一、是什么
- 从Spark 1.0开始,成为Spark生态系统一员
- 专门处理结构化数据(比如DB, Json)的Spark组件
- 提供了2种操作数据的方式
SQL
DataFrames/Datasets API - Spark SQL = Schema + RDD
二、为什么用
- SQL能够跟现有系统进行很好集成
跟现有的JDBC/ODBC BI系统兼容 - 很多工程师习惯使用SQL
- 相比于Spark RDD API,SQL更容易表达
- 更快地编写和运行Spark程序
编写更少的代码
读取更少的数据
让优化器自动优化程序,释放程序员的工作
三、怎么用
- 了解结构
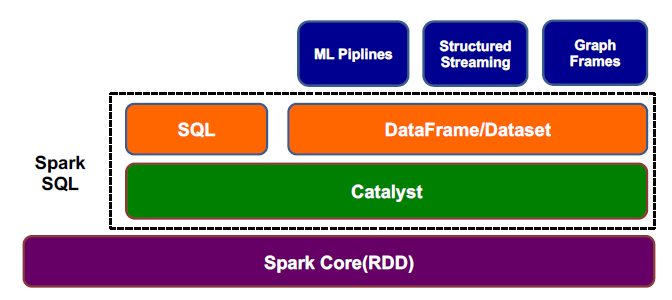
2 . 程序设计编写流程
创建SparkSession对象:封装了spark sql执行环境信息,是所有Spark SQL程序的唯一入口
创建DataFrame或Dataset:Spark SQL支持各种数据源
在DataFrame或Dataset之上进行transformation和action:Spark SQL提供了多种transformation和action函数
返回结果:保存到HDFS中,或直接打印出来
3 . 使用SQL
熟悉SQL的情况下则直接使用SQL,其部署架构如下图: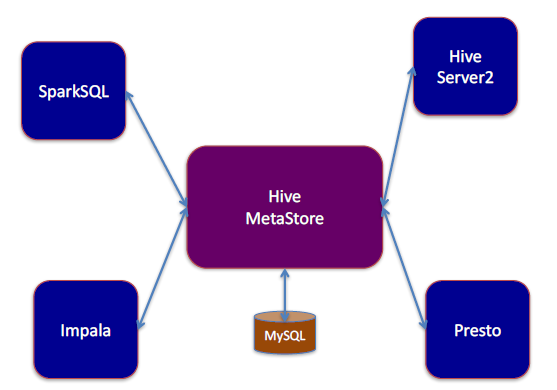
与Hive MetaStore结合
将core-site.xml、hdfs-site.xml和hive-site.xml拷入spark安装目录下的conf/中
Spark SQL与Hive Metastore结合:直接使用spark.sql(“SELECT… FROM table WHERE …”)
JDBC/ODBC和CLI
启动thrift server
使用beeline访问
4 . 使用DataFrame API
优势:
Row对象组成的分布式数据集合
不可变且具有容错能力
处理结构化数据
自带优化器Catalyst,可自动优化程序
Data source API
局限性:
运行时类型检查
不能直接操作domain对象
函数式编程风格
5 . 使用DataSet API
扩展自DataFrame API,提供了编译时类型安全,面向对象风格的API
较DataFrame优势:
类型安全:可直接作用在domain对象上
高效:代码生成编解码器,序列化更高效
协作:Dataset与Dataframe可相互转换
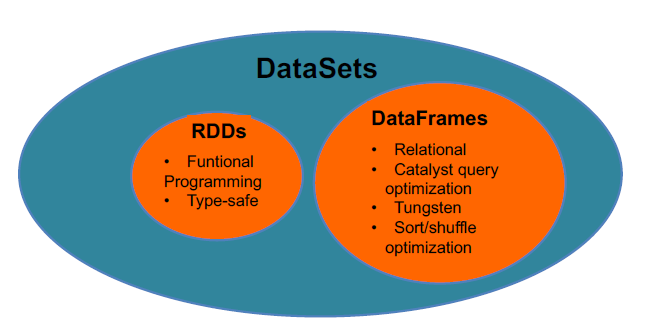
6 . RDD、DataFrame与DataSet对应关系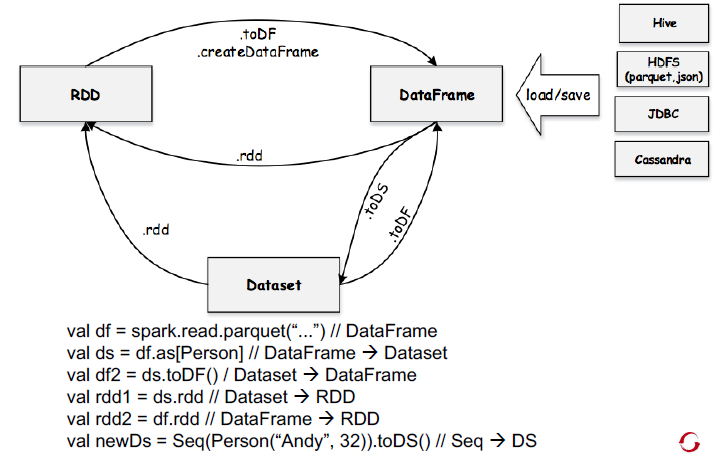
四、调优
- DataFrame缓存
- 参数调优
Reduce task数目:spark.sql.shuffle.partitions (默认是200)
读数据时每个Partition大小:spark.sql.files.maxPartitionBytes (默认128MB)
小文件合并读:spark.sql.files.openCostInBytes (默认是4194304 (4 MB) )
广播小表大小:spark.sql.autoBroadcastJoinThreshold(默认是10485760 (10 MB))
五、总结
Spark SQL程序设计思路与Spark类似
Spark SQL支持各种数据源:json, parquet, jdbc, hbase ….
DataFrame提供了丰富的operation函数
Transformation
Action
转换为临时表,用SQL查询
RDD operation

若有收获,就点个赞吧
0 人点赞
