1、概述
Stream是Java8引进的,搭配lambda表达式使用的,是一种新的处理集合的方法。Stream将集合里的元素处理成流,对流进行一系列聚合操作(类比数据库里的聚合操作,比如求平均值,求最大值等)。此外,Stream还提供并行的处理模式,能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程,而达到上述目的不需要写一行Java多线程代码,使用起来方便高效。
1.1 Stream流的特点
Stream流式处理有以下几个特点:
- 不是数据结构;
- Intermediate操作不会修改原数据源,而是会生成一个新数据源(也是Stream)返回;
- Intermediate操作是惰性化(lazy)的;
支持并行处理模式,且无需写额外的多线程代码,所有对它的操作会自动并行进行。
1.2 API分类
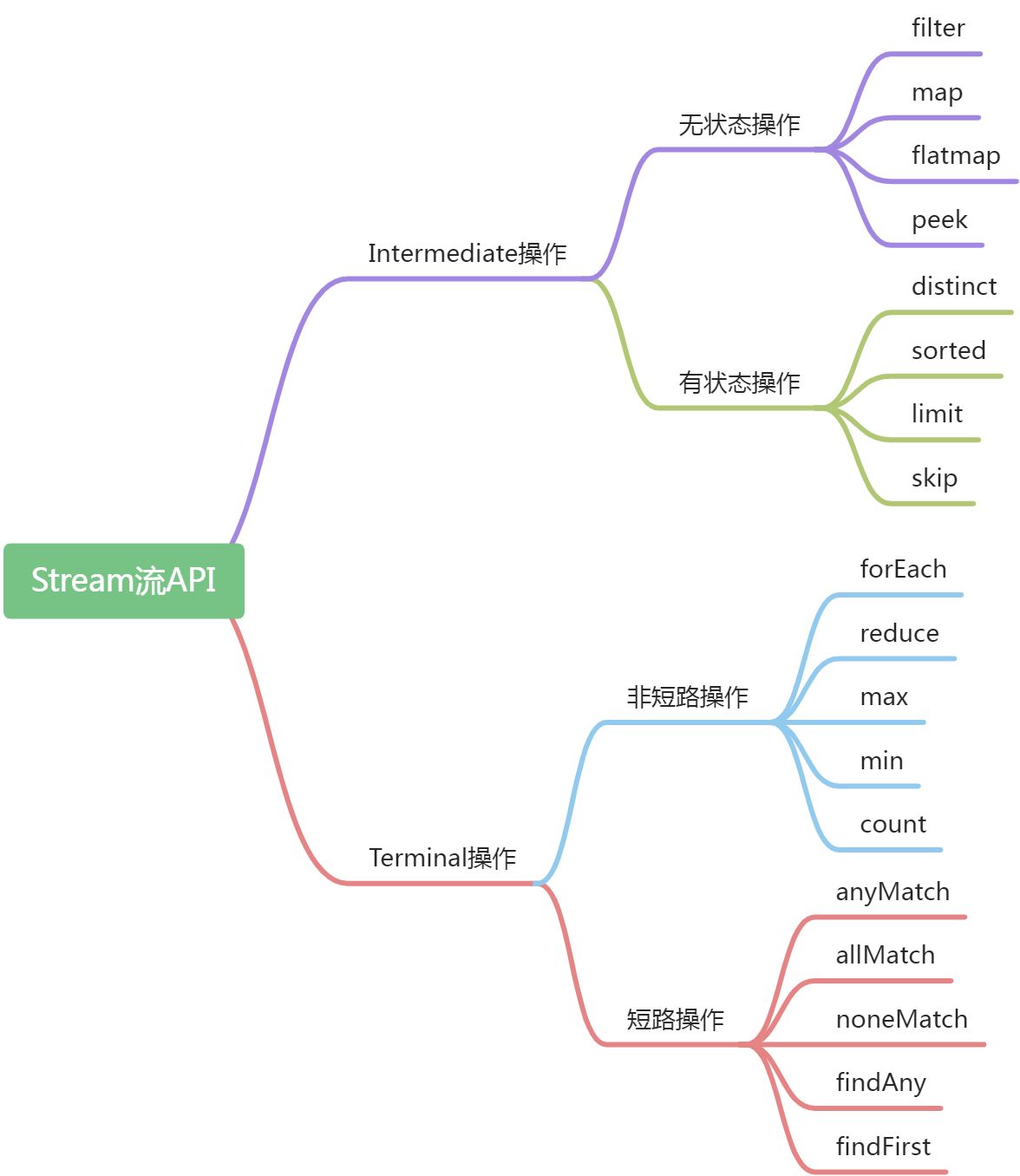
Intermediate操作:也叫中间操作,一个流可以有零个或多个intermediate操作,由于是惰性的,执行中间操作并没有开始遍历流,而是将一系列intermediate操作记录在集合里。- 无状态操作:指元素的处理不受之前元素的影响;
- 有状态操作:指该操作会受到之前对流做的操作的影响,只有拿到所有元素之后才可以进行。
Terminal操作:Terminal操作是流执行的最后一个操作,且一个流只能有一个terminal操作,比如ForEach还有max都是要等到所有中间操作执行完毕后才能进行。- 非短路操作:指必须处理所有元素才能得到最终结果
- 短路操作:指遇到某些符合条件的元素就可以得到最终结果,类比Java语法里的短路与和非短路与。
2、Stream API
2.1 流的创建
2.1.1 使用Collection下的 stream() 和 parallelStream() 方法
List<String> list = new ArrayList<>();Stream<String> stream = list.stream(); //获取一个顺序流Stream<String> parallelStream = list.parallelStream(); //获取一个并行流
2.1.2 使用Arrays 中的 stream() 方法,将数组转成流
```java
- Integer[] nums = new Integer[10];
Stream
stream = Arrays.stream(nums); <a name="sBBMY"></a>### 2.1.3 使用Stream中的静态方法:of()、iterate()、generate()```javaStream<Integer> stream = Stream.of(1,2,3,4,5,6);Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);stream2.forEach(System.out::println); // 0 2 4 6 8 10Stream<Double> stream3 = Stream.generate(Math::random).limit(2);stream3.forEach(System.out::println);
2.1.4 使用 BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt")); Stream<String> lineStream = reader.lines(); lineStream.forEach(System.out::println);2.1.5 使用 Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(","); Stream<String> stringStream = pattern.splitAsStream("a,b,c,d"); stringStream.forEach(System.out::println);上面的5种写法,第一种使用最为广泛,其他代码里基本没见过,知道回字有几种写法就行了。
2.2 Intermediate操作
2.2.1 无状态操作
2.2.1.1 filter
filter方法对原Stream按照指定条件过滤,返回符合条件的元素组成的新的stream流。filter传入的
Lambda表达式必须是Predicate实例,参数可以为任意类型,而其返回值必须是boolean类型。
举例:过滤数组,返回值大于3的流并打印:int[] nums = {1, 2, 3, 4, 5}; Arrays.stream(nums).filter(num -> num > 3).forEach(System.out::print);2.2.1.2 map
map方法对原stream中的元素按照map中传入的lambda表达式处理,返回处理后的元素组成的新的stream。
举例:返回数字中的元素的平方的集合/流:int[] nums = {1, 2, 3, 4, 5}; Arrays.stream(nums).map(num -> num * 2).forEach(System.out::println);举例:返回Student实例里的age属性组成的列表:
public class StudentSortDemo { public static void main(String[] args) { List<Student> studentList = new ArrayList<>(); studentList.add(new Student("Jerry", 27, 1)); studentList.add(new Student("Jerry", 27, 2)); studentList.add(new Student("Jerry", 28, 3)); studentList.add(new Student("Cissie", 27, 4)); System.out.println(studentList.stream().map(Student::getAge).collect(Collectors.toList())); } }2.2.1.3 flatmap
flatmap和map的功能类似,都是对stream里的元素进行处理返回一个stream流,但是与map不同的是,它可以对Stream
流中每个stream再进行拆分(切片),并将每个stream合并成一个stream返回 ,从另一种角度上说,使用了它,就是使用了双重for循环。
举例:有年级Grade的POJO类,如下:@Data @AllArgsConstructor public class Grade { private String name; private List<Student> studentList; }每个年级里有若干学生,这些学生组成一个列表,即该年级的学生集合。
Student的POJO类:@Data @AllArgsConstructor public class Student { private String name; private int age; private int id; }现在的需求是:给定若干个年级的实例,将这些年级里的所有学生的姓名组成一个列表返回。
如果直接对gradeList使用map,只能对每个grade里的studentList进行操作,拿不到studentList里的每个student的name属性,这时就需要用flatMap将所有的studentList的stream合并成一个stream,再用map去拿每个student的name属性,如下:public class FlatMapDemo { public static void main(String[] args) { // 初始化每个年级包含的学生列表 List<Student> studentList1 = new ArrayList<>(); studentList1.add(new Student("Jerry", 24, 1)); studentList1.add(new Student("Cissie", 27, 2)); List<Student> studentList2 = new ArrayList<>(); studentList2.add(new Student("Tom", 26, 3)); studentList2.add(new Student("Jack", 28, 4)); // 初始化所有年级 List<Grade> gradeList = new ArrayList<>(); gradeList.add(new Grade("grade1", studentList1)); gradeList.add(new Grade("grade2", studentList2)); // 取出所有年级的学生的姓名属性组成一个列表 List nameList = gradeList.stream().flatMap(grade -> grade.getStudentList().stream()) .map(Student::getName).collect(Collectors.toList()); System.out.println(nameList); } }总之当遇到要获取实例属性的属性值这种嵌套关系时,用flatMap!
2.2.1.4 peek
与map有些类似,也是对stream流中的元素进行处理,比如
stream.peek(System.out::println),区别在于:
- peek方法接收一个Consumer接口的入参,该方法返回类型为void;
- map方法的入参为 Function接口的入参,该方法可以return类型。
2.2.2 有状态操作
2.2.2.1 distinct
distinct方法用来对原Stream中的元素去重,返回去重后的元素组成的新的stream。
举例:对数组元素去重:
int[] nums = {1, 2, 3, 3, 4, 5, 5};
Arrays.stream(nums).distinct().forEach(System.out::println);
2.2.2.2 sorted
sorted返回排序后的元素组成的新的stream,需要注意两点:
- 默认sorted(),是对元素升序排序;
- 如果stream中的元素的类实现了Comparator接口,则sorted方法接收一个自定义排序规则函数,推荐使用Comparator.comparing更简洁直观。
举例:对数组元素进行升序降序排列:
public class terminalDemo {
public static void main(String[] args) {
Integer[] nums = {1, 2, 3, 4, 5, 0};
Stream<Integer> stream = Arrays.stream(nums);
// 升序排序
stream.sorted().forEach(System.out::println);
// 降序排序
stream.sorted(Comparator.reverseOrder()).forEach(System.out::println);
}
}
注意:自然序逆序元素,使用**Comparator** 提供的**reverseOrder()** 方法。
举例:对Student实例按照年龄升序,id降序排列。
Student类:
package com.Jerry.comparator;
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
public class Student {
private String name;
private int age;
private int id;
}
Demo:
public class StreamSortDemo {
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
studentList.add(new Student("Jerry", 27, 1));
studentList.add(new Student("Tom", 27, 2));
studentList.add(new Student("Cissie", 28, 3));
studentList.stream().sorted(Comparator.comparing(Student::getAge).thenComparing(Student::getId,
Comparator.reverseOrder())).forEach(System.out::println);
}
}
结果:
Student(name=Tom, age=27, id=2)
Student(name=Jerry, age=27, id=1)
Student(name=Cissie, age=28, id=3)
2.2.2.3 limit
返回前n个元素组成的新stream。
举例:返回前2个元素组成的新stream:
int[] nums = {1, 2, 3, 4, 5};
Arrays.stream(nums).limit(4).forEach(System.out::println);
2.2.2.4 skip
skip方法将过滤掉原Stream中的前N个元素,返回剩下的元素所组成的新Stream。如果原Stream的元素个数大于N,将返回原Stream的后(原Stream长度-N)个元素所组成的新Stream;如果原Stream的元素个数小于或等于N,将返回一个空Stream。
举例:返回第四个元素开始的stream:
int[] nums = {1, 2, 3, 4, 5};
Arrays.stream(nums).skip(3).forEach(System.out::println);
2.3 Terminal操作
2.3.1 非短路操作
这些操作又称为“聚合操作”,因为提供的功能跟sql里的聚合操作很类似。
2.3.1.1 forEach
对得到的流进行遍历操作,比如上面例子中的打印流中的每个元素。
2.3.1.2 reduce
reduce操作意思是聚合操作,可以实现从Stream中根据指定的计算方式生产一个计算结果,之前提到count、min和max方法也是聚合操作,因为常用而被纳入标准库中。事实上,这些方法都是reduce操作。
reduce方法有三个重载方法:
Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
(1)Optional
主要实现了“累加”的效果,这里的“累加”不仅是单纯的相加,任何操作如果有在之前的计算结果上再执行相同的计算模式,都可以使用reduce方法。
举个例子,实现1到5的数字累加,代码如下:
public class StreamReduceDemo {
public static void main(String[] args) {
int[] arrays = new int[]{1, 2, 3, 4, 5};
int res = Arrays.stream(arrays).reduce((a, b) -> a + b).getAsInt();
// 上面的写法可以简化成如下写法,为了说明a,b两个参数的意义用上面的写法讲解
// int res = Arrays.stream(arrays).reduce(Integer::sum).getAsInt();
System.out.print(res);
}
}
例子中lambada表达式的a参数是表达式的执行结果的缓存,也就是表达式这一次的执行结果会被作为下一次执行的参数,而第二个参数b则是依次为stream中每个元素。如果表达式是第一次被执行,a则是stream中的第一个元素,b是stream中的第二个元素。
(2)T reduce(T identity, BinaryOperator
与上面方法的实现的唯一区别是它首次执行时表达式第一次参数并不是stream的第一个元素,而是通过第一个参数identity来指定,但要注意并行计算和非并行计算的结果是不一样的,当用parallelStream时第一个参数identity要慎用!
举例:计算从10开始,依次累加1-5的数字:
public class StreamReduceDemo {
public static void main(String[] args) {
int[] arrays = new int[]{1, 2, 3, 4, 5};
int res = Arrays.stream(arrays).reduce(10, (a, b) -> a + b);
System.out.print(res);
}
}
仅需要将第一个入参指定为起始数字10即可。
(3) U reduce(U identity,BiFunction
第三种方法更多的应用场景是返回的计算结果和stream中元素的类型不一样,需要转换的场景。
举例:现在有一个元素类型为Integer的list,需要转化为元素类型为String的list,即[1, 2, 3] -> [“1”, “2”, “3”]:
public class StreamReduceDemo {
public static void main(String[] args) {
List<Integer> list1 = Arrays.asList(1, 2, 3, 4, 5);
List<String> list2 = list1.stream().reduce(new ArrayList<String>(), (a, b) -> {
a.add("element-" + b);
return a;
}, (a, b) -> null);
System.out.print(list2);
}
}
- 第一个参数传入一个空的ArrayList
(),即初始值就是这个,也指定了我要返回的list到底是什么类型; - 第二个参数里,a代表往这个ArrayList
()里add元素后的list,b代表stream里每个Integer类型的值,跟前面两种重载方法的参数意义是一样的; 第三个参数如果不是并行的stream,指定为(a, b) -> null即可,网上博客里说随便指定什么都行,但是当是并行的stream时这个参数代表将并行的stream合并的意思,这种情况我目前没遇到过,目前仅遇到了stream元素类型需要转换的场景。
2.3.1.3 max/min
统计流中的最大值和最小值。max/min方法根据指定的Comparator(可选),返回一个Optional,该Optional中的value值就是Stream中最大/最小元素。
举例:统计数组里元素的最小值:public class IntermediateDemo { public static void main(String[] args) { int[] nums = {1, 2, 3, 4, 5}; System.out.println(Arrays.stream(nums).min().getAsInt()); } }举例:统计student列表里age最大的student:
public class StudentSortDemo { public static void main(String[] args) { List<Student> studentList = new ArrayList<>(); studentList.add(new Student("Jerry", 27, 1)); studentList.add(new Student("Jerry", 27, 2)); studentList.add(new Student("Jerry", 28, 3)); studentList.add(new Student("Cissie", 27, 4)); System.out.println(studentList.stream().max(Comparator.comparing(Student::getAge)).get()); } }2.3.1.4 count
返回流中元素的个数。
举例:Integer[] nums = {1, 2, 3, 4, 5}; Stream<Integer> stream = Arrays.stream(nums); System.out.println(stream.count());2.3.2 短路操作
2.3.2.1 allMatch anyMatch noneMatch
allMatch:接收一个Predicate函数接口的lambda表达式,当流中每个元素都符合该断言时才返回true,否则返回false;
- anyMatch:接收一个Predicate函数接口的lambda表达式,只要流中有一个元素满足该断言则返回true,否则返回false;
- noneMatch:接收一个Predicate函数接口的lambda表达式,当流中每个元素都不符合该断言时才返回true,否则返回false。
举例:
public class terminalDemo {
public static void main(String[] args) {
Integer[] nums = {1, 2, 3, 4, 5};
Stream<Integer> stream = Arrays.stream(nums);
System.out.println("流中所有元素都大于0,返回true");
System.out.println(stream.allMatch(num -> num > 0));
System.out.println("流中所有元素至少有一个大于3,返回true");
System.out.println(stream.anyMatch(num -> num > 3));
System.out.println("流中所有元素均没有大于6,返回true");
System.out.println(stream.noneMatch(num -> num > 6));
}
}
2.3.2.2 findAny findFirst
- findAny:返回流中的任意元素;
- findFirst:返回流中第一个元素。
举例:
public class terminalDemo {
public static void main(String[] args) {
Integer[] nums = {1, 2, 3, 4, 5};
Stream<Integer> stream = Arrays.stream(nums);
System.out.println("返回流中的任意元素");
System.out.println(stream.findAny().get());
System.out.println("返回流中的第一个元素");
System.out.println(stream.findFirst().get());
}
}
3、Collectors工具库
在java stream中,我们通常需要将处理后的stream转换成集合类,这个时候就需要用到stream.collect方法,collect方法需要传入一个Collector类型的接口,java提供了简单的Collectors工具类来方便我们构建Collector。Collectors工具类有很多,下面仅介绍比较常用的几个。
3.1 Collectors.toList()
将stream转化为ArrayList,注意仅支持ArrayList,如果是LinkedList则不行。这个方法也是使用最多的Collectors工具库。
举例:
public class CollectorsDemo {
public static void main(String[] args) {
Integer[] arrays = new Integer[]{1, 2, 3, 4, 5};
List<Integer> list = Arrays.stream(arrays).collect(Collectors.toList());
System.out.print(list);
}
}
3.2 Collectors.toSet()
将stream转化成Set,注意这里转换后的set是HashSet,如果需要特别指定set,那么需要使用toCollection方法。
举例:
public class CollectorsDemo {
public static void main(String[] args) {
Integer[] arrays = new Integer[]{1, 2, 2, 4, 4};
Set<Integer> set = Arrays.stream(arrays).collect(Collectors.toSet());
System.out.print(set);
}
}
3.3 Collectors.toMap()
Collectors.toMap 有三个重载方法:
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper);
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction);
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier);
参数含义分别是:
- keyMapper:Key 的映射函数;
- valueMapper:Value 的映射函数;
- mergeFunction:当 Key 冲突时,调用的合并方法;
- mapSupplier:Map 构造器,在需要返回特定的 Map 时使用。
Collectors.toMap的一个典型的应用场景是list转换成map。
3.3.1 2个参数的重载方法
举例:
POJO类如下:
@Data
@AllArgsConstructor
public class Employee {
private String name;
private String department;
}
需求是:将Employee实例组成的list转换成如下的map:
Develop -> Jerry
Test -> Cissie
Product -> Jason
代码:
public class CollectorToMapDemo {
public static void main(String[] args) {
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Jerry", "Develop"));
employeeList.add(new Employee("Cissie", "Test"));
employeeList.add(new Employee("Jason", "Product"));
Map<String, String> map = employeeList.stream().collect(Collectors.toMap(Employee::getDepartment,
Employee::getName));
System.out.println(map);
}
}
结果:
{Develop=Jerry, Test=Cissie, Product=Jason}
注意:2个参数的Collectors.toMap方法的前提是生成的map的key不能重复,否则会抛异常,即例子里的部门属性值是唯一的。
3.3.2 3个参数的重载方法
接上面的例子,当map的key有重复怎么处理?第三个参数mergeFunction就是指定key冲突时的处理方法,比如上面例子中,当部门属性冲突时,value指定重复的属性对应的name值字符串拼接:
public class CollectorToMapDemo {
public static void main(String[] args) {
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Jerry", "Develop"));
employeeList.add(new Employee("Cissie", "Test"));
employeeList.add(new Employee("Tom", "Test"));
employeeList.add(new Employee("Jack", "Develop"));
employeeList.add(new Employee("Jason", "Product"));
Map<String, String> map = employeeList.stream().collect(Collectors.toMap(Employee::getDepartment,
Employee::getName, (e1, e2) -> (e1 + "&" + e2)));
System.out.println(map);
}
}
结果:
{Develop=Jerry&Jack, Test=Cissie&Tom, Product=Jason}
注意:第三个参数里的lambda表达式里的(e1, e2)对应的生成的map里的value,即name。
3.3.3 4个参数的重载方法
第四个参数(mapSupplier)用于自定义返回 Map 类型,比如我们希望返回的 Map 是根据 Key 排序的,可以使用如下写法:
public static void main(String[] args) {
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Jerry", "Develop"));
employeeList.add(new Employee("Cissie", "Test"));
employeeList.add(new Employee("Tom", "Test"));
employeeList.add(new Employee("Jack", "Develop"));
employeeList.add(new Employee("Jason", "Product"));
Map<String, String> map = employeeList.stream().collect(Collectors.toMap(Employee::getDepartment,
Employee::getName, (e1, e2) ->e1, TreeMap::new));
System.out.println(map);
}
结果:
{Develop=Jerry, Product=Jason, Test=Cissie}
第三个参数(e1, e2) -> e1,即当key冲突时,保留之前的value。
3.4 Collectors.groupingBy()
Collectors.groupingBy有3种重载函数,如下:
Collector<T, ?, Map<K, List<T>>>
groupingBy(Function<? super T, ? extends K> classifier);
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream);
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream);
得到的map是可以自定义的,即指定map的key和value是如何生成的,参考6.1的案例体会一下。
3.4.1 1个参数的重载方法
举例:
按照Employee的department属性分类,最后得到一个map,map的key是department,value是这个department对应的Employee实例:
public static void main(String[] args) {
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Jerry", "Develop", 1));
employeeList.add(new Employee("Cissie", "Test", 2));
employeeList.add(new Employee("Tom", "Test", 3));
employeeList.add(new Employee("Jack", "Develop", 4));
employeeList.add(new Employee("Jason", "Product", 5));
Map<String, List<Employee>> groupByMap =
employeeList.stream().collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(groupByMap);
}
结果:
{Develop=[Employee(name=Jerry, department=Develop, id=1), Employee(name=Jack, department=Develop, id=4)], Test=[Employee(name=Cissie, department=Test, id=2), Employee(name=Tom, department=Test, id=3)], Product=[Employee(name=Jason, department=Product, id=5)]}
3.4.2 2个参数的重载方法
举例:
按照Employee的department属性分类,最后得到一个map,map的key是department,value是这个department对应的Employee实例的个数:
public static void main(String[] args) {
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Jerry", "Develop", 1));
employeeList.add(new Employee("Cissie", "Test", 2));
employeeList.add(new Employee("Tom", "Test", 3));
employeeList.add(new Employee("Jack", "Develop", 4));
employeeList.add(new Employee("Jason", "Product", 5));
Map<String, Long> groupByMap =
employeeList.stream().collect(Collectors.groupingBy(Employee::getDepartment, Collectors.counting()));
System.out.println(groupByMap);
}
结果:
{Develop=2, Test=2, Product=1}
3.5 Collectors.partitioningBy()
partitioningBy是一个特别的groupingBy,partitioningBy返回的是一个Map,这个Map是以boolean值为key,从而将stream分成两部分,key为true的value是匹配partitioningBy条件的list,key为false的value是不匹配partitioningBy条件的list。
举例:将employeeList分成两组,一组是id属性大于3的,一组是id属性小于等于3的:
public static void main(String[] args) {
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("Jerry", "Develop", 1));
employeeList.add(new Employee("Cissie", "Test", 2));
employeeList.add(new Employee("Tom", "Test", 3));
employeeList.add(new Employee("Jack", "Develop", 4));
employeeList.add(new Employee("Jason", "Product", 5));
Map<Boolean, List<Employee>> map =
employeeList.stream().collect(Collectors.partitioningBy(employee -> employee.getId() > 3));
System.out.println(map);
}
结果:
{false=[Employee(name=Jerry, department=Develop, id=1), Employee(name=Cissie, department=Test, id=2), Employee(name=Tom, department=Test, id=3)], true=[Employee(name=Jack, department=Develop, id=4), Employee(name=Jason, department=Product, id=5)]}
4、Parallel Stream
parallelStream不需要添加其他多线程代码就可以实现流的并行处理,其底层使用Fork/Join框架实现。
举例:
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream().forEach(number -> System.out.print(number + " "));
}
结果:
6 5 8 9 7 4 1 2 3
结果并没有按顺序一次输出1-9,原因是有多个工作线程在打印这些数字,做如下处理可以显示处理:
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream().forEach(number -> System.out.println(Thread.currentThread().getName() + "-" + number));
}
结果:
main-6
main-5
ForkJoinPool.commonPool-worker-11-4
ForkJoinPool.commonPool-worker-11-1
main-2
ForkJoinPool.commonPool-worker-11-9
ForkJoinPool.commonPool-worker-2-8
ForkJoinPool.commonPool-worker-4-7
ForkJoinPool.commonPool-worker-9-3
可见,由main线程和worker线程分别打印数字,整个打印过程时并行的。
什么时候使用stream,什么时候使用parallelStream呢?
我们可以从以下几个角度考虑使用场景:
- 是否需要并行?
- 任务之间是否是独立的?是否会引起任何竞态条件?
- 结果是否取决于任务的调用顺序?
思考结论:
- 对于问题1,当数据量不大时,顺序执行往往比并行执行更快,毕竟准备线程池和其它相关资源也是需要时间的;但是当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择,通常而言,将这类程序并行化之后,执行速度会提升好几个等级;
- 对于问题2,如果任务之间是独立的,并且代码中不涉及到对同一个对象的某个属性或者某个变量的更新操作,那么代码是可以被并行化的;
- 对于问题3,由于在并行环境中任务的执行顺序是不确定的,因此对于依赖于顺序的任务而言,并行化也许不能给出正确的结果。
5、Stream性能分析
具体过程可以阅读参考文献中的这篇文章:Java Stream API性能测试,这里直接上测试结果:
- 对于简单操作,比如最简单的遍历,Stream串行API性能明显差于for循环迭代,但并行的Stream API能够发挥多核特性;
- 对于复杂操作,Stream串行API性能可以和for循环迭代的效果匹敌,在并行执行时Stream API效果远超手动实现。
因此在实际使用时,选择stream还是普通的for循环,给出几点建议:
- 对于简单操作推荐使用外部for循环手动实现,
- 对于复杂操作,推荐使用Stream API;
- 在多核情况下,推荐使用并行Stream API来发挥多核优势;
- 单核情况下不建议使用并行Stream API。
如果出于代码简洁性考虑,使用Stream API能够写出更短的代码。即使是从性能方面说,尽可能的使用Stream API也有另外一个优势,那就是只要Java Stream类库做了升级优化,代码不用做任何修改就能享受到升级带来的好处。
6、实战Demo
这里总结一些工作中遇到的需要借助stream api处理的场景。
6.1 合并多个相同属性的对象集合
场景描述:从数据库读取若干条云主机的账单记录到内存,需要将regionId、ordId(组织id)和cpu(cpu核数)都相同的DTO的expense(计费)相加,并将累加结果转换成返回给前端的VO,即根据这三个维度去聚合账单并set一些其他属性字段拼成最终的VO。
云主机账单DTO如下:
package stream;
import lombok.AllArgsConstructor;
import lombok.Data;
import java.math.BigDecimal;
@Data
@AllArgsConstructor
public class ECSBillDTO {
private String regionId;
private String ordId;
private int cpu;
private BigDecimal expense;
}
返回给前端的账单VO如下:
package stream;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.math.BigDecimal;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ECSBillVO {
private String regionId;
private String ordId;
private int cpu;
private BigDecimal expense;
// 相比DTO多加的属性字段
private String createTime;
}
main:
public class streamMain {
public static void main(String[] args) {
// 生成数据
List<ECSBillDTO> ecsBillList = new ArrayList<>();
ecsBillList.add(new ECSBillDTO("region01", "org01", 1, new BigDecimal("100")));
ecsBillList.add(new ECSBillDTO("region01", "org01", 2, new BigDecimal("200")));
ecsBillList.add(new ECSBillDTO("region01", "org01", 4, new BigDecimal("400")));
ecsBillList.add(new ECSBillDTO("region01", "org02", 4, new BigDecimal("400")));
ecsBillList.add(new ECSBillDTO("region01", "org02", 4, new BigDecimal("400")));
ecsBillList.add(new ECSBillDTO("region02", "org01", 2, new BigDecimal("200")));
ecsBillList.add(new ECSBillDTO("region02", "org02", 4, new BigDecimal("400")));
// 调用函数处理
List<ECSBillVO> results = getBillList(ecsBillList);
System.out.println(results);
}
private static List<ECSBillVO> getBillList(List<ECSBillDTO> ecsBillList)
{
List<ECSBillVO> resultList = new ArrayList<>();
ecsBillList.stream().collect(Collectors.groupingBy(ecsBillDTO ->
ecsBillDTO.getCpu() + ecsBillDTO.getOrdId() + ecsBillDTO.getRegionId(), Collectors.toList()))
.forEach((k, v) -> v.stream().reduce((a, b) ->
new ECSBillDTO(a.getRegionId(), a.getOrdId(), a.getCpu(), a.getExpense().add(b.getExpense()))
).map(ecsBillDTO -> {
ECSBillVO ecsBillVO = new ECSBillVO();
try {
BeanUtils.copyProperties(ecsBillVO, ecsBillDTO);
} catch (IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
ecsBillVO.setCreateTime(new Date().toString());
return ecsBillVO;
}).ifPresent(resultList::add));
return resultList;
}
}
结果:
[ECSBillVO(regionId=region02, ordId=org01, cpu=2, expense=200, createTime=Mon Jan 18 00:40:40 CST 2021), ECSBillVO(regionId=region02, ordId=org02, cpu=4, expense=400, createTime=Mon Jan 18 00:40:40 CST 2021), ECSBillVO(regionId=region01, ordId=org01, cpu=2, expense=200, createTime=Mon Jan 18 00:40:40 CST 2021), ECSBillVO(regionId=region01, ordId=org01, cpu=1, expense=100, createTime=Mon Jan 18 00:40:40 CST 2021), ECSBillVO(regionId=region01, ordId=org01, cpu=4, expense=400, createTime=Mon Jan 18 00:40:40 CST 2021), ECSBillVO(regionId=region01, ordId=org02, cpu=4, expense=800, createTime=Mon Jan 18 00:40:40 CST 2021)]
alibaba Java编程规范里禁止使用BeanUtils方法进行属性拷贝了,原因是性能低下,推荐使用Spring的BeanUtils。
参考:
Java 8 stream的详细用法
Java8中Stream详细用法大全
Java 8系列之Stream的基本语法详解
java stream中Collectors的用法
Java 8 中的 Streams API 详解
java stream api中的reduce方法使用 大侠陈 关注 赞赏支持
java 8 stream reduce详解和误区
Java8 中 List 转 Map(Collectors.toMap) 使用技巧
深入浅出parallelStream
Java Stream API性能测试
Java8中用Lambda表达式合并多个相同属性的对象集合
Java-Stream重用流

若有收获,就点个赞吧
0 人点赞
