本文翻译至 software2.0 migration, 原因也是趁休息期间整理下自己的知识点(最近一直围绕零代码平台做些事情).也是受了无意间看采访旷世科技创始人的视频-主要围绕当前机器学习的发展是否能够真正能达到自学习,智能化的地步。个人也想深入研究下是否在软件开发领域能够引入人工智能(无监督自学习,元学习,强化学习,组合求解,联邦学习等)来真正带来一定变革。构建对应的平台来提高软件开发生产力。
所谓的低代码,无代码平台总体来讲是一个接入层和交互层(在未来的一段时间我是这么认为)。个人认为, 所谓的智能化数据驱动,逻辑驱动开发在将来某一天将会变为现实。所以临渊慕鱼不如结网捕之,就算对自己的一个督促吧。
这个系列会想到哪写到哪,也有可能出本书。到时候再说吧。总之,是想跟大家分享下自己的经验总结,也期待碰撞出些有意思的思想火花, 毕竟一个人的思考和经验总是有一定的局限性。很多事情群策群力才能够很好的实现。
本文讨论的论文为以软件2.0设计方式重构隐私安全信息提取系统,完整的翻译会在第二篇文章中体现出来。
软件开发2.0设计方式是andrej karpathy提出来的一个有意思的设想,完整描述了通过深度学习方式来实现软件关键组件的一种设计方式。由于我们最近花了很多时间研究可解释模型和简单规则非常理想的情况,这个案例研究提出了一个很好的对比:它描述了一个以手写规则开始的系统,随着时间的推移,这种情况变得复杂,难以维持,直到有意义的进展几乎放缓到停顿。(从可解释性的角度来看,一套复杂的规则也不是很好)。用机器学习组件替换这些规则,极大地简化了代码库(删除了45k代码),使系统回到了增长和改进的轨道上。
从开发软件1.0(即传统软件)到软件2.0系统,会发生一件非常有趣的事情。在软件1.0中,我们将大部分精力花在编写代码上,表达系统如何实现其目标。我们的整个工具链都围绕着这个逻辑的创建和验证。但是在软件2.0中,我们的大部分工作都集中在训练数据的管理上,即通过示例来说明系统应该做什么。我们需要一个全新的工具链,围绕数据的创建/管理和验证。
本文讨论的具体系统是Google的电子邮件信息抽取系统。这将学习企业对消费者电子邮件的模板,然后使用这些模板提取诸如订单号、旅行日期等信息。现有系统基于一个基于规则的体系结构,带有手工编制的规则,自2013年开始投入生产。在替换之前,“基于启发式的提取系统的覆盖范围已经好几个月没有进行更新了,因为它太脆弱,无法在不引入错误提取的情况下进行改进。”
切换到软件2.0设计为谷歌带来了四大好处:
精确性和召回率很快超过了基于启发式的系统的结果
谷歌能够删除约4.5万行代码,大大减少了代码占用。
新系统更易于维护——手写规则变得脆弱,难以调试错误并进一步提高准确性。
它打开了一扇全新的大门,这是以前从未考虑过的——主要是集成跨语言单词嵌入,以学习跨多种语言的信息提取模型(最初的系统仅适用于英语)。
在这次迁移过程中,我们遇到的最大挑战是生成和管理培训数据。
在软件1.0系统中,最大的挑战是生成和管理手写规则。但在软件2.0中,(训练)数据是关键。在这个特殊的案例中,有一个有趣的转折:系统必须运行的电子邮件语料库是私有的。 例如,谷歌的工程师无法访问他们。
从低精度规则中检测低质量的训练数据,并随着时间的推移提高数据质量至关重要。在隐私安全系统的环境中开发这些功能,没有人可以直观地检查底层数据,这是一个特别具有挑战性的任务。
Juicer系统的背景介绍**
谷歌从非结构化邮件中提取结构化信息的系统叫做Juicer。Juicer将共享类似结构的电子邮件(使用组成电子邮件的HTML DOM树的一组xpath的对位置敏感的散列)聚集在一起,然后使用一组经过预训练的垂直分类器来确定群集表示的电子邮件类型(例如,订单确认、旅行预订)。此分类器分配的标签确定Juicer将尝试从电子邮件中提取何种字段信息(例如,如果此电子邮件群集已被分类为订单确认,则为订单号)。因此,从集群中形成该集群中电子邮件的模板。
最初的系统(从2013年开始生产)使用手写规则进行现场开采,经过多年开发。
在软件2.0方法中,提取规则是机器学习的。每个字段都有一个对应的字段分类器,该分类器应用于电子邮件中的一组候选字段,以识别目标字段值。
**
注释器库用于在电子邮件文本中注释日期、电子邮件地址、数字、价格等。字段提取的候选者是具有适当类型注释(例如,如果要查找交货日期字段值,则为日期)的任意文本范围。训练字段分类器(每个模板)以预测给定的候选字段是否与垂直方向上的给定字段相对应。在观察到XPath的集群中的所有电子邮件中,对分类器得分进行平均。如果平均得分大于预先确定的阈值,则会将提取规则添加到该XPath的模板中。

当系统运行时,当新的电子邮件到达时,Juicer根据xpath的散列查找适当的模板,然后应用该模板的任何提取规则。
提取是通过检查从底层模板生成的合成电子邮件并突出显示来自遗留系统或机器学习规则的结果来评估的。因为电子邮件数据是私有的,所以没有人可以查看任何真实的数据。相反,电子邮件是从通过k-匿名约束的模板文本中综合生成的。
管理训练数据
最初训练的模型只能替换先前启发式规则提取的6%。缩小这一差距完全是为了管理训练数据。如果你不能检查真正的电子邮件的目的,那么下一个最好的事情是生成你自己的合成电子邮件。CandidateGenerator会收到一封带注释的电子邮件,并返回一组候选对象,用于模型训练或字段规则生成的推理。然后,候选标记器实现逻辑,将每个候选标记为正、负或未知,以用于模型训练(例如,通过将注释值与最初用于构造电子邮件的已知基本事实进行比较)。
考虑到电子邮件的私密性,如果不能通过真实的电子邮件样本实际查看结果,就很难深入了解候选生成或标记逻辑的质量。
为了解决这个问题,为每个字段提取器计算一组计数器度量。通过检查这些计数器(例如,由于只有负面标签而被忽略的电子邮件数量),开发人员可以快速查明问题,而无需了解特定字段的详细信息。

训练数据中只允许有高置信度的结果。对排除了低质量示例的数据进行训练的分类器的性能优于包含该示例的分类器。
使用计数器度量,可以识别手工编写的规则可以成功提取但ML系统不能提取的情况。然后,可以针对这些领域进行改进。
一旦为模板生成了字段提取规则,就会为该模板创建综合生成的电子邮件,通过提取程序运行,然后由人工评估人员验证垂直标签和字段提取。”这些评估相当便宜,因为它们只需要对诸如“这是酒店确认书吗?”?“,”是否提取了正确的签入日期?’等。“
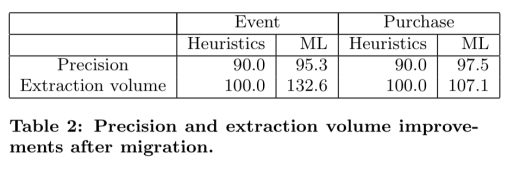
结果
我们在这篇文章的前面报道了标题结果。在上述过程之后的几周内,ML系统已经开始超越手工编写的规则,而多年的开发已经落后于这些规则。例如,ML模型发现了额外的模板和规则,导致事件提取量增加了32.6%。
我们的工作加强了这样一种观点,即现实世界中软件2.0方法的一个关键组成部分是管理训练数据。与解决从头提取问题相比,我们将重点放在用一个易于理解和改进的完全机器学习系统取代复杂的基于启发式的生产提取系统上。我们认为,任何此类工作的关键组件都是管理培训数据的系统,包括获取、调试、版本控制和转换训练数据。

若有收获,就点个赞吧
0 人点赞
