类图

概念解释
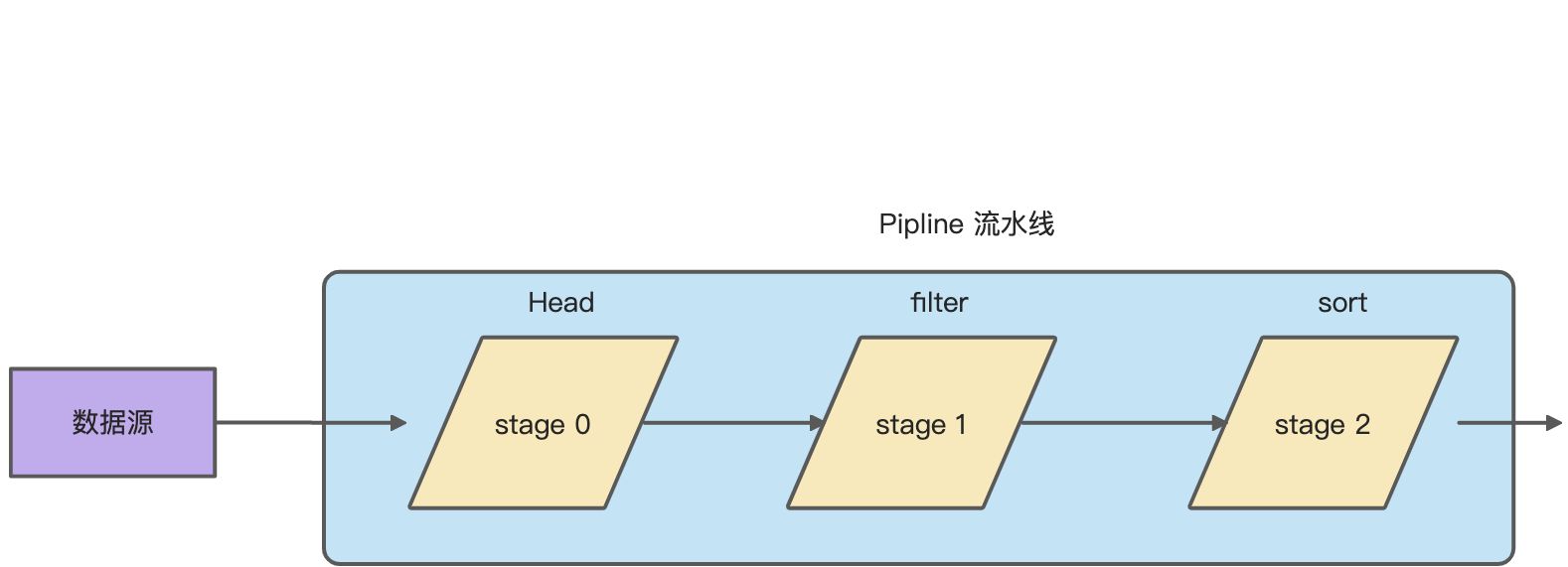
Pipline和Stage
Pipline是流水线,表示一整个流程。Stage表示流水线的其中一个阶段。是一个比较抽象层面的描述,因为stage主要表示一种逻辑上的顺序关系,而具体每一个阶段要干嘛、怎么干,使用Sink来进行描述。
new stream //stage 0.filter() //stage 1.sort() //stage 2
Sink
直译为水槽,生活中水槽的作用无非
- 打开水龙头,知道有水要来
- 水在水槽里, 可以进行一些操作
- 打开水闸,放水
Java中的Sink核心功能为:
- begin(): 告诉该水槽水流要来了,可以进行一些初始化操作
- accept():接受水流,然后进行操作
- end():水流全部处理完了。
看一个sort()的示例,sort这个stage的目的就是对所有水流进行排序,然后再流到下游。
private static final class SizedRefSortingSink<T> extends AbstractRefSortingSink<T> {private T[] array; //要进行排序,需要一个数组进行缓存private int offset;SizedRefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {super(sink, comparator);}@Override@SuppressWarnings("unchecked")public void begin(long size) {if (size >= Nodes.MAX_ARRAY_SIZE)throw new IllegalArgumentException(Nodes.BAD_SIZE);//上游调用begin(),通知sort进行初始化操作,生产一个数组array = (T[]) new Object[(int) size];}//上游调用end()方法,告诉sort水已经全部流过来了。sort开始执行操作@Overridepublic void end() {//操作Arrays.sort(array, 0, offset, comparator);//告诉sort的下游准备接受水流downstream.begin(offset);//一个个元素的传递给下游if (!cancellationWasRequested) {for (int i = 0; i < offset; i++)downstream.accept(array[i]);}else {for (int i = 0; i < offset && !downstream.cancellationRequested(); i++)downstream.accept(array[i]);}//告诉下游水流传递结束downstream.end();//缓存清空array = null;}//上游调用accept()方法,将水流存储到到sort的缓存数组中@Overridepublic void accept(T t) {array[offset++] = t;}}
创建Head
几个疑问
-
使用方式
可以使用Stream.of()创建一个流,例如
//创建方式 of()Stream<Integer> stream = Stream.of(1, 2, 3);
源码分析
of()方法调用
StreamSupport.stream(Arrays.spliterator(arr, 0, arr.length), false);
stream()方法逻辑:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {Objects.requireNonNull(spliterator);return new ReferencePipeline.Head<>(spliterator,StreamOpFlag.fromCharacteristics(spliterator),parallel);}
构造方法的主要了逻辑要一直super()到
AbstractPipeline类/*** The source spliterator. Only valid for the head pipeline.* Before the pipeline is consumed if non-null then {@code sourceSupplier}* must be null. After the pipeline is consumed if non-null then is set to* null.*/private Spliterator<?> sourceSpliterator;/*** Constructor for the head of a stream pipeline.** @param source {@code Spliterator} describing the stream source* @param sourceFlags the source flags for the stream source, described in* {@link StreamOpFlag}* @param parallel {@code true} if the pipeline is parallel*/AbstractPipeline(Spliterator<?> source,int sourceFlags, boolean parallel) {this.previousStage = null;//使用一个字段指向数据集合的Spliterator,后续终结操作的时候,引用的方式操作数据this.sourceSpliterator = source;this.sourceStage = this;this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;// The following is an optimization of:// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;this.depth = 0;this.parallel = parallel;}
调用了
ReferencePipeline.Head<>,返回一个Head对象。Head是ReferencePipeline的子类。可以理解为Head是流水线的第一个stage。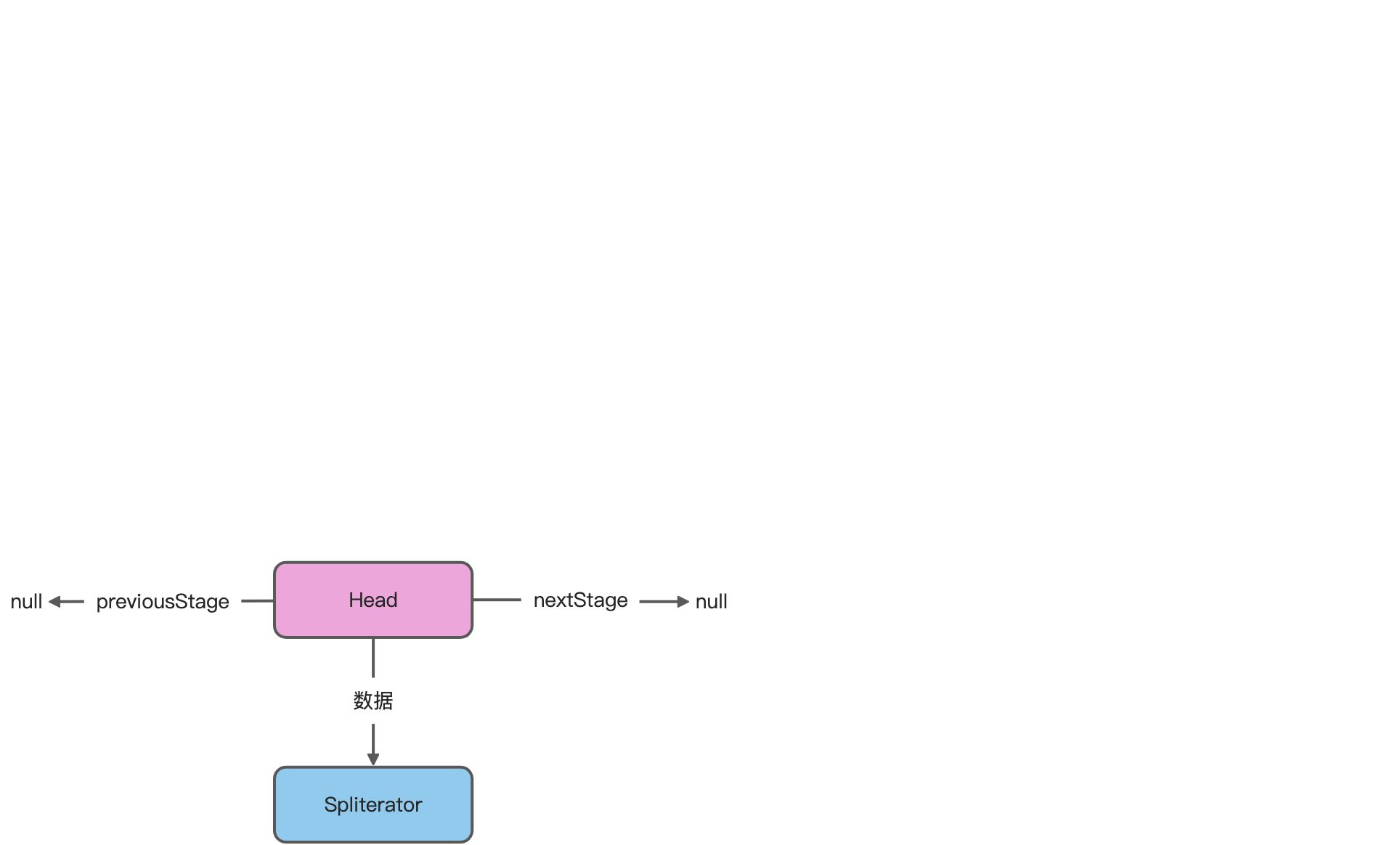
疑问解答
- 官方说Stream不存储数据,那么数据保存在那里呢?
Head中保存数据源的Spliterator对象,后续操作Spliterator的方式操作数据
中间操作
几个疑问
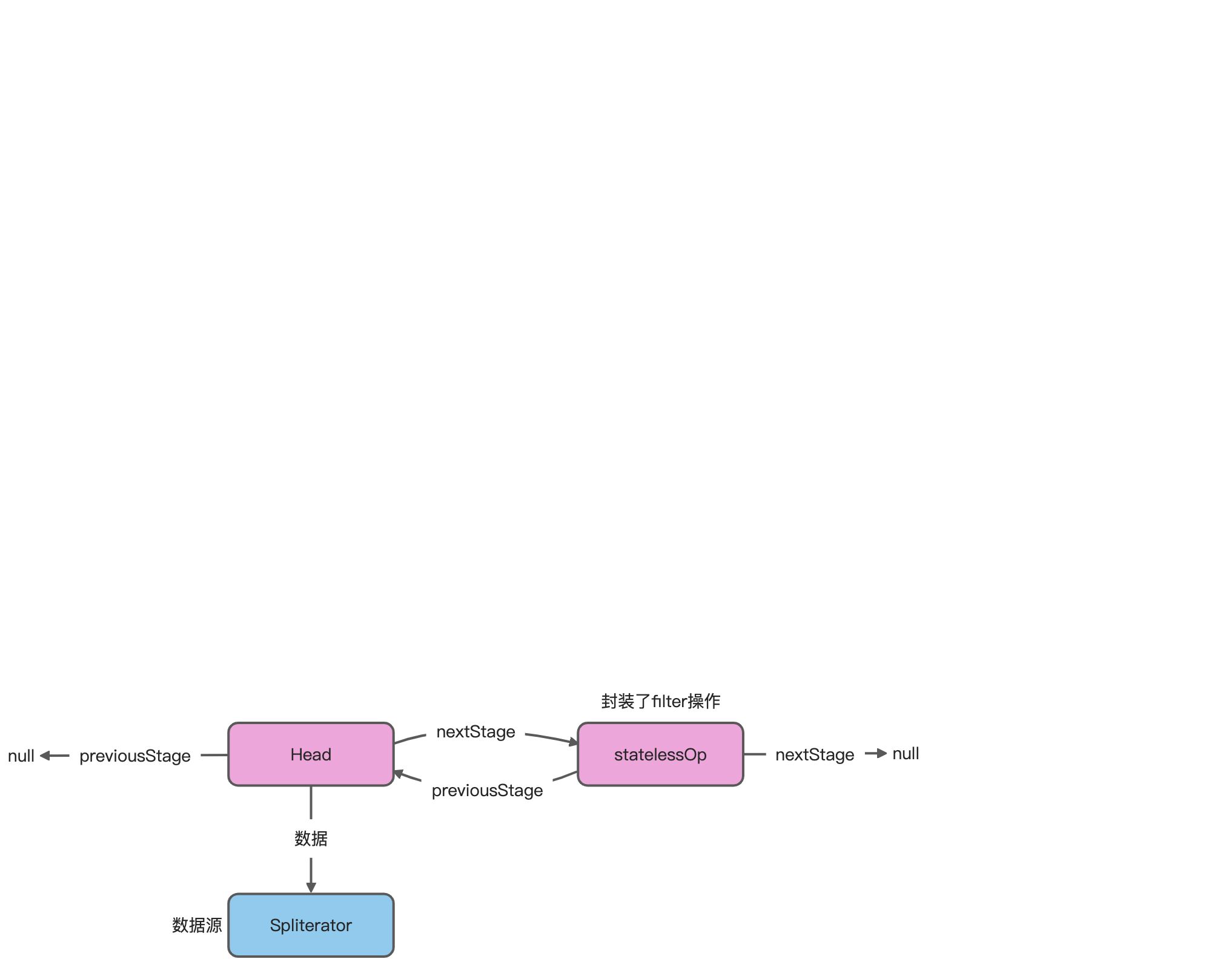
- 各个中间操作是如何进行关联的?
- 一个个的操作封装成了一个个的
statelessOp或stateFulOp对象,以双向链表的方法串起来。
- 一个个的操作封装成了一个个的
- 如何执行完一个中间操作,然后执行下一个?
- Sink类负责流水线操作的承接上下游和执行操作的任务,核心方法为begain()、accept()、end()。
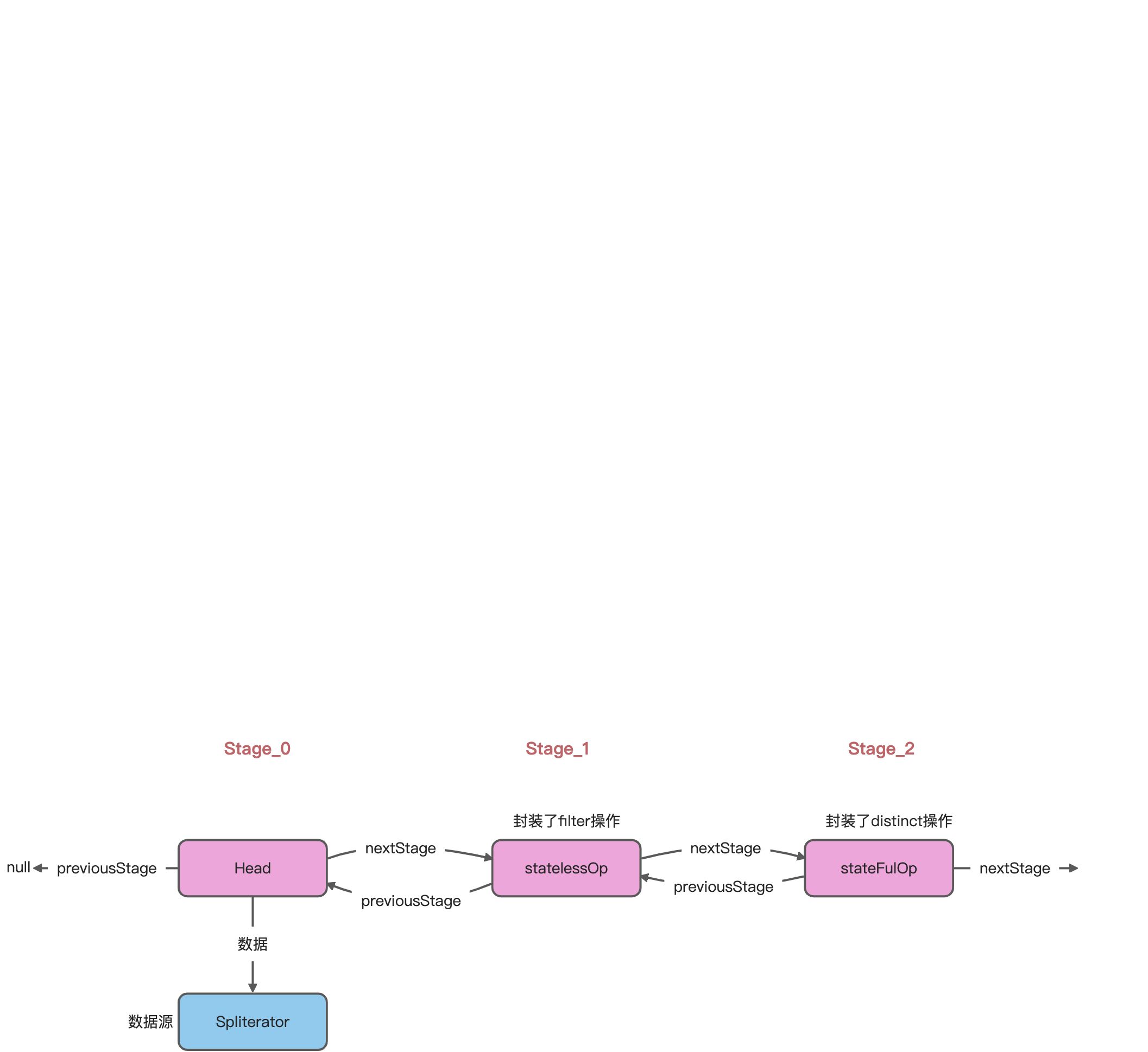
- 有状态的中间操作是怎么保存状态的?
- 有状态的中间操作封装成
stateFulOp对象,各自都有独立的逻辑,具体的参考sort()的实现逻辑。
- 有状态的中间操作封装成
- 懒加载如何实现的
//等同于
Stream
<a name="BzfO4"></a>### Filter执行filter(op)会发生什么?```javaStream<Integer> afterFilter = head.filter(e -> e = 1);
filter()方法定义在Stream类,实现在ReferencePipeline类。
//ReferencePipeline.class@Overridepublic final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {Objects.requireNonNull(predicate);// 返回一个StatelessOp类// 构造函数参数为(this,)return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {@Overridepublic void begin(long size) {downstream.begin(-1);}@Overridepublic void accept(P_OUT u) {if (predicate.test(u))downstream.accept(u);}};}};}
返回一个StatelessOp类(因为filter是一个无状态操作),看下StatelessOp类,是一个静态抽象内部类,继承了ReferencePipeline类。
//ReferencePipeline.class/*** Base class for a stateless intermediate stage of a Stream.** @param <E_IN> type of elements in the upstream source* @param <E_OUT> type of elements in produced by this stage* @since 1.8*/abstract static class StatelessOp<E_IN, E_OUT>extends ReferencePipeline<E_IN, E_OUT> {/*** Construct a new Stream by appending a stateless intermediate* operation to an existing stream.** @param upstream The upstream pipeline stage* @param inputShape The stream shape for the upstream pipeline stage* @param opFlags Operation flags for the new stage*/StatelessOp(AbstractPipeline<?, E_IN, ?> upstream,StreamShape inputShape,int opFlags) {super(upstream, opFlags);assert upstream.getOutputShape() == inputShape;}@Overridefinal boolean opIsStateful() {return false;}}
中间super()会执行AbstractPipeline�类的构造方法, 连接stage之间的关系
//AbstractPipeline.class/*** Constructor for appending an intermediate operation stage onto an* existing pipeline.** @param previousStage the upstream pipeline stage* @param opFlags the operation flags for the new stage, described in* {@link StreamOpFlag}*/AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {if (previousStage.linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);previousStage.linkedOrConsumed = true;previousStage.nextStage = this;this.previousStage = previousStage;this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);this.sourceStage = previousStage.sourceStage;if (opIsStateful())sourceStage.sourceAnyStateful = true;this.depth = previousStage.depth + 1;}
�Distinct
示例
Stream<Integer> afterDistinct = afterFilter.distinct();
distinct的方法实现在ReferencePipeline类下
@Overridepublic final Stream<P_OUT> distinct() {return DistinctOps.makeRef(this);}
调用DistinctOps类的makeRef()方法,返回一个StatefulOp类,并重写了4个方法,实现逻辑在opWrapSink()中:
/*** Appends a "distinct" operation to the provided stream, and returns the* new stream.** @param <T> the type of both input and output elements* @param upstream a reference stream with element type T* @return the new stream*/static <T> ReferencePipeline<T, T> makeRef(AbstractPipeline<?, T, ?> upstream) {// 返回一个StatefulOp类return new ReferencePipeline.StatefulOp<T, T>(upstream, StreamShape.REFERENCE,StreamOpFlag.IS_DISTINCT | StreamOpFlag.NOT_SIZED) {// 重写了以下几个方法,内容省略...<P_IN> Node<T> reduce(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {...}@Override<P_IN> Node<T> opEvaluateParallel(PipelineHelper<T> helper,Spliterator<P_IN> spliterator,IntFunction<T[]> generator) {...}@Override<P_IN> Spliterator<T> opEvaluateParallelLazy(PipelineHelper<T> helper, Spliterator<P_IN> spliterator) {...}@OverrideSink<T> opWrapSink(int flags, Sink<T> sink) {Objects.requireNonNull(sink);if (StreamOpFlag.DISTINCT.isKnown(flags)) {...} else if (StreamOpFlag.SORTED.isKnown(flags)) {...} else {// 返回一个SinkChainedReference类return new Sink.ChainedReference<T, T>(sink) {//使用一个Set缓存数据,进行去重Set<T> seen;//当上游通知begin的时候,初始化Set@Overridepublic void begin(long size) {seen = new HashSet<>();downstream.begin(-1);}//略@Overridepublic void end() {seen = null;downstream.end();}//如果已经存在,之间抛弃@Overridepublic void accept(T t) {if (!seen.contains(t)) {seen.add(t);downstream.accept(t);}}};}}};}
StatefulOp类与StatelessOp类相似,都是继承了ReferencePipeline类,然后中间super()页会执行AbstractPipeline�类的构造方法, 连接stage之间的关系
/*** Base class for a stateful intermediate stage of a Stream.** @param <E_IN> type of elements in the upstream source* @param <E_OUT> type of elements in produced by this stage* @since 1.8*/abstract static class StatefulOp<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {//省略}
至于其他的中间操作,套路都是类似的,操作逻辑封装在opWrapSink()方法里, 可以慢慢的看。
终结操作
几个疑问
- 终结方法是如何进行操作的?
- 终结操作的实现里面都有调用evaluate()方法,这个方法最后会warp所有操作变成一串sink,然后从头开始执行begin(),accept(),end()方法
- 如何实现由终结操作触发流的运作的?
- 触发的开关是wrapAndCopyInto(),这个方法只有在终结操作中才有被调用。
- 如何保证一个流一次只能执行一个终结方法?
 ```java
// 计算流中元素数量,FindOP
long count = afterLimit.count();
```java
// 计算流中元素数量,FindOP
long count = afterLimit.count();// 遍历所有元素,ForEachOp afterLimit.forEach(System.out::printl);
// 获取第一个元素,MatchOp
Optional
// 判断是否,ReduceOp boolean flag = afterLimit.anyMatch(i -> i == 1);
<a name="RhEbI"></a>### count()在`ReferencePipeline`类中实现```java@Overridepublic final long count() {// 调用mapToLong将所有元素变成1,然后计算sumreturn mapToLong(e -> 1L).sum();}
maoToLong()
mapToLong()方法,是一个中间操作
@Overridepublic final LongStream mapToLong(ToLongFunction<? super P_OUT> mapper) {Objects.requireNonNull(mapper);return new LongPipeline.StatelessOp<P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {@OverrideSink<P_OUT> opWrapSink(int flags, Sink<Long> sink) {return new Sink.ChainedReference<P_OUT, Long>(sink) {@Overridepublic void accept(P_OUT u) {//downstream.accept(mapper.applyAsLong(u));}};}};}
ToLongFunction是一个函数式接口类, accept()里的逻辑便是e -> 1L.
@FunctionalInterfacepublic interface ToLongFunction<T> {/*** Applies this function to the given argument.** @param value the function argument* @return the function result*/long applyAsLong(T value);}
看下Sum()方法,在LongPipeline类中,传入参数是一个Long::sum, sum的作用是相加两个值。
@Overridepublic final long sum() {// use better algorithm to compensate for intermediate overflow?return reduce(0, Long::sum);}//public static long sum(long a, long b) {// return a + b;//}
reduce()
reduce方法,将操作函数op封装成一个Sink,makeLong()的作用就是会生产一个Sink
@Overridepublic final long reduce(long identity, LongBinaryOperator op) {return evaluate(ReduceOps.makeLong(identity, op));}
/*** Constructs a {@code TerminalOp} that implements a functional reduce on* {@code long} values.** @param identity the identity for the combining function* @param operator the combining function* @return a {@code TerminalOp} implementing the reduction*/public static TerminalOp<Long, Long>makeLong(long identity, LongBinaryOperator operator) {Objects.requireNonNull(operator);class ReducingSinkimplements AccumulatingSink<Long, Long, ReducingSink>, Sink.OfLong {//state是一个用作记录的值private long state;@Overridepublic void begin(long size) {state = identity;}//参数传进来的就是sun(),所以这里的accept()的作用就是对state不断进行累加@Overridepublic void accept(long t) {state = operator.applyAsLong(state, t);}@Overridepublic Long get() {return state;}@Overridepublic void combine(ReducingSink other) {accept(other.state);}}return new ReduceOp<Long, Long, ReducingSink>(StreamShape.LONG_VALUE) {@Overridepublic ReducingSink makeSink() {return new ReducingSink();}};}
evaluate()
看回evaluate()方法,这个方法用来执行终结操作的
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {assert getOutputShape() == terminalOp.inputShape();//判断流是否已被使用if (linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);//设置使用标记为truelinkedOrConsumed = true;//根据流类型,执行相应的推断操作return isParallel()? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags())): terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));}
关注时序流的推断方法,可以看到这个方法的实现分为四种,对应上面提到的四类类型操作,count属于ReduceOp,进去看下。
//from ReduceOps@Overridepublic <P_IN> R evaluateSequential(PipelineHelper<T> helper,Spliterator<P_IN> spliterator) {//调用wrapAndCopyInto()方法return helper.wrapAndCopyInto(makeSink(), spliterator).get();}
wrapAndCopyInto()
保证所有stage -> sink链表,然后执行copyInto()方法
@Overridefinal <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);return sink;}
warpSink()
就是在这里,从后向前,包装所有的stage阶段,形成一条sink链表。这样将之前一个个stage的链表结构包装成一个个Sink。
@Override@SuppressWarnings("unchecked")final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {Objects.requireNonNull(sink);//从后向前遍历for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {//执行每个opWrapSink()方法,这个方法在每个操作类中都进行了重写sink = p.opWrapSink(p.previousStage.combinedFlags, sink);}//返回头sinkreturn (Sink<P_IN>) sink;}
copyInto()
这个方法是整个流水线的启动开关,流程如下:
- 调用第一个sink的begin()方法
- 执行数据源的spliterator.forEachRemaining(wrappendSink)方法遍历调用accept()方法
end() 通知结束
@Overridefinal <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {Objects.requireNonNull(wrappedSink);if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {//通知第一个sink,做好准备接受流wrappedSink.begin(spliterator.getExactSizeIfKnown());//执行spliterator.forEachRemaining(wrappedSink);wrappedSink.end();}else {copyIntoWithCancel(wrappedSink, spliterator);}}
forEachRemaining()
在各个容器中都有实现forEachRemaining()这个方法,在ArrayList中:
public boolean tryAdvance(Consumer<? super E> action) {if (action == null)throw new NullPointerException();int hi = getFence(), i = index;if (i < hi) {index = i + 1;@SuppressWarnings("unchecked") E e = (E)list.elementData[i];//执行accept()方法action.accept(e);if (list.modCount != expectedModCount)throw new ConcurrentModificationException();return true;}return false;}
其他终结操作
forEach()
在
ReferencePipeline类中,实现了forEach()方法, ```java // from ReferencePipeline.class
@Override public void forEach(Consumer<? super P_OUT> action) { // ForEachOps.. evaluate(ForEachOps.makeRef(action, false)); }
evaluate后面的逻辑与count后面的一样了,略。<a name="s1dNc"></a>#### findFirst() anyMatch()findFirst()和anyMatch()的逻辑也不再多说了,一个套路,看下实现```java@Overridepublic final Optional<P_OUT> findFirst() {return evaluate(FindOps.makeRef(true));}@Overridepublic final boolean anyMatch(Predicate<? super P_OUT> predicate) {return evaluate(MatchOps.makeRef(predicate, MatchOps.MatchKind.ANY));}

若有收获,就点个赞吧
0 人点赞
