- 📖基础认知
- 目标检测
- 上采样(UnSampling)下采样(DownSampling)上池化(UnPooling)转置卷积(Transposed Convolution)
- Dropout
- numpy
- matplotlib
- PyTorch
- ⚡模型认知
- 🐱🏍数据处理
- 将图像裁剪为重复率为0.25的256*256的数据集
- 数据筛选
- Standard parties
- Third parties
- Configuration
- -- coding: utf-8 --
- 制作YOLOv5格式的样本数据集
- Standard parties
- Third parties
- Standard parties
- Third parties
- (506.0000, 330.0000, 528.0000, 348.0000) -> (520.4747, 381.5080, 540.5596, 398.6603)
- -- coding: utf-8 --
- sets = [(‘2007’, ‘train’), (‘2007’, ‘val’), (‘2007’, ‘test’)]
- VOC数据集类型:
- classes = [“aeroplane”, “bicycle”, “bird”, “boat”, “bottle”, “bus”, “car”, “cat”, “chair”, “cow”, “diningtable”,
- “nodogse”, “horse”, “motorbike”, “person”, “sheep”, “nose”, “sofa”, “train”, “tvmonitor”]
- 完成制作
- 3. 训练结果查看
- 4. 总结
- 5. 后续计划
- YOLOv5 [2021.02.28]
- YOLOv5 [2021.04.02]
- YOLOv5 [2021.04.06]
- YOLOv5 [2021.04.16]
文章记录此项目的模型训练研究进展/思考/总结/计划,除了记录训练模型的内容与结果之外,尽可能地以通俗易懂的内容让成员能够迅速配置出对应训练环境,开展相关训练,共同探讨项目发展
📖基础认知
深度学习
端到端的深度学习(end-to-end deep learning)
传统的深度学习流程是比较复杂的,往往由多个独立模块组合而成,并且会执行多个步骤,每个步骤都是一个独立的任务。如自然语言处理,包括分词、词性标注、句法分析、语义分析等,每个步骤得到的结果都会对下一个步骤产生影响,从而影响这个模型训练结果。但这并非端到端的深度学习。
如果说将输入端到输出端得到的一个预测结果,与真实值比较得到一个误差值,该误差会在每一层中进行传播(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束,这便是端到端的深度学习。
端到端的深度学习在可能需要大量的数据训练,模型才有比较好的结果,否则使用传统的“流水线”方式更加合适。
组件的合理性和完备性及其适用性也是我们去考虑要不要舍弃去进行端到端学习的一个考量。
张量操作
element-wise
element-wise是在神经网络编程中常用的张量操作。其定义为:
An element-wise operation operates on corresponding elements between tensors. element-wise是两个张量之间的操作,它是对相应张量的对应元素中进行操作
t1 = torch.tensor([[1, 2],[3, 4]], dtype=torch.float32)t2 = torch.tensor([[9, 8],[7, 6]], dtype=torch.float32)
与对矩阵进行操作类型类似,张量也能够进行算数运算,张量中的每个元素也能通过索引获取到元素值。
print(t1[0]) // tensor([1., 2.])print(t1[0][0]) // tensor([1.])print(t1[0]) // tensor([9., 8.])print(t1[0][0]) // tensor([9.])
算术运算是基于Element-Wise的运算,element-wise可以进行算术操作
print(t1+t2) // tensor([[10., 10.],[10., 10.]])
如果与标量进行element-wise操作,则会将标量广播(Broadcasting)变换成相匹配形状的张量,再进行算术操作
print(t1+2) // tensor([[3., 4.],[5., 6.]])// 实际操作print(t1 + torch.tensor(np.broadcast_to(2, t1.shape),dtype=torch.float32))// tensor([[3., 4.],[5., 6.]])
如果与其他阶数不一致的张量进行element-wise操作,则会将低阶张量进行广播(Broadcasting)变换,以匹配高阶张量的形状,再进行算术操作;具体操作是使用broadcast_to() 的numpy函数检查broadcast转换
t1 = torch.tensor([[1,1],[1,1]], dtype=torch.float32)t2 = torch.tensor([2,4], dtype=torch.float32)print(t1.shape) // torch.Size([2, 2])print(t2.shape) // torch.Size([2])print(p.broadcast_to(t2.numpy(), t1.shape))// array([[2., 4.],// [2., 4.]], dtype=float32)print(t1 + t2)//tensor([[3., 5.],// [3., 5.]])
不仅只有算术运算,element-wise还能够实现逻辑判断(大于、小于…)
损失函数
Classification Error(分类错误率)

Mean Squared Error (均方误差)
较为常见的损失函数:预测值与真实值的差值的平方,再累加求和,最后取平均值
均方误差常被被用于表示预测值和实际值相差的程度
Corss Entropy(交叉熵)
二分类:
在二分类的情况下,模型最后需要预测的结果只有两种情况,对于每个类别能够预测到的概率为 或者
或者 。此时表达式为:
。此时表达式为:
其中:
 ——表示样本i的label,正样本为1,负样本为0
——表示样本i的label,正样本为1,负样本为0 ——表示样本i预测为正样本的概率
——表示样本i预测为正样本的概率
因为 是经过激活函数的输出,所以在0~1之间,因此对于简单正样本而言,输出概率越大,损失越小;对于负样本而言,数据概率越小,损失越小。但是此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。之后便出现了Focal Loss
是经过激活函数的输出,所以在0~1之间,因此对于简单正样本而言,输出概率越大,损失越小;对于负样本而言,数据概率越小,损失越小。但是此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。之后便出现了Focal Loss
多分类:
多分类是对二分类进行扩展:
其中:
 ——表示类别的数量
——表示类别的数量 ——表示 指示变量(0或1),如果该类别c和样本i的类别相同就是1,否则是0
——表示 指示变量(0或1),如果该类别c和样本i的类别相同就是1,否则是0-
参考资料
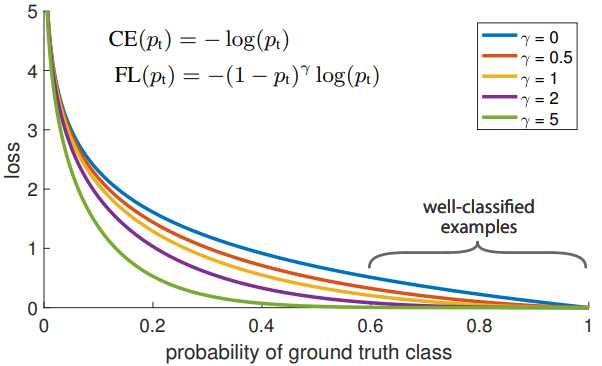
Focal Loss
Focal Loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数是在标准交叉熵损失的基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更加专注于难分类的样本。

其中:  ——表示样本i预测为正样本的概率
——表示样本i预测为正样本的概率 ——参数,用于控制损失函数的值(
——参数,用于控制损失函数的值( 时最优)
时最优) ——平衡因子,用来平衡正负样本比例不均
——平衡因子,用来平衡正负样本比例不均
 ——表示 对于预测样本i属于类别c的预测概率
——表示 对于预测样本i属于类别c的预测概率
参考资料
Focal Loss理解
Focal Loss
Focal Loss for Dense Object Detection.pdf
激活函数
Sigmoid
Sigmoid是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外,(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。
Sigmoid的定义:
对其进行求导,得到:
可以看出,sigmoid函数连续,光滑,严格单调,以(0,0.5)中心对称,是一个非常良好的阈值函数。Sigmoid函数的值域范围限制在(0,1)之间,我们知道[0,1]与概率值的范围是相对应的,这样sigmoid函数就能与一个概率分布联系起来了。
Sigmoid也有其自身的缺陷,最明显的就是饱和性。从上图可以看到,其两侧导数逐渐趋近于0
有这种性质的称为软饱和激活函数。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是硬饱和, 即 f′(x)=0,当f′(x)=0,当|x|>c,其中c为常数。Sigmoid 的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因
参考资料
激活函数—(Sigmoid,tanh,Relu,maxout)
Softmax
Softmax从字面上来说,可以分成soft和max两个部分。max顾名思义就是最大值的意思。
Softmax的核心在于soft,而soft可以简单理解成属于对应类别的可信度,相对于soft,便是hard,引申出来就是hardmax,比如很多场景中需要我们找出数组所有元素中值最大的元素,实质上都是求的hardmax。
Softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。通过Softmax函数就可以将多分类的输出值转换为范围在[0, 1]和为1的概率分布。
Softmax的定义:
其中:
 ——表示第i个节点的输出值
——表示第i个节点的输出值 ——表示输出节点的个数,即分类的类别个数
——表示输出节点的个数,即分类的类别个数
引入指数函数既有优点也有缺点:
- 优点
指数函数曲线呈现递增趋势,最重要的是斜率逐渐增大,也就是说在x轴上一个很小的变化,可以导致y轴上很大的变化。因此经过使用指数形式的Softmax函数能够将差距大的数值距离拉的更大。在深度学习中通常使用反向传播求解梯度进而使用梯度下降进行参数更新的过程,而指数函数在求导的时候比较方便。比如
- 缺点
当 值非常大的话,计算得到的数值也会变的非常大,数值可能会溢出。不过针对数值溢出有对应的优化方法,将每一个输出值减去输出值中最大的值。
值非常大的话,计算得到的数值也会变的非常大,数值可能会溢出。不过针对数值溢出有对应的优化方法,将每一个输出值减去输出值中最大的值。

参考资料
目标检测
常用网络(backbone)
边框(Bounding Box)
在某一个grid检测目标的情况下,获取到检测到目标的位置参数,并能够在图中标注出框选的位置
先验框(Anchor Box / Prior Bounding Box)
在众多经典的目标检测模型(Faster RCNN、SSD、YOLO v2&v3等)中,均有先验框的说法,有的论文(如Faster RCNN)中称之为Anchor(锚点),有的论文(如SSD)称之为Prior Bounding Box(先验框),实际上是同一个概念(后面内容则以Anchor表示先验框)。先验框就是提前在图像上预设好的不同大小,不同长宽比的框。先验框设置的合理与否,极大的影响着最终模型检测性能的好坏。
引入先验框是为了模型更容易学习。目标检测中模型不仅需要学习目标的类别,更需要学习到目标的位置和大小。YOLOv1是较早的one-stage目标检测方法(YOLOv1没有设计Anocher),它最后采用全连接层直接对边界框进行预测,由于各个图片中存在不同尺度和长宽比(Scales and Ratios)的物体,使得YOLOv1在训练过程中学习适应不同物体的形状比较困难,这也导致YOLOv1在精确定位方面不如Faster R-CNN。之后在YOLOv2使用Anchor boxes之后,其召回率大大提升,所以在YOLO之后的版本中,均保留了先验框。
使用使用不同尺寸和长宽比是为了得到更大的交并比(IOU)。通过设置不同的尺度的先验框,就有更高的概率出现对于目标物体有良好匹配度的先验框(体现为高IoU)。
曾经Anochor Box的尺寸一般是认为设计的(比如在SSD、Faster-RCNN中,设计了9个不同大小和宽高比的anchor),但认为设计anchor不能保证它们能很好的适合数据集,如果anchor的尺寸和目标的尺寸差异较大,则会影响模型的检测效果。目前主要使用三种方式选择Anchor Box:
- 人为经验选取
- K-Means聚类(在YOLOv2&v3中有使用)
- 作为超参数进行学习
参考资料
目标检测|Anchor(先验框)的作用
锚框(anchor box)/先验框(prior bounding box)概念介绍及其生成上采样(UnSampling)下采样(DownSampling)上池化(UnPooling)转置卷积(Transposed Convolution)
上采样和下采样是个互逆的过程,简单来说,实现的效果就是上采样将图像放大,下采样则将图像缩小。
池化也叫下采样,操作与普通卷积基本相同, 不过根据取最大值或平均值可分为最大池化(MaxPooling)和平均池化(AveragePooling), 同时无反向传播过程(无需学习参数)。上池化(UnPooling)保留位置信息补0 上采样(UnSampling)不保留位置信息直接复制 但二者均无反向传播过程(无需学习参数), 也就是对中间地带不采取过渡值只是简单处理

图(a)表示上池化UnPooling的过程,特点是在池化Maxpooling的时候保留最大值的位置信息,之后在上池化UnPooling阶段使用该信息扩充Feature Map,除最大值位置以外,其余补0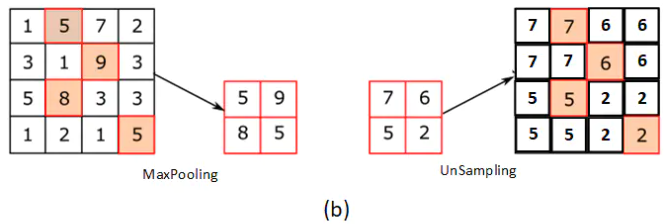
与图(a)相对的是图(b),两者的区别在于上采样UnSampling阶段没有使用MaxPooling时的位置信息,而是直接将内容复制来扩充Feature Map。从图中即可看到两者结果的不同。
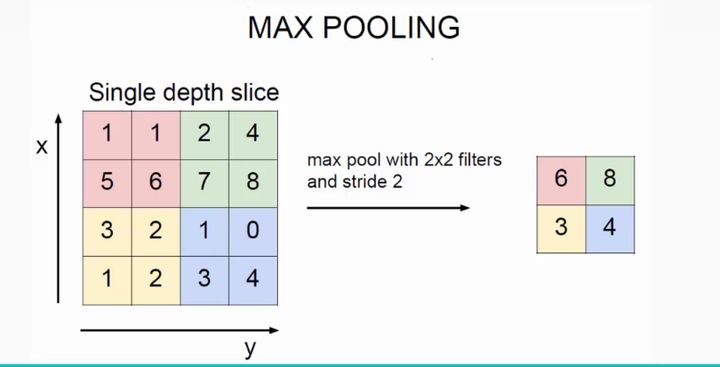
最大池化(MaxPooling)可以理解为卷积核每空两格做一次卷积,卷积核的大小是2x2, 但是卷积核的作用是取这个核里面最大的值(即特征最明显的值),而不是做卷积运算
反卷积是卷积的逆过程,又称作转置卷积(Transposed Convolution)。反卷积过程是有参数要进行学习的(类似卷积过程),而上池化和上采样是无反向传播过程的. 理论上反卷积可以实现UnPooling和unSampling,只要卷积核的参数设置的合理。
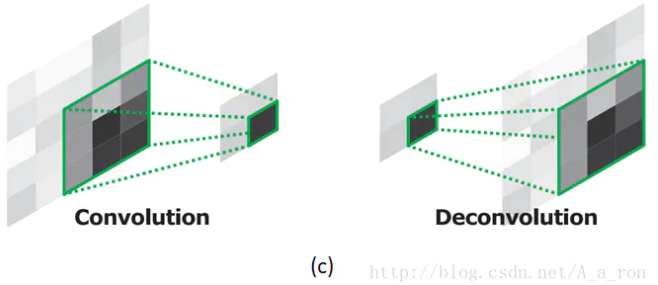
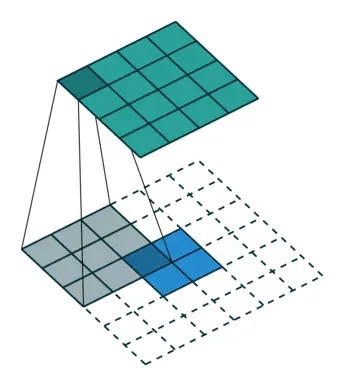
图中蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。图中的卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了
参考资料
CNN入门讲解:什么是采样层(pooling)
上池化(unpooling),上采样(unsampling)和反卷积(deconvolution)的区别
Dropout
Dropout是指在深度学习网络训练时,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,并且这种丢弃是随机的,因此每个mini-batch都是在训练不同的网络。是在CNN中防止过拟合并且提高效果的有利方式。
Dropout出现的原因(大规模的神经网络缺点/通病):
- 容易过拟合。过拟合虽然在训练时会有很高的精确度,但是在测试中精确度却会很低。比如将一些简单的样本放到大规模神经网络中,就十分容易出现过拟合,导致训练得到的模型废掉。为了解决过拟合的问题,一般采用ensemble方法(即将训练多个模型,并组合在一起),但是这样也出现了新问题:费时
- 费时。大规模的神经网络不仅训练费时,测试也费时。
因为有了上面两个“痛点”,因此出现了Dropout。当每次做完Dropout,相当于从原始的网络上找到更瘦的网络。
对于一个有n个节点的神经网络,有了Dropout后,就可以看做是2n个模型的集合了,但此时要训练的参数数目却是不变的,这就解决了费时的问题。同时,Dropout强迫一个神经元与其他随机挑选出来的神经元共同工作,达到更好的效果,增加了模型的泛化能力,这也就解决了过拟合的问题
因为Dropout的提出,网络模型也会随之而改变:
- 训练时的每个单元都要添加一道概率流程
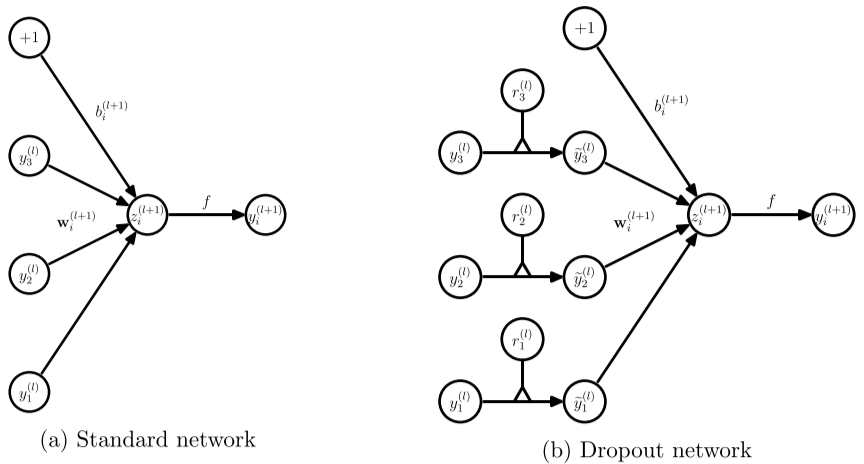
- 标准神经网络(没有Dropout的神经网络):


- Dropout神经网络:




- 测试时,需要对每个单元的参数乘以


在每次Dropout后的网络,在训练时相当于做了数据增强(Data Augmentation),因为总可以找到一个样本,使得在原始的网络上也能达到Dropout单元后的效果。 比如,对于某一层,Dropout一些单元后,形成的结果是(1.5,0,2.5,0,1,2,0),其中0是被Drop掉的单元,那么总能找到一个样本,使得结果也是如此。这样,每一次Dropout其实都相当于增加了样本。
参考资料
理解dropout
Dropout A Simple Way to Prevent Neural Networks from Overfitting.pdf
Dropout As Data Augmentation.pdf
numpy
matplotlib
PyTorch
⚡模型认知
YOLOv1(one-stage)
整体概念
在单个神经网络的一次预测中,实现直接地对整张图片中识别物体边框范围(Bounding box)和类别置信度的预测。可以这么理解:在一张完整的图中快速框定类别的边框以及判断出属于该类的可能性
优点:
- 快速。改变传统two-stage做法,发展one-stage,使用单个卷积网络同时识别多个边框范围以及边框中物体的类型和置信度
- 在预测时全局地推理图像。YOLOv1会在训练/测试时间浏览整个图像,因此该模型能够暗地解析类型的上下文环境信息以及它们的外观
会从对象中概括性地学习其特征。比如先对大自然的图像进行训练,然后在艺术画上做测试(泛化能力强)
基本概念:
1. 交并比
表达的是真实边框与预测边框的相似程度。具体来说就是真实边框与预测边框的交集除于并集,公式如下:

2. 置信度
置信度反映模型对于某个边框内存在目标的自信程度以及预测该边框内的目标是具体某一个类型的把握,对于YOLOv1来说,置信度的公式如下:

3. 在存在目标的情况下,具体到某一类的概率
这是一个条件概率,通过上述的交并比以及置信度的计算功能,能够得到该概率,计算结果既编码了类出现在方框中的概率,也编码了预测方框与对象的匹配程度:

核心思想:
利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别
实现方式:
将图像分成S*S的网格(grid cell),如果目标的中心在一个网格中,该网格则负责对该目标进行预测
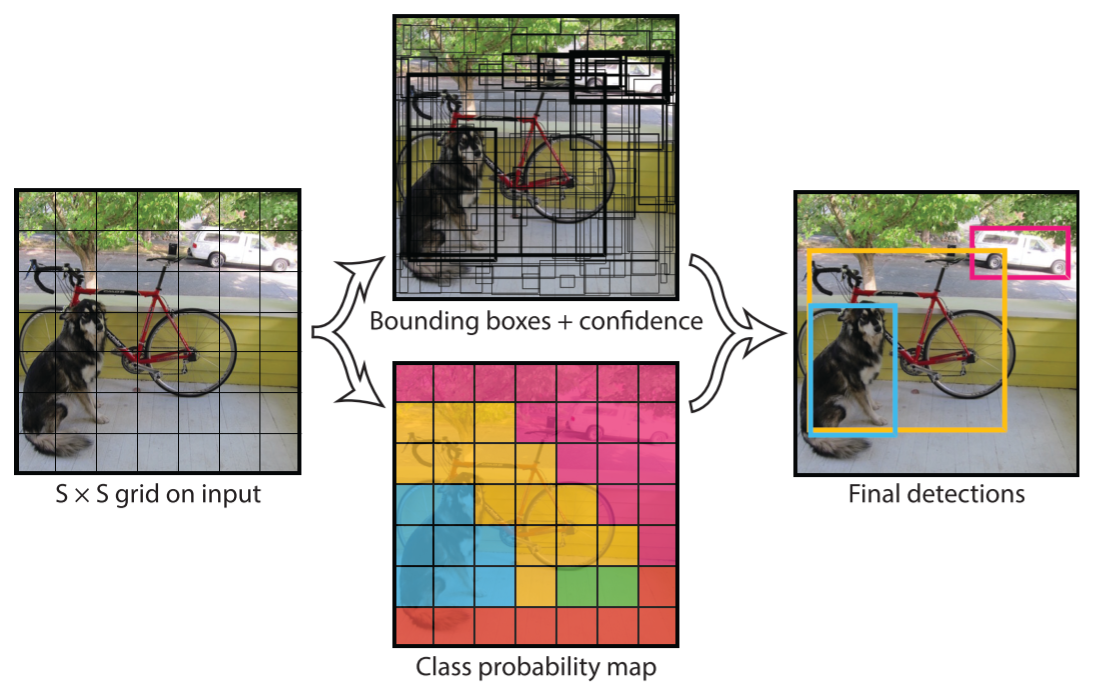
- 每个网格要预测B个边框以及这些边框的置信度。如果在网格中不存在目标,则置信度为0(即
 为0),否则为1,进而可以的出边框的置信度。
为0),否则为1,进而可以的出边框的置信度。 - 每个边框需要有四个参数:边框中心坐标点(x, y)、边框尺寸(w, h)
- 每个网格还预测条件类的概率(confidence)
综上可得,YOLOv1是将输入图像分割成SS个网格,每个网格预测B个边框和边框中存在目标概率以及C个类别出现的概率。因此,整体的张量为:
引用论文中的例子:输入图片为VOC数据集(20个类别),将其每个图片分为77网格,每个单元格负责两个边框的预测, 因此可以将其解码为一个**7*7*(2*5+20)**的张量
网络设计:
YOLOv1借鉴了GoogleNet模型,使用24个卷积层和两个全连接层,使用1×1的reduction layer紧跟着3×3卷积层取代GoogleNet的inception模块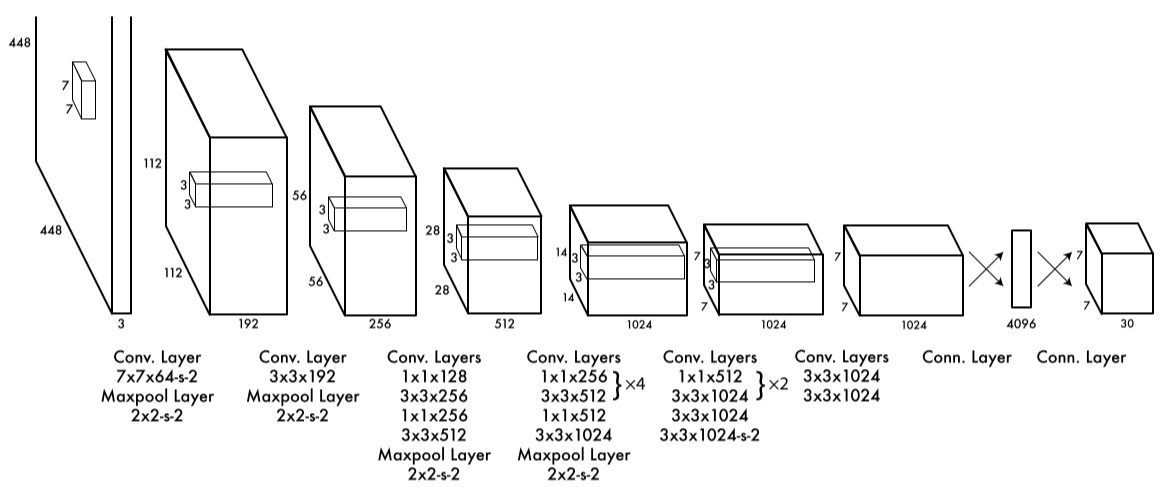
损失函数:

不足:
- 无法精确识别多个目标,无法集中处理一些目标,特别是对于小目标(YOLO在边框预测中利用强大的空间约束,时的每个grid cell只能预测两个边框以及一个类型;该空间约束限制了模型能够预测目标附近的目标数量。同时也很难精确预测小目标,如一群鸟)
- YOLO很难概括出具有新的或不寻常纵横比或立体的对象。它也使用相对粗糙的特征来预测边框,因为神经网络架构从输入图像中有多个下采样层
- 大目标边框里的误差通常是良性的,但小目标边框的误差对IOU的影响要大得多。主要误差来源是不正确的定位
参考资料
YOLOv2 / YOLO9000
整体概念
在保持YOLOv1处理图像速度的基础上,根据其不足之处,对精确度(Better)、速度(Faster)以及检测范围(Stronger)上做了一些改进,因此出现了YOLOv2以及能够识别超过9000个类别的YOLO9000,并且还能够实时检测。
目标检测的发展情况
在当时,目标检测的问题主要体现在检测方法的问题以及数据集的问题上。
- 检测方法的问题:大多数目标检测的方法还局限于少数的对象
- 数据集的问题:比起用于分类和标记任务的数据集,当时用于检测的数据集相对较少(分类数据集包含数百万个具有数万或数十万个类别图像,而最常见的检测数据集只包含成千上万的图像以及数十到百个标签)
针对于以上的问题,YOLO开发团队使用WordNet词库的构建思路创建了WordTree,将ImageNet和COCO数据集结合得到超过9000个类型的数据集,并提出一个新的训练方法——联合训练,来拓展模型的检测范围。
精确度的提高(Better)
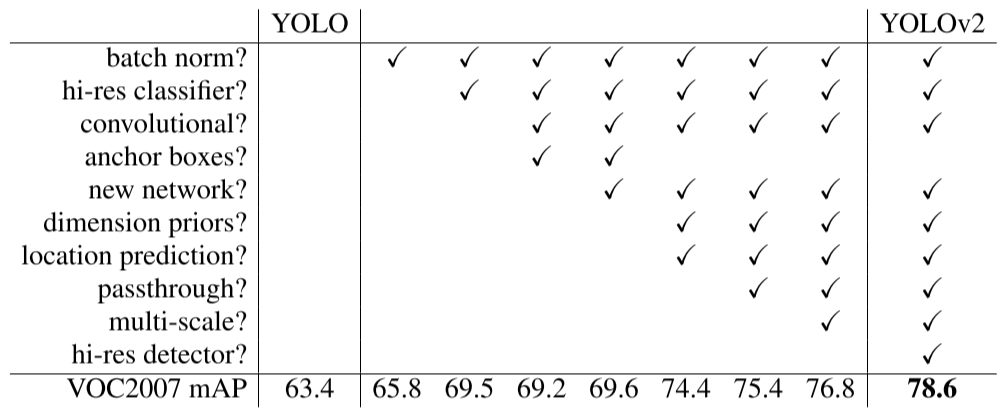
批归一化(Batch Normalization)
- 批归一化有助于解决反向传播过程中的梯度消失和梯度爆炸问题
- 降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性
- 每个batch分别进行归一化的时候,起到了一定的正则化效果
- YOLO2不再使用Dropout,从而能够获得更好的收敛速度和收敛效果(防止过拟合)
高分辨率分类器(High Resolution Classifier)
在YOLOv1中,分类模型是使用224224分辨率的图像进行训练,而使用448448分辨率的图像进行检测的,在训练完后立即进行检测,这样切换对模型性能有一定影响。基于这个问题,YOLOv2在使用使用224224分辨率的图像预训练后,采用448448分辨率的图像对分类模型进行微调(10个epoch / 迭代),使网络特征逐渐适应 448448 的分辨率图像。然后再使用 448448 的检测样本进行训练,缓解了YOLOv1中分辨率突然切换造成的影响。先验框(Anchor Boxes)
沿用Faster R-CNN的做法,采用先验框(Anchor),在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。同时YOLO2移除了全连接层和一个池化层,使网络卷积层输出具有更高的分辨率。并在后续进一步改良:
- 聚类提取先验框尺度
对训练集中标注的边框进行聚类分析,以寻找尽可能匹配样本的边框尺寸。
聚类算法最重要的是选择如何计算两个边框之间的“距离”,对于常用的欧式距离,大边框会产生更大的误差,但我们关心的是边框的IOU。YOLO2在聚类时采用以下公式来计算两个边框之间的“距离”。使用k-means聚类方法,使得先验框有较好的IOU,同时也让模型有更好的表现以及更加容易去学习
centroid是聚类时被选作中心的边框,box就是其它边框,d就是两者间的“距离”。IOU越大,“距离”越近。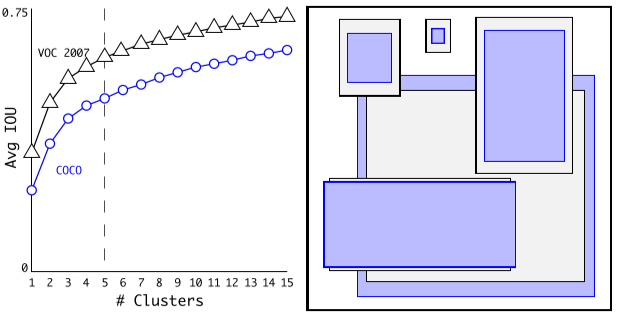
- 约束预测边框的位置
借鉴于Faster R-CNN的先验框方法,在训练的早期阶段,其位置预测容易不稳定。

其中, 是预测边框的中心,
是预测边框的中心,  是先验框(anchor)的中心点坐标,
是先验框(anchor)的中心点坐标, 其中,
其中, 是要学习的参数。
是要学习的参数。
由于 的取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。
的取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。
YOLO调整了预测公式,将预测边框的中心约束在特定gird网格内。




其中,  是预测边框的中心和宽高
是预测边框的中心和宽高 是预测边框的置信度,YOLOv1是直接预测置信度的值,这里对预测参数
是预测边框的置信度,YOLOv1是直接预测置信度的值,这里对预测参数 进行
进行 变换后作为置信度的值。
变换后作为置信度的值。 是当前网格左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1。
是当前网格左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1。  是先验框的宽和高。
是先验框的宽和高。 是sigmoid函数。
是sigmoid函数。  是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
这样做使得参数更容易学习,也使得神经网络更加的稳定

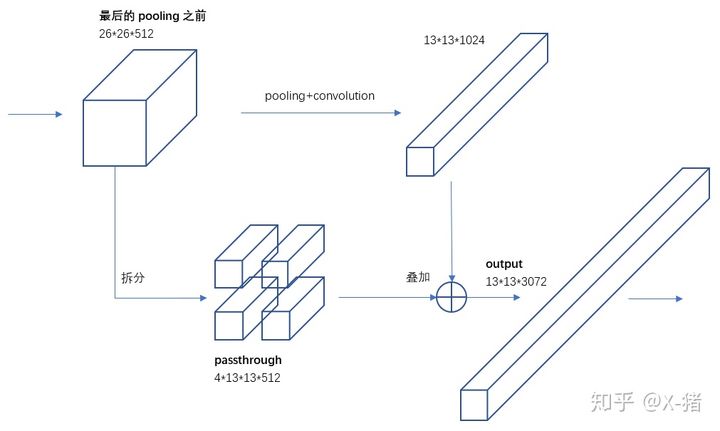
良好细粒度的特征(Fined-Grained Feature)
面对图像中对象大小的不确定性,经过多层网络提取特征后,最后输出的特征中较小的对象可能被忽略掉了,因此YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体做法就是在最后一个pooling之前,特征图的大小是2626512,将其隔开采样,拆分成4个1313512的特征图,直接传递到pooling+卷积后的特征图,两者叠加后作为输出的特征图
多尺度训练(Multi-Scale Trainng)
YOLOv2使用多尺度训练的目的是在训练不同尺寸的图像时有更好的鲁棒性。具体做法是去掉全连接层,因为整个网络下采样倍数是32,作者采用了{320,352,…,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,…19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
速度的提升(Faster)
为了进一步提升速度,YOLO2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构。DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。
检测范围的扩展(Stronger)
当时检测数据集相对分类数据集要少,检测数据集只有大类的标签,而分类数据集有更详细的类别标签, 因此,作者想通过WordNet的构建思路,去融合ImageNet和COCO数据集。其基本思路是,如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差
YOLO2于是根据WordNet,将ImageNet和COCO中的名词对象一起构建了一个WordTree,以physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接表达了对象概念之间的蕴含关系(上位/下位关系)
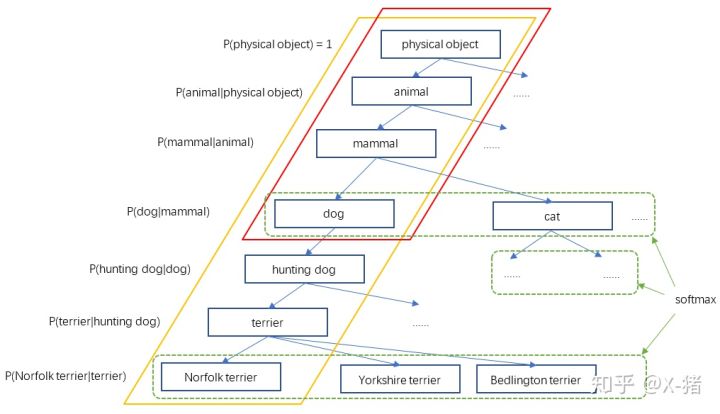
WordTree的构建
构建WordTree的步骤是:
- 检查每一个将用于训练和测试的ImageNet和COCO对象,在WordNet中找到对应的节点,如果该节点到WordTree根节点(physical object)的路径只有一条(大部分对象都只有一条路径),就将该路径添加到WrodTree。
- 经过上面操作后,剩下的是存在多条路径的对象。对每个对象,检查其额外路径长度(将其添加到已有的WordTree中所需的路径长度),选择最短的路径添加到WordTree
如何表达对象类别
比如一个样本图像,其标签是是”dog”,那么显然dog节点的概率应该是1,然后,dog属于mammal,自然mammal的概率也是1,……一直沿路径向上到根节点physical object,所有经过的节点其概率都是1。参考上图,红色框内的节点概率都是1,其它节点概率为0。另一个样本假如标签是”Norfolk terrier”,则从”Norfolk terrier”直到根节点的所有节点概率为1(图中黄色框内的节点),其它节点概率为0。
所以,一个WordTree对应且仅对应一个对象,不过该对象节点到根节点的所有节点概率都是1,体现出对象之间的蕴含关系,而其它节点概率是0。
检测如何确定WordTree中对应的对象
根据训练标签的设置,其实模型学习的是各节点的条件概率。比如我们看WordTree(图10)中的一小段。假设一个样本标签是dog,那么dog=1,父节点mammal=1,同级节点cat=0,即P(dog|mammal)=1,P(cat|mammal)=0。既然各节点预测的是条件概率,那么一个节点的绝对概率就是它到根节点路径上所有条件概率的乘积。比如
对于分类的计算, 。不过,为了计算简便,实际中并不计算出所有节点的绝对概率。而是采用一种比较贪婪的算法。从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个(一个节点下面的所有子节点是互斥的),一直向下遍历直到某个节点的子节点概率低于设定的阈值(意味着很难确定它的下一层对象到底是哪个),或达到叶子节点,那么该节点就是该WordTree对应的对象。
。不过,为了计算简便,实际中并不计算出所有节点的绝对概率。而是采用一种比较贪婪的算法。从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个(一个节点下面的所有子节点是互斥的),一直向下遍历直到某个节点的子节点概率低于设定的阈值(意味着很难确定它的下一层对象到底是哪个),或达到叶子节点,那么该节点就是该WordTree对应的对象。
分类和检测联合训练
由于ImageNet样本比COCO多得多,所以对COCO样本会多做一些采样(oversampling),适当平衡一下样本数量,使两者样本数量比为4:1。YOLO9000依然采用YOLO2的网络结构,不过5个先验框减少到3个先验框,以减少计算量。YOLO2的输出是13135(4+1+20),现在YOLO9000的输出是13133(4+1+9418)。假设输入是4164163。
由于对象分类改成WordTree的形式,相应的误差计算也需要一些调整。对一个检测样本,其分类误差只包含该标签节点以及到根节点的所有节点的误差。比如一个样本的标签是dog,那么dog往上标签都是1,但dog往下就不好设置了。因为这个dog其实必然也是某种具体的dog,假设它是一个Norfolk terrier,那么最符合实际的设置是从Norfolk terrier到根节点的标签都是1。但是因为样本没有告诉我们这是一个Norfolk terrier,只是说一个dog,那么从dog以下的标签就没法确定了。
对于分类样本,则只计算分类误差。YOLO9000总共会输出13133=507个预测框(预测对象),计算它们对样本标签的预测概率,选择概率最大的那个框负责预测该样本的对象,即计算其WrodTree的误差。
参考资料
YOLOv3
整体概念
YOLOv3对上一个版本(YOLO9000)进行的修改,将模型结构增大了点,但速度却增加了不少(比如在YOLOv3中处理320*320的图像需要花22ms,精度为28.2mAP,但在SSD中处理相同的图像,需要花66ms,精度也是28.2mAP,也就是说,YOLOv3在达到相同进度的情况下,处理时间却是SDD的1/3)。因此更加适用于实时(real-time)的目标检测。同时作者的团队也尝试其他方式去改进YOLO9000,但效果并不好。
改进方案
网络结构的改进
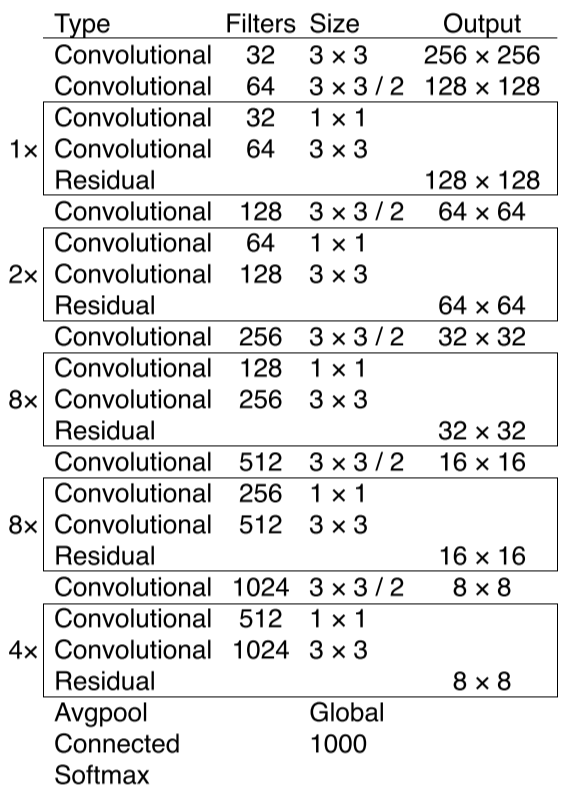
- 名称来源
在YOLO9000中使用了Darknet-19,而在YOLOv3中,沿用了YOLO9000中的Darknet-19,并借鉴残差网络Residual Network的做法,在一些层之间设置了快捷链路(Shortcut Connections),新的网络总共使用了53个卷积层,因此作者将其取名为Darknet-53。可以简单理解为Darknet-53 = Darknet-19 + Residual Network
- 快捷链路
Darknet-53使用连续的11和33的卷积层组成,并且使用一些快捷链路,使得整个网络结构更大了
预测边界框的改进
继续沿用YOLO9000中使用的方式——通过维度聚类(Dimension Cluster)固定Anchor box来选定边界框。YOLOv3通过逻辑回归对每个bounding box进行预测,通过其IOU的取值判断:当IOU=1时,说明该bounding box与ground turth完全重合;而当IOU<0.5时,则忽略该bounding box。YOLOv3只为每个ground truth对象分配一个先验框(prior bounding box),如果先验框未分配给相应对象,那它只是检测错了对象,不会对坐标或分类预测造成影响。
类别预测的改进
YOLOv3没有Softmax而使用单独的逻辑分类器(logistic classifier)。因为Softmax会强加一个假设,使得每个框只包含一个类别。同时,YOLOv3在训练时会使用二元交叉熵损失(binary cross-entropy loss)来预测类别。因此,通过逻辑分类器更加适用于复杂的领域(比如对多标签的分类,人和女人,狗和猎犬…)
多尺度预测
YOLO2曾采用passthrough结构来检测细粒度特征,YOLOv3使用三种尺度判别预测框。三种尺度分别对应大、中、小目标检测对象。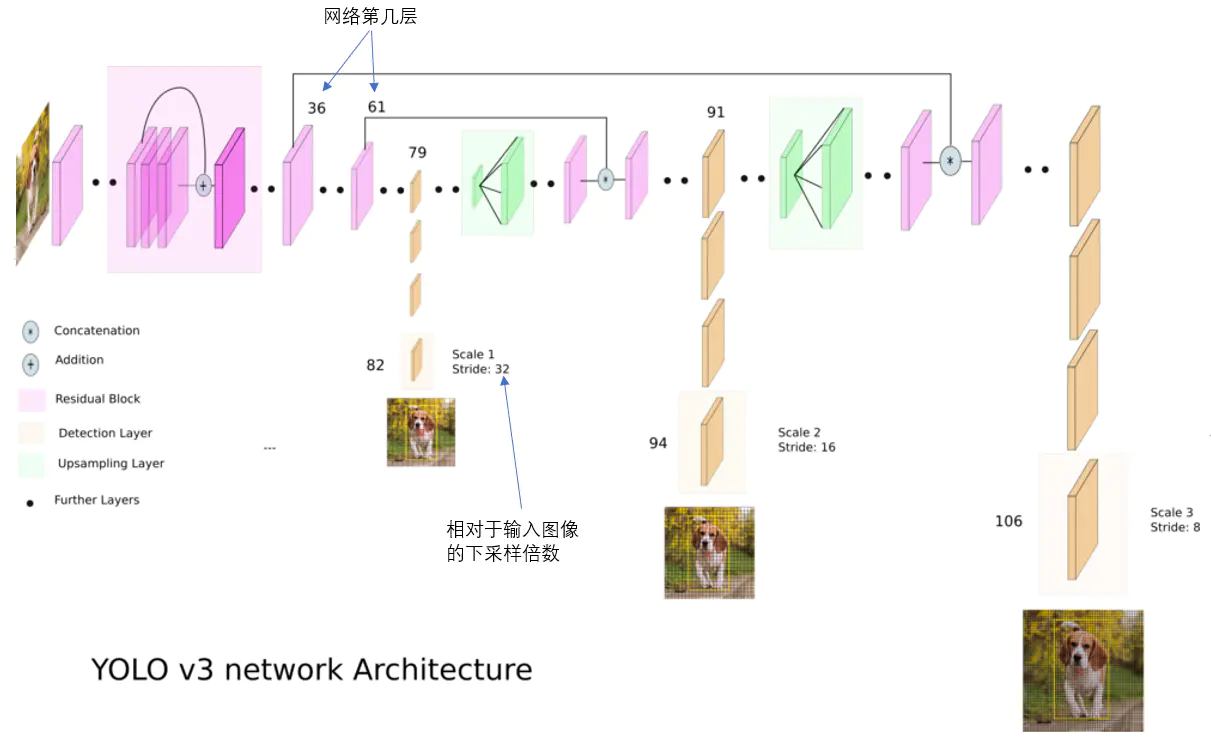
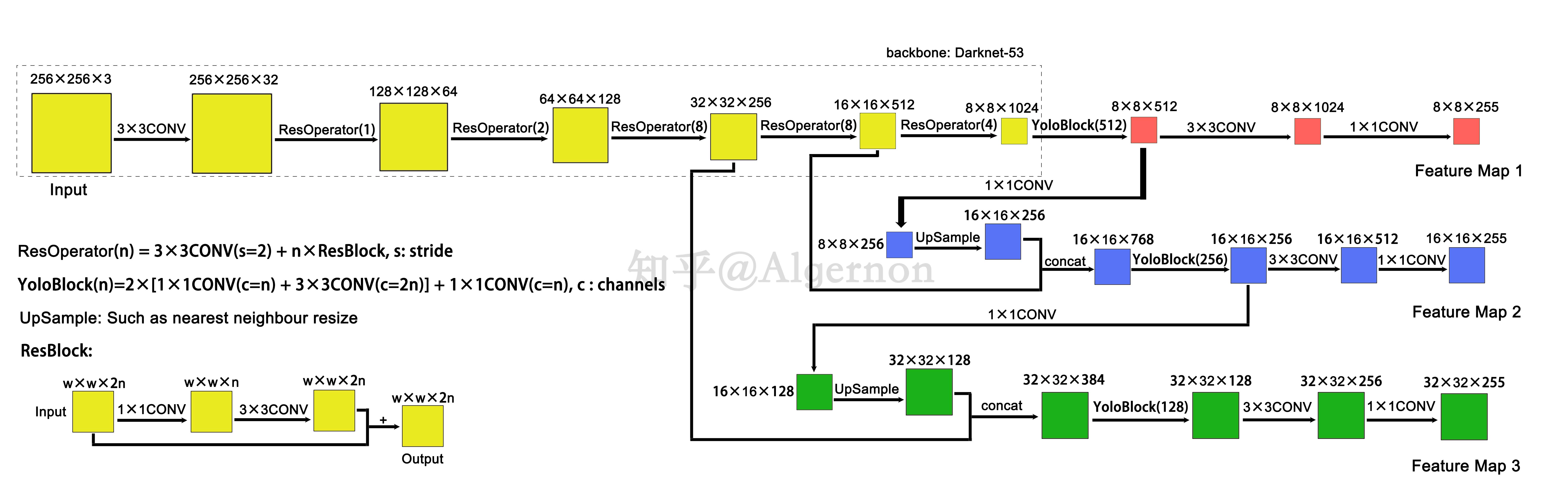
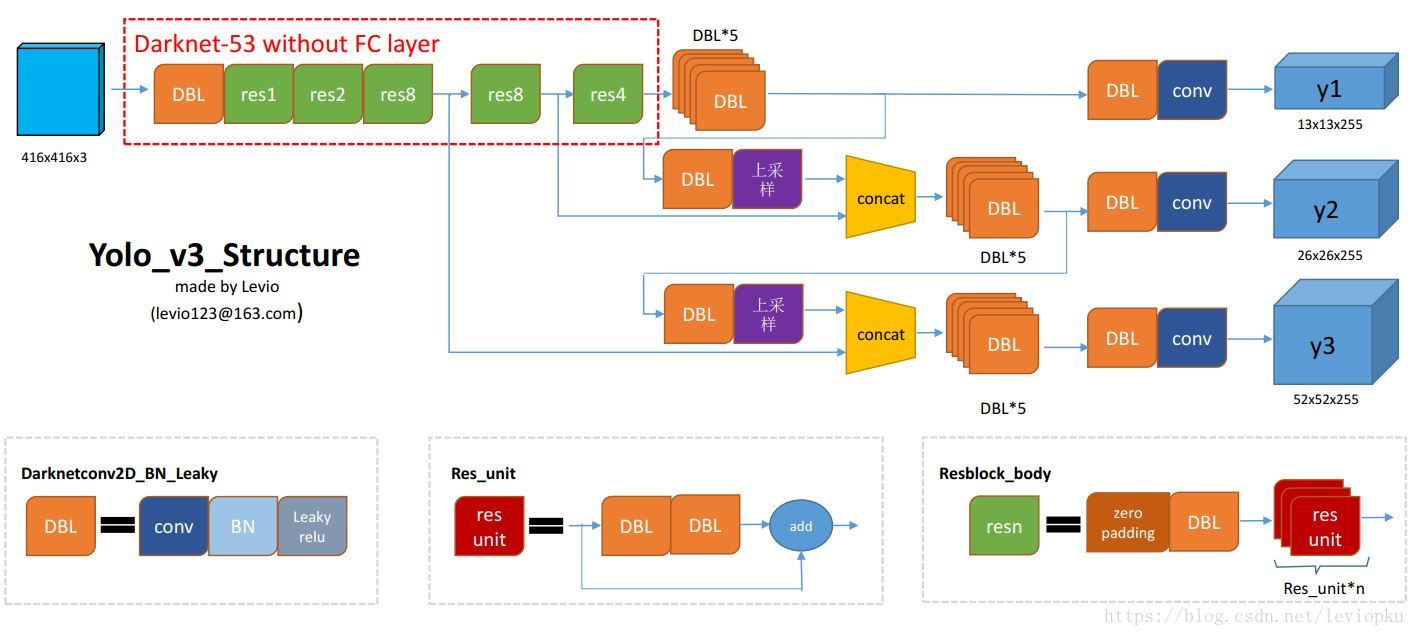
YOLOv3在基础的特征提取器(Darknet-53)中添加了多个卷积层,并在最后一个卷积层中预测一个三位张量,该张量编码了预测框(bounding box)、框中的目标(objectness)以及分类的预测(prediction),其中,在COCO数据集中得到结果为 ,N表示图像尺寸,3表示三种预测的尺寸边框,4表示边框范围,1表示框中的目标,80表示COCO数据集有80种类别
,N表示图像尺寸,3表示三种预测的尺寸边框,4表示边框范围,1表示框中的目标,80表示COCO数据集有80种类别
从不同尺寸的预测框结果前的两个卷积层种得到的特征图,对其进行上采样(总共上采样两次),再从更早的卷积层中得到特征中,使用element-wise(一种张量操作的方法)将高低两种分辨率连接在一起。之后再对最后一个尺度设置类似的操作。
这样做的目的是能够找到早期特征图中的上采样特征和细粒度特征,并获得更有意义的语义信息。
与YOLOv2一样,YOLOv3使用K-Means聚类方法来确定边框的先验,随意选择9个聚类和3种尺寸,在不同的尺寸的边距中均匀地分割维度聚类,在COCO数据集上,这9个聚类分别是:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116 × 90)、(156 × 198)、(373 × 326)
参考资料
【论文解读】Yolo三部曲解读——Yolov3
深度学习论文翻译解析(一):YOLOv3: An Incremental Improvement
YOLOv4
整体概念
YOLOv3之后,原作者Joe Redmon宣布退出计算机视觉(CV)领域,但之后就被Alexey Bochkovskiy接棒,对YOLO系列继续更新(同时也得到了Joe Redmon的认可)。而YOLOv4的特点,就是集大成者(俗称堆料),经过了一系列的对比实现,得到最终呈现出来的YOLOv4。其主要贡献如下:
- 优化模型。开发出一个高效且强大的目标检测模型
- 优化使用场景。改进SOTA(state-of-the-art)的方法(包括CBN,PAN,SAM等),使得这些方法更加高效且适应单个GPU的训练
验证训练算法。验证了SOTA中BoF(Bag-of Freebies)和BoS(Bag-of-Specials)的方法的影响
目标检测器的组成部分
Input(输入):即输入的图片,补丁,影像金字塔
- Backbone(骨架):一般指的是在ImageNet上进行与训练得到的模型
- Neck(颈部):常用在backbone和head之间的多个层中,以及这些层通常用来在不同stage中收集特征图
-
调优手段
Bag of Freebies(免费包)
一般来说,训练都是在离线状态下进行,那么在该状态下为了提高精度而使用的调优手段,不增加预测的时间,只改变训练策略或者增加训练计算量(代价)的方法
Bag of Specials(特价包)
是对于一些只增加少量的推理代价,就能有效地提高物体检测的精度的插件模块和后处理方法。插件模块是为了提高模型中的某一属性,扩大感受野、引入注意力机制、增强特征集成能力和激活函数;后处理是为了筛选模型预测结果
YOLOv4技术框架
组成部分
Backbone:CSPDarknet53
- Neck:SPP, PAN
-
使用方法
对于骨架(backbone)
Bag of Freebies:CutMix 和 Mosaic 数据增强,DropBlock正则化,Class label smoothing标签平滑
Bag of Specials:Mish激活函数,CSP跨阶段部分连接,MiWRC多输入加权残差连接
对于检测器(detector)
Bag of Freebies:CIoU-loss损失函数,DropBlock正则化,Mosaic 数据增强,Self-Adversarial Training自对抗训练,Eliminate grid sensitivity消除网格敏感性,针对一个真值使用多个锚,余弦退火调度器,优化超参数和随机训练形状
- Bag of Specials:Mish 激活函数,SPP 块,SAM 块、PAN 路径聚合块和 DIoU-NMS。
参考资料
大神接棒,YOLOv4来了!
【YOLO V4】目标检测模型之YOLO V4框架
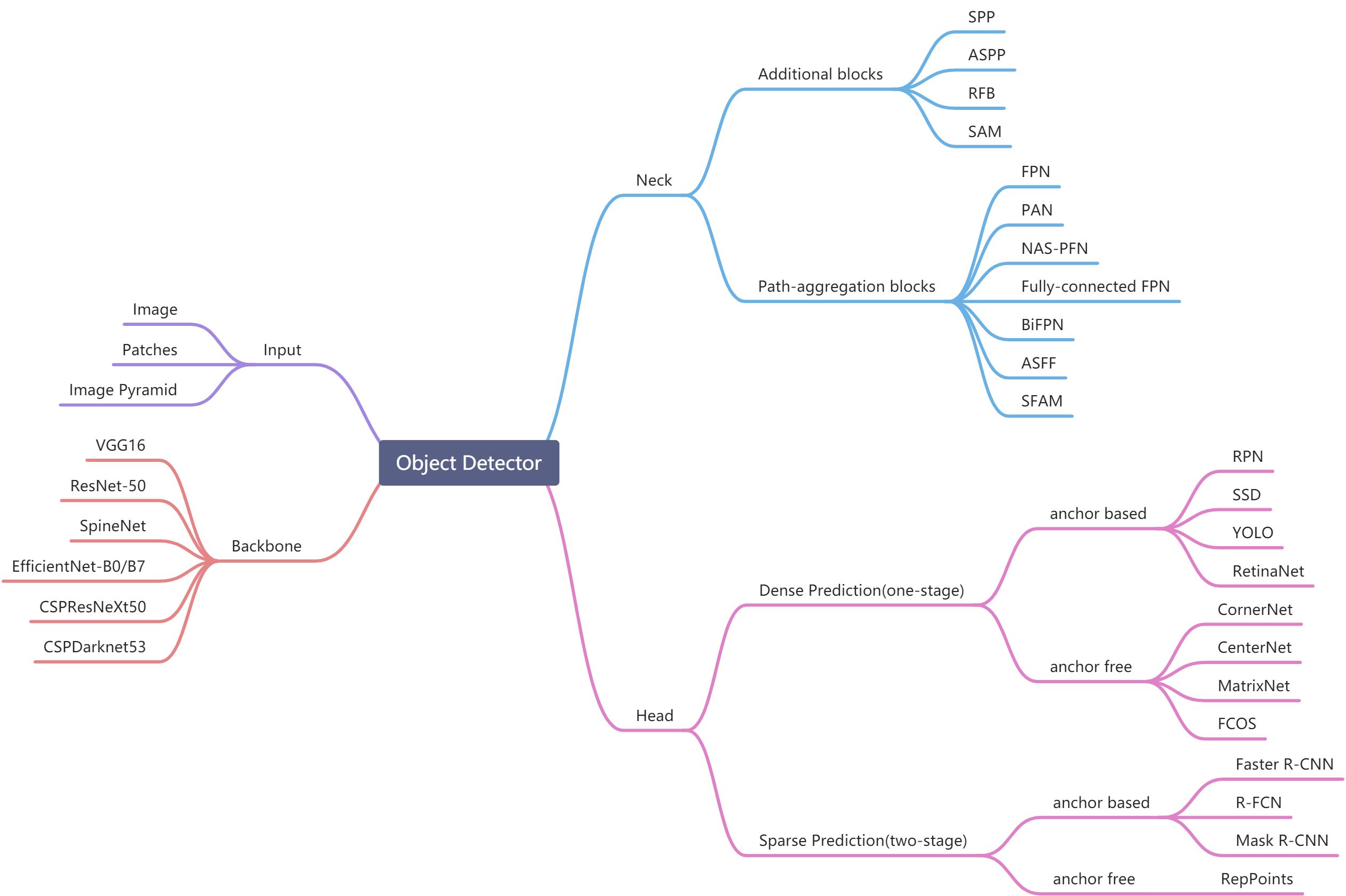
模型评定指标
基础指标
- True positive(TP):对象本身为正例,模型识别为正例
- False positive(FP):对象本身为负例,模型识别为正例,通常叫误报
- True negative(TN):对象本身是负例,模型识别为负例
- False negative(FN):对象本身是正例,模型识别为负例,通常叫漏报
Ground Truth
指的是实际情况,即“数据集+标注”
在VOC数据集中,一般认为预测的边框和Ground Truth的IOU大于0.5才算预测正确(归为TP)Error(误差)
Accuracy(准确率)
模型预测结果与真实结果的比率,越接近100%效果越好。常用于分类问题。例子: 在分类问题中,比如有模型预测了一百个结果,其中有95个结果是正确的,那么准确率为 (95/100)*100% = 95%
如果是回归问题,则使用 R2 Score 指标进行判断 如果是测量不平衡的数据的精度,则使用 f1 Score 指标进行判断
Precision(精确率/查准率)
表示在模型识别出所有正例(TP+FP)中,识别出正确的正例(TP)的占比,因此计算公式为 
Recall(召回率/查全率)
表示在所有真正的正例(TP+FN)中,模型识别出是正确的正例(TP)的占比,因此计算公式为 
AP/Average Precision(平均精确率)
即平均精确率,在准确率从0到1各个点的召回率的均值: ,这个积分无限接近每种可能的阈值下的精确率与召回率的变化值的乘积之和。
,这个积分无限接近每种可能的阈值下的精确率与召回率的变化值的乘积之和。
也就是PRC图中曲线下面的面积。通常来说一个越好的分类器,AP值越高。
mAP / mean Average Precision(平均AP值)
指的是所有类别的平均AP值,在PRC图中也能够体现,可以说是计算所有类别PRC曲线下面积的平均值
mAP_0.5(平均精确率;0.5<IoU)
mAP_0.5:0.95(平均精确率;0.5<IoU<0.95)
指标关系
精确率(Precision)与召回率(Recall)

ROC和PRC
🐱🏍数据处理
关于数据处理,主要是将采集的数据进行清洗处理、标注处理等数据组织的方式,将已有数据组织成深度学习网络模型能够读取的数据格式。包括样本图像裁剪、样本标签注释、样本内容统一等等
数据来源
影像数据:
- 梅州市梅县区石扇镇三坑村部分区域正射影像图[63865041 .tif]*(2020夏季)
该影像数据通过无人机——大疆精灵Phantom 4 RTK采集,经过Pix4Dmapper软件一键化处理生成采集区域的正射影像图(DOM)[.tif]
- (2020秋季、2020冬季、2021春季)
该影像数据通过无人机——大疆精灵Phantom 4 RTK采集,下图从左只有分别是2020秋季、2020冬季、2021春季的影像数据(经过ArcGIS处理后栅格裁剪等操作得到)

标签数据:
- 实地考察标注的柚树点要素数据[.shp](夏季)
于2020年7月13日前往该地区进行柚树位置确认以及通过奥维地图移动端对要素进行标记
将两份数据通过通过ArcGIS软件叠加后得到(红色三角▲表示实地考查柚树的地理位置),该步骤是为了用于后续制作标签提供位置参考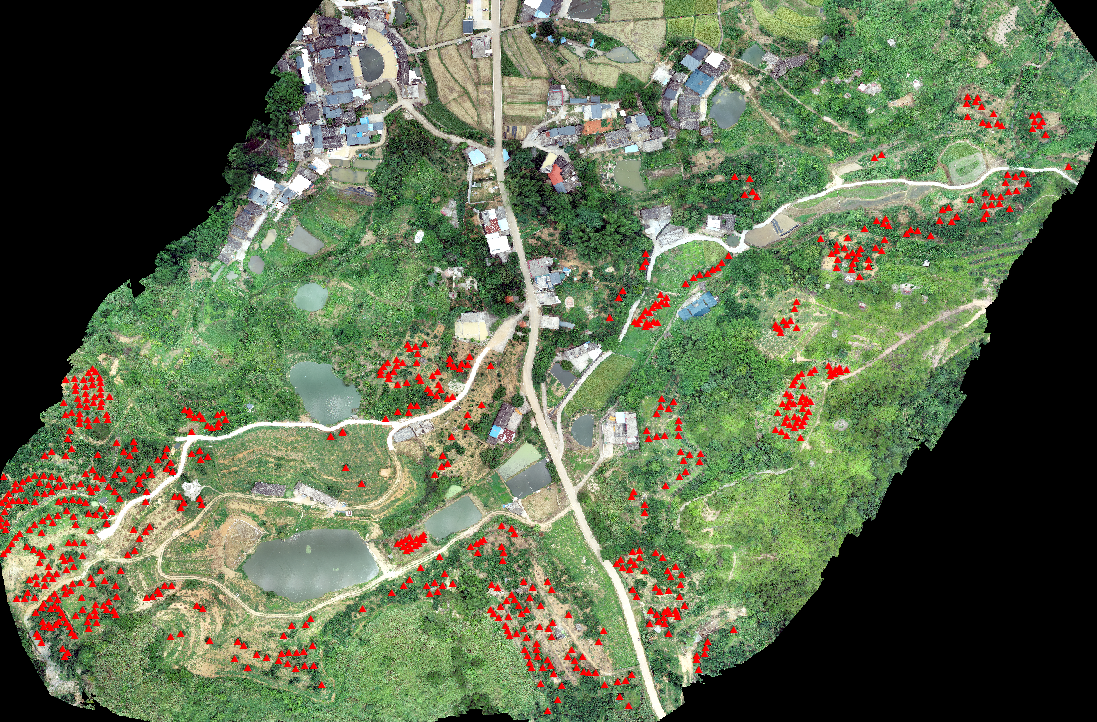
- 实地考察标注的柚树面要素数据[.shp](秋季、冬季、春季)
将两份数据通过通过ArcGIS软件叠加后得到(黄色空心圆⊙表示实地考查柚树的地理位置),该步骤是为了用于后续制作标签提供位置参考
图像裁剪脚本/工具(已废弃,改用ArcGIS进行裁剪)
图像裁剪主要用于后续为训练模型的输入做好尺寸的准备,若图像尺寸过大,模型可能会无法处理,进而无法训练
- Tif_Segment.py ```python import os import gdal import numpy as np
def read_tiff(filename): “””读取tif数据集
:param filename: 影像文件路径:return dataset: 影像数据集"""dataset = gdal.Open(filename)if dataset is None:print(filename + "文件无法打开")return dataset
def write_tiff(im_data, im_geo_trans, im_proj, path): “””保存tif文件
:param im_data: 影像数据矩阵
:param im_geo_trans: 影像的仿射矩阵
:param im_proj: 影像的投影坐标系相关信息
:param path: 文件保存路径
:return:
"""
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
elif len(im_data.shape) == 2:
im_data = np.array([im_data])
im_bands, im_height, im_width = im_data.shape
# GeoTIFF格式的驱动器
driver = gdal.GetDriverByName("GTiff")
# 创建文件
dataset = driver.Create(path, int(im_width), int(im_height), int(im_bands), datatype)
if dataset is not None:
dataset.SetGeoTransform(im_geo_trans) # 写入仿射变换参数
dataset.SetProjection(im_proj) # 写入投影
for i in range(im_bands):
dataset.GetRasterBand(i + 1).WriteArray(im_data[i])
del dataset
def tif_crop(tif_path, save_path, crop_size, repetition_rate): “””滑动窗口裁剪函数
:param tif_path: 影像文件路径
:param save_path: 裁剪后文件保存目录
:param crop_size: 裁剪尺寸
:param repetition_rate: 重复率
:return:
"""
dataset_img = read_tiff(tif_path) # 读取数据集
width = dataset_img.RasterXSize # 获取数据集列数
height = dataset_img.RasterYSize # 获取数据集行数
proj = dataset_img.GetProjection() # 获取数据集的投影坐标系
geo_trans = dataset_img.GetGeoTransform() # 获取数据集的仿射投影
img = dataset_img.ReadAsArray(0, 0, width, height) # 将数据集读取为numpy数组
# 获取当前文件夹的文件个数len,并以len+1命名即将裁剪得到的图像
new_name = len(os.listdir(save_path)) + 1
# 裁剪图片(从左到右,从上到下),重复率为repetition_rate
for i in range(int((height - crop_size * repetition_rate) / (crop_size * (1 - repetition_rate)))):
for j in range(int((width - crop_size * repetition_rate) / (crop_size * (1 - repetition_rate)))):
# 如果图像是单波段
if len(img.shape) == 2:
cropped = img[int(i * crop_size * (1 - repetition_rate)):
int(i * crop_size * (1 - repetition_rate)) + crop_size,
int(j * crop_size * (1 - repetition_rate)):
int(j * crop_size * (1 - repetition_rate)) + crop_size]
# 如果图像是多波段
else:
cropped = img[:,
int(i * crop_size * (1 - repetition_rate)):
int(i * crop_size * (1 - repetition_rate)) + crop_size,
int(j * crop_size * (1 - repetition_rate)):
int(j * crop_size * (1 - repetition_rate)) + crop_size]
# 写图像
write_tiff(cropped, geo_trans, proj, save_path + "/%d.tif" % new_name)
# 文件名 + 1
new_name = new_name + 1
# 向前裁剪最后一列
for i in range(int((height - crop_size * repetition_rate) / (crop_size * (1 - repetition_rate)))):
if len(img.shape) == 2:
cropped = img[int(i * crop_size * (1 - repetition_rate)):
int(i * crop_size * (1 - repetition_rate)) + crop_size,
(width - crop_size): width]
else:
cropped = img[:,
int(i * crop_size * (1 - repetition_rate)):
int(i * crop_size * (1 - repetition_rate)) + crop_size,
(width - crop_size): width]
# 写入图像
write_tiff(cropped, geo_trans, proj, save_path + "/%d.tif" % new_name)
new_name = new_name + 1
# 向前裁剪最后一行
for j in range(int((width - crop_size * repetition_rate) / (crop_size * (1 - repetition_rate)))):
if len(img.shape) == 2:
cropped = img[(height - crop_size): height,
int(j * crop_size * (1 - repetition_rate)):
int(j * crop_size * (1 - repetition_rate)) + crop_size]
else:
cropped = img[:,
(height - crop_size): height,
int(j * crop_size * (1 - repetition_rate)):
int(j * crop_size * (1 - repetition_rate)) + crop_size]
write_tiff(cropped, geo_trans, proj, save_path + "/%d.tif" % new_name)
# 文件名 + 1
new_name = new_name + 1
# 裁剪右下角
if len(img.shape) == 2:
cropped = img[(height - crop_size): height, (width - crop_size): width]
else:
cropped = img[:, (height - crop_size): height, (width - crop_size): width]
write_tiff(cropped, geo_trans, proj, save_path + "/%d.tif" % new_name)
new_name = new_name + 1
将图像裁剪为重复率为0.25的256*256的数据集
tif_crop(r”E:\Study\01_Projects\PanDeng\spilt_test\data\test.tif”, r”E:\Study\01_Projects\PanDeng\spilt_test\result_256\tif”, 256, 0.25)
<a name="c5c30a0c"></a>
## 格式转换脚本/工具(已废弃,改用ArcGIS进行裁剪)
> 深度学习模型一般都是以.jpg格式的图像作为图像输入,因此对于该项目的.tif格式图像,需要进行格式转换
- **tif2jpg.py**
```python
import os
from osgeo import gdal
open_path = "E:/Study/01_Projects/PanDeng/spilt_test/result_256/tif/"
save_path = "E:/Study/01_Projects/PanDeng/spilt_test/result_256/jpg/"
images = os.listdir(open_path) # 列出指定目录下的所有文件
for image in images:
im = gdal.Open(os.path.join(open_path, image)) # 打开图像
driver = gdal.GetDriverByName('JPEG') # 获取图像的格式驱动器
dst_ds = driver.CreateCopy(os.path.join(save_path, image.split('.')[0] + ".jpg"), im) # 转换图像格式
图像标注工具(已废弃,改用ArcGIS进行标注)
- labelImg(本项目使用该工具)
一款图像注释工具,能够对图片进行框选,并设置相关标注内容

- labelme
一个可以实现多种形状的标注的图像注释工具,比如多边形、圆形、矩形、直线、点等
图像文件筛选脚本/工具(已废弃,改用ArcGIS进行筛选)
该脚本用于处理制作数据集时增加了无效图像的问题,在减少数据数量的同时提高数据质量。
data-filter.py ```python “””
数据筛选
作用:
- 用于排除没有对应标签文件的图像
- 减少无用数据,提高数据使用率 实现:
- 通过标签文件名称[如:123.xml ]提取图像序号,保存至txt文件种
读取txt文件,获取对应影像文件[ 如:123.jpg ],并另存至其他文件夹中
待处理数据组织结构:
dataset ├─ Annotation │ ├─ 。。。 │ └─ xxx.xml └─ Images ├─ 。。。 └─ xxx.jpg
“””
Standard parties
import os from pathlib import Path import shutil
Third parties
Configuration
data_path = ‘./dataset’ # 待处理文件夹路径 save_path = ‘./output’ # 筛选后存放的位置 annotation_txt = ‘./annotation.txt’
def get_filename_txt(annot_path, txt_path): “”” 获取指定目录下的所有文件名
:param annot_path: 数据集根目录
:return:
"""
if annot_path.exists():
file_list = os.listdir(annot_path) # 得到目录下所有文件的名称
txt = open(txt_path, 'w') # 创建txt文件,保存文件名(不包括扩展名)
for name in file_list:
txt.write(name[:-4] + '\n') # 文件写入
txt.close()
else:
print("ERROR!")
def filter_image(img_path, txt_path, target_path): “”” 筛选筛选文本对应的图像
:param img_path: 源标签目录
:param txt_path: 标签收集文本路径
:param target_path: 目标图像路径
:return:
"""
img_ids = open(txt_path).read().strip().split() # 读取txt文件
os.makedirs(target_path)
for img_id in img_ids:
path = str(img_path) + '/%s.jpg' % img_id
shutil.copy(path, target_path)
if name == ‘main‘: source_annotation = Path(data_path + ‘/Annotation’) # 源标签目录 source_images = Path(data_path + ‘/Images’) # 源图像目录 target_annotation = Path(save_path + ‘/Annotation’) # 目标标签目录 target_images = Path(save_path + ‘/Images’) # 目标图像目录
get_filename_txt(source_annotation, annotation_txt) # 获取文件名信息 至 txt文件
shutil.copytree(source_annotation, target_annotation) # 复制源标签文件 至 目标标签目录
filter_image(source_images, annotation_txt, target_images) # 筛选文本对应的 至 目标图像目录
print("DONE!")
<a name="efSxH"></a>
## **图像标注**处理脚本/工具(统一标注文件内容)
- **maketext.py(生成数据集分类文件)**
```python
# -*- coding: utf-8 -*-
"""
# 生成数据集分类文件
-------------------
作用:
- 用于将样本数据进行分类(分为train,valid,test)
实现:
- 根据设置的比例进行随机分配(训练验证集比例决定了测试集比例,训练集比例决定验证集比例)
"""
# Standard parties
import os
import random
import argparse
# 运行指令参数
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='./data/augment/labels', type=str, help='input xml label path')
parser.add_argument('--txt_path', default='./data/texts', type=str, help='output txt label path')
opt = parser.parse_args()
# 设置数据分配比例,剩下的会分配给测试集(1-训练验证集比例)
trainval_percent = 0.9 # 训练验证集比例
train_percent = 0.8 # 训练集比例,剩下的就是验证集
# 获取参数(xml文件路径、txt存放路径)
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
# mxl文件列表
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
# 分配数据集
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
# 随机获取一定数量的数据
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
# 将txt文件设为可写状态
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/valid.txt', 'w')
# txt文件写入内容
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
# 关闭txt文件
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
print("DONE!")
- fixNodeText.py(适用于YOLOv3,已弃用)
该脚本用于当图像标注数据源于不同成员,需要在训练之前将数据统一。若xml文件出现中文字符,则会出现’gbk’编码解析失败错误
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import listdir, getcwd
sets = ['train', 'val', 'test']
def change_text(image_id, path):
"""改变xml文件中节点内容,适用VOC格式数据,更改<folder>, <path>
:param image_id: 影像文件编号
:param path: 需要更改的目标路径
:return:
"""
# 获取path参数的最后一个’/‘后的字符串,即文件夹名称
foldername = path.split('/')[-1]
# 获取xml文件——(待处理的文件)
input_file = open('data/Pomelotree/toFormat/%s.xml' % image_id)
# 解析xml文件
tree = ET.parse(input_file)
# 读取xml根节点
root = tree.getroot()
# (n代表节点node)获取文件名称、文件所在文件夹名称
n_filename = root.find('filename').text
# 替换文件夹名称
n_folder = root.find('folder')
n_folder.text = foldername
# 拼接路径(path + n_filename)
fullpath = path + '/' + n_filename
n_path = root.find('path')
n_path.text = fullpath
# 修改后文件的保存路径
tree.write('data/Pomelotree/Annotations/%s.xml' % image_id)
wd = getcwd()
print(wd)
for image_set in sets:
# 获取图片id
image_ids = open('data/Pomelotree/ImageSets/%s.txt' % image_set).read().strip().split()
list_file = open('data/Pomelotree/%s.txt' % image_set, 'w')
for image_id in image_ids:
list_file.write('data/Pomelotree/images/%s.jpg\n' % image_id)
change_text(image_id, 'data/Pomelotree/Annotations')
list_file.close()
print('Done!')
yolov5-format.py(适用于YOLOv5) ```python
-- coding: utf-8 --
“””
制作YOLOv5格式的样本数据集
作用:
- 用于YOLOv5模型训练 实现:
根据maketext.py生成的txt文件(train.txt,valid.txt,test.txt)中指定的数据编号进行分配数据
结果数据组织结构:
yolov5_format ├─ train │ ├─ labels │ │ ├─ 。。。 │ │ └─ xxx.txt │ └─ images │ ├─ 。。。 │ └─ xxx.jpg ├─ valid │ ├─ labels │ │ ├─ 。。。 │ │ └─ xxx.txt │ └─ images │ ├─ 。。。 │ └─ xxx.jpg └─ test ├─ labels │ ├─ 。。。 │ └─ xxx.txt └─ images ├─ 。。。 └─ xxx.jpg
“””
Standard parties
import xml.etree.ElementTree as ET import os import shutil
Third parties
from tqdm import tqdm
sets = [‘train’, ‘valid’, ‘test’] classes = [‘PT’]
def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = round(x dw, 8) w = round(w dw, 8) y = round(y dh, 8) h = round(h dh, 8) return x, y, w, h
def convert_annotation(image_set, image_id): try: in_file = open(‘./data/augment/labels/%s.xml’ % image_id, encoding=’utf-8’) # 标签xml文件 out_file = open(‘./data/yolov5_format/%s/labels/%s.txt’ % (image_set, image_id), ‘w’, encoding=’utf-8’) # maketext文件分配的txt文件 tree = ET.parse(in_file) root = tree.getroot() size = root.find(‘size’) w = int(size.find(‘width’).text) h = int(size.find(‘height’).text) for obj in root.iter(‘object’):
# difficult = obj.find('difficult').text or None
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), \
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
# 负数处理
bblist = []
for a in bb:
if a < 0:
bblist.append(True)
continue
else:
bblist.append(False)
if True in bblist:
continue
else:
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
except Exception as e:
print(e, image_id)
def copy_image(image_set, image_id): try: source = ‘./data/augment/images/%s.jpg’ % image_id target = ‘./data/yolov5_format/%s/images/‘ % image_set shutil.copy(source, target) except IOError as e: print(“Unable to copy file. %s” % e)
for image_set in sets:
# 判断是否存在指定目录,不存在则创建
if not os.path.exists('./data/yolov5_format/%s' % image_set):
os.makedirs('./data/yolov5_format/%s' % image_set)
os.makedirs('./data/yolov5_format/%s/images' % image_set)
os.makedirs('./data/yolov5_format/%s/labels' % image_set)
# 获取图像的id
image_ids = open('./data/texts/%s.txt' % image_set).read().strip().split()
# list_file = open('E:/Study/01_Projects/PomeloDetection/02_Datasets/TempDataset/VOCData/%s.txt' % (image_set), 'w')
for image_id in tqdm(image_ids):
# list_file.write('VOCData/20210405/Images/%s.jpg\n' % (image_id))
# 复制jpg文件
copy_image(image_set, image_id)
# 转换xml信息
convert_annotation(image_set, image_id)
# list_file.close()
- **modify-xml.py(适用于标签文件)**
```python
"""
# 修改/统一标签文件(.xml)指定内容
------------------------------------
作用:
- 统一修改多人协作制作的标签文件
实现:
- 对每个文件xml节点进行提取,通过配置项进行修改
待处理数据组织结构:
----------------------------
dataset
├─ Annotation
│ ├─ 。。。
│ └─ xxx.xml
└─ Images
├─ 。。。
└─ xxx.jpg
----------------------------
"""
# Standard parties
import os
from pathlib import Path
import xml.etree.ElementTree as ET
# Third parties
# Configuration
annotation_path = 'E:/Study/01_Projects/PomeloDetection/02_Datasets/23-20210413/combine/labels' # 标注目录
union = {
'folder': 'Annotation', # xml所属文件夹
'database': 'PomeloTree', # 数据库名称
'name': 'PT' # 类别名称(只适合single class)
}
def modify_info(input_file, dic):
"""
改变xml文件中节点内容(基础信息),适用VOC格式数据,更改<folder>, <path>
:param input_file: 影像的标注文件编号
:param dic: 需要更改的目标路径
:return:
"""
folder, database, name = dic['folder'], dic['database'], dic['name']
tree = ET.parse(input_file) # 解析xml
# 获取xml节点
root = tree.getroot() # 读取xml根节点
n_folder = root.find('folder') # 文件夹节点
n_filename = root.find('filename') # 文件节点
n_path = root.find('path') # 绝对路径
n_source = root.find('source') # 数据源节点
n_database = n_source.find('database') # 数据库节点
# 获取xml信息
v_filename = n_filename.text
# 替换xml信息
n_folder.text = folder
abspath = os.path.abspath(os.path.join(os.getcwd(), "..")) # 当前文件所在上上级绝对路径
n_path.text = abspath + '\\' + n_folder.text + '\\' + v_filename
n_database.text = database
for obj in root.iter('object'):
n_name = obj.find('name')
n_name.text = name
# 修改后文件的保存路径
tree.write(input_file.name)
def modify_coordinate(input_file):
"""
修改xml文件中坐标带小数位的情况(四舍五入),适用于ArcGIS导出的样本
:param input_file: 影像的标注文件编号
:return:
"""
# bndbox_list = read_coordinate(input_file) # 读取所有boundingbox的坐标
bndbox_list = []
tree = ET.parse(input_file) # 解析xml
# 获取xml节点
root = tree.getroot() # 读取xml根节点
index = 0
for obj in root.findall('object'): # 找到root节点下的所有object节点
bndbox = obj.find('bndbox') # 子节点下节点rank的值
# 坐标信息
new_xmin = int(round(float(bndbox.find('xmin').text)))
new_ymin = int(round(float(bndbox.find('ymin').text)))
new_xmax = int(round(float(bndbox.find('xmax').text)))
new_ymax = int(round(float(bndbox.find('ymax').text)))
# 更改坐标信息
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
tree.write(input_file.name)
if __name__ == '__main__':
xml_list = os.listdir(Path(annotation_path))
for xml in xml_list:
file = open(annotation_path + '/' + xml)
# 更改内容(类名...)
modify_info(file, union)
# 更改坐标(小数点四舍五入,保留整数)
# modify_coordinate(file)
file.close()
print("DONE!")
数据增强脚本/工具
ia.seed(1)
def read_xml_annotation(root, image_id): in_file = open(os.path.join(root, image_id)) tree = ET.parse(in_file) root = tree.getroot() bndboxlist = []
for object in root.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
xmin = int(round(float(bndbox.find('xmin').text)))
xmax = int(round(float(bndbox.find('xmax').text)))
ymin = int(round(float(bndbox.find('ymin').text)))
ymax = int(round(float(bndbox.find('ymax').text)))
# print(xmin,ymin,xmax,ymax)
bndboxlist.append([xmin, ymin, xmax, ymax])
# print(bndboxlist)
bndbox = root.find('object').find('bndbox')
return bndboxlist
(506.0000, 330.0000, 528.0000, 348.0000) -> (520.4747, 381.5080, 540.5596, 398.6603)
def change_xml_annotation(root, image_id, new_target): new_xmin = new_target[0] new_ymin = new_target[1] new_xmax = new_target[2] new_ymax = new_target[3]
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
xmlroot = tree.getroot()
object = xmlroot.find('object')
bndbox = object.find('bndbox')
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
tree.write(os.path.join(root, str("%09d" % (str(id) + '.xml'))))
def change_xml_list_annotation(root, image_id, new_target, saveroot, id): in_file = open(os.path.join(root, str(image_id) + ‘.xml’)) # 这里root分别由两个意思 tree = ET.parse(in_file) elem = tree.find(‘filename’) elem.text = (str(“%09d” % int(id)) + ‘.jpg’) xmlroot = tree.getroot() index = 0
for object in xmlroot.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
# xmin = int(bndbox.find('xmin').text)
# xmax = int(bndbox.find('xmax').text)
# ymin = int(bndbox.find('ymin').text)
# ymax = int(bndbox.find('ymax').text)
new_xmin = new_target[index][0]
new_ymin = new_target[index][1]
new_xmax = new_target[index][2]
new_ymax = new_target[index][3]
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
tree.write(os.path.join(saveroot, str("%09d" % int(id)) + '.xml'))
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if name == “main“:
IMG_DIR = "./data/origin/images"
XML_DIR = "./data/origin/labels"
AUG_IMG_DIR = "./data/augment/images" # 存储增强后的影像文件夹路径
AUG_XML_DIR = "./data/augment/labels" # 存储增强后的XML文件夹路径
try:
shutil.rmtree(AUG_XML_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_XML_DIR)
try:
shutil.rmtree(AUG_IMG_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_IMG_DIR)
AUGLOOP = 5 # 每张影像增强的数量
boxes_img_aug_list = []
new_bndbox = []
new_bndbox_list = []
# 影像增强
seq = iaa.Sequential([
iaa.OneOf([
# 翻转
iaa.Flipud(1), # 上下翻转,50%的数据集
iaa.Fliplr(1), # 左右翻转,50%的数据集
]),
iaa.OneOf([
# 像素运算
iaa.Multiply((0.8, 1.2)), # 在不影响Bounding box的基础上,改变每个像元的亮度,随机对每个像素乘以0.8~1.2
iaa.MultiplyElementwise((0.8, 1.2)), # 在不影响Bounding box的基础上,将像素值与相邻像素可能不同的值相乘,改变每个像元的亮度,随机对每个像素乘以0.8~1.2
]),
iaa.OneOf([
# 模糊效果
iaa.GaussianBlur(sigma=(0.0, 3.0)), # 高斯模糊
# 噪声效果
iaa.AdditiveGaussianNoise(scale=(0, 0.2 * 255)), # 高斯噪声
]),
iaa.Sometimes(
0.8,
# 图像旋转
iaa.Affine(
scale=(0.5, 0.7), # 将图像缩放至原始大小的0.5~0.7
rotate=(-180, 180) # 将图像旋转-180~180
) # 影响Bounding box的位置
)
])
for root, sub_folders, files in os.walk(XML_DIR):
for name in files:
bndbox = read_xml_annotation(XML_DIR, name)
shutil.copy(os.path.join(XML_DIR, name), AUG_XML_DIR)
shutil.copy(os.path.join(IMG_DIR, name[:-4] + '.jpg'), AUG_IMG_DIR)
for epoch in range(AUGLOOP):
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
# sp = img.size
img = np.asarray(img)
# bndbox 坐标增强
for i in range(len(bndbox)):
bbs = ia.BoundingBoxesOnImage([
ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),
], shape=img.shape)
bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]
boxes_img_aug_list.append(bbs_aug)
# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]
n_x1 = int(round(float(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))))
n_y1 = int(round(float(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))))
n_x2 = int(round(float(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))))
n_y2 = int(round(float(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))))
if n_x1 == 1 and n_x1 == n_x2:
n_x2 += 1
if n_y1 == 1 and n_y2 == n_y1:
n_y2 += 1
if n_x1 >= n_x2 or n_y1 >= n_y2:
print('error', name)
new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR,
str("%09d" % (len(files) + int(name[:-4]) + epoch * 250)) + '.jpg')
image_auged = bbs.draw_on_image(image_aug, size=0)
# RGBA (PNG),上面的文件后缀需要修改为.png
# Image.fromarray(image_auged).save(path)
# RGB (JEPG)
Image.fromarray(image_auged).convert('RGB').save(path)
# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,
len(files) + int(name[:-4]) + epoch * 250)
print(str("%09d" % (len(files) + int(name[:-4]) + epoch * 250)) + '.jpg')
new_bndbox_list = []
<a name="1sfer"></a>
## 数据集配置文件
- data.yaml
用“记事本”的打开,并设置成模型训练时所需即可,用于YOLOv5路由数据集
train: ../train/images val: ../valid/images
nc: 1 names: [‘PT’]
<a name="pnlkw"></a>
# 🚀训练日志
<a name="oQ2JL"></a>
## YOLOv3 [2020.12.19]
<a name="9BJY8"></a>
### 1. 前提准备 [2020.12.5-2020.12.19]
- 模型
[YOLOv3](https://github.com/ultralytics/yolov3),在GitHub中将该模型clone下来(日期:2020.12.5),根据`./requirements.txt`配置运行该模型所需的相关模块/库,或通过PyCharm打开该工程,在Terminal中使用命令`pip install -r requirements.txt`一键配置
- 数据
柚树样本集(Annotations[xml]+Images[256*256 .jpg])制作
- 首先通过**Tif_Segment.py(图像裁剪脚本)**将原始图像裁剪成256*256大小,重复度为25%的图像
- 再使用**tif2jpg.py(格式转换脚本)**对这些裁剪好的图像进行格式转换(.tif -> .jpg)
- 最后使用**labelImg(图像标注工具)**,以无人机航拍数据于实地考察数据叠加后的图层作为参考,制作图像标注,生成VOC格式的XML文件
<a name="eDxo2"></a>
### 2. 训练前配置
<a name="uq4M2"></a>
#### 2.1 样本数据文件组织结构
data └─ Pomelotree # 项目文件 ├─ Annotations # 注释xml文件 │ ├─ x.xml │ ├─ xx.xml │ ├─ … │ └─ nx.xml ├─ Annotations-origin # 待处理的注释xml文件 │ ├─ x.xml │ ├─ xx.xml │ ├─ … │ └─ nx.xml ├─ images # 图像文件 │ ├─ x.jpg │ ├─ xx.jpg │ ├─ … │ └─ nx.jpg ├─ ImageSets # 过渡处理文件 │ ├─ test.txt │ ├─ train.txt │ ├─ trainval.txt │ └─ val.txt ├─ JEPGImages # 图像文件-备份 │ ├─ x.jpg │ ├─ xx.jpg │ ├─ … │ └─ nx.jpg └─ labels # 注释txt文件 ├─ x.txt ├─ xx.txt ├─ … └─ nx.txt
<a name="r60gi"></a>
#### 2.2 数据读取配置
- 制作文本文件
制做该文本文件用于将样本数据进行分类,按一定比例分配**训练数据 | 测试数据 | 验证数据**
- **maketxt.py**
```python
import os
import random
trainval_percent = 0.8 # 训练验证集比重
train_percent = 0.8 # 训练集比重
xmlfilepath = 'data/Pomelotree/Annotations-origin' # 人工标注的xml文件路径
txtsavepath = 'data/Pomelotree/ImageSets' # 文本文件存放路径
total_xml = os.listdir(xmlfilepath) # 获取xml文件的数量
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent) # 在样本集的基础上计算训练集的数量
tr = int(tv * train_percent) # 在训练集的基础上计算训练验证集的数量
trainval = random.sample(list, tv) # 随机获取 - 训练集
train = random.sample(trainval, tr) # 随机获取 - 训练验证集
# 将文本文件设置可写
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n' # 获取文件名称(去掉文件扩展名)
if i in trainval: # 判断单个图像文件是否作为训练验证集
ftrainval.write(name) # True,写入训练验证集文本文件中
if i in train: # 判断单个训练验证文件是否作为于训练集中
ftest.write(name) # True,写入测试集文本文件中
else:
fval.write(name) # False,写入验证集文件中
else:
ftrain.write(name) # False,写入训练集文件中
# 关闭文件
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
# 完成制作
print('Done!')
- 制作标注文本文件
制作该文件用于导出标注好的xml文件中的相关信息,并作归一化处理,得到 cls_id x y w h
- voc_label.py
```python
-- coding: utf-8 --
import xml.etree.ElementTree as ET import os from os import getcwdsets = [(‘2007’, ‘train’), (‘2007’, ‘val’), (‘2007’, ‘test’)]
VOC数据集类型:
classes = [“aeroplane”, “bicycle”, “bird”, “boat”, “bottle”, “bus”, “car”, “cat”, “chair”, “cow”, “diningtable”,
“nodogse”, “horse”, “motorbike”, “person”, “sheep”, “nose”, “sofa”, “train”, “tvmonitor”]
sets = [‘train’, ‘val’, ‘test’] # 项目所需数据集 classes = [“Pomelo tree”] # 数据集的类型
def convert(size, box): “””将图像大小和bounding box的大小归一化
:param size: 图像大小
:param box: bounding box的大小
:return:
x: 归一化后的图像的中心x坐标
y: 归一化后的图像的中心y坐标
w: 归一化后的bounding box的宽度
h: 归一化后的bounding box的长度
"""
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return x, y, w, h
def convert_annotation(image_id): “””将注释文件xml转化为文本值 [cls_id x y w h], 其中x,y,w,h都会归一化为0-1之间的值
:param image_id: 影像文件编号
:return:
"""
in_file = open('data/Pomelotree/Annotations/%s.xml' % image_id) # 将数据集放于当前目录下
out_file = open('data/Pomelotree/labels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text) # 256
h = int(size.find('height').text) # 256
for obj in root.iter('object'):
difficult = obj.find('difficult').text # 目标是否难以识别,0/1,0表示容易识别
cls = obj.find('name').text # 目标类型
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls) # 得到目标类型的索引值
xmlbox = obj.find('bndbox') # 得到bounding box
# 获取bounding box的左下角和右上角坐标
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# 归一化处理
bb = convert((w, h), b)
# 将处理后的数据写入文本文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd() print(wd) for image_set in sets:
# 不存在labels路径则新建路径
if not os.path.exists('data/Pomelotree/labels/'):
os.makedirs('data/Pomelotree/labels/')
image_ids = open('data/Pomelotree/ImageSets/%s.txt' % image_set).read().strip().split() # 图像的ID
list_file = open('data/Pomelotree/%s.txt' % image_set, 'w') # 列表文件,即图像数据集文件(train, val, test)
for image_id in image_ids:
list_file.write('data/Pomelotree/images/%s.jpg\n' % image_id) # 写入图像路径
# 处理xml文件
convert_annotation(image_id)
# 关闭文件
list_file.close()
完成制作
print(‘Done!’)
- 制作训练数据文件[.data]
将训练所需的文件制作网络模型能够识别并读取的格式.data,其实就是一个Python字典的格式
- **pomelotree.data**
**注意:**目前版本所需的.data文件与网上教程.data对比
- 以前版本是纯文本格式;当前版本是Python字典格式
- classes → nc
- valid → val
- 以前版本中的names的值是文件路径(因此需要多一个.names的文件),当前版本是以数组形式将训练类型写入(省略.names文件)
```python
classes=1
train=data/train.txt
valid=data/test.txt
names=data/rbc.names
backup=backup/
eval=coco
曾经版本
{
'nc':1,
'train':data/Pomelotree/train.txt,
'val':data/Pomelotree/test.txt,
'names':[Pomelo_tree,],
'backup':backup/,
'eval':coco
}
2.3 模型训练配置
- 下载预训练模型权重文件
在工程中找到./weights/download_weights.sh,Windows系统需要在git的cmd中执行该文件(但不确定下载速度),因此同样可以通过PyCharm打开该文件,通过拼接其中的链接(例如 https://github.com/ultralytics/yolov3/releases/yolov3-tiny.pt)然后使用下载器(比如 IDM)下载预训练模型权重文件
#!/bin/bash
# Download latest models from https://github.com/ultralytics/yolov3/releases
python - <<EOF
from utils.google_utils import atempt_downloadt
for x in ['yolov3', 'yolov3-spp', 'yolov3-tiny']:
attempt_download(f'{x}.pt')
EOF
- 配置训练脚本
不管是工程中的训练脚本./train.py ,或者是测试脚本./test.py ,甚至是检测脚本./detect.py,又都一部分代码是对参数的配置。这里以训练脚本./train.py为例,配置完成后即可运行脚本,等待训练结果。
- train.py
if __name__ == '__main__': parser = argparse.ArgumentParser() # 预训练模型权重文件 parser.add_argument('--weights', type=str, default='yolov3.pt', help='initial weights path') # 神经网络文件 parser.add_argument('--cfg', type=str, default='models/yolov3-tiny.yaml', help='model.yaml path') # 需要训练的数据(需要在外部配置) parser.add_argument('--data', type=str, default='data/Pomelotree/pomelotree.data', help='data.yaml path') parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path') # 迭代次数/训练次数 parser.add_argument('--epochs', type=int, default=1000) # 批处理小大(根据自身设备设置,数值[一般为8的倍数]越大,所占的GPU内存则会越大,太大则会出现'CUDA out of memory'错误) parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs') # 图像的大小 parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes') parser.add_argument('--rect', action='store_true', help='rectangular training') parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training') parser.add_argument('--nosave', action='store_true', help='only save final checkpoint') parser.add_argument('--notest', action='store_true', help='only test final epoch') parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check') parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters') parser.add_argument('--bucket', type=str, default='', help='gsutil bucket') parser.add_argument('--cache-images', action='store_true', help='cache images for faster training') parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training') # 处理器设置(CPU/GPU) parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%') parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset') parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer') parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode') parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify') parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100') # 线程数(数值设置过大,可能会出现'页面文件太小,无法完成操作'错误) parser.add_argument('--workers', type=int, default=1, help='maximum number of dataloader workers') # 训练相关文件保存路径 parser.add_argument('--project', default='runs/train', help='save to project/name') # 项目名 parser.add_argument('--name', default='pt1000', help='save to project/name') parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment') opt = parser.parse_args()3. 训练结果查看
- 训练时间
本次迭代1000次,花费1.203小时
- 训练效果
平均精确度(mAP):0.487
召回率:0.7左右

- 样本与预测对比


4. 总结
总体而言,此次训练的效果不够好,因为平均精度值只达到48.7%,但这是第一次对几个月前采集回来柚树数据进行样本制作并进行训练,是个好的开始,经过分析,效果不好的原因有两点:
- 数据量少
数据用这最原始的数据,并没有对样本数据进行数据增强(数据扩增),导致训练的数据量太少,精度则不理想
- 模型太小
受限于设备配置,只能暂时使用yolov3-tiny模型进行训练,相比起yolov3模型,yolov3-tiny模型训练时损失了很多细节的学习,因此进度自然不会很理想
5. 后续计划
- 使用数据增强方法,暂时使用几何操作类(随机旋转,随机裁剪,翻转)的增强方式,对数据量进行扩增;并将颜色变化类(噪声,模糊,颜色变化等操作)纳入考虑范围。
- 去租赁一个GPU计算服务器,使用更大的网络模型去训练
YOLOv5 [2021.02.28]
1. 前提准备 [2021.02.06-2021.02.28]
- 数据:
与YOLOv3制作数据集的步骤一样,但不同的是图像的大小与图像重复度。制作柚树样本集(Annotations[xml]+Images[418*418 .jpg])
- 首先通过Tif_Segment.py(图像裁剪脚本)将原始图像裁剪成418*418大小,重复度为80%的图像
- 再使用tif2jpg.py(格式转换脚本)对这些裁剪好的图像进行格式转换(.tif -> .jpg)
- 最后使用labelImg(图像标注工具),以无人机航拍数据于实地考察数据叠加后的图层作为参考,制作图像标注,生成VOC格式的XML文件
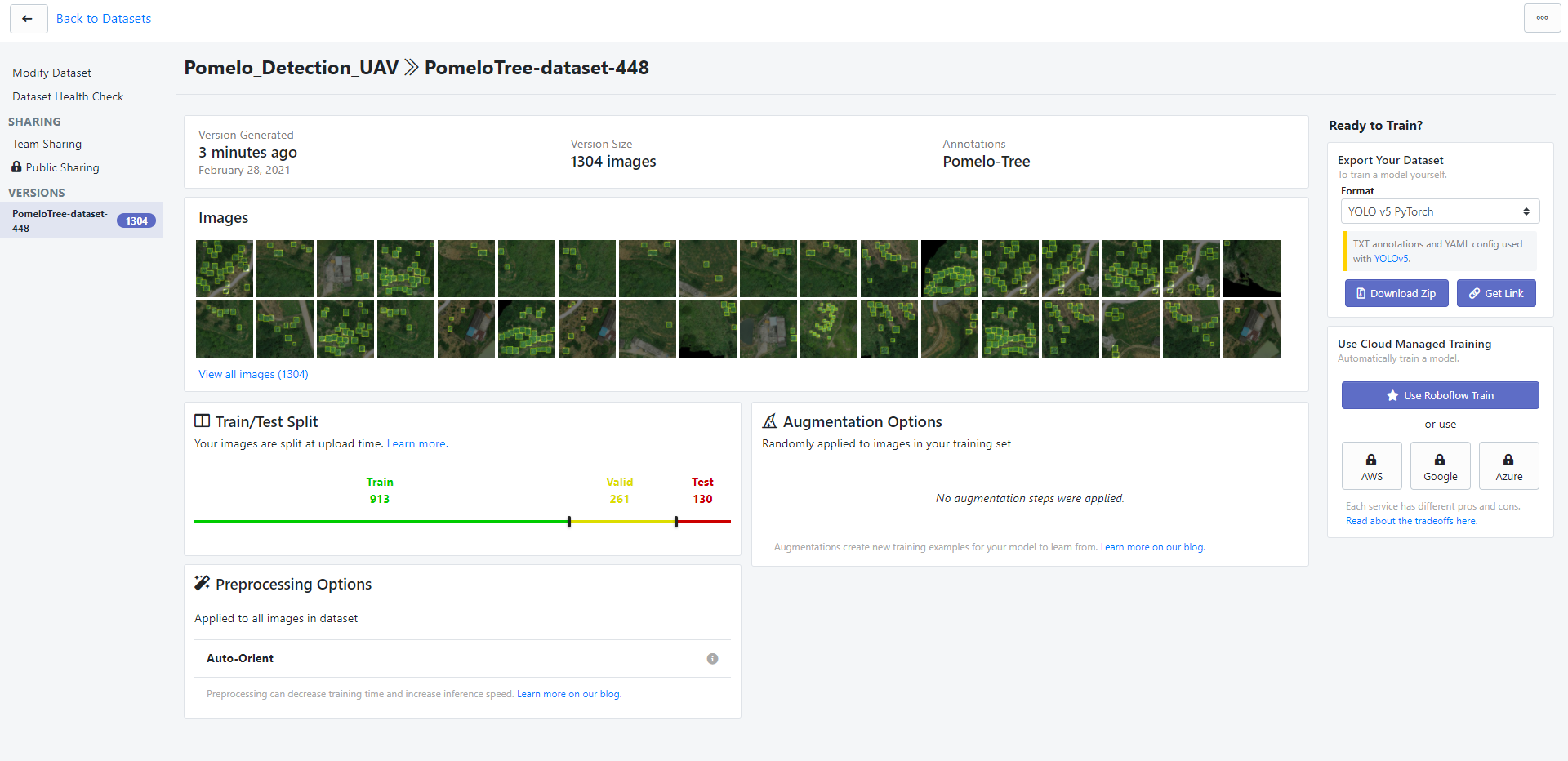
- 使用平台:
- Roboflow:将数据集上传,并可选择性进行数据增强(部分功能需要付费),最终导出适合YOLOv5训练的训练格式(后续通过自己的代码制作了类似的数据集,使得模型能够正常训练)
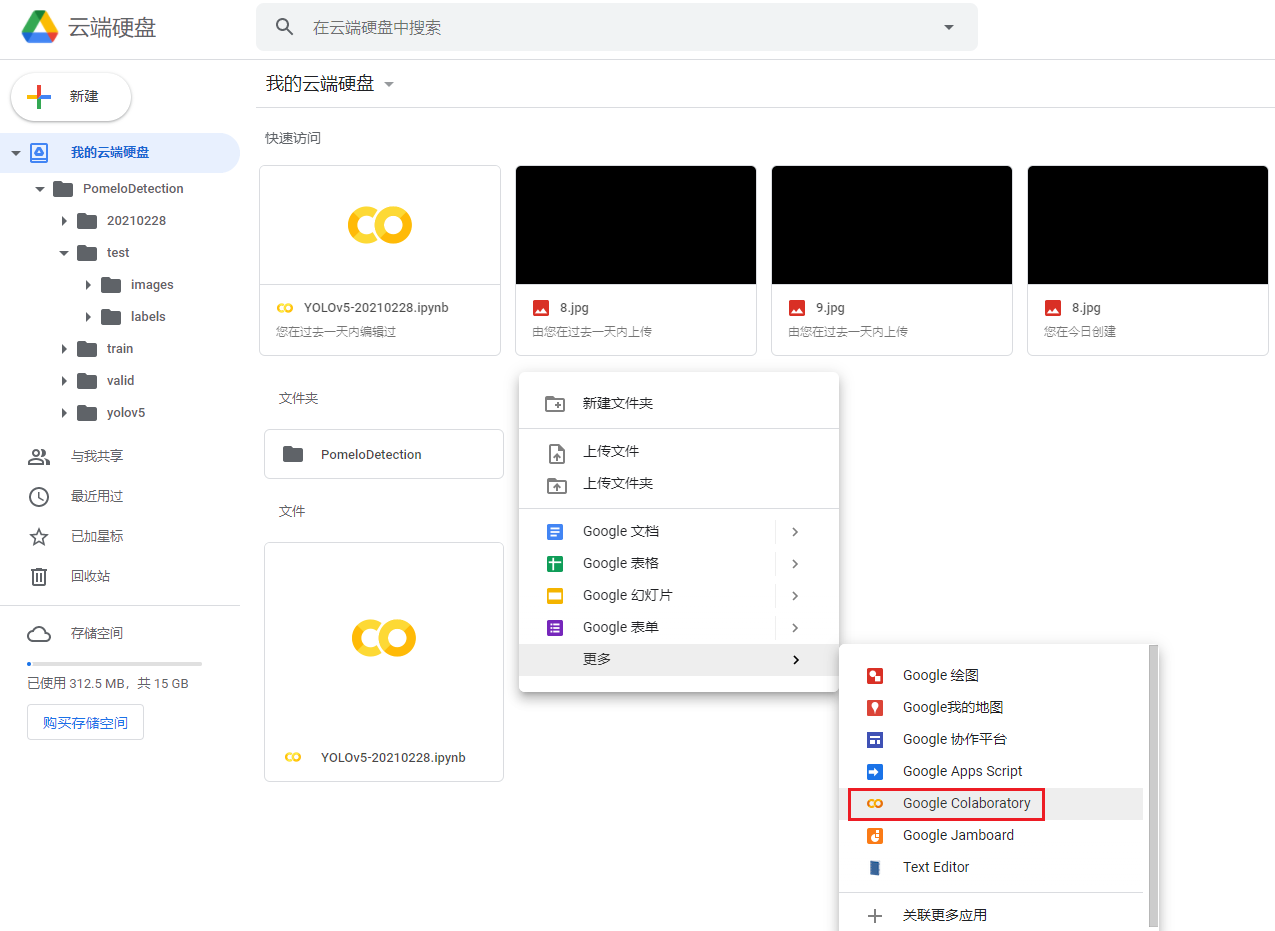
- Google Colaboratory:类似一个Jupyter notebook的服务,同时提供了免费的GPU和TPU运行环境。可以挂载Google drive目录到Colaboratory的工作目录下
2. 训练前配置
2.1 样本数据文件组织结构
PomeloDetection
├─ data.yaml # 数据集配置文件
├─ train # 训练数据集文件夹
│ ├─ images # 图像文件,下同
│ │ ├─ x.jpg
│ │ ├─ xx.jpg
│ │ ├─ ...
│ │ └─ nx.jpg
│ └─ labels # 标注文件,下同
│ ├─ x.xml
│ ├─ xx.xml
│ ├─ ...
│ └─ nx.xml
├─ test # 测试数据集文件夹
│ ├─ images
│ │ ├─ x.jpg
│ │ ├─ xx.jpg
│ │ ├─ ...
│ │ └─ nx.jpg
│ └─ labels
│ ├─ x.xml
│ ├─ xx.xml
│ ├─ ...
│ └─ nx.xml
└─ valid # 验证数据集文件夹
├─ images
│ ├─ x.jpg
│ ├─ xx.jpg
│ ├─ ...
│ └─ nx.jpg
└─ labels
├─ x.xml
├─ xx.xml
├─ ...
└─ nx.xml
2.2 模型训练配置
具体详见Google Colaboratory中的训练文件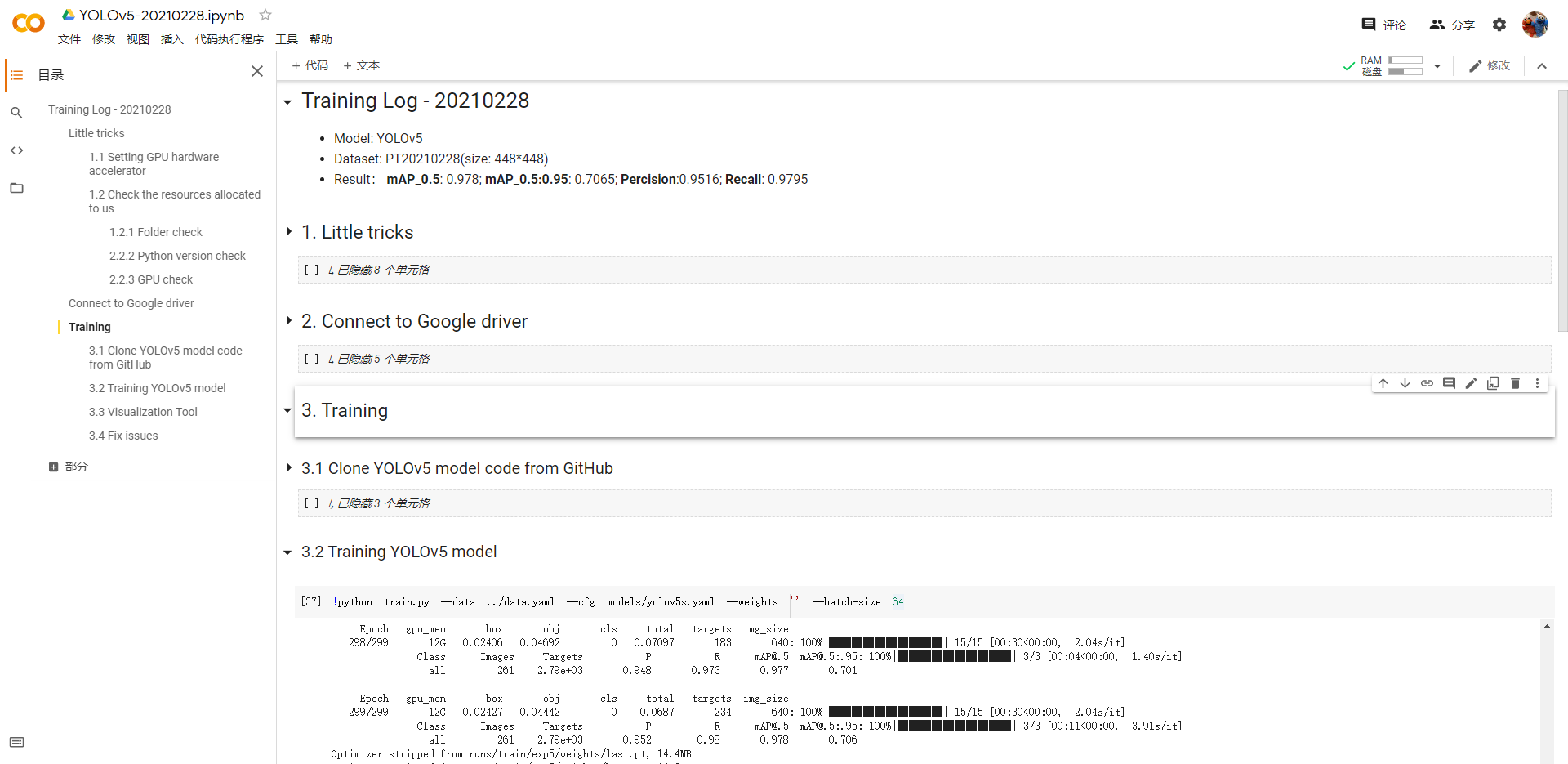
3. 训练结果查看
- 训练时间
本次迭代300次,花费3.021小时
- 训练效果
平均精确度(mAP_0.5):0.978
平均精确度(mAP_0.5:0.95):0.7065
精度(Percision):0.9516
召回率(Recall):0.9795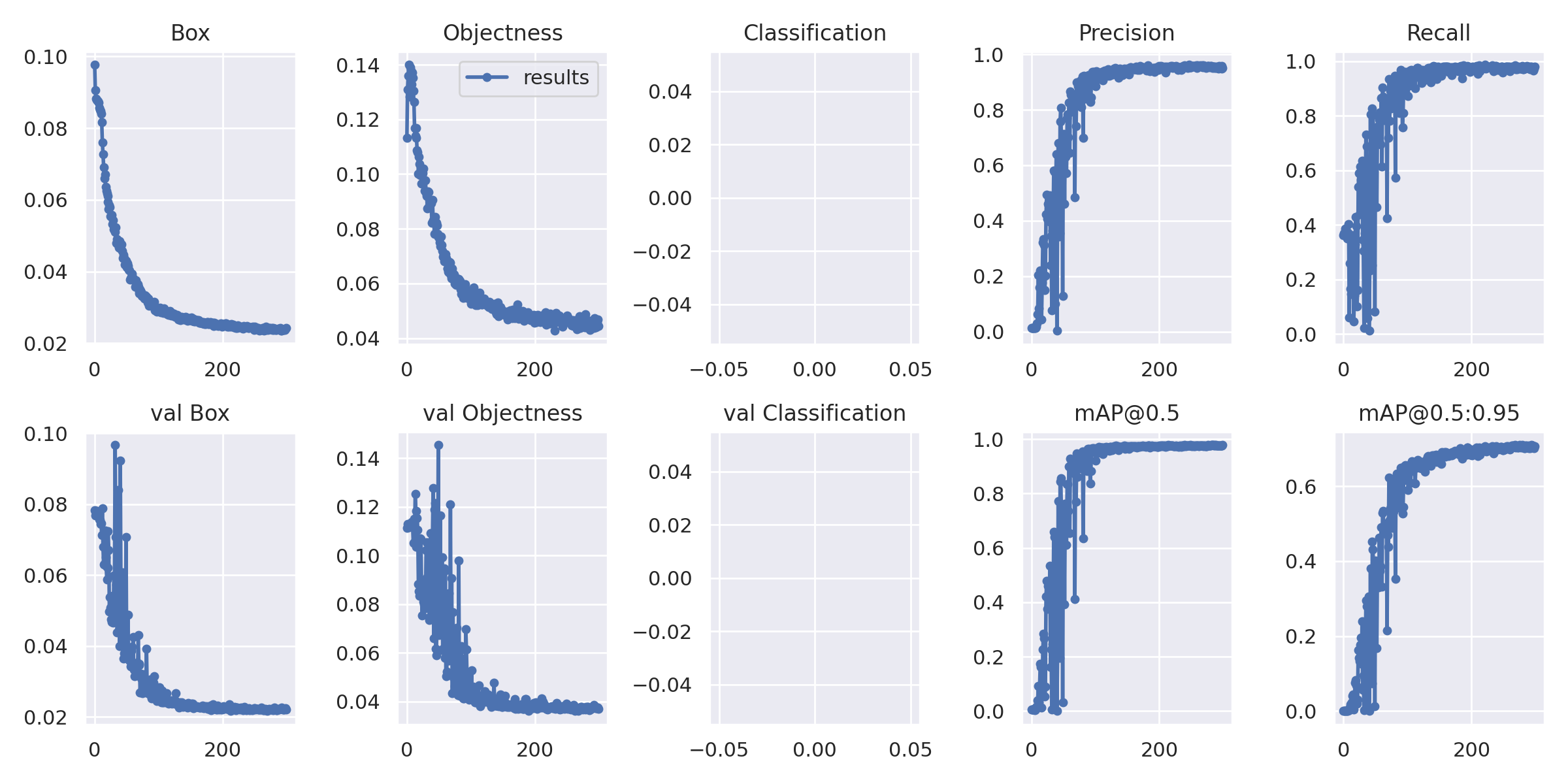
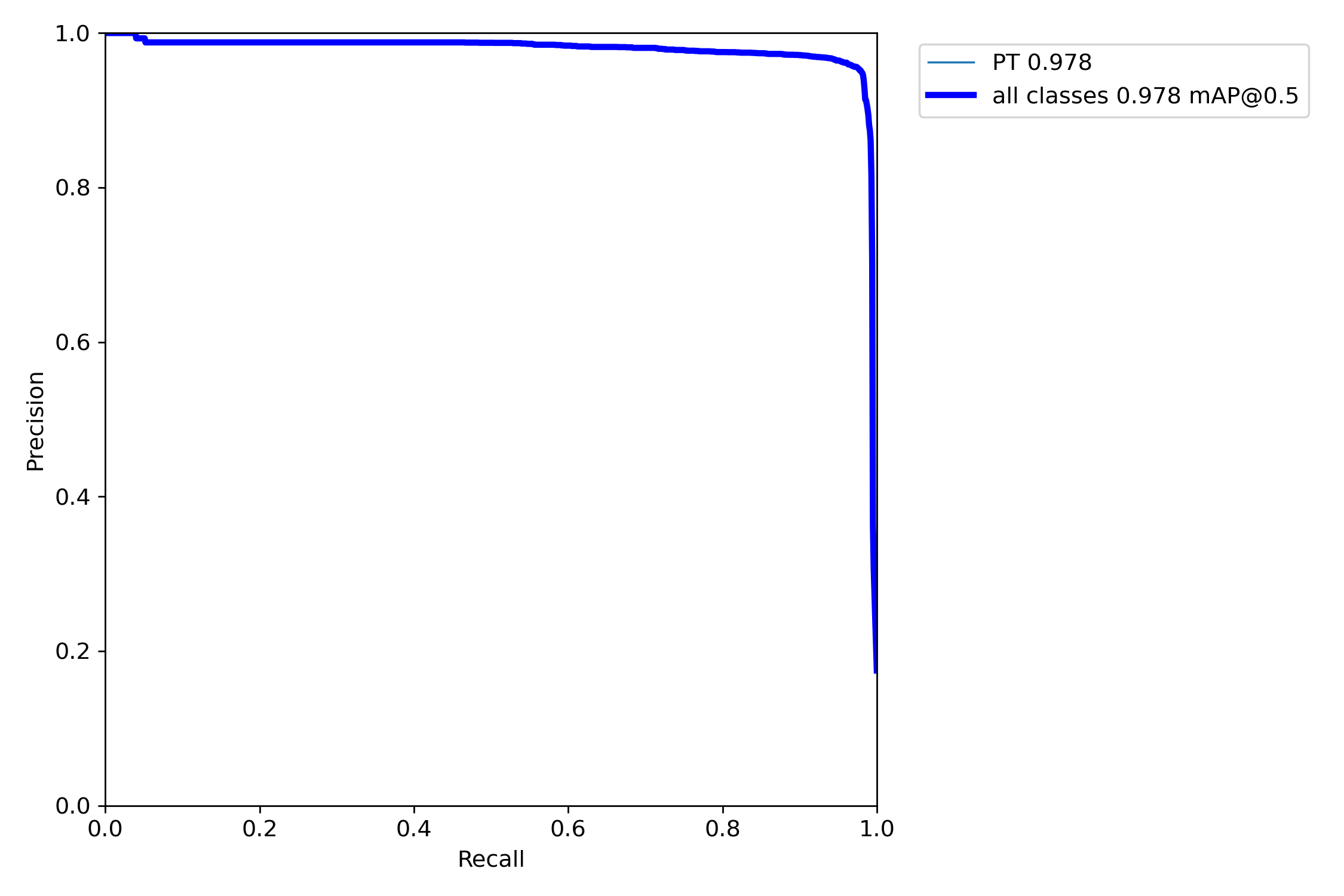
- 样本与预测对比


4. 总结
看起来,此次训练的效果非常不错,平均精度值(mAP)能够达到97.8%,根据第一次训练的不同,选择了新的模型YOLOv5,以及使用云GPU进行训练。但尝试了检测近期的新数据,结果却是十分糟糕的,检测一个果园的数据但一棵柚树都识别不出来。经过分析,效果不好的原因有两点:
- 模型泛化能力差
数据集没有进行预处理(数据增强),只能适合当前色调的图像。
- 模型深度和宽度较小
此次训练使用yolov5s模型进行训练,是yolov5最小规格的模型
5. 后续计划
- 考虑预处理,将可能的情况列表记录,询问老师是否有相关办法解决
- 使用数据增强方法,暂时使用几何操作类(随机旋转,随机裁剪,翻转)的增强方式,对数据量进行扩增;并将颜色变化类(噪声,模糊,颜色变化等操作)纳入考虑范围。
- 尝试规模大一点的模型进行训练
YOLOv5 [2021.04.02]
1. 前提准备 [2021.04.02]
与[2021.02.28]的训练保持一致,只是增加了数据增强的部分:旋转90/180/270度和高斯模糊。
2. 训练前配置
训练epoch还是300。训练数据集2593个,验证集261个和测试集130个。
3. 训练结果查看
- 训练时间
本次迭代300次,花费8.024小时
- 训练效果
平均精确度(mAP_0.5):0.9729
平均精确度(mAP_0.5:0.95):0.6959
精度(Percision):0.9603
召回率(Recall):0.9641
4. 总结
此次训练的效果与上次相似,没有测试其他数据集,应该结果也是不好的。
- 大概训练到150个epoch的时候模型就已经稳定了,因此也不需要再训练到300epoch。
通过数据增强并没有办法提高精度,可能是这个精度已经很好了;也可能是应为数据集比较单一,没有负样本;也可能是增强方式单一。
5. 后续计划
更换数据增强方法,使用几何操作类随机旋转和添加高斯噪声的增强方式对数据量进行扩增;
- 考虑预处理,增强红色通道(通过对比绿色和蓝色通道,发现红色通道的柚树边缘和纹理比较明显)
- 做种考虑提取部分,暂时用来做毕设,随机森林+形态学处理
YOLOv5 [2021.04.06]
1. 前提准备 [2021.04.06]
与[2021.02.28]的训练保持一致,随机数据增强的部分:上下/左右翻转、高斯模糊、高斯噪声。2. 训练前配置
训练epoch还是100。训练数据集2164个,验证集240个,测试集0个。3. 训练结果查看
- 训练时间
本次迭代100次,花费2.49小时
- 训练效果
平均精确度(mAP_0.5):0.9373
平均精确度(mAP_0.5:0.95):0.6154
精度(Percision):0.9488
召回率(Recall):0.8664
- 样本与预测对比


4. 总结
此次训练的效果与上次相似,但测试第一批数据集,能够检查出部分柚树
- 网上的制作自己的训练集的方法可能不适用yolov5的模型,因此还是通过平台进行制作,之后考虑参考网上教程和平台导出的数据自己组织数据。
- 此次训练量较少,大概训练到80个epoch的时候模型就已经稳定了,因为做了数据增加,使得能够是通过第四批训练的模型去检测到第一批的数据。


2021.04.02的训练总结中描述的负样本是不正确的,背景/ground true之外的就是负样本。5. 后续计划
考虑降低研究难度,去询问老师,看看能不能有新思路。
- 集成训练 和 分散训练
- 识别大分辨率图像,识别前裁剪成小分辨率,识别完后拼接回大分辨率(识别预处理和后处理)
- 自行组织数据,并制作教程
- 根据数据数量判断训练epoch
YOLOv5 [2021.04.16]
1. 前提准备 [2021.04.16]
与[2021.02.28]的训练保持一致,随机数据增强的部分:上下/左右翻转、高斯模糊、高斯噪声,同时自己通过代码制作数据集,形成一套数据流,快速制作YOLOv5格式的数据集2. 训练前配置
影像数据来自三个季度(2020秋季、2020冬季以及2021春季)无人机采集的数据,因为飞行范围不完全一致,通过ArcGIS求它们相交区域,裁剪得到公共区域影像数据
训练epoch是150。训练数据集2225个,验证集557个,测试集310个。
样本图像参数:640*640,50%3. 训练结果查看
- 训练时间
这次是集成训练,本次迭代150次,花费3.821个小时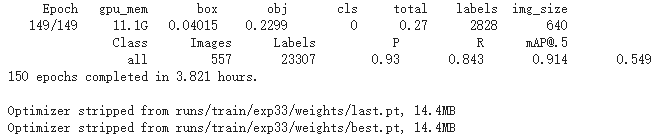
- 训练结果
平均精确度(mAP_0.5):0.9463
平均精确度(mAP_0.5:0.95):0.6754
精度(Percision):0.9588
召回率(Recall):0.8661

- 样本与预测对比

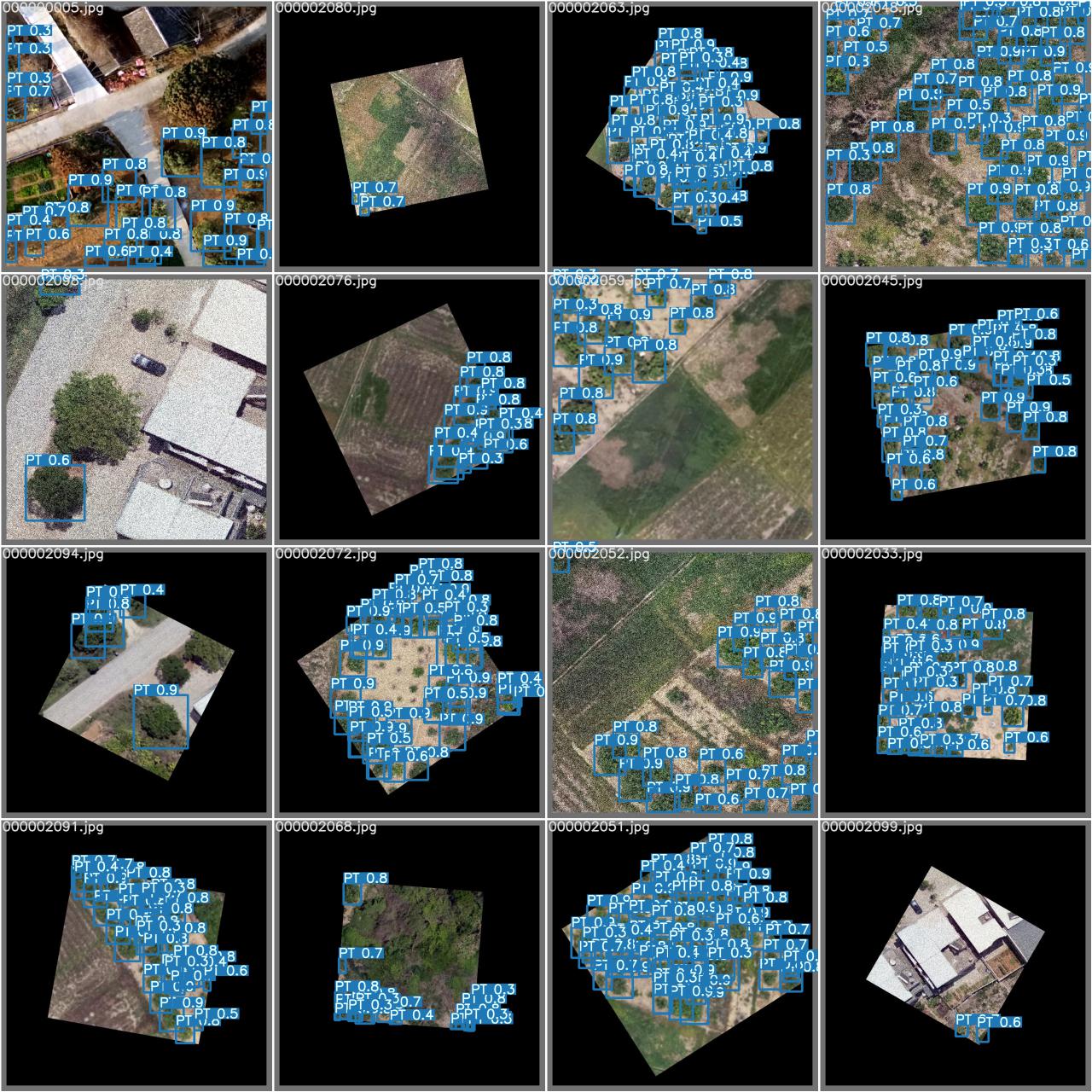
4. 总结
这次是将三个季度(2020秋季、2020冬季以及2021春季)飞的无人机数据进行训练,精度蛮高,同时也能识别出第一批数据(2020夏季,研究范围不同)的部分柚树

但也发现了点问题:

若有收获,就点个赞吧
0 人点赞
