1. 扩容
- 垂直扩容(纵向疒展):提高系统部件能力
- 水平扩容(横向扩展):增加更多系统成员来实现
扩容 - 数据库
- 读操作扩展:memcache、redis、CND 等缓存
- 写操作扩展:Cassandra、Hbase 等
2. 缓存
2.1 缓存特征
- 命中率 = 命中数 / (命中数+没有命中数)
- 最大元素(空间):缓存中可以存放的最大元素的数量,一旦超过这个值,将会触发缓存清空策略。
- 清空策略:
- FIFO(先进先出):比较缓存元素的创建时间,在数据实时性有要求时可以选用改策略,保障最新数据可用
- LUF(最少使用策略):无论是否过期,根据元素的使用次数来判断,清除使用次数最少的元素释放空间。主要比较命中次数,在高频数据有效场景下使用。
- LRU(最近最少使用策略):无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。主要比较元素最近一次被get使用时间,在热线数据场景下使用,优先保证热点数据的有效性
- LFU 最不经常使用
- 过期时间、随机等
2.2 缓存命中率的影响因素
- 业务场景和业务需求
- 缓存适合读多写少的业务场景
- 缓存的设计(粒度和策略)
- 缓存的粒度越小,命中率越高
- 缓存容量和基础设施
高频访问且时效性要求不高的热点数据上使用
2.3 缓存的分类和应用场景
- 本地绶存:编程实现(成员变量、局部变量、静态变量)、Guava Cache
- 分布式缓存:Memcache、Redis
2.4 Guava Cache
是谷歌开源的 Guava 工具库的一款缓存工具,设计灵感来源于 ConcurrentHashMap。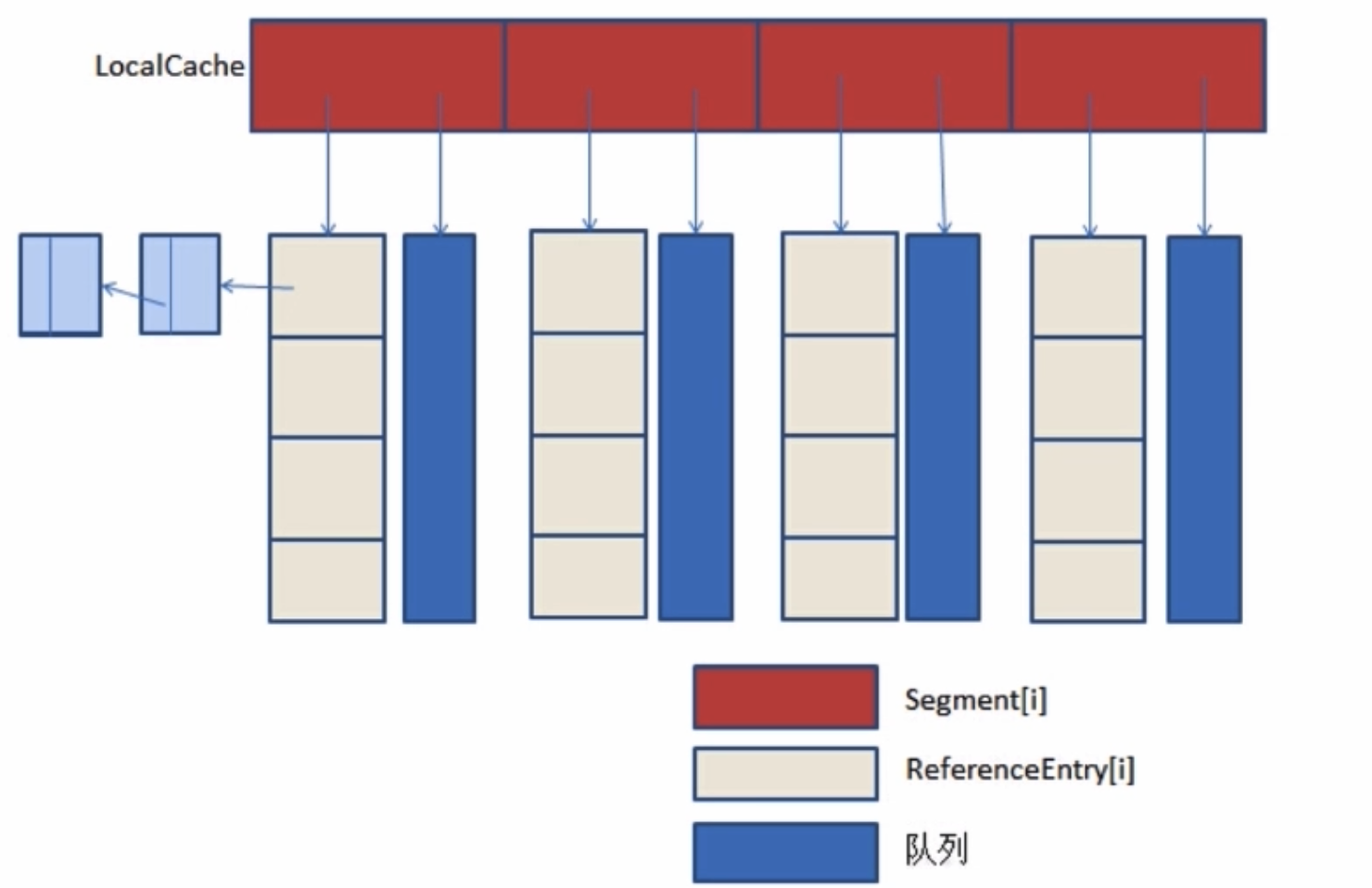
2.5 高并发场景下的常见问题
2.5.1 缓存一致性
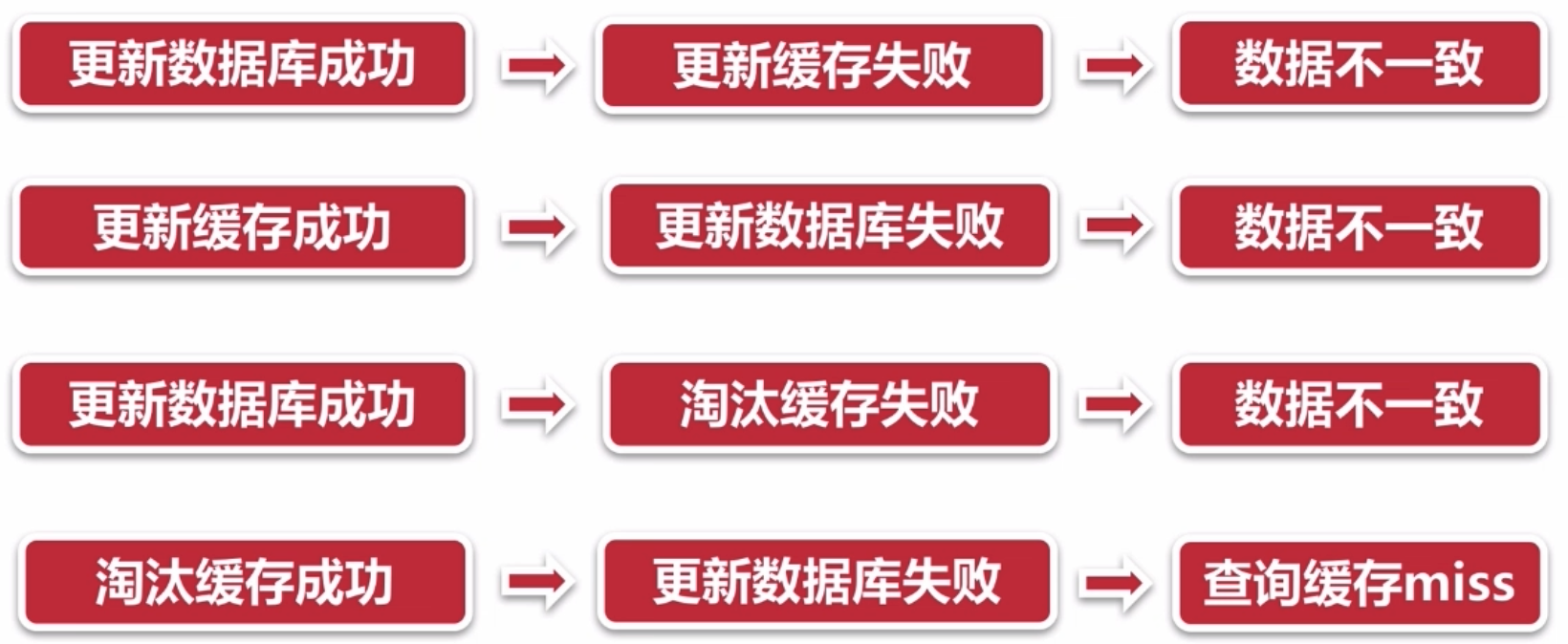
2.5.2 缓存并发问题
2.5.3 缓存穿透问题
在高并发场景下,如果某一个 key 被高并发的访问没有被命中,出于容错的考虑会尝试去数据库获取,从而导致大量请求达到数据库,当该 key 对应的数据为空的情况下,导致执行了很多不必要的查询操作,产生了巨大的冲击和压力。
解决方式:
- 对查询结果为空的对象也进行缓存,如果是集合的话,可以缓存一个空的集合。这种方式实现成本较低,适合命中不高,但可能被频繁更新的数据
- 单独过滤处理。对所有可能请求为空的 key 统一存放,并在请求前做拦截,避免请求传到后端数据库。实现相对复杂,适合命中不高,更新不频繁的数据(最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。)
2.5.4 缓存的雪崩现象
缓存的颠簸问题(缓存抖动):一种比雪崩更轻微的故障,一般是由于缓存节点故障导致。业内一般做法是通过一致性 hash 算法解决。
缓存雪崩:由于缓存的原因导致大量数据到达后端数据库,导致数据库崩溃的灾难。
解决方式:
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
这里分享一个简单方案就是讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
2.5.5 缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回射到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案
**
- 使用互斥锁(mutex key)
**
业界比较常用的做法,是使用 mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。在redis2.6.1之前版本未实现setnx的过期时间,所以这里给出两种版本代码参考:
//2.6.1前单机版本锁String get(String key) {String value = redis.get(key);if (value == null) {if (redis.setnx(key_mutex, "1")) {// 3 min timeout to avoid mutex holder crashredis.expire(key_mutex, 3 * 60)value = db.get(key);redis.set(key, value);redis.delete(key_mutex);} else {//其他线程休息50毫秒后重试Thread.sleep(50);get(key);}}}
新版本代码:
public String get(key) {String value = redis.get(key);if (value == null) { //代表缓存值过期//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load dbif (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功value = db.get(key);redis.set(key, value, expire_secs);redis.del(key_mutex);} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可sleep(50);get(key); //重试}} else {return value;}}
memcache代码:
if (memcache.get(key) == null) {// 3 min timeout to avoid mutex holder crashif (memcache.add(key_mutex, 3 * 60 * 1000) == true) {value = db.get(key);memcache.set(key, value);memcache.delete(key_mutex);} else {sleep(50);retry();}}
2. “提前”使用互斥锁(mutex key)
**
在value内部设置1个超时值(timeout1), timeout1比实际的memcache timeout(timeout2)小。
当从cache读取到timeout1发现它已经过期时候,马上延长timeout1并重新设置到cache。然后再从数据库加载数据并设置到cache中。
伪代码如下:
v = memcache.get(key);if (v == null) {if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {value = db.get(key);memcache.set(key, value);memcache.delete(key_mutex);} else {sleep(50);retry();}} else {if (v.timeout <= now()) {if (memcache.add(key_mutex, 3 * 60 * 1000) == true) {// extend the timeout for other threadsv.timeout += 3 * 60 * 1000;memcache.set(key, v, KEY_TIMEOUT * 2);// load the latest value from dbv = db.get(key);v.timeout = KEY_TIMEOUT;memcache.set(key, value, KEY_TIMEOUT * 2);memcache.delete(key_mutex);} else {sleep(50);retry();}}}
3. “永远不过期”
这里的“永远不过期”包含两层意思:
(1) 从redis上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。
(2) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期
从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
String get(final String key) {V v = redis.get(key);String value = v.getValue();long timeout = v.getTimeout();if (v.timeout <= System.currentTimeMillis()) {// 异步更新后台异常执行threadPool.execute(new Runnable() {public void run() {String keyMutex = "mutex:" + key;if (redis.setnx(keyMutex, "1")) {// 3 min timeout to avoid mutex holder crashredis.expire(keyMutex, 3 * 60);String dbValue = db.get(key);redis.set(key, dbValue);redis.delete(keyMutex);}}});}return value;}
```
4. 资源保护
采用 netflix 的 hystrix,可以做资源的隔离保护主线程池,如果把这个应用到缓存的构建也未尝不可。
四种解决方案:没有最佳只有最合适
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 简单分布式锁(Tim yang) | 1. 思路简单 2. 保证一致性 |
1. 代码复杂度增大 2. 存在死锁的风险 3. 存在线程池阻塞的风险 |
| 加另外一个过期时间(Tim yang) | 1. 保证一致性 | 同上 |
| 不过期(本文) | 1. 异步构建缓存,不会阻塞线程池 | 1. 不保证一致性。 2. 代码复杂度增大(每个value都要维护一个timekey)。 3. 占用一定的内存空间(每个value都要维护一个timekey)。 |
| 资源隔离组件hystrix(本文) | 1. hystrix技术成熟,有效保证后端。 2. hystrix监控强大。 |
1. 部分访问存在降级策略。 |
四种方案来源网络,详文请链接:
3. 消息队列
消息队列特性
- 业务无关,只做消息分发
- FIFO,先投递先到达
- 容灾:消息的动态增删和消息的持久化
- 性能:吞吐量提升,系统内部通信效率提高
为什么需要消息队列
- 生产和消费的速度或稳定性等因素不一致
消息队列的好处
- 业务解耦
- 最终一致性
- 用记录和补偿的方式来处理,在做所有的不确定事情之前,先把事情记录下来,然后再去做不确定的事。结果分三种:成功;失败;不确定(超时)。对于失败和不确定,可以用定时任务的方式,重新做一遍。
- 比如:比如系统A扣钱并通知系统B这件事情记录到库里面。也可以把通知B系统加钱和通知成功放到一个本地事务里,通知成功则删除这条记录,通知失败或者不确定,依靠定时任务补偿性的通知我们,直到我们把状态更新成正确的为止。
- 广播
- 错峰于流控
- 当上下游系统处理能力存在差距的时候,利用消息队列做一个通用的漏斗,在下游有能力处理的时候再进行分发
4. 应用拆分
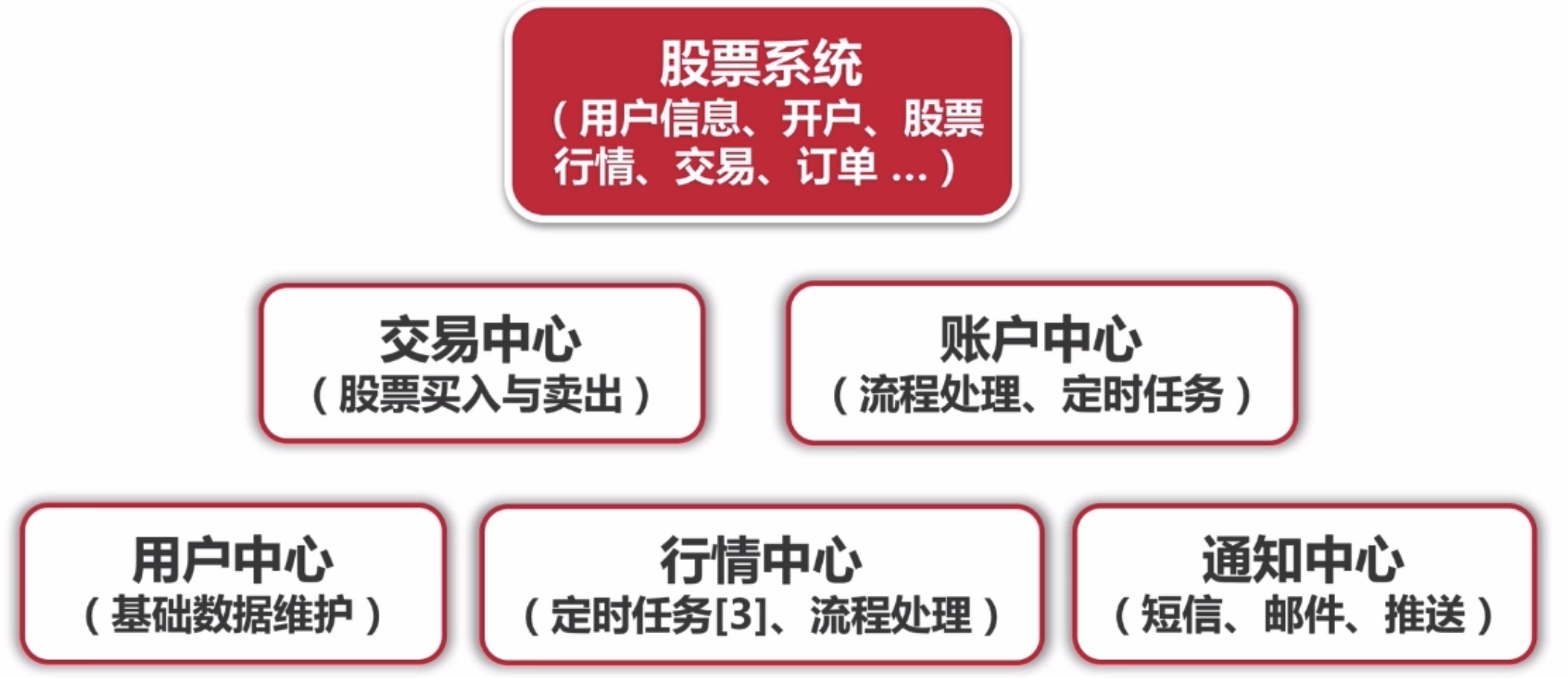
股票系统只是调用其他系统的接口。用 dubbo 进行相互调用。
应用拆分的原则:
- 业务优先
- 优先按照业务边界进行切割
- 循序渐进(拆分 + 测试)
- 兼顾技术:重构、分层
- 可靠测试
应用拆分的思考:
- 应用间的通信:RPC(dubbo)、消息队列
- 应用之间的数据库设计:每个应用都有独立的数据库
- 避免事务操作跨应用(分布式事务很消耗资源)
5. 应用限流
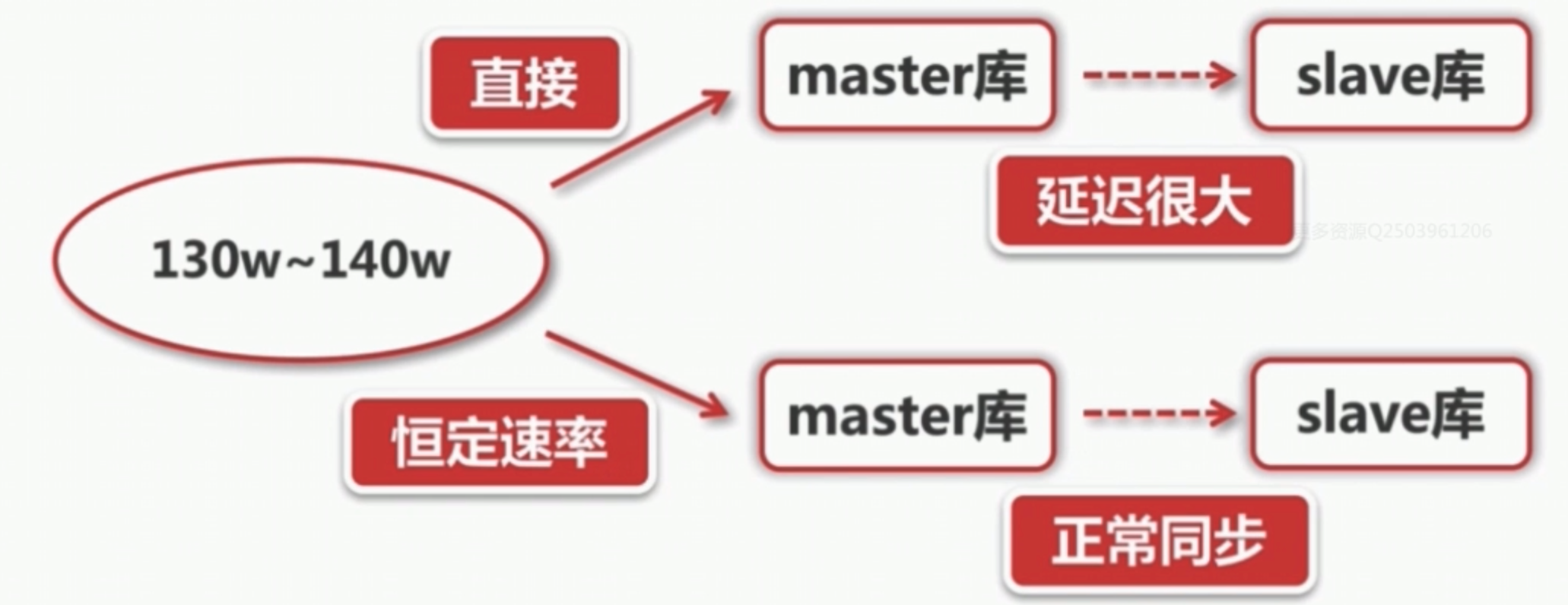
改为每秒钟插入400条。
应用限流 - 算法
- 计数器法
- 滑动窗口
- 漏桶算法
- 令牌桶算法
6. 服务降级和熔断
- 服务降级
- 自动降级:超时、失败次数、故障、限流
- 人工降级:秒杀、双 11 大促等
- 服务熔断(过载保护)
7. 数据库的分库分表
- 数据库瓶颈
- 单个库数据量太大(1T ~ 2T):多个库
- 单个数据库服务器压力过大、读写瓶颈:多个库
- 单个表数据量过大:分表
数据库切库
数据库一般使用读写分离,一个主库,多个从库(负载均衡),使用技术是 注解 + springAOP(链接)
- 主库主要负责数据更新和实时数据查询
- 从库负责非实时数据查询
数据库分表
- 横向(水平)分表与纵向(垂直)分表
- 数据库分表:mybatis 分表插件 shardbatis2.0
8 高可用
- 任务调度系统分布式:elastic-job + zookeeper
- 主备切換:apache curator + zookeeper 分布式锁实现
- 监控报警机制

若有收获,就点个赞吧
0 人点赞
