开发中如果需要用到List接口的实现类,我们第一个想到的就是ArrayList,这篇文章不介绍ArrayList的一些常用API,主要介绍一下ArrayList的源码。
话说我只有在做LeetCode需要用到栈或者队列的实现类时才会想到LinkedList,平时开发中还真没咋用到… 另外,新手研究jdk源码,建议先从简单的集合类,比如ArrayList开始。
1、概述
- ArrayList底层实现是数组,数组的默认长度为10,当数组长度不够时,会进行扩容,底层的数组长度扩展为原来的1.5倍;
- 由于底层数据结构是数组,ArrayList的查找效率很高,时间复杂度为O(1),缺点是每次删除或者添加元素会带来数组里元素的大量移动(时间复杂度为O(n)),这意味着会开辟新的内存空间,且效率低下;
- ArrayList相比LinkedList最大的一个优势在于遍历速度快。ArrayList遍历最大的优势在于内存的连续性(底层是数组结构),CPU的内部缓存结构会缓存连续的内存片段,可以大幅降低读取内存的性能开销;
- ArrayList是线程不安全的,多线程场景下考虑使用线程安全的集合类(比如CopyOnWriteArrayList)或者加锁。
2、底层数据结构
```java // ArrayList默认的初始容量大小 private static final int DEFAULT_CAPACITY = 10;
// 空对象数组,用于空实例的共享空数组实例 private static final Object[] EMPTY_ELEMENTDATA = {};
// 空对象数组,如果使用默认的构造函数创建,则默认对象内容是该值 private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 底层数组,ArrayList的几乎所有操作都是在这个数组上完成的 transient Object[] elementData;
// ArrayList的长度 private int size;
// 记录ArrayList被修改了多少次,包括添加、删除 protected transient int modCount = 0;
<a name="KbVRT"></a># 3、构造函数```java// 有参构造函数,传入ArrayList的初始长度用来初始化底层数组public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {// 这里不再new一个空数组,而是让elementData引用指向static的空数组,避免频繁创建对象this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}// 无参构造函数public ArrayList() {// 无参构造函数底层数组也是空数组,同样没有new一个数组,理由同上this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}// 有参构造函数,传入参数是一个集合,即用这个集合初始化一个ArrayListpublic ArrayList(Collection<? extends E> c) {elementData = c.toArray();if ((size = elementData.length) != 0) {// c.toArray might (incorrectly) not return Object[] (see 6260652)if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);} else {// replace with empty array.this.elementData = EMPTY_ELEMENTDATA;}}
4、add(E e)
ArrayList有个特性是动态扩容,动态意思是代码提供了判断机制自动进行扩容。因为底层数据结构是数组,如果ArrayList的size大于数组的length时会抛异常,因此每次向ArrayList里添加元素时会判断一下底层数组是否已经满了,如果满了会对数组进行扩容(1.5倍),再插入元素。这个动态扩容的代码入口就是add方法,即只有插入元素时才有可能触发动态扩容。
public boolean add(E e) {
// 这里会判断是否需要动态扩容,以及执行动态扩容
ensureCapacityInternal(size + 1);
// 对底层数组下标是size的位置赋值,然后size+1
elementData[size++] = e;
return true;
}
ensureCapacityInternal:
private void ensureCapacityInternal(int minCapacity) {
// 如果是第一次向ArrayList添加元素,会将默认的初始容量大小10赋值给minCapacity
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 这里判断是否扩容以及执行扩容
ensureExplicitCapacity(minCapacity);
}
ensureExplicitCapacity:
private void ensureExplicitCapacity(int minCapacity) {
// 维护的ArrayList修改次数+1
modCount++;
// 如果minCapacity大于底层数组的长度,才进行扩容
if (minCapacity - elementData.length > 0)
// 真正的扩容动作的入口
grow(minCapacity);
}
grow:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
// oldCapacity >> 1是位运算,效率更高,结果是获取oldCapacity的1/2的值
// 跟oldCapacity相加就是扩容之前长度的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果是第一次进行扩容,即oldCapacity为0,newCapacity也为0,minCapacity为10,会进入这个if分支
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果扩容前ArrayList的长度已经很大了,1.5倍后长度已经超过了Integer.MAX_VALUE - 8,
// 会进行针对超大ArrayList的扩容
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 上面这段注释是源码里的,通常扩容场景都是minCapacity的值与当前ArrayList长度接近
// 调用Arrays类的静态copyeOf方法,将原来的底层数组中的元素拷贝到扩容后的数组中
elementData = Arrays.copyOf(elementData, newCapacity);
}
hugeCapacity:
private static int hugeCapacity(int minCapacity) {
//
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
// 最大能分配的长度就是Integer.MAX_VALUE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
关于数组拷贝的实现,最底层是Arrays类里会调用System.arraycopy方法,该方法是个native方法,由操作系统通过C/C++语言提供接口实现。
总结一下ArrayList的动态扩容过程:
- 当ArrayList集合为空时,会初始化一个容量为10的底层数组;
之后每次调用add方法时,会判断是否需要扩容,如果需要则通过grow方法实现扩容,在grow方法里,底层数组的容量会扩充为之前的1.5倍,调用Arrays.copyOf(elementData,newCapacity(minCapacity))实现,传入的新的数组长度通过右移运算符计算得到。
5、add(int index, E element)
public void add(int index, E element) { // 检查index是否越界 rangeCheckForAdd(index); // 上面分析过,动态扩容的入口 ensureCapacityInternal(size + 1); // 拷贝数组,即将原数组从index之后(不包含)的元素拷贝到index+1(包含)的位置 // 表现为将原数组中index之后的元素整体往后移动了1位 System.arraycopy(elementData, index, elementData, index + 1, size - index); // 将插入的元素放在index对应的数组位置中 elementData[index] = element; size++; }ArrayList被诟病的在指定index下插入元素慢的原因也在此,System.arraycopy方法将原数组中index之后的元素整体往后移动了1位,这一步开销很大。
6、set(int index, E element)
// index是插入列表的索引位置,element为插入的元素,返回index位置之前的值 public E set(int index, E element) { // 索引范围检查 rangeCheck(index); // 获取该index位置之前的值,用来返回 E oldValue = elementData(index); // 底层操作数组,给数组index位置赋值 elementData[index] = element; return oldValue; }rangeCheck:
// 检查索引是否越界的函数 private void rangeCheck(int index) { if (index >= size) // 熟悉的运行时异常....... throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }elemetdData:
// 获取指定索引index位置的元素,这里实现虽然简单但又封装了一层,猜是想后期优化这个点抽象起来便于一起整改 E elementData(int index) { // 底层还是访问数组返回index位置的元素 return (E) elementData[index]; }7、get(int index)
public E get(int index) { // 同样检查索引是否越界,源码分析见上 rangeCheck(index); // 方法见上 return elementData(index); }
最后有关ArrayList和LinkedList的比较统一放在了LinekdList这篇博客中:https://www.yuque.com/docs/share/b5938b66-7155-4fbd-9750-14d795cb1f90?# 《LinkedList》
8、其他问题
8.1 为什么查询数组中指定index的元素时间复杂度是O(1)?
这个问题首先需要知道数组在内存中的存储形式,创建一个数组对象时,会在堆内存中开辟一块连续的内存空间,举例:
int[] a = new int[10];
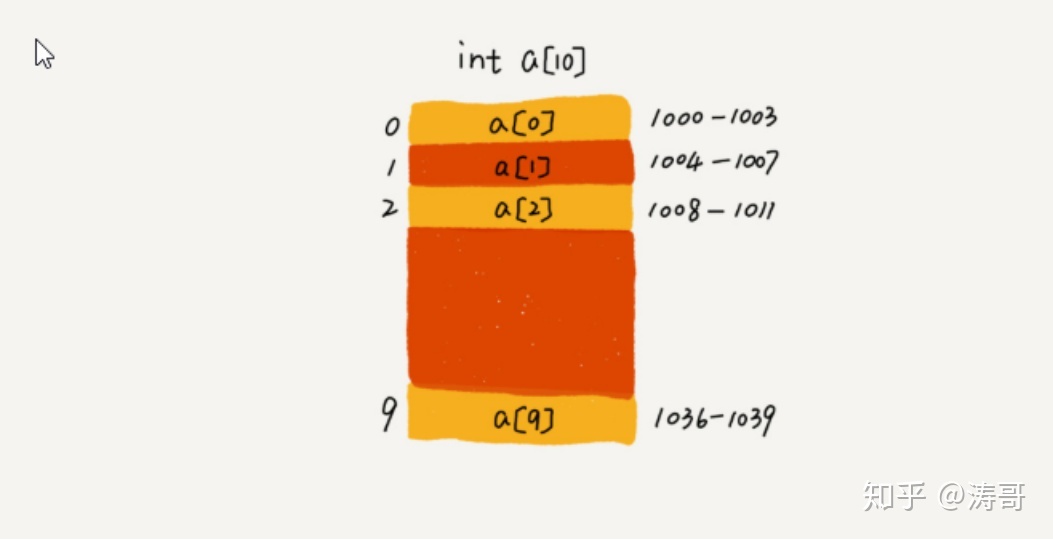
上图中,JVM给数组a[10]在堆中分配了一块连续的内存空间,地址范围是1000 - 1039,其中,内存块的首地址为base_address = 1000。数组中的每一个元素都会在内存中分配一个地址,计算机通过在内存中的地址来访问内存中的数据。当计算机需要随机访问数组中的某一个元素时,会通过如下寻址公式来计算得到元素对应的内存地址,然后获取:a[i]_address = base_address + i * data_type_size
其中data_type_size表示数组类型占的字节,上面例子是个int[],因此data_type_size就是4,代表4个字节。
总结:数组支持随机访问,根据下标随机访问数组元素的时间复杂度为O(1)。
参考

若有收获,就点个赞吧
0 人点赞
