论文地址:Procella:统一YouTube的数据服务和分析,Chattopadhyay等人 VLDB’19
基于支持谷歌YouTube业务的主要用例,我们在这里看到的很可能是谷歌数据处理的未来。好吧,我说的是未来,但“Procella现在已经生产多年了。今天,它部署在十几个数据中心,每天在数百兆字节的数据上提供数千亿次查询……”所以,也许我们所关注的是我们其他人的数据处理的未来!
谷歌已经拥有Dremel、Mesa、Photon、F1、PowerDrill和splanter,那么为什么他们还需要另一个数据处理系统呢?因为他们有太多的数据处理系统!
大型组织…正在处理爆炸式的数据量和对数据驱动应用程序的日益增长的需求。大体上,它们可以分为:报告和仪表板、页面中的嵌入式统计信息、时间序列监视和即席分析。通常,组织为每个用例构建专门的基础设施。然而,这会造成数据和处理的筒仓,并导致复杂、昂贵和难以维护的基础设施。
当这些用例中的每一个都由一个专用的后端支持时,在更好的性能、更好的可伸缩性和效率等方面的投资就会被分割开来。鉴于YouTube的规模不断扩大,一些后端系统开始出现问题。此外,在不同系统之间移动数据以支持不同的用例可能会导致复杂的ETL管道。
Procella的大目标是“在一个产品中实现解决所有四个用例所需的超能力集……具有高规模和高性能”(又称HTAP1)。这很困难,原因有很多,包括吞吐量和延迟之间需要在用例中进行不同的权衡。
用例
报告和仪表板用例(例如,了解YouTube视频性能)每秒会驱动数万个屏蔽(预先知道)查询,这些查询需要在数十毫秒内提供延迟。每个被查询的数据源每天可以添加数千亿个新行。哦,除了低延迟之外,“我们还需要访问新数据。”
对于YouTube Analytics应用程序,我们正在研究这样的指标,其99%的延迟为412ms: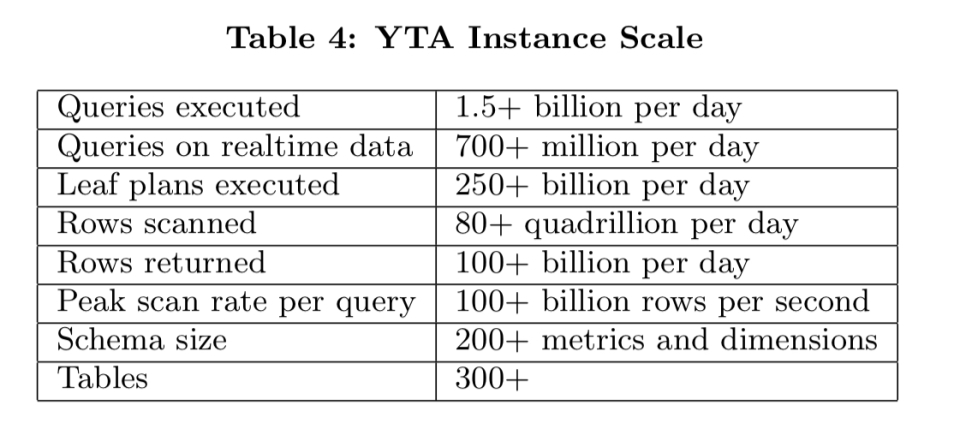
嵌入式统计用例包括页面中包含的各种计数器,如视图、喜好和订阅。这里的查询量每天运行数千亿个查询,需要毫秒的延迟(Procella在这里达到99%的ile延迟3.3ms)。
时间序列监视工作负载具有与仪表板类似的属性(相对简单的屏蔽查询,但需要新的数据)。这里还需要其他查询特性,如近似和专用的时间序列函数。
特别分析用例支持内部团队执行复杂的特别分析,以了解使用趋势并确定如何改进产品。这些是相对较低的卷查询,具有中等的延迟要求,但它们可能很复杂,并且查询模式高度不可预测。
Procella系统概述
这篇论文涉及很多领域。在本文中,我们将研究一些高级架构原则,然后我将挑选与Procella如何实现其性能、延迟和数据新鲜度目标相关的细节。
对其客户机来说,Procella是一个SQL查询引擎(SQL-all-things)。在封面下,它是一个基于云本机系统原则构建的复杂分布式系统:
- 分类(远程)存储,通过rpc执行读或写操作,以及不可变数据(仅追加文件)。
- 共享计算层,用于水平扩展许多小任务,而不是少量大任务。(很少或)没有本地状态。
- 从任何一台机器的损失中快速恢复
- 处理运行不正常的和周期性不可用任务的复杂策略
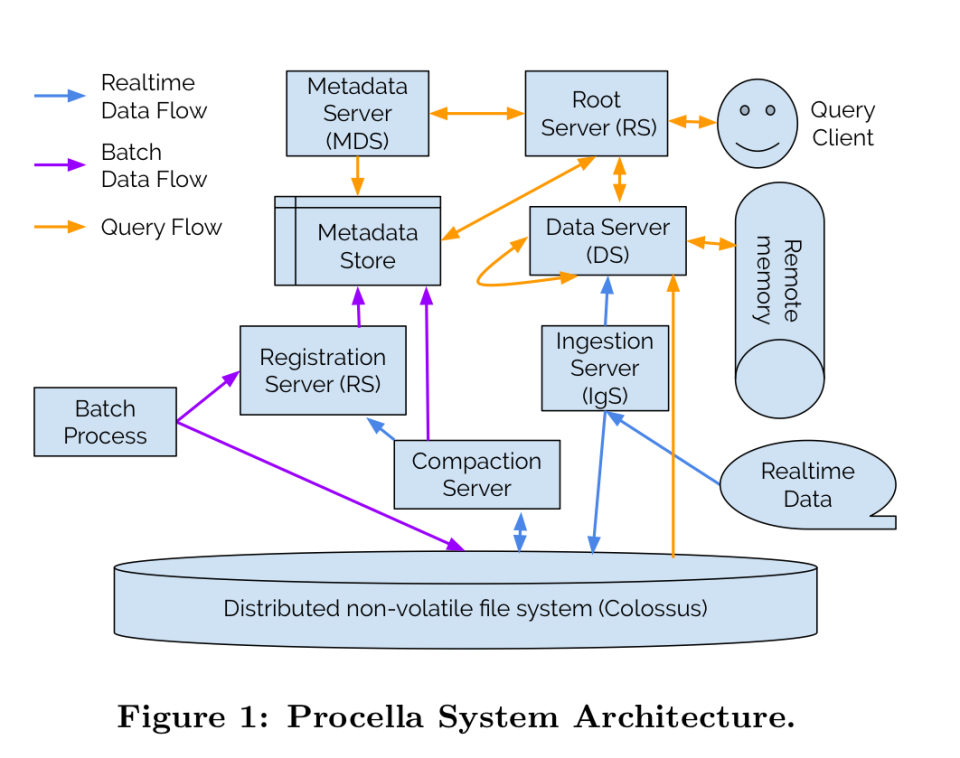
综合起来,这些原则使Procella能够扩展,但是在支持“几乎完整的标准SQL实现(包括复杂的多阶段连接、分析函数和set操作)以及一些有用的扩展(如近似聚合)的同时,可以达到所需的性能级别,处理复杂的嵌套和重复的模式、用户定义的函数等等“是一个全新的挑战。现在让我们来看看有助于加快Procella速度的一些东西。
使Procella变快
缓存任何数据和作业
Procella通过将存储(在Colossus中)与计算(在Borg上)分离,实现了高度的可伸缩性和效率。然而,这给读取甚至打开文件带来了巨大的开销,因为每个文件都涉及多个rpc。Procella使用多个缓存来减轻这种网络惩罚。
不过,关闭后不可变的文件的好处是,您不必担心缓存失效。
Procella强烈地缓存元数据、列文件头和列数据(使用新开发的数据格式Artus,它在磁盘和内存中提供相同的数据表示)。如果有足够的内存,Procella基本上可以成为内存数据库。对于他们的报告实例,只有大约2%的数据可以存储在内存中,但是系统仍然达到99%以上的文件句柄缓存命中率和90%的数据缓存命中率。
这些高命中率的秘密之一是关联调度。对数据服务器和元数据服务器的请求被路由,使得对同一数据/元数据的操作以高概率进入同一服务器。存储层的另一个特性,即所有数据都可以从任何地方获得,这意味着关联调度是一种优化,如果请求由于某种原因最终被路由到其他地方,那么它们仍然可以被服务。
大量优化和预计算数据格式
由于Procella的目标是覆盖[特别分析工作负载中典型的大型扫描]和其他几个需要快速查找和范围扫描的用例,因此我们构建了一种名为Artus的新列式文件格式,该格式专为查找和扫描的高性能而设计。
我们真的可以写一篇关于Artus本身的专门论文,但这里有一些亮点。
大量使用自定义编码,而不是像LZW这样的通用压缩算法。
多通道编码,第一个快速通道用于理解数据的形状(例如不同值的数量、范围、排序顺序等),然后选择最佳编码策略,然后第二个通道使用所选策略执行完整编码。
Artus使用多种方法对数据进行编码:dictionary和indexer类型、run-length、delta等,以在强通用字符串压缩(如ZSTD)的2倍范围内实现压缩,同时仍然能够直接对数据进行操作。每种编码都有估计方法,以确定它在所提供的数据上的大小和速度。
对于排序列,Artus的编码允许在O(\log N)时间内快速查找,其中O(1)查找给定的行号。
对于嵌套和重复的数据类型,Artus使用一种新的树表示法来记录给定字段是否出现,并消除缺少父字段下的任何子树。
Artus向计算引擎公开字典索引和运行长度编码信息等编码信息,并可以直接在其API中支持一些过滤操作。“这使我们能够积极地将此类计算向下推送到数据格式,从而在许多常见情况下获得较大的性能提升。”
在文件和列标题中保留丰富的元数据(排序顺序、最小值和最大值、详细的编码信息、bloom筛选器等),使许多修剪操作成为可能,而无需读取列中的实际数据。
通过对四种典型的YouTube分析查询模式的评估,以下是谷歌BigQuery的专栏存储格式Artus vs Capacitor的性能和内存消耗数据。
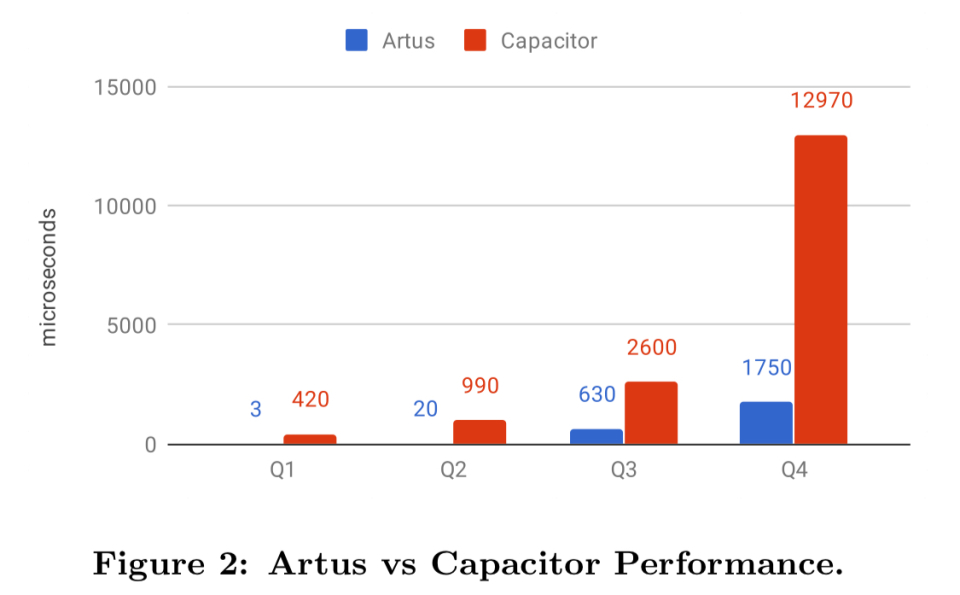

改编和汇编
高性能评估对于低延迟查询至关重要。现在许多现代的分析系统通过使用LLVM在查询时将执行计划编译为本机代码来实现这一点。然而,Procella需要同时服务于分析性和高QPS的用例,对于后者,编译时间往往会成为瓶颈。Procella评估引擎,超光速,采取了不同的方法…
Superluminal得C++模板元编程的广泛使用,并在底层的数据编码上进行操作。没有实现中间表示。
查询优化程序然后将静态和动态(自适应)查询优化技术结合起来。基于规则的优化程序应用标准逻辑重写。然后,当查询运行时,Procella根据查询中使用的实际数据的样本收集统计信息,并使用这些数据来确定下一步要做什么。
自适应技术使传统的基于成本的优化器难以实现强大的优化,同时大大简化了我们的系统,因为我们不必收集和维护数据的统计信息(特别是在以非常高的速率接收数据时),而且我们也不必构建复杂的估计模型,这些模型可能只对有限的查询子集有用。
聚合、连接和排序策略都是在运行时根据查询执行期间的不断学习进行调整的。对于具有严格的低延迟目标的查询,可以预先完全定义执行策略并关闭自适应优化程序。
尽可能少地工作,尽可能在最好的地方工作
Procella除了尽可能将计算推到最底层之外,还提供了多种连接策略,使分布式连接尽可能高效。我没有足够的篇幅在这里描述它们,但你可以在论文的第3.5节找到一个很好的摘要。
对于重聚合,Procella在最终聚合的输入处添加中间聚合运算符,以防止它成为瓶颈。

若有收获,就点个赞吧
0 人点赞
