一、简要概述
- 全量导入系统
Sqoop - Apache顶级项目,官网地址:http://sqoop.apache.org/
- 增量导入系统(CDC)
Cancal - 由Alibaba开源,源码下载地址:https://github.com/alibaba/canal
DataBus - 由LinkIn开源,源码下载地址:https://github.com/linkedin/databus
二、全量导入系统-Sqoop(SQL-to-Hadoop)
- 介绍
a) 连接传统关系型数据库和Hadoop 的桥梁
把关系型数据库的数据导入到Hadoop 系统( 如HDFS
、HBase 和Hive) 中;
把数据从Hadoop 系统里抽取并导出到关系型数据库里
b) 利用MapReduce加快数据传输速度
c) 批处理方式进行数据传输
d) 高效、可控地利用资源
可配置任务并行度,超时时间等
e) 数据类型映射与转换
可自动进行,用户也可自定义
f) 支持多种数据库
MySQL
Oracle
PostgreSQL
- 架构
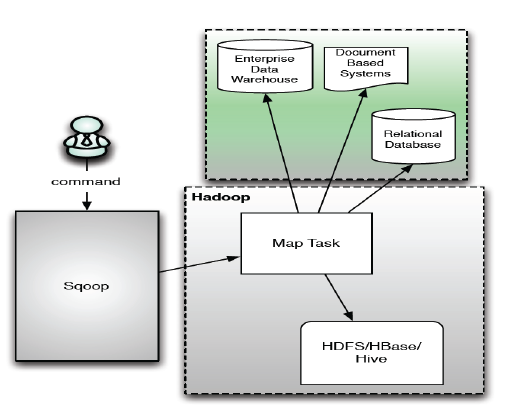
- 将数据从关系型数据库导入Hadoop中
步骤1:Sqoop与数据库Server
通信,获取数据库表的元数据
信息;
步骤2:Sqoop启动一个Map-
Only的MR作业,利用元数据信
息并行将数据写入Hadoop
sqoop import \
—connect jdbc:mysql://mysql.example.com/sqoop \
—username sqoop \
—password sqoop \
—table cities
Ø—connnect: 指定JDBC URL
Ø—username/password:mysql数据库的用户名
Ø—table:要读取的数据库表
举例: bin/hadoop fs -cat cities/part-m-*
1,USA,Palo Alto
2,Czech Republic,Brno
3,USA,Sunnyvale
扩展:将数据从关系型数据库导入Hive中
sqoop import \
—connect jdbc:mysql://mysql.example.com/sqoop \
—username sqoop \
—password sqoop \
—table cities \
—hive-import
扩展: 将数据从关系型数据库导入HBASE中
sqoop import \
—connect jdbc:mysql://mysql.example.com/sqoop \
—username sqoop \
—password sqoop \
—table cities \
—hbase-table cities \
—column-family world
- 将数据从Hadoop导入关系型数据库导中
步骤1:Sqoop与数据库Server
通信,获取数据库表的元数据
信息;
步骤2:并行导入数据:
将Hadoop上文件划分成若
干个split;
每个split由一个Map Task进
行数据导入。
sqoop export \
—connect jdbc:mysql://mysql.example.com/sqoop \
—username sqoop \
—password sqoop \
—table cities \
—export-dir cities
Ø—connnect: 指定JDBC URL
Ø—username/password:mysql数据库的用户名
Ø—table:要导入的数据库表
Øexport-dir:数据在HDFS上存放目录
三、增量数据导入系统CDC
- 介绍
常用工具: Canal、DataBus
可借助MySQL Binlog实现实时数据抽取至任意存储, 工作模式如下图: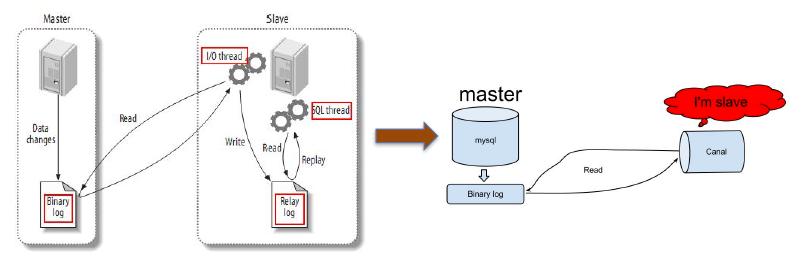
- 架构(Canal)
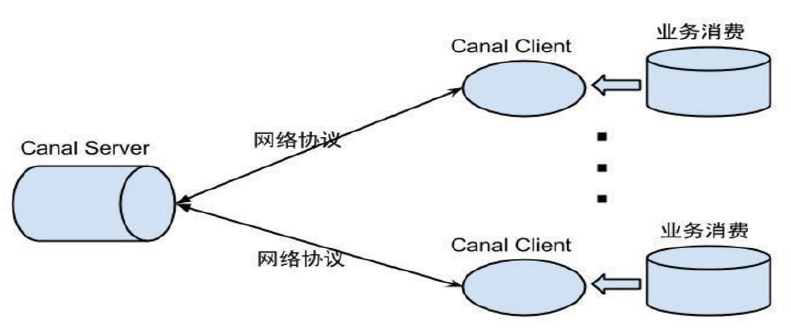
数据消费原理
- 基于网络协议,提供数据订阅&消费,类似于SQL Thread实现业务自定义

若有收获,就点个赞吧
0 人点赞
