时间复杂度是 O(1),而 LinkedList 是 O(n)。
54. 用哪两种方式来实现集合的排序?
你可以使用有序集合,如 TreeSet 或 TreeMap,你也可以使用有顺序的的集合,如 list,然后通过 Collections.sort() 来排序。
55. Java 中怎么打印数组?
你可以使用 Arrays.toString() 和 Arrays.deepToString() 方法来打印数组。由于数组没有实现 toString() 方法,所以如果将数组传递给 System.out.println() 方法,将无法打印出数组的内容,但是 Arrays.toString() 可以打印每个元素。
56. Java 中的 LinkedList 是单向链表还是双向链表?
是双向链表,你可以检查 JDK 的源码。在 Eclipse,你可以使用快捷键 Ctrl + T,直接在编辑器中打开该类。
57. Java 中的 TreeMap 是采用什么树实现的?
Java 中的 TreeMap 是使用红黑树实现的。
58. Java 中的 HashSet,内部是如何工作的?
HashSet 的内部采用 HashMap来实现。由于 Map 需要 key 和 value,所以所有 key 的都有一个默认 value。类似于 HashMap,HashSet 不允许重复的 key,只允许有一个null key,意思就是 HashSet 中只允许存储一个 null 对象。
59. 写一段代码在遍历 ArrayList 时移除一个元素?
该问题的关键在于面试者使用的是 ArrayList 的 remove() 还是 Iterator 的 remove()方法。这有一段示例代码,是使用正确的方式来实现在遍历的过程中移除元素,而不会出现 ConcurrentModificationException 异常的示例代码。
60. 我们能自己写一个容器类,然后使用 for-each 循环吗?
可以,你可以写一个自己的容器类。如果你想使用 Java 中增强的循环来遍历,你只需要实现 Iterable 接口。如果你实现 Collection 接口,默认就具有该属性。
61. ArrayList 和 HashMap 的默认大小是多数?
在 Java 7 中,ArrayList 的默认大小是 10 个元素,HashMap 的默认大小是16个元素(必须是2的幂)。这就是 Java 7 中 ArrayList 和 HashMap 类的代码片段:
// from ArrayList.java JDK 1.7
private static final int DEFAULT_CAPACITY = 10;
//from HashMap.java JDK 7
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
62. 有没有可能两个不相等的对象有有相同的 hashcode?
有可能,两个不相等的对象可能会有相同的 hashcode 值,这就是为什么在 hashmap 中会有冲突。相等 hashcode 值的规定只是说如果两个对象相等,必须有相同的hashcode 值,但是没有关于不相等对象的任何规定。
63. 两个相同的对象会有不同的的 hash code 吗?
不能,根据 hash code 的规定,这是不可能的。
64. 我们可以在 hashcode() 中使用随机数字吗?
不行,因为对象的 hashcode 值必须是相同的。
65. Java 中,Comparator 与 Comparable 有什么不同?
Comparable 接口用于定义对象的自然顺序,而 comparator 通常用于定义用户定制的顺序。Comparable 总是只有一个,但是可以有多个 comparator 来定义对象的顺序。
66. 为什么在重写 equals 方法的时候需要重写 hashCode 方法?
因为有强制的规范指定需要同时重写 hashcode 与 equal 是方法,许多容器类,如 HashMap、HashSet 都依赖于 hashcode 与 equals 的规定。
67. “a==b”和”a.equals(b)”有什么区别?
如果 a 和 b 都是对象,则 a==b 是比较两个对象的引用,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true,而 a.equals(b) 是进行逻辑比较,所以通常需要重写该方法来提供逻辑一致性的比较。例如,String 类重写 equals() 方法,所以可以用于两个不同对象,但是包含的字母相同的比较。
68. a.hashCode() 有什么用?与 a.equals(b) 有什么关系?
简介:hashCode() 方法是相应对象整型的 hash 值。它常用于基于 hash 的集合类,如 Hashtable、HashMap、LinkedHashMap等等。它与 equals() 方法关系特别紧密。根据 Java 规范,两个使用 equal() 方法来判断相等的对象,必须具有相同的 hash code。
1、hashcode的作用
List和Set,如何保证Set不重复呢?通过迭代使用equals方法来判断,数据量小还可以接受,数据量大怎么解决?引入hashcode,实际上hashcode扮演的角色就是寻址,大大减少查询匹配次数。
2、hashcode重要吗
对于数组、List集合就是一个累赘。而对于hashmap, hashset, hashtable就异常重要了。
3、equals方法遵循的原则
对称性 若x.equals(y)true,则y.equals(x)true
自反性 x.equals(x)必须true
传递性 若x.equals(y)true,y.equals(z)true,则x.equals(z)必为true
一致性 只要x,y内容不变,无论调用多少次结果不变
其他 x.equals(null) 永远false,x.equals(和x数据类型不同)始终false
两者的关系
69. final、finalize 和 finally 的不同之处?
final 是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不能被改变。Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的,但是什么时候调用 finalize 没有保证。finally 是一个关键字,与 try 和 catch 一起用于异常的处理。finally 块一定会被执行,无论在 try 块中是否有发生异常。
70. Java 中的编译期常量是什么?使用它又什么风险?
变量也就是我们所说的编译期常量,这里的 public 可选的。实际上这些变量在编译时会被替换掉,因为编译器知道这些变量的值,并且知道这些变量在运行时不能改变。这种方式存在的一个问题是你使用了一个内部的或第三方库中的公有编译时常量,但是这个值后面被其他人改变了,但是你的客户端仍然在使用老的值,甚至你已经部署了一个新的jar。为了避免这种情况,当你在更新依赖 JAR 文件时,确保重新编译你的程序。
71. 说出几点 Java 中使用 Collections 的最佳实践
这是我在使用 Java 中 Collectionc 类的一些最佳实践:
a)使用正确的集合类,例如,如果不需要同步列表,使用 ArrayList 而不是 Vector。
b)优先使用并发集合,而不是对集合进行同步。并发集合提供更好的可扩展性。
c)使用接口代表和访问集合,如使用List存储 ArrayList,使用 Map 存储 HashMap 等等。
d)使用迭代器来循环集合。
e)使用集合的时候使用泛型。
72. 静态内部类与顶级类有什么区别?
一个公共的顶级类的源文件名称与类名相同,而嵌套静态类没有这个要求。一个嵌套类位于顶级类内部,需要使用顶级类的名称来引用嵌套静态类,如 HashMap.Entry 是一个嵌套静态类,HashMap 是一个顶级类,Entry是一个嵌套静态类。
73. Java 中,Serializable 与 Externalizable 的区别?
Serializable 接口是一个序列化 Java 类的接口,以便于它们可以在网络上传输或者可以将它们的状态保存在磁盘上,是 JVM 内嵌的默认序列化方式,成本高、脆弱而且不安全。Externalizable 允许你控制整个序列化过程,指定特定的二进制格式,增加安全机制。
74. 说出 JDK 1.7 中的三个新特性?
虽然 JDK 1.7 不像 JDK 5 和 8 一样的大版本,但是,还是有很多新的特性,如 try-with-resource 语句,这样你在使用流或者资源的时候,就不需要手动关闭,Java 会自动关闭。Fork-Join 池某种程度上实现 Java 版的 Map-reduce。允许 Switch 中有 String 变量和文本。菱形操作符(<>)用于泛型推断,不再需要在变量声明的右边申明泛型,因此可以写出可读写更强、更简洁的代码。另一个值得一提的特性是改善异常处理,如允许在同一个 catch 块中捕获多个异常。
75. 说出 5 个 JDK 1.8 引入的新特性?
Java 8 在 Java 历史上是一个开创新的版本,下面 JDK 8 中 5 个主要的特性:
Lambda 表达式,允许像对象一样传递匿名函数
Stream API,充分利用现代多核 CPU,可以写出很简洁的代码
Date 与 Time API,最终,有一个稳定、简单的日期和时间库可供你使用
扩展方法,现在,接口中可以有静态、默认方法。
重复注解,现在你可以将相同的注解在同一类型上使用多次。
下述包含 Java 面试过程中关于 SOLID 的设计原则,OOP 基础,如类,对象,接口,继承,多态,封装,抽象以及更高级的一些概念,如组合、聚合及关联。也包含了 GOF 设计模式的问题。
76. 接口是什么?为什么要使用接口而不是直接使用具体类?
接口用于定义 API。它定义了类必须得遵循的规则。同时,它提供了一种抽象,因为客户端只使用接口,这样可以有多重实现,如 List 接口,你可以使用可随机访问的 ArrayList,也可以使用方便插入和删除的 LinkedList。接口中不允许普通方法,以此来保证抽象,但是 Java 8 中你可以在接口声明静态方法和默认普通方法。
- Java 中,抽象类与接口之间有什么不同?
Java 中,抽象类和接口有很多不同之处,但是最重要的一个是 Java 中限制一个类只能继承一个类,但是可以实现多个接口。抽象类可以很好的定义一个家族类的默认行为,而接口能更好的定义类型,有助于后面实现多态机制
参见第六条。
78. 除了单例模式,你在生产环境中还用过什么设计模式?
这需要根据你的经验来回答。一般情况下,你可以说依赖注入,工厂模式,装饰模式或者观察者模式,随意选择你使用过的一种即可。不过你要准备回答接下的基于你选择的模式的问题。
79. 你能解释一下里氏替换原则吗?
严格定义:如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象用o1替换o2时,程序P的行为没有变化,那么类型S是类型T的子类型。
通俗表述:所有引用基类(父类)的地方必须能透明地使用其子类的对象。也就是说子类可以扩展父类的功能,但不能改变父类原有的功能。它包含以下4层含义:
子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
子类中可以增加自己特有的方法。
当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
80.什么情况下会违反迪米特法则?为什么会有这个问题?
迪米特法则建议“只和朋友说话,不要陌生人说话”,以此来减少类之间的耦合。
81. 适配器模式是什么?什么时候使用?
适配器模式提供对接口的转换。如果你的客户端使用某些接口,但是你有另外一些接口,你就可以写一个适配去来连接这些接口。
82. 构造器注入和 setter 依赖注入,那种方式更好?
每种方式都有它的缺点和优点。构造器注入保证所有的注入都被初始化,但是 setter 注入提供更好的灵活性来设置可选依赖。如果使用 XML 来描述依赖,Setter 注入的可读写会更强。经验法则是强制依赖使用构造器注入,可选依赖使用 setter 注入。
83. 依赖注入和工厂模式之间有什么不同?
虽然两种模式都是将对象的创建从应用的逻辑中分离,但是依赖注入比工程模式更清晰。通过依赖注入,你的类就是 POJO,它只知道依赖而不关心它们怎么获取。使用工厂模式,你的类需要通过工厂来获取依赖。因此,使用 DI 会比使用工厂模式更容易测试。
84. 适配器模式和装饰器模式有什么区别?
虽然适配器模式和装饰器模式的结构类似,但是每种模式的出现意图不同。适配器模式被用于桥接两个接口,而装饰模式的目的是在不修改类的情况下给类增加新的功能。
85. 适配器模式和代理模式之前有什么不同?
这个问题与前面的类似,适配器模式和代理模式的区别在于他们的意图不同。由于适配器模式和代理模式都是封装真正执行动作的类,因此结构是一致的,但是适配器模式用于接口之间的转换,而代理模式则是增加一个额外的中间层,以便支持分配、控制或智能访问。
86. 什么是模板方法模式?
模板方法提供算法的框架,你可以自己去配置或定义步骤。例如,你可以将排序算法看做是一个模板。它定义了排序的步骤,但是具体的比较,可以使用 Comparable 或者其语言中类似东西,具体策略由你去配置。列出算法概要的方法就是众所周知的模板方法。
87. 什么时候使用访问者模式?
访问者模式用于解决在类的继承层次上增加操作,但是不直接与之关联。这种模式采用双派发的形式来增加中间层。
88. 什么时候使用组合模式?
组合模式使用树结构来展示部分与整体继承关系。它允许客户端采用统一的形式来对待单个对象和对象容器。当你想要展示对象这种部分与整体的继承关系时采用组合模式。
89. 继承和组合之间有什么不同?
虽然两种都可以实现代码复用,但是组合比继承共灵活,因为组合允许你在运行时选择不同的实现。用组合实现的代码也比继承测试起来更加简单。
90. 描述 Java 中的重载和重写?
重载和重写都允许你用相同的名称来实现不同的功能,但是重载是编译时活动,而重写是运行时活动。你可以在同一个类中重载方法,但是只能在子类中重写方法。重写必须要有继承。
91. OOP 中的 组合、聚合和关联有什么区别?
如果两个对象彼此有关系,就说他们是彼此相关联的。组合和聚合是面向对象中的两种形式的关联。组合是一种比聚合更强力的关联。组合中,一个对象是另一个的拥有者,而聚合则是指一个对象使用另一个对象。如果对象 A 是由对象 B 组合的,则 A 不存在的话,B一定不存在,但是如果 A 对象聚合了一个对象 B,则即使 A 不存在了,B 也可以单独存在。
92. 给我一个符合开闭原则的设计模式的例子?
开闭原则要求你的代码对扩展开放,对修改关闭。这个意思就是说,如果你想增加一个新的功能,你可以很容易的在不改变已测试过的代码的前提下增加新的代码。有好几个设计模式是基于开闭原则的,如策略模式,如果你需要一个新的策略,只需要实现接口,增加配置,不需要改变核心逻辑。一个正在工作的例子是 Collections.sort() 方法,这就是基于策略模式,遵循开闭原则的,你不需为新的对象修改 sort() 方法,你需要做的仅仅是实现你自己的 Comparator 接口。
93. 什么时候使用享元模式(蝇量模式)?
享元模式通过共享对象来避免创建太多的对象。为了使用享元模式,你需要确保你的对象是不可变的,这样你才能安全的共享。JDK 中 String 池、Integer 池以及 Long 池都是很好的使用了享元模式的例子。
94. Java 中如何格式化一个日期?如格式化为 ddMMyyyy 的形式?
Java 中,可以使用 SimpleDateFormat 类或者 joda-time 库来格式日期。DateFormat 类允许你使用多种流行的格式来格式化日期。
95. Java 中,怎么在格式化的日期中显示时区?
pattern中加z yyyy-MM-dd HH:mm:ss.SSS Z
- Java 中 java.util.Date 与 java.sql.Date 有什么区别?
java.sql.Date是针对SQL语句使用的,它只包含日期而没有时间部分,它们都有getTime方法返回毫秒数,自然就可以直接构建。java.util.Date 是 java.sql.Date 的父类,前者是常用的表示时间的类,我们通常格式化或者得到当前时间都是用他,后者之后在读写数据库的时候用他,因为PreparedStament的setDate()的第2参数和ResultSet的getDate()方法的第2个参数都是java.sql.Date。
97. Java 中,如何计算两个日期之间的差距?
public static int dateDiff(Date d1, Date d2) throws Exception {long n1 = d1.getTime();long n2 = d2.getTime();long diff = Math.abs(n1 - n2);diff /= 3600 * 1000 * 24;return diff;}
98. Java 中,如何将字符串 YYYYMMDD 转换为日期?
SimpleDateFormat的parse方法
99. 说出几条 Java 中方法重载的最佳实践?
下面有几条可以遵循的方法重载的最佳实践来避免造成自动装箱的混乱。
a)不要重载这样的方法:一个方法接收 int 参数,而另个方法接收 Integer 参数。
b)不要重载参数数量一致,而只是参数顺序不同的方法。
c)如果重载的方法参数个数多于 5 个,采用可变参数。
100. 说出 5 条 IO 的最佳实践
IO 对 Java 应用的性能非常重要。理想情况下,你应该在你应用的关键路径上避免 IO 操作。下面是一些你应该遵循的 Java IO 最佳实践:
a)使用有缓冲区的 IO 类,而不要单独读取字节或字符
b)使用 NIO 和 NIO2
c)在 finally 块中关闭流,或者使用 try-with-resource(Java7) 语句
d)使用内存映射文件获取更快的 IO
101. Object有哪些公用方法?
clone equals hashcode wait notify notifyall finalize toString getClass
除了clone和finalize其他均为公共方法。
11个方法,wait被重载了两次
102. equals与==的区别
区别1. ==是一个运算符 equals是Object类的方法
区别2. 比较时的区别
a. 用于基本类型的变量比较时:==用于比较值是否相等,equals不能直接用于基本数据类型的比较,需要转换为其对应的包装类型。
b. 用于引用类型的比较时。==和equals都是比较栈内存中的地址是否相等 。相等为true 否则为false。但是通常会重写equals方法去实现对象内容的比较。
103. String、StringBuffer与StringBuilder的区别
第一点:可变和适用范围。String对象是不可变的,而StringBuffer和StringBuilder是可变字符序列。每次对String的操作相当于生成一个新的String对象,而对StringBuffer和StringBuilder的操作是对对象本身的操作,而不会生成新的对象,所以对于频繁改变内容的字符串避免使用String,因为频繁的生成对象将会对系统性能产生影响。
第二点:线程安全。String由于有final修饰,是immutable的,安全性是简单而纯粹的。StringBuilder和StringBuffer的区别在于StringBuilder不保证同步,也就是说如果需要线程安全需要使用StringBuffer,不需要同步的StringBuilder效率更高。
104. switch能否用String做参数
Java1.7开始支持,但实际这是一颗Java语法糖。除此之外,byte,short,long,枚举,boolean均可用于switch,只有浮点型不可以。
105. 封装、继承、多态
封装:
1.概念:就是把对象的属性和操作(或服务)结合为一个独立的整体,并尽可能隐藏对象的内部实现细节。
2.好处:
(1)隐藏内部实现细节。
继承:
1.概念:继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力
2.好处:提高代码的复用,缩短开发周期。
多态:
1.概念:多态(Polymorphism)按字面的意思就是“多种状态,即同一个实体同时具有多种形式。一般表现形式是程序在运行的过程中,同一种类型在不同的条件下表现不同的结果。多态也称为动态绑定,一般是在运行时刻才能确定方法的具体执行对象。
2.好处:
1)将接口和实现分开,改善代码的组织结构和可读性,还能创建可拓展的程序。
2)消除类型之间的耦合关系。允许将多个类型视为同一个类型。
3)一个多态方法的调用允许有多种表现形式
106. Comparable和Comparator接口区别
Comparator位于包java.util下,而Comparable位于包java.lang下
如果我们需要使用Arrays或Collections的排序方法对对象进行排序时,我们需要在自定义类中实现Comparable接口并重写compareTo方法,compareTo方法接收一个参数,如果this对象比传递的参数小,相等或大时分别返回负整数、0、正整数。Comparable被用来提供对象的自然排序。String、Integer实现了该接口。
Comparator比较器的compare方法接收2个参数,根据参数的比较大小分别返回负整数、0和正整数。
Comparator 是一个外部的比较器,当这个对象自然排序不能满足你的要求时,你可以写一个比较器来完成两个对象之间大小的比较。用 Comparator 是策略模式(strategy design pattern),就是不改变对象自身,而用一个策略对象(strategy object)来改变它的行为。
107. 与Java集合框架相关的有哪些最好的实践
(1)根据需要选择正确的集合类型。比如,如果指定了大小,我们会选用Array而非ArrayList。如果我们想根据插入顺序遍历一个Map,我们需要使用TreeMap。如果我们不想重复,我们应该使用Set。
(2)一些集合类允许指定初始容量,所以如果我们能够估计到存储元素的数量,我们可以使用它,就避免了重新哈希或大小调整。
(3)基于接口编程,而非基于实现编程,它允许我们后来轻易地改变实现。
(4)总是使用类型安全的泛型,避免在运行时出现ClassCastException。
(5)使用JDK提供的不可变类作为Map的key,可以避免自己实现hashCode()和equals()。
108. IO和NIO简述
1、简述
在以前的Java IO中,都是阻塞式IO,NIO引入了非阻塞式IO。
第一种方式:我从硬盘读取数据,然后程序一直等,数据读完后,继续操作。这种方式是最简单的,叫阻塞IO。
第二种方式:我从硬盘读取数据,然后程序继续向下执行,等数据读取完后,通知当前程序(对硬件来说叫中断,对程序来说叫回调),然后此程序可以立即处理数据,也可以执行完当前操作在读取数据。
2.流与块的比较
原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。这样做是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
一个 面向块 的 I/O 系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
3.通道与流
Channel是一个对象,可以通过它读取和写入数据。通道与流功能类似,不同之处在于通道是双向的。而流只是在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类), 而通道可以用于读、写或者同时用于读写。
4.缓冲区Buffer
在 NIO 库中,所有数据都是用缓冲区处理的。在 NIO 库中,所有数据都是用缓冲区处理的。
Position: 表示下一次访问的缓冲区位置
Limit: 表示当前缓冲区存放的数据容量。
Capacity:表示缓冲区最大容量
flip()方法:读写模式切换
clear方法:它将 limit 设置为与 capacity 相同。它设置 position 为 0。
二、Java高级(JavaEE、框架、服务器、工具等)
1. Servlet
1.1 Servlet继承实现结构
Servlet (接口) —> init|service|destroy方法
GenericServlet(抽象类) —> 与协议无关的Servlet
HttpServlet(抽象类) —> 实现了http协议
自定义Servlet —> 重写doGet/doPost
1.2 编写Servlet的步骤
继承HttpServlet
重写doGet/doPost方法
在web.xml中注册servlet
1.3 Servlet生命周期
init:仅执行一次,负责装载servlet时初始化servlet对象
service:核心方法,一般get/post两种方式
destroy:停止并卸载servlet,释放资源
1.4 过程
客户端request请求 -> 服务器检查Servlet实例是否存在 -> 若存在调用相应service方法
客户端request请求 -> 服务器检查Servlet实例是否存在 -> 若不存在装载Servlet类并创建实例 -> 调用init初始化 -> 调用service
加载和实例化、初始化、处理请求、服务结束
1.5 doPost方法要抛出的异常:
ServletExcception、IOException
1.6 Servlet容器装载Servlet
web.xml中配置load-on-startup启动时装载
客户首次向Servlet发送请求
Servlet类文件被更新后, 重新装载Servlet
1.7 HttpServlet容器响应web客户请求流程
Web客户向servlet容器发出http请求
servlet容器解析Web客户的http请求
servlet容器创建一个HttpRequest对象, 封装http请求信息
servlet容器创建一个HttpResponse对象
servlet容器调用HttpServlet的service方法, 把HttpRequest和HttpResponse对象作为service方法的参数传给HttpServlet对象
HttpServlet调用httprequest的有关方法, 获取http请求信息
httpservlet调用httpresponse的有关方法, 生成响应数据
Servlet容器把HttpServlet的响应结果传给web客户
1.8 HttpServletRequest完成的一些功能
request.getCookie()
request.getHeader(String s)
request.getContextPath()
request.getSession()
HttpSession session = request.getSession(boolean create)
返回当前请求的会话
1.9 HttpServletResponse完成一些的功能
设http响应头
设置Cookie
输出返回数据
1.10 Servlet与JSP九大内置对象的关系
JSP对象 怎样获得
- out -> response.getWriter
2. request -> Service方法中的req参数
3. response -> Service方法中的resp参数
4. session -> request.getSession
5. application -> getServletContext
6. exception -> Throwable
7. page -> this
8. pageContext -> PageContext
9. Config -> getServletConfig
exception是JSP九大内置对象之一,其实例代表其他页面的异常和错误。只有当页面是错误处理页面时,即isErroePage为 true时,该对象才可以使用。
2. JSP
JSP的前身就是Servlet
3. Tomcat
3.1 Tomcat容器的等级
Tomcat - Container - Engine - Host - Servlet - 多个Context(一个Context对应一个web工程)-Wrapper
4. struts
struts可进行文件上传
struts基于MVC模式
struts让流程结构更清晰
struts有许多action类, 会增加类文件数目
5. Hibernate的7大鼓励措施
尽量使用many-to-one, 避免使用单项one-to-many
灵活使用单项one-to-many
不用一对一, 使用多对一代替一对一
配置对象缓存, 不使用集合对象
一对多使用bag, 多对一使用set
继承使用显示多态
消除大表, 使用二级缓存
6. Hibernate延迟加载
Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
Hibernate3 提供了属性的延迟加载功能
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。
7. Java 中,DOM 和 SAX 解析器有什么不同?
DOM 解析器将整个 XML 文档加载到内存来创建一棵 DOM 模型树,这样可以更快的查找节点和修改 XML 结构,而 SAX 解析器是一个基于事件的解析器,不会将整个 XML 文档加载到内存。由于这个原因,DOM 比 SAX 更快,也要求更多的内存,但不适合于解析大的 XML 文件。
8. Java 中,Maven 和 ANT 有什么区别?
虽然两者都是构建工具,都用于创建 Java 应用,但是 Maven 做的事情更多,在基于“约定优于配置”的概念下,提供标准的Java 项目结构,同时能为应用自动管理依赖(应用中所依赖的 JAR 文件)。
9. 解析XML不同方式对比
DOM、SAX、JDOM、DOM4J
DOM DOM树驻留内存
可以进行修改和写入,耗费内存。
步骤:创建DocumentBuilderFactory对象 -> 创建DocumentBuilder对象 -> Document document = db.parse(“xml”)
SAX 事件驱动模式
获取一个SAXParserFactory工厂的实例 -> 根据该实例获取SAXParser -> 创建Handler对象 -> 调用SAXParser的parse方法解析
用于读取节点数据 不易编码 事件有顺序 很难同时访问xml的多处数据
JDOM
创建一个SAXBuilder的对象 -> 创建一个输入流,加载xml文件 ->通过saxBuilder的build方法将输入流加载至saxBuilder并接收Document对象
使用具体类而不使用接口
DOM4J
通过SAXReader的read方法加载xml文件并获取document对象
使用接口和抽象类,灵活性好,功能强大
10. Nginx相关
请参https://www.runoob.com/linux/nginx-install-setup.html
11. XML与JSON对比和区别
XML
1)应用广泛,可扩展性强,被广泛应用各种场合
2)读取、解析没有JSON快
3)可读性强,可描述复杂结构
1
2
3
JSON
1)结构简单,都是键值对
2)读取、解析速度快,很多语言支持
3)传输数据量小,传输速率大大提高
4)描述复杂结构能力较弱
JavaScript、PHP等原生支持,简化了读取解析。成为当前互联网时代普遍应用的数据结构。
三、多线程和并发
- Java 中的 volatile 变量是什么
Java 语言提供了一种稍弱的同步机制,即volatile变量。但是volatile并不容易完全被正确、完整的理解。
一般来说,volatile具备2条语义,或者说2个特性。第一是保证volatile修饰的变量对所有线程的可见性,这里的可见性是指当一条线程修改了该变量,新值对于其它线程来说是立即可以得知的。而普通变量做不到这一点。
第二条语义是禁止指令重排序优化,这条语义在JDK1.5才被修复。
关于第一点:根据JMM,所有的变量存储在主内存,而每个线程还有自己的工作内存,线程的工作内存保存该线程使用到的变量的主内存副本拷贝,线程对变量的操作在工作内存中进行,不能直接读写主内存的变量。在volatile可见性这一点上,普通变量做不到的原因正因如此。比如,线程A修改了一个普通变量的值,然后向主内存进行回写,线程B在线程A回写完成后再从主内存读取,新变量才能对线程B可见。其实,按照虚拟机规范,volatile变量依然有工作内存的拷贝,要借助主内存来实现可见性。但由于volatile的特殊规则保证了新值能立即同步回主内存,以及每次使用从主内存刷新,以此保证了多线程操作volatile变量的可见性。
关于第二点:先说指令重排序,指令重排序是指CPU采用了允许将多条指令不按规定顺序分开发送给相应的处理单元处理,但并不是说任意重排,CPU需要正确处理指令依赖情况确保最终的正确结果,指令重排序是机器级的优化操作。那么为什么volatile要禁止指令重排序呢,又是如何去做的。举例,DCL(双重检查加锁)的单例模式。volatile修饰后,代码中将会插入许多内存屏障指令保证处理器不发生乱序执行。同时由于Happens-before规则的保证,在刚才的例子中写操作会发生在后续的读操作之前。
除了以上2点,volatile还保证对于64位long和double的读取是原子性的。因为在JMM中允许虚拟机对未被volatile修饰的64位的long和double读写操作分为2次32位的操作来执行,这也就是所谓的long和double的非原子性协定。
基于以上几点,我们知道volatile虽然有这些语义和特性在并发的情况下仍然不能保证线程安全。大部分情况下仍然需要加锁。
除非是以下2种情况,1.运算结果不依赖变量的当前值,或者能够确保只有单一线程修改变量的值;2.变量不需要与其他的状态变量共同参与不变约束。
- volatile简述
Java 语言提供了一种稍弱的同步机制,即volatile变量.用来确保将变量的更新操作通知到其他线程,保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。 当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的。volatile修饰变量,每次被线程访问时强迫其从主内存重读该值,修改后再写回。保证读取的可见性,对其他线程立即可见。volatile的另一个语义是禁止指令重排序优化。但是volatile并不保证原子性,也就不能保证线程安全。
- Java 中能创建 volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组。我的意思是,如果改变引用指向的数组,将会受到 volatile 的保护,但是如果多个线程同时改变数组的元素,volatile 就不能起到之前的保护作用了。
- volatile 能使得一个非原子操作变成原子操作吗?
一个典型的例子是在类中有一个 long 类型的成员变量。如果你知道该成员变量会被多个线程访问,如计数器、价格等,你最好是将其设置为 volatile。为什么?因为 Java 中读取 long 类型变量不是原子的,需要分成两步,如果一个线程正在修改该 long 变量的值,另一个线程可能只能看到该值的一半(前 32 位)。但是对一个 volatile 型的 long 或 double 变量的读写是原子。
volatile 禁止指令重排序的底层原理
指令重排序,是指CPU允许多条指令不按程序规定的顺序分开发送给相应电路单元处理。但并不是说任意重排,CPU需要能正确处理指令依赖情况以正确的执行结果。volatile禁止指令重排序是通过内存屏障实现的,指令重排序不能把后面的指令重排序到内存屏障之前。由内存屏障保证一致性。注:该条语义在JDK1.5才得以修复,这点也是JDK1.5之前无法通过双重检查加锁来实现单例模式的原因。volatile 类型变量提供什么保证?
volatile 变量提供有序性和可见性保证,例如,JVM 或者 JIT为了获得更好的性能会对语句重排序,但是 volatile 类型变量即使在没有同步块的情况下赋值也不会与其他语句重排序。 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。某些情况下,volatile 还能提供原子性,如读 64 位数据类型,像 long 和 double 都不是原子的,但 volatile 类型的 double 和 long 就是原子的。
volatile的使用场景:
运算结果不依赖变量的当前值,或者能够确保只有单一的线程修改该值
变量不需要与其他状态变量共同参与不变约束
- volatile的性能
volatile变量的读操作性能消耗和普通变量差不多,但是写操作可能相对慢一些,因为它需要在本地代码中插入许多内存屏障指令以确保处理器不发生乱序执行。大多数情况下,volatile总开销比锁低,但我们要注意volatile的语义能否满足使用场景。
- 10 个线程和 2 个线程的同步代码,哪个更容易写?
从写代码的角度来说,两者的复杂度是相同的,因为同步代码与线程数量是相互独立的。但是同步策略的选择依赖于线程的数量,因为越多的线程意味着更大的竞争,所以你需要利用同步技术,如锁分离,这要求更复杂的代码和专业知识。
- 你是如何调用 wait()方法的?使用 if 块还是循环?为什么?
wait() 方法应该在循环调用,因为当线程获取到 CPU 开始执行的时候,其他条件可能还没有满足,所以在处理前,循环检测条件是否满足会更好。下面是一段标准的使用 wait 和 notify 方法的代码:
// The standard idiom for using the wait method
synchronized (obj) {
while (condition does not hold)
obj.wait(); // (Releases lock, and reacquires on wakeup)
… // Perform action appropriate to condition
}
1
2
3
4
5
6
7
参见 Effective Java 第 69 条,获取更多关于为什么应该在循环中来调用 wait 方法的内容。
- 什么是多线程环境下的伪共享(false sharing)?
伪共享是多线程系统(每个处理器有自己的局部缓存)中一个众所周知的性能问题。伪共享发生在不同处理器的上的线程对变量的修改依赖于相同的缓存行,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wSHFkwHb-1596373001450)(http://jbcdn2.b0.upaiyun.com/2015/11/2bccd7f52a70db95aa72524ef3a55164.gif)]
伪共享问题很难被发现,因为线程可能访问完全不同的全局变量,内存中却碰巧在很相近的位置上。如其他诸多的并发问题,避免伪共享的最基本方式是仔细审查代码,根据缓存行来调整你的数据结构。
- 线程的run方法和start方法
run方法
只是thread类的一个普通方法,若直接调用程序中依然只有主线程这一个线程,还要顺序执行,依然要等待run方法体执行完毕才可执行下面的代码。
start方法
用start方法来启动线程,是真正实现了多线程。调用thread类的start方法来启动一个线程,此时线程处于就绪状态,一旦得到cpu时间片,就开始执行run方法。
- ReadWriteLock(读写锁)
写写互斥 读写互斥 读读并发, 在读多写少的情况下可以提高效率
resume(继续挂起的线程)和suspend(挂起线程)一起用
wait与notify、notifyall一起用
sleep与wait的异同点
sleep是Thread类的静态方法, wait来自object类
sleep方法短暂停顿不释放锁, wait方法条件等待要释放锁,因为只有这样,其他等待的线程才能在满足条件时获取到该锁。
wait, notify, notifyall必须在同步代码块中使用, sleep可以在任何地方使用
都可以抛出InterruptedException
15. 让一个线程停止执行
异常 - 停止执行
休眠 - 停止执行
阻塞 - 停止执行
- ThreadLocal简介
16.1 ThreadLocal解决了变量并发访问的冲突问题
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,每个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本,是线程隔离的。线程隔离的秘密在于ThreadLocalMap类(ThreadLocal的静态内部类)
16.2 与synchronized同步机制的比较
首先,它们都是为了解决多线程中相同变量访问冲突问题。不过,在同步机制中,要通过对象的锁机制保证同一时间只有一个线程访问该变量。该变量是线程共享的, 使用同步机制要求程序缜密地分析什么时候对该变量读写, 什么时候需要锁定某个对象, 什么时候释放对象锁等复杂的问题,程序设计编写难度较大, 是一种“以时间换空间”的方式。
而ThreadLocal采用了以“以空间换时间”的方式。
- 线程局部变量原理
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,每个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本,是线程隔离的。线程隔离的秘密在于ThreadLocalMap类(ThreadLocal的静态内部类)
线程局部变量是局限于线程内部的变量,属于线程自身所有,不在多个线程间共享。Java 提供 ThreadLocal 类来支持线程局部变量,是一种实现线程安全的方式。但是在管理环境下(如 web 服务器)使用线程局部变量的时候要特别小心,在这种情况下,工作线程的生命周期比任何应用变量的生命周期都要长。任何线程局部变量一旦在工作完成后没有释放,Java 应用就存在内存泄露的风险。
ThreadLocal的方法:void set(T value)、T get()以及T initialValue()。
ThreadLocal是如何为每个线程创建变量的副本的:
首先,在每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的,键值为当前ThreadLocal变量,value为变量副本(即T类型的变量)。初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。
总结:
实际的通过ThreadLocal创建的副本是存储在每个线程自己的threadLocals中的
为何threadLocals的类型ThreadLocalMap的键值为ThreadLocal对象,因为每个线程中可有多个threadLocal变量,就像上面代码中的longLocal和stringLocal;
在进行get之前,必须先set,否则会报空指针异常;如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法
- JDK提供的用于并发编程的同步器
Semaphore Java并发库的Semaphore可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。
CyclicBarrier 主要的方法就是一个:await()。await()方法每被调用一次,计数便会减少1,并阻塞住当前线程。当计数减至0时,阻塞解除,所有在此CyclicBarrier上面阻塞的线程开始运行。
CountDownLatch 直译过来就是倒计数(CountDown)门闩(Latch)。倒计数不用说,门闩的意思顾名思义就是阻止前进。在这里就是指 CountDownLatch.await() 方法在倒计数为0之前会阻塞当前线程。
19. 什么是 Busy spin?我们为什么要使用它?
Busy spin 是一种在不释放 CPU 的基础上等待事件的技术。它经常用于避免丢失 CPU 缓存中的数据(如果线程先暂停,之后在其他CPU上运行就会丢失)。所以,如果你的工作要求低延迟,并且你的线程目前没有任何顺序,这样你就可以通过循环检测队列中的新消息来代替调用 sleep() 或 wait() 方法。它唯一的好处就是你只需等待很短的时间,如几微秒或几纳秒。LMAX 分布式框架是一个高性能线程间通信的库,该库有一个 BusySpinWaitStrategy 类就是基于这个概念实现的,使用 busy spin 循环 EventProcessors 等待屏障。
- Java 中怎么获取一份线程 dump 文件?
在 Linux 下,你可以通过命令 kill -3 PID (Java 进程的进程 ID)来获取 Java 应用的 dump 文件。在 Windows 下,你可以按下 Ctrl + Break 来获取。这样 JVM 就会将线程的 dump 文件打印到标准输出或错误文件中,它可能打印在控制台或者日志文件中,具体位置依赖应用的配置。
- Swing 是线程安全的?
不是,Swing 不是线程安全的。你不能通过任何线程来更新 Swing 组件,如 JTable、JList 或 JPanel,事实上,它们只能通过 GUI 或 AWT 线程来更新。这就是为什么 Swing 提供 invokeAndWait() 和 invokeLater() 方法来获取其他线程的 GUI 更新请求。这些方法将更新请求放入 AWT 的线程队列中,可以一直等待,也可以通过异步更新直接返回结果。
- 用 wait-notify 写一段代码来解决生产者-消费者问题?
记住在同步块中调用 wait() 和 notify()方法,如果阻塞,通过循环来测试等待条件。
- 用 Java 写一个线程安全的单例模式(Singleton)?
当我们说线程安全时,意思是即使初始化是在多线程环境中,仍然能保证单个实例。Java 中,使用枚举作为单例类是最简单的方式来创建线程安全单例模式的方式。参见我整理的单例的文章6种单例模式的实现以及double check的剖析
- Java 中,编写多线程程序的时候你会遵循哪些最佳实践?
这是我在写Java 并发程序的时候遵循的一些最佳实践:
a)给线程命名,这样可以帮助调试。
b)最小化同步的范围,而不是将整个方法同步,只对关键部分做同步。
c)如果可以,更偏向于使用 volatile 而不是 synchronized。
d)使用更高层次的并发工具,而不是使用 wait() 和 notify() 来实现线程间通信,如 BlockingQueue,CountDownLatch 及 Semeaphore。
e)优先使用并发集合,而不是对集合进行同步。并发集合提供更好的可扩展性。
- 说出至少 5 点在 Java 中使用线程的最佳实践。
这个问题与之前的问题类似,你可以使用上面的答案。对线程来说,你应该:
a)对线程命名
b)将线程和任务分离,使用线程池执行器来执行 Runnable 或 Callable。
c)使用线程池
- 在多线程环境下,SimpleDateFormat 是线程安全的吗?
不是,非常不幸,DateFormat 的所有实现,包括 SimpleDateFormat 都不是线程安全的,因此你不应该在多线程序中使用,除非是在对外线程安全的环境中使用,如将 SimpleDateFormat 限制在 ThreadLocal 中。如果你不这么做,在解析或者格式化日期的时候,可能会获取到一个不正确的结果。因此,从日期、时间处理的所有实践来说,我强力推荐 joda-time 库。
- Happens-Before规则
程序次序规则
按控制流顺序先后发生
管程锁定规则
一个unlock操作先行发生于后面对同一个锁的lock操作
volatile变量规则
对一个volatile变量的写操作先行发生于后面对这个变量的读操作
线程启动规则
start方法先行发生于线程的每一个动作
线程中断规则
对线程的interrupt方法调用先行发生于被中断线程的代码检测到中断时间的发生
线程终止规则
线程内的所有操作都先行发生于对此线程的终止检测
对象终结规则
一个对象的初始化完成先行发生于它的finalize方法的开始
传递性
如果A先行发生于操作B,B先行发生于操作C,则A先行发生于操作C
- 什么是线程
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。程序员可以通过它进行多处理器编程,可以使用多线程对运算密集型任务提速。比如,如果一个线程完成一个任务要100 毫秒,那么用十个线程完成改任务只需 10 毫秒。Java在语言层面对多线程提供了很好的支持。
- 线程和进程有什么区别
从概念上:
进程:一个程序对一个数据集的动态执行过程,是分配资源的基本单位。
线程:存在于进程内,是进程内的基本调度单位。共享进程的资源。
从执行过程中来看:
进程:拥有独立的内存单元,而多个线程共享内存,从而提高了应用程序的运行效率。
线程:每一个独立的线程,都有一个程序运行的入口、顺序执行序列、和程序的出口。但是线程不能够独立的执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
从逻辑角度来看:(重要区别)
多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但是,操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理及资源分配。
简言之,一个程序至少有一个进程,一个进程至少有一个线程。进程是资源分配的基本单位,线程共享进程的资源。
- 用 Runnable 还是 Thread
Java 不支持类的多重继承,但允许你调用多个接口。所以如果你要继承其他类,当然是实现Runnable接口好了。
- Java 中 Runnable 和 Callable 有什么不同
Runnable和 Callable 都代表那些要在不同的线程中执行的任务。Runnable 从 JDK1.0 开始就有了,Callable 是在 JDK1.5 增加的。它们的主要区别是 Callable 的 call () 方法可以返回值和抛出异常,而 Runnable 的 run ()方法没有这些功能。
- Java 中 CyclicBarrier 和 CountDownLatch 有什么不同
它们都是JUC下的类,CyclicBarrier 和 CountDownLatch 都可以用来让一组线程等待其它线程。区别在于CountdownLatch计数无法被重置。如果需要重置计数,请考虑使用 CyclicBarrier。
- Java 内存模型是什么
Java 内存模型规定和指引Java 程序在不同的内存架构、CPU 和操作系统间有确定性地行为。它在多线程的情况下尤其重要。Java内存模型对一个线程所做的变动能被其它线程可见提供了保证,它们之间是先行发生关系。这个关系定义了一些规则让程序员在并发编程时思路更清晰。
线程内的代码能够按先后顺序执行,这被称为程序次序规则。
对于同一个锁,一个解锁操作一定要发生在时间上后发生的另一个锁定操作之前,也叫做管程锁定规则。
前一个对volatile的写操作在后一个volatile的读操作之前,也叫volatile变量规则。
一个线程内的任何操作必需在这个线程的 start ()调用之后,也叫作线程启动规则。
一个线程的所有操作都会在线程终止之前,线程终止规则。
一个对象的终结操作必需在这个对象构造完成之后,也叫对象终结规则。
a先行于b,b先行于c,传递性
- 什么是线程安全?Vector 是一个线程安全类吗
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。一个线程安全的计数器类的同一个实例对象在被多个线程使用的情况下也不会出现计算失误。很显然你可以将集合类分成两组,线程安全和非线程安全的。Vector 是用同步方法来实现线程安全的,而和它相似的 ArrayList 不是线程安全的。
- Java 中什么是竞态条件? 举个例子说明。
竞态条件会导致程序在并发情况下出现一些 bugs。多线程对一些资源的竞争的时候就会产生竞态条件,如果首先要执行的程序竞争失败排到后面执行了,那么整个程序就会出现一些不确定的 bugs。这种 bugs 很难发现而且会重复出现,因为线程间的随机竞争。几类竞态条件check-and-act、读取-修改-写入、put-if-absent。
- Java 中如何停止一个线程
当 run () 或者 call () 方法执行完的时候线程会自动结束,如果要手动结束一个线程,你可以用 volatile 布尔变量来退出 run ()方法的循环或者是取消任务来中断线程。其他情形:异常 - 停止执行 休眠 - 停止执行 阻塞 - 停止执行
- 一个线程运行时发生异常会怎样
简单的说,如果异常没有被捕获该线程将会停止执行。Thread.UncaughtExceptionHandler 是用于处理未捕获异常造成线程突然中断情况的一个内嵌接口。当一个未捕获异常将造成线程中断的时候 JVM 会使用 Thread.getUncaughtExceptionHandler ()来查询线程的 UncaughtExceptionHandler 并将线程和异常作为参数传递给 handler 的 uncaughtException ()方法进行处理。
- 如何在两个线程间共享数据?
通过共享对象来实现这个目的,或者是使用像阻塞队列这样并发的数据结构
- Java 中 notify 和 notifyAll 有什么区别
notify ()方法不能唤醒某个具体的线程,所以只有一个线程在等待的时候它才有用武之地。而 notifyAll ()唤醒所有线程并允许他们争夺锁确保了至少有一个线程能继续运行。
- 为什么 wait, notify 和 notifyAll 这些方法不在 thread 类里面
一个很明显的原因是 JAVA 提供的锁是对象级的而不是线程级的。如果线程需要等待某些锁那么调用对象中的 wait ()方法就有意义了。如果 wait ()方法定义在 Thread 类中,线程正在等待的是哪个锁就不明显了。简单的说,由于 wait,notify 和 notifyAll 都是锁级别的操作,所以把他们定义在 Object 类中因为锁属于对象。
- 什么是 FutureTask?
在 Java 并发程序中 FutureTask 表示一个可以取消的异步运算。它有启动和取消运算、查询运算是否完成和取回运算结果等方法。只有当运算完成的时候结果才能取回,如果运算尚未完成 get 方法将会阻塞。一个 FutureTask 对象可以对调用了 Callable 和 Runnable 的对象进行包装,由于 FutureTask 也是调用了 Runnable 接口所以它可以提交给 Executor 来执行。
- Java 中 interrupted 和 isInterruptedd 方法的区别
interrupted是静态方法,isInterruptedd是一个普通方法
如果当前线程被中断(没有抛出中断异常,否则中断状态就会被清除),你调用interrupted方法,第一次会返回true。然后,当前线程的中断状态被方法内部清除了。第二次调用时就会返回false。如果你刚开始一直调用isInterrupted,则会一直返回true,除非中间线程的中断状态被其他操作清除了。也就是说isInterrupted 只是简单的查询中断状态,不会对状态进行修改。
- 为什么 wait 和 notify 方法要在同步块中调用
如果不这么做,代码会抛出 IllegalMonitorStateException异常。还有一个原因是为了避免 wait 和 notify 之间产生竞态条件。
- 为什么你应该在循环中检查等待条件?
处于等待状态的线程可能会收到错误警报和伪唤醒,如果不在循环中检查等待条件,程序就会在没有满足结束条件的情况下退出。因此,当一个等待线程醒来时,不能认为它原来的等待状态仍然是有效的,在 notify 方法调用之后和等待线程醒来之前这段时间它可能会改变。这就是在循环中使用 wait 方法效果更好的原因。
- Java 中的同步集合与并发集合有什么区别
同步集合与并发集合都为多线程和并发提供了合适的线程安全的集合,不过并发集合的可扩展性更高。在 Java1.5 之前程序员们只有同步集合来用且在多线程并发的时候会导致争用,阻碍了系统的扩展性。Java1.5加入了并发集合像 ConcurrentHashMap,不仅提供线程安全还用锁分离和内部分区等现代技术提高了可扩展性。它们大部分位于JUC包下。
- 什么是线程池? 为什么要使用它?
创建线程要花费昂贵的资源和时间,如果任务来了才创建线程那么响应时间会变长,而且一个进程能创建的线程数有限。为了避免这些问题,在程序启动的时候就创建若干线程来响应处理,它们被称为线程池,里面的线程叫工作线程。从 JDK1.5 开始,Java API 提供了 Executor 框架让你可以创建不同的线程池。比如单线程池,每次处理一个任务;数目固定的线程池或者是缓存线程池(一个适合很多生存期短的任务的程序的可扩展线程池)。
- 如何写代码来解决生产者消费者问题?
在现实中你解决的许多线程问题都属于生产者消费者模型,就是一个线程生产任务供其它线程进行消费,你必须知道怎么进行线程间通信来解决这个问题。比较低级的办法是用 wait 和 notify 来解决这个问题,比较赞的办法是用 Semaphore 或者 BlockingQueue 来实现生产者消费者模型。
48.如何避免死锁?
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。这是一个严重的问题,因为死锁会让你的程序挂起无法完成任务,死锁的发生必须满足以下四个条件:
互斥条件:一个资源每次只能被一个进程使用。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
避免死锁最简单的方法就是阻止循环等待条件,将系统中所有的资源设置标志位、排序,规定所有的进程申请资源必须以一定的顺序(升序或降序)做操作来避免死锁。
- Java 中活锁和死锁有什么区别?
活锁和死锁类似,不同之处在于处于活锁的线程或进程的状态是不断改变的,活锁可以认为是一种特殊的饥饿。一个现实的活锁例子是两个人在狭小的走廊碰到,两个人都试着避让对方好让彼此通过,但是因为避让的方向都一样导致最后谁都不能通过走廊。简单的说就是,活锁和死锁的主要区别是前者进程的状态可以改变但是却不能继续执行。
- 怎么检测一个线程是否拥有锁
在 java.lang.Thread 中有一个方法叫 holdsLock,当且仅当当前线程拥有某个具体对象的锁时它返回true。
- 你如何在 Java 中获取线程堆栈
在 Linux 下,你可以通过命令 kill -3 PID (Java 进程的进程 ID)来获取 Java 应用的 dump 文件。在 Windows 下,你可以按下 Ctrl + Break 来获取。这样 JVM 就会将线程的 dump 文件打印到标准输出或错误文件中,它可能打印在控制台或者日志文件中,具体位置依赖应用的配置。
52.Java 中 synchronized 和 ReentrantLock 有什么不同
Java 在过去很长一段时间只能通过 synchronized 关键字来实现互斥,它有一些缺点。比如你不能扩展锁之外的方法或者块边界,尝试获取锁时不能中途取消等。Java 5 通过 Lock 接口提供了更复杂的控制来解决这些问题。 ReentrantLock 类实现了 Lock,它拥有与 synchronized 相同的并发性和内存语义且它还具有可扩展性。
53.有三个线程 T1,T2,T3,怎么确保它们按顺序执行
可以用线程类的 join ()方法。具体操作是在T3的run方法中调用t2.join(),让t2执行完再执行t3;T2的run方法中调用t1.join(),让t1执行完再执行t2。这样就按T1,T2,T3的顺序执行了
54.Thread 类中的 yield 方法有什么作用
Yield 方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃 CPU 占用而不能保证使其它线程一定能占用 CPU,执行 yield的线程有可能在进入到暂停状态后马上又被执行。
55.Java 中 ConcurrentHashMap 的并发度是什么
ConcurrentHashMap 把实际 map 划分成若干部分来实现它的可扩展性和线程安全。这种划分是使用并发度获得的,它是 ConcurrentHashMap 类构造函数的一个可选参数,默认值为 16,这样在多线程情况下就能避免争用。
56.Java 中 Semaphore是什么
JUC下的一种新的同步类,它是一个计数信号。从概念上讲,Semaphore信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire,然后再获取该许可。每个 release添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。信号量常常用于多线程的代码中,比如数据库连接池。
57.如果你提交任务时,线程池队列已满。会发会生什么?
这个问题问得很狡猾,许多程序员会认为该任务会阻塞直到线程池队列有空位。事实上如果一个任务不能被调度执行那么 ThreadPoolExecutor’s submit ()方法将会抛出一个 RejectedExecutionException 异常。
58.Java 线程池中 submit () 和 execute ()方法有什么区别
两个方法都可以向线程池提交任务,execute ()方法的返回类型是 void,它定义在 Executor 接口中, 而 submit ()方法可以返回持有计算结果的 Future 对象,它定义在 ExecutorService 接口中,它扩展了 Executor 接口,其它线程池类像 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 都有这些方法。
59.什么是阻塞式方法?
阻塞式方法是指程序会一直等待该方法完成期间不做其他事情,ServerSocket 的 accept ()方法就是一直等待客户端连接。这里的阻塞是指调用结果返回之前,当前线程会被挂起,直到得到结果之后才会返回。此外,还有异步和非阻塞式方法在任务完成前就返回。
60.Swing 是线程安全的吗?
你可以很肯定的给出回答,Swing 不是线程安全的。你不能通过任何线程来更新 Swing 组件,如 JTable、JList 或 JPanel,事实上,它们只能通过 GUI 或 AWT 线程来更新。这就是为什么 Swing 提供 invokeAndWait() 和 invokeLater() 方法来获取其他线程的 GUI 更新请求。这些方法将更新请求放入 AWT 的线程队列中,可以一直等待,也可以通过异步更新直接返回结果。
61.Java 中 invokeAndWait 和 invokeLater 有什么区别
这两个方法是 Swing API 提供给 Java 开发者用来从当前线程而不是事件派发线程更新 GUI 组件用的。InvokeAndWait ()同步更新 GUI 组件,比如一个进度条,一旦进度更新了,进度条也要做出相应改变。如果进度被多个线程跟踪,那么就调用 invokeAndWait ()方法请求事件派发线程对组件进行相应更新。而 invokeLater ()方法是异步调用更新组件的。
62.Swing API 中那些方法是线程安全的?
虽然Swing不是线程安全的但是有一些方法是可以被多线程安全调用的。如repaint (), revalidate ()。 JTextComponent 的 setText ()方法和 JTextArea 的 insert () 和 append () 方法也是线程安全的。
63.如何在 Java 中创建 Immutable 对象
Immutable 对象可以在没有同步的情况下共享,降低了对该对象进行并发访问时的同步化开销。可是 Java 没有@Immutable 这个注解符,要创建不可变类,要实现下面几个步骤:通过构造方法初始化所有成员、对变量不要提供 setter 方法、将所有的成员声明为私有的,这样就不允许直接访问这些成员、在 getter 方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝。
64.Java 中的 ReadWriteLock 是什么?
一般而言,读写锁是用来提升并发程序性能的锁分离技术的成果。Java 中的 ReadWriteLock 是 Java 5 中新增的一个接口,一个 ReadWriteLock 维护一对关联的锁,一个用于只读操作一个用于写。在没有写线程的情况下一个读锁可能会同时被多个读线程持有。写锁是独占的,你可以使用 JDK 中的 ReentrantReadWriteLock 来实现这个规则,它最多支持 65535 个写锁和 65535 个读锁。
65.多线程中的忙循环是什么?
忙循环就是程序员用循环让一个线程等待,不像传统方法 wait (), sleep () 或 yield () 它们都放弃了 CPU 控制,而忙循环不会放弃 CPU,它就是在运行一个空循环。这么做的目的是为了保留 CPU 缓存,在多核系统中,一个等待线程醒来的时候可能会在另一个内核运行,这样会重建缓存。为了避免重建缓存和减少等待重建的时间就可以使用它了。
66.volatile 变量和 atomic 变量有什么不同
volatile 变量和 atomic 变量看起来很像,但功能却不一样。volatile 变量可以确保先行关系,即写操作会发生在后续的读操作之前, 但它并不能保证原子性。例如用 volatile 修饰 count 变量那么 count++ 操作并不是原子性的。而 AtomicInteger 类提供的 atomic 方法可以让这种操作具有原子性如 getAndIncrement ()方法会原子性的进行增量操作把当前值加一,其它数据类型和引用变量也可以进行相似操作。
67.如果同步块内的线程抛出异常会发生什么?
无论你的同步块是正常还是异常退出的,里面的线程都会释放锁,所以对比锁接口我更喜欢同步块,因为它不用我花费精力去释放锁,该功能可以在 finally block 里释放锁实现。
68.如何在 Java 中创建线程安全的 Singleton
5种,急加载,同步方法,双检锁,静态内部类,枚举
69.如何强制启动一个线程?
这个问题就像是如何强制进行 Java 垃圾回收,目前还没有觉得方法,虽然你可以使用 System.gc ()来进行垃圾回收,但是不保证能成功。在 Java 里面没有办法强制启动一个线程,它是被线程调度器控制着且 Java 没有公布相关的 API。
70.Java 中的 fork join 框架是什么?
fork join 框架是 JDK7 中出现的一款高效的工具,Java 开发人员可以通过它充分利用现代服务器上的多处理器。它是专门为了那些可以递归划分成许多子模块设计的,目的是将所有可用的处理能力用来提升程序的性能。fork join 框架一个巨大的优势是它使用了工作窃取算法,可以完成更多任务的工作线程可以从其它线程中窃取任务来执行。
71.Java 多线程中调用 wait () 和 sleep ()方法有什么不同?
Java 程序中 wait 和 sleep 都会造成某种形式的暂停,它们可以满足不同的需要。wait ()方法意味着条件等待,如果等待条件为真且其它线程被唤醒时它会释放锁,而 sleep ()方法仅仅释放 CPU 资源或者让当前线程短暂停顿,但不会释放锁。
72.可重入锁
可重入锁:如果当前线程已经获得了某个监视器对象所持有的锁,那么该线程在该方法中调用另外一个同步方法也同样持有该锁。
public synchrnozied void test() {
xxxxxx;
test2();
}
public synchronized void test2() {
yyyyy;
}
在上面代码段中,执行 test 方法需要获得当前对象作为监视器的对象锁,但方法中又调用了 test2 的同步方法。
如果锁是具有可重入性的话,那么该线程在调用 test2 时并不需要再次获得当前对象的锁,可以直接进入 test2 方法进行操作。
如果锁是不具有可重入性的话,那么该线程在调用test2前会等待当前对象锁的释放,实际上该对象锁已被当前线程所持有,不可能再次获得。
如果锁是不具有可重入性特点的话,那么线程在调用同步方法、含有锁的方法时就会产生死锁。
- 同步方法和同步代码块
同步方法默认用this或者当前类class对象作为锁;
同步代码块可以选择以什么来加锁,比同步方法要更细颗粒度,我们可以选择只同步会发生同步问题的部分代码而不是整个方法。
四、Java虚拟机
- 对哪些区域回收
Java运行时数据区域:程序计数器、JVM栈、本地方法栈、方法区和堆。
由于程序计数器、JVM栈、本地方法栈3个区域随线程而生随线程而灭,对这几个区域内存的回收和分配具有确定性。而方法区和堆则不一样,程序需要在运行时才知道创建哪些对象,对这部分内存的分配是动态的,GC关注的也就是这部分内存。
- 主动GC
调用system.gc() Runtime.getRuntime.gc()
- 垃圾回收
释放那些不在持有任何引用的对象的内存
- 怎样判断是否需要收集
引用计数法:对象没有任何引用与之关联(无法解决循环引用)
ext:Python使用引用计数法
可达性分析法:通过一组称为GC Root的对象为起点,从这些节点向下搜索,如果某对象不能从这些根对象的一个(至少一个)所到达,则判定该对象应当回收。
ext:可作为GCRoot的对象:虚拟机栈中引用的对象。方法区中类静态属性引用的对象,方法区中类常量引用的对象,本地方法栈中JNI引用的对象
4.对象的自我救赎
即使在可达性算法中判定为不可达时,也并非一定被回收。对象存在自我救赎的可能。要真正宣告对象的死亡,需要经历2次标记的过程。如果对象经过可达性分析法发现不可达时,对象将被第一次标记被进行筛选,筛选的条件是此对象是否有必要执行finalize方法。如果对象没有重写finalize方法或finalize方法已经被JVM调用过,则判定为不需要执行。
如果对象被判定为需要执行finalize方法,该对象将被放置在一个叫做F-Queue的队列中,JVM会建立一个低优先级的线程执行finalize方法,如果对象想要完成自我救赎需要在finalize方法中与引用链上的对象关联,比如把自己也就是this赋值给某个类变量。当GC第二次对F-Queue中对象标记时,该对象将被移出“即将回收”的集合,完成自我救赎。简言之,finalize方法是对象逃脱死亡命运的最后机会,并且任何对象的finalize方法只会被JVM调用一次。
5.垃圾回收算法
Mark-Sweep法:标记清除法 容易产生内存碎片,导致分配较大对象时没有足够的连续内存空间而提前出发GC。这里涉及到另一个问题,即对象创建时的内存分配,对象创建内存分配主要有2种方法,分别是指针碰撞法和空闲列表法。指针碰撞法:使用的内存在一侧,空闲的在另一侧,中间使用一个指针作为分界点指示器,对象内存分配时只要指针向空闲的移动对象大小的距离即可。
空闲列表法:使用的和空闲的内存相互交错无法进行指针碰撞,JVM必须维护一个列表记录哪些内存块可用,分配时从列表中找出一个足够的分配给对象,并更新列表记录。所以,当采用Mark-Sweep算法的垃圾回收器时,内存分配通常采用空闲列表法。
Copy法:将内存分为2块,每次使用其中的一块,当一块满了,将存活的对象复制到另一块,把使用过的那一块一次性清除。显然,Copy法解决了内存碎片的问题,但算法的代价是内存缩小为原来的一半。现代的垃圾收集器对新生代采用的正是Copy算法。但通常不执行1:1的策略,HotSpot虚拟机默认Eden区Survivor区8:1。每次使用Eden和其中一块Survivor区。也就是说新生代可用内存为新生代内存空间的90%。
Mark-Compact法:标记整理法。它的第一阶段与Mark-Sweep法一样,但不直接清除,而是将存活对象向一端移动,然后清除端边界以外的内存,这样也不存在内存碎片。
分代收集算法:将堆内存划分为新生代,老年代,根据新生代老年代的特点选取不同的收集算法。因为新生代对象大多朝生夕死,而老年代对象存活率高,没有额外空间进行分配担保,通常对新生代执行复制算法,老年代执行Mark-Sweep算法或Mark-Compact算法。
6.垃圾收集器
通常来说,新生代老年代使用不同的垃圾收集器。新生代的垃圾收集器有Serial(单线程)、ParNew(Serial的多线程版本)、ParallelScavenge(吞吐量优先的垃圾收集器),老年代有SerialOld(单线程老年代)、ParallelOld(与ParallelScavenge搭配的多线程执行标记整理算法的老年代收集器)、CMS(标记清除算法,容易产生内存碎片,可以开启内存整理的参数),以及当前最先进的垃圾收集器G1,G1通常面向服务器端的垃圾收集器,在我自己的Java应用程序中通过-XX:+PrintGCDetails,发现自己的垃圾收集器是使用了ParallelScavenge + ParallelOld的组合。
- 不同垃圾回收算法对比
标记清除法(Mark-Sweeping):易产生内存碎片
复制回收法(Copying):为了解决Mark-Sweep法而提出,内存空间减至一半
标记压缩法(Mark-Compact):为了解决Copying法的缺陷,标记后移动到一端再清除
分代回收法(GenerationalCollection):新生代对象存活周期短,需要大量回收对象,需要复制的少,执行copy算法;老年代对象存活周期相对长,回收少量对象,执行mark-compact算法.新生代划分:较大的eden区 和 2个survivor区
8. 内存分配
新生代的三部分 |Eden Space|From Space|To Space|,对象主要分配在新生代的Eden区
大对象直接进入老年代
大对象比如大数组直接进入老年代,可通过虚拟机参数-XX:PretenureSizeThreshold参数设置
长期存活的对象进入老年代
ext:虚拟机为每个对象定义一个年龄计数器,如果对象在Eden区出生并经过一次MinorGC仍然存活,将其移入Survivor的To区,GC完成标记互换后,相当于存活的对象进入From区,对象年龄加1,当增加到默认15岁时,晋升老年代。可通过-XX:MaxTenuringThreshold设置
GC的过程:GC开始前,对象只存在于Eden区和From区,To区逻辑上始终为空。对象分配在Eden区,Eden区空间不足,发起MinorGC,将Eden区所有存活的对象复制到To区,From区存活的对象根据年龄判断去向,若到达年龄阈值移入老年代,否则也移入To区,GC完成后Eden区和From区被清空,From区和To区标记互换。对象每在Survivor区躲过一次MinorGC年龄加一。MinorGC将重复这样的过程,直到To区被填满,To区满了以后,将把所有对象移入老年代。
动态对象年龄判定 suvivor区相同年龄对象总和大于suvivor区空间的一半,年龄大于等于该值的对象直接进入老年代
空间分配担保 在MinorGC开始前,虚拟机检查老年代最大可用连续空间是否大于新生代所有对象总空间,如果成立,MinorGC可以确保是安全的。否则,虚拟机会查看HandlePromotionFailure设置值是否允许担保失败,如果允许,继续查看老年代最大可用连续空间是否大于历次晋升到老年代对象的平均大小,如果大于则尝试MinorGC,尽管这次MinorGC是有风险的。如果小于,或者HandlerPromotionFailure设置不允许,则要改为FullGC。
新生代的回收称为MinorGC,对老年代的回收成为MajorGC又名FullGC
- 关于GC的虚拟机参数
GC相关
-XX:NewSize和-XX:MaxNewSize 新生代大小
-XX:SurvivorRatio Eden和其中一个survivor的比值
-XX:PretenureSizeThreshold 大对象进入老年代的阈值
-XX:MaxTenuringThreshold 晋升老年代的对象年龄
收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
堆大小设置
-Xmx:最大堆大小
-Xms:初始堆大小(最小内存值)
-Xmn:年轻代大小
-XXSurvivorRatio:3 意思是Eden:Survivor=3:2
-Xss栈容量
垃圾回收统计信息
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
- 方法区的回收
方法区通常会与永久代划等号,实际上二者并不等价,只不过是HotSpot虚拟机设计者用永久代实现方法区,并将GC分代扩展至方法区。
永久代垃圾回收通常包括两部分内容:废弃常量和无用的类。常量的回收与堆区对象的回收类似,当没有其他地方引用该字面量时,如果有必要,将被清理出常量池。
判定无用的类的3个条件:
1.该类的所有实例都已经被回收,也就是说堆中不存在该类的任何实例
2.加载该类的ClassLoader已经被回收
3.该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
当然,这也仅仅是判定,不代表立即卸载该类。
- JVM工具
命令行
jps(jvm processor status)虚拟机进程状况工具
jstat(jvm statistics monitoring)统计信息监视
jinfo(configuration info for java)配置信息工具
jmap(memory map for java)Java内存映射工具
jhat(JVM Heap Analysis Tool)虚拟机堆转储快照分析工具
jstack(Stack Trace for Java)Java堆栈跟踪工具
HSDIS:JIT生成代码反汇编
可视化
JConsole(Java Monitoring and Management Console):Java监视与管理控制台
VisualVM(All-in-one Java Troubleshooting Tool):多合一故障处理工具
12. JVM内存结构
堆:新生代和年老代
方法区(非堆):持久代, 代码缓存, 线程共享
JVM栈:中间结果,局部变量,线程隔离
本地栈:本地方法(非Java代码)
程序计数器 :线程私有,每个线程都有自己独立的程序计数器,用来指示下一条指令的地址
注:持久代Java8消失, 取代的称为元空间(本地堆内存的一部分)
13. JVM的方法区
与堆一样,是线程共享的区域。方法区中存储:被虚拟机加载的类信息,常量,静态变量,JIT编译后的代码等数据。参见我是一个Java Class。
- Java类加载器
一个jvm中默认的classloader有Bootstrap ClassLoader、Extension ClassLoader、App ClassLoader,分别各司其职:
Bootstrap ClassLoader(引导类加载器) 负责加载java基础类,主要是 %JRE_HOME/lib/目录下的rt.jar、resources.jar、charsets.jar等
Extension ClassLoader(扩展类加载器) 负责加载java扩展类,主要是 %JRE_HOME/lib/ext目录下的jar等
App ClassLoader(系统类加载器) 负责加载当前java应用的classpath中的所有类。
classloader 加载类用的是全盘负责委托机制。 所谓全盘负责,即是当一个classloader加载一个Class的时候,这个Class所依赖的和引用的所有 Class也由这个classloader负责载入,除非是显式的使用另外一个classloader载入。
所以,当我们自定义的classloader加载成功了com.company.MyClass以后,MyClass里所有依赖的class都由这个classLoader来加载完成。
15. 64 位 JVM 中,int 的长度是多大?
Java 中,int 类型变量的长度是一个固定值,与平台无关,都是 32 位。意思就是说,在 32 位 和 64 位 的Java 虚拟机中,int 类型的长度是相同的。
- Serial 与 Parallel GC之间的不同之处?
Serial 与 Parallel 在GC执行的时候都会引起 stop-the-world。它们之间主要不同 serial 收集器是默认的复制收集器,执行 GC 的时候只有一个线程,而 parallel 收集器使用多个 GC 线程来执行。
17.Java 中 WeakReference 与 SoftReference的区别?
Java中一共有四种类型的引用。StrongReference、 SoftReference、 WeakReference 以及 PhantomReference。
StrongReference:Java 的默认引用实现, 它会尽可能长时间的存活于 JVM 内,当没有任何对象指向它时将会被GC回收
SoftReference:尽可能长时间保留引用,直到JVM内存不足,适合某些缓存应用
WeakReference:顾名思义, 是一个弱引用, 当所引用的对象在 JVM 内不再有强引用时, 下一次将被GC回收
PhantomReference:它是最弱的一种引用关系,也无法通过PhantomReference取得对象的实例。仅用来当该对象被回收时收到一个通知
虽然 WeakReference 与 SoftReference 都有利于提高 GC 和 内存的效率,但是 WeakReference ,一旦失去最后一个强引用,就会被 GC 回收,而 SoftReference 会尽可能长的保留引用直到 JVM 内存不足时才会被回收(虚拟机保证), 这一特性使得 SoftReference 非常适合缓存应用。
- WeakHashMap 是怎么工作的?
WeakHashMap 的工作与正常的 HashMap 类似,但是使用弱引用作为 key,意思就是当 key 对象没有任何引用时,key/value 将会被回收。
- JVM 选项 -XX:+UseCompressedOops 有什么作用?为什么要使用?
当你将你的应用从 32 位的 JVM 迁移到 64 位的 JVM 时,由于对象的指针从 32 位增加到了 64 位,因此堆内存会突然增加,差不多要翻倍。这也会对 CPU 缓存(容量比内存小很多)的数据产生不利的影响。因为,迁移到 64 位的 JVM 主要动机在于可以指定最大堆大小,通过压缩 OOP 可以节省一定的内存。通过 -XX:+UseCompressedOops 选项,JVM 会使用 32 位的 OOP,而不是 64 位的 OOP。
- 怎样通过 Java 程序来判断 JVM 是 32 位 还是 64 位?
你可以检查某些系统属性如 sun.arch.data.model 或 os.arch 来获取该信息。
- 32 位 JVM 和 64 位 JVM 的最大堆内存分别是多数?
理论上说上 32 位的 JVM 堆内存可以到达 2^32,即 4GB,但实际上会比这个小很多。不同操作系统之间不同,如 Windows 系统大约 1.5 GB,Solaris 大约 3GB。64 位 JVM允许指定最大的堆内存,理论上可以达到 2^64,这是一个非常大的数字,实际上你可以指定堆内存大小到 100GB。甚至有的 JVM,如 Azul,堆内存到 1000G 都是可能的。
- JRE、JDK、JVM 及 JIT 之间有什么不同?
JRE 代表 Java 运行时(Java run-time),是运行 Java 应用所必须的。JDK 代表 Java 开发工具(Java development kit),是 Java 程序的开发工具,如 Java 编译器,它也包含 JRE。JVM 代表 Java 虚拟机(Java virtual machine),它的责任是运行 Java 应用。JIT 代表即时编译(Just In Time compilation),当代码执行的次数超过一定的阈值时,会将 Java 字节码转换为本地代码,如,主要的热点代码会被准换为本地代码,这样有利大幅度提高 Java 应用的性能。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AOOeicFo-1596373001454)(http://jbcdn2.b0.upaiyun.com/2015/11/4468a2440b48658c08acc50f15c3985b.jpg)]
- 解释 Java 堆空间及 GC?
当通过 Java 命令启动 Java 进程的时候,会为它分配内存。内存的一部分用于创建堆空间,当程序中创建对象的时候,就从对空间中分配内存。GC 是 JVM 内部的一个后台进程,回收无效对象的内存用于将来的分配。
- 你能保证 GC 执行吗?
不能,虽然你可以调用 System.gc() 或者 Runtime.getRuntime().gc(),但是没有办法保证 GC 的执行。
- 怎么获取 Java 程序使用的内存?堆使用的百分比?
可以通过 java.lang.Runtime 类中与内存相关方法来获取剩余的内存,总内存及最大堆内存。通过这些方法你也可以获取到堆使用的百分比及堆内存的剩余空间。Runtime.freeMemory() 方法返回剩余空间的字节数,Runtime.totalMemory() 方法总内存的字节数,Runtime.maxMemory() 返回最大内存的字节数。
- Java 中堆和栈有什么区别?
JVM 中堆和栈属于不同的内存区域,使用目的也不同。栈常用于保存方法帧和局部变量,而对象总是在堆上分配。栈通常都比堆小,也不会在多个线程之间共享,而堆被整个 JVM 的所有线程共享。
- JVM调优
使用工具Jconsol、VisualVM、JProfiler等
堆信息查看
可查看堆空间大小分配(年轻代、年老代、持久代分配)
提供即时的垃圾回收功能
垃圾监控(长时间监控回收情况)
查看堆内类、对象信息查看:数量、类型等
对象引用情况查看
有了堆信息查看方面的功能,我们一般可以顺利解决以下问题:
年老代年轻代大小划分是否合理
内存泄漏
垃圾回收算法设置是否合理
线程监控
线程信息监控:系统线程数量。
线程状态监控:各个线程都处在什么样的状态下
Dump线程详细信息:查看线程内部运行情况
死锁检查
热点分析
CPU热点:检查系统哪些方法占用的大量CPU时间
内存热点:检查哪些对象在系统中数量最大(一定时间内存活对象和销毁对象一起统计)
快照
系统两个不同运行时刻,对象(或类、线程等)的不同
举例说,我要检查系统进行垃圾回收以后,是否还有该收回的对象被遗漏下来的了。那么,我可以在进行垃圾回收前后,分别进行一次堆情况的快照,然后对比两次快照的对象情况。
内存泄漏检查
年老代堆空间被占满
持久代被占满
堆栈溢出
线程堆栈满
系统内存被占满
- Java中有内存泄漏吗?
内存泄露的定义: 当某些对象不再被应用程序所使用,但是由于仍然被引用而导致垃圾收集器不能释放。
内存泄漏的原因:对象的生命周期不同。比如说对象A引用了对象B. A的生命周期比B的要长得多,当对象B在应用程序中不会再被使用以后, 对象 A 仍然持有着B的引用. (根据虚拟机规范)在这种情况下GC不能将B从内存中释放。这种情况很可能会引起内存问题,倘若A还持有着其他对象的引用,那么这些被引用的(无用)对象也不会被回收,并占用着内存空间。甚至有可能B也持有一大堆其他对象的引用。这些对象由于被B所引用,也不会被垃圾收集器所回收,所有这些无用的对象将消耗大量宝贵的内存空间。并可能导致内存泄漏。
怎样防止:
1、当心集合类, 比如HashMap, ArrayList等,因为这是最容易发生内存泄露的地方.当集合对象被声明为static时,他们的生命周期一般和整个应用程序一样长。
- OOM解决办法
内存溢出的空间:Permanent Generation和Heap Space,也就是永久代和堆区
1、永久代的OOM
解决办法有2种:
a.通过虚拟机参数-XX:PermSize和-XX:MaxPermSize调整永久代大小
b.清理程序中的重复的Jar文件,减少类的重复加载
2、堆区的溢出
发生这种问题的原因是java虚拟机创建的对象太多,在进行垃圾回收之间,虚拟机分配的到堆内存空间已经用满了,与Heap Space的size有关。解决这类问题有两种思路:
检查程序,看是否存在死循环或不必要地重复创建大量对象,定位原因,修改程序和算法。
通过虚拟机参数-Xms和-Xmx设置初始堆和最大堆的大小
- DirectMemory直接内存
直接内存并不是Java虚拟机规范定义的内存区域的一部分,但是这部分内存也被频繁使用,而且也可能导致OOM异常的出现。
JDK1.4引入了NIO,这是一种基于通道和缓冲区的非阻塞IO模式,它可以使用Native函数库分配直接堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作,使得在某些场合显著提高性能,因为它避免了在Java堆和本地堆之间来回复制数据。
- Java 中堆和栈有什么不同
每个线程都有自己的栈内存,用于存储本地变量,方法参数和栈调用,一个线程中存储的变量对其它线程是不可见的。而堆是所有线程共享的一片公用内存区域。对象都在堆里创建,为了提升效率线程会从堆中弄一个缓存到自己的栈,如果多个线程使用该变量就可能引发问题,这时 volatile 变量就可以发挥作用了,它要求线程从主存中读取变量的值。
- 双亲委派模型中的方法
findLoadedClass(),LoadClass(),findBootstrapClassOrNull(),findClass(),resolveClass()
- IO模型
一般来说 I/O 模型可以分为:同步阻塞,同步非阻塞,异步阻塞,异步非阻塞 四种IO模型
同步阻塞 IO :
在此种方式下,用户进程在发起一个 IO 操作以后,必须等待 IO 操作的完成,只有当真正完成了 IO 操作以后,用户进程才能运行。 JAVA传统的 IO 模型属于此种方式!
同步非阻塞 IO:
在此种方式下,用户进程发起一个 IO 操作以后可返回做其它事情,但是用户进程需要时不时的询问 IO 操作是否就绪,这就要求用户进程不停的去询问,从而引入不必要的 CPU 资源浪费。其中目前 JAVA 的 NIO 就属于同步非阻塞 IO 。
异步阻塞 IO :
此种方式下是指应用发起一个 IO 操作以后,不等待内核 IO 操作的完成,等内核完成 IO 操作以后会通知应用程序,这其实就是同步和异步最关键的区别,同步必须等待或者主动的去询问 IO 是否完成,那么为什么说是阻塞的呢?因为此时是通过 select 系统调用来完成的,而 select 函数本身的实现方式是阻塞的,而采用 select 函数有个好处就是它可以同时监听多个文件句柄,从而提高系统的并发性!
异步非阻塞 IO:
在此种模式下,用户进程只需要发起一个 IO 操作然后立即返回,等 IO 操作真正的完成以后,应用程序会得到 IO 操作完成的通知,此时用户进程只需要对数据进行处理就好了,不需要进行实际的 IO 读写操作,因为 真正的 IO读取或者写入操作已经由 内核完成了。目前 Java7的AIO正是此种类型。
BIO即同步阻塞IO,适用于连接数目较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4之前的唯一选择,但程序直观、简单、易理解。
NIO即同步非阻塞IO,适用于连接数目多且连接比较短的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持。
AIO即异步非阻塞IO,适用于连接数目多且连接比较长的架构,如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK1.7开始支持
- 类加载器按照层次,从顶层到底层,分别加载哪些类?
启动类加载器:负责将存放在JAVA_HOME/lib下的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用。
扩展类加载器:这个加载器负责加载JAVA_HOME/lib/ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器
应用程序类加载器:这个加载器是ClassLoader中getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(Classpath)上所指定的类库,可直接使用这个加载器,如果应用程序没有自定义自己的类加载器,一般情况下这个就是程序中默认的类加载器
实现自己的加载器
只需要继承ClassLoader,并覆盖findClass方法。
在调用loadClass方法时,会先根据委派模型在父加载器中加载,如果加载失败,则会调用自己的findClass方法来完成加载
五、数据库(Sql、MySQL、Redis等)
- Statement
1.1 基本内容
Statement是最基本的用法, 不传参, 采用字符串拼接,存在注入漏洞
PreparedStatement传入参数化的sql语句, 同时检查合法性, 效率高可以重用, 防止sql注入
CallableStatement接口扩展PreparedStatement,用来调用存储过程
BatchedStatement用于批量操作数据库,BatchedStatement不是标准的Statement类
public interface CallableStatement extends PreparedStatement
public interface PreparedStatement extends Statement
1
2
1.2 Statement与PrepareStatement的区别
创建时的区别
Statement statement = conn.createStatement();
PreparedStatement preStatement = conn.prepareStatement(sql);
1
2
执行的时候
ResultSet rSet = statement.executeQuery(sql);
ResultSet pSet = preStatement.executeQuery();
1
2
由上可以看出,PreparedStatement有预编译的过程,已经绑定sql,之后无论执行多少遍,都不会再去进行编译,而 statement 不同,如果执行多遍,则相应的就要编译多少遍sql,所以从这点看,preStatement 的效率会比 Statement要高一些
安全性
PreparedStatement是预编译的,所以可以有效的防止SQL注入等问题
代码的可读性和可维护性
PreparedStatement更胜一筹
游标
列出 5 个应该遵循的 JDBC 最佳实践
有很多的最佳实践,你可以根据你的喜好来例举。下面是一些更通用的原则:
a)使用批量的操作来插入和更新数据
b)使用 PreparedStatement 来避免 SQL 异常,并提高性能
c)使用数据库连接池
d)通过列名来获取结果集,不要使用列的下标来获取
- 数据库索引的实现
数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
B树:
一棵m阶B树(balanced tree of order m)是一棵平衡的m路搜索树。它或者是空树,或者是满足下列性质的树:
1、根结点至少有两个子女;
2、每个非根节点所包含的关键字个数 j 满足:┌m/2┐ - 1 <= j <= m - 1;
3、除根结点以外的所有结点(不包括叶子结点)的度数正好是关键字总数加1,故内部子树个数 k 满足:┌m/2┐ <= k <= m ;
4、所有的叶子结点都位于同一层。
由于B-Tree的特性,在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。
一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
B+树:
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
B+树是B树的变形,它把所有的data都放在叶子结点中,只将关键字和子女指针保存于内结点,内结点完全是索引的功能。
与B-Tree相比,B+Tree有以下不同点:
1、每个节点的指针上限为2d而不是2d+1。
2、内节点不存储data,只存储key;叶子节点存储data不存储指针。
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针
例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
为什么B树(B+树)?
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
这涉及到磁盘存取原理、局部性原理和磁盘预读。
先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
至于B+Tree为什么更适合外存索引,原因和内节点出度d有关。
由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。
六、算法与数据结构
二叉搜索树:(Binary Search Tree又名:二叉查找树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉搜索树。
RBT红黑树
二叉搜索树:(Binary Search Tree又名:二叉查找树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉搜索树。
红黑树是一棵二叉搜索树,它在每个结点上增加一个存储位来表示结点的颜色,可以是RED或BLACK。通过对任何一条从根到叶子的简单路径上各个结点的颜色进行约束,红黑树没有一条路径会比其他路径长出2倍,所以红黑树是近似平衡的,使得红黑树的查找、插入、删除等操作的时间复杂度最坏为O(log n),但需要注意到在红黑树上执行插入或删除后将不在满足红黑树性质,恢复红黑树的属性需要少量(O(log
n))的颜色变更(实际是非常快速的)和不超过三次树旋转(对于插入操作是两次)。虽然插入和删除很复杂,但操作时间仍可以保持为 O(log n) 次。具体如何保证?引出红黑树的5个性质。
红黑树的5个性质:满足以下五个性质的二叉搜索树
每个结点或是红色的或是黑色的
根结点是黑色的
每个叶结点是黑色的
如果一个结点是红色的,则它的两个子结点是黑色的
对于每个结点,从该结点到其后代叶结点的简单路径上,均包含相同数目的黑色结点
插入操作:
由于性质的约束,插入的结点都是红色的。插入时性质1、3始终保持。破坏性质2当且仅当当前插入结点为根节点。变一下颜色即可。如果是破坏性质4或5,则需要旋转和变色来继续满足红黑树的性质。下面说一说插入的几种情况,约定当前插入结点为N,其父结点为P,叔叔为U,祖父为G
情形1:树空,直接插入违反性质1,将红色改黑。
情形2:N的父结点为黑,不必修改,直接插入
从情形3开始的情形假定N结点的父结点P为红色,所以存在G,并且G为黑色。且N存在一个叔叔结点U,尽管U可能为叶结点。
情形3:P为红,U为红(G结点一定存在且为黑)这里不论P是G的左孩子还是右孩子;不论N是P的左孩子还是右孩子。
首先把P、U改黑,G改红,并以G作为一个新插入的红结点重新进行各种情况的检查,若一路检索至根节点还未结束,则将根结点变黑。
情形4:P为红,U为黑或不存在(G结点一定存在且为黑),且P为G的左孩子,N为P的左孩子(或者P为G的右孩子,N为P的右孩子,保证同向的)。
P、G右旋并将P、G变相反色。因为P取代之前黑G的位置,所以P变黑可以理解,而G变红是为了不违反性质5。
情形5:P为红,U为黑或不存在,且P为G的左孩子,N为P的右孩子(或P为G的右孩子,N为P的左孩子,保证是反向的),对N,P进行一次左旋转换为情形4
删除操作比插入复杂一些,但最多不超过三次旋转可以让红黑树恢复平衡。
其他
黑高从某个结点x出发(不含x)到达一个叶结点的任意一条简单路径上的黑色结点个数称为该结点的黑高。红黑树的黑高为其根结点的黑高。
一个具有n个内部结点的红黑树的高度h<=2lg(n+1)
结点的属性(五元组):color key left right p
动态集合操作最坏时间复杂度为O(lgn)
3. 排序算法
稳定排序:插入排序、冒泡排序、归并排序、基数排序
插入排序[稳定]
适用于小数组,数组已排好序或接近于排好序速度将会非常快
复杂度:O(n^2) - O(n) - O(n^2) - O(1)[平均 - 最好 - 最坏 - 空间复杂度]
归并排序[稳定]
采用分治法
复杂度:O(nlogn) - O(nlgn) - O(nlgn) - O(n)[平均 - 最好 - 最坏 - 空间复杂度]
冒泡排序[稳定]
复杂度:O(n^2) - O(n) - O(n^2) - O(1)[平均 - 最好 - 最坏 - 空间复杂度]
基数排序 分配+收集[稳定]
复杂度: O(d(n+r)) r为基数d为位数 空间复杂度O(n+r)
树排序[不稳定]
应用:TreeSet的add方法、TreeMap的put方法
不支持相同元素,没有稳定性问题
复杂度:平均最差O(nlogn)
堆排序(就地排序)[不稳定]
复杂度:O(nlogn) - O(nlgn) - O(nlgn) - O(1)[平均 - 最好 - 最坏 - 空间复杂度]
快速排序[不稳定]
复杂度:O(nlgn) - O(nlgn) - O(n^2) - O(1)[平均 - 最好 - 最坏 - 空间复杂度]
栈空间0(lgn) - O(n)
选择排序[不稳定]
复杂度:O(n^2) - O(n^2) - O(n^2) - O(1)[平均 - 最好 - 最坏 - 空间复杂度]
希尔排序[不稳定]
复杂度 小于O(n^2) 平均 O(nlgn) 最差O(n^s)[1<s<2] 空间O(1)
九大内部排序算法代码及性能分析参见我的GitHub
- 查找与散列
4.1 散列函数设计
直接定址法:f(key) = a*key+b
简单、均匀,不易产生冲突。但需事先知道关键字的分布情况,适合查找表较小且连续的情况,故现实中并不常用
除留余数法:f(key) = key mod p (p<=m) p取小于表长的最大质数 m为表长
DJBX33A算法(time33哈希算法hash = hash*33+(unsigned int)str[i];
平方取中法 折叠法 更多…
4.2 冲突处理
闭散列(开放地址方法):要求装填因子a较小,闭散列方法把所有记录直接存储在散列表中
线性探测:易产生堆积现象(基地址不同堆积在一起)
二次探测:f(key) = (f(key)+di) % m di=12,-12,22,-22…可以消除基本聚集
随机探测:f(key) = (f(key)+di),di采用随机函数得到,可以消除基本聚集
双散列:避免二次聚集
开散列(链地址法):原地处理
同义词记录存储在一个单链表中,散列表中子存储单链表的头指针。
优点:无堆积 事先无需确定表长 删除结点易于实现 装载因子a>=1,缺点:需要额外空间
5. 跳表
为什么选择跳表?
目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。
想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树
出来吗? 很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树,
还要参考网上的代码,相当麻烦。
用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,
它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,
就能去实现一个 SkipList。
跳跃表是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间),并且对并发算法友好。
Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。Skip list让已排序的数据分布在多层链表中,以0-1随机数决定一个数据的向上攀升与否,是一种“空间来换取时间”的一个算法,在每个节点中增加了指向下一层的指针,在插入、删除、查找时可以忽略一些不可能涉及到的结点,从而提高了效率。
在Java的API中已经有了实现:分别是
ConcurrentSkipListMap(在功能上对应HashTable、HashMap、TreeMap) ;
ConcurrentSkipListSet(在功能上对应HashSet)
Skip list的性质
(1) 由很多层结构组成,level是通过一定的概率随机产生的
(2) 每一层都是一个有序的链表,默认是升序
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在Level i 的链表中,则它在Level i 之下的链表也都会出现
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素
时间复杂度O(lgn) 最坏O(2lgn)
Java实现参见我的GitHub Repo Algorithm
- AVL树
1.LL型
在某一节点的左孩子的左子树上插入一个新的节点,使得该节点不再平衡。
举例 A B Ar Bl Br 在Bl下插入N,执行一次右旋即可,即把B变为父结点,原来的根节点A变为B的左孩子,B的右子树变为A的左子树。
2.RR型
与LL型是对称的,执行一次左旋即可。
3.LR型
指在AVL树某一结点左孩子的右子树上插入一个结点,使得该节点不在平衡。这时需要两次旋转,先左旋再右旋。
4.RL型
与LR对称,执行一次右旋,再执行一次左旋。
删除
1、被删的节点是叶子节点
将该节点直接从树中删除,并利用递归的特点和高度的变化,反向推算其父节点和祖先节点是否失衡。
2、被删的节点只有左子树或只有右子树
将左子树(右子树)替代原有节点的位置,并利用递归的特点和高度的变化,反向推算父节点和祖先节点是否失衡。
3、被删的节点既有左子树又有右子树
找到被删节点的左子树的最右端的节点,将该结点的的值赋给待删除结点,再用该结点的左孩子替换它本来的位置,然后释放该结点,并利用递归特点,反向推断父节点和祖父节点是否失衡。
- 一致性Hash
第一:简单介绍
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将对象存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,N是机器节点数。
1、考虑到比如一个服务器down掉,服务器结点N变为N-1,映射公式必须变为key%(N-1)
2、访问量加重,需要添加服务器结点,N变为N+1,映射公式变为hash(object)%(N+1)
当出现1,2的情况意味着我们的映射都将无效,对服务器来说将是一场灾难,尤其是对缓存服务器来说,因为缓存服务器映射的失效,洪水般的访问都将冲向后台服务器。
第二点:hash算法的单调性
Hash 算法的一个衡量指标是单调性,单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
consistent hash 也是一种hash 算法,简单的说,在移除 / 添加一个结点时,它能够尽可能小的改变已存在的映射关系,尽可能的满足单调性的要求。
第三点:将对象和服务器结点分别映射到环型空间
通常的一致性哈希做法是将 value 映射到一个 32 位的 key 值,也即是 0~2^32-1 次方的数值空间;我们可以将这个空间想象成一个首( 0 )尾( 2^32-1 )相接的圆环。
我们可以通过hash函数将我们的key映射到环型空间中,同时根据相同的哈希算法把服务器也映射到环型空间中,顺便提一下服务器或者某个计算节点的 hash 计算,一般的方法可以使用机器的 IP 地址或者机器名作为 hash 输入。
第四点:将对象映射到服务器
在这个环形空间中,如果沿着顺时针方向从对象的 key 值出发,直到遇见一个 服务器结点,那么就将该对象存储在这个服务器结点上,因为对象和服务器的hash 值是固定的,因此这个 cache 必然是唯一和确定的。
这时候考察某个服务器down机或者需要添加服务器结点,也就是移除和添加的操作,我们只需要几个对象的映射。
第五点:虚拟结点
Hash 算法的另一个指标是平衡性 (Balance)。平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
对于上述的做法,可能导致某些对象都映射到某个服务器,使得分布不平衡。为此可以采用“虚拟结点”的做法。
“虚拟结点”( virtual node )是实际节点在 hash 空间的复制品,一实际结点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以 hash 值排列。引入“虚拟结点”会让我们的映射分布更为平衡一些。
引入“虚拟结点”前:
Hash(“192.168.1.1”);
引入“虚拟结点”后:
Hash(“192.168.1.1#1”);
Hash(“192.168.1.1#2”);
- 如何判断链表是否有环
方法1:快慢指针法 2.设两个工作指针p、q,p总是向前走,但q每次都从头开始走,对于每个节点,看p走的步数是否和q一样。比如p从A走到D,用了4步,而q则用了14步。因而步数不等,出现矛盾,存在环。
- 熟悉哪些算法?
[哈希算法] 一致性哈希 time33哈希 FNV1_32_HASH
[排序算法] 快速排序
[搜索算法] DFS BFS
[最小生成树算法] Kruskal Prim
[最短路径算法] Dijkstra Floyed
七、计算机网络
1.停止等待协议
停止等待协议是最基本的数据链路层协议,它的工作原理是这样的。
在发送端,每发送完一帧就停止发送,等待接收端的确认,如果收到确认就发送下一帧。
在接收端,每收到一个无差错的帧,就把这个帧交付上层并向发送端发送确认。若该帧有差错,就丢弃,其他什么也不做。
其他细节:
停止等待协议为了可靠交付,需要对帧进行编号,由于每次只发送一帧,所以停止等待协议使用1个比特编号,编号0和1
停止等待协议会出现死锁现象(A等待B的确认),解决办法,启动超时计时器,超时计时器有一个重传时间。重传时间一般选择略大于“正常情况下从发完数据帧到收到确认帧所需的平均时间”。
2.滑动窗口协议
再说滑动窗口之前,先说下连续ARQ,连续ARQ又称Go-back-N ARQ,意思是当出现差错必须重传时,要向回走N个帧,然后再开始重传,也就意味着只要有一帧出现差错,即使已经正确的帧也需要重传,白白浪费时间,增大开销。为此,应该对发送出去但未被确认的帧的数目加以限制,这就是滑动窗口协议。滑动窗口指收发两端分别维护一个发送窗口和接收窗口,发送窗口有一个窗口值Wt,窗口值Wt代表在没有收到对方确认的情况下最多可以发送的帧的数目。当发送的帧的序号被接收窗口正确收下后,接收端向前滑动并向发送端发去确认,发送端收到确认后,发送窗口向前滑动。收发两端按规律向前推进。
连续ARQ和选择重传ARQ均是窗口大于1的滑动窗口协议,而停止等待协议相当于收发两端窗口等于1。
滑动窗口指接收和发送两端的窗口按规律不断向前推进,是一种流量控制的策略。
3.Http1.0和Http1.1的区别
1.HTTP/1.0协议使用非持久连接,即在非持久连接下,一个tcp连接只传输一个Web对象。
2.HTTP/1.1默认使用持久连接(然而,HTTP/1.1协议的客户机和服务器可以配置成使用非持久连接)。在持久连接下,不必为每个Web对象的传送建立一个新的连接,一个连接中可以传输多个对象。
4.Post和Get的区别
1.安全性上说:get的方式是把数据在地址栏中明文的形式发送,URL中可见,POST方式对用户是透明的,安全性更高。
2.数据量说:Get传送的数据量较小,一般不能大于2KB,POST传送的数据量更大。
3.适用范围说:查询用Get,数据添加、修改和删除建议Post
5.TCP/IP体系各层功能及协议
TCP/IP体系共有四个层次,分别为网络接口层Host-to-Network Layer, 网际层 Internet Layer, 传输层Transport Layer,应用层Application Layer。
5.1 网络接口层 -> 接收和发送数据报
主要负责将数据发送到网络传输介质上以及从网络上接收TCP/IP数据报,相当于OSI参考模型的物理层和数据链路层。在实际中,先后流行的以太网、令牌环网、ATM、帧中继等都可视为其底层协议。它将发送的信息组装成帧并通过物理层向选定网络发送,或者从网络上接收物理帧,将去除控制信息后的IP数据报交给网络层。
5.2 网际层 -> 数据报封装和路由寻址
网际层主要功能是寻址和对数据报的封装以及路由选择功能。这些功能大部分通过IP协议完成,并通过地址解析协议ARP、逆地址解析协议RARP、因特网控制报文协议ICMP、因特网组管理协议IGMP从旁协助。所以IP协议是网络层的核心。
网际协议IP:IP协议是一个无连接的协议,主要负责将数据报从源结点转发到目的结点。也就是说IP协议通过对数据报中源地址和目的地址进行分析,然后进行路由选择,最后再转发到目的地。需要注意的是:IP协议只负责对数据进行转发,并不对数据进行检查,也就是说,它不负责数据的可靠性,这样设计的主要目的是提高IP协议传送和转发数据的效率。
ARP:该协议负责将IP地址解析转换为计算机的物理地址。
虽然我们使用IP地址进行通信,但IP地址只是主机在抽象的网络层中的地址。最终要传到数据链路层封装成MAC帧才能发送到实际的网络。因此不管使用什么协议最终需要的还是硬件地址。
每个主机拥有一个ARP高速缓存(存放所在局域网内主机和路由器的IP地址到硬件地址的映射表)
举例:A发送B
(1)A在自己的ARP高速缓存中查到B的MAC地址,写入MAC帧发往此B
(2)没查到,A向本局域网广播ARP请求分组,内容包括自己的地址映射和B的IP地址
(3)B发送ARP响应分组,内容为自己的IP地址到物理地址的映射,同时将A的映射写入自己的ARP高速缓存(单播的方式)
注:ARP Cache映射项目具有一个生存时间。
RARP:将计算机物理地址转换为IP地址
ICMP:该协议主要负责发送和传递包含控制信息的数据报,这些控制信息包括了哪台计算机出现了什么错误,网络路由出现了什么错误等内容。
5.3 传输层 -> 应用进程间端到端的通信
传输层主要负责应用进程间“端到端”的通信,即从某个应用进程传输到另一个应用进程,它与OSI参考模型的传输层功能类似。
传输层在某个时刻可能要同时为多个不同的应用进程服务,因此传输层在每个分组中必须增加用于识别应用进程的标识,即端口。
TCP/IP体系的传输层主要包含两个主要协议,即传输控制协议TCP和用户数据报协议UDP。TCP协议是一种可靠的、面向连接的协议,保证收发两端有可靠的字节流传输,进行了流量控制,协调双方的发送和接收速度,达到正确传输的目的。
UDP是一种不可靠的、无连接的协议,其特点是协议简单、额外开销小、效率较高,不能保证可靠传输。
传输层提供应用进程间的逻辑通信。它使应用进程看见的就好像是在两个运输层实体间一条端到端的逻辑通信信道。
当运输层采用TCP时,尽管下面的网络是不可靠的,但这种逻辑通信信道相当于一条全双工的可靠信道。可以做到报文的无差错、按序、无丢失、无重复。
注:单单面向连接只是可靠的必要条件,不充分。还需要其他措施,如确认重传,按序接收,无丢失无重复。
熟知端口:
20 FTP数据连接
21 FTP控制连接
22 SSH
23 TELNET
25 SMTP
53 DNS
69 TFTP
80 HTTP
161 SNMP
1
2
3
4
5
6
7
8
9
UDP重要
UDP的优点:
1.发送之前无需建立连接,减小了开销和发送数据的时延
2.UDP不使用连接,不使用可靠交付,因此主机不需要维护复杂的参数表、连接状态表
3.UDP用户数据报只有8个字节的首部开销,而TCP要20字节。
4.由于没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(IP电话等实时应用要求源主机以恒定的速率发送数据是有利的)
Table,使用TCP和UDP的应用
应用 应用层协议 运输层协议
名字转换 DNS UDP
文件传送 TFTP UDP
路由选择协议 RIP UDP
IP地址配置 BOOTTP,DHCP UDP
网络管理 SNMP UDP
远程文件服务器 NFS UDP
IP电话 专用协议 UDP
流式多媒体通信 专用协议 UDP
电子邮件 SMTP TCP
远程终端接入 TELNET TCP
万维网 HTTP TCP
文件传送 FTP TCP
注:TFTP:Trivial File Transfer Protocol
UDP的过程(以TFTP举例):
1.服务器进程运行着,等待TFTP客户进程的服务请求。客户端TFTP进程启动时,向操作系统申请一个临时端口号,然后操作系统为该进程创建2个队列,
入队列和出队列。只要进程在执行,2个队列一直存在。
2.客户进程将报文发送到出队列中。UDP按报文在队列的先后顺序发送。在传送到IP层之前给报文加上UDP首部,其中目的端口后为69,然后发给IP层。
出队列若溢出,则操作系统通知应用层TFTP客户进程暂停发送。
3.客户端收到来自IP层的报文时,UDP检查报文中目的端口号是否正确,若正确,放入入队列队尾,客户进程按先后顺序一一取走。若不正确,UDP丢弃该报文,并请ICMP发送”端口不可达“差错报文给服务器端。入队列可能会溢出,若溢出,UDP丢弃该报文,不通知对方。
服务器端类似。
UDP首部:源端口 - 目的端口 - 长度 - 检验和,每个字段22字节。
注:IP数据报检验和只检验IP数据报的首部,而UDP的检验和将首部和数据部分一起都检验。
TCP重要
细节:
TCP报文段是面向字节的数据流。
TCP首部:20字节固定首部
确认比特ACK,ACK=1 确认号字段才有效;同步比特SYN:SYN=1 ACK=0表示一个连接请求报文段;终止比特FIN,FIN=1时要求释放连接。
窗口:将TCP收发两端记为A和B,A根据TCP缓存空间的大小确定自己的接收窗口大小。并在A发送给B的窗口字段写入该值。作为B的发送窗口的上限。意味着B在未收到A的确认情况下,最多发送的字节数。
选项:最大报文段长度MSS,MSS告诉对方TCP:我的缓存所能接收的报文段的数据字段的最大长度是MSS个字节。若主机未填写,默认为536字节。
TCP的可靠是使用了序号和确认。当TCP发送一个报文时,在自己的重传队列中存放一个副本。若收到确认,删除副本。
TCP使用捎带确认。
TCP报文段的发送时机:1.维持一个变量等于MSS,发送缓存达到MSS就发送 2.发送端应用进程指明要发送,即TCP支持的PUSH操作。3.设定计时器
TCP的拥塞控制:TCP使用慢开始和拥塞避免算法进行拥塞控制
慢开始和拥塞避免
接收端根据自身资源情况控制发送端发送窗口的大小。
每个TCP连接需要维持一下2个状态变量:
接收端窗口rwnd(receiver window):接收端根据目前接收缓存大小设置的窗口值,是来自接收端的流量控制
拥塞窗口cwnd(congestion window):是发送端根据自己估计的网络拥塞程度设置的窗口值,是来自发送端的流量控制
发送端的窗口上限值=Min(rwnd, cwnd)
慢开始算法原理:主机刚开始发送数据时,如果立即将较大的发送窗口的全部字节注入网络,由于不清楚网络状况,可能会引起拥塞。通常的做法是将cwnd设置为1个MSS,每收到一个确认,将cwnd+1,由小到大逐步增大cwnd,使分组注入网络的速率更加合理。为了防止拥塞窗口增长引起网络拥塞,还需设置一个状态变量ssthresh,即慢开始门限。
慢开始门限:ssthresh,当cwnd < ssthresh,执行慢开始算法;cwnd > ssthresh,改用拥塞避免算法。 cwnd = ssthresh时,都可以。
拥塞避免算法使发送端的拥塞窗口每经过一个RTT增加一个MSS(而不管在此期间收到多少ACK),这样,拥塞窗口cwnd按线性规律增长,拥塞窗口此时比慢开始增长速率缓慢很多。这一过程称为加法增大,目的在于使拥塞窗口缓慢增长,防止网络过早拥塞。
无论是慢开始还是拥塞避免,只要发送端发现网络出现拥塞(根据是没有按时收到ACK或者收到重复ACK),就将慢开始门限ssthresh设置为拥塞窗口值的一半并将拥塞窗口cwnd置为1,重新执行慢开始算法。这一过程称为乘法减小。目的在于迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
上述TCP确认都是通过捎带确认执行的。
快重传和快恢复
上述的慢开始和拥塞避免算法是早期TCP使用的拥塞控制算法。因为有时TCP连接会在重传时因等待重传计时器的超时时间而空闲。为此在快重传中规定:只要发送端一连收到三个重复的ACK,即可断定分组丢失,不必等待重传计数器,立即重传丢失的报文。
与快重传搭配使用的还有快恢复:当不使用快恢复时,发送端若发现网络拥塞就将拥塞窗口降为1,然后执行慢开始算法,这样的缺点是网络不能很快恢复到正常状态。快恢复是指当发送端收到3个重复的ACK时,执行乘法减小,ssthresh变为拥塞窗口值的一半。但是cwnd不是置为1,而是ssthresh+3xMSS。若收到的重复ACK
为n(n > 3),则cwnd=ssthresh+n*MSS.这样做的理由是基于发送端已经收到3个重复的ACK,它表明已经有3个分组离开了网络,它们不在消耗网络的资源。
注意的是:在使用快恢复算法时,慢开始算法只在TCP连接建立时使用。
TCP的重传机制
每发送一个报文段,就对这个报文段设置一次计时器。新的重传时间=γ*旧的重传时间。
TCP连接建立和释放的过程
SYN置1和FIN的报文段要消耗一个序号。
客户端连接状态变迁:CLOSED -> 主动打开,发送SYN=1 -> SYN_SENT -> 收到服务器的SYN=1和ACK时,发送三次握手的最后一个ACK
-> ESTABLISHED -> 数据传送 -> 主动关闭 -> 发送FIN=1,等待确认ACK的到达 -> FIN_WAIT_1 -> 收到确认ACK后 -> FIN_WAIT_2
-> 收到服务器发送的FIN=1报文,响应,发送四次挥手的的最后一个确认ACK -> 进入TIME_WAIT状态
-> 经过2倍报文寿命,TCP删除连接记录 -> 回到CLOSED状态
客户端状态:CLOSED - SYN_SENT- ESTABLISHED - FIN_WAIT_1 - FIN_WAIT_2 - TIME_WAIT - CLOSED
服务器端连接状态变迁:CLOSED -> 被动打开 -> LISTEN -> 收到SYN=1的报文,发送SYN=1和确认ACK -> 进入SYN_RCVD -> 收到三次握手
的最后一个确认ACK -> ESTABLISHED -> 数据传送 -> 数据传送完毕,收到FIN=1 -> 发送确认ACK并进入CLOSED_WAIT -> 发送FIN=1给客户端 -> LAST_ACK
-> 收到客户端四次挥手的最后一个确认ACK -> 删除连接记录 -> 回到CLOSED状态
服务器端:CLOSED - LISTEN - SYN_RCVD - ESTABLISHED - CLOSED_WAIT - LAST_ACK - CLOSED
5.4 应用层
应用层位于TCP/IP体系结构的最高一层,也是直接为应用进程服务的一层,即当不同的应用进程数据交换时,就去调用应用层的不同协议实体,让这些实体去调用传输层的TCP或者UDP来进行网络传输。具体的应用层协议有,SMTP 25、DNS 53、HTTP 80、FTP 20数据端口 21控制端口、TFTP 69、TELNET 23、SNMP 161等
5.5 网络的划分
按网络拓扑结构:总线、星型、环型、树型、网状结构和混合型。
按覆盖范围:局域网、城域网、广域网
按传播方式:广播网络和点对点网络
广播式网络是指网络中的计算机使用一个共享信道进行数据传播,网络中的所有结点都能收到某一结点发出的数据信息。
单播:一对一的发送形式。
组播:采用一对一组的发送形式,将数据发送给网络中的某一组主机。
广播:采用一对所有,将数据发送给网络所有目的结点。
点对点网络中两个结点间的通信方式是点对点的。如果两台计算机之间没有直连的线路,则需要中间结点的接收、存储、转发直至目的结点。
- TCP的三次握手和四次挥手的过程
以客户端为例
连接建立(三次握手):首先Client端发送连接请求报文SYN并进入SYN_SENT状态,Server收到后发送ACK+SYN报文,并为这次连接分配资源。Client端接收到Server端的SYN+ACK后发送三次握手的最后一个ACK,并分配资源,连接建立。
连接释放(四次挥手):假设Client端发起断开连接请求,首先发送FIN=1,等待确认ACK的到达 -> FIN_WAIT_1 -> 收到Server端的确认ACK后时 -> FIN_WAIT_2
->收到服务器发送的FIN=1报文,响应,发送四次挥手的的最后一个确认ACK ->进入TIME_WAIT状态
-> 经过2倍报文寿命,TCP删除连接记录 -> 回到CLOSED状态
- 为什么连接建立是三次握手,而连接释放要四次挥手?
因为当Server端收到Client端发送的SYN连接请求报文后,可以直接发送SYN+ACK报文,其中ACK用来应答,SYN用来同步。但是关闭连接时,当Server端收到FIN报文后,并不会立即关闭socket,所以先回复一个ACK,告诉Client端“你的FIN我收到了”,只有等Server端的所有报文发送完了,Server端才发送FIN报文,因此不能一起发送,故需要四次挥手。
- 为什么TIME_WAIT状态需要2MSL(最大报文段生存时间)才能返回Closed状态?
这是因为虽然双方都同意关闭连接了,而且四次挥手的报文也都协调发送完毕。但是我们必须假想网络是不可靠的,无法保证最后发送的ACK报文一定被对方收到,因此处于LAST_ACK状态下的
Server端可能会因未收到ACK而重发FIN,所以TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。
- Http报文格式
Http请求报文格式:1.请求行 2.Http头 3.报文主体
请求行由三部分组成,分别是请求方法,请求地址,Http版本
Http头:有三种,分别为请求头(request header),普通头(General Header)和实体头(entity header)。Get方法没有实体头。
报文主体:只在POST方法请求中存在。
Http响应报文:1.状态行 2.Http头 3.返回内容
状态行:第一部分为Http版本,第二部分为响应状态码 第三部分为状态码的描述
其中第三部分为状态码的描述,信息类100-199 响应成功200-299 重定向类300-399 客户端错误400-499 服务器端错误500-599
常见的
100 continue 初始请求已接受,客户端应继续发送请求剩余部分
200 OK
202 Accepted 已接受,处理尚未完成
301 永久重定向
302 临时重定向
400 Bad Request
401 Unauthorized
403 Forbidden 资源不可用
404 Not Found
500 Internal Server Error 服务器错误
502 Bad Gateway
503 Service Unavailable 服务器负载过重
504 Gateway Timeout 未能及时从远程服务器获得应答
1
2
3
4
5
6
7
8
9
10
11
12
13
Http头:响应头(Response Header),普通头(General Header)和实体头(Entity Header)
返回内容:即Http请求的信息,可以是HTML也可以是图片等等。
- Http和Https的区别
Https即Secure Hypertext Transfer Protocol,即安全超文本传输协议,它是一个安全通信信道,基于Http开发,用于在客户机和服务器间交换信息。它使用安全套接字层SSL进行信息交换,是Http的安全版。
Https协议需要到CA申请证书,一般免费证书很少,需要交费。
Http是超文本传输协议,信息是明文传输,https则是具有安全性的tls/ssl加密传输协议。
http是80端口,https是443端口
- 浏览器输入一个URL的过程
浏览器向DNS服务器请求解析该URL中的域名所对应的IP地址
解析出IP地址后,根据IP地址和默认端口80和服务器建立TCP连接
浏览器发出Http请求,该请求报文作为TCP三次握手的第三个报文的数据发送给服务器
服务器做出响应,把对应的请求资源发送给浏览器
释放TCP连接
浏览器解析并显示内容
- 中间人攻击
中间人获取server发给client的公钥,自己伪造一对公私钥,然后伪造自己让client以为它是server,然后将伪造的公钥发给client,并拦截client发给server的密文,用伪造的私钥即可得到client发出去的内容,最后用真实的公钥对内容加密发给server。
解决办法:数字证书,证书链,可信任的中间人
- 差错检测
误码率:传输错误的比特与传输总比特数的比率
CRC是检错方法并不能纠错,FCS(Frame Check Sequence)是冗余码。
计算冗余码(余数R)的方法:先补0(n个)再对生成多项式取模。
CRC只能表示以接近1的概率认为它没有差错。但不能做到可靠传输。可靠传输还需要确认和重传机制。
生成多项式P(X):CRC-16,CRC-CCITT,CRC-32
- 数据链路层的协议
停止等待协议 - 连续ARQ - 选择重传ARQ - PPP - 以太网协议- 帧中继 - ATM - HDLC
- 截断二进制指数退避算法
是以太网用于解决当发生碰撞时就停止发送然后重发再碰撞这一问题。
截断二进制指数退避算法:基本退避时间为2τ k=min{重传次数,10} r=random(0~2^k-1) 重传所需时延为r倍的基本退避时间
八、操作系统(OS基础、Linux等)
- 并发和并行
“并行”是指无论从微观还是宏观,二者都是一起执行的,也就是同一时刻执行
而“并发”在微观上不是同时执行的。是在同一时间间隔交替轮流执行
- 进程间通信的方式
管道( pipe ):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
有名管道 (named pipe) : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
信号量( semophore ) :信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
消息队列( message queue ) 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号 ( sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
共享内存( shared memory )
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
套接字( socket ) :套接字也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。
3. LinuxIO模型
1、阻塞IO模型
以socket为例,在进程空间调用recvfrom,其系统调用知道数据包到达且被复制到应用进程的缓冲区或者发生错误才返回,在此期间一直等待,进程从调用recvfrom开始到它返回的整段时间内都是被阻塞的,因此称为阻塞IO
2、非阻塞IO模型
应用进程调用recvfrom,如果缓冲区没有数据直接返回EWOULDBLOCK错误。一般对非阻塞IO进行轮询,以确定是否有数据到来。
3、IO多路复用模型
Linux提供select/poll,通过将一个或多个fd传递给select或poll系统调用,阻塞在select上。select/poll顺序扫描fd是否就绪。
4、信号驱动IO
开启套接字接口信号驱动IO功能,并通过系统调用sigaction执行信号处理函数。当数据准备就绪时,为该进程生成SIGIO信号,通过信号回调通知应用程序调用recvfrom来读取数据,并通知主函数处理数据。
5、异步IO
告知内核启动某个操作,并让内核在整个操作完成后通知我们。它与信号驱动IO的区别在于信号驱动IO由内核通知我们何时可以开始IO操作。而异步IO模型由内核通知我们IO操作已经完成。
九、其他
- 开源软件有哪些?
Eclipse、Linux及其Linux下的大多数软件、Git等。
Apache下的众多软件:Lucene、Velocity、Maven、高性能Java网络框架MINA、版本控制系统SVN、应用服务器Tomcat、Http服务器Apache、MVC框架Struts、持久层框架iBATIS、Apache SPARK、ActiveMQ
- 开源协议
MIT:相对宽松。适用:JQuery
Apache:相对宽松与MIT类似的协议,考虑有专利的情况。适用:Apache服务器、SVN
GPL:GPLV2和GPLV3,如果你在乎作品的传播和别人的修改,希望别人也以相同的协议分享出来。
LGPL:主要用于一些代码库。衍生代码可以以此协议发布(言下之意你可以用其他协议),但与此协议相关的代码必需遵循此协议。
BSD:较为宽松的协议,包含两个变种BSD 2-Clause 和BSD 3-Clause,两者都与MIT协议只存在细微差异。

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}