java基础
1.Java基本数据类型
byte(位)8、char(字符)16和boolean(布尔值) 8
short(短整数)16、int(整数)32、long(长整数)64、
float(单精度)32、double(双精度)64、
2.JDK和JRE
JDK:java development kit (java开发工具)
JRE:java runtime environment (java运行时环境)
3.重载和重写
重写:参数列表,方法名,返回值类型必须一致,子类函数的访问修饰权限不能比父类低
重载:方法名一致,参数列表中的顺序,类型,个数可以不同,重载对返回类型没有要求
4.Java构造方法能不能重写
重写是子类方法重写父类的方法,重写的方法名不变,而类的构造方法名必须与类名一致,假设父类的构造方法如果能够被
子类重写则子类类名必须与父类类名一致才行,所以 Java 的构造方法是不能被重写的。
5.集合
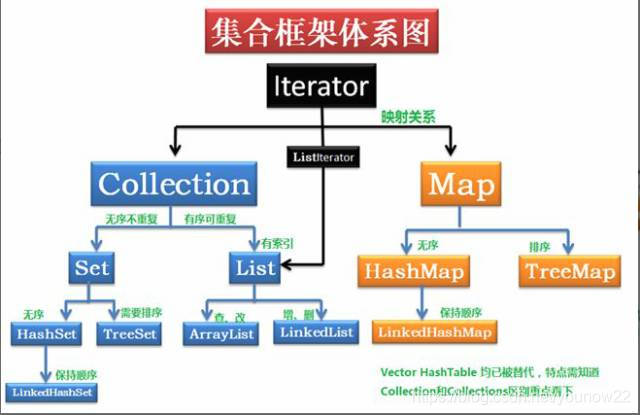
6.线程安全的集合有哪些?
Vector、HashTable, ConcurrentHashMap
7.hashmap的底层原理?
HashMap基于Map接口实现,元素以键值对的方式存储,他的键和值都可为空(hashtable不允许空值,键和值都不可以), 但最多只允许一条记录的键为null,允许多条记录的的值为null。hashmap是无序的,是线程不安全的。
JDK1.8之前为数组+链表,JDK1.8之后数组+链表/红黑树(当链表长度到8时,转化为红黑树)
HashMap的初始容量 16,扩容因子默认为0.75,也就是会浪费1/4的空间,达到扩容因子时,会将数组扩容一倍,0.75是时间与空间的一个平衡值
1.Hashmap为什么线程不安全?
HashMap的线程不安全主要是发生在扩容函数中
1.在JDK1.7中,扩容时采用头插法,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,扩容时采用尾插法,在并发执行put操作时会发生数据覆盖的情况。
2.怎么存储的
使用put(key, value)存储对象到HashMap中, 当添加一个元素(key-value)时,首先调用key对象的hashcode()方法,获得hashcode,然后根据hashcode计算出hash值,以此确定插入数组中的位置,但是可能存在同一个hash值的元素已经放在同一位置了,这是就添加到同一hash值元素的后面,他们在数组同一个位置,就形成了链表,同一个链表上的hash值是相同的,所以说数组存放的是链表。
3.为什么用红黑树不用B+树
之所以选择红黑树是为了解决二叉查找树的缺陷,二叉查找树在特殊情况下会变成一条线性结构,遍历查找会非常慢。而红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,引入红黑树就是为了查找数据快,解决链表查询深度的问题
8.hashtable和ConcurrentHashMap的区别?
ConcurrentHashMap和HashTable都是线程安全的集合,它们的不同主要是加锁粒度上的不同。HashTable的加锁方法是给每个方法加上synchronized关键字,这样锁住的是整个Table对象。而ConcurrentHashMap是更细粒度的加锁
在JDK1.8之前,ConcurrentHashMap加的是分段锁,也就是Segment锁,每个Segment含有整个table的一部分,这样不同分段之间的并发操作就互不影响
JDK1.8对此做了进一步的改进,它取消了Segment字段,直接在table元素上加锁,实现对每一行进行加锁,进一步减小了并发冲突的概率
9.ConcurrentHashMap 底层具体实现知道吗?实现原理是什么?
在JDK1.7中,ConcurrentHashMap采用Segment + HashEntry的方式进行实现,结构如下:
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
JDK1.8
在JDK1.8中,放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
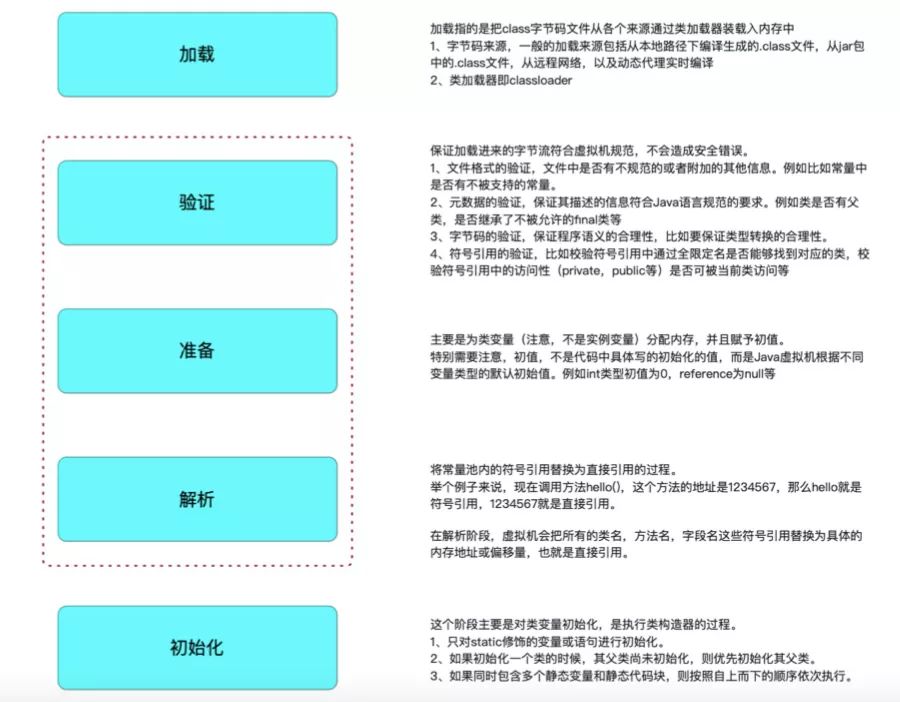
10.类加载器
1)启动类加载器
2)扩展类加载器
3)系统类加载器(App类加载器)
1.什么是classloader
就是类加载。虚拟机把描述类的数据从class字节码文件加载到内存,并对数据进行检验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制
Mysql
1、mysql优化流程
1).通过show status 命令了解各种sql的执行效率
2). 定位执行效率较低的SQL语句(dql出现问题的概率较dml的大)
3).通过explain分析低效率的SQL语句的执行情况
4).确定问题并采取相应的优化措施
常用的优化措施是添加索引
explain + SQL语句 select_type:查询的类型
select_type:查询的类型
type: 非常重要的指标:
System>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
possible_keys:显示可能应用在这张表中的索引,一个或多个
Key:实际使用的索引
2.避免索引失效优化方案:
1.全字段匹配
2如果索引了多列,要遵守最左前缀法则
3.尽量避免在where子句中对字段进行null值判断
4,尽量避免在字段开头模糊查询(%…%)
5,尽量避免使用or,会导致索引失效,可以用union代替or
6,尽量避免使用in或not in,会导致索引失效,如果是连续数值,用between代替,如果是子查询,可以有exists代替。

若有收获,就点个赞吧
0 人点赞
