查询的类型有哪些 ?:关键词【query】
查询所有:match_all 【一般测试用】
全文检索: 利用分词器对用户输入的内容进行分词然后去倒排索引库中匹配文档
例如:
1. match_query 单个字段查询1. multi_match_query 多个字段查询
精确查询: 根据精确词条值查询数据 一般 查找keyword 数值日期 boolean等字段
- ids 根据id查询【用的少】- range 范围查询- term 根据词条精准查询
地理【geo】查询:
- geo_distance 圆形范围查询- geo_bounding_box 左上角坐标+右上角坐标
复合查询: 将上述 合并查询条件
- **fuction score:算分函数查询**,可以控制文档相关性分值,
1 首先正常查询
2 然后过滤出【filter】 需要加score的 用户
3 定义分值:weight 分值
4 然后定义【boost_mode】 分值运算方式 默认相乘【multiply】 可以自定义 boost_mode 可以分值替换【replace】
- **bool query:布尔查询**,利用逻辑关系组合多个其它的查询,实现复杂搜索- must:必须匹配每个子查询,类似“与”- should:选择性匹配子查询,类似“或”- must_not:必须不匹配,**不参与算分**,类似“非”- filter:必须匹配,**不参与算分**- 其它,例如:sum、avg、max、min
搜索结果的处理:
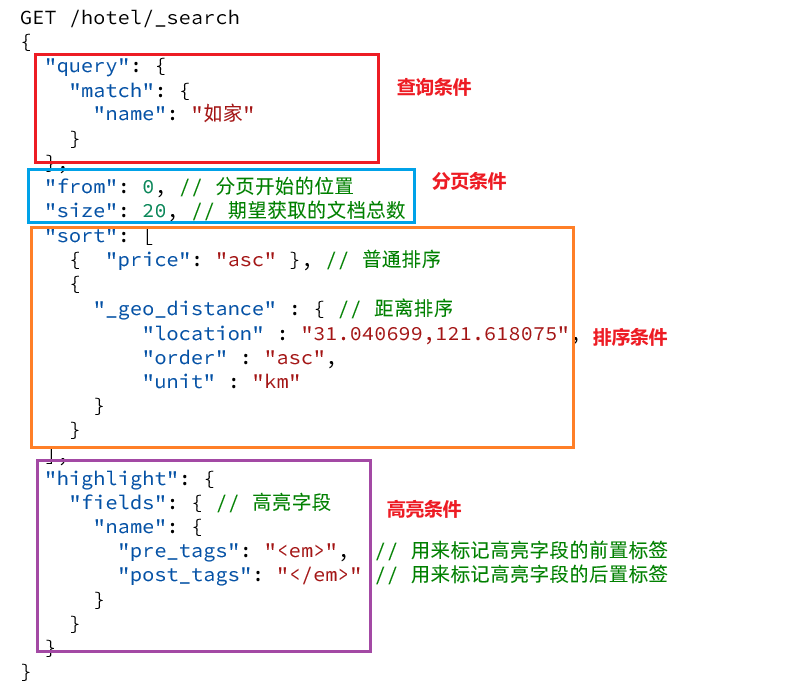
排序【关键词 sort】
默认按照 score 排序来降序排序,也可以自定义方式对搜索结果进行排序,可以按照字段类型: keyword,数值类型:地理坐标类型,日期类型等;
分页 默认情况下 返回的是前10条数据 如果查询更多就需要修改分页参数了
from 和size 只能查询top1000条数据
如果是单点模式 并无影响 如果是多个节点 就需要查询每个节点的1000条数据 然后汇总结果重新排名,重新截取top1000
from 从第几个文档开始
size 期望获得的条数
针对深度分页,查询更多数据990-10000条数据,es提供了两种解决方案
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。没有上限度,需要逐页查询,不能随机翻页,应用场景,没有随机翻页的需求的,例 <br />如手机的滚动翻页- scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。- 没有上限度,单词查询的size 不超过10000条- 消耗内存,搜索结果是非实时的- 应用场景,海量数据获取和迁移
高亮【关键词highlight】
高亮显示的实现分为两步:
highlight
fields 指定高亮字段 pre_tags 前缀 post_tags后缀
- 1)给文档中的所有关键字都添加一个标签,例如`<em>`标签- 2)页面给`<em>`标签编写CSS样式
查询基本语法格式:
GET /indexName/_search{"query": {"查询类型": {"查询条件": "条件值"}}}
RestClient查询文档
1 首先创建 RestHighLevelClient 获 取clint 链接
new RestHighLevelClient(RestClient.builder(HttpHost.create(“http://192.168.200.130:9200“))
2 创建查询文档对象
1. 创建SearchRequest对象 new SearchRequest();1. 准备Request.source(),也就是DSL。<br />① QueryBuilders来构建查询条件<br />② 传入Request.source() 的 query() 方法1. 发送请求,得到结果1. 解析结果(参考JSON结果,从外到内,逐层解析)

若有收获,就点个赞吧
0 人点赞
