干货
1.sprak streaming是底层基于rdd的,这也是为什么他有很多函数和rdd是一样的
2.streaing本质是微批
3.带状态的算子,mapwithstate(增量计算)性能优于updatestatebykey(全量计算)
4.数据来源很多种,实际业务都是从KAFKA
5.应用streaming时是基于transformation然后action.
这里还有一个点需要强调一下,就是自定义接口foreachRDD,和transformation都是基于rdd的
前者(foreachrdd)无返回值,后者有返回值。
6.与数据库交互过程最优方案是在forpation里取得与数据库的连接
7.kafaka offset的管理是从0.10开始支持的
8.容错要用到CHECKPOINT
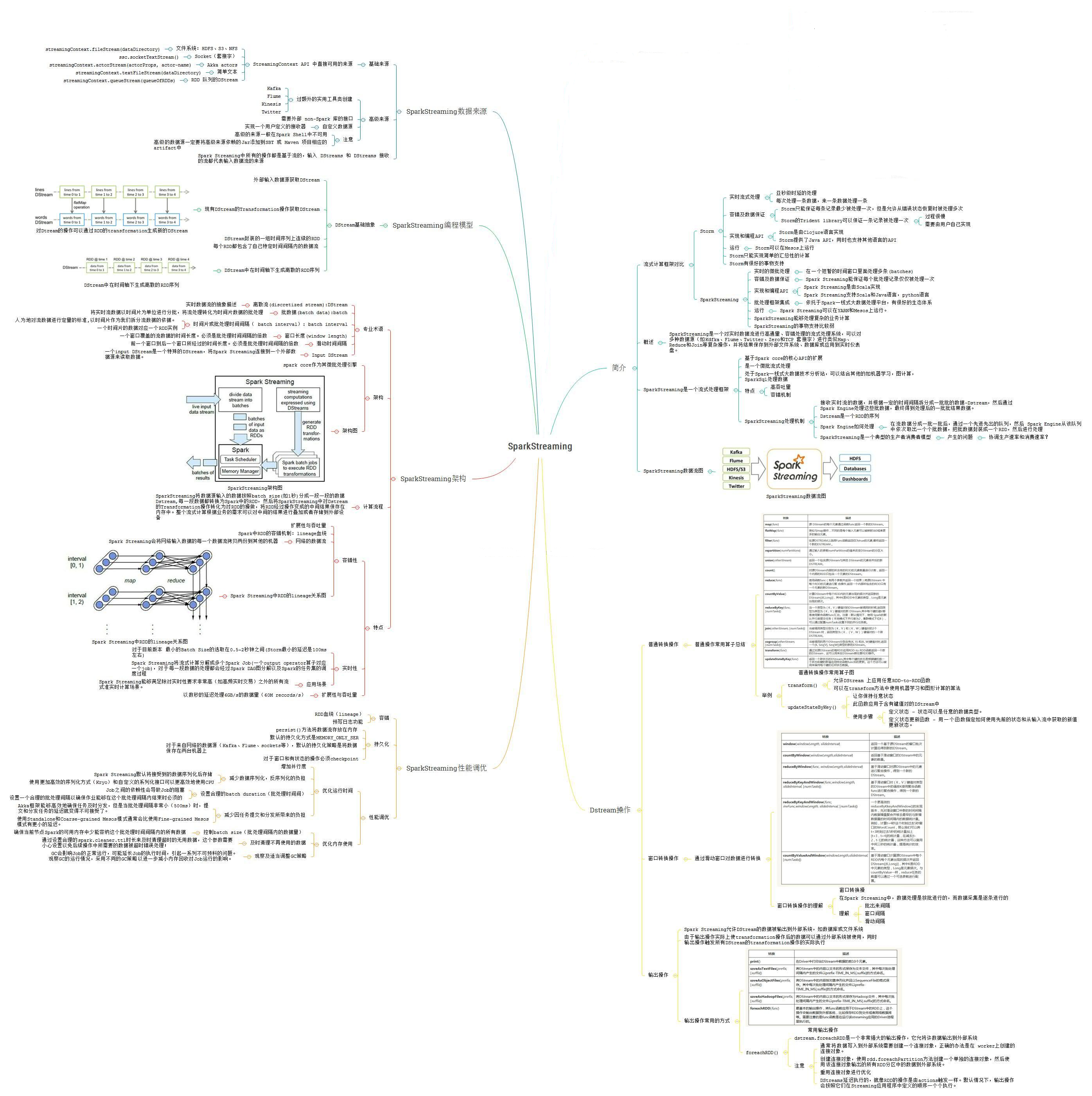
知识架构图
RDD
each RDD is characterized by five main properties:
*
- A list of partitions
- A list of partitions
- A function for computing each split
- A function for computing each split
- A list of dependencies on other RDDs
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for
- an HDFS file)
每个RDD有5个主要的属性:
- 一组分片(partition),即数据集的基本组成单位
- 一个计算每个分片的函数
- 对parent RDD的依赖,这个依赖描述了RDD之间的lineage
- 对于key-value的RDD,一个Partitioner
- 一个列表,存储存取每个partition的preferred位置。对于一个HDFS文件来说,存储每个partition所在的块的位置。
org.apache.spark.rdd.RDD是一个抽象类,定义了RDD的基本操作和属性。这些基本操作包括map,filter和persist。另外,org.apache.spark.rdd.PairRDDFunctions定义了key-value类型的RDD的操作,包括groupByKey,join,reduceByKey,countByKey,saveAsHadoopFile等。org.apache.spark.rdd.SequenceFileRDDFunctions包含了所有的RDD都适用的saveAsSequenceFile。
RDD支持两种操作:转换(transformation)从现有的数据集创建一个新的数据集;而动作(actions)在数据集上运行计算后,返回一个值给驱动程序。 例如,map就是一种转换,它将数据集每一个元素都传递给函数,并返回一个新的分布数据集表示结果。另一方面,reduce是一种动作,通过一些函数将所有的元素叠加起来,并将最终结果返回给Driver程序。(不过还有一个并行的reduceByKey,能返回一个分布式数据集)
Spark中的所有转换都是惰性的,也就是说,他们并不会直接计算结果。相反的,它们只是记住应用到基础数据集(例如一个文件)上的这些转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。
默认情况下,每一个转换过的RDD都会在你在它之上执行一个动作时被重新计算。不过,你也可以使用persist(或者cache)方法,持久化一个RDD在内存中。在这种情况下,Spark将会在集群中,保存相关元素,下次你查询这个RDD时,它将能更快速访问。在磁盘上持久化数据集,或在集群间复制数据集也是支持的。
如果把类定义一个时间戳
就可以GROUP BY S
….
jvm参数
csm
j1jc
RDD->DataFrame:反射方式
显示注入Schema


若有收获,就点个赞吧
0 人点赞
