一、Presto基础知识
Presto是Facebook开源的,基于内存的,分布式SQL交互式查询引擎,被设计成一种MPP(massively parallel processing - 大规模并行处理)架构。Presto本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto是一个OLAP(Online Analytical Processing - 联机分析处理)的工具,擅长对海量数据进行复杂的分析,但是对于OLTP(Online Transaction Processing - 联机事务处理)场景,并不擅长。
1.技术特性
完全基于内存的并⾏计算
MPP架构,多个节点管道式执⾏
使用ANSI SQL语法和语义
向量化计算
多线程处理
动态编译执⾏计划
优化的ORC和Parquet Reader
类BlinkDB的近似查询
不太支持存储过程,支持部分标准sql
2.适用范围
适合进行PB级海量数据复杂分析
适合进行交互式SQL查询
适合进行⽀持跨数据源查询
不适合进行多个大表的join操作,因为presto是基于内存的,多张大表在内存里可能放不下
二、基本架构
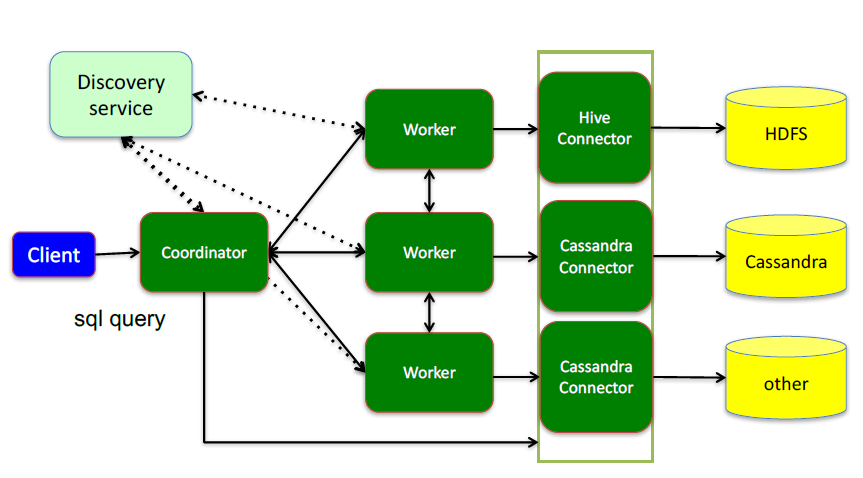
1.两种进程三大组件
- Coordinator服务进程
Coordinator是整个Presto集群的管理单元,与Discovery service协同完成调度工作。Coordinator主要用于接收客户端提交的查询,查询语句解析,生成查询执行计划、Stage和Task并对生成的Task进行调度。
- Worker服务进程
Worker节点是真正的计算节点。Presto集群拥有多个Worker节点。在每个Worker节点上都会存在一个Worker服务进程,该服务进程主要进行数据的处理以及Task的执行。当客户端提交一个查询的时候,Coordinator则会从当前存活的Worker列表中选择出合适的Worker节点去运行Task。而Worker在执行每个Task的时候又会进一步对当前Task读入的每个Spli进行一系列的操作和处理。每次处理时会到对应的数据源里面,去把数据提取出来,提取方式是通过各种各样的connector。
- Discovery service
Discovery service是Coordinator的一部分,通过它Presto实现了Coordinator与Worker结合。Worker节点启动后向Discovery Server服务进行注册,从而准备接受Coordinator的调度。而Worker服务进程每隔一定的时间都会向Discovery Server发送心跳,以表示:我还活着,并接受调度。Coordinator从Discovery Server获得可用的Worker节点信息。
2.Presto数据模型
- Connector
Presto是通过多种多样的Connector来访问多种不同的数据源的。你可以将Connector当作Presto访问各种不同数据源的驱动程序。Presto已经针对多种数据源开发了对应的Connector,包括:HDFS,ORC,RCFILE,Parquet,SequenceFile,Text,MySQL,PostgreSQL,Cassandra,Kafka,Redis,MongoDB,ElasticSearch,HBase等。每种Connector都实现了Presto中标准的SPI接口,因此只要你实现Presto中的标准的SPI接口,就可以轻易地实现使用适合自己特定需求的Connector来访问特定的数据源。
- Catalog
Catalog是数据源,如:MySql、Hive等。Presto通过Catalog实现跨数据源的级联查询。
- Schema
Schema是数据库实例,与传统数据库的Schema概念没有区别。
- Table
Table是数据表,同样与传统数据库的Table概念没有区别。
三、SQL的运行流程
1.整体流程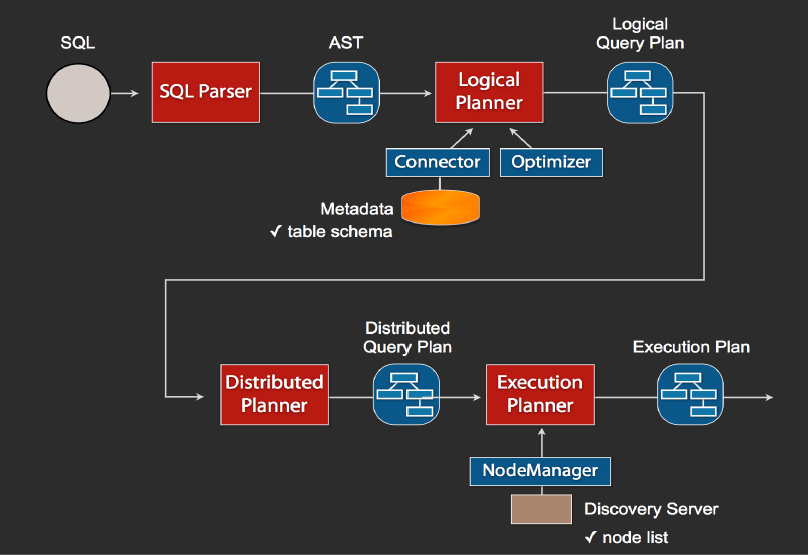
当执行一条sql查询时,coordinator接收到这条sql语句之后,会调用sql的语法解析器(SQL Parser)去把sql语法解析变成一个抽象的语法树(AST),这个过程中只是对SQL进行语法解析,比如说关键字你用的是int而不是Integer,就会在语法解析这里报错。
如果语法是符合sql语法规范,之后会经过一个逻辑查询计划器(Logical Planner)的组件,它的主要作用是将表的元信息与语法树对应起来并给出它认为最优的执行计划,即逻辑查询计划(Logical Query Plan)。比如sql里面出现的表,会通过connector的方式去meta里面把表的schema,列名,列的类型等,全部给找出来,并将这些信息和语法树给对应起来,之后会生成一个物理的语法树节点,这个语法树节点里面,不仅拥有了它的查询关系,还拥有类型的关系。如果发现表里某一列的类型,与sql的类型不一致,就会在这里报错。
通过上述两步得到的逻辑查询计划会被送到分布式的逻辑查询计划器(Distributed Planner)里面,进行分布式的解析,从而将对应的每一个查询计划转化为task,生成分布式查询计划(Distributed Query Plan)。
分布式查询计划会被发送给执行计划器(Execution Planner),执行计划器会向Discovery Server询问可用节点,生成执行计划(Execution Plan),由执行计划把task发给对应的worker去执行。
2.MapReduce vs Presto
Presto相比于MapReduce的优势在于全部Stage之间使用管道连接,没有等待时间;全内存数据传递没有IO损耗。一般认为可以提速5-10倍。但是因为没有落盘操作高可用性上表现不佳。<br />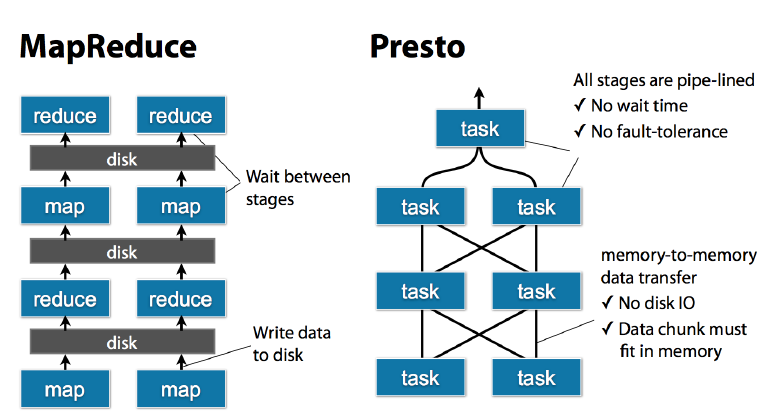

若有收获,就点个赞吧
0 人点赞
